
Comparing Speaker Adaptation Methods for Visual Speech Recognition for Continuous Spanish †



Abstract
:1. Introduction
2. Related Work
3. The LIP-RTVE Database
4. Model Architecture
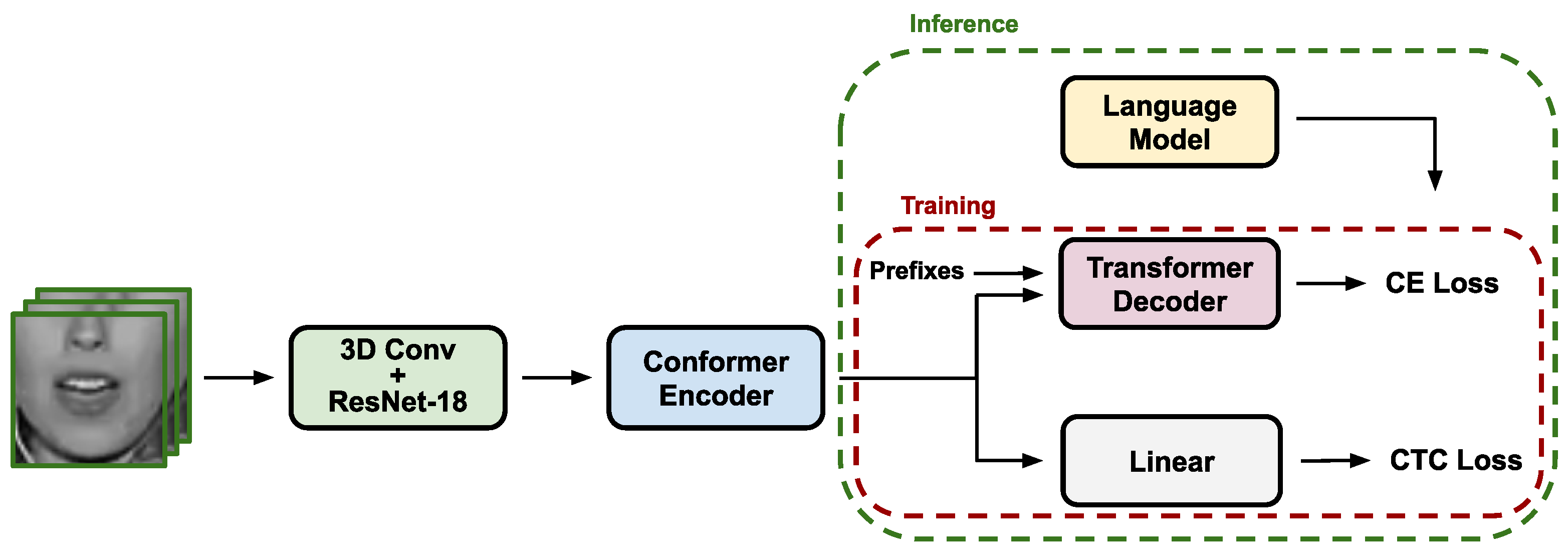
4.1. Visual Speech Recogniser
- Visual Front-end: Consists of a 2D ResNet-18 [55] in which, in order to deal with temporal relationships in the data, the first layer has been replaced by a 3D convolutional layer with a kernel size of 7 × 7 pixels and a receptive field of five frames.
- Conformer Encoder: Defined as a 12-layer encoder based on Conformers [56], an approach explicitly designed to capture both global and local speech interactions from the previous latent representation provided by the visual front-end.
- Hybrid CTC/Attention Decoder: Composed of a six-layer Transformer decoder [24] based on the Cross-Entropy (CE) loss and a linear layer as the CTC-based decoding branch [23]. Both decoders are followed by a softmax activation layer. Details on how these loss functions are combined can be found in Section 4.3.
4.2. Language Model
4.3. Loss Function
4.4. Inference
5. Speaker Adaptation Methods
5.1. Fine-Tuning
- Multi-Speaker Training (MST). The VSR system is re-estimated using the training data of the entire speaker-dependent partition of the database. This strategy, as discussed throughout the paper, can be considered as a task adaptation.
- Speaker-Adapted Training (SAT). In this case, only data corresponding to a specific speaker is considered when fine-tuning the VSR system.
