
MTR-SAM: Visual Multimodal Text Recognition and Sentiment Analysis in Public Opinion Analysis on the Internet

 , ,
, ,
Abstract
:1. Introduction
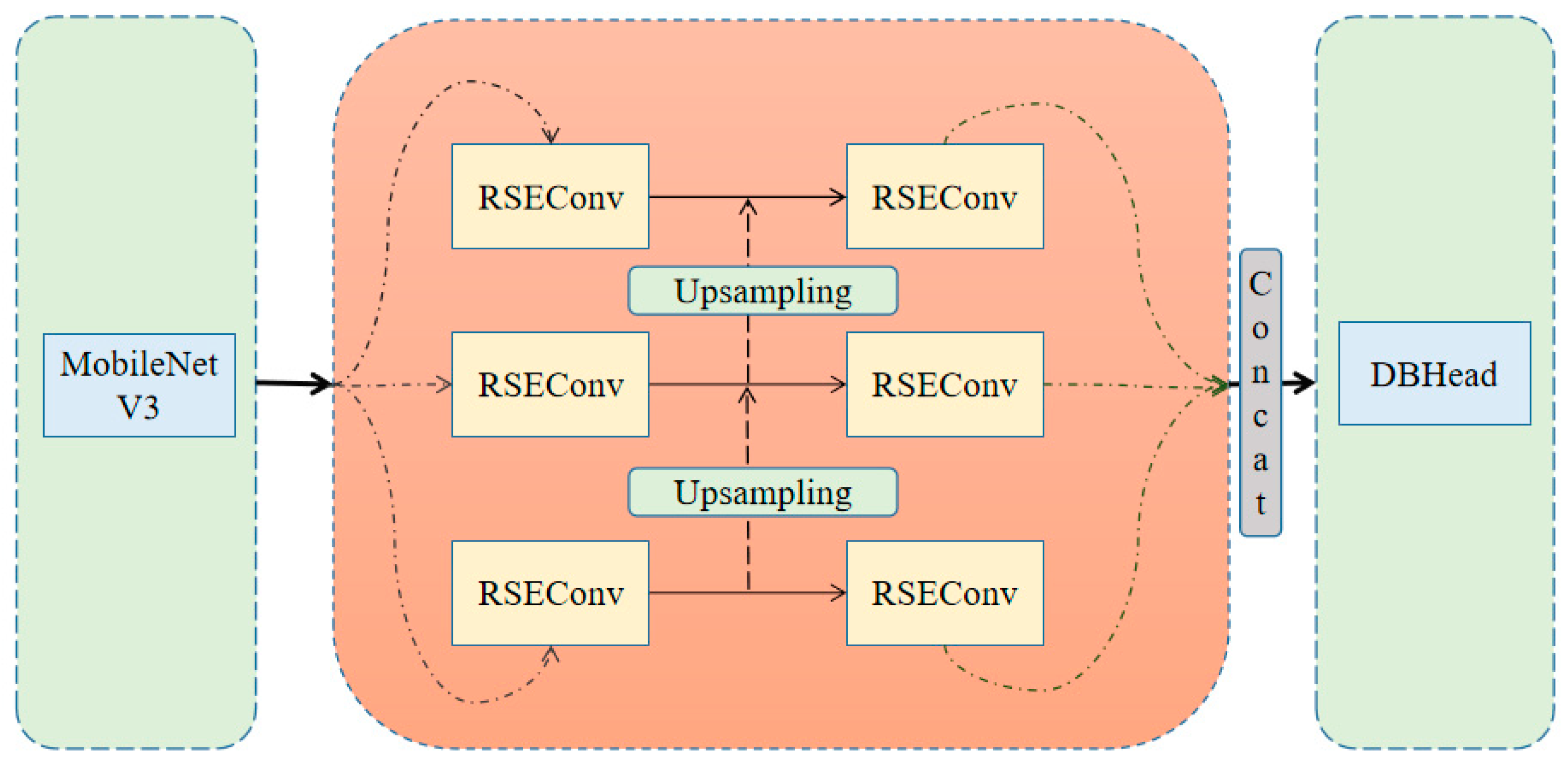
- To address the problem of insufficient text detection models in existing multimodal scenes for large font text or text with an extreme aspect ratio. We proposed the LK-PAN network of large receptive fields in the detection module to improve the CML distillation strategy and then employed an RSE-FPN with a residual attention mechanism.
- As a solution to the issue of low accuracy of text recognition models for rotating fonts in existing multimodal scenes, we modified the original CTC decoder to use the GTC (Guided Training of CTC) method and applied a sinusoidal loss function for rotation recognition. This loss function can optimize the model’s recognition of rotating fonts and improve text detection performance in settings with arbitrary rotation angles.
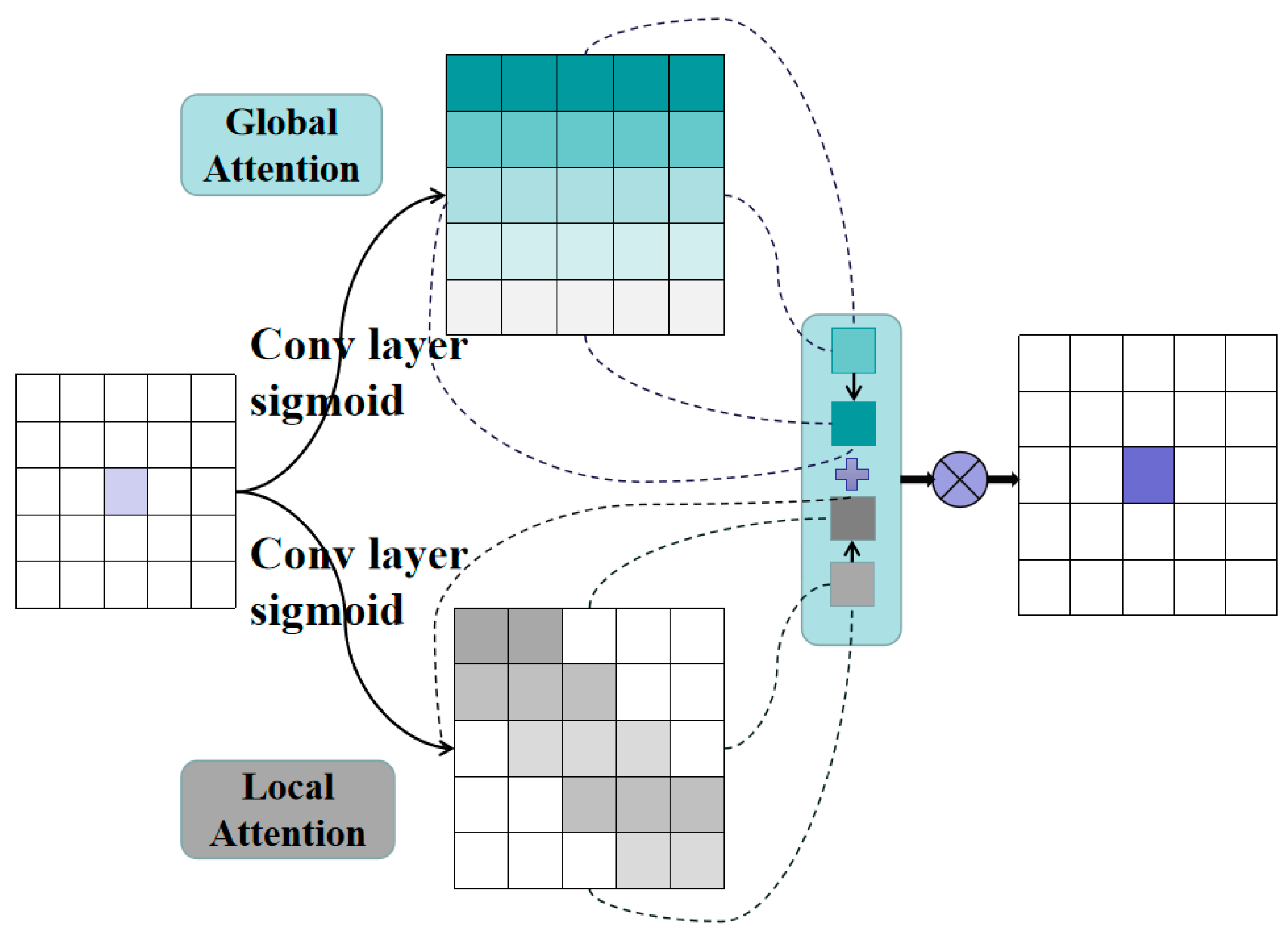
- In internet public opinion services, public opinion risk detection needs to be conducted on multimodal data, including images and videos. To distinguish the results of multimodal text recognition, we therefore introduce a sentiment analysis model. This model is capable of positive and negative sentiment discrimination on multimodal data such as images and videos. Additionally, this paper proposes a fusion of global and local information block attention mechanisms to solve the issue that word vectors are easily lost during the splicing process and the information loss of intermediate vectors during encoding.
2. Related Work
2.1. Public Opinion Scene Text Recognition
2.1.1. Text Detection
2.1.2. Text Recognition
2.2. Text Sentiment Analysis
2.3. Multimodal Visual Text Recognition
3. Methodology
3.1. Improvement Strategy in Text Detection Module
3.2. Improvement Strategy in the Identification Module
3.3. Sentiment Analysis Model Improvement
3.3.1. BERT
3.3.2. Attention Layer
4. Systematic Experimental Process and Results Analysis
4.1. Experimental Environment
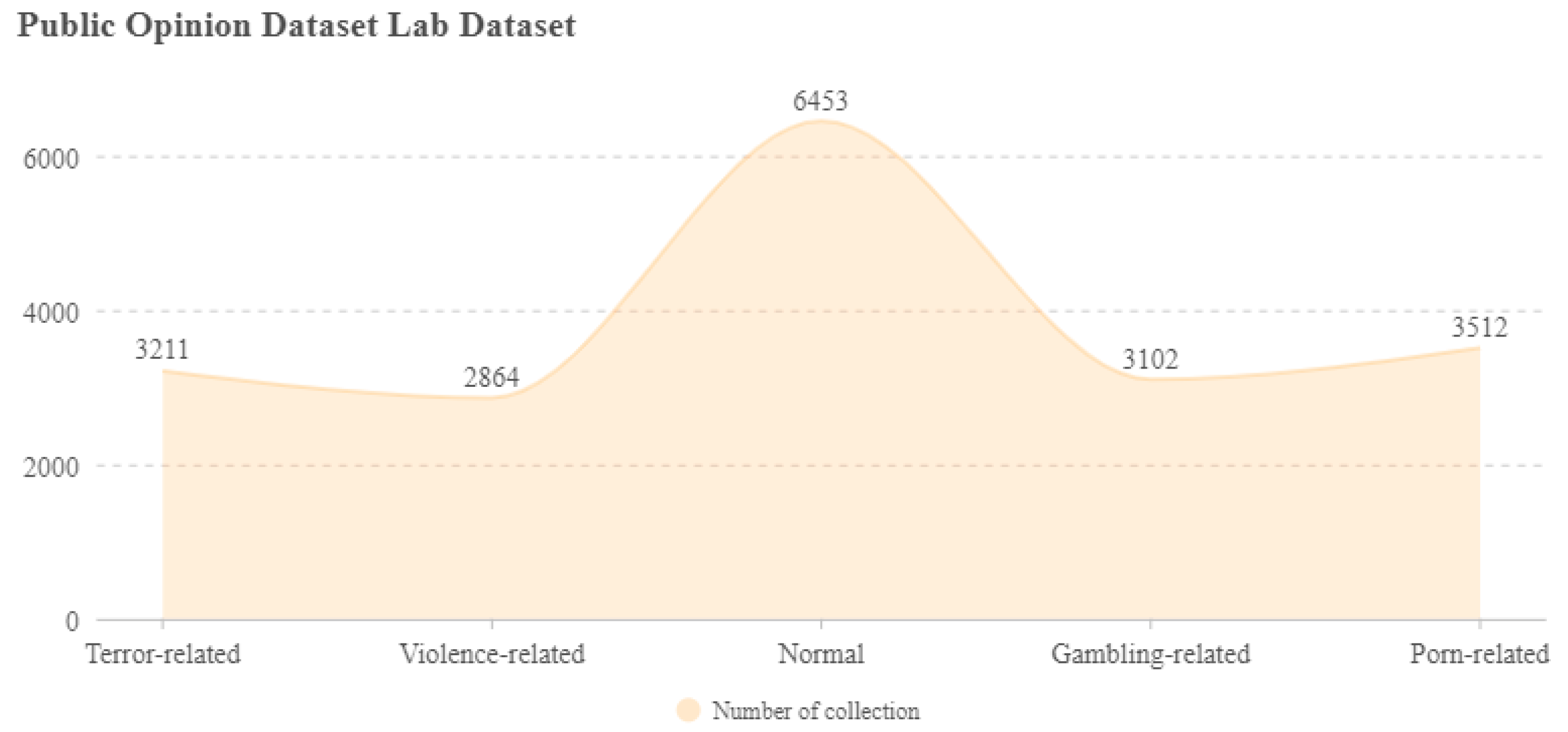
4.2. Experimental Dataset
4.3. Evaluation Metrics
4.4. Experimental Results
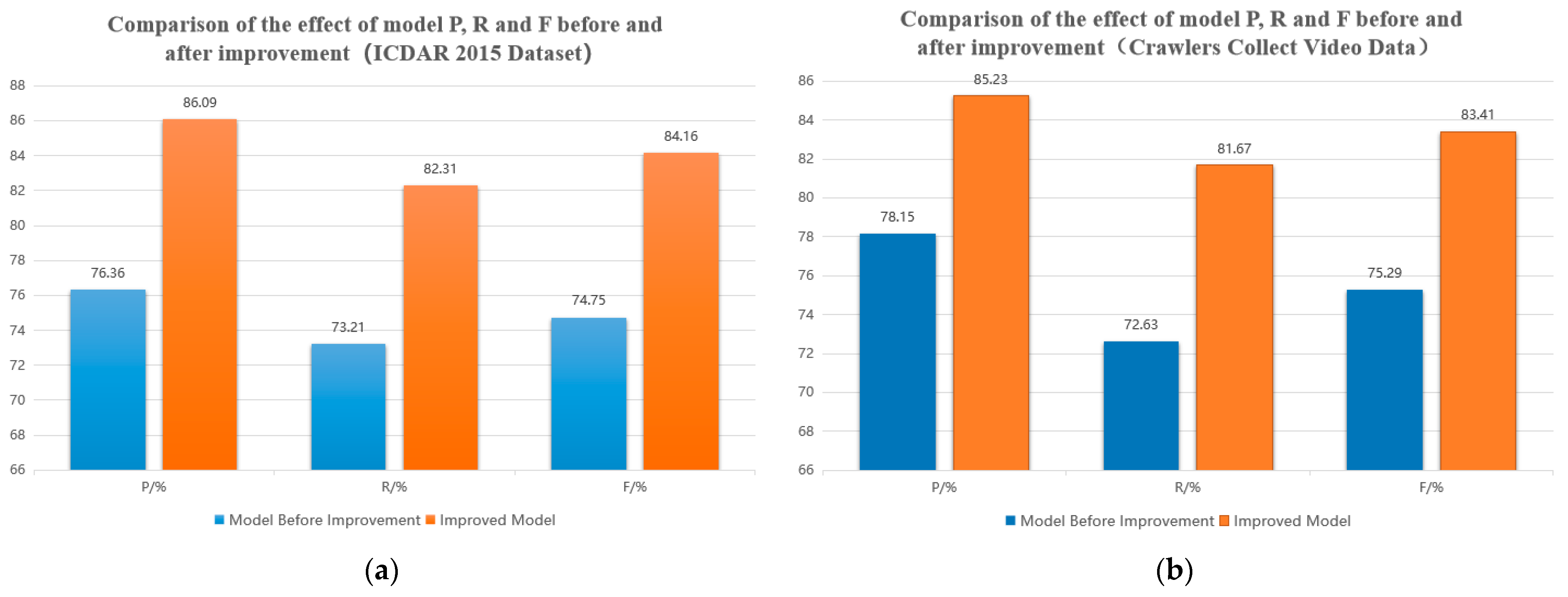
4.4.1. Comparison of Experimental Results of Multimodal Text Recognition
4.4.2. Comparison of the Experimental Results of the Emotion Analysis Model
- GRU [56]: This model has one less internal “gating” mechanism than LSTM, but the experimental results are comparable to LSTM.
- BiLSTM [57]: The model was proposed by G. Xu et al. to better capture the semantic dependencies in both directions.
- TextCNN [58]: B. Guo et al. did not introduce an attention mechanism in this model and did not consider contextual relationships.
- BERT-BiGRU [59]: A BERT-BiGRU-CRF entity recognition model is proposed for the text data of electronic cases, which can obtain the best sequence information, but the potential information of electronic medical records needs to be further explored.
- BERT-BiLSTM [60]: In the process of information extraction, the model is capable of F1 values up to 75%, but not by considering the important parts of the many extracted pieces of information.
- BERT-BiLSTM + Attention [61]: The model uses BERT as a word embedding and combines BiLSTM with attention to achieve the desired inference.
4.4.3. Experimental Results of Multimodal Text Recognition and Sentiment Analysis Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Jain, M.; Mathew, M.; Jawahar, C. Unconstrained scene text and video text recognition for arabic script. In Proceedings of the 2017 1st International Workshop on Arabic Script Analysis and Recognition (ASAR), Nancy, France, 3–5 April 2017; pp. 26–30. [Google Scholar]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl. Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, Z.; He, X.; Deng, L. Multimodal intelligence: Representation learning, information fusion, and applications. IEEE J. Sel. Top. Signal Process. 2020, 14, 478–493. [Google Scholar] [CrossRef] [Green Version]
- Muzammil, S.R.; Maqsood, S.; Haider, S.; Damaševičius, R. CSID: A novel multimodal image fusion algorithm for enhanced clinical diagnosis. Diagnostics 2020, 10, 904. [Google Scholar] [CrossRef]
- Pielawski, N.; Wetzer, E.; Öfverstedt, J.; Lu, J.; Wählby, C.; Lindblad, J.; Sladoje, N. CoMIR: Contrastive multimodal image representation for registration. Adv. Neural Inf. Process. Syst. 2020, 33, 18433–18444. [Google Scholar]
- Tian, Y.; Xu, C. Can audio-visual integration strengthen robustness under multimodal attacks? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5601–5611. [Google Scholar]
- Xia, R.; Ding, Z. Emotion-cause pair extraction: A new task to emotion analysis in texts. arXiv 2019, arXiv:1906.01267. [Google Scholar]
- Santiago Garcia, E. Country-Independent MRTD Layout Extraction and Its Applications. Master’s Thesis, University of Twente, Enschede, The Netherlands, 2022. [Google Scholar]
- Castro-Zunti, R.D.; Yépez, J.; Ko, S.B. License plate segmentation and recognition system using deep learning and OpenVINO. IET Intell. Transp. Syst. 2020, 14, 119–126. [Google Scholar] [CrossRef]
- Chen, X.; Jin, L.; Zhu, Y.; Luo, C.; Wang, T. Text recognition in the wild: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 42. [Google Scholar] [CrossRef]
- Cheng, Z.; Xu, Y.; Bai, F.; Niu, Y.; Pu, S.; Zhou, S. Aon: Towards arbitrarily-oriented text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5571–5579. [Google Scholar]
- Wei, T.C.; Sheikh, U.; Ab Rahman, A.A.-H. Improved optical character recognition with deep neural network. In Proceedings of the 2018 IEEE 14th International Colloquium on Signal Processing & Its Applications (CSPA), Penang, Malaysia, 9–10 March 2018; pp. 245–249. [Google Scholar]
- Lin, J.; Ren, X.; Zhang, Y.; Liu, G.; Wang, P.; Yang, A.; Zhou, C. Transferring General Multimodal Pretrained Models to Text Recognition. arXiv 2022, arXiv:2212.09297. [Google Scholar]
- Aberdam, A.; Ganz, R.; Mazor, S.; Litman, R. Multimodal semi-supervised learning for text recognition. arXiv 2022, arXiv:2205.03873. [Google Scholar]
- Salim, F.A.; Haider, F.; Luz, S.; Conlan, O. Automatic transformation of a video using multimodal information for an engaging exploration experience. Appl. Sci. 2020, 10, 3056. [Google Scholar] [CrossRef]
- Rasenberg, M.; Özyürek, A.; Dingemanse, M. Alignment in multimodal interaction: An integrative framework. Cogn. Sci. 2020, 44, e12911. [Google Scholar] [CrossRef]
- Wang, Y.; Xie, H.; Zha, Z.-J.; Xing, M.; Fu, Z.; Zhang, Y. Contournet: Taking a further step toward accurate arbitrary-shaped scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11753–11762. [Google Scholar]
- Xu, Y.; Wang, Y.; Zhou, W.; Wang, Y.; Yang, Z.; Bai, X. Textfield: Learning a deep direction field for irregular scene text detection. IEEE Trans. Image Process. 2019, 28, 5566–5579. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9336–9345. [Google Scholar]
- Huang, R.; Fan, M.; Xing, Y.; Zou, Y. Image blur classification and unintentional blur removal. IEEE Access 2019, 7, 106327–106335. [Google Scholar] [CrossRef]
- Sumady, O.O.; Antoni, B.J.; Nasuta, R.; Irwansyah, E. A Review of Optical Text Recognition from Distorted Scene Image. In Proceedings of the 2022 4th International Conference on Cybernetics and Intelligent System (ICORIS), Prapat, Indonesia, 8–9 October 2022; pp. 1–5. [Google Scholar]
- Zhu, Y.; Chen, J.; Liang, L.; Kuang, Z.; Jin, L.; Zhang, W. Fourier contour embedding for arbitrary-shaped text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3123–3131. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Cao, L.; Li, H.; Xie, R.; Zhu, J. A text detection algorithm for image of student exercises based on CTPN and enhanced YOLOv3. IEEE Access 2020, 8, 176924–176934. [Google Scholar] [CrossRef]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. Textboxes: A fast text detector with a single deep neural network. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Dai, P.; Zhang, S.; Zhang, H.; Cao, X. Progressive contour regression for arbitrary-shape scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7393–7402. [Google Scholar]
- Li, Y.; Wu, Z.; Zhao, S.; Wu, X.; Kuang, Y.; Yan, Y.; Ge, S.; Wang, K.; Fan, W.; Chen, X. PSENet: Psoriasis severity evaluation network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 800–807. [Google Scholar]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-time scene text detection with differentiable binarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11474–11481. [Google Scholar]
- Liu, Y.; Si, C.; Jin, K.; Shen, T.; Hu, M. FCENet: An instance segmentation model for extracting figures and captions from material documents. IEEE Access 2020, 9, 551–564. [Google Scholar] [CrossRef]
- Liu, J.; Liu, X.; Sheng, J.; Liang, D.; Li, X.; Liu, Q. Pyramid mask text detector. arXiv 2019, arXiv:1903.11800. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [Green Version]
- Yin, F.; Wu, Y.-C.; Zhang, X.-Y.; Liu, C.-L. Scene text recognition with sliding convolutional character models. arXiv 2017, arXiv:1709.01727. [Google Scholar]
- Yousef, T.; Janicke, S. A survey of text alignment visualization. IEEE Trans. Vis. Comput. Graph. 2020, 27, 1149–1159. [Google Scholar] [CrossRef] [PubMed]
- He, P.; Huang, W.; Qiao, Y.; Loy, C.; Tang, X. Reading scene text in deep convolutional sequences. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Luo, C.; Jin, L.; Sun, Z. Moran: A multi-object rectified attention network for scene text recognition. Pattern Recognit. 2019, 90, 109–118. [Google Scholar] [CrossRef]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Litman, R.; Anschel, O.; Tsiper, S.; Litman, R.; Mazor, S.; Manmatha, R. Scatter: Selective context attentional scene text recognizer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11962–11972. [Google Scholar]
