
A New Body Weight Lifelog Outliers Generation Method: Reflecting Characteristics of Body Weight Data


Abstract
:1. Introduction
- (a)
- Propose an anomaly detection algorithm reflecting the characteristics of data with small daily variability and periodicity;
- (b)
- Propose an anomaly detection algorithm that utilizes weekly data transformation to reflect outliers with small differences from normal values;
- (c)
- Suggest a way to improve performance through outlier generation to solve the problem of outlier class imbalance.
2. Materials and Methods
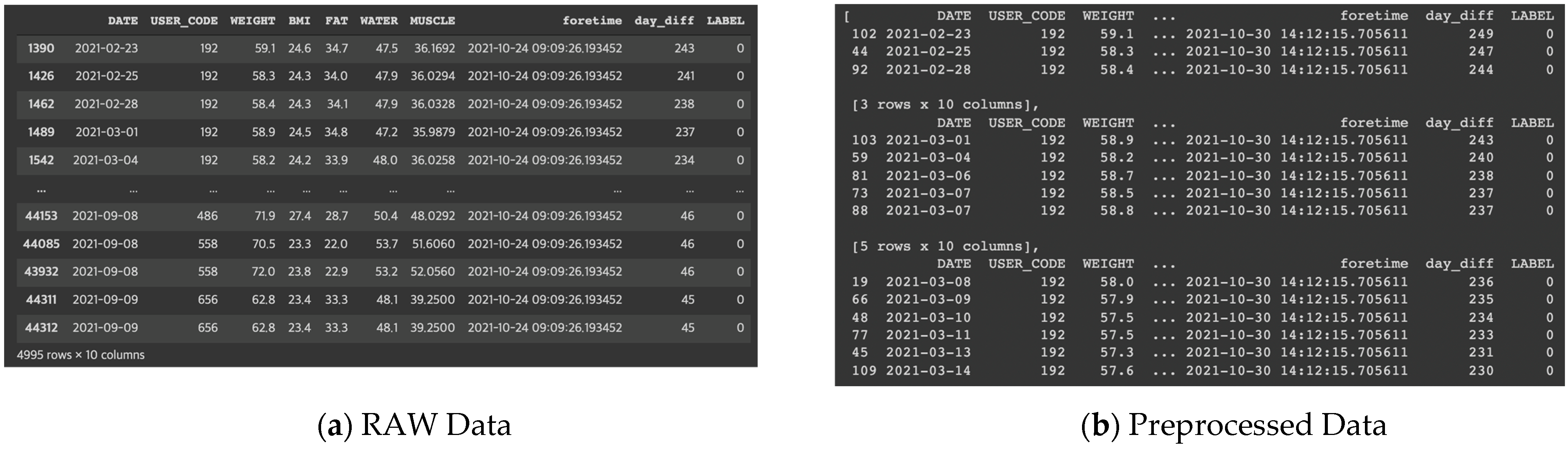
2.1. Data Preparation
2.2. Solution for the Problem of Outlier Class Imbalance
2.3. Two Outliers Generation Methods
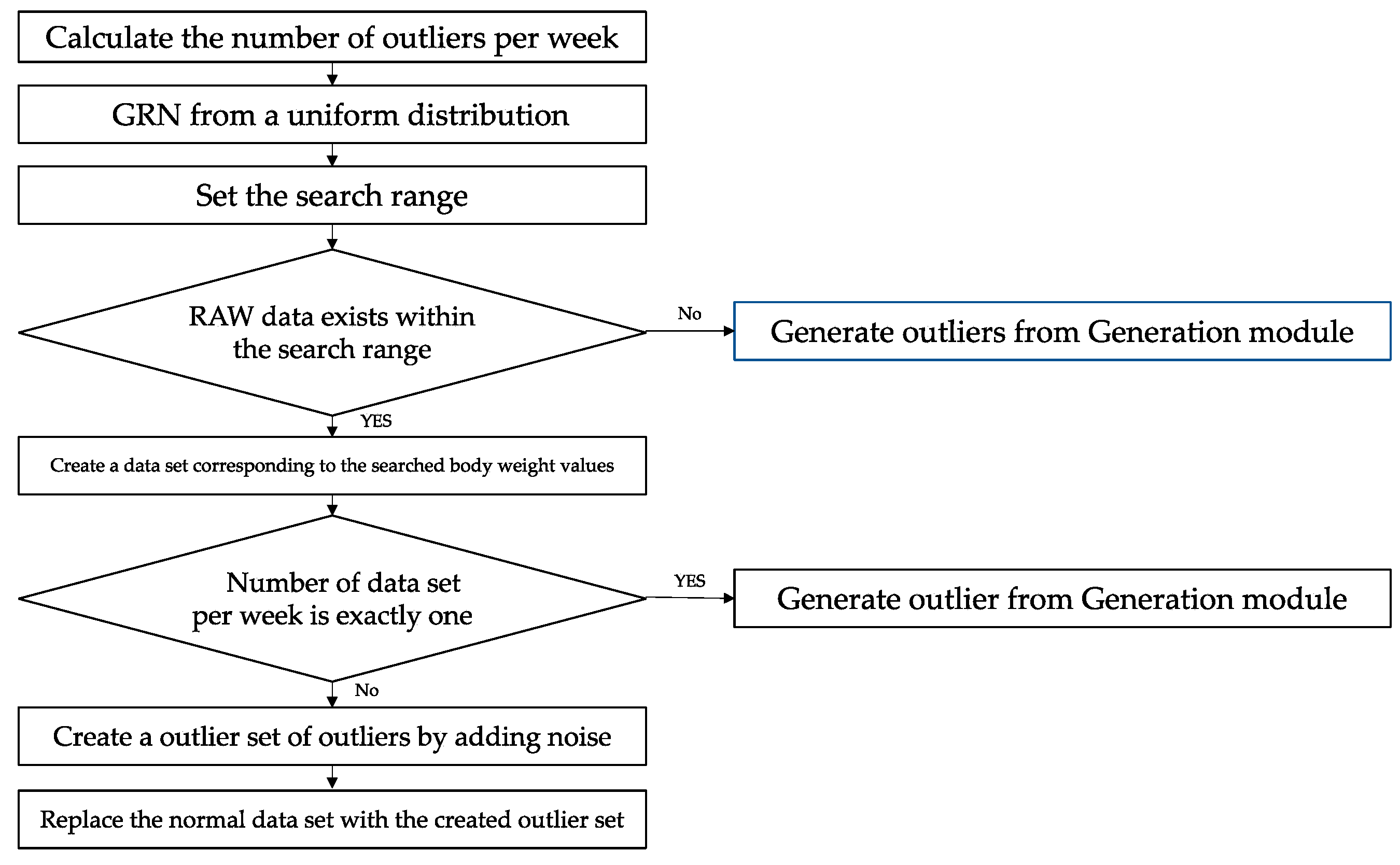
2.3.1. Search Module Method
- Set the search range (GRN − RN, GRN + RN) based on the random number (GRN) generated with a uniform distribution of (40 kg, 120 kg).
- RN is set as a real value in the range (0, 2).
- Search and extract all values in the search range from all RAW data sets within the search range.
- If there is no searched data, the generation module creates the remaining required outliers.
- Create a data set by finding the BMI, FAT, WATER, and MUSCLE values corresponding to the searched body weight values.
- Create a set of outliers by adding noise corresponding to each variable of the data set created in 3. The noise of each variable is summarized in Table 1.
- The number of preset outliers is converted into the number of weekly generations.
- Obtain an index for the day of the week according to the number of generations per week and replace the corresponding normal data with an outlier table.
- Repeat steps 1–6 for each week to generate outliers by substituting them.
2.3.2. Generation Module Method
- The generation module creates the number of outliers to be generated, minus the total number of outliers generated by the search module.
- Divide the number of outliers to be generated in the generation module by the number of weeks to calculate the number to be generated per week.
- Excluding the days selected in the search module, the number of day indices to be created per week is extracted.
- The average of the normal distribution was obtained by multiplying the weekly average weight calculated for each week by an arbitrary ratio of 1.1, and the mean standard deviation was set to “2”. The mean standard deviation, “2”, may change depending on data characteristics. Here, the reason for multiplying by 1.1 was to minimize distortion due to the difference in weight values. For example, 5 kg for a 50 kg user and 5 kg for an 80 kg user is the same 5 kg but feels different. Therefore, rather than modifying the weight by addition, we applied a multiplicative scaling to increase fairness.Average(A) = average + (average × random ratio), which ratio = 0.1Standard deviation(S) = ± 2
- Generate one body weight (BW) randomly from the graph (A, S) of normal distribution created in step 1.
