


Joint Deployment Optimization of Parallelized SFCs and BVNFs in Multi-Access Edge Computing

Abstract
:1. Introduction
- We propose a new approach to enhance the reliability of P-SFCs and reduce the deployment number of idle BVNFs. Then, we model the dynamics of delay and reliability caused by the deployment of P-SFCS and BVNFs and formulate the throughput maximization problem;
- We design an approximation algorithm to find a near-optimal solution. It defines delay-reduction priority and reliability-enhancement priority to identify the critical VNF in SFC and designs two schemes to deploy P-SFCs and BVNFs and steer user requests traversing these VNF instances;
- To evaluate the effectiveness of our proposed algorithm, we conduct extensive simulation experiments based on real-world datasets from the central business district of Melbourne, Australia. Experimental results show that compared to two benchmark algorithms (see Section 5), our proposed algorithm can significantly decrease the delay and increase throughput while improving resource utilization.
2. Recent Works
2.1. Joint Deployment of SFC and BVNFs without Parallelization
2.2. Joint Deployment of SFC and BVNFs with Parallelization
2.3. Our Research
3. System Model and Problem Statement
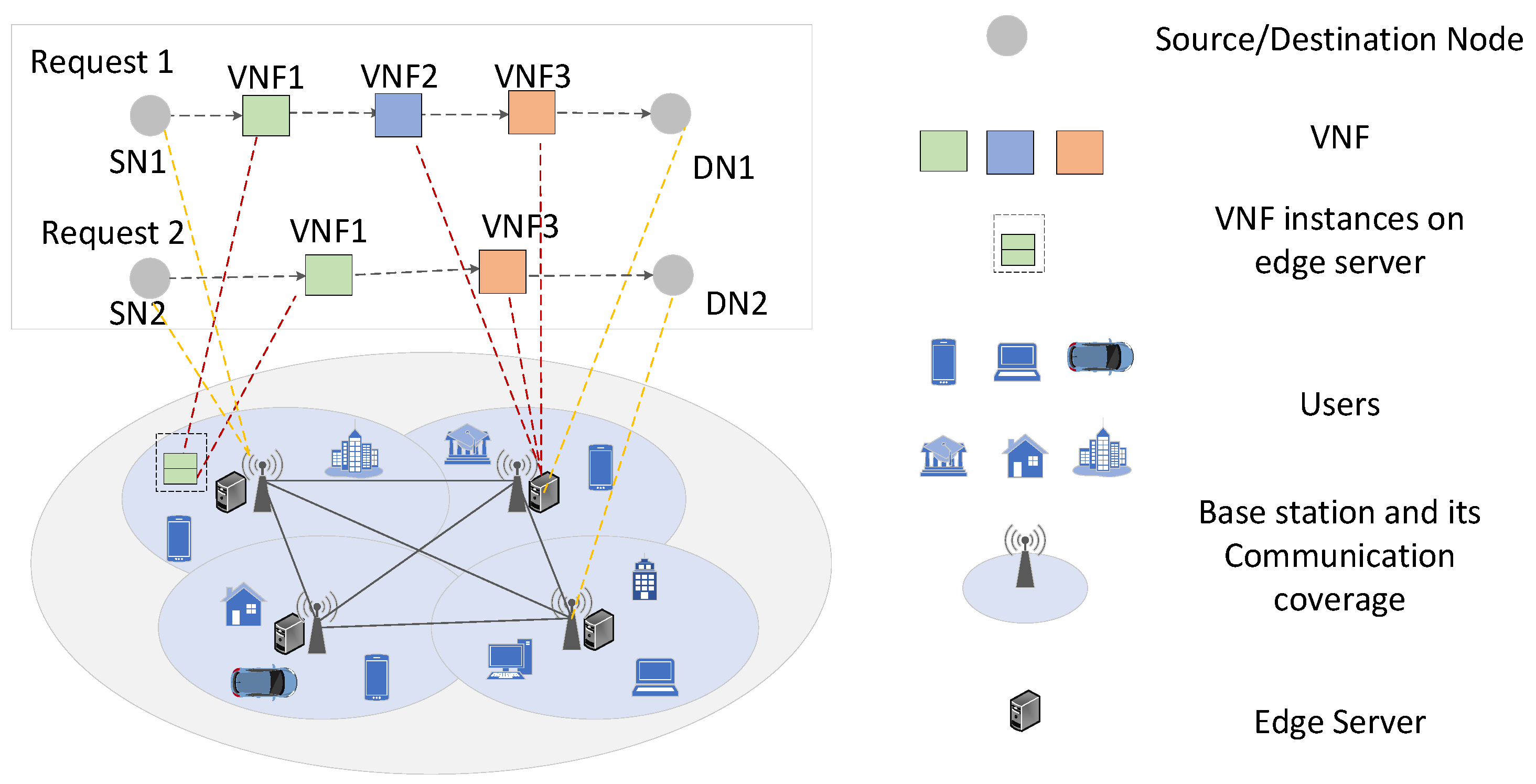
3.1. Network Topology
3.2. P-SFCs and BVNFs Deployment
3.3. Problem Statement
4. Proposed Solution
4.1. Throughput Maximization Algorithm
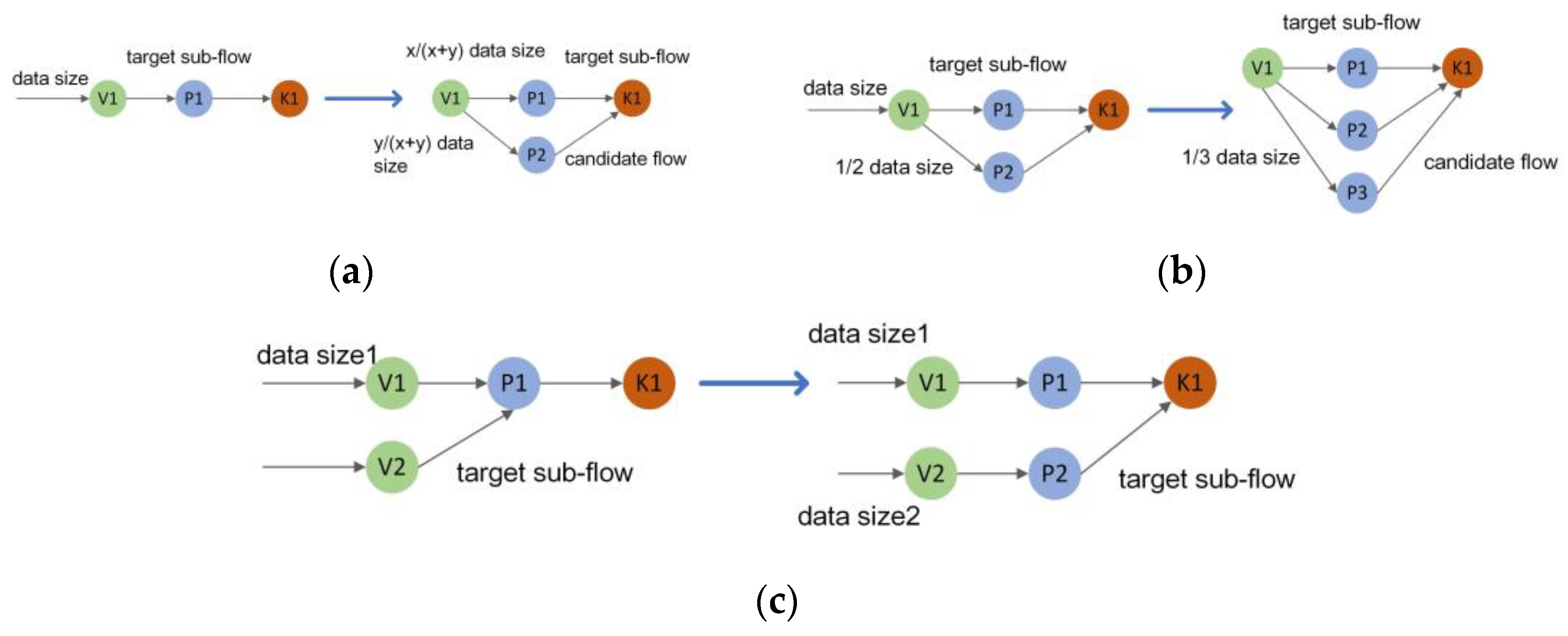
- If has the highest priority and the number of parallel instances does not exceed the maximum number of sub-flows, we select as the critical VNF to obtain the high potential of delay reduction by deploying parallel VNF instances of . In reverse, we select the next VNF with high priority as the critical VNF. The next step is to find a target sub-flow and split it into smaller sub-flows;
- Then, we sort all sub-flows of user requests by the delay of sub-flows traversing from the previous server to the current server and from the current server to the next edge server. We select the sub-flow with the maximum delay as the target sub-flow. Next, we record the previous server, current server, and next server that were traversed by the target sub-flow. We also record the communication distance to traverse these three servers as the target communication distance. The next step finds all feasible edge servers;
- Next, we define a set of edge servers that deploy instances traversed by the user request as a comparison set. Then, we select edge servers whose resource capacity exceeds resource demand from all edge servers except for edge servers in the comparison set. This operation ensures that the target sub-flow is split into two sub-flows and traverses different paths to decrease delay. Next, we insert these edge servers into a candidate set and record the transmission and processing capacities of different paths from the previous server to these edge servers and from these edge servers to the next server. Next, we find the target edge server to deploy a parallel VNF instance;
- Then, we select the edge server with the highest capacity as the target server and define the flow that traverses it as the candidate flow. The next step splits and merges sub-flows to reduce delay;
- To decrease delay, we split the target sub-flow into two sub-flows according to their transmission and processing capacities. We do not evenly split the size of the user request between all sub-flows and the candidate flow or the size of the target sub-flow between the target sub-flow and the candidate flow. Although the former can significantly reduce delay, it affects the delay and reliability of subsequent VNFs. The latter does not guarantee delay reduction if the communication distance of the candidate flow is too large.
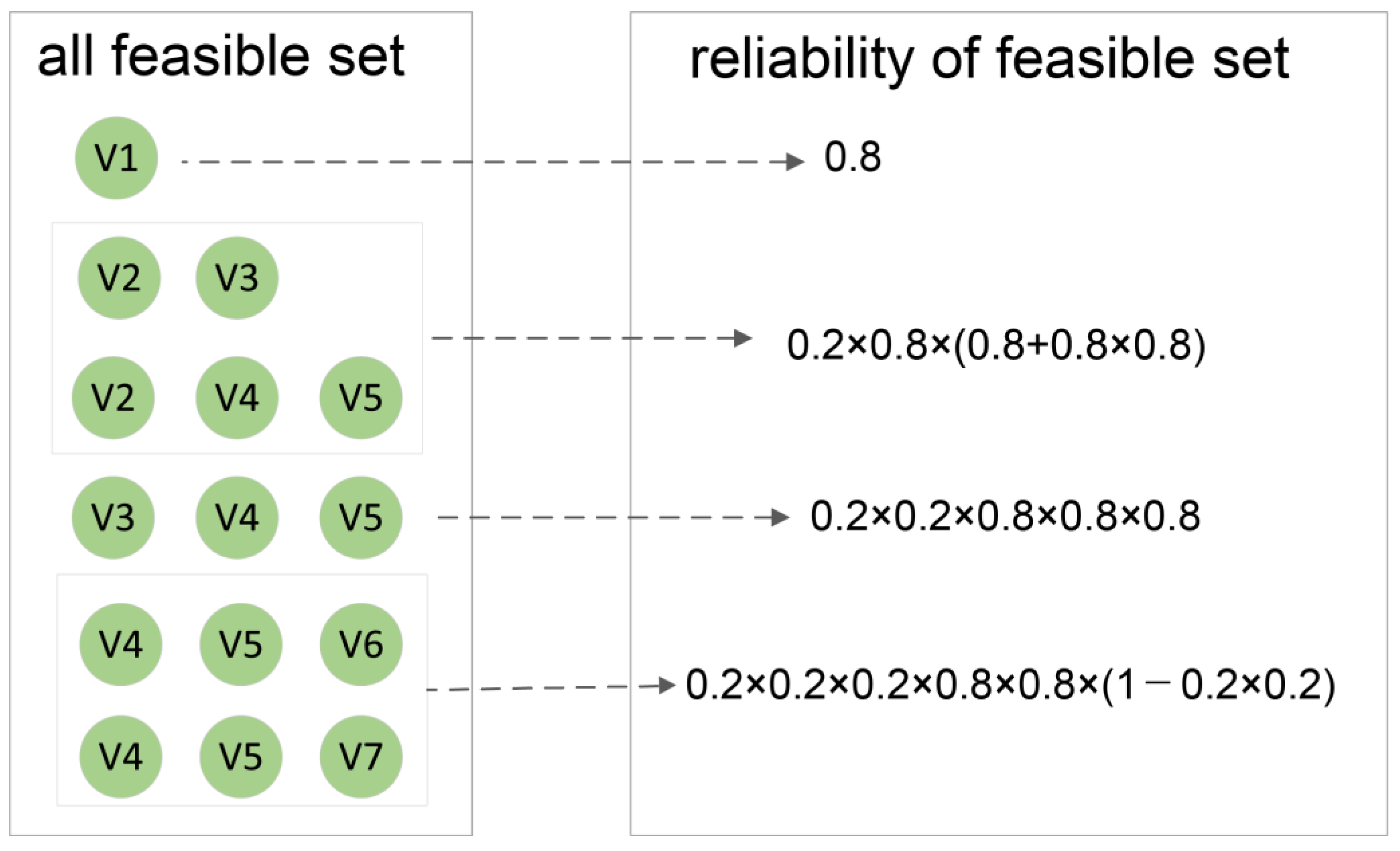
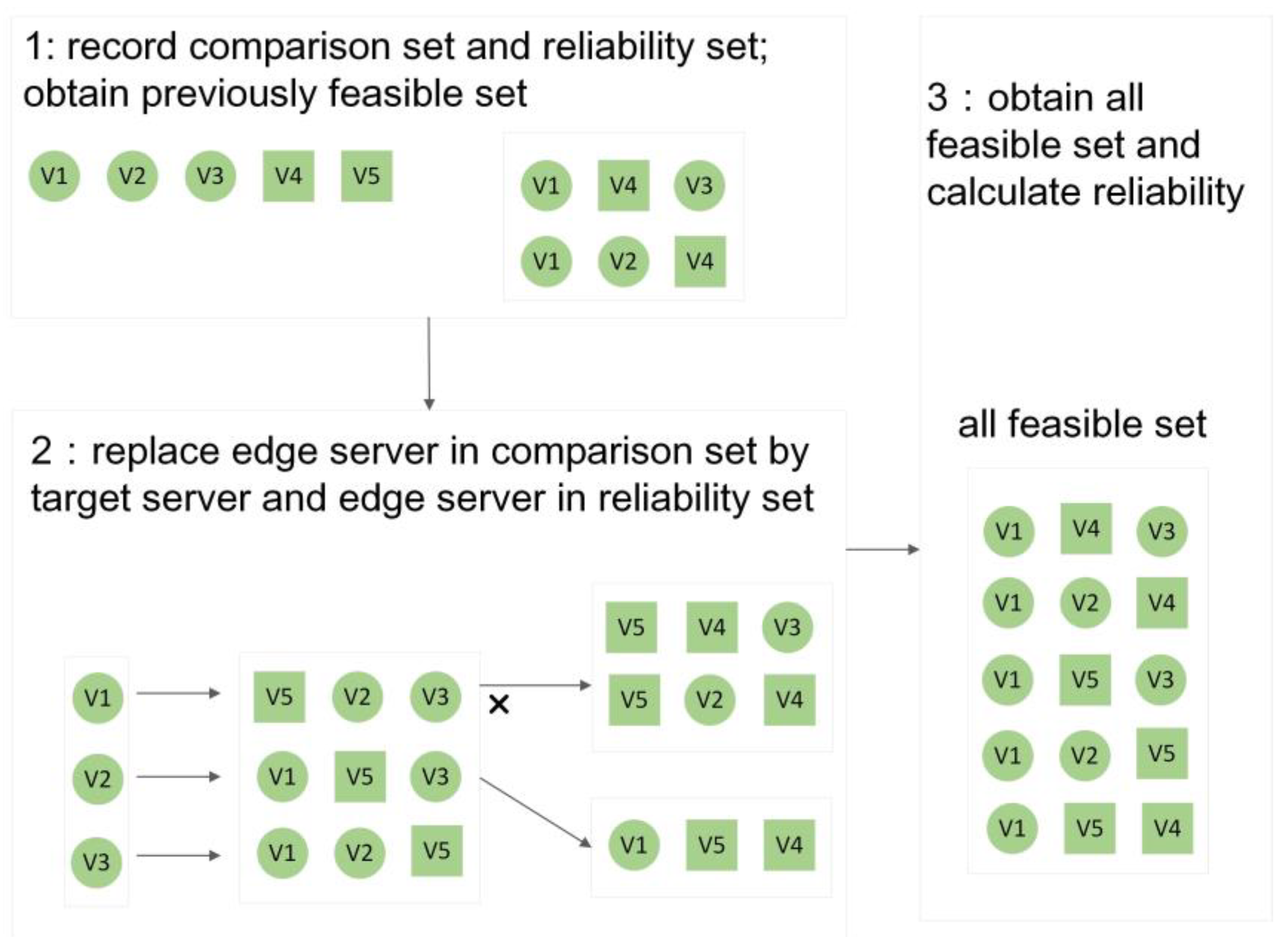
- If has the highest priority and the number of parallel instances does not exceed the maximum number of sub-flows, we select as the critical VNF to obtain a high potential of reliability enhancement by deploying parallel VNF instances of [25,34]. In reverse, we select the next VNF with high priority as the critical VNF. We execute the above steps 2–3 to find the target sub-flow and all feasible edge servers. Then, we sort feasible edge servers by their transmission and processing capacities. We record the comparison set that satisfies the delay requirement and the reliability set that consists of all edge servers which deploy parallel instances used to enhance reliability. The next step is to find the target edge server to deploy parallel VNF instances;
- Then, we define the feasible edge server with the highest capacity as the selected edge server. Next, we calculate the end-to-end delay when replacing one edge server in the comparison set one by one with the selected edge server. If the end-to-end delay satisfies the delay requirement, we replace other edge servers in the comparison set one by one with the edge server in the reliability set. Then, if the end-to-end delay satisfies the delay requirement, we record the selected edge server and other edge servers as a feasible set and the number of all feasible sets. If the number exceeds the length of the comparison set, we define the selected server as the target server and the flow that traverses it as the candidate flow. In reverse, we select the next edge server with high priority as the selected edge server. Then, we execute the above step 5 to split and merge the target sub-flow.
| Algorithm 1 Throughput Maximization Algorithm |
| Input: Output: ; 1: = 0; 2: FOR all DO 3: Calculate P[] by Dijkstra algorithm; 4: END FOR 5: FOR all , DO 6: Calculate D[][] and find the nearest base station for ; 7: END FOR 8: FOR all DO 9: FOR all DO 10: Find the edge server with the lowest transmission distance; 11: IF THEN 12: Deploy one instance in ; 13: Calculate the delay and reliability of ; 14: END IF 15: END FOR 16: WHILE the delay of DO 17: Execute the delay-reduction scheme; 18: IF all THEN 19: Drop ; 20: Release all resources of ; 21: BREAK; 22: END IF 23: END WHILE 24: IF the delay of DO 25: WHILE the reliability of DO 26: Execute the reliability-enhancement scheme; 27: IF all ||>= THEN 28: Find with the highest priority; 29: Find server with the lowest communication distance; 30: IF THEN 31: Deploy one backup instance in ; 32: Calculate the delay and reliability of ; 33: ELSE 34: BREAK; 35: END IF 36: END IF 37: END WHILE 38: END IF 39: IF the delay of && >= Ri DO 40: A = A + 1; 41: END IF 42: END FOR 43: Return ; |
4.2. Complexity Analysis
5. Performance Evaluation
- The Joint Deployment algorithm of P-SFCs and BVNFs with Static Reliability (SRPD): this algorithm deploys parallel VNF instances only to decrease delay. Then, it deploys BVNF instances to satisfy the reliability requirement. The reliability of parallel VNF instances is the product of the reliability of all VNF instances;
- The Joint Deployment algorithm of P-SFCs and BVNFs for Decreasing BVNFs (DBPD): this algorithm deploys parallel VNF instances only to decrease delay and enhance reliability for decreasing BVNFs. When deploying parallel instances to decrease delay, it calculates delay-reduction priority and finds the target edge server by comparing the communication distances from the previous edge server traversed by the target sub-flow to all feasible edge servers.
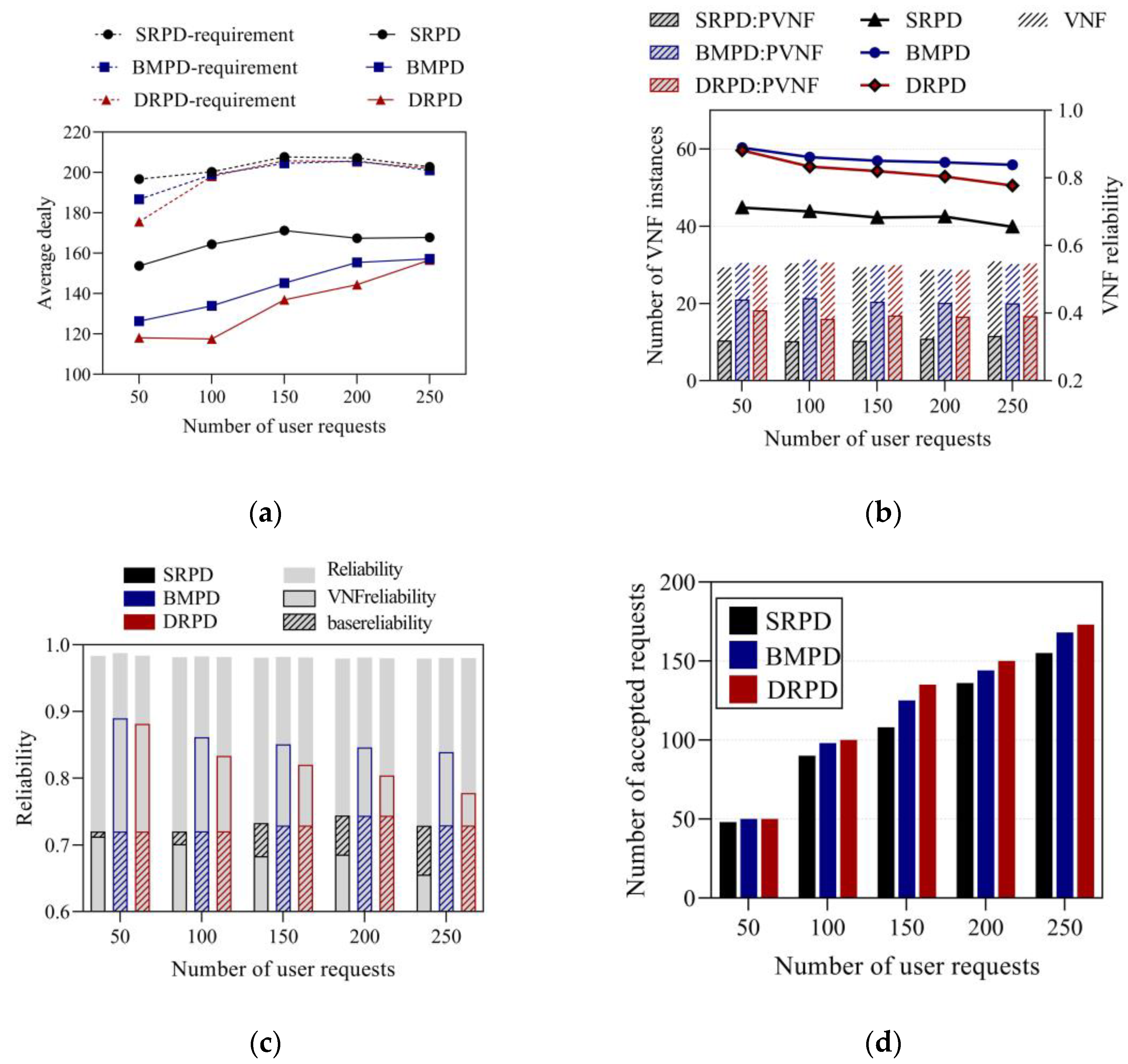
5.1. The Impact of the Number of Mobile Users on Different Algorithms
5.2. The Impact of the Number of Edge Servers on Different Algorithms
5.3. The Impact of the Number of VNFs on Each SFC on Different Algorithms
5.4. The Impact of the Reliability of Each VNF on Different Algorithms
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, C.T.; Nguyen, D.N.; Hoang, D.T.; Phan, K.T.; Niyato, D.; Pham, H.A.; Dutkiewicz, E. Elastic Resource Allocation for Coded Distributed Computing Over Heterogeneous Wireless Edge Networks. IEEE Trans. Wirel. Commun. 2023, 22, 2636–2649. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, Z.; Wu, C.; Li, Z.; Lau, F.C.M. Online Stochastic Buy-Sell Mechanism for VNF Chains in the NFV Market. IEEE J. Sel. Areas Commun. 2017, 2, 392–406. [Google Scholar] [CrossRef]
- Mijumbi, R.; Serrat, J.; Gorricho, J.; Bouten, N.; De Turck, F.; Boutaba, R. Network Function Virtualization: State-of-the-Art and Research Challenges. IEEE Commun. Surv. Tutor. 2016, 18, 236–262. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Li, F.; Trajanovski, S.; Yahyapour, R.; Fu, X. Recent Advances of Resource Allocation in Network Function Virtualization. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 295–314. [Google Scholar] [CrossRef]
- Huang, H.; Miao, W.; Min, G.; Tian, J.; Alamri, A. NFV and Blockchain Enabled 5G for Ultra-Reliable and Low-Latency Communications in Industry: Architecture and Performance Evaluation. IEEE Trans. Ind. Inform. 2021, 17, 5595–5604. [Google Scholar] [CrossRef]
- Ma, W.; Sandoval, O.; Beltran, J.; Pan, D.; Pissinou, N. Traffic aware placement of interdependent NFV middleboxes. In Proceedings of the IEEE INFOCOM 2017, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Li, B.; Cheng, B.; Liu, X.; Wang, M.; Yue, Y.; Chen, J. Joint Resource Optimization and Delay-Aware Virtual Network Function Migration in Data Center Networks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 2960–2974. [Google Scholar] [CrossRef]
- Promwongsa, N.; Abu-Lebdeh, M.; Kianpishesh, S.; Belqasmi, F.; Glitho, R.H.; Elbiaze, H.; Crespi, N.; Alfandi, O. Ensuring Reliability and Low Cost When Using a Parallel VNF Processing Approach to Embed Delay-Constrained Slices. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2226–2241. [Google Scholar] [CrossRef]
- Polese, M.; Chiariotti, F.; Bonetto, E.; Rigotto, F.; Zanella, A.; Zorzi, M. A Survey on Recent Advances in Transport Layer Protocols. IEEE Commun. Surv. Tutor. 2019, 21, 3584–3608. [Google Scholar] [CrossRef] [Green Version]
- Taleb, T.; Ksentini, A.; Sericola, B. On Service Resilience in Cloud-Native 5G Mobile Systems. IEEE J. Sel. Areas Commun. 2016, 34, 483–496. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Jiang, M.; Qiao, C. Carrier-grade availability-aware mapping of Service Function Chains with on-site backups. In Proceedings of the 2017 IEEE/ACM 25th International Symposium on Quality of Service (IWQoS), Vilanova i la Geltrú, Spain, 14–16 June 2017; pp. 1–10. [Google Scholar]
- Li, J.; Liang, W.; Xu, W.; Xu, Z.; Jia, X.; Zomaya, A.Y.; Guo, S. Budget-Aware User Satisfaction Maximization on Service Provisioning in Mobile Edge Computing. IEEE Trans. Mob. Comput. 2022, 1–13. [Google Scholar] [CrossRef]
- Huang, M.; Liang, W.; Shen, X.; Ma, Y.; Kan, H. Reliability-Aware Virtualized Network Function Services Provisioning in Mobile Edge Computing. IEEE Trans. Mob. Comput. 2020, 19, 2699–2713. [Google Scholar] [CrossRef] [Green Version]
- Shang, X.; Huang, Y.; Liu, Z.; Yang, Y. Reducing the Service Function Chain Backup Cost over the Edge and Cloud by a Self-adapting Scheme. In Proceedings of the IEEE INFOCOM 2020, Toronto, ON, Canada, 6–9 July 2020; pp. 2096–2105. [Google Scholar]
- Li, J.; Guo, S.; Liang, W.; Chen, Q.; Xu, Z.; Xu, W.; Zomaya, A.Y. Digital Twin-Assisted, SFC-Enabled Service Provisioning in Mobile Edge Computing. IEEE Trans. Mob. Comput 2022, 1–16. [Google Scholar] [CrossRef]
- Rui, L.; Chen, X.; Gao, Z.; Li, W.; Qiu, X.; Meng, L. Petri Net-Based Reliability Assessment and Migration Optimization Strategy of SFC. IEEE Trans. Netw. Serv. Manag. 2021, 18, 167–181. [Google Scholar] [CrossRef]
- Qiu, Y.; Liang, J.; Leung, V.C.M.; Wu, X.; Deng, X. Online Reliability-Enhanced Virtual Network Services Provisioning in Fault-Prone Mobile Edge Cloud. IEEE Trans. Wirel. Commun. 2022, 21, 7299–7313. [Google Scholar] [CrossRef]
- Liang, W.; Ma, Y.; Xu, W.; Xu, Z.; Jia, X.; Zhou, W. Request Reliability Augmentation With Service Function Chain Requirements in Mobile Edge Computing. IEEE Trans. Mob. Comput. 2022, 21, 4541–4554. [Google Scholar] [CrossRef]
- Yang, L.; Jia, J.; Lin, H.; Cao, J. Reliable Dynamic Service Chain Scheduling in 5G Networks. IEEE Trans. Mob. Comput. 2022, 1. [Google Scholar] [CrossRef]
- Karimzadeh-Farshbafan, M.; Shah-Mansouri, V.; Niyato, D. A Dynamic Reliability-Aware Service Placement for Network Function Virtualization (NFV). IEEE J. Sel. Areas Commun. 2020, 38, 318–333. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Liang, W.; Huang, M.; Jia, X. Reliability-Aware Network Service Provisioning in Mobile Edge-Cloud Networks. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1545–1558. [Google Scholar] [CrossRef]
- Jia, J.; Yang, L.; Cao, J. Reliability-aware Dynamic Service Chain Scheduling in 5G Networks based on Reinforcement Learning. In Proceedings of the IEEE INFOCOM 2021, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Qu, L.; Assi, C.; Shaban, K.; Khabbaz, M.J. A Reliability-Aware Network Service Chain Provisioning With Delay Guarantees in NFV-Enabled Enterprise Datacenter Networks. IEEE Trans. Netw. Serv. Manag. 2017, 14, 554–568. [Google Scholar] [CrossRef]
- Qu, L.; Assi, C.; Khabbaz, M.J.; Ye, Y. Reliability-Aware Service Function Chaining With Function Decomposition and Multipath Routing. IEEE Trans. Netw. Serv. Manag. 2020, 17, 835–848. [Google Scholar] [CrossRef]
- Engelmann, A.; Jukan, A. A Reliability Study of Parallelized VNF Chaining. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Engelmann, A.; Jukan, A.; Pries, R. On Coding for Reliable VNF Chaining in DCNs. In Proceedings of the 2019 15th International Conference on the Design of Reliable Communication Networks (DRCN), Coimbra, Portugal, 19–21 March 2019; pp. 83–90. [Google Scholar]
- Kianpisheh, S.; Glitho, R.H. Cost-Efficient Server Provisioning for Deadline-Constrained VNFs Chains: A Parallel VNF Processing Approach. In Proceedings of the 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; pp. 1–6. [Google Scholar]
- Wang, M.; Cheng, B.; Wang, S.; Chen, J. Availability- and Traffic-Aware Placement of Parallelized SFC in Data Center Networks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 182–194. [Google Scholar]
- Alleg, A.; Ahmed, T.; Mosbah, M.; Boutaba, R. Joint Diversity and Redundancy for Resilient Service Chain Provisioning. IEEE J. Sel. Areas Commun. 2020, 38, 1490–1504. [Google Scholar] [CrossRef]
- Thiruvasagam, P.K.; Kotagi, V.J.; Murthy, S.R. A Reliability-Aware, Delay Guaranteed, and Resource Efficient Placement of Service Function Cshains in Softwarized 5G Networks. IEEE Trans. Cloud Comput. 2022, 10, 1515–1531. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Joint Task Offloading and Resource Allocation for Multi-Server Mobile-Edge Computing Networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef] [Green Version]
- Dinh, T.; Kim, Y. An efficient improvement potential-based virtual network function selection scheme for reliability/availability improvement. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018; pp. 461–463. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| (BS∪V,E) | The MEC network |
| The physical links between edge servers and Vj | |
| The resource capacity of edge servers | |
| F | The set of different VNFs |
| , and | The resource demand, processing capacity, and reliability of each VNF |
| seven tuple definition: is the source node; is the destination node of user request ; is end-to-end delay requirement; is the reliability requirement; SFCi is requested VNF chains; and is data size of user request ; is the maximum number of sub-flows | |
| Indicate the deployment of in on the edge server for processing sub-flow of user request | |
| Indicate whether sub-flow of traffic flow pass through link | |
| Indicate if BVNFs for of traffic flow is deployed on edge server Vj |
| Notation | Explanation | Value |
|---|---|---|
| |U| | Number of mobile users | 50, 100, 150, 200, 250 |
| |V| | Number of edge servers | 50, 75, 100, 125 |
| || | Number of VNFs in SFC | 6, 8, 10, 12, 14 |
| |R| | Reliability of each VNF | 0.6, 0.7, 0.8, 0.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Y.; Liang, J.; Lin, Y. Joint Deployment Optimization of Parallelized SFCs and BVNFs in Multi-Access Edge Computing. Appl. Sci. 2023, 13, 7261. https://doi.org/10.3390/app13127261
Han Y, Liang J, Lin Y. Joint Deployment Optimization of Parallelized SFCs and BVNFs in Multi-Access Edge Computing. Applied Sciences. 2023; 13(12):7261. https://doi.org/10.3390/app13127261
Chicago/Turabian StyleHan, Ying, Junbin Liang, and Yun Lin. 2023. "Joint Deployment Optimization of Parallelized SFCs and BVNFs in Multi-Access Edge Computing" Applied Sciences 13, no. 12: 7261. https://doi.org/10.3390/app13127261
APA StyleHan, Y., Liang, J., & Lin, Y. (2023). Joint Deployment Optimization of Parallelized SFCs and BVNFs in Multi-Access Edge Computing. Applied Sciences, 13(12), 7261. https://doi.org/10.3390/app13127261