
Aero-Engine Remaining Useful Life Estimation Based on CAE-TCN Neural Networks


Abstract
:1. Introduction
2. Methodology
2.1. CAE
2.2. TCN
2.3. Proposed RUL Estimation Model
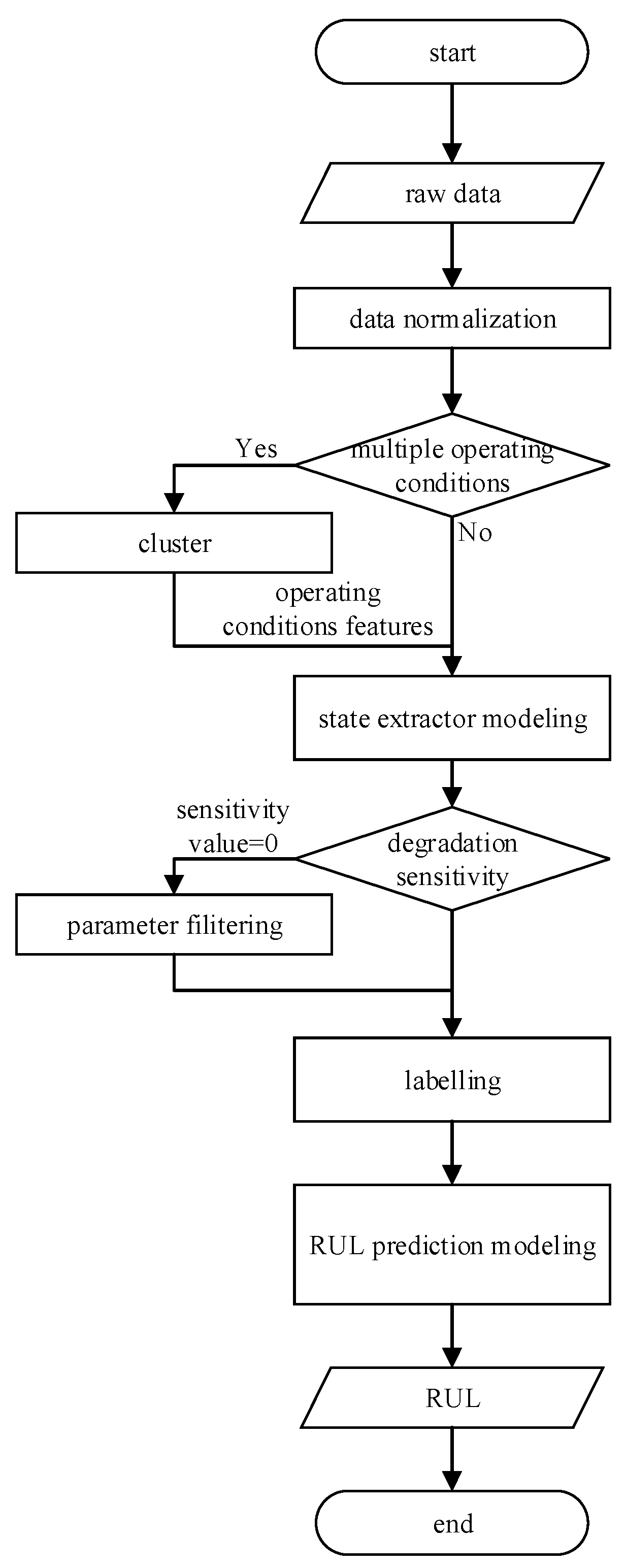
2.4. Complete RUL Prediction Algorithm
3. Experiments
3.1. Dataset Description
3.2. Data Pre-Processing
3.3. Data Cleaning and Labelling
3.4. Model Configuration and Training
3.5. Performance Evaluation
4. Results and Discussion
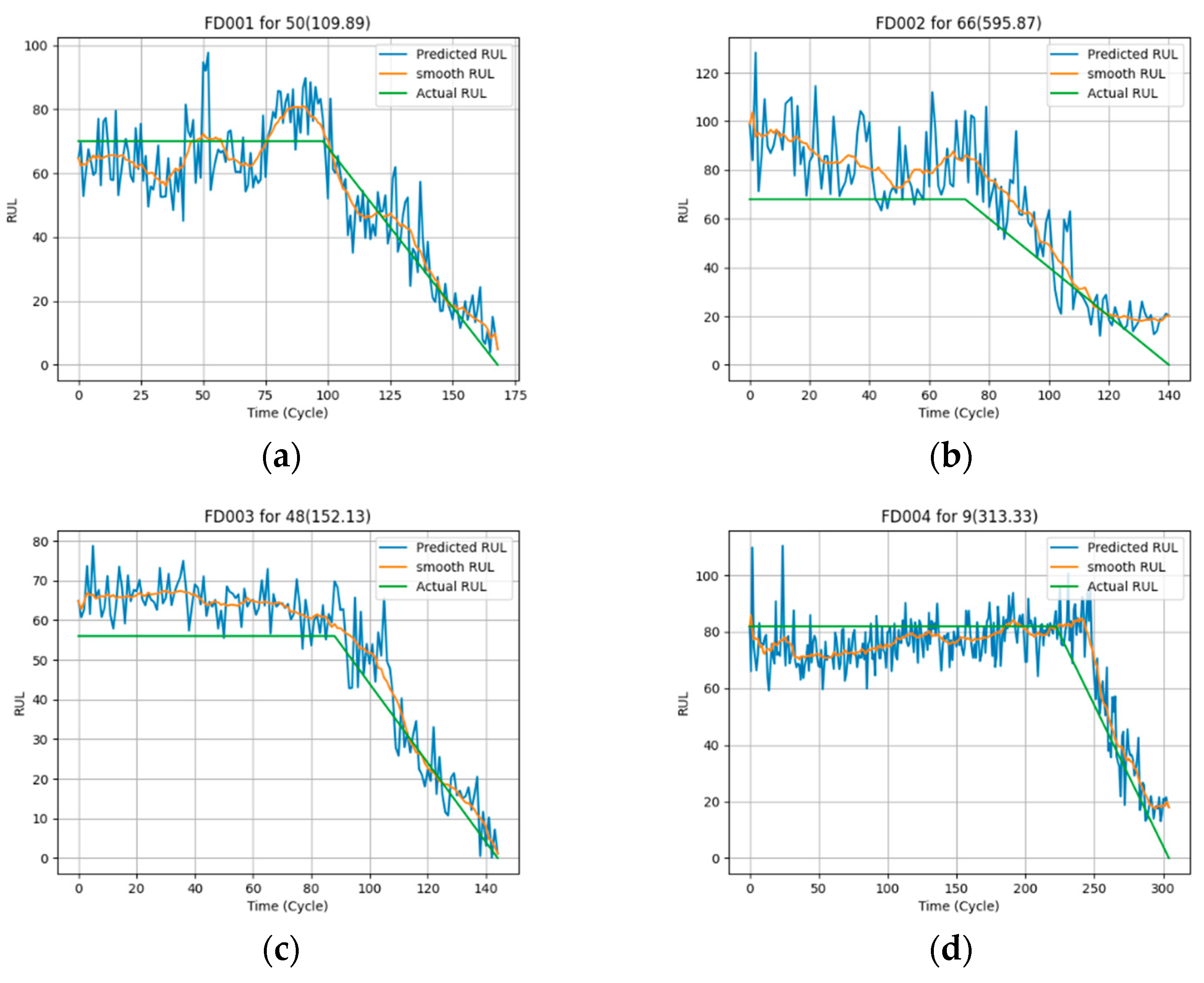
4.1. Prediction Performance
4.2. Comparison
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Li, X.; Ding, Q.; Sun, J.Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliabil. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Azadeh, A.; Asadzadeh, S.M.; Salehi, N.; Firoozi, M. Condition-based maintenance effectiveness for series-parallel power generation system—A combined Markovian simulation model. Reliabil. Eng. Syst. Saf. 2015, 142, 357–368. [Google Scholar] [CrossRef]
- Zaidan, M.A.; Mills, A.R.; Harrision, R.F. Bayesian framework for aerospace gas turbine engine prognostics. In Proceedings of the 2013 IEEE Aerospace Conference, Big Sky, MT, USA, 2–9 March 2013; pp. 1–8. [Google Scholar]
- Qian, Y.; Yan, R.; Gao, R.X. A multi-time scale approach to remaining useful life prediction in rolling bearing. Mech. Syst. Signal. Process. 2017, 83, 549–567. [Google Scholar] [CrossRef] [Green Version]
- Jouin, M.; Gouriveau, R.; Hissel, D.; Pra, M.-C.; Zerhouni, N. Particle filter-based prognostics: Review, discussion and perspectives. Mech. Syst. Signal. Process. 2016, 7273, 2–31. [Google Scholar] [CrossRef]
- Jouin, M.; Gouriveau, R.; Hissel, D.; Pra, M.-C.; Zerhouni, N. Degradations analysis and aging modeling for health assessment and prognostics of PEMFC. Reliabil. Eng. Syst. Saf. 2016, 148, 78–95. [Google Scholar] [CrossRef]
- Ali, J.B.; Chebel-Morello, B.; Saidi, L.; Malinowski, S.; Fnaiech, F. Accurate bearing remaining useful life prediction based on Weibull distribution and artificial neural network. Mech. Syst. Signal. Process. 2015, 5657, 150–172. [Google Scholar]
- Jun, Z.; Nan, C.; Weiwen, P. Estimation of bearing remaining useful life based on multiscale convolutional neural network. IEEE Trans. Ind. Electron. 2018, 66, 3208–3216. [Google Scholar]
- Li, Y.; Shi, J.; Wang, G.; Liu, X. A data-driven prognostics approach for RUL based on principle component and instance learning. In Proceedings of the IEEE International Conference on Prognostics and Health Management (ICPHM), Ottawa, ON, Canada, 20–22 June 2016; pp. 1–7. [Google Scholar]
- Khelif, R.; Chebel-Morello, B.; Malinowski, S.; Laajili, E.; Fnaiech, F.; Zerhouni, N. Direct remaining useful life estimation based on support vector regression. IEEE Trans. Ind. Electron. 2017, 64, 2276–2285. [Google Scholar] [CrossRef]
- Dong, M.; He, D. A segmental hidden semi-Markov model (HSMM)-based diagnostics and prognostics framework and methodology. Mech. Syst. Signal. Process. 2007, 21, 2248–2266. [Google Scholar] [CrossRef]
- Peel, L. Data driven prognostics using a Kalman filter ensemble of neural network models. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008. [Google Scholar]
- Zhang, C.; Lim, P. Multi-objective deep belief networks ensemble for remaining useful life estimation in prognostics. IEEE Trans. Neural. Netw. Learn Syst. 2017, 28, 2306–2318. [Google Scholar] [CrossRef] [PubMed]
- Babu, G.S.; Zhao, P.; Li, X.L. Deep convolutional neural network based regression approach for estimation of remaining useful life. In Proceedings of the International Conference on Database Systems for Advanced Applications, Dallas, TX, USA, 16–19 April 2016; pp. 214–228. [Google Scholar]
- Heimes, F.O. Recurrent neural networks for remaining useful life estimation. In Proceedings of the International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008. [Google Scholar]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Lin, Y. Remaining useful life estimation of engineered systems using vanilla LSTM neural networks. Neurocomputing 2017, 275, 167–179. [Google Scholar] [CrossRef]
- Ince, T.; Kiranyaz, S.; Eren, L.; Askar, M.; Gabbouj, M. Real-time motor fault detection by 1-D convolutional neural network. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Hinton, G.E. Connectionist learning procedures. In Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1990; pp. 555–610. [Google Scholar]
- LeCun, Y. Modèles connexionnistes de l’apprentissage. Ph.D. Thesis, Universite P. et M. Curie, Paris, France, 1987. [Google Scholar]
- Bourlard, H.; Kamp, Y. Auto-association by multilayer perceptrons and singular value decomposition. Biol. Cybern. 1988, 59, 291–294. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kiranyaz, S.; Ince, T.; Gabbouj, M. Real-time patient-specific ECG classification by 1-D convolutional neural networks. IEEE Trans. Biomed. Eng. 2016, 63, 664–675. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Choi, J. Convolutional neural network for gear fault diagnosis based on signal segmentation approach. Struct. Health Monit. 2019, 18, 1401–1415. [Google Scholar] [CrossRef]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- van den, O.A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.W.; Kavukcuoglu, K. “WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Saxena, A.; Goebel, K. Turbofan Engine Degradation Simulation Data Set; NASA Ames: Mountain View, CA, USA, 2008. [Google Scholar]
- Prognostics Data Repository; NASA Ames Research Center: Moffett Field, CA, USA, 2008.
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage propagation modeling for aircraft engine run-to-failure simulation. In Proceedings of the International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | CMAPSS | ||||
|---|---|---|---|---|---|
| FD001 | FD002 | FD003 | FD004 | ||
| Training dataset | Engine units | 100 | 260 | 100 | 249 |
| Total samples | 20,631 | 53,759 | 24,720 | 61,249 | |
| Maximum life cycles | 362 | 378 | 525 | 543 | |
| Minimum life cycles | 128 | 128 | 145 | 128 | |
| Testing dataset | Engine units | 100 | 259 | 100 | 248 |
| Maximum cycles | 303 | 367 | 475 | 486 | |
| Minimum cycles | 31 | 21 | 38 | 19 | |
| Total samples | 13,096 | 33,991 | 16,596 | 41,214 | |
| Operating conditions | 1 | 6 | 1 | 6 | |
| Fault modes | 1 | 1 | 2 | 2 | |
| Trend | Sensor NO. |
|---|---|
| Ascending | 2, 3, 4, 8, 11, 13, 15, 17 |
| Descending | 7, 9, 12, 14, 20, 21 |
| Constant | 1, 5, 10, 16, 18, 19 |
| Name | (Kernel, Stride, Padding) | |
|---|---|---|
| 1 | Convolution block | (3, 1, 1), (2, 2) |
| 2 | Convolution block | (3, 1, 1), (2, 2) |
| 3 | Convolution block | (3, 1, 1), (2, 2) |
| 4 | Convolution layer | (2, 1) |
| 5 | Upsampling block | (4, 2, 1) |
| 6 | Upsampling block | (4, 2, 1) |
| 7 | Upsampling block | (3, 2) |
| 8 | Upsampling block | (4, 2, 1) |
| Name | (Kernel, Stride, Dilation) | |
|---|---|---|
| 1 | Temporal block | (3, 1, 1) |
| 2 | Temporal block | (3, 1, 2) |
| 3 | Temporal block | (3, 1, 4) |
| 4 | Linear layer | / |
| FD001 | FD002 | FD003 | FD004 | |
|---|---|---|---|---|
| Proposed network | 0.26 s | 0.80 s | 0.31 s | 0.93 s |
| One-Dimensional CNN | 0.28s | 1.06s | 0.34s | 1.24s |
| LSTM | 0.62s | 1.64s | 0.75s | 1.95s |
| Test score | FD001 | FD002 | FD003 | FD004 |
|---|---|---|---|---|
| Proposed network | 3.72 | 26.57 | 7.36 | 56.75 |
| One-Dimensional CNN | 7.22 | 67.32 | 11.04 | 80.24 |
| LSTM | 5.27 | 50.81 | 9.84 | 73.18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, G.; Wang, Y.; Shi, Z.; Zhang, G.; Jin, F.; Wang, J. Aero-Engine Remaining Useful Life Estimation Based on CAE-TCN Neural Networks. Appl. Sci. 2023, 13, 17. https://doi.org/10.3390/app13010017
Ren G, Wang Y, Shi Z, Zhang G, Jin F, Wang J. Aero-Engine Remaining Useful Life Estimation Based on CAE-TCN Neural Networks. Applied Sciences. 2023; 13(1):17. https://doi.org/10.3390/app13010017
Chicago/Turabian StyleRen, Guanghao, Yun Wang, Zhenyun Shi, Guigang Zhang, Feng Jin, and Jian Wang. 2023. "Aero-Engine Remaining Useful Life Estimation Based on CAE-TCN Neural Networks" Applied Sciences 13, no. 1: 17. https://doi.org/10.3390/app13010017
APA StyleRen, G., Wang, Y., Shi, Z., Zhang, G., Jin, F., & Wang, J. (2023). Aero-Engine Remaining Useful Life Estimation Based on CAE-TCN Neural Networks. Applied Sciences, 13(1), 17. https://doi.org/10.3390/app13010017