1. Introduction
With the development of the global economy, the demand for mineral resources in all countries in the world is also increasing. However, due to complex terrain conditions, many areas rich in mineral resources cannot be explored. In order to increase the detection range and improve exploration efficiency, aeromagnetic measurement technology has been rapidly developed. Airborne magnetic surveying is an important airborne geophysical exploration method, which can be used for magnetic data acquisition under various complex terrain conditions.
Moreover, UAV technology has developed very rapidly and has been well used in all walks of life, so UAV survey technology has gradually developed, and is now widely used in resource exploration, regional survey and other fields [
1,
2]. With the development of UAV technology, more and more countries have carried out the research and development of UAV aeromagnetic measurement equipment technology and achieved remarkable results. The available information indicates that the first company in the world to develop UAV aeromagnetic survey equipment was Magsurvey in the United Kingdom, which developed the PrionUAV aeromagnetic survey system in 2003 [
3]. Since then, many companies around the world have conducted research and development of UAV aeromagnetic survey systems, such as the GeoRanger-I of the Dutch company Fugro [
4], the Canadian company Universal Wing Geophysical (UWG) Venturer [
5], the Japanese RMAX-G1 [
6], the Swiss and German jointly developed reconnaissance B1-100 [
7], the German MD4-1000 [
8], CH-3 [
9] from the Institute of Geophysical and Geochemical Exploration (IGGE) of the Chinese Academy of Geological Science, and an integrated multi-rotor aeromagnetic survey system at Queen’s University in Canada [
10].
Due to the ferromagnetic material inside the UAV and its various influences during flight, it will inevitably cause certain interference to the data collected by the magnetometer sensor; if we want to obtain high-quality aeromagnetic data, we must study the appropriate aeromagnetic compensation technology [
11,
12].The compensation methods of aeromagnetic interference are mainly divided into hardware compensation and software compensation. The hardware compensation method is to first calculate the magnetic interference of the detection platform, and then add several coils to the detection platform to counteract the magnetic interference generated by the aircraft. In the late 20th century, high-cost, low-precision hardware compensation began to be slowly replaced by software compensation [
11]. According to the nature and causes of magnetic interference, Tolles and Lawson divided it into constant interference, induced interference, and eddy current interference, and established the classic Tolles–Lawson model (T-L model) [
13], which is the foundation on which current aeromagnetic compensation methods are built. Based on the T–L model, Leliak established an aeromagnetic compensation method based on FOM compensation flight [
14]. The variables in the T–L equation are not independent of each other, and the linear relationship between the variables affects the stability of the solution, and the linear relationship between the variables is called multicollinearity. Bickel proposed a small-signal method to weaken the linear relationship between variables, resulting in a more stable solution [
15]. Leach first proposed to overcome the multicollinearity problem of equations by introducing regularization terms through the linear regression method [
16], Hardwick et al. proposed a compensation algorithm for total field gradients [
17]. Dou proposes a new real-time method based on recursive least squares, and the simulation results showed that the method has a good ability to compensate for magnetic interference caused by an aircraft and its maneuvering [
18]. Wu et al. use principal component analysis (PCA) to reduce the multicollinearity of the T-L model [
19]. Xu applied deep learning to magnetic anomaly detection and noise cancellation [
20].
Considering the lack of computational accuracy and generalization ability of linear regression methods, people began to explore new aeromagnetic compensation algorithms through neural networks. Williams successfully established an aeromagnetic compensation model based on a neural network for the first time, but his model had the problem of overfitting [
21]. Zhang proposes a new compensation method that used a one-dimensional convolutional neural network to perform secondary compensation on the data that were compensated by the T–L model to eliminate the influence of tail boom swing, which has a significant compensation effect on aeromagnetic noise [
22]. Ma proposed a dual estimation method for aeromagnetic compensation, combining a linear model with a neural network to improve the accuracy of magnetic compensation [
23]. Although the above two methods improved the accuracy of aeromagnetic compensation, there were also problems, such as difficult parameters selection and complex network structures in design. Yu et al. proposed an aeromagnetic compensation algorithm based on deep autoencoder (DAE) [
24], which reduced the multicollinearity between variables in the T–L equation, but it was not perfect for the feature extraction of high-dimensional complex data in the training process of the autoencoder network, and the local minimum problem easily occurred. They then proposed to use a generalized regression neural network (GRNN) to establish an aeromagnetic compensation model, which had a fast calculation speed, high compensation accuracy, and no backpropagation [
25]. Although they solved the problem of over fitting, the problem of gradient disappearance was not considered.