- Based on the weight reference value obtained in step 5, if it is greater than 70, it is assumed that it is a man, and if it is less than 70, it is created separately.The reason for this setting is that, as a result of the data set EDA (Exploratory Data Analysis), the maximum value of women’s weight was less than 70.
- 7.
- Create an outlier by replacing the outlier data obtained in 6-1 or 6-2 with the normal value of the selected day index.
- 8.
- Repeat steps 1–7 for each week to generate outliers.
2.3.3. Summary
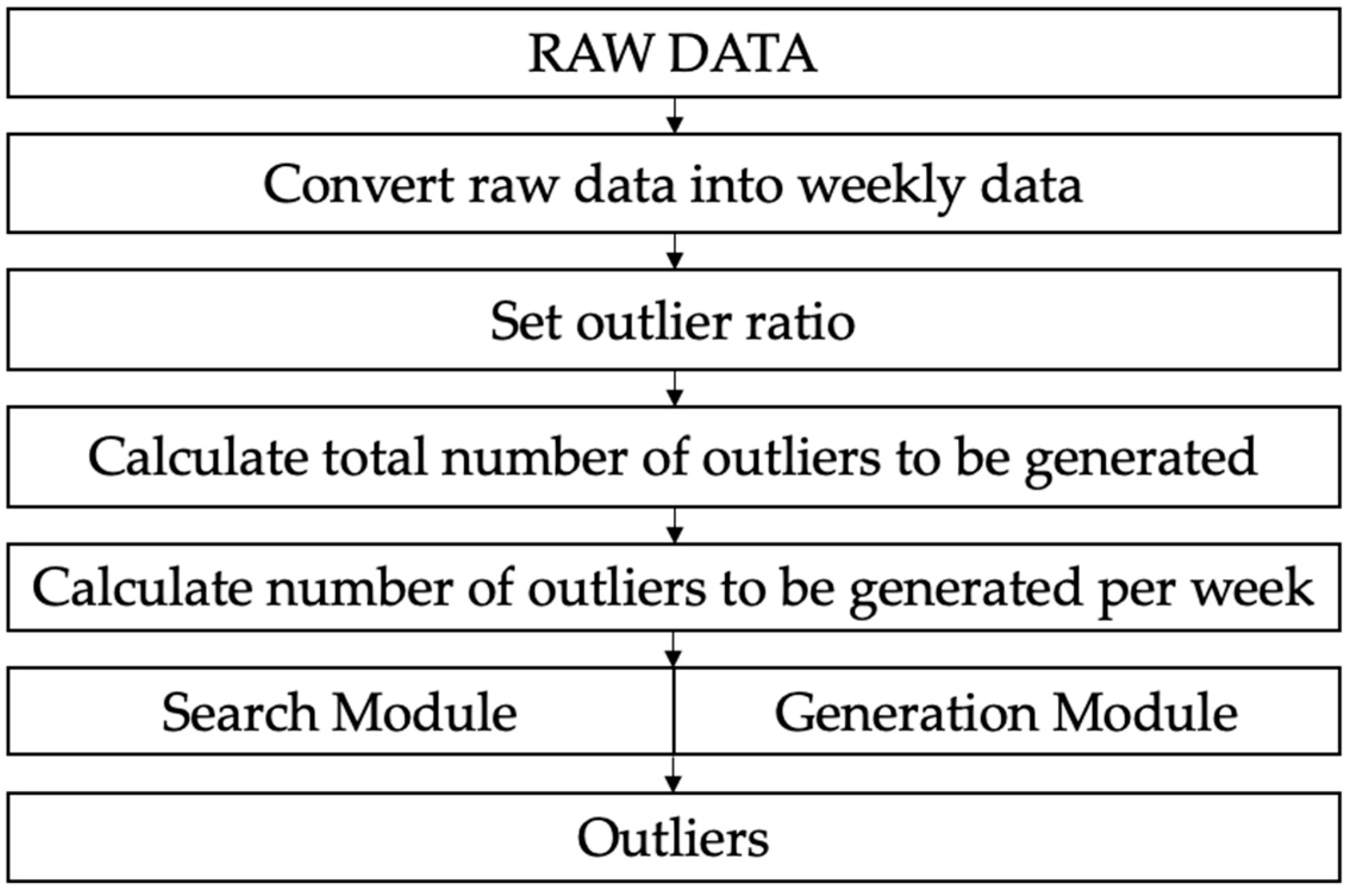
- Convert all general time series data (RAW data) into weekly data.