- Makhmudov, F.; Mukhiddinov, M.; Abdusalomov, A.; Avazov, K.; Khamdamov, U.; Cho, Y.I. Improvement of the end-to-end scene text recognition method for “text-to-speech” conversion. Int. J. Wavelets Multiresolution Inf. Process. 2020, 18, 2050052. [Google Scholar] [CrossRef]
- Nasukawa, T.; Yi, J. Sentiment analysis: Capturing favorability using natural language processing. In Proceedings of the 2nd International Conference on Knowledge Capture, Sanibel Island, FL, USA, 23–25 October 2003; pp. 70–77. [Google Scholar]
- Willaert, T.; Van Eecke, P.; Beuls, K.; Steels, L. Building social media observatories for monitoring online opinion dynamics. Soc. Media+ Soc. 2020, 6, 1–12. [Google Scholar] [CrossRef]
- Ying, S.; Jianhua, D. A fine-grained emotional analysis of E-commerce product review data based on dictionaries. In Proceedings of the 2021 2nd International Conference on Education, Knowledge and Information Management (ICEKIM), Xiamen, China, 29–31 January 2021; pp. 257–262. [Google Scholar]
- Xu, G.; Yu, Z.; Yao, H.; Li, F.; Meng, Y.; Wu, X. Chinese text sentiment analysis based on extended sentiment dictionary. IEEE Access 2019, 7, 43749–43762. [Google Scholar] [CrossRef]
- Guenther, N.; Schonlau, M. Support vector machines. Stata J. 2016, 16, 917–937. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.-J. An implementation of naive bayes classifier. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; pp. 301–306. [Google Scholar]
- Liu, P.; Zhang, J.; Leung, C.W.-K.; He, C.; Griffiths, T.L. Exploiting effective representations for Chinese sentiment analysis using a multi-channel convolutional neural network. arXiv 2018, arXiv:1808.02961. [Google Scholar]
- Zhang, Y.-K.; Zhang, H.; Liu, Y.-G.; Yang, Q.; Liu, C.-L. Oracle character recognition by nearest neighbor classification with deep metric learning. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 309–314. [Google Scholar]
- Zhu, L.; Yang, Y. Actbert: Learning global-local video-text representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8746–8755. [Google Scholar]
- Gao, D.; Li, K.; Wang, R.; Shan, S.; Chen, X. Multi-modal graph neural network for joint reasoning on vision and scene text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12746–12756. [Google Scholar]
- Zhang, M.; Yang, Z.; Liu, C.; Fang, L. Traditional Chinese medicine knowledge service based on semi-supervised BERT-BiLSTM-CRF model. In Proceedings of the 2020 International Conference on Service Science (ICSS), Xining, China, 24–26 August 2020; pp. 64–69. [Google Scholar]
- Li, Z.; Zhang, S.; Zhang, J.; Huang, K.; Wang, Y.; Yu, Y. MVP-Net: Multi-view FPN with position-aware attention for deep universal lesion detection. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Proceedings, Part VI 22, Shenzhen, China,, 13–17 October 2019; pp. 13–21. [Google Scholar]
- Ronen, R.; Tsiper, S.; Anschel, O.; Lavi, I.; Markovitz, A.; Manmatha, R. Glass: Global to local attention for scene-text spotting. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Proceedings, Part XXVIII, Tel Aviv, Israel, 23–27 October 2022; pp. 249–266. [Google Scholar]
- Ghazi, M.M.; Yanikoglu, B.; Aptoula, E. Plant identification using deep neural networks via optimization of transfer learning parameters. Neurocomputing 2017, 235, 228–235. [Google Scholar] [CrossRef]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment analysis of comment texts based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Guo, B.; Zhang, C.; Liu, J.; Ma, X. Improving text classification with weighted word embeddings via a multi-channel TextCNN model. Neurocomputing 2019, 363, 366–374. [Google Scholar] [CrossRef]
- Qin, Q.; Zhao, S.; Liu, C. A BERT-BiGRU-CRF model for entity recognition of Chinese electronic medical records. Complexity 2021, 2021, 6631837. [Google Scholar] [CrossRef]
- Dai, Z.; Wang, X.; Ni, P.; Li, Y.; Li, G.; Bai, X. Named entity recognition using BERT BiLSTM CRF for Chinese electronic health records. In Proceedings of the 2019 12th International Congress on Image and Signal Processing, Biomedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 19–21 October 2019; pp. 1–5. [Google Scholar]
- Lee, L.-H.; Lu, Y.; Chen, P.-H.; Lee, P.-L.; Shyu, K.-K. NCUEE at MEDIQA 2019: Medical text inference using ensemble BERT-BiLSTM-Attention model. In Proceedings of the 18th BioNLP Workshop and Shared Task, Florence, Italy, 1 August 2019; pp. 528–532. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Single Test Image | Marked Out Text | Coordinate Points |
|---|---|---|
| “FORMULA” | [[570, 81], [645, 101], [644, 121], [568, 101]] | |
| “DIAGNOSIS” | [[654, 42], [730, 62], [727, 82], [652, 62]] | |
| “40,257” | [[456, 17], [521, 34], [515, 57], [451, 41]] | |
| img_891.jpg | “POSSIBLE” | [[520, 34], [597, 52], [594, 77], [516, 60]] |
| “TECHNOLOGICAL” | [[524, 1], [661, 42], [660, 63], [523, 22]] | |
| “FORMULAS” | [[596, 54], [675, 75], [673, 97], [594, 76]] | |
| “UNIQUE” | [[408, 38], [491, 60], [487, 85], [405, 64]] | |
| “FOR” | [[645, 100], [677, 107], [675, 126], [643, 118]] | |
| ... | ... |
| Test Dataset | Network Model | Average Detection Speed (Frames/s) |
|---|---|---|
| Video data collected by crawler | Model before improvement | 19.2 |
| Video data collected by crawler | Improved model | 25.3 |
| Network Model | Image Text Detection Effect | Detection Confidence |
|---|---|---|
| Model before improvement | 40.257POSSIBLE FORMULA | 0.815 |
| UNIQUE SKINCARE FORMULA FOR | 0.936 | |
| SALE | 0.913 | |
| omo | 0.738 | |
| Improved model | 40.257POSSIBLEFORMULA | 0.837 |
| INOLOCICALDIACNOSIS | 0.859 | |
| UNIQUESKINCAREFORMULAFOR | 0.949 | |
| SALE | 0.927 | |
| lomd | 0.695 | |
| MACREME | 0.924 |
| GRU | BiLSTM | TextCNN | BERT-GRU | BERT-BiLSTM | BERT-BiLSTM-Attention | Improved Model | |
|---|---|---|---|---|---|---|---|
| P/% | 71.17 | 76.35 | 78.31 | 89.61 | 90.17 | 94.24 | 96.71 |
| R/% | 73.49 | 75.86 | 74.84 | 86.12 | 88.49 | 89.61 | 95.88 |
| F/% | 72.31 | 76.1 | 76.54 | 87.83 | 89.32 | 91.87 | 96.29 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Wei, F.; Jiang, W.; Zheng, Q.; Qiao, Y.; Liu, J.; Niu, L.; Chen, Z.; Dong, H. MTR-SAM: Visual Multimodal Text Recognition and Sentiment Analysis in Public Opinion Analysis on the Internet. Appl. Sci. 2023, 13, 7307. https://doi.org/10.3390/app13127307
Liu X, Wei F, Jiang W, Zheng Q, Qiao Y, Liu J, Niu L, Chen Z, Dong H. MTR-SAM: Visual Multimodal Text Recognition and Sentiment Analysis in Public Opinion Analysis on the Internet. Applied Sciences. 2023; 13(12):7307. https://doi.org/10.3390/app13127307
Chicago/Turabian StyleLiu, Xing, Fupeng Wei, Wei Jiang, Qiusheng Zheng, Yaqiong Qiao, Jizong Liu, Liyue Niu, Ziwei Chen, and Hangcheng Dong. 2023. "MTR-SAM: Visual Multimodal Text Recognition and Sentiment Analysis in Public Opinion Analysis on the Internet" Applied Sciences 13, no. 12: 7307. https://doi.org/10.3390/app13127307
APA StyleLiu, X., Wei, F., Jiang, W., Zheng, Q., Qiao, Y., Liu, J., Niu, L., Chen, Z., & Dong, H. (2023). MTR-SAM: Visual Multimodal Text Recognition and Sentiment Analysis in Public Opinion Analysis on the Internet. Applied Sciences, 13(12), 7307. https://doi.org/10.3390/app13127307