
Research on a Rolling Bearing Fault Diagnosis Method Based on Multi-Source Deep Sub-Domain Adaptation

Abstract
:1. Introduction
2. Fundamental Theory
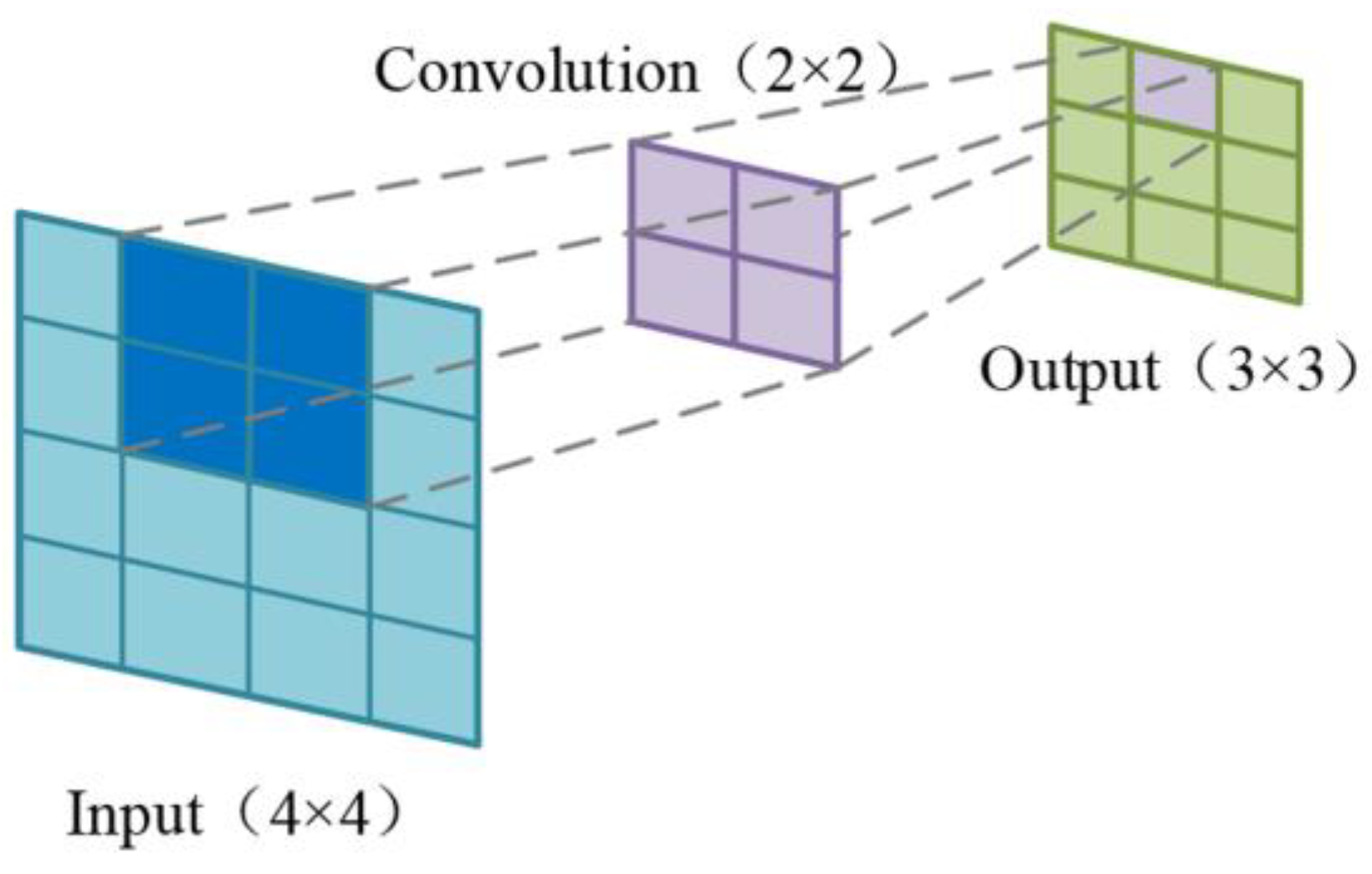
2.1. Convolutional Neural Network
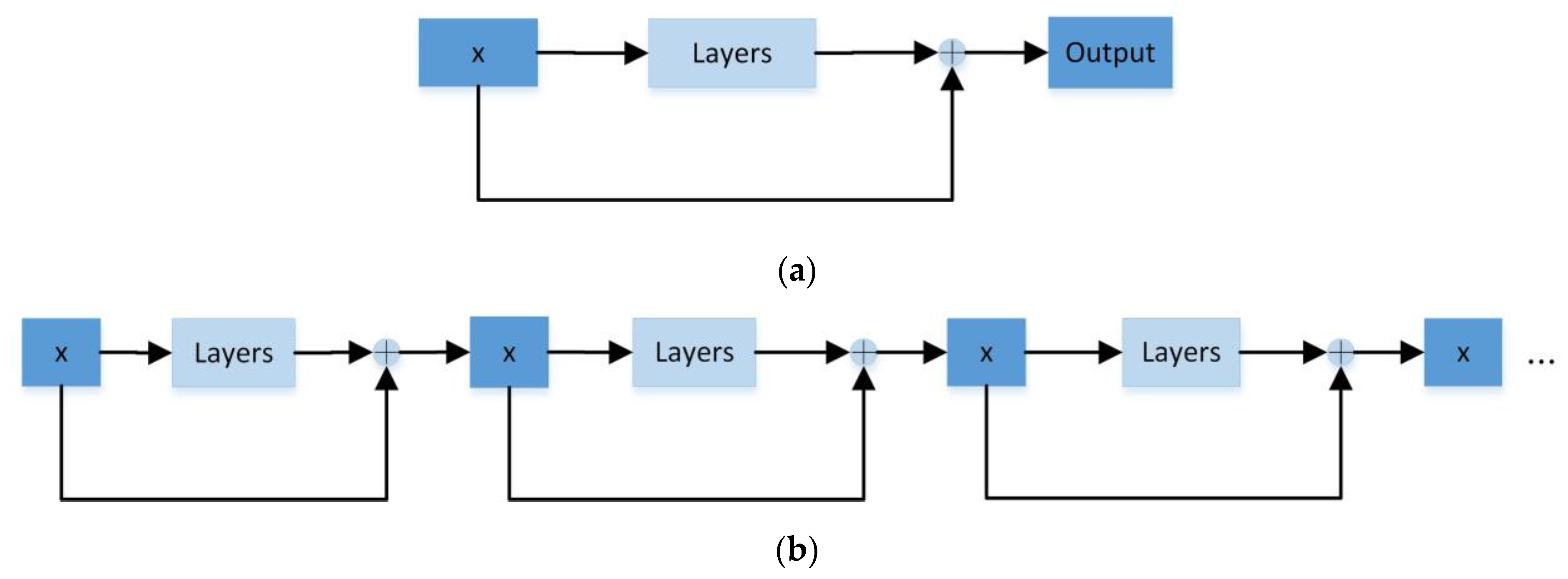
2.2. Deep Residual Network
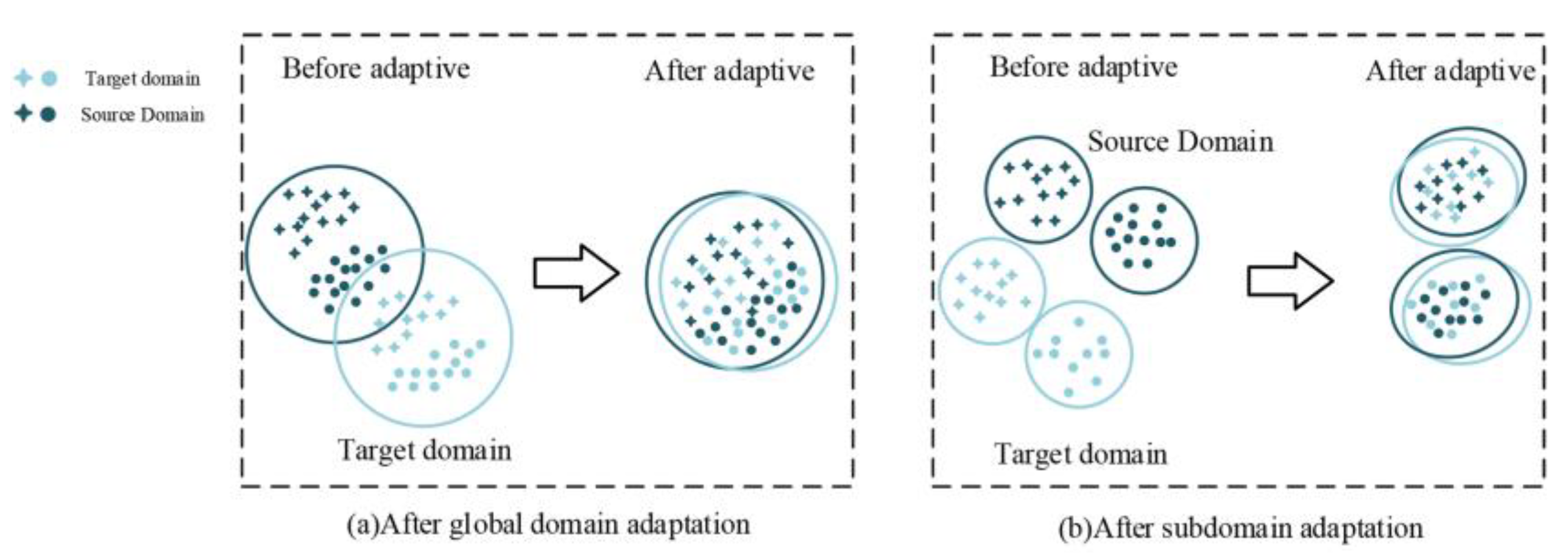
2.3. Domain Distribution Difference Measure
2.4. Optimal Algorithm
3. Multi-Source Subdomain Adaptation Model
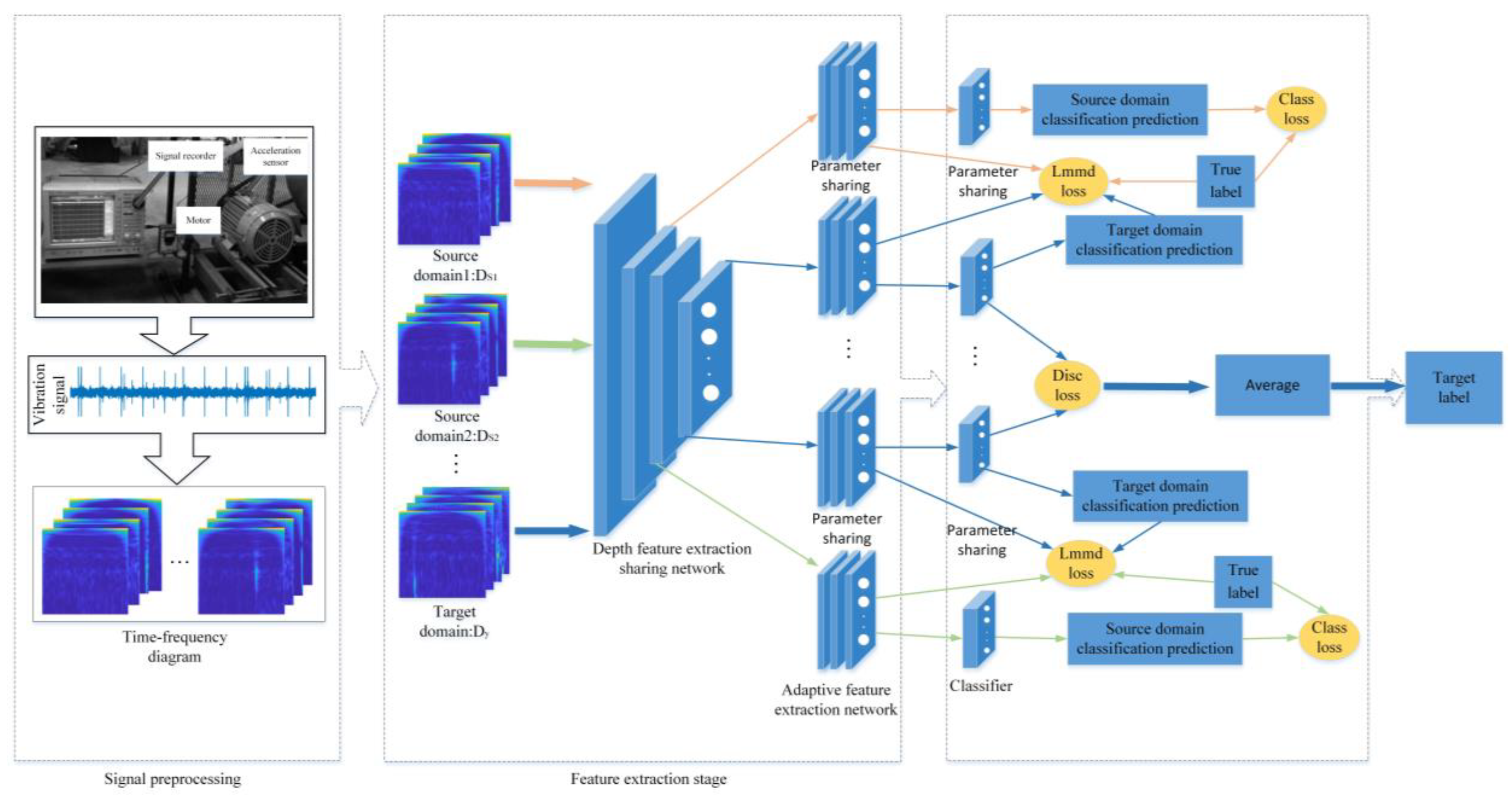
3.1. The Structure of the Model
- (1)
- Signal preprocessing: The bearing vibration signal of Jiangnan University is sampled by an overlapping sampling method to increase the number of samples. Continuous wavelet transform is performed on each type of signal sample using CMOR wavelet to obtain a time–frequency diagram. Meanwhile, source–target data pairs are constructed.
- (2)
- Feature extraction network: The network consists of shared and domain-specific feature extraction networks. First, the data are extracted using a shared feature extraction network. Then, the specific feature extraction network is used to extract the specific features for each group of data.
- (3)
- Network optimization: The total training loss function of the network consists of three parts. In this paper, the local maximum mean difference metric loss function is selected to reduce the distribution difference in each group of data pairs, so that the network can better learn the domain invariant representation. Each group of specific feature extraction networks can extract the domain invariant representation of each pair of source domain and target domain by minimizing losslmmd. N classifiers are trained using labeled source domain data, and the cross-entropy loss between the actual label and the predicted label in the source domain is calculated. Each group of classifiers corresponds to the corresponding lossclass. The loss function lossdisc is used to minimize the error between all classifiers and reduce the classification error near the target domain class boundary. The network training process uses the Ranger optimizer to reduce the total training loss function value.
- (4)
- State recognition: Target domain data are input into the trained network and the diagnostic results are output.
3.2. Continuous Wavelet Transform
3.3. Shared Feature Extraction Network
3.4. Local Maximum Mean Discrepancy
3.5. Ranger Optimization Algorithm
3.6. Network Optimization
- Minimize the classification loss function, lossclass, of the source domain dataset;
- Minimize the difference loss, lossdisc, between different classifiers;
- Minimize the domain invariant, losslmmd, of the source and target domain datasets.