- Set the pre-set ratio of the number of outliers to the total number of data (“outlier value generation ratio”)
- Calculate the total number of outliers to be generated through the outlier generation ratio.
- Calculate the number of outliers to be generated per week by dividing the total number of outliers by the number of weeks.
- For each week, half of the outliers are generated by the search module and the other half are generated by the generation module. At this time, the generation module generates as many outliers as the number of outliers that were not generated by the search module if it did not satisfy the execution condition.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, Y.-J.; Ko, Y.S. A Lifelog Common Data Reference Model for the Healthcare Ecosystem. Knowl. Manag. Res. 2018, 19, 149–170. [Google Scholar]
- Qi, J.; Yang, P.; Hanneghan, M.; Latham, K.; Tang, S. Uncertainty Investigation for Personalised Lifelogging Physical Activity Intensity Pattern Assessment with Mobile Devices. In Proceedings of the 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Exeter, UK, 21–23 June 2017; pp. 871–876. [Google Scholar]
- Yang, P.; Stankevicius, D.; Marozas, V.; Deng, Z.; Liu, E.; Lukosevicius, A.; Dong, F.; Xu, L.; Min, G. Lifelogging Data Validation Model for Internet of Things Enabled Personalized Healthcare. In IEEE Transactions on Systems, Man, and Cybernetics: Systems; IEEE: Manhattan, NY, USA, 2018; Volume 48, pp. 50–64. [Google Scholar] [CrossRef] [Green Version]
- Park, M.S. Application and Expansion of Artificial Intelligence Technology to Healthcare. J. Bus. Converg. 2021, 6, 101–109. [Google Scholar] [CrossRef]
- Zheng, Y.; Manson, J.E.; Yuan, C. Associations of Weight Gain from Early to Middle Adulthood with Major Health Outcomes Later in Life. JAMA 2017, 318, 255–269. [Google Scholar] [CrossRef] [PubMed]
- Wilding, J. The importance of weight management in type 2 diabetes mellitus. Int. J. Clin. Pract. 2014, 68, 682–691. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ades, P.A.; Savage, P.D. Potential Benefits of Weight Loss in Coronary Heart Disease. Prog. Cardiovasc. Dis. 2014, 56, 448–456. [Google Scholar] [CrossRef] [PubMed]
- Blumenthal, J.A.; Sherwood, A.; Gullette, E.C.; Babyak, M.; Waugh, R.; Georgiades, A.; Hinderliter, A. Exercise and weight loss reduce blood pressure in men and women with mild hypertension: Effects on cardiovascular, metabolic, and hemodynamic functioning. Arch. Intern. Med. 2000, 160, 1947–1958. [Google Scholar] [CrossRef] [Green Version]
- Blumenthal, J.A.; Babyak, M.A.; Hinderliter, A. Effects of the DASH Diet Alone and in Combination with Exercise and Weight Loss on Blood Pressure and Cardiovascular Biomarkers in Men and Women with High Blood Pressure: The ENCORE Study. Arch Intern Med. 2010, 170, 126–135. [Google Scholar] [CrossRef]
- Pak, M.; Lindseth, G. Risk factors for cholelithiasis. Gastroenterol. Nurs. 2016, 39, 297–309. [Google Scholar] [CrossRef]
- Demark-Wahnefried, W.; Campbell, K.L.; Hayes, S.C. Weight management and its role in breast cancer rehabilitation. Cancer 2012, 118, 2277–2287. [Google Scholar] [CrossRef] [Green Version]
- Ali, S.; Khusro, S.; Khan, A.; Khan, H. Smartphone-Based Lifelogging: Toward Realization of Personal Big Data. In Information and Knowledge in Internet of Things; Guarda, T., Anwar, S., Leon, M., Mota Pinto, F.J., Eds.; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Choi, J.; Choi, C.; Ko, H.; Kim, P. Intelligent Healthcare Service Using Health Lifelog Analysis. J. Med. Syst. 2016, 40, 188. [Google Scholar] [CrossRef]
- Kim, J.W.; Lim, J.H.; Moon, S.M.; Jang, B. Collecting Health Lifelog Data from Smartwatch Users in a Privacy-Preserving Manner. IEEE Trans. Consum. Electron. 2019, 65, 369–378. [Google Scholar] [CrossRef]
- Deng, Z.; Zhao, Y.; Parvinzamir, F.; Zhao, X.; Wei, S.; Liu, M.; Zhang, X.; Dong, F.; Liu, E.; Clapworthy, G. MyHealthAvatar: A Lifetime Visual Analytics Companion for Citizen Well-being. In International Conference on Technologies for E-Learning and Digital Entertainment; Springer: Cham, Switzerland, 2016; pp. 345–356. [Google Scholar]
- Ni, J.; Chen, B.; Allinson, N.M.; Ye, X. A hybrid model for predicting human physical activity status from lifelogging data. Eur. J. Oper. Res. 2019, 281, 532–542. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.Y.; Lee, J.S.; Park, M.S. Analysis of Lifelong for Health of Middle-Aged Men by Using Machine Learning Algorithm. J. Korean Inst. Ind. Eng. 2021, 47, 504–513. [Google Scholar]
- Chung, C.F.; Cook, J.; Bales, E.; Zia, J.; Munson, S.A. More Than Telemonitoring: Health Provider Use and Nonuse of Life-Log Data in Irritable Bowel Syndrome and Weight Management. J. Med. Internet Res. 2015, 17, e203. [Google Scholar] [CrossRef] [Green Version]
- Muruti, G.; Rahim, F.; Ibrahim, Z.A. A Survey on Anomalies Detection Techniques and Measurement Methods. In Proceedings of the 2018 IEEE Conference on Application, Information and Network Security (AINS), Langkawi, Malaysia, 21–22 November 2018. [Google Scholar] [CrossRef]
- Wang, H.; Bah, M.J.; Hammad, M. Progress in Outlier Detection Techniques: A Survey. IEEE Access 2019, 7, 107964–108000. [Google Scholar] [CrossRef]
- Berthoud, H.R.; Morrison, C.D.; Münzberg, H. The obesity epidemic in the face of homeostatic body weight regulation: What went wrong and how can it be fixed? Physiol. Behav. 2020, 222, 112959. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Luengo, J.; Fernández, A.; García, S.; Herrera, F. Addressing data complexity for imbalanced data sets: Analysis of SMOTE-based oversampling and evolutionary undersampling. Soft Comput. 2010, 15, 1909–1936. [Google Scholar] [CrossRef]
- Wilson, D.L. Asymptotic properties of nearest neighbor rules using edited data. IEEE Trans. Syst. Man Cybern. 1972, 3, 408–421. [Google Scholar] [CrossRef] [Green Version]
- Vuttipittayamongkol, P.; Elyan, E. Neighbourhood-based undersampling approach for handling imbalanced and overlapped data. Inf. Sci. 2020, 509, 47–70. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Tomek, I. Two Modifications of CNN. IEEE Trans. Syst. Man Cybern. 1976, 6, 769–772. [Google Scholar]
- Ramentol, E.E.; Caballero, Y.; Bello, R. SMOTE-RSB*: A hybrid preprocessing approach based on oversampling and undersampling for high imbalanced data-sets using SMOTE and rough sets theory. Knowl. Inf. Syst. 2012, 33, 45–265. [Google Scholar] [CrossRef]
- Wang, S.; Li, Z.; Chao, W.; Cao, Q. Applying adaptive over-sampling technique based on data density and cost-sensitive SVM to imbalanced learning. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using conditional gan. arXiv 2019, arXiv:1907.00503. [Google Scholar]
- Bourou, S.; El Saer, A.; Velivassaki, T.H.; Voulkidis, A.; Zahariadis, T. A Review of Tabular Data Synthesis Using GANs on an IDS Dataset. Information 2021, 12, 375. [Google Scholar] [CrossRef]
- Maldonado, S.; López, J.; Vairetti, C. An alternative SMOTE oversampling strategy for high-dimensional datasets. Appl. Soft Comput. 2018, 76, 380–389. [Google Scholar] [CrossRef]
- Bowles, C.; Chen, L.; Guerrero, R.; Bentley, P.; Gunn, R.; Hammers, A.; Rueckert, D. GAN augmentation: Augmenting training data using generative adversarial networks. arXiv 2018, arXiv:1810.10863. [Google Scholar]
- Nnamoko, N.; Korkontzelos, I. Efficient treatment of outliers and class imbalance for diabetes prediction. Artif. Intell. Med. 2020, 104, 101815. [Google Scholar] [CrossRef]
- Loyola-González, O.; Martínez-Trinidad, J.F.; Carrasco-Ochoa, J.A.; García-Borroto, M. Effect of class imbalance on quality measures for contrast patterns: An experimental study. Inf. Sci. 2016, 374, 179–192. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Remedies for severe class imbalance. In Applied Predictive Modeling; Springer: New York, NY, USA, 2013; pp. 419–443. [Google Scholar]
- Racette, S.B.; Weiss, E.P.; Schechtman, K.B.; Steger-May, K.; Villareal, D.T.; Obert, K.A.; Washington University School of Medicine CALERIE Team. Influence of weekend lifestyle patterns on body weight. Obesity 2008, 16, 1826–1830. [Google Scholar] [CrossRef]
- Orsama, A.L.; Mattila, E.; Ermes, M.; van Gils, M.; Wansink, B.; Korhonen, I. Weight rhythms: Weight increases during weekends and decreases during weekdays. Obes. Facts 2014, 7, 36–47. [Google Scholar] [CrossRef] [PubMed]
- Madden, K.M. The Seasonal Periodicity of Healthy Contemplations About Exercise and Weight Loss: Ecological Correlational Study. JMIR Public Health Surveill. 2017, 3, e92. [Google Scholar] [CrossRef] [PubMed]
- Turicchi, J.; O’Driscoll, R.; Horgan, G.; Duarte, C.; Palmeira, A.L.; Larsen, S.C.; Stubbs, J. Weekly, seasonal and holiday body weight fluctuation patterns among individuals engaged in a European multi-centre behavioural weight loss maintenance intervention. PLoS ONE 2020, 15, e0232152. [Google Scholar] [CrossRef] [PubMed]
- Moreno, J.P.; Johnston, C.A.; Chen, T.A.; O’Connor, T.A.; Hughes, S.O.; Baranowski, J.; Baranowski, T. Seasonal variability in weight change during elementary school. Obesity 2015, 23, 422–428. [Google Scholar] [CrossRef]
- Xia, Y.; Cao, X.; Wen, F.; Hu, G.; Sun, J. Learning Discriminative Reconstructions for Unsupervised Outlier Removal. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1511–1519. [Google Scholar] [CrossRef]
- Gao, Y.; Ma, J.; Zhao, J. A robust and outlier-adaptive method for non-rigid point registration. Pattern Anal. Appl. 2013, 17, 379–388. [Google Scholar] [CrossRef]
- Mouret, F.; Albughdadi, M.; Duthoit, S.; Kouamé, D.; Rieu, G.; Tourneret, J.-Y. Outlier Detection at the Parcel-Level in Wheat and Rapeseed Crops Using Multispectral and SAR Time Series. Remote Sens. 2021, 13, 956. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D.D. Hyperopt: A Python Library for Optimizing the Hyperparameters of Machine Learning Algorithms. In Proceedings of the 12th Python in Science Conference, Austin, TX, USA, 24–29 June 2013; p. 20. [Google Scholar]
- Ayan, E.; Ünver, H.M. Data augmentation importance for classification of skin lesions via deep learning. In Proceedings of the 2018 Electric Electronics, Computer Science, Biomedical Engineerings’ Meeting (EBBT), Istanbul, Turkey, 18–19 April 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Ranjan, K.G.; Prusty, B.R.; Jena, D. Review of preprocessing methods for univariate volatile time-series in power system applications. Electr. Power Syst. Res. 2021, 191, 106885. [Google Scholar] [CrossRef]
- Hassler, A.; Menasalvas, E.; García-García, F.J.; Rodríguez-Mañas, L.; Holzinger, A. Importance of medical data preprocessing in predictive modeling and risk factor discovery for the frailty syndrome. BMC Med. Inform. Decis. Mak. 2019, 19, 33. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Variable | Variable Description and Range |
|---|---|
| Random Noise for body weight | Noise for search scope, any real value between (0, 2) |
| BMI Noise | Noise for BMI calculation, any real value between (0.5, 1.5) |
| Body Mass Noise | Noise for calculating body mass, any real value between (1.5, 3) |
| Muscle Mass Noise | Noise for muscle mass calculation, any real value between (0.5, 3) |
| Height Noise | Used for BMI calculation with noise for the set height |
| FAT | Any real value between (17, 32) for men + body mass noise, and random real value between (15, 30) for women + body mass noise |
| MUSCLE | Weight Value—Body Mass Value + Muscle Noise |
| Body Water Noise | Noise for body water calculation, any real value between (2.5, 3) |
| Weight | Weight Value + Weight Noise from full RAW data |
| BMI | Weight (kg)/(Height (m) + Height Noise)2 The height of 1.73 m for males and 1.61 m for females is the standard height used in calculations. |
| Water | Any real value between (50, 65) for male + body water noise, and random real value between (45, 60) for female + body water noise |
| Variable | Description |
|---|---|
| DATE | Data Collection Date |
| WEIGHT | User’s Weight |
| FAT | User’s Body Fat |
| MUSCLE | User’s Muscle Mass |
| USER_CODE | User’s Identification Code |
| BMI | User’s Weight |
| WATER | User’s Body Water |
| Variable | Description |
|---|---|
| BIRTH_YEAR_MONTH | User’s date of birth and month |
| GENDER | User’s gender |
| USER_CODE | User’s identification code |
| HEIGHT | User’s height |
| HEIGHT_CATEGORIZE_10 | User’s height category in 10 cm increments from 160 cm to 190 cm |
| DAY_DIFF | To reflect the date information of the data point due to the difference in date days as 2 October 2021 |
| LABEL | It is a variable showing a normal value: 0 and an abnormal value: 1 and is used for performance evaluation. |
| None | SMOTE | SMOTE + ENN | SMOTE + TOMEK | CTGAN | Proposed Algorithms | |
|---|---|---|---|---|---|---|
| SVM | 0.207 | 0.878 | 0.886 | 0.828 | 0.888 | 0.986 |
| XGBoost | 0.207 | 0.818 | 0.822 | 0.968 | 0.805 | 0.987 |
| CatBoost | 0.323 | 0.965 | 0.969 | 0.888 | 0.948 | 0.987 |
| None | SMOTE | SMOTE + ENN | SMOTE + TOMEK | CTGAN | Proposed Algorithms | |
|---|---|---|---|---|---|---|
| SVM | 0.812 | 0.952 | 0.956 | 0.953 | 0.936 | 0.995 |
| XGBoost | 0.938 | 0.965 | 0.968 | 0.962 | 0.938 | 0.986 |
| CatBoost | 0.990 | 0.968 | 0.992 | 0.971 | 0.983 | 0.998 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Park, M. A New Body Weight Lifelog Outliers Generation Method: Reflecting Characteristics of Body Weight Data. Appl. Sci. 2022, 12, 4726. https://doi.org/10.3390/app12094726
Kim J, Park M. A New Body Weight Lifelog Outliers Generation Method: Reflecting Characteristics of Body Weight Data. Applied Sciences. 2022; 12(9):4726. https://doi.org/10.3390/app12094726
Chicago/Turabian StyleKim, Jiyong, and Minseo Park. 2022. "A New Body Weight Lifelog Outliers Generation Method: Reflecting Characteristics of Body Weight Data" Applied Sciences 12, no. 9: 4726. https://doi.org/10.3390/app12094726
APA StyleKim, J., & Park, M. (2022). A New Body Weight Lifelog Outliers Generation Method: Reflecting Characteristics of Body Weight Data. Applied Sciences, 12(9), 4726. https://doi.org/10.3390/app12094726