The aeromagnetic compensation method based on a neural network still has some problems to be solved, such as local minimum problems in backpropagation, difficult parameters selection, and complex network structures. In order to further improve the accuracy of aeromagnetic compensation, this paper proposed, for the first time, a magnetic compensation method based on BRF-ANN, which is widely used in function approximation, pattern recognition, and signal processing [
26]; it is also widely used in aerospace, such as the longitudinal channel flight control of small UAVs [
27], the navigation of UAVs [
28], issues related to the optimization of UAV [
29], and so on. The hidden nodes of RBF-ANN adopted the distance between the input mode and the center vector (such as the Euclidean distance) as the independent variable of the function and used the radial basis function (such as the Gaussian function) as the activation function, which is a local approximation network with better generalization ability and a simple network design. The paper is divided into five chapters. The first and last chapters present the introduction and conclusion. The second chapter discusses compensation models and methods, introducing the T–L model and the principles of BP-ANN and RBF-ANN, including the characteristics of RBF-ANN. The third chapter introduces data simulation and testing, and the fourth chapter shows the testing of the measured data; the results are displayed in graphs and tables and a method effectiveness analysis was also carried out. The application and analysis of theoretical synthetic data and real measured aeromagnetic compensation data showed that the proposed method effectively solved the problem of high-precision compensation of aeromagnetic survey data based on rotary wing UAV platform, and greatly improved the error compensation accuracy of aeromagnetic dynamic measurement data.
2. Compensation Models and Methods
2.1. T-L Model
The conversion relationship between the local coordinate system and the aircraft coordinate system is shown in
Figure 1. The center of the magnetometer probe mounted on the drone is set as the origin of the coordinate system
O,
xb,
yb, and
zb are the coordinate axes of the aircraft coordinate system, and their distribution direction is parallel to the direction of the three axes of the magnetometer.
x,
y, and
z are the spatial axes of the local coordinate system at the same origin as the aircraft coordinate system. The
yc axis is the projection of the
yb axis on the
xOy plane. The flight attitude during the flight of the drone can be divided into three parts: side sliding, roll and pitch. Where, is the angle between xb axis and plane
xOy, is the angle between
yb axis and
yc axis, and is the angle between
y axis and
yc axis. The local coordinate system can be rotated according to the sequence of yaws
, pitches
and rolls
. The rotation sequence cannot be replaced at will [
5].
Tolles and Lawson divide interference fields into constant interference fields, induced interference fields, and eddy current interference fields, according to their nature and causes [
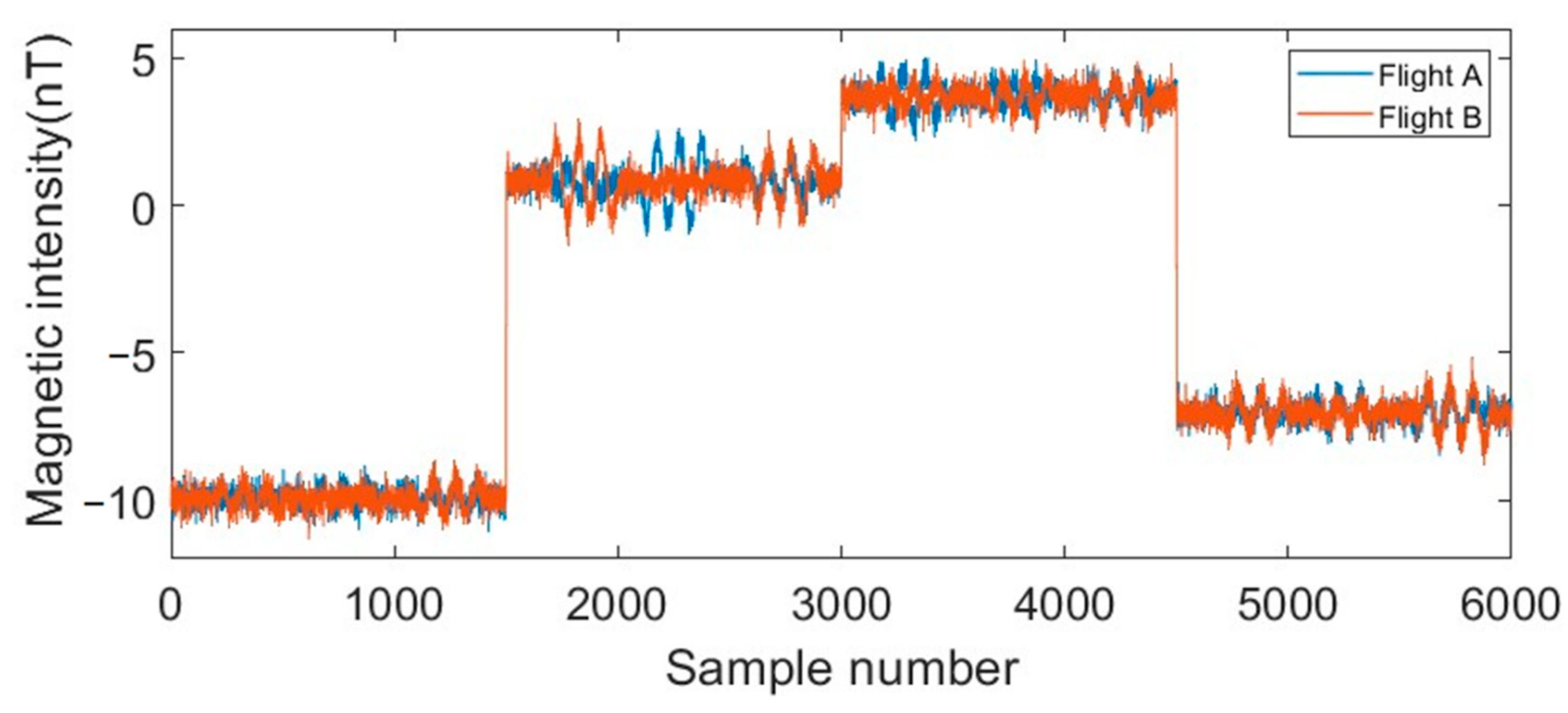
9]. The constant interference field (
) is caused by direct current in the ferromagnetic material and wires inside the aircraft, and its value and direction are independent of the flight attitude of the aircraft, and the interference value is constant for the same aircraft. The induced interference field (
) is produced by the magnetization of soft magnetic or paramagnetic substances inside the aircraft by the geomagnetic field, and its magnitude and direction are closely related to the flight attitude of the aircraft and the changes of the local geomagnetic field. The eddy current interference field is generated by the metal body cutting the geomagnetic field magnetic induction line during the flight of the aircraft, and its size and direction change with the change of the geomagnetic field gradient, flight acceleration and flight action [
5]. They can be represented in the aircraft coordinate system as:
where
T represents the geomagnetic field,
c1,
c2, ......,
c18 represents the compensation coefficient,
u1,
u2, and
u3 are the cosine values of the angle between the three axes of the aircraft coordinate system and the geomagnetic field direction,
,
,
are the differentiation of
u1,
u2,
u3 with respect to time
t,
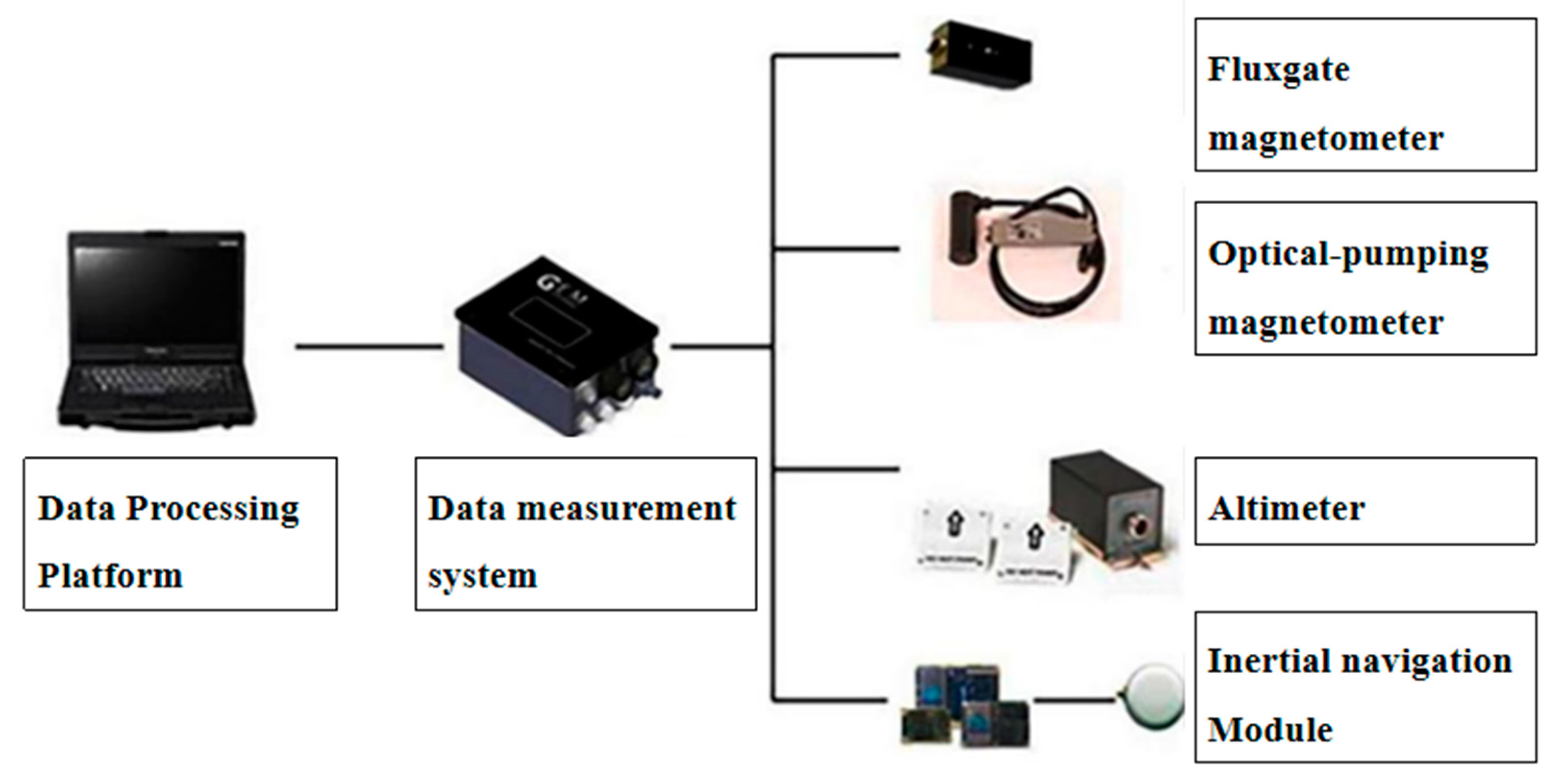
Tt represents the total geomagnetic field data measured by the optical pump magnetometer,
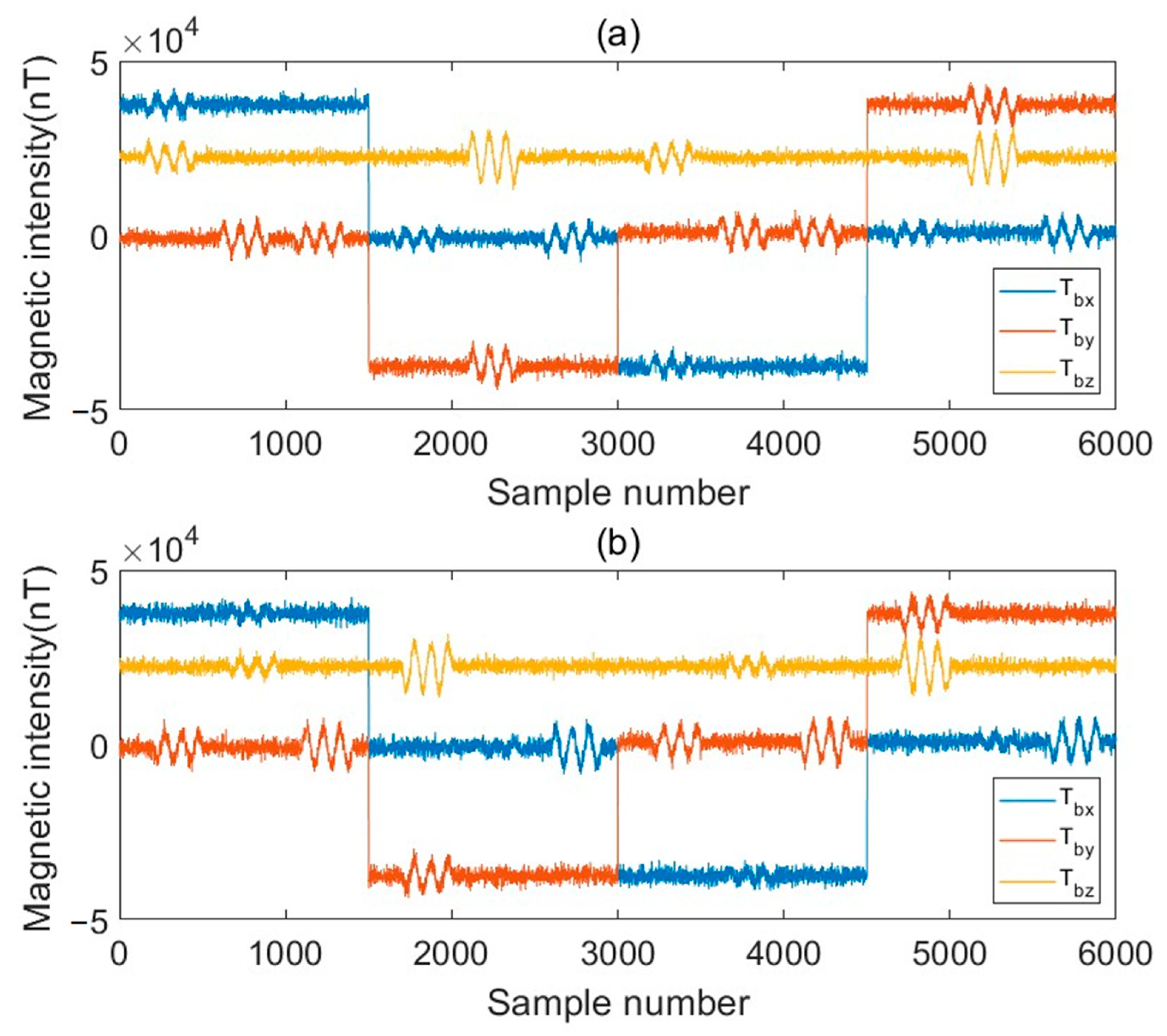
Tbx,
Tby and
Tbz represent the three components of the fluxgate. The accuracy of the measured data of the triaxial fluxgate magnetometer is far inferior to that of the optical pump magnetometer, and it also needs to be corrected accordingly during its installation, resulting in errors in the measured fluxgate three-component data, which indirectly affects the compensation effect. Therefore, this paper needs to make corresponding corrections to the measured fluxgate three-component data, and the correction formula is as follows:
where
Ψ is the side roll angle when the aircraft is flying,
is the pitch angle when the aircraft is flying,
is the side slip angle when the aircraft is flying,
is the magnetization bias angle, and
is the magnetization tilt angle
Finishing Formulas (1)~(5) can be obtained, the total interference magnetic field (
Ht) of the aircraft is:
According to the relationship between
u1,
u2, and
u3After sorting out Equations (11) and (12), we get:
where
b1,
b2, ...,
b16 represent 16 compensation coefficients.
2.2. BP Artificial Neural Network
BP-ANN is an algorithm that can learn and store the relationship between input data and output data without knowing the relationship between the two; it is currently the neural network with the highest application frequency and the widest application field. The calculation process of BP-ANN mainly consists of two parts: forward propagation of information and backpropagation of error. The process of forward propagation is to conduct the input data in the order of the input layer, the hidden layer, and the output layer, and then compare the output data with the expected output. If the error reaches the specified range, or the number of training times reaches a certain number of times, the training can be stopped, otherwise it will be transferred to the backpropagation process of error. The backpropagation of error refers to the process of finding the parameters corresponding to the minimum value of the loss function of the neural network by continuously and iteratively optimizing the weights and biases in the neural network. At present, gradient descent is the most widely used optimization method in the backpropagation process. The BP-ANN structure diagram is shown in
Figure 2.
In the process of aeromagnetic compensation, the causes of aeromagnetic interference were analyzed to determine the training parameters of BP-ANN, the same goes for RBF-ANN, the compensation model had 9 input parameters, which consists of the fluxgate three components, the directional cosine and its derivative to time. In addition, the output layer is magnetic interference (
Ht), and the number of hidden layers of BP-ANN and the number of nodes per hidden layer can be determined by trial and error and the following empirical formula:
where
δ take the integer (experience value) of 1~10,
r is the number of hidden layer nodes,
n is the number of input layer nodes,
l is the number of output layer nodes. In this paper, the number of hidden layers of BP-ANN is 3, and the number of hidden layer nodes is 4.
The training process of BP-ANN is:
(1) The weights and bias vectors of the neural network are initialized, and the weights and biases from the input layer to the hidden layer and the hidden layer to the output layer are denoted as , , and , respectively.
(2) The forward propagation process of information is carried out to calculate the output value of each layer and its corresponding loss function:
where
represents the parameter collection of the neural network,
represents the true value in the data,
represents the weight of the neural network,
represents the bias of the neural network and
φ represents the activation function;
(3) Calculate the error terms of the output and hidden elements based on the loss function. The error terms of the output unit are:
The error terms of the hidden cell are:
where
represents the input value of the hidden layer,
represents the output layer,
h represents the output value of the hidden layer, and
represents the model predicted value;
(4) Update weights and biases in the neural network. The updated output unit is:
The updated hidden unit is:
where
η represents the learning rate and
k represents the number of iterations;
(5) Repeat the above steps repeatedly, when the loss function is less than a given threshold or the number of iterations is greater than the set number of times, stop the iteration; this article believes that the parameters obtained at this time are the best parameters.
Before feeding data into the neural network, it is important to normalize the data. This can not only speed up the calculation of the neural network, but also improves the accuracy of the algorithm. In order to facilitate the calculation, this paper normalized the data to the interval of [−1,1], and the normalization method is:
where
x is the data before normalization and
y is the normalized data.
2.3. RBF Artificial Neural Network
Compared with BP artificial neural network, RBF artificial neural network is an effective feed forward neural network, which has significant advantages such as strong global approximation ability, no local minimum problems and fast learning speed [
30]. It usually consists of an input layer, hidden layer, and output layer, in which it can be adjusted according to the actual need for the number of neurons in the hidden layer. In this paper, the number of RBF-ANN neurons in the hidden layer was the same as the number of input samples, and its network structure diagram is shown in
Figure 3.
BP-ANN can have one or multiple hidden layers, while BRF-ANN have only one hidden layer. The first layer of the BRF-ANN is the input layer, which only plays the role of transmitting information and does not do any transformation processing on the input data. The second layer is a hidden layer, the number of nodes of the hidden layer is not fixed, it can be adjusted according to actual need, and based on the task goal is constantly changing, the activation function of the hidden layer is a non-negative linear function symmetrical along the center point and constantly decaying rapidly to both sides, with local response characteristics. The third layer is the output layer, which will linearly transform the input data and then the output.
The activation function of the hidden layer of the BP-ANN calculates the inner product of the input data and connection weights, while the independent variable of the activation function in the hidden layer of the BRF-ANN is the Euclidean distance between the input data and the center vector, and the activation function is the radial basis function. The farther the input data is from the center of the radial basis function, the less active it is. It can be seen that the output of the BRF-ANN is not related to all parameters, but only to a small number of parameters, and this article calls this characteristic of the BRF-ANN a local response characteristic. Therefore, BRF-ANNs are local approximation networks, while BP-ANNs are global approximation networks.
The hidden and output layers of a BP-ANN can be linear or nonlinear, while the hidden layer of an BRF-ANN is nonlinear, and the output layer is linear. The basic idea of BRF-ANN is that the radial basis function is used to construct a hidden layer space for the data in hidden nodes in the hidden layer, and the hidden layer converts the input data to a certain extent, and converts the low-dimensional mode input data into the high-dimensional space, so that the linear indivisible problem in the low-dimensional space becomes linearly separable in the high-dimensional space.
In the learning process of BRF-ANN, the most critical problem is how to determine the expansion coefficient of the hidden layer activation function. The common method is to select directly from a given set of training samples according to a certain method, or to determine by clustering. In this paper, the center point was randomly selected from the input sample using the direct selection method.
The activation function of the BRF-ANN is generally the Gaussian function:
In the above equation,
r is the Euclidean distance of the input data to the center point,
represents the rate at which the function falls to 0, also known as the expansion factor. As can be seen from
Figure 4, the smaller the expansion factor, the narrower the image.
The training process of the BRF-ANN is as follows:
- (1)
Determine the parameters. Initialize the connection weights between the hidden layer and the output layer:
where
is the minimum value of the output of the
k-th neuron,
is the maximum value of the output of the
k-th neuron, and
q is the number of output layer units.
Initialize the center parameters of each neuron in the hidden layer: In order to reflect the characteristics of the input information to the greatest extent, the values of the centers of neurons in different hidden layers should be as different as possible and should correspond to the width vector. In order to show the characteristics of the input information more obviously, this paper changes the initial value of the central component of each neuron in the hidden layer from small to large equal spacing, so that the weaker input information produces a stronger response near the smaller center. The size of the spacing is determined by the number of neurons in the hidden layer. Finally, the initial value of the central parameter of each neuron in the hidden layer of the BRF-ANN can be expressed as:
where
is the minimum value entered for the
i-th feature value
is the maximum value entered in the
i-th feature, and
p is the number of neurons in the hidden layer.
Initialize the width vector: As can be seen from
Figure 4, the smaller the width vector, the narrower the image of the activation function, and the smaller the response of other neuron centers in this neuron. Its calculation formula is:
- (1)
Input layer to hidden layer calculation:
where
is the center vector corresponding to the
j-th hidden layer neuron and
is the width vector of the
j-th hidden layer neuron.
- (2)
Calculation of the output layer:
- (3)
Updated iteration of weight:
where is
the learning rate and
E represents the loss function.
In the training process, this paper first initializes the weight from the hidden layer to the output layer, the central parameters of each neuron in the hidden layer, and the width vector, and then calculates the loss function, when the loss function is less than the given threshold or the number of iterations is greater than the set number of times, stop the iteration, otherwise the gradient descent method is used to recalculate each weight until the conditions are met.
5. Conclusions
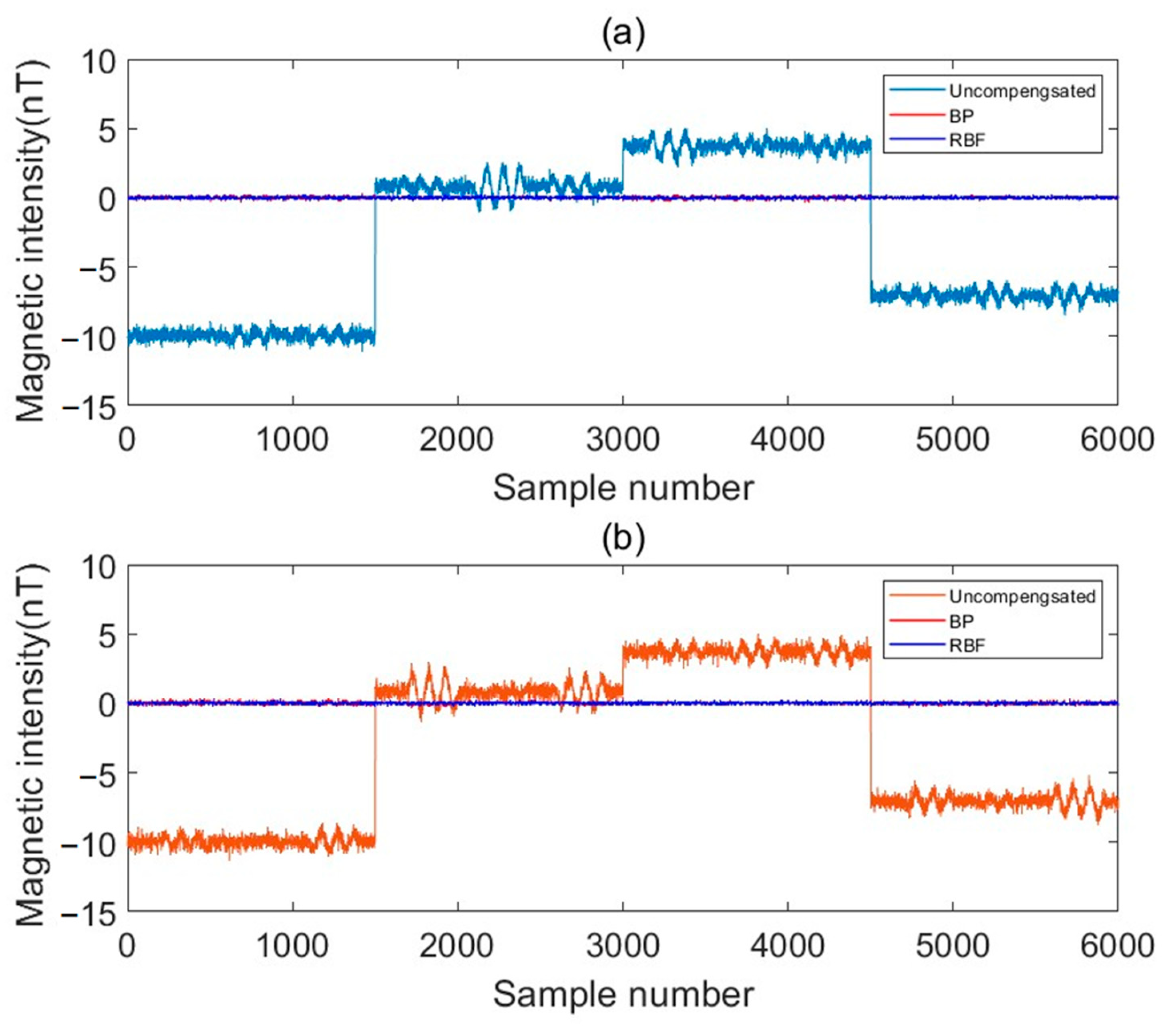
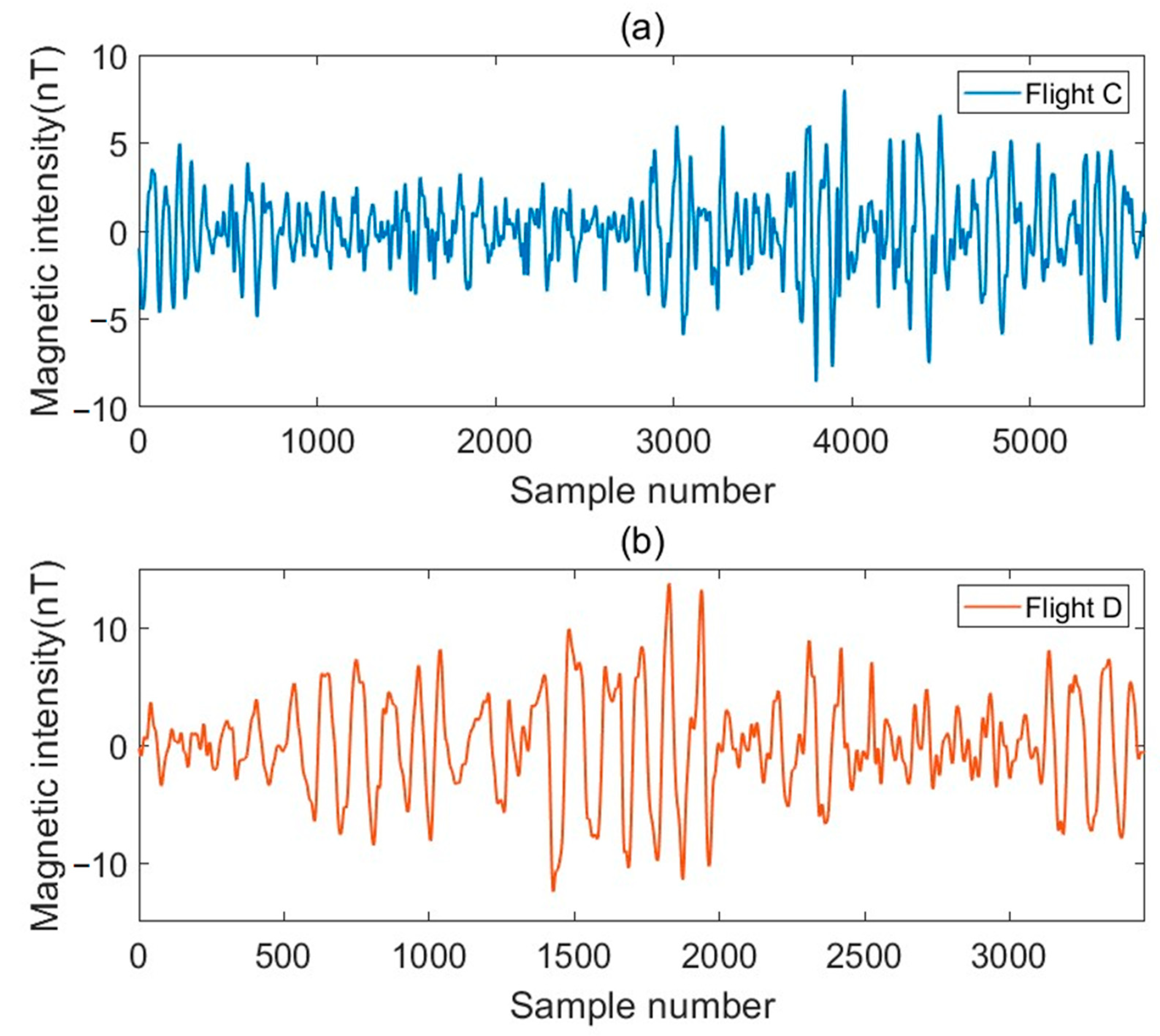
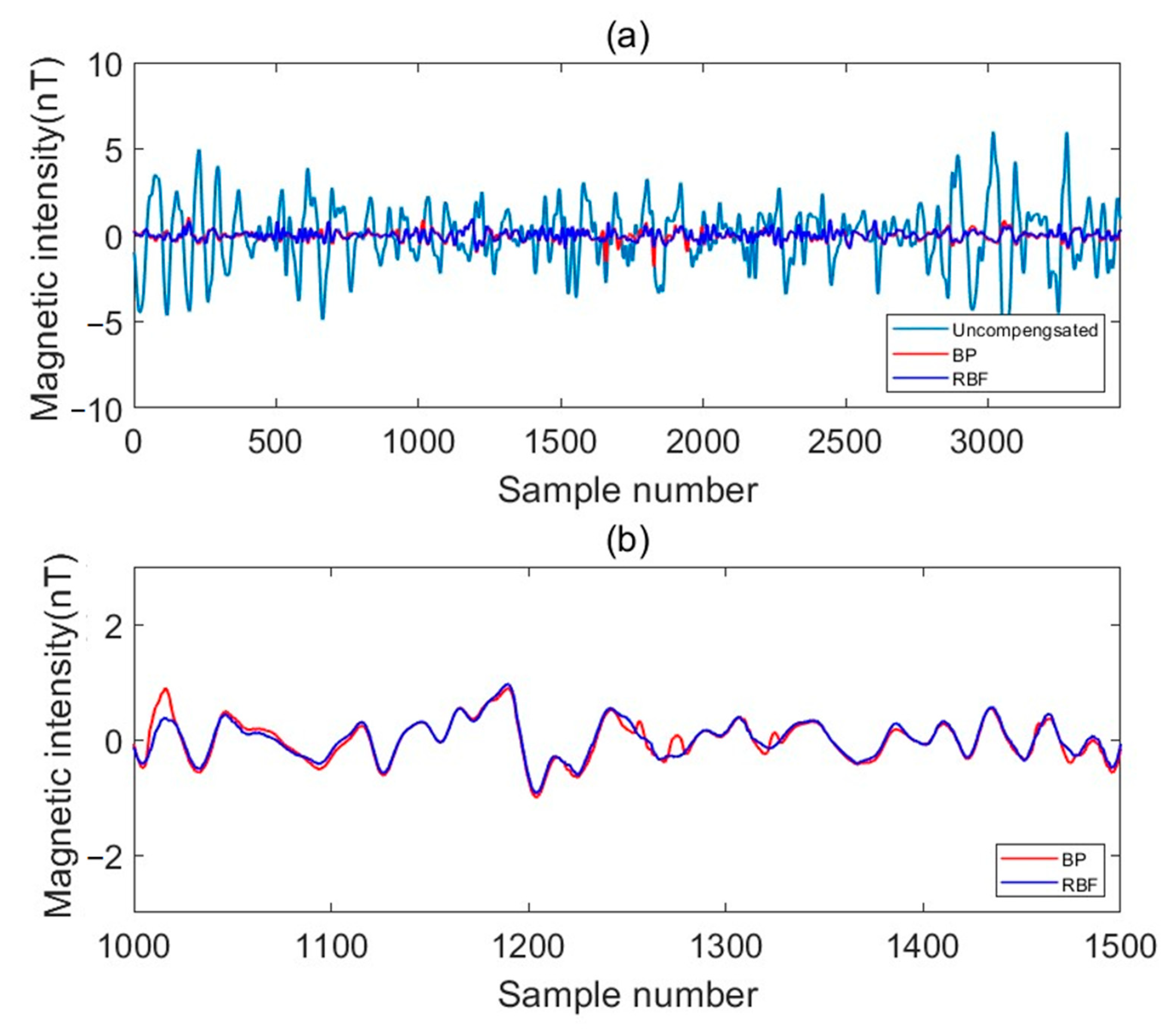
In the previous aeromagnetic compensation work, although the classical BP-ANN is stronger than traditional regression algorithms in terms of fitting ability, the BP-ANN is a global approximation network, with limited generalization ability, and there are problems, such as falling into a local minimum easily, gradient disappearance, and an overfitting problem in magnetic compensation which affects the accuracy of aeromagnetic compensation. In order to improve the accuracy of compensation, on the basis of the T–L model, we proposed a compensation algorithm based on BRF-ANN, in which the hidden layer node uses the distance between the input mode and the central vector as the independent variable of the function, and uses the radial basis function as the activation function, which has the characteristics of local approximation and better generalization ability, avoids the problem of local minimum effectively, and improves the accuracy of magnetic compensation to a certain extent. We verified the feasibility of this method in simulated data and measured data experiments.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}