4. Experiments and Analysis
4.1. Experimental Data
4.2. Comparative Analysis of the Results of Different Domain Adaptation Methods
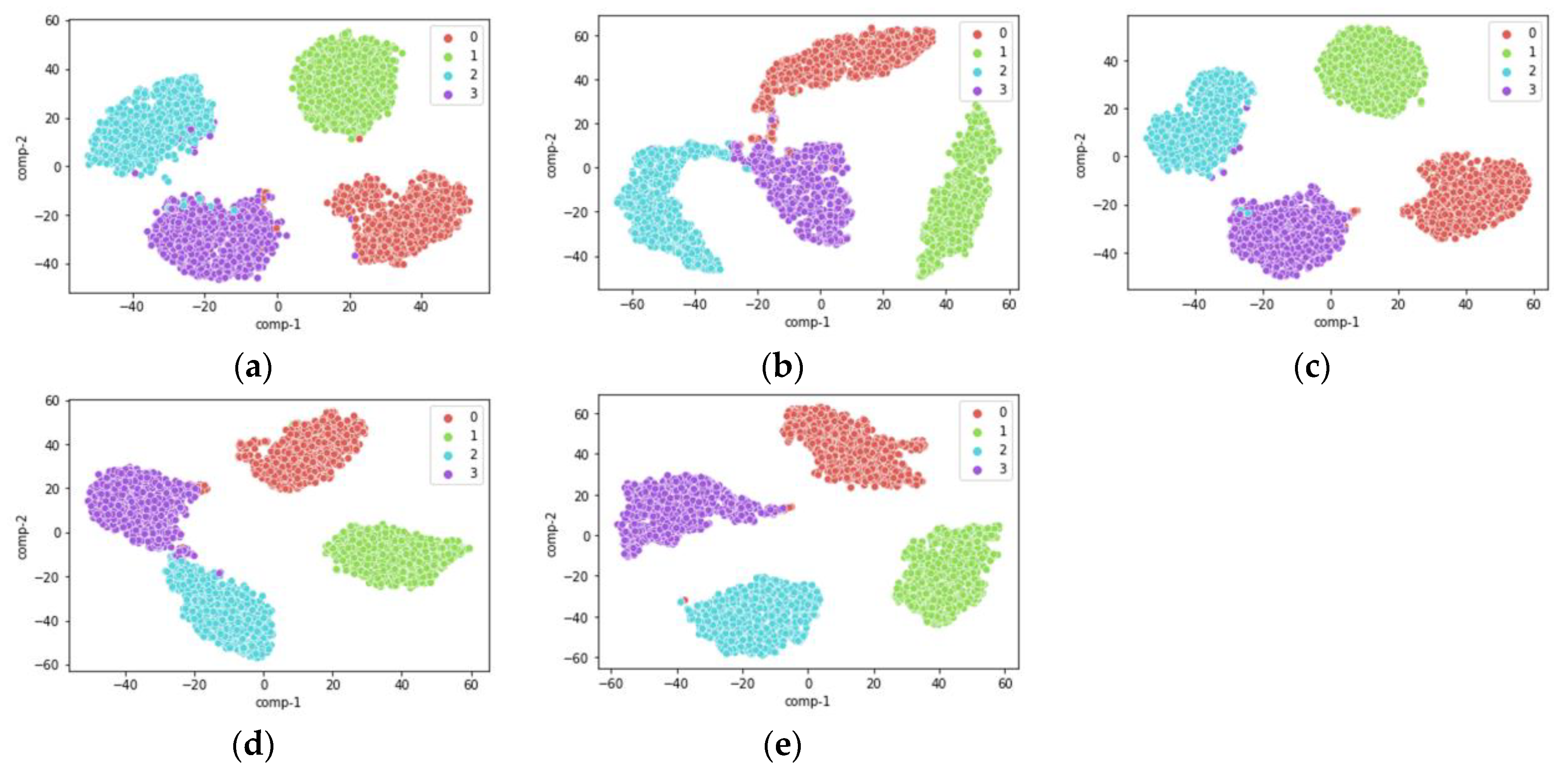
4.2.1. Visual Comparative Analysis of Output Features
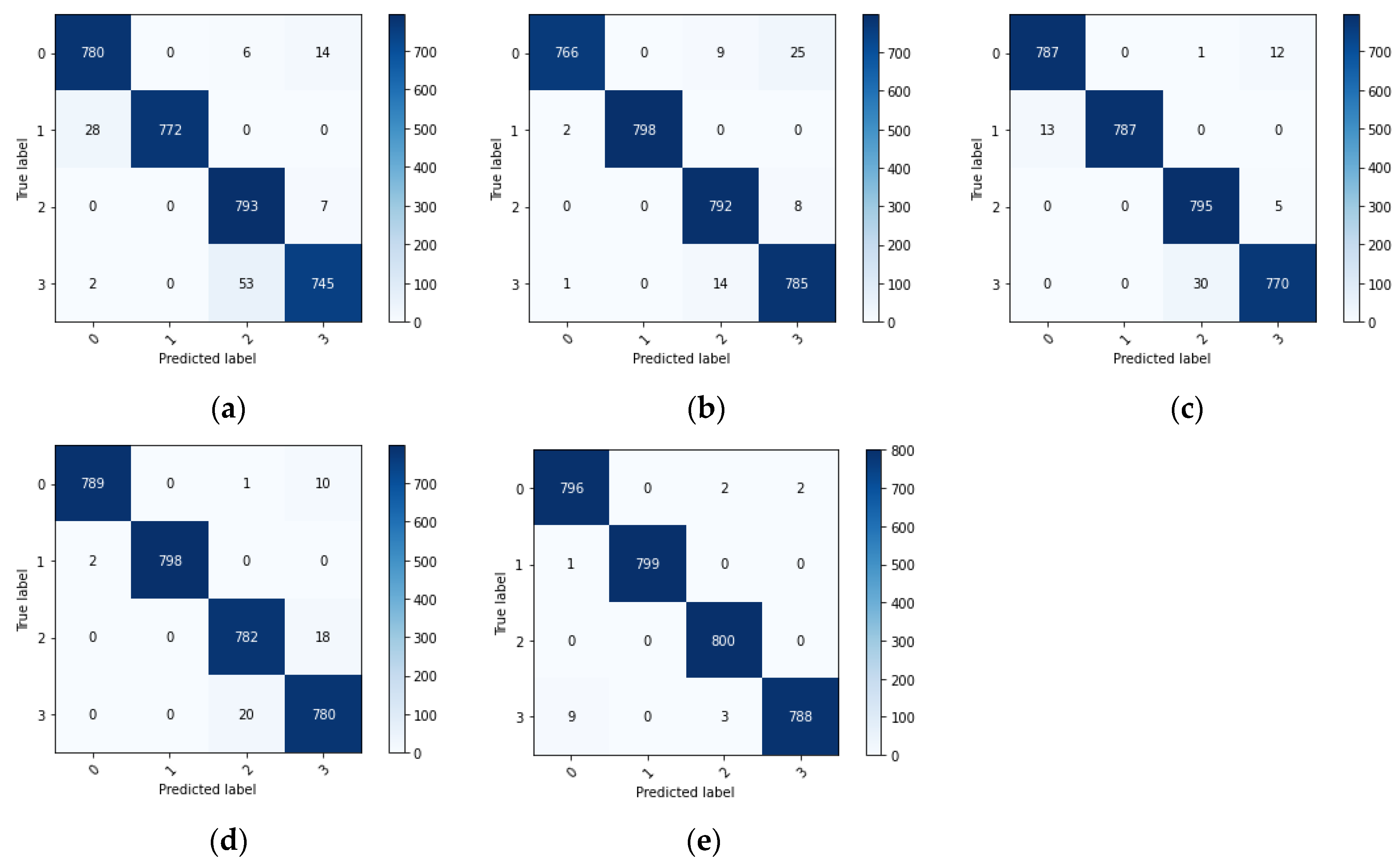
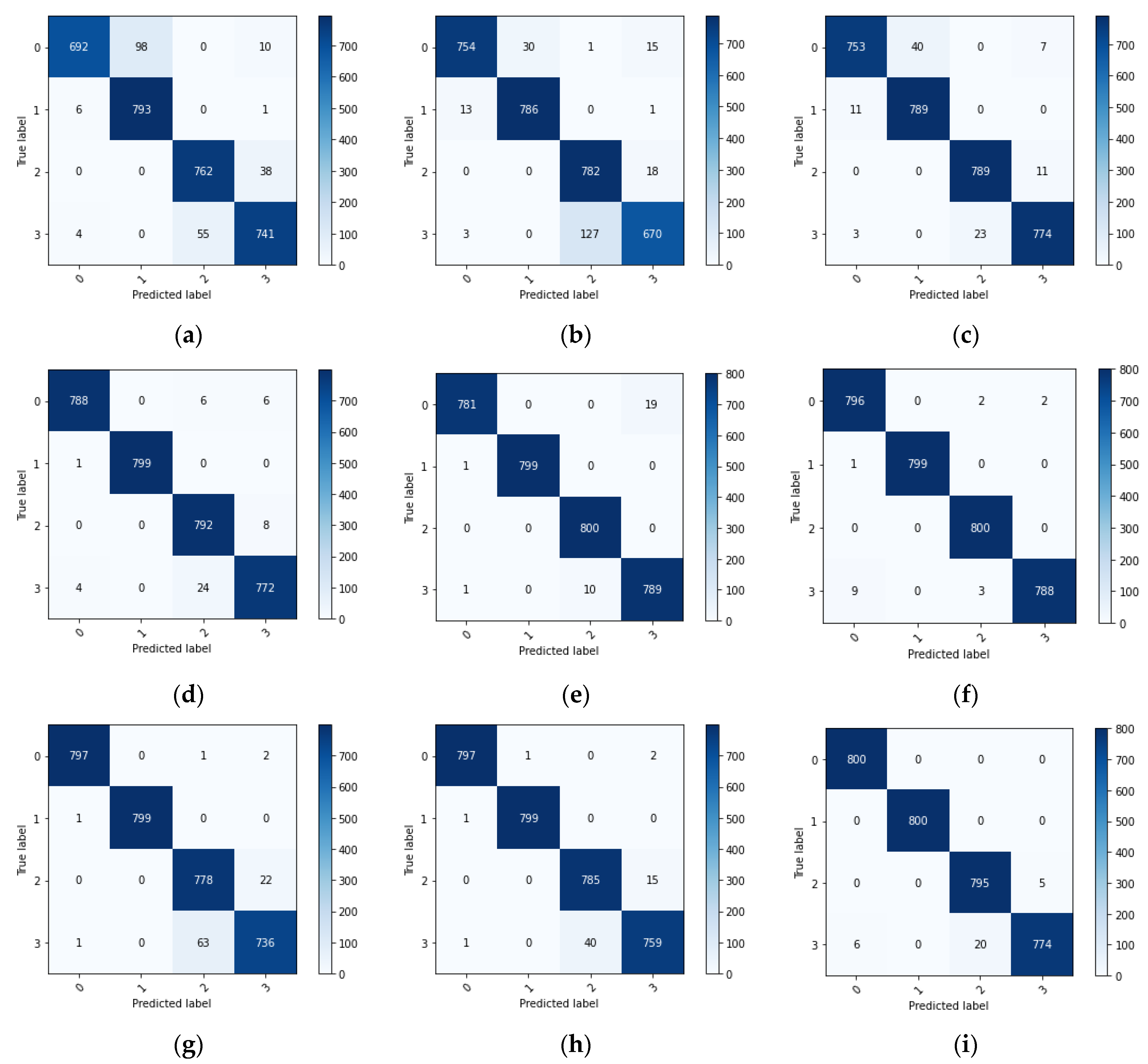
4.2.2. Comparative Analysis of Diagnostic Results
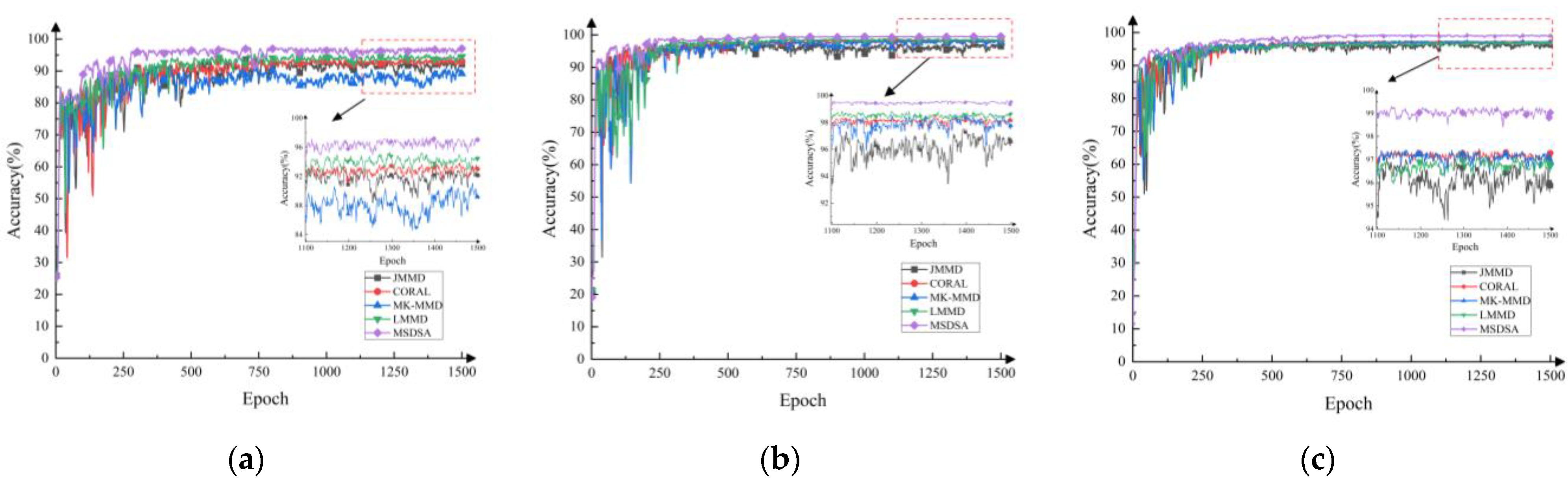
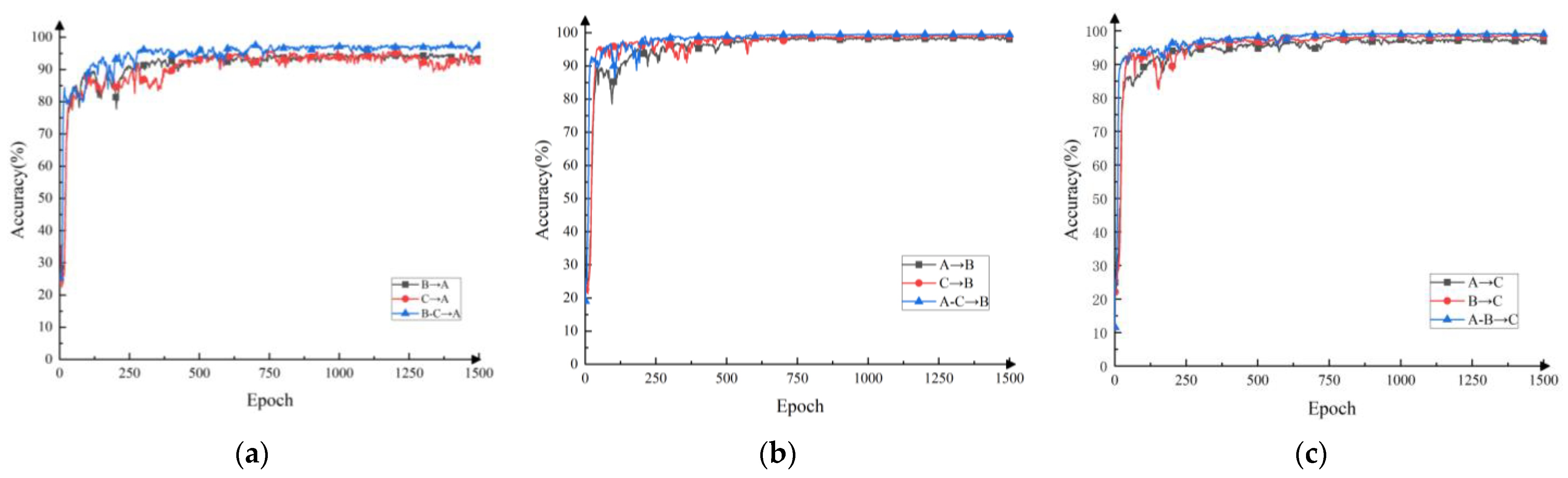
4.2.3. Comparative Analysis of Diagnostic Accuracy and Change Curve
4.3. Comparative Analysis of Single-Source Domain and Multi-Source Domain Transfer Learning Task Results
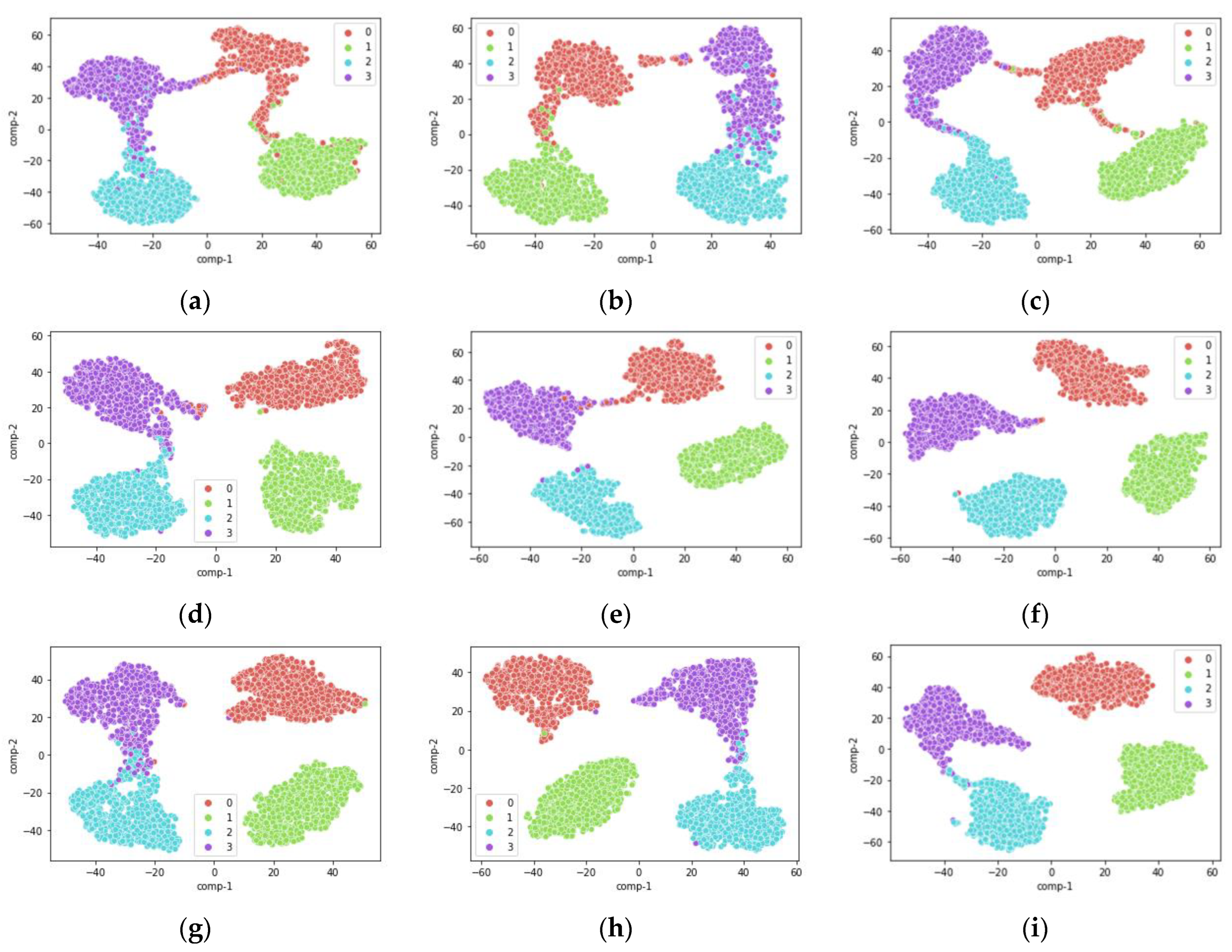
4.3.1. Visual Comparative Analysis of Output Features
4.3.2. Comparative Analysis of Diagnostic Results
4.3.3. Comparative Analysis of Diagnostic Accuracy and Change Curve
5. Discussion
6. Conclusions
- (1)
- The subdomain adaptive method can better align the distribution difference between the source domain and the target domain;
- (2)
- Using multi-source domain learning can extract richer information;
- (3)
- Using the Ranger optimizer instead of a mainstream optimizer can further improve the accuracy of network training.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xiao, Q.; Li, S.; Zhou, L.; Shi, W. Improved variational mode decomposition and CNN for intelligent rotating machinery fault diagnosis. Entropy 2022, 24, 908. [Google Scholar] [CrossRef] [PubMed]
- Han, T.; Li, Y.-F.; Qian, M. A hybrid generalization network for intelligent fault diagnosis of rotating machinery under unseen working conditions. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- Jin, J.; Xu, Z.; Li, C.; Zhou, L.; Miao, W. Research on fault diagnosis of rolling bearings based on deep learning and support vector machine. Therm. Power Eng. 2022, 37, 176–184. [Google Scholar] [CrossRef]
- Yang, S.; Kong, X.; Wang, Q.; Li, Z.; Cheng, H.; Yu, L. A multi-source ensemble domain adaptation method for rotary machine fault diagnosis. Measurement 2021, 186, 110213. [Google Scholar] [CrossRef]
- Junbo, T.; Weining, L.; Juneng, A.; Xueqian, W. Fault diagnosis method study in roller bearing based on wavelet transform and stacked auto-encoder. In Proceedings of the 27th Chinese control and decision conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 4608–4613. [Google Scholar]
- Shao, S.; McAleer, S.; Yan, R.; Baldi, P. Highly accurate machine fault diagnosis using deep transfer learning. IEEE Trans. Ind. Inform. 2018, 15, 2446–2455. [Google Scholar] [CrossRef]
- Yan, R.; Shen, F.; Sun, C.; Chen, X. Knowledge transfer for rotary machine fault diagnosis. IEEE Sens. J. 2019, 20, 8374–8393. [Google Scholar] [CrossRef]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Feng, W.; Shen, Z. Balanced distribution adaptation for transfer learning. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; pp. 1129–1134. [Google Scholar]
- Zhu, J.; Chen, N.; Shen, C. A new deep transfer learning method for bearing fault diagnosis under different working conditions. IEEE Sens. J. 2019, 20, 8394–8402. [Google Scholar] [CrossRef]
- Qian, W.; Li, S.; Yi, P.; Zhang, K. A novel transfer learning method for robust fault diagnosis of rotating machines under variable working conditions. Measurement 2019, 138, 514–525. [Google Scholar] [CrossRef]
- Cheng, C.; Zhou, B.; Ma, G.; Wu, D.; Yuan, Y. Wasserstein distance based deep adversarial transfer learning for intelligent fault diagnosis with unlabeled or insufficient labeled data. Neurocomputing 2020, 409, 35–45. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Wang, X.; He, H.; Li, L. A hierarchical deep domain adaptation approach for fault diagnosis of power plant thermal system. IEEE Trans. Ind. Inform. 2019, 15, 5139–5148. [Google Scholar] [CrossRef]
- Duan, L.; Xu, D.; Tsang, I.W.-H. Domain adaptation from multiple sources: A domain-dependent regularization approach. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 504–518. [Google Scholar] [CrossRef]
- Liu, H.; Shao, M.; Fu, Y. Structure-preserved multi-source domain adaptation. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 1059–1064. [Google Scholar]
- Mansour, Y.; Mohri, M.; Rostamizadeh, A. Domain adaptation with multiple sources. Adv. Neural Inf. Process. Syst. 2008, 21, 1041–1048. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, D. Aligning domain-specific distribution and classifier for cross-domain classification from multiple sources. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; pp. 5989–5996. [Google Scholar]
- Rezaeianjouybari, B.; Yi, S. A Novel Deep Multi-Source Domain Adaptation Framework for Bearing Fault Diagnosis Based on Feature-level and Task-specific Distribution Alignment. Measurement 2021, 178, 109359. [Google Scholar] [CrossRef]
- Zhan, K. A CNN-LSTM ship motion extreme value prediction model. Shanghai Jiaotong Univ. 2022, 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2208–2217. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep subdomain adaptation network for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1713–1722. [Google Scholar] [CrossRef] [PubMed]
- Song, L. Research on Fault Diagnosis Methods Based on Attention Mechanism and Deep Learning. Master’s Thesis, Southwest University of Science and Technology, Mianyang, China, 2021. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Zhang, M.; Lucas, J.; Ba, J.; Hinton, G.E. Lookahead optimizer: K steps forward, 1 step back. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 9597–9608. [Google Scholar]
- Xu, R.; Chen, Z.; Zuo, W.; Yan, J.; Lin, L. Deep cocktail network: Multi-source unsupervised domain adaptation with category shift. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3964–3973. [Google Scholar]
- Li, K. Available online: http://www.52phm.cn/blog/detail/52 (accessed on 2 February 2023).
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10, 15–16 October 2016; pp. 443–450. [Google Scholar]
- Braun, S. LSTM benchmarks for deep learning frameworks. arXiv 2018, arXiv:1806.01818. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Kim, B.; Kim, D.H.; Park, S.H.; Kim, J.; Lee, J.-G.; Ye, J.C. CycleMorph: Cycle consistent unsupervised deformable image registration. Med. Image Anal. 2021, 71, 102036. [Google Scholar] [CrossRef]
- Yang, B.; Xu, S.; Lei, Y.; Lee, C.-G.; Stewart, E.; Roberts, C. Multi-source transfer learning network to complement knowledge for intelligent diagnosis of machines with unseen faults. Mech. Syst. Signal Process. 2022, 162, 108095. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Structure | Network Parameter |
|---|---|
| Feature extraction network | ResNet50(share)- Conv (2048,256)-Bn()- Conv (256,256)-Bn()-Conv(256,256)-Bn()-ReLU() |
| Classifier | Linear(256,4) |
| Network Structure | Type | Receptive Field Size |
|---|---|---|
| Input | 224 × 224 × 3 | |
| Con1 | Convolution layer | |
| Max pool | Maximum pooling layer | |
| Conv2_x | Residual block 1 × 3 | |
| Conv3_x | Residual block 1 × 4 | |
| Conv4_x | Residual block 1 × 6 | |
| Conv5_x | Residual block 1 × 3 | |
| Average | Average pooling layer |
| Dataset | State of Health | Rotating Speed(R/Min) | Label | Sample Size |
|---|---|---|---|---|
| A | Normal | 600 | 0 | 800 |
| A | Inner ring fault | 600 | 1 | 800 |
| A | Outer ring fault | 600 | 2 | 800 |
| A | Rolling element fault | 600 | 3 | 800 |
| B | Normal | 800 | 0 | 800 |
| B | Inner ring fault | 800 | 1 | 800 |
| B | Outer ring fault | 800 | 2 | 800 |
| B | Rolling element fault | 800 | 3 | 800 |
| C | Normal | 1000 | 0 | 800 |
| C | Inner ring fault | 1000 | 1 | 800 |
| C | Outer ring fault | 1000 | 2 | 800 |
| C | Rolling element fault | 1000 | 3 | 800 |
| Adaptive Method | JMMD | CORAL | MK-MMD | LMMD | MSDSA | Increase Percentage (%) | |
|---|---|---|---|---|---|---|---|
| Test | |||||||
| B-C→A | 93.87% | 94.00% | 89.34% | 95.37% | 97.40% | 2.03–8.06% | |
| A-C→B | 97.81% | 98.53% | 98.75% | 98.81% | 99.65% | 0.84–1.84% | |
| A-B→C | 97.03% | 97.47% | 97.50% | 97.37% | 99.34% | 1.84–2.31% | |
| Average | 96.24% | 96.67% | 95.20% | 97.18% | 98.80% | 1.62–3.6% | |
| Task | Accuracy | Task | Accuracy | Increase Percentage (%) |
|---|---|---|---|---|
| B-C→A | 97.78% | B→A C→A | 95.09% 96.13% | 2.69% 1.65% |
| A-C→B | 99.65% | A→B C→B | 98.72% 99.28% | 0.93% 0.37% |
| A-B→C | 99.34% | A→C B→C | 97.85% 98.84% | 1.49% 0.50% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, F.; Wang, L.; Zhu, H.; Xie, S. Research on a Rolling Bearing Fault Diagnosis Method Based on Multi-Source Deep Sub-Domain Adaptation. Appl. Sci. 2023, 13, 6800. https://doi.org/10.3390/app13116800
Xie F, Wang L, Zhu H, Xie S. Research on a Rolling Bearing Fault Diagnosis Method Based on Multi-Source Deep Sub-Domain Adaptation. Applied Sciences. 2023; 13(11):6800. https://doi.org/10.3390/app13116800
Chicago/Turabian StyleXie, Fengyun, Linglan Wang, Haiyan Zhu, and Sanmao Xie. 2023. "Research on a Rolling Bearing Fault Diagnosis Method Based on Multi-Source Deep Sub-Domain Adaptation" Applied Sciences 13, no. 11: 6800. https://doi.org/10.3390/app13116800
APA StyleXie, F., Wang, L., Zhu, H., & Xie, S. (2023). Research on a Rolling Bearing Fault Diagnosis Method Based on Multi-Source Deep Sub-Domain Adaptation. Applied Sciences, 13(11), 6800. https://doi.org/10.3390/app13116800