- Two-Step Speaker-Adapted Training (TS-SAT). As its name suggests, this strategy consists of two fine-tuning steps. First, following the MST strategy, the entire partition is used to re-estimate the VSR system and achieve task adaptation. Afterwards, the system is fine-tuned to a specific speaker using the corresponding data.
5.2. Use of Adapters
6. Experimental Setup
6.1. Datasets
- The entire speaker-dependent partition. This corresponds to the official speaker- dependent partition of the LIP-RTVE database. The training and development sets offer around 9 h and 2 h of data, respectively. As suggested in Section 5, using one of these data sets to estimate the model can be seen as a task adaptation. Concretely, this partition is used when applying the fine-tuning MST strategy, providing a model used as initialisation for the TS-SAT strategy and the Adapters-based adaptation method.
- The speaker-specific partition. Only the data corresponding to the aforementioned twenty speakers are considered in this case. On average, the training and development sets offer around 15 min and 4 min of data per speaker, respectively. As suggested in Section 5, when seeking to estimate a VSR system adapted to a specific speaker, only data associated with that speaker is used. Concretely, this partition is considered in all of our proposed methods with the exception of the fine-tuning MST strategy.
6.2. Experiments
6.3. Methodology
- Both the MST- and SAT-based models were initially pretrained using the weights publicly released by Ma et al. [22] for the Spanish language (see Section 4.1).
- The MST-based system was fine-tuned using the entire speaker-dependent partition of the LIP-RTVE database, which is considered our task-adapted VSR system.
- An SAT-based system using the corresponding speaker-specific training data was independently estimated for each speaker considered in our study, i.e., twenty SAT-based systems were defined.
- When applying the TS-SAT strategy, the previously estimated MST-based system was used for initialisation, which can be considered an adaptation of the model to the task. Then, we followed the same fine-tuning scheme described for the SAT strategy to obtain a TS-SAT-based system for each speaker.
- Regarding the Adapters-based method, different experiments were conducted using the entire speaker-dependent partition training set. However, no acceptable recognition rates were obtained when adapting the Spanish VSR model provided by Ma et al. [22] to the LIP-RTVE task using Adapters. Therefore, we decided to use the MST-based model for initialisation. Similar to the TS-SAT strategy, this can be seen as starting from a task-adapted model. Then, speaker-specific adapter modules were injected and estimated for each speaker considered in our study while keeping the original VSR system backbone frozen, as described in Section 5.2.
- Experiments were conducted using either the training or development set for adapting. However, it should be noted that TS-SAT-based systems were always based on the MST-based system estimated with the training set, while in the second step the training or development set was used depending on the experiment. Conversely, when applying the Adapters-based method, depending on whether we used the speaker-specific training or development set, for initialisation we used the MST-based model estimated with the corresponding dataset from the entire speaker-dependent partition.
- All these VSR systems, as suggested in Section 6.1, were evaluated on the test set corresponding to each of the speakers selected in our study. The MST-based system was the same regardless of the evaluated speaker. Conversely, for the rest of the methods, the corresponding speaker-adapted system was used in each case.
- The LM used in all the tests was the one described in Section 4.2. Unlike the VSR system, it was not re-estimated in any of our experiments.
