

Building Ensemble of Resnet for Dolphin Whistle Detection



Abstract
:1. Introduction
- The creation of a new baseline on this benchmark (note: using data augmentation on the testing set increased performance);
- Clear and repeatable criteria for testing various new developments in machine learning on this dataset by providing fixed training and test sets (both augmented and not augmented) rather than a protocol involving randomization;
- Access to all the MATLAB/PyTorch source code used in this study https://github.com/LorisNanni/ (accessed on 7 July 2023).
2. Materials and Methods
2.1. Dataset
2.1.1. Data Preprocessing and Tagging
2.1.2. Original Training and Test Sets
2.2. Baseline Detection
- The “Sound Acquisition” module from the “Sound Processing” section was included to manage the data acquisition device and convey its data to other modules;
- The “FFT (spectrogram) Engine” module from the “Sound Processing” section was incorporated to calculate spectrograms;
- The “Whistle and Moan Detector” module from the “Detectors” section was added for detecting dolphin whistles;
- The “Binary Storage” module from the “Utilities” section was incorporated to preserve information from various modules;
- A new spectrogram display was created by adding the “User Display” module from the “Displays” section.
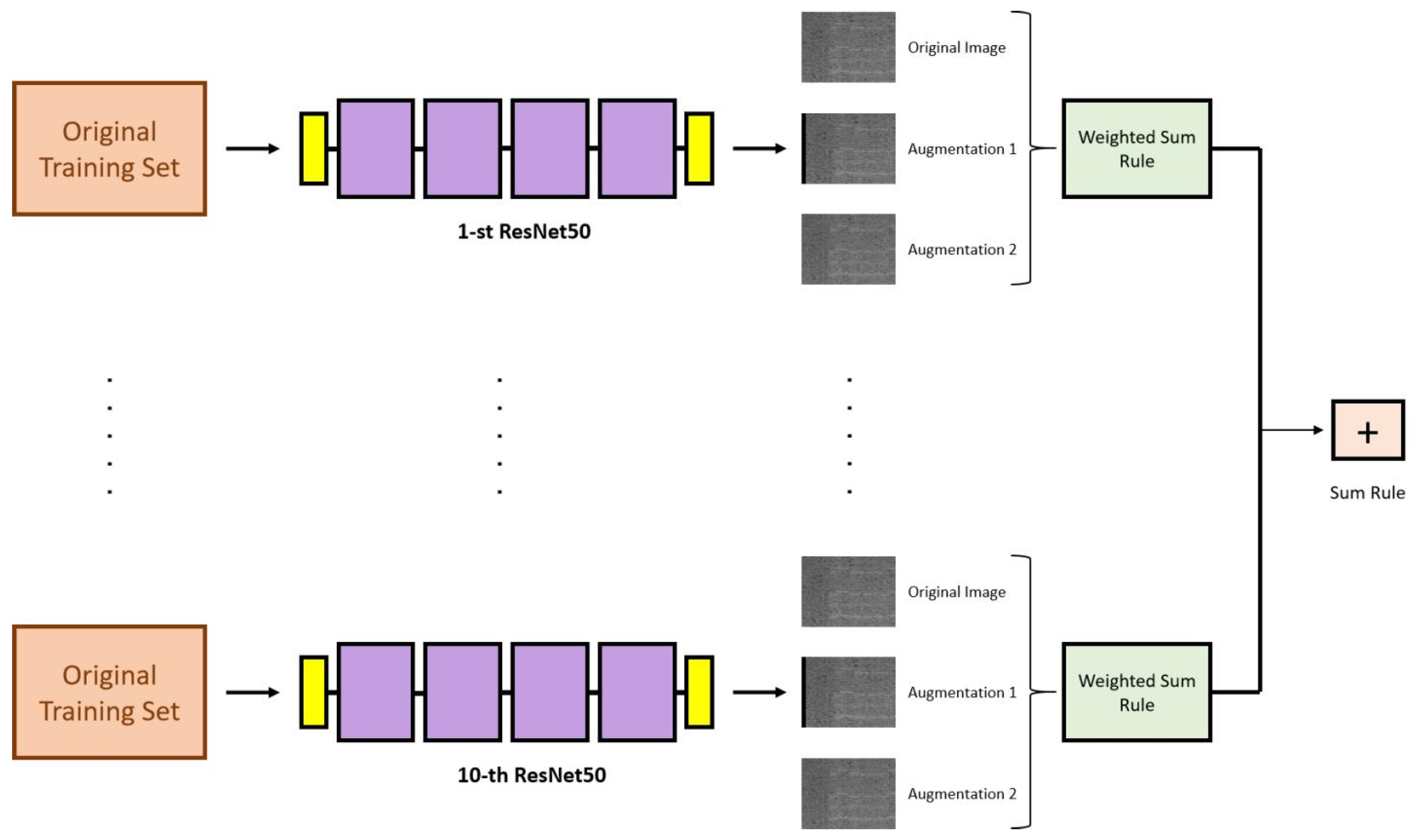
2.3. Proposed Approach
2.3.1. ResNet50
2.3.2. Validation Set Construction
- Original pattern;
- Random shift with black or wrap;
- Symmetric alternating diagonal shift.
2.3.3. Test Set Construction
- 1
- The Random shift with black or wrap (RS) augmentation function undertakes the task of randomly shifting the content of each image. The shift can be either to the left or right, determined by an equal probability of 50% for each direction. The shift’s magnitude falls within a specified shift width. Upon performing the shift, an empty space is created within the image. To handle this void, the function uses one of two strategies, each of which is selected with an equal chance of 50%. The first strategy is to fill the space with a black strip, and the second is to wrap the cut piece from the original image around to the other side, effectively reusing the displaced part of the image. In our tests, we utilized a shift_width randomly selected between 1 and 90.
- 2
- The symmetric alternating diagonal shift (SA) augmentation function applies diagonal shifts to distinct square regions within each image. Specifically, the content of a selected square region is moved diagonally in the direction of the top-left corner. The subsequent square region undergoes an opposite shift, with its content displaced diagonally towards the bottom-right corner. The size of the square regions is chosen randomly within the specified minimum and maximum size range.
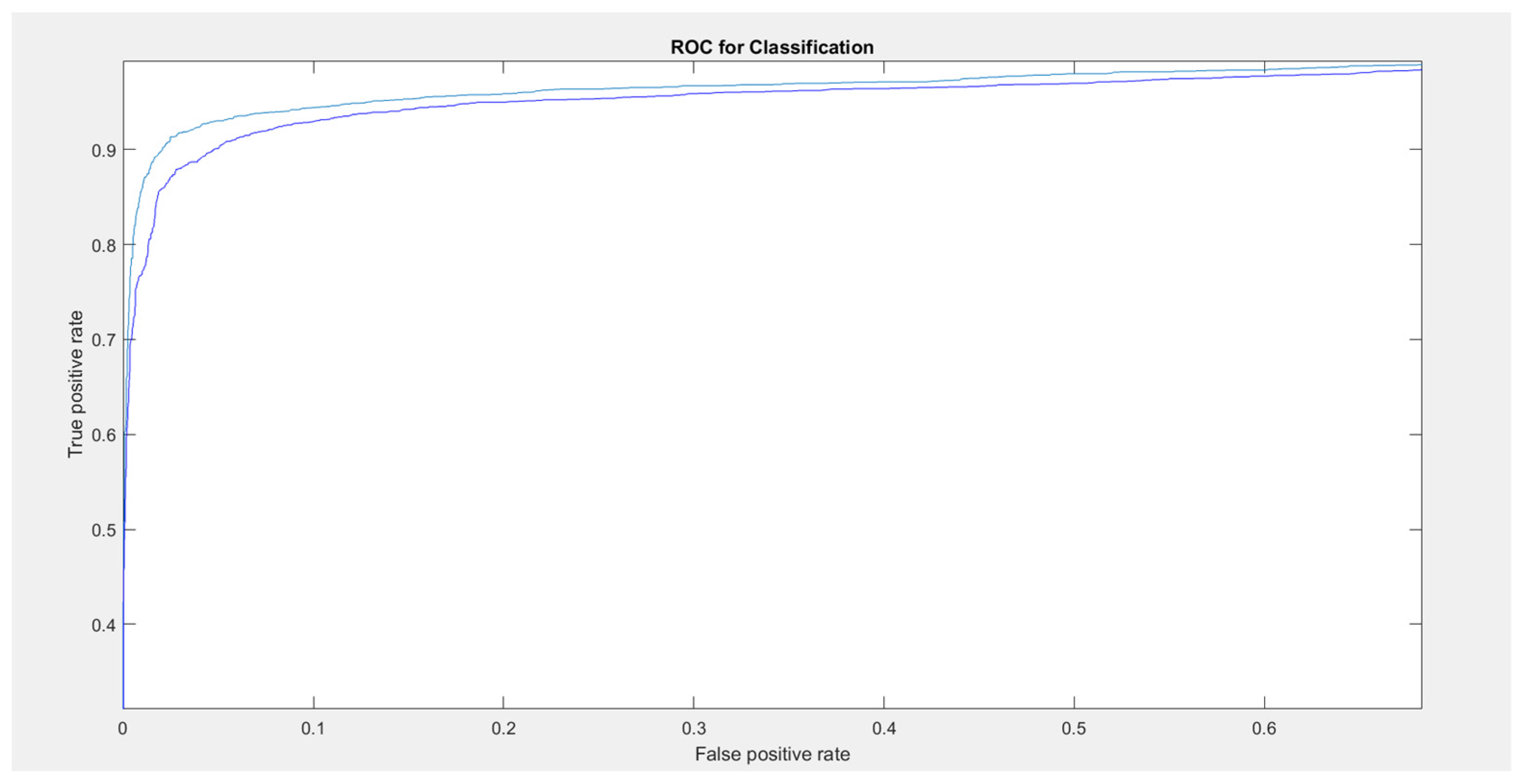
3. Experimental Results
- 1
- Data augmentation applied to the training set, with the test set consisting of only the original images: AUC: 0.968; Accuracy: 0.940; Recall: 0.911 Precision: 0.931;
- 2
- Data augmentation applied to both the training set and test set, with the proposed weighted sum rule used for the test set: AUC: 0.970; Accuracy: 0.941; Recall: 0.911; Precision: 0.934.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Halpern, B.S.; Frazier, M.; Afflerbach, J.; Lowndes, J.S.; Micheli, F.; O’hara, C.; Scarborough, C.; Selkoe, K.A. Recent pace of change in human impact on the world’s ocean. Sci. Rep. 2019, 9, 11609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Danovaro, R.; Carugati, L.; Berzano, M.; Cahill, A.E.; Carvalho, S.; Chenuil, A.; Corinaldesi, C.; Cristina, S.; David, R.; Dell’Anno, A.; et al. Implementing and Innovating Marine Monitoring Approaches for Assessing Marine Environmental Status. Front. Mar. Sci. 2016, 3, 213. [Google Scholar] [CrossRef]
- Gibb, R.; Browning, E.; Glover-Kapfer, P.; Jones, K.E. Emerging opportunities and challenges for passive acoustics in ecological assessment and monitoring. Methods Ecol. Evol. 2019, 10, 169–185. [Google Scholar] [CrossRef] [Green Version]
- Desjonquères, C.; Gifford, T.; Linke, S. Passive acoustic monitoring as a potential tool to survey animal and ecosystem processes in freshwater environments. Freshw. Biol. 2020, 65, 7–19. [Google Scholar] [CrossRef] [Green Version]
- Macaulay, J.; Kingston, A.; Coram, A.; Oswald, M.; Swift, R.; Gillespie, D.; Northridge, S. Passive acoustic tracking of the three-dimensional movements and acoustic behaviour of toothed whales in close proximity to static nets. Methods Ecol. Evol. 2022, 13, 1250–1264. [Google Scholar] [CrossRef]
- Wijers, M.; Loveridge, A.; Macdonald, D.W.; Markham, A. CARACAL: A versatile passive acoustic monitoring tool for wildlife research and conservation. Bioacoustics 2021, 30, 41–57. [Google Scholar] [CrossRef]
- Ross, S.R.P.; O’Connell, D.P.; Deichmann, J.L.; Desjonquères, C.; Gasc, A.; Phillips, J.N.; Sethi, S.S.; Wood, C.M.; Burivalova, Z. Passive acoustic monitoring provides a fresh perspective on fundamental ecological questions. Funct. Ecol. 2023, 37, 959–975. [Google Scholar] [CrossRef]
- Kowarski, K. Humpback Whale Singing Behaviour in the Western North Atlantic: From Methods for Analysing Passive Acoustic Monitoring Data to Understanding Humpback Whale Song Ontogeny. Ph.D. Thesis, Dalhousie University, Halifax, NS, Canada, 2020. [Google Scholar]
- Arranz, P.; Miranda, D.; Gkikopoulou, K.C.; Cardona, A.; Alcazar, J.; de Soto, N.A.; Thomas, L.; Marques, T.A. Comparison of visual and passive acoustic estimates of beaked whale density off El Hierro, Canary Islands. J. Acoust. Soc. Am. 2023, 153, 2469. [Google Scholar] [CrossRef]
- Lusseau, D. The emergent properties of a dolphin social network. Proc. R. Soc. B Boil. Sci. 2003, 270 (Suppl. 2), S186–S188. [Google Scholar] [CrossRef]
- Lehnhoff, L.; Glotin, H.; Bernard, S.; Dabin, W.; Le Gall, Y.; Menut, E.; Meheust, E.; Peltier, H.; Pochat, A.; Pochat, K.; et al. Behavioural Responses of Common Dolphins Delphinus delphis to a Bio-Inspired Acoustic Device for Limiting Fishery By-Catch. Sustainability 2022, 14, 13186. [Google Scholar] [CrossRef]
- Papale, E.; Fanizza, C.; Buscaino, G.; Ceraulo, M.; Cipriano, G.; Crugliano, R.; Grammauta, R.; Gregorietti, M.; Renò, V.; Ricci, P.; et al. The Social Role of Vocal Complexity in Striped Dolphins. Front. Mar. Sci. 2020, 7, 584301. [Google Scholar] [CrossRef]
- Oswald, J.N.; Barlow, J.; Norris, T.F. Acoustic identification of nine delphinid species in the eastern tropical Pacific Ocean. Mar. Mammal Sci. 2003, 19, 20–37. [Google Scholar] [CrossRef] [Green Version]
- Gillespie, D.; Caillat, M.; Gordon, J.; White, P. Automatic detection and classification of odontocete whistles. J. Acoust. Soc. Am. 2013, 134, 2427–2437. [Google Scholar] [CrossRef] [PubMed]
- Serra, O.; Martins, F.; Padovese, L. Active contour-based detection of estuarine dolphin whistles in spectrogram images. Ecol. Informatics 2020, 55, 101036. [Google Scholar] [CrossRef]
- Siddagangaiah, S.; Chen, C.-F.; Hu, W.-C.; Akamatsu, T.; McElligott, M.; Lammers, M.O.; Pieretti, N. Automatic detection of dolphin whistles and clicks based on entropy approach. Ecol. Indic. 2020, 117, 106559. [Google Scholar] [CrossRef]
- Parada, P.P.; Cardenal-López, A. Using Gaussian mixture models to detect and classify dolphin whistles and pulses. J. Acoust. Soc. Am. 2014, 135, 3371–3380. [Google Scholar] [CrossRef] [PubMed]
- Jarvis, S.; DiMarzio, N.; Morrissey, R.; Morretti, D. Automated classification of beaked whales and other small odontocetes in the tongue of the ocean, bahamas. In Proceedings of the OCEANS 2006, Boston, MA, USA, 18–21 September 2006. [Google Scholar]
- Ferrer-I-Cancho, R.; McCowan, B. A Law of Word Meaning in Dolphin Whistle Types. Entropy 2009, 11, 688–701. [Google Scholar] [CrossRef] [Green Version]
- Oswald, J.N.; Rankin, S.; Barlow, J.; Lammers, M.O. A tool for real-time acoustic species identification of delphinid whistles. J. Acoust. Soc. Am. 2007, 122, 587–595. [Google Scholar] [CrossRef] [Green Version]
- Mouy, X.; Bahoura, M.; Simard, Y. Automatic recognition of fin and blue whale calls for real-time monitoring in the St. Lawrence. J. Acoust. Soc. Am. 2009, 126, 2918–2928. [Google Scholar] [CrossRef] [PubMed]
- Usman, A.M.; Ogundile, O.O.; Versfeld, D.J.J. Review of Automatic Detection and Classification Techniques for Cetacean Vocalization. IEEE Access 2020, 8, 105181–105206. [Google Scholar] [CrossRef]
- Abayomi-Alli, O.O.; Damaševičius, R.; Qazi, A.; Adedoyin-Olowe, M.; Misra, S. Data Augmentation and Deep Learning Methods in Sound Classification: A Systematic Review. Electronics 2022, 11, 3795. [Google Scholar] [CrossRef]
- Testolin, A.; Diamant, R. Combining denoising autoencoders and dynamic programming for acoustic detection and tracking of underwater moving targets. Sensors 2020, 20, 2945. [Google Scholar] [CrossRef] [PubMed]
- Jiang, J.-J.; Bu, L.-R.; Duan, F.-J.; Wang, X.-Q.; Liu, W.; Sun, Z.-B.; Li, C.-Y. Whistle detection and classification for whales based on convolutional neural networks. Appl. Acoust. 2019, 150, 169–178. [Google Scholar] [CrossRef]
- Zhong, M.; Castellote, M.; Dodhia, R.; Ferres, J.L.; Keogh, M.; Brewer, A. Beluga whale acoustic signal classification using deep learning neural network models. J. Acoust. Soc. Am. 2020, 147, 1834–1841. [Google Scholar] [CrossRef] [PubMed]
- Buchanan, C.; Bi, Y.; Xue, B.; Vennell, R.; Childerhouse, S.; Pine, M.K.; Briscoe, D.; Zhang, M. Deep convolutional neural networks for detecting dolphin echolocation clicks. In Proceedings of the 2021 36th International Conference on Image and Vision Computing New Zealand (IVCNZ), Tauranga, New Zealand, 9–10 December 2021. [Google Scholar]
- Korkmaz, B.N.; Diamant, R.; Danino, G.; Testolin, A. Automated detection of dolphin whistles with convolutional networks and transfer learning. Front. Artif. Intell. 2023, 6, 1099022. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Qiao, G.; Liu, S.; Qing, X.; Zhang, H.; Mazhar, S.; Niu, F. Automated classification of Tursiops aduncus whistles based on a depth-wise separable convolutional neural network and data augmentation. J. Acoust. Soc. Am. 2021, 150, 3861–3873. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Liu, X.; Palmer, K.J.; Fleishman, E.; Gillespie, D.; Nosal, E.M.; Shiu, Y.; Klinck, H.; Cholewiak, D.; Helble, T.; et al. Learning deep models from synthetic data for extracting dolphin whistle contours. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Jin, C.; Kim, M.; Jang, S.; Paeng, D.-G. Semantic segmentation-based whistle extraction of Indo-Pacific Bottlenose Dolphin residing at the coast of Jeju island. Ecol. Indic. 2022, 137, 108792. [Google Scholar] [CrossRef]
- Zhang, L.; Huang, H.-N.; Yin, L.; Li, B.-Q.; Wu, D.; Liu, H.-R.; Li, X.-F.; Xie, Y.-L. Dolphin vocal sound generation via deep WaveGAN. J. Electