
Semi-Automatic Method of Extracting Road Networks from High-Resolution Remote-Sensing Images


Abstract
:1. Introduction
- A complete road network extraction framework with high accuracy and availability is proposed. With only a few seed points, the whole road can be obtained quickly. First, the width and seed points of a road are set interactively, and the skeleton of the road is extracted by using regional growth and morphological algorithms. Then, a single-road vector is obtained after vector tracking, vector simplification, endpoint modification, and road connection. Finally, the road network is generated by using intersection connection and buffer algorithms.
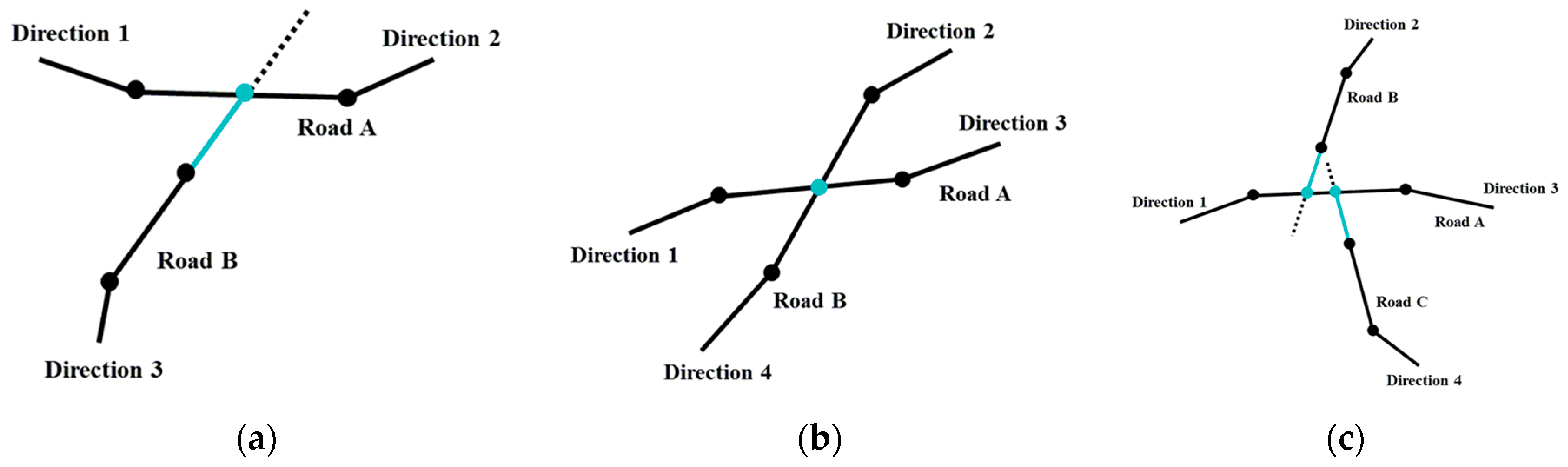
- To further improve the effectiveness of the proposed method, we adopt the road segment modification and road network construction strategy using the combination of grid image level and vector level. At the raster level, morphological algorithms are used to acquire the initial road segment, and at the vector level, further corrections and connections are completed based on road geometric features. For example, considering the ‘T’, ‘Y’, and ‘+’ shape of the intersection, an intersection connection algorithm is proposed.
- The strategy proposed in this paper can be successfully applied to the extraction of rural areas, suburbs, and urban areas. At the same time, it also has a certain degree of correction effect on occlusion and shadow problems. The algorithm for extracting a single road can extract roads with a length of more than 4000 pixels at a time, which is fast and convenient, and has great potential for the application of labeling images for deep learning.
2. Materials and Methods
2.1. Experimental Data
2.2. Methodology
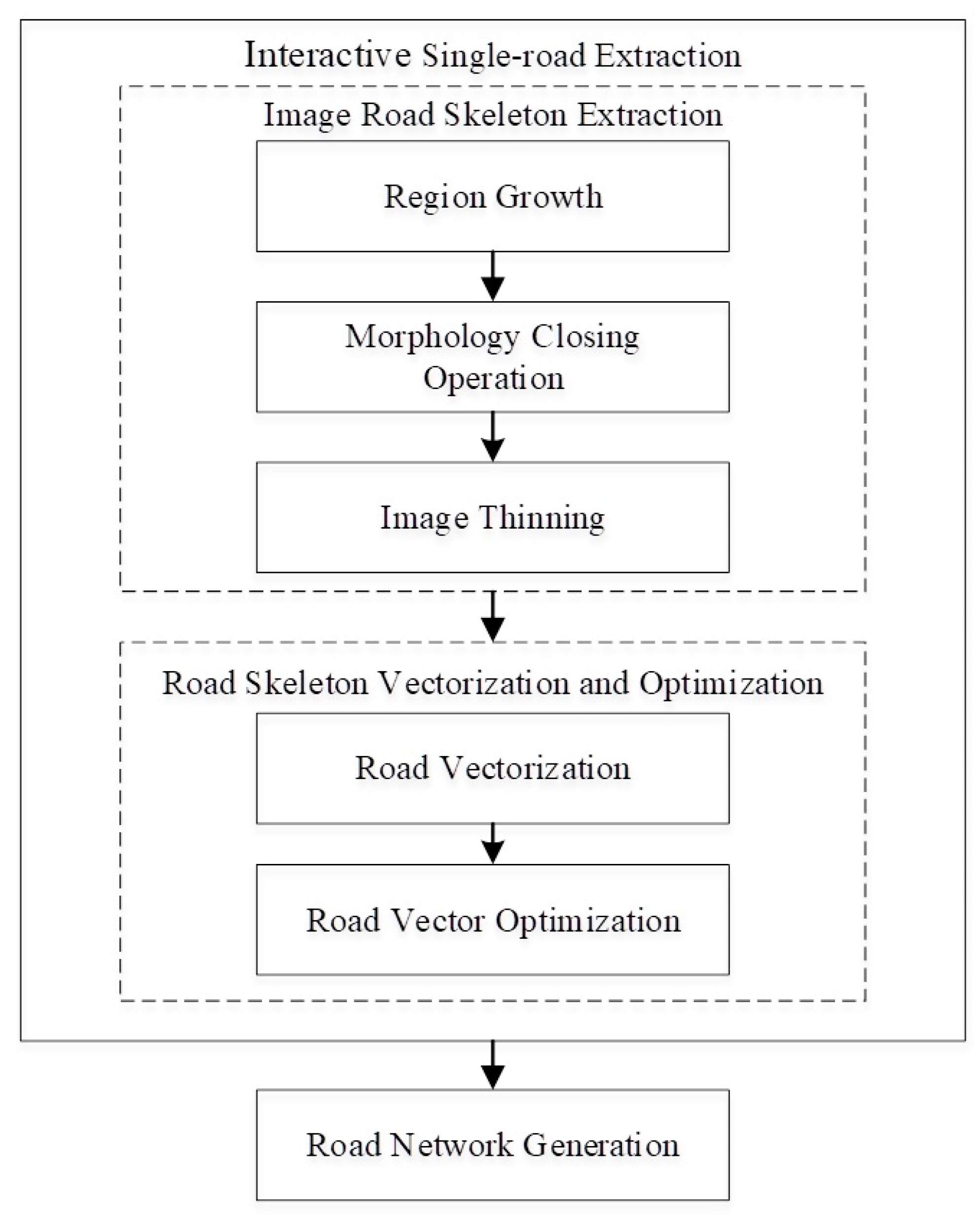
2.2.1. Interactive Single-Road Extraction
Image Road Skeleton Extraction
Road Skeleton Vectorization and Optimization
- (1)
- Road vectorization to generate road segments
| Algorithm 1: Road Vectorization | |
| Input: image Input Image neighbor Neighborhood Search Order dt Length Threshold Output: Lines Segments | |
| 1: | function FindLines(image, Lines, neighbor, dt) |
| 2: | BEGIN |
| 3: | while (findFirstPoint(image, firstPt)) |
| 4: | BEGIN |
| 5: | line.push_back(firstPt); |
| 6: | currPt = firstPt; |
| 7: | while (findNextPoint(neighbor, image, currPt, nextPt)) |
| 8: | BEGIN |
| 9: | line.push_back(nextPt); |
| 10: | currPt = nextPt; |
| 11: | END |
| 12: | currPt = firstPt; |
| 13: | while (findNextPoint(neighbor, image, currPt, nextPt)) |
| 14: | BEGIN |
| 15: | line.push_front(nextPt); |
| 16: | currPt = nextPt; |
| 17: | END |
| 18: | if (line.length() > dt) |
| 19: | BEGIN |
| 20: | line.simplify(T); |
| 21: | Lines.push_back(line); |
| 22: | END |
| 23: | END |
| 24: | END |
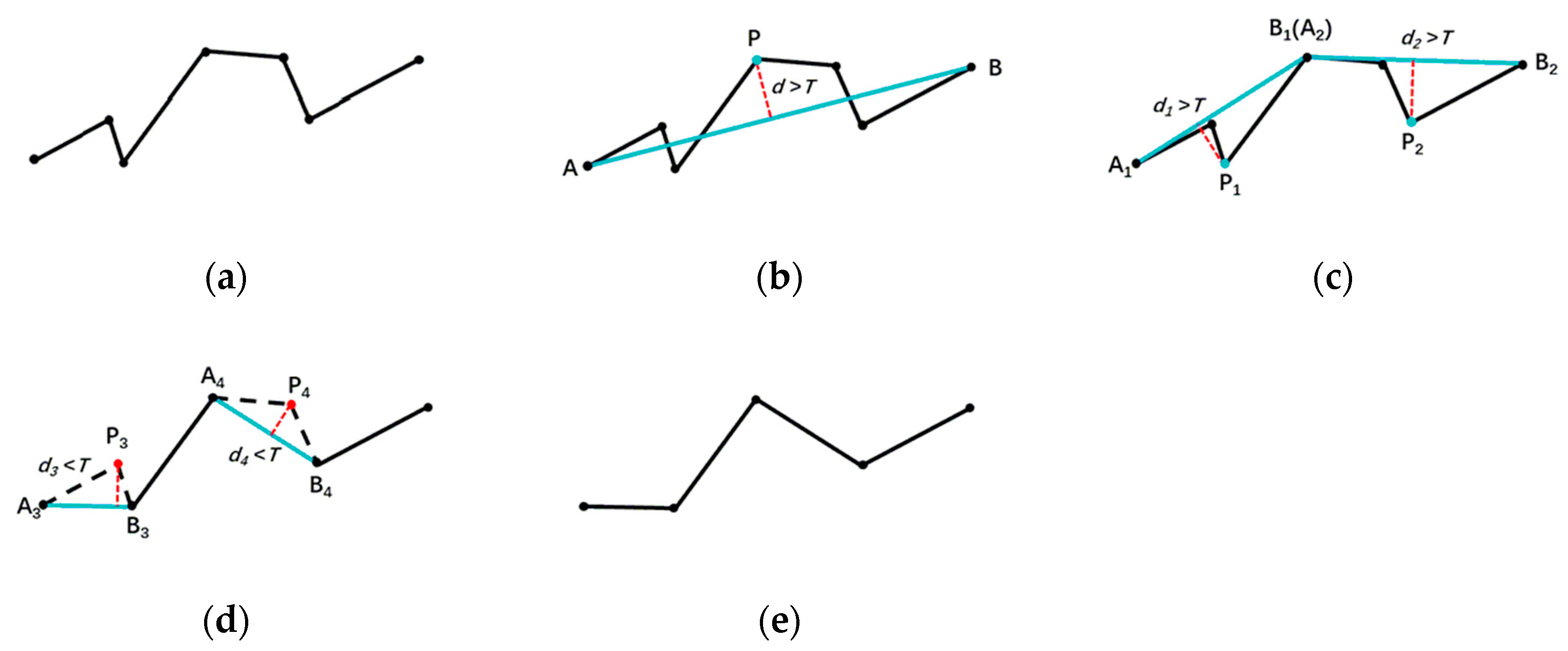
- (2)
- Road segment optimization and connection
| Algorithm 2: Road Connection | |
| Input: Lines Segments after Tracking Algorithm Output: Lines Roads after Connection Algorithm | |
| 1: | function LinkLines(&Lines) |
| 2: | BEGIN |
| 3: | Ver = FindVertex(Lines); |
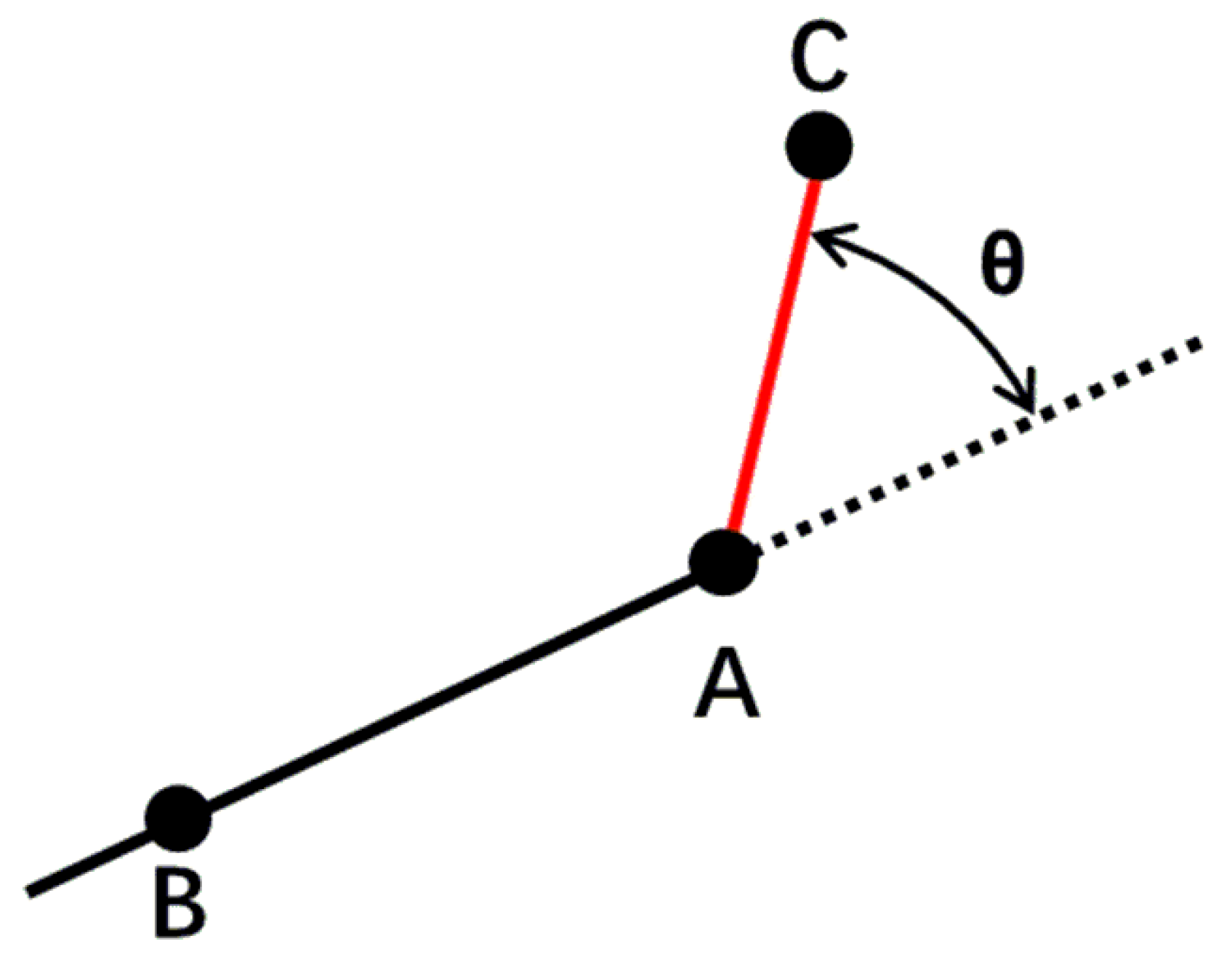
| 4: | Ver_theta = FindVertexAzimuth(Lines); |
| 5: | for i ← 0 to Ver.size() |
| 6: | BEGIN |
| 7: | min = 9999.0; |
| 8: | if (isinConnectedPt(i, ConnectedPt)) continue; |
| 9: | for j ← (i + 1) to Ver.size() |
| 10: | BEGIN |
| 11: | if (isinSameLine(Ver(i), Ver(j))) continue; |
| 12: | temp_distance = cal_Distance(Ver(i),Ver(j)); |
| 13: | if (temp_distance < min) |
| 14: | BEGIN |
| 15: | min = temp_distance; |
| 16: | flag = j; |
| 17: | END |
| 18: | END |
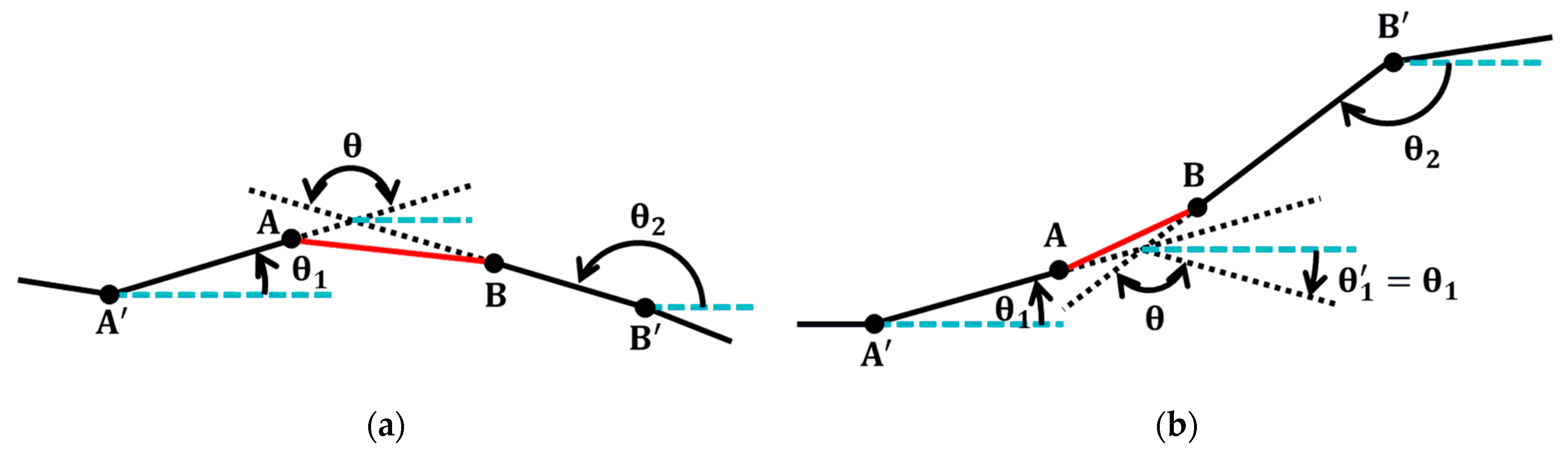
| 19: | if ((abs(Ver_theta(i)-Ver_theta(flag)) > 90) AND (min < dt)) |
| 20: | BEGIN |
| 21: | Temp_line.pushback(Ver(i)); |
| 22: | Temp_line.pushback(Ver(flag)); |
| 23: | L1 = findLinefromVer(Ver(i)); |
| 24: | L2 = findLinefromVer(Ver(flag)); |
| 25: | JudgeConnectOrder(L1,L2,&Line1,Temp_line,&Line2); |
| 26: | Line1 = Line1.combine(Temp_line); |
| 27: | Line1 = Line1.combine(Line2); |
| 28: | ChangeLine(L1,Line1, &Lines); |
| 29: | deleteLine(L2,&Lines); |
| 30: | ConnectedPt.pushback(flag); |
| 31: | END |
| 32: | END |
| 33: | END |
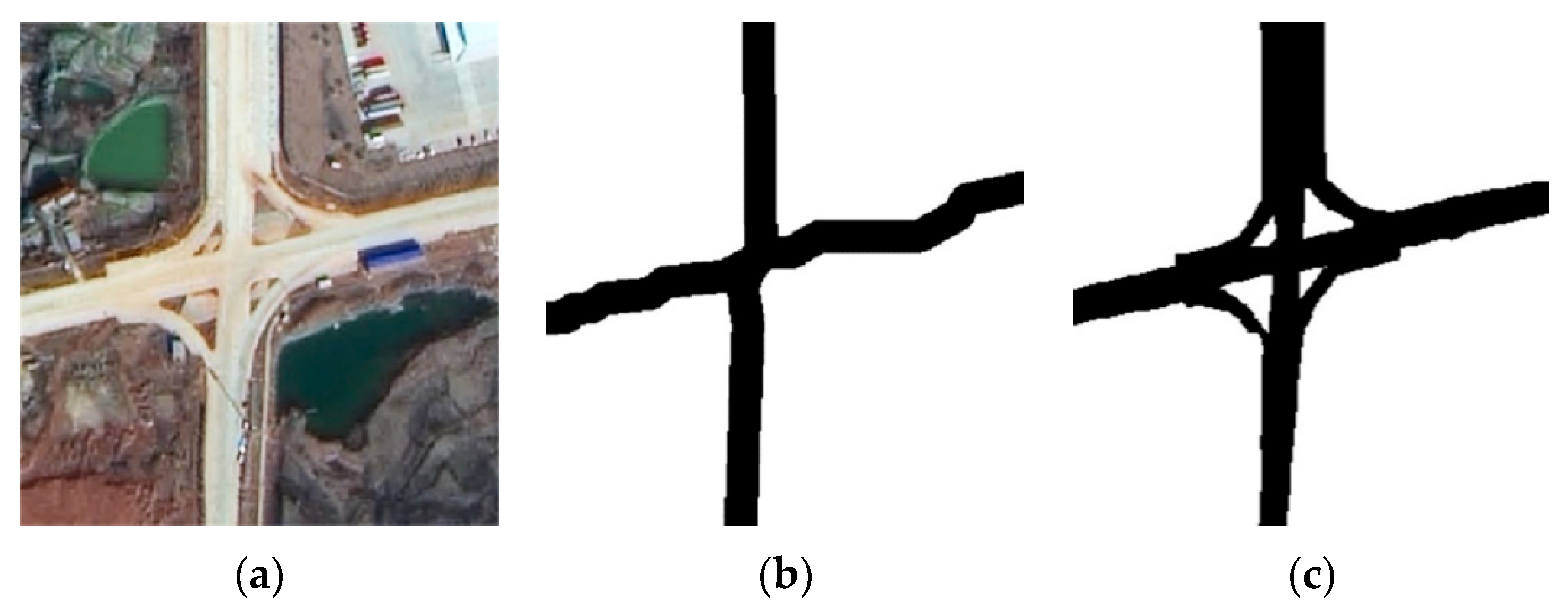
2.2.2. Road Network Generation
| Algorithm 3: Intersection Connection | |
| Input: Lines Roads Output: addLines Newly added connection roads | |
| 1: | function addJunctionLines(Lines, addLines) |
| 2: | BEGIN |
| 3: | Ver = FindVertex(Lines); |
| 4: | Ver_theta = FindVertexAzimuth(Lines); |
| 5: | for i ← 0 to Ver.size() |
| 6: | BEGIN |
| 7: | extendline.push_back(Ver(i)); |
| 8: | extendpoint = cal_coordinate(Ver(i), Ver_theta(i), dt); |
| 9: | extendline.push_back(extendpoint); |
| 10: | for j ← 0 to Lines.size() |
| 11: | BEGIN |
| 12: | if (intersects(Lines(j), extendline)) |
| 13: | BEGIN |
| 14: | intersect_geo = intersection(Lines(j), extendline); |
| 15: | intersect = intersect_geo- > asPoint(); |
| 16: | if (Ver(i)≠intersect) |
| 17: | BEGIN |
| 18: | temp_polyline.push_back(Ver(i)); |
| 19: | temp_polyline.push_back(intersect); |
| 20: | addLines.pushback(temp_polyline); |
| 21: | END |
| 22: | END |
| 23: | END |
| 24: | END |
| 25: | END |
2.2.3. Evaluation of the Extraction Results
3. Results
3.1. Parameter Settings
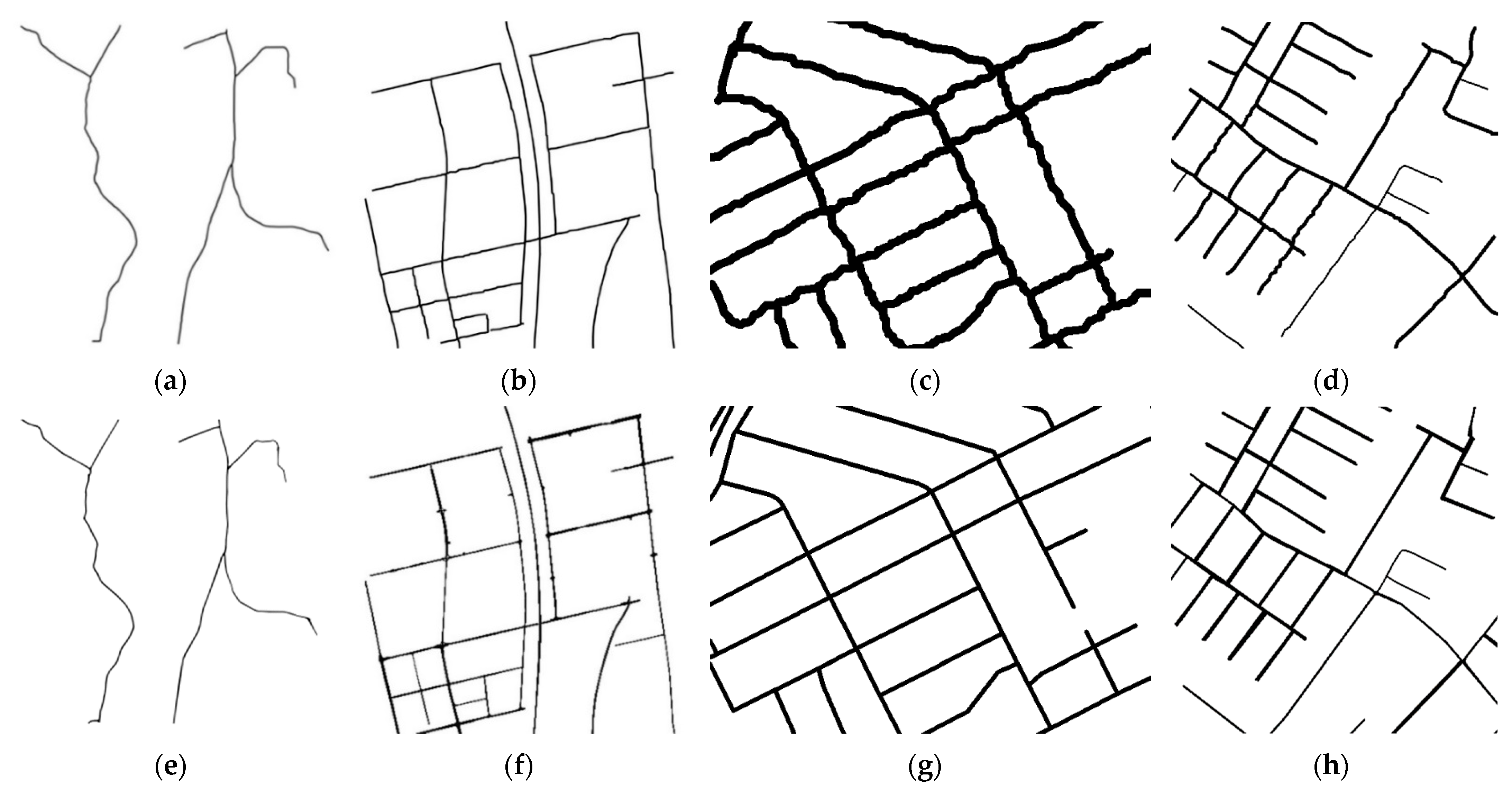
3.2. Road Extraction Results for the Four Datasets
3.3. Comparison with Other Existing Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, Q.; Zhang, Y.; Wang, L.; Zhong, Y.; Guan, Q.; Lu, X.; Zhang, L.; Li, D. A global context-aware and batch-independent network for road extraction from VHR satellite imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 353–365. [Google Scholar] [CrossRef]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road extraction from high-resolution remote sensing imagery using refined deep residual convolutional neural network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.K.; Zhang, X.; Huang, X. Road detection and centerline extraction via deep recurrent convolutional neural network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Wang, C.; Zourlidou, S.; Golze, J.; Sester, M. Trajectory analysis at intersections for traffic rule identification. Geo-Spat. Inf. Sci. 2020, 24, 75–84. [Google Scholar] [CrossRef]
- Gurung, P. Challenging infrastructural orthodoxies: Political and economic geographies of a Himalayan road. Geoforum 2021, 120, 103–112. [Google Scholar] [CrossRef]
- Alamgir, M.; Campbell, M.J.; Sloan, S.; Goosem, M.; Clements, G.R.; Mahmoud, M.I.; Laurance, W.F. Economic, socio-political and environmental risks of road development in the tropics. Curr. Biol. 2017, 27, 1130–1140. [Google Scholar] [CrossRef] [Green Version]
- Qi, Y.; Chodron Drolma, S.; Zhang, X.; Liang, J.; Jiang, H.; Xu, J.; Ni, T. An investigation of the visual features of urban street vitality using a convolutional neural network. Geo-Spat. Inf. Sci. 2020, 23, 341–351. [Google Scholar] [CrossRef]
- Metz, D. Economic benefits of road widening: Discrepancy between outturn and forecast. Transp. Res. Part A Policy Pract. 2021, 147, 312–319. [Google Scholar] [CrossRef]
- Chaudhuri, D.; Kushwaha, N.K.; Samal, A. Semi-Automated road detection from high resolution satellite images by directional morphological enhancement and segmentation techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1538–1544. [Google Scholar] [CrossRef]
- Wang, J.; Qin, Q.; Gao, Z.; Zhao, J.; Ye, X. A new approach to urban road extraction using high-resolution aerial image. ISPRS Int. J. Geo-Inf. 2016, 5, 114. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Du, L.; Yi, W.; Hong, J.; Zhang, L.; Zheng, J.; Li, C.; Ma, X.; Zhang, D.; Fang, W.; et al. An adaptive atmospheric correction algorithm for the effective adjacency effect correction of submeter-scale spatial resolution optical satellite images: Application to a WorldView-3 panchromatic image. Remote Sens. Environ. 2021, 259, 112412. [Google Scholar] [CrossRef]
- Máttyus, G.; Luo, W.; Urtasun, R. DeepRoadMapper: Extracting Road Topology from Aerial Images. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3458–3466. [Google Scholar] [CrossRef]
- Zhao, J.Q.; Yang, J.; Li, P.X.; Lu, J.M. Semi-automatic Road Extraction from SAR Images Using EKF and PF. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-7/W4, 227–230. [Google Scholar] [CrossRef] [Green Version]
- Guan, H.; Lei, X.; Yu, Y.; Zhao, H.; Peng, D.; Marcato Junior, J.; Li, J. Road marking extraction in UAV imagery using attentive capsule feature pyramid network. Int. J. Appl. Earth Obs. 2022, 107, 102677. [Google Scholar] [CrossRef]
- Ekim, B.; Sertel, E.; Kabadayı, M.E. Automatic road extraction from historical maps using deep learning techniques: A regional case study of turkey in a German World War II Map. ISPRS Int. J. Geo-Inf. 2021, 10, 492. [Google Scholar] [CrossRef]
- Kuo, C.-L.; Tsai, M.-H. Road characteristics detection based on joint convolutional neural networks with adaptive squares. ISPRS Int. J. Geo-Inf. 2021, 10, 377. [Google Scholar] [CrossRef]
- Yang, M.; Yuan, Y.; Liu, G. SDUNet: Road extraction via spatial enhanced and densely connected UNet. Pattern Recognit. 2022, 126, 108549. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, W.; Li, C.; Wu, J.; Tang, X.; Jiao, L. Fully Convolutional Network-Based Ensemble Method for Road Extraction from Aerial Images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1777–1781. [Google Scholar] [CrossRef]
- Heipke, C.; Rottensteiner, F. Deep learning for geometric and semantic tasks in photogrammetry and remote sensing. Geo-Spat. Inf. Sci. 2020, 23, 10–19. [Google Scholar] [CrossRef]
- Wu, S.; Du, C.; Chen, H.; Xu, Y.; Guo, N.; Jing, N. Road extraction from very high resolution images using weakly labeled openstreetmap centerline. ISPRS Int. J. Geo-Inf. 2019, 8, 478. [Google Scholar] [CrossRef] [Green Version]
- Bakhtiari, H.R.R.; Abdollahi, A.; Rezaeian, H. Semi automatic road extraction from digital images. Egypt. J. Remote Sens. Space Sci. 2017, 20, 117–123. [Google Scholar] [CrossRef]
- Miao, Z.; Wang, B.; Shi, W.; Zhang, H. A semi-automatic method for road centerline extraction from VHR images. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1856–1860. [Google Scholar] [CrossRef]
- Nunes, D.M.; Medeiros, N.D.G.; Santos, A.D.P.D. Semi-automatic road network extraction from digital images using object-based classification and morphological operators. Bol. Ciênc. Geod. 2018, 24, 485–502. [Google Scholar] [CrossRef]
- Chen, L.; Rottensteiner, F.; Heipke, C. Feature detection and description for image matching: From hand-crafted design to deep learning. Geo-Spat. Inf. Sci. 2020, 24, 58–74. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2020: An annotated image dataset for automatic road damage detection using deep learning. Data Brief 2021, 36, 107133. [Google Scholar] [CrossRef]
- Li, P.; He, X.; Qiao, M.; Miao, D.; Cheng, X.; Song, D.; Chen, M.; Li, J.; Zhou, T.; Guo, X.; et al. Exploring multiple crowdsourced data to learn deep convolutional neural networks for road extraction. Int. J. Appl. Earth Obs. 2021, 104, 102544. [Google Scholar] [CrossRef]
- Yu, J.; Yu, F.; Zhang, J.; Liu, Z. High resolution remote sensing image road extraction combining region growing and road-unit. Geomat. Inf. Sci. Wuhan Univ. 2013, 38, 761–764. [Google Scholar] [CrossRef]
- Li, J.; Wen, Z.Q.; Hu, Y.X.; Liu, Z.D. Road Extraction from Remote Sensing Images Based on Improved Regional Growth. Comput. Eng. Appl. 2016, 209–213, 238. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, L.; Sheng, Y.; Shen, M. Pole-like Objects Segmentation and Multiscale Classification-Based Fusion from Mobile Point Clouds in Road Scenes. Remote Sens. 2021, 13, 4382. [Google Scholar] [CrossRef]
- Cao, F.; Xu, Y.; Zhu, B.; Li, R. Semi-automatic road centerline extraction from high-resolution remote sensing by image utilizing dynamic programming. J. Geomat. Sci. Technol. 2015, 32, 615–618. [Google Scholar] [CrossRef]
- Gruen, A.; Li, H. Road extraction from aerial and satellite images by dynamic programming. ISPRS J. Photogramm. Remote Sens. 1995, 50, 11–20. [Google Scholar] [CrossRef]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road Extraction Methods in High-Resolution Remote Sensing Images: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Ghandorh, H.; Boulila, W.; Masood, S.; Koubaa, A.; Ahmed, F.; Ahmad, J. Semantic Segmentation and Edge Detection—Approach to Road Detection in Very High Resolution Satellite Images. Remote Sens. 2022, 14, 613. [Google Scholar] [CrossRef]
- Hormese, J.; Saravanan, C. Automated road extraction from high resolution satellite images. Procedia Technol. 2016, 24, 1460–1467. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Y.; Tan, T.S.; Tay, S.C. Utilizing Edge to Extract Roads in High-Resolution Satellite Imagery. In Proceedings of the IEEE International Conference on Image Processing, Genova, Italy, 14 September 2005; Volume 1, p. I-637. [Google Scholar] [CrossRef]
- Chen, G.; Sui, H.; Tu, J.; Song, Z. Semi-automatic road extraction method from high resolution remote sensing images based on P-N learning. Geomat. Inf. Sci. Wuhan Univ. 2017, 42, 775–781. [Google Scholar] [CrossRef]
- Tan, H.; Shen, Z.; Dai, J. Semi-automatic extraction of rural roads under the constraint of combined geometric and texture features. ISPRS Int. J. Geo-Inf. 2021, 10, 754. [Google Scholar] [CrossRef]
- Wang, F.; Wang, W.; Xue, B.; Cao, T.; Gao, T. Road extraction from high-spatial-resolution remote sensing image by combining GVF snake with salient features. Acta Geod. Cartogr. Sin. 2017, 46, 1978–1985. [Google Scholar] [CrossRef]
- Abdelfattah, R.; Chokmani, K. A Semi Automatic off-roads and Trails Extraction Method from Sentinel-1 Data. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3728–3731. [Google Scholar] [CrossRef]
- Gu, D.; Wang, X. Road extraction in remote sensing images based on region growing and GVF-Snake. Comput. Eng. Appl. 2010, 46, 202–205. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Z.; Xu, M. Road structure refined CNN for road extraction in aerial image. IEEE Geosci. Remote. Sens. Lett. 2017, 14, 709–713. [Google Scholar] [CrossRef]
- Wang, W.; Yang, N.; Zhang, Y.; Wang, F.; Cao, T.; Eklund, P. A review of road extraction from remote sensing images. J. Traffic Transp. Eng. 2016, 3, 271–282. [Google Scholar] [CrossRef] [Green Version]
- Wan, Y.; Wang, D.; Xiao, J.; Lai, X.; Xu, J. Automatic determination of seamlines for aerial image mosaicking based on vector roads alone. ISPRS J. Photogramm. Remote Sens. 2013, 76, 1–10. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canda, 2013. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
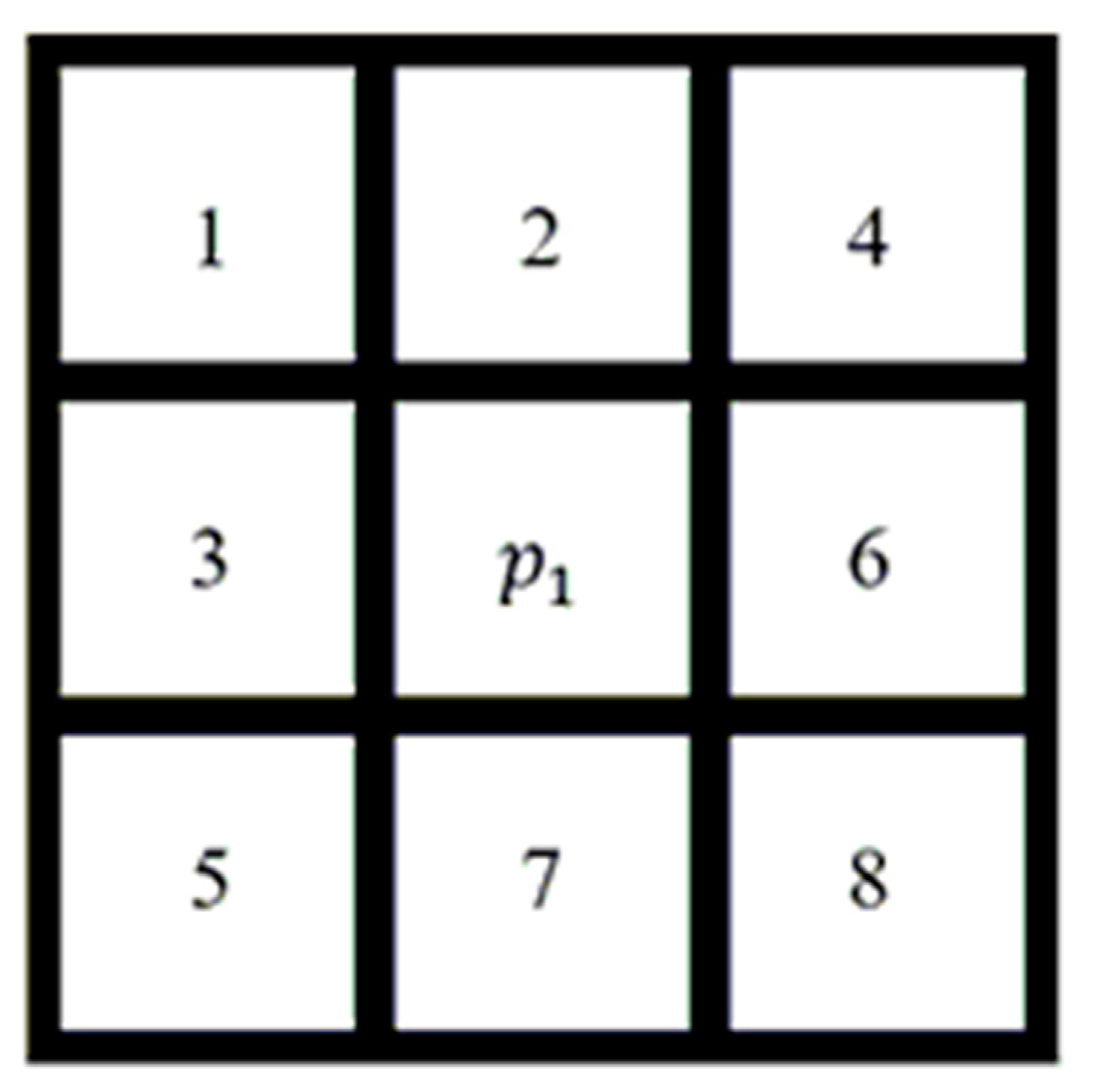
- Zhang, T.Y.; Suen, C.Y. A fast parallel algorithm for thinning digital patterns. Commun. ACM 1984, 27, 236–239. [Google Scholar] [CrossRef]
- Cao, X.; Liu, D.; Ren, X. Detection method for auto guide vehicle’s walking deviation based on image thinning and Hough transform. Meas. Control 2019, 52, 252–261. [Google Scholar] [CrossRef]
- Saalfeld, A. Topologically consistent line simplification with the Douglas-Peucker algorithm. Cartogr. Geogr. Inf. Sci. 1999, 26, 7–18. [Google Scholar] [CrossRef]
- Henry, C.; Azimi, S.M.; Merkle, N. Road segmentation in SAR satellite images with deep fully convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef] [Green Version]
- Abdollahi, A.; Pradhan, B.; Alamri, A. SC-RoadDeepNet: A New Shape and Connectivity-Preserving Road Extraction Deep Learning-Based Network from Remote Sensing Data. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5617815. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Precision | Accuracy | Recall | IoU |
|---|---|---|---|---|
| Data 1 | 88.54% | 99.70% | 88.97% | 0.80 |
| Data 2 | 87.08% | 98.13% | 77.06% | 0.69 |
| Data 3 | 98.10% | 88.31% | 88.68% | 0.87 |
| Data 4 | 80.70% | 96.80% | 81.56% | 0.68 |
| No. | Road Length (pixel) | Time (s) | Time per 1000 pixels (s) |
|---|---|---|---|
| 1 | 2040 | 4.125 | 2.02 |
| 2 | 2126 | 4.739 | 2.23 |
| 3 | 2378 | 4.64 | 1.95 |
| 4 | 2415 | 5.688 | 2.36 |
| 5 | 2770 | 6.776 | 2.45 |
| 6 | 4056 | 4.536 | 1.12 |
| 7 | 4064 | 6.43 | 1.58 |
| 8 | 4115 | 5.83 | 1.42 |
| 9 | 4121 | 6.095 | 1.48 |
| 10 | 4188 | 6.486 | 1.55 |
| Mean | - | - | 1.81 |
| Sample 1 | Sample 2 | Sample 3 | ||||
|---|---|---|---|---|---|---|
| Gu’s Method | Proposed Method | Gu’s Method | Proposed Method | Gu’s Method | Proposed Method | |
| Precision | 0.64 | 0.96 | 0.57 | 0.79 | 0.76 | 0.84 |
| Accuracy | 0.94 | 0.97 | 0.96 | 0.98 | 0.94 | 0.98 |
| Recall | 0.88 | 0.70 | 0.99 | 0.94 | 0.25 | 0.86 |
| IoU | 0.59 | 0.67 | 0.57 | 0.75 | 0.23 | 0.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, K.; Cui, W.; Shi, S.; Liu, Y.; Li, Y.; Ge, M. Semi-Automatic Method of Extracting Road Networks from High-Resolution Remote-Sensing Images. Appl. Sci. 2022, 12, 4705. https://doi.org/10.3390/app12094705
Yang K, Cui W, Shi S, Liu Y, Li Y, Ge M. Semi-Automatic Method of Extracting Road Networks from High-Resolution Remote-Sensing Images. Applied Sciences. 2022; 12(9):4705. https://doi.org/10.3390/app12094705
Chicago/Turabian StyleYang, Kaili, Weihong Cui, Shu Shi, Yu Liu, Yuanjin Li, and Mengyu Ge. 2022. "Semi-Automatic Method of Extracting Road Networks from High-Resolution Remote-Sensing Images" Applied Sciences 12, no. 9: 4705. https://doi.org/10.3390/app12094705
APA StyleYang, K., Cui, W., Shi, S., Liu, Y., Li, Y., & Ge, M. (2022). Semi-Automatic Method of Extracting Road Networks from High-Resolution Remote-Sensing Images. Applied Sciences, 12(9), 4705. https://doi.org/10.3390/app12094705