1. Introduction
Panoramic images, also known as panoramas, are wide-angle photographs with a horizontal field of view (FOV) of up to 360 degrees. Panoramas can be created by merging numerous photos using an image stitching technique. It is a widely used technique of increasing the camera’s FOV in a constructive manner. Real-time image stitching has been a challenging area for image processing professionals in recent decades. Image stitching techniques have been employed in various applications: aerial and satellite image mosaics [
1,
2], SAR image mosaicking [
3,
4], video frame mosaicking [
5], augmented reality [
6], real state and many more. Image stitching methods contain two main steps: image alignment and image blending. The advancement of image stitching technology is often dependent on the advancement of these two components. Image alignment is being used to determine motion relationships by identifying and matching feature points across images. It has a direct link to the speed and success rate of the image stitching procedure. Integral aspects of image alignment are feature detection, feature description and feature matching. In an image, a feature refers to a certain meaningful pattern. It can be a pixel, edge or contour, and it can also be an object. The procedure of finding these meaningful patterns in an image is called feature detection. The feature detector generates a number of distinct points in an image, known as key-points or feature points. The feature detection algorithm selects these locations depending upon their tolerance to noise and other deformations. Many feature detectors have their own feature descriptors for detected feature points. A feature descriptor is a vector of values that represents the image patch surrounding a feature point. It might be as basic as the raw pixel values or as complex as a histogram of gradient orientations. Various feature detectors and descriptors have evolved over time. However, due to their poor speed and high number of false matches, the majority of them are not useful for image stitching applications. Feature detectors and descriptors are crucial in image alignment; if a good pairing of feature detector and descriptor is not chosen, then the images to be stitched will not be aligned properly, which will add distortions in the resulting stitched image. Thus, a comparative study is required to determine the best combination of feature detector and descriptor that can provide high-quality stitched images with lower computational cost.
In the field of computer vision and image processing, the research on feature detectors and descriptors has grown rapidly in last couple of decades. A brief literature review is presented in the following to show the continuous development in feature detection and description. The first corner detector was proposed by Morevec [
7]. The authors of [
8] proposed a fast operator for the detection and precise location of distinct points, corners and centers of circular image features. Harris and Stephens [
9] proposed a new corner detector named the Harris corner detector, which overcomes the limitations of the Moravec detector. Tomasi and Kanade [
10] developed Kanade–Lucas–Tomasi (KLT) tracker based on the Harris detector for the detection and tracking of features across images.
A comparison of the Harris corner detector with other detectors was carried out by [
11,
12]. Shi and Tomasi [
13] presented an improved version of the Harris corner detector named Good Features to Track (GFTT). Lindeberg [
14] presented a junction detector with auto-scale selection. It is a two-stage process that begins with detection at coarse scales and progresses to localization at finer scales.
Wang and Brady [
15] presented a fast corner detection approach based on cornerness measurement of total curvature. The authors of [
16] proposed a new approach for feature detection, named SUSAN; however, it is not rotation- or scale-invariant. Hall et al. [
17] presented a definition of saliency for scale change and evaluated the Harris corner detector, the method presented in [
18] and the Harris–Laplacian corner detector [
19]. Harris–Laplacian is a combination of the Harris and Laplacian methods which can detect feature points in an image, each with their own characteristic and scale. The authors of [
20] compared various popular detectors. Later, Schmid et al. [
21] modified the comparison procedure and conducted several qualitative tests. These tests showed that the Harris detector outperforms all other algorithms. Lowe [
22] presented the scale-invariant feature transform (SIFT) algorithm, which is a combination of both detector and descriptor. SIFT is invariant to scaling, orientation and illumination changes. Brown and Lowe [
23,
24] used SIFT for automatic construction of panoramas. They used the SIFT detector for feature detection and description. Multi-band blending was used to smoothly blend the images. Image stitching techniques based on SIFT are well suited for stitching high-resolution images with a number of transformations (rotation, scale, affine and so on); however, they suffer from image mismatch and are computationally costly. The authors of [
25] combined the Harris corner detector with the SIFT descriptor with the aim to address scaling, rotation and variations in lighting condition issues across the images. The authors of [
26] tried to accelerate the process and reduced the distortions by modifying the traditional algorithm. The center image was selected as a reference image, then the following image in the sequence was taken based on a set of statistical matching points between adjacent images. The authors of [
27] compared different descriptors with SIFT, and the results proved that SIFT is one of the best detectors based on the robustness of its descriptor. Zuliani et al. [
28] presented a mathematical comparison of various popular approaches with the Harris corner detector and KLT tracker. Several researchers examined and refined the Harris corner detector and SIFT [
29,
30,
31]. A comparative study of SIFT and Its variants was carried out by [
32]. Mikolajczyk and Schmid [
33] proposed a novel approach for detecting interest points invariant to scale and affine transformations. It uses the Harris interest point detector to build a multi-scale representation and then identifies points where a local measure (the Laplacian) is maximum across scales. Mikolajczyk [
34] compared the performance of different affine covariant region detectors under varying imaging conditions.
The authors of [
35] evaluated Harris, Hessian and difference of Gaussian (DoG) filters on images of 3D objects with different viewpoints, lighting variations and changes of scale. Matas et al. [
36] proposed the Maximally Stable Extremal Regions (MSER) detector, which detects blobs in images. Nistér and Stewénius [
37] provided its faster implementation. Bay et al. [
38] proposed SURF, which is both a detector and descriptor. It is based on a Hessian matrix and is similar to SIFT. It reduces execution time at the cost of accuracy as compared to SIFT. The authors of [
39] proposed a phase correlation and SURF-based automated image stitching method. First, phase correlation is utilized to determine the overlapping and the connection between two images. Then, in the overlapping areas, SURF is used to extract and match features. The authors of [
40] used SURF features for image stitching. They attempted to speed up the image stitching process by removing non-key feature points and then utilized the RELIEF-F algorithm to reduce dimension and simplify the SURF descriptor. Yang et al. [
41] proposed an image stitching approach based on SURF line segments, with the goal of achieving robustness to scaling, rotation, change in light and substantial affine distortion across images in a panorama series. For real-time corner detection, the authors of [
42] proposed a new detector named the Features from Accelerated Segment Test (FAST) corner detector. The authors of [
43] surveyed different local invariant feature detectors. The authors of [
44] provided a good comparison of local feature detectors. Some application-specific evaluations were presented by [
45,
46,
47,
48]. Agrawal et al. [
49] introduced CenSurE, a novel feature detector that outperforms current state-of-the-art feature detectors in image registration and visual odometry. Willis and Sui [
50] proposed a fast corner detection algorithm for use on structural images, i.e., images with man-made structures. Calonder et al. [
51] proposed the Binary Robust Independent Elementary Features (BRIEF) descriptor, which is very helpful for extracting descriptors from interest points for image matching. The authors of [
52] presented a new local image descriptor, DAISY, for wide-baseline stereo applications.
Leutenegger et al. [
53] proposed a combination of both detector and descriptor named Binary Robust Invariant Scalable Key-Points (BRISK), which is based on the FAST detector and in combination with the assembly of a bit-string descriptor. The use of the FAST detector reduced its computational time. Rublee et al. [
54] presented the Oriented FAST and Rotated BRIEF (ORB) detector and descriptor as a very fast alternative to SIFT and SURF. The authors of [
55] presented the Fast Retina Key-Point (FREAK) descriptor based on the retina of the human visual system (HVS). Alcantarilla [
56] developed a new feature detector and descriptor named KAZE in which they formed nonlinear scale spaces to detect features in order to improve localization accuracy. The faster version of KAZE was presented by the authors in the year 2013 and named Accelerated-KAZE (AKAZE) [
57]. The authors of [
58] proposed the AKAZE-based image stitching algorithm. The authors of [
59,
60] presented a detailed evaluation of image stitching techniques. Lyu et al. [
61] surveyed various image/video stitching algorithms. They first discussed the fundamental principles and weaknesses of image/video stitching algorithms and then proposed the potential solutions to overcome those weaknesses. Megha et al. [
62] analyzed different image stitching techniques. They reviewed various image stitching algorithms based on the three components of the image stitching process: calibration, registration and blending. Further, they discussed challenges, open issues and future directions of image stitching algorithms.
Various prominent feature detectors and descriptors were analyzed by [
63,
64] and [
65]. However, these studies included a few detectors and descriptors, and they have not considered all combinations of detectors and descriptors. The authors of [
66] introduced a new simple descriptor and compared it to BRIEF and SURF. The authors of [
67] compared several feature detectors and descriptors and analyzed their performance against various transformations in general and then presented a practical analysis of detectors and descriptors for feature tracking.
Several outstanding feature detectors and descriptors have been reported in the existing literature. Some studies compared detectors and descriptors in general, and some are application-specific, and a few have compared only detectors, while others have compared only descriptors. The number of detectors and descriptors used in all of these studies is limited, and they have not considered all pairs of detectors and descriptors. However, as the introduction of new detectors and descriptors is an evolving process, improved comparative studies are always needed. In this study, we aimed to update the comparative studies in connection with existing literature.
The following statements show a connection of existing studies with the proposed work and the attributes that differentiate our study from previous studies:
Several detectors and descriptors were included in this study, apart from those already compared by [
63,
64,
67,
68,
69].
A variety of prominent measures were employed in our research in accordance with [
63]. We also used image quality assessment measures to compare the quality of the stitched image to the input image.
We present an appropriate framework on image stitching to analyze the performance of the chosen detector and descriptor combination. Our aim is to present an assessment of all detectors and descriptors for image stitching applications. For future research in image stitching area this framework can assist as a guideline.
We present a comparison and performance analysis of detectors and descriptors for different types of datasets for image stitching applications.
Finally, we obtained a rank for the detector—descriptor pairs in terms of individual datasets.
This paper compares several feature detectors and descriptors for image stitching applications. It may assist researchers in selecting a suitable detector and descriptor combination for image stitching applications. First, all popular detectors and descriptors are presented. Next, each combination of detector and descriptor is evaluated for stitching the images. For the evaluation, a variety of datasets including various possible scenarios are considered. The outcomes of this work, as presented above, add various new contributions to this domain. These contributions are outlined after a brief overview of earlier studies. The paper is structured as follows: A brief overview of feature detectors and descriptors used in this study is presented in
Section 2.
Section 3 provides details about the datasets and methodology used in the study.
Section 4 presents results and discusses the outcomes. Finally, the paper is concluded in
Section 5.
4. Results and Discussion
In this study, we analyzed a total 85 feature detector–descriptor combinations pairs. It is not possible to show outputs of all combinations here; therefore, we show stitched image outputs of the top six combinations in each dataset category.
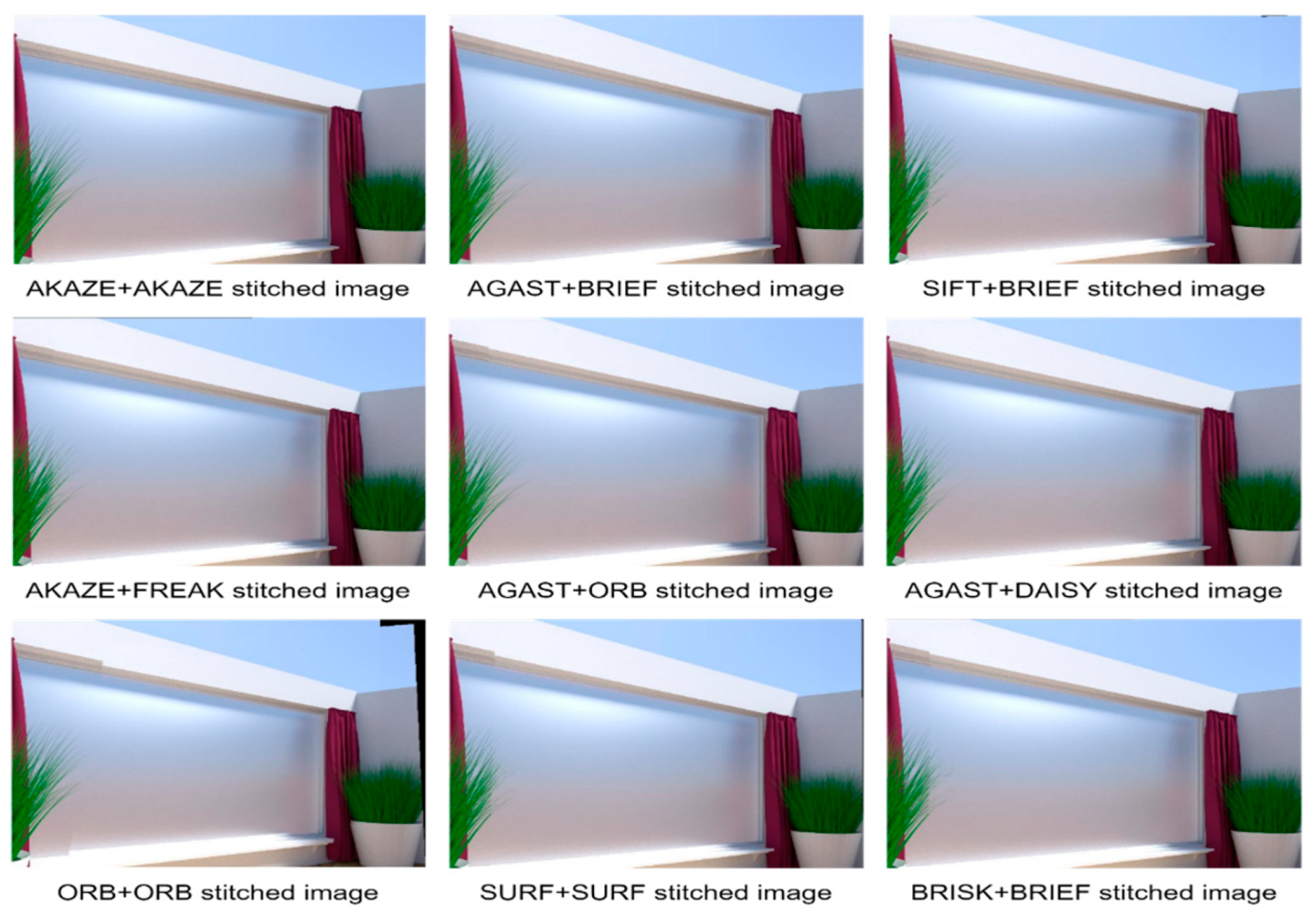
Figure 4 shows the output stitched images of the top six combinations which produce better quality of stitched images in comparison to all other combinations for dataset 1. Upon close examination of the stitched images, it can be observed that AKAZE + AKAZE combination gives the best-quality image, which is further verified by the objective IQA metrics.
Table 2 shows the inlier ratio obtained using different combinations of feature detector and descriptors for dataset 1.
Table 3,
Table 4,
Table 5 and
Table 6 presents the values of PSNR, SSIM, FSIM and VSI obtained using various combinations of detector–descriptor pairs for dataset 1.
Table 7 shows execution time of different detector–descriptor-based algorithms for dataset 1. In all the tables, some entries are marked as NC. NC stands for “not compatible”, i.e., that particular descriptor is not compatible with combined detector.
For dataset 1, ORB + SIFT has a very good inlier ratio, but the quality of the stitched image is poor in comparison to other pairs. This pair has poor quality of stitched images despite its very good inlier ratio because in order to obtain a better-quality image, the matched points should be spread into the image, but for this pair, matched points are clustered. It also takes more execution time. ORB + BRISK also has a very good inlier ratio, but the quality of the stitched image is poor because of the low number of matched points. It has better execution time than ORB + SIFT, which may be because the BRISK descriptor takes less time to extract descriptors than SIFT. AKAZE + SIFT and AKAZE + DAISY both have very good inlier ratio, a little lower than ORB + BRISK. The quality of stitched image obtained using both the combinations is also good because they have sufficient matches. AKAZE + AKAZE also has a good inlier ratio, and the quality of stitched image is also superior to all other combinations. This is because the number of matches is good and are well spread over the image. It also takes less execution time. GFTT + BRISK, AKAZE + ORB, AKAZE + BRISK and FAST + BRISK all have average inlier ratio, but the quality of stitched image is very good. This may be because these combinations produce more false matches, which reduces the inlier ratio, and the correct matches are well spread over the image, which leads to a better quality stitched image. BRISK + ORB and SIFT + FREAK have low inlier ratio and degraded quality of the stitched image. Overall, AKAZE + AKAZE has very good inlier ratio, generating very good stitched images with relatively short execution time (
Table 7), which implies that AKAZE + AKAZE is best suited for stitching dataset 1.
Figure 5 shows results obtained using AKAZE + AKAZE, BRISK + ORB and SIFT + FREAK combinations for dataset 1. The first column in each row displays the initial matches for that particular detector–descriptor combination, and the second column shows the correct matches for the detector–descriptor pair. The last column shows the stitched image obtained using that particular combination.
Figure 6 shows the output stitched images of the top six combinations, which produces a better quality of stitched image in comparison to all other combinations for dataset 2. Again, it is observed that the AKAZE + AKAZE combination gives the best-quality image.
Table 8 shows the inlier ratio obtained using different combinations of feature detector and descriptors for dataset 2.
Table 9,
Table 10,
Table 11 and
Table 12 presents the values of PSNR, SSIM, FSIM and VSI obtained using various combinations of detector–descriptor pairs for dataset 2. It is observed that the AKAZE + AKAZE combination has highest values of quality metrics for dataset 2.
Table 13 shows execution time of different detector–descriptor-based algorithms for dataset 2.
For dataset 2, AKAZE + BRISK and ORB + BRISK both have very good inlier ratio, but the quality of the stitched image is poor; this is because they have a smaller number of correct matched points, which affected the homography metric that in turn resulted into degraded quality of the stitched image. SURF + BRISK and ORB + SIFT also have a very good inlier ratio, but the quality of stitched image is poor; this is because the matched points are not well spread in the image. AKAZE + AKAZE has a very good inlier ratio, and stitched image quality is also very good. This is because AKAZE + AKAZE has a good number of matched points that are well spread across the image. KAZE + ORB, SIFT + FREAK, KAZE + FREAK and AKAZE + FREAK have average inlier ratio in comparison to other combinations, but the quality of stitched image is good. The inlier ratio is low because of the higher number of initial matched points and smaller number of correct matched points in comparison to initial matched points, but correct matched points are sufficient to obtain an accurate homography metric, which in turn gives a good quality of stitched image. AGAST + BRISK has low inlier ratio and poor stitched image quality because of a smaller number of matched points. SIFT + BRIEF and AKAZE + SIFT also generate a poor quality of stitched image because of the low inlier ratio. Once again, AKAZE + AKAZE generated a very good quality of stitched image with relatively short execution time (
Table 13), which makes AKAZE + AKAZE the best choice for stitching dataset 2, which contains outdoor scenes with irregular features such as trees.
Figure 7 shows results obtained using AKAZE + AKAZE, AGAST + BRISK and ORB + BRISK combinations for dataset 2. Each row in the figure presents a detector–descriptor combination, where the first column illustrates the initial matches for that particular pair, the second column shows the correct matches, and the last column exhibits the stitched image produced using that combination.
Figure 8 shows the output stitched images of the top six combinations which produce a better quality of stitched image in comparison to all other combinations for dataset 3. It is observed that the AKAZE + AKAZE combination gives the best-quality image. We found one more combination, AGAST + BRIEF which also gives a better quality of stitched image.
Table 14 shows the inlier ratio, obtained using different combinations of feature detector and descriptors for dataset 3.
Table 15,
Table 16,
Table 17 and
Table 18 presents the values of PSNR, SSIM, FSIM and VSI obtained using various combinations of detector–descriptor pairs for dataset 3. It is observed that the AKAZE + AKAZE combination has the highest values of quality metrics for dataset 3. It is observed that the AGAST + BRIEF combination also gives a very good quality of stitched image.
For dataset 3, MSD + BRISK, ORB + BRISK, SURF + BRISK and GFTT + BRISK have very good inlier ratio, but the quality of stitched image is poor because of a smaller number of matched points. This also implies that the BRISK descriptor is not suitable for stitching indoor scene images. AKAZE + SIFT has a good inlier ratio, but the quality of stitched image is poor because matched points are not well spread across the image. AKAZE + AKAZE has a good inlier ratio, and the stitched image quality is also very good because it has sufficient number of matched points that are well spread across the images. SIFT + FREAK has an average inlier ratio in comparison to other combinations, and its quality is poor because it has a smaller number of matched points. AGAST + DAISY has average inlier ratio, but the quality of stitched image is very good because of the sufficient number of correct matches. SIFT + BRIEF, AKAZE + FREAK, AGAST + BRIEF and MSD + FREAK generate a good quality of stitched images because the correct matched points are well spread across the image. AGAST + BRISK, ORB + SIFT and KAZE + ORB have poor inlier ratio and poor quality of stitched image. This is because they have very a smaller number of matched points. The inlier ratio of AKAZE + ORB, KAZE + FREAK and FAST + BRISK is low, and the quality of stitched image is not good because of a smaller number of matched points. Overall, AKZE + AKAZE and AGAST + BRIEF generate a very good quality of stitched image, and both are computationally faster (
Table 19) for stitching dataset 3 images. Therefore, it can be concluded that AKAZE + AKZE and AGAST + BRIEF are the best choices for stitching indoor scene images.
Figure 9 shows results obtained using AKAZE + AKAZE, AGAST + BRIEF, ORB + BRISK and GFTT + BRISK combinations for dataset 3. In the figure, each row represents a unique detector–descriptor combination. The first column demonstrates the initial matches for that particular pair, while the second column showcases the correct matches. The last column displays the resulting stitched image obtained using that specific combination.
We also considered six publicly available datasets for image stitching. The input images of the dataset used and the generated stitched output images are given in
Appendix A. We examined a pair of deep learning algorithms for image stitching that were recently introduced in the literature.
Appendix B contains the results obtained using these deep learning algorithms.
Table 20 (dataset 1 column) shows the top ten methods (detector and descriptor combination) for dataset 1. AKAZE + AKAZE is top ranked for dataset 1, and after that BRISK + FREAK and AKAZE + ORB are at second position.
Table 20 (dataset 2 column) presents the top ten methods for dataset 2. AKAZE + AKAZE performs the best in dataset 2 and hence ranks first. SIFT + FREAK and Star + BRIEF are at the second position.
Table 20 (dataset 3 column) shows the top ten methods for dataset 3. AKAZE + AKAZE is at top position for dataset 3, and AGAST + BRIEF secures the second position. SIFT + BRIEF is in the third position.
Finally, the ranking may be adjusted by weighting particular metrics while averaging the results. In future, different weights can be assigned to each metric depending upon the requirements; for example, in real time applications, we can compromise with quality for shorter execution time; therefore, we can assign higher weight to execution time in comparison to quality metrics. In virtual tour applications, quality is important, so we can assign quality metrics higher weight than execution time.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}