6.4. Implementation Details
7. Results & Discussion
7.1. Fine-Tuning
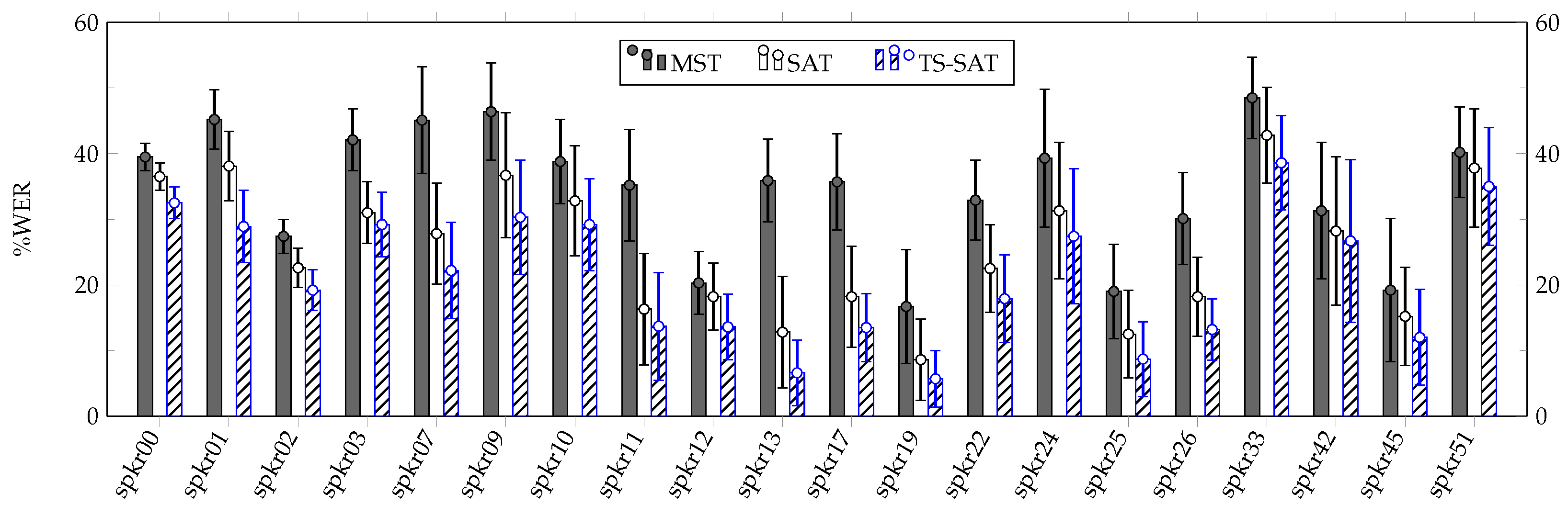
- Irrespective of the dataset used for estimation, it can be observe that the MST method is significantly outperformed by the rest of the proposed strategies, a fact that supports the effectiveness of our fine-tuning speaker adaptation approaches.
- When the training set was used, the MST-based model provided a considerable quality of speech recognition. This result could mean that the end-to-end architecture employed in our experiments was able to generalise common patterns across speakers when addressing VSR.
- Regarding the amount of data used during the fine-tuning process, the results reflect a drastic deterioration of system performance when the development set was used. However, this deterioration was noticeably lower when the TS-SAT strategy was applied, showing that this approach could be more robust against situations where a given speaker presents data scarcity.
- The TS-SAT strategy stands as the best option when addressing speaker adaptation. This fact supports the idea that a two-step fine-tuning process in which the model is first adapted to the general task could benefit the final adaptation of the VSR system to a specific speaker.
- Results comparable to the current state of the art were obtained. Moreover, our findings suggest that the fine-tuning method employed in our experiments is capable of adapting VSR end-to-end architectures in a small number of epochs, even when only a limited amount of data is available.
7.2. Use of Adapters
- In data scarcity scenarios, i.e., when using the development set for estimation, the Adapters-based adaptation method was able to significantly improve the MST-based model performance reported in Table 2. However, no significant differences were observed when using different Adapter sizes.
- When the training set was used, more remarkable differences could be observed regarding the Adapter size, leading to the conclusion that 32 hidden units (estimating around 0.52% of parameters with respect to the entire end-to-end model; see Table 1) provided the best recognition rate. However, the Adapters-based method did not outperform the MST-based model in this scenario, as Table 2 confirms.
7.3. Overall Analysis
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASR | Automatic Speech Recognition |
| CE | Cross-Entropy |
| CTC | Connectionist Temporal Classification |
| LM | Language Model |
| MST | Multi-Speaker Training |
| ROI | Region Of Interest |
| SAT | Speaker-Adapted Training |
| TS-SAT | Two-Step Speaker-Adapted Training |
| VSR | Visual Speech Recognition |
| WER | Word Error Rate |
References
- Juang, B.H.; Rabiner, L.R. Hidden Markov models for speech recognition. Technometrics 1991, 33, 251–272. [Google Scholar] [CrossRef]
- Gales, M.; Young, S. The Application of Hidden Markov Models in Speech Recognition; Now Publishers Inc.: Delft, The Netherlands, 2008. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the ICASSP, Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar]
- Juang, B. Speech recognition in adverse environments. Comput. Speech Lang. 1991, 5, 275–294. [Google Scholar] [CrossRef]
- Afouras, T.; Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Deep audio-visual speech recognition. Trans. PAMI 2018, 44, 8717–8727. [Google Scholar] [CrossRef] [PubMed]
- Ma, P.; Petridis, S.; Pantic, M. End-To-End Audio-Visual Speech Recognition with Conformers. In Proceedings of the ICASSP, Toronto, ON, Canada, 6–11 June 2021; pp. 7613–7617. [Google Scholar]
- McGurk, H.; MacDonald, J. Hearing lips and seeing voices. Nature 1976, 264, 746–748. [Google Scholar] [CrossRef] [PubMed]
- Besle, J.; Fort, A.; Delpuech, C.; Giard, M.H. Bimodal speech: Early suppressive visual effects in human auditory cortex. Eur. J. Neurosci. 2004, 20, 2225–2234. [Google Scholar] [CrossRef] [PubMed]
- Potamianos, G.; Neti, C.; Gravier, G.; Garg, A.; Senior, A. Recent advances in the automatic recognition of audiovisual speech. Proc. IEEE 2003, 91, 1306–1326. [Google Scholar] [CrossRef]
- Shi, B.; Hsu, W.N.; Lakhotia, K.; Mohamed, A. Learning audio-visual speech representation by masked multimodal cluster prediction. arXiv 2022, arXiv:2201.02184. [Google Scholar]
- Fernandez-Lopez, A.; Sukno, F. Survey on automatic lip-reading in the era of deep learning. Image Vis. Comput. 2018, 78, 53–72. [Google Scholar] [CrossRef]
- Ezz, M.; Mostafa, A.M.; Nasr, A.A. A Silent Password Recognition Framework Based on Lip Analysis. IEEE Access 2020, 8, 55354–55371. [Google Scholar] [CrossRef]
- Stafylakis, T.; Tzimiropoulos, G. Zero-shot keyword spotting for visual speech recognition in-the-wild. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 513–529. [Google Scholar]
- Denby, B.; Schultz, T.; Honda, K.; Hueber, T.; Gilbert, J.M.; Brumberg, J.S. Silent speech interfaces. Speech Commun. 2010, 52, 270–287. [Google Scholar] [CrossRef]
- González-López, J.A.; Gómez-Alanís, A.; Martín Doñas, J.M.; Pérez-Córdoba, J.L.; Gómez, A.M. Silent Speech Interfaces for Speech Restoration: A Review. IEEE Access 2020, 8, 177995–178021. [Google Scholar] [CrossRef]
- Matsui, K.; Fukuyama, K.; Nakatoh, Y.; Kato, Y. Speech Enhancement System Using Lip-reading. In Proceedings of the IICAIET, Kota Kinabalu, Malaysia, 26–27 September 2020; pp. 1–5. [Google Scholar]
- Chung, J.; Senior, A.; Vinyals, O.; Zisserman, A. Lip reading sentences in the wild. In IEEE Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 3444–3453. [Google Scholar]
- Afouras, T.; Chung, J.; Zisserman, A. LRS3-TED: A large-scale dataset for visual speech recognition. arXiv 2018, arXiv:1809.00496. [Google Scholar]
- Zhao, Y.; Xu, R.; Song, M. A cascade sequence-to-sequence model for chinese mandarin lip reading. In Proceedings of the ACM Multimedia Asia, Beijing, China, 16–18 December 2019; pp. 1–6. [Google Scholar]
- Prajwal, K.; Afouras, T.; Zisserman, A. Sub-word level lip reading with visual attention. In Proceedings of the CVPR, New Orleans, LA, USA, 19–24 June 2022; pp. 5162–5172. [Google Scholar]
- Ma, P.; Petridis, S.; Pantic, M. Visual Speech Recognition for Multiple Languages in the Wild. Nat. Mach. Intell. 2022, 4, 930–939. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Gómez, F.; Schmidhuber, J. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd ICML, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gómez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. 2017. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 24 May 2023).
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.; Hayashi, T. Hybrid CTC/Attention Architecture for End-to-End Speech Recognition. IEEE J. Sel. Top. Signal Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Bear, H.; Harvey, R.; Theobald, B.; Lan, Y. Which phoneme-to-viseme maps best improve visual-only computer lip-reading? In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 8–10 December 2014; pp. 230–239. [Google Scholar]
- Fernández-López, A.; Sukno, F. Optimizing Phoneme-to-Viseme Mapping for Continuous Lip-Reading in Spanish. In Proceedings of the International Joint Conference on Computer Vision, Imaging and Computer Graphics, Porto, Portugal, 27 February–1 March 2017; pp. 305–328. [Google Scholar]
- Thangthai, K. Computer Lipreading via Hybrid Deep Neural Network Hidden Markov Models. Ph.D. Thesis, University of East Anglia, Norwich, UK, 2018. [Google Scholar]
- Cox, S.J.; Harvey, R.W.; Lan, Y.; Newman, J.L.; Theobald, B.J. The challenge of multispeaker lip-reading. In Proceedings of the AVSP, Queensland, Australia, 26–29 September 2008; pp. 179–184. [Google Scholar]
- Bear, H.; Harvey, R. Decoding visemes: Improving machine lip-reading. In Proceedings of the ICASSP, Shanghai, China, 20–25 March 2016; pp. 2009–2013. [Google Scholar]
- Bear, H.; Harvey, R.; Theobald, B.; Lan, Y. Resolution limits on visual speech recognition. In Proceedings of the ICIP. IEEE, Paris, France, 27–30 October 2014; pp. 1371–1375. [Google Scholar]
- Dungan, L.; Karaali, A.; Harte, N. The Impact of Reduced Video Quality on Visual Speech Recognition. In Proceedings of the ICIP, Athens, Greece, 7–10 October 2018; pp. 2560–2564. [Google Scholar]
- Duchnowski, P.; Lum, D.; Krause, J.; Sexton, M.; Bratakos, M.; Braida, L. Development of speechreading supplements based on automatic speech recognition. IEEE Trans. Biomed. Eng. 2000, 47, 487–496. [Google Scholar] [CrossRef] [PubMed]
- Thangthai, K.; Harvey, R. Improving Computer Lipreading via DNN Sequence Discriminative Training Techniques. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 3657–3661. [Google Scholar]
- Assael, Y.; Shillingford, B.; Whiteson, S.; Freitas, N. LipNet: Sentence-level Lipreading. arXiv 2016, arXiv:1611.01599. [Google Scholar]
- Leung, K.Y.; Mak, M.W.; Kung, S.Y. Articulatory feature-based conditional pronunciation modeling for speaker verification. In Proceedings of the Interspeech, Jeju Island, Republic of Korea, 4–8 October 2004; pp. 2597–2600. [Google Scholar]
- Ochiai, T.; Watanabe, S.; Katagiri, S.; Hori, T.; Hershey, J. Speaker Adaptation for Multichannel End-to-End Speech Recognition. In Proceedings of the ICASSP, Calgary, AB, Canada, 15–20 April 2018; pp. 6707–6711. [Google Scholar]
- Delcroix, M.; Watanabe, S.; Ogawa, A.; Karita, S.; Nakatani, T. Auxiliary Feature Based Adaptation of End-to-end ASR Systems. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2444–2448. [Google Scholar]
- Weninger, F.; Andrés-Ferrer, J.; Li, X.; Zhan, P. Listen, Attend, Spell and Adapt: Speaker Adapted Sequence-to-Sequence ASR. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 3805–3809. [Google Scholar]
- Li, K.; Li, J.; Zhao, Y.; Kumar, K.; Gong, Y. Speaker Adaptation for End-to-End CTC Models. In Proceedings of the IEEE SLT, Athens, Greece, 18–21 December 2018; pp. 542–549. [Google Scholar]
- Kandala, P.; Thanda, A.; Margam, D.; Aralikatti, R.; Sharma, T.; Roy, S.; Venkatesan, S. Speaker Adaptation for Lip-Reading Using Visual Identity Vectors. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 2758–2762. [Google Scholar]
- Fernández-López, A.; Karaali, A.; Harte, N.; Sukno, F. Cogans For Unsupervised Visual Speech Adaptation To New Speakers. In Proceedings of the ICASSP 2020, Barcelona, Spain, 4–8 May 2020; pp. 6294–6298. [Google Scholar]
- Yang, H.; Zhang, M.; Tao, S.; Ma, M.; Qin, Y. Chinese ASR and NER Improvement Based on Whisper Fine-Tuning. In Proceedings of the ICACT, Pyeongchang, Republic of Korea, 19–22 February 2023; pp. 213–217. [Google Scholar]
- Bapna, A.; Firat, O. Simple, Scalable Adaptation for Neural Machine Translation. In Proceedings of the EMNLP-IJCNLP. ACL, Hong Kong, China, 3–7 November 2019; pp. 1538–1548. [Google Scholar]
- Tomanek, K.; Zayats, V.; Padfield, D.; Vaillancourt, K.; Biadsy, F. Residual Adapters for Parameter-Efficient ASR Adaptation to Atypcal and Accented Speech. In Proceedings of the EMNLP, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 6751–6760. [Google Scholar]
- Thomas, B.; Kessler, S.; Karout, S. Efficient Adapter Transfer of Self-Supervised Speech Models for Automatic Speech Recognition. In Proceedings of the ICASSP, Singapore, 22–27 May 2022; pp. 7102–7106. [Google Scholar]
- Fernández-López, A.; Martínez, O.; Sukno, F. Towards estimating the upper bound of visual-speech recognition: The visual lip-reading feasibility database. In Proceedings of the 12th FG, Washington, DC, USA, 30 May–3 June 2017; pp. 208–215. [Google Scholar]
- Gimeno-Gómez, D.; Martínez-Hinarejos, C.D. Analysis of Visual Features for Continuous Lipreading in Spanish. In Proceedings of the IberSPEECH, Valladolid, Spain, 24–25 March 2021; pp. 220–224. [Google Scholar]
- Gimeno-Gómez, D.; Martínez-Hinarejos, C.D. LIP-RTVE: An Audiovisual Database for Continuous Spanish in the Wild. In Proceedings of the LREC, Marseille, France, 20–25 June 2022; pp. 2750–2758. [Google Scholar]
- Neto, J.; Almeida, L.; Hochberg, M.; Martins, C.; Nunes, L.; Renals, S.; Robinson, T. Speaker-adaptation for hybrid HMM-ANN continuous speech recognition system. In Proceedings of the EUROSPEECH, Madrid, Spain, 18–21 September 1995; pp. 2171–2174. [Google Scholar]
- Saon, G.; Soltau, H.; Nahamoo, D.; Picheny, M. Speaker adaptation of neural network acoustic models using i-vectors. In Proceedings of the IEEE ASRU, Olomouc, Czech Republic, 8–12 December 2013; pp. 55–59. [Google Scholar]
- Zadeh, A.B.; Cao, Y.; Hessner, S.; Liang, P.P.; Poria, S.; Morency, L.P. CMU-MOSEAS: A Multimodal Language Dataset for Spanish, Portuguese, German and French. In Proceedings of the EMNLP, Online, 16–20 November 2020; pp. 1801–1812. [Google Scholar]
- Fernández-López, A.; Sukno, F. End-to-End Lip-Reading Without Large-Scale Data. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2076–2090. [Google Scholar] [CrossRef]
- Gimeno-Gómez, D.; Martínez-Hinarejos, C.D. Speaker-Adapted End-to-End Visual Speech Recognition for Continuous Spanish. In Proceedings of the IberSPEECH, Granada, Spain, 14–16 November 2022; pp. 41–45. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented Transformer for Speech Recognition. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 5036–5040. [Google Scholar]
- Salesky, E.; Wiesner, M.; Bremerman, J.; Cattoni, R.; Negri, M.; Turchi, M.; Oard, D.; Post, M. The Multilingual TEDx Corpus for Speech Recognition and Translation. In Proceedings of the Interspeech, Brno, Czech Republic, 30 August–3 September 2021; pp. 3655–3659. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Kohler, M.; Meyer, J.; Henretty, M.; Morais, R.; Saunders, L.; Tyers, F.; Weber, G. Common Voice: A Massively-Multilingual Speech Corpus. In Proceedings of the LREC, Online, 20–25 June 2020; pp. 4218–4222. [Google Scholar]
- Pratap, V.; Xu, Q.; Sriram, A.; Synnaeve, G.; Collobert, R. MLS: A Large-Scale Multilingual Dataset for Speech Research. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 2757–2761. [Google Scholar]
- Turk, M.; Pentland, A. Face recognition using eigenfaces. In Proceedings of the CVPR, Maui, HI, USA, 3–6 June 1991; pp. 586–587. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Soplin, N.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-to-End Speech Processing Toolkit. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2207–2211. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the CVPR, Online, 14–19 June 2020; pp. 5202–5211. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. How Far are We from Solving the 2D & 3D Face Alignment Problem? (and a Dataset of 230,000 3D Facial Landmarks). In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; pp. 1021–1030. [Google Scholar]
- Zhang, Y.; Yang, S.; Xiao, J.; Shan, S.; Chen, X. Can We Read Speech Beyond the Lips? Rethinking RoI Selection for Deep Visual Speech Recognition. In Proceedings of the 15th IEEE FG, Buenos Aires, Argentina, 16–20 November 2020; pp. 356–363. [Google Scholar]
- Park, D.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.; Le, Q. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Smith, L.; Topin, N. Super-convergence: Very fast training of neural networks using large learning rates. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, San Jose, CA, USA, 24–28 February 2019; Volume 11006, pp. 36–386. [Google Scholar]
- Ott, M.; Edunov, S.; Grangier, D.; Auli, M. Scaling Neural Machine Translation. In Proceedings of the 3rd Conference on Machine Translation, Brussels, Belgium, 31 October–1 November 2018; pp. 1–9. [Google Scholar]
- Bisani, M.; Ney, H. Bootstrap estimates for confidence intervals in ASR performance evaluation. In Proceedings of the ICASSP, Seoul, Republic of Korea, 14–19 April 2004; Volume 1, pp. 409–412. [Google Scholar]
- Higuchi, Y.; Watanabe, S.; Chen, N.; Ogawa, T.; Kobayashi, T. Mask CTC: Non-Autoregressive End-to-End ASR with CTC and Mask Predict. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 3655–3659. [Google Scholar]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- He, Y.; Sainath, T.; Prabhavalkar, R.; McGraw, I.; Álvarez, R.; Zhao, D.; Rybach, D.; Kannan, A.; Wu, Y.; Pang, R.; et al. Streaming End-to-end Speech Recognition for Mobile Devices. In Proceedings of the ICASSP, Brighton, UK, 12–17 May 2019; pp. 6381–6385. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Adapter Size | 8 | 16 | 32 | 64 | 128 | 256 |
| Learnable Parameters | 0.15% | 0.27% | 0.52% | 1.02% | 2.02% | 4.02% |
| Fine-Tuning Strategy | Data Set | |
|---|---|---|
| DEV | TRAIN | |
| MST | 59.6 ± 1.3 | 36.4 ± 1.3 |
| SAT | 52.2 ± 1.4 | 29.1 ± 1.5 |
| TS-SAT | 32.8 ± 1.3 | 24.9 ± 1.4 |
| Method | % WER | Training Time | Storage |
|---|---|---|---|
| TS-SAT | 24.9 ± 1.4 | 78.1 | 4.2 |
| Best Adapter | 32.9 ± 1.3 | 13.6 | 0.611 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gimeno-Gómez, D.; Martínez-Hinarejos, C.-D. Comparing Speaker Adaptation Methods for Visual Speech Recognition for Continuous Spanish. Appl. Sci. 2023, 13, 6521. https://doi.org/10.3390/app13116521
Gimeno-Gómez D, Martínez-Hinarejos C-D. Comparing Speaker Adaptation Methods for Visual Speech Recognition for Continuous Spanish. Applied Sciences. 2023; 13(11):6521. https://doi.org/10.3390/app13116521
Chicago/Turabian StyleGimeno-Gómez, David, and Carlos-D. Martínez-Hinarejos. 2023. "Comparing Speaker Adaptation Methods for Visual Speech Recognition for Continuous Spanish" Applied Sciences 13, no. 11: 6521. https://doi.org/10.3390/app13116521
APA StyleGimeno-Gómez, D., & Martínez-Hinarejos, C. -D. (2023). Comparing Speaker Adaptation Methods for Visual Speech Recognition for Continuous Spanish. Applied Sciences, 13(11), 6521. https://doi.org/10.3390/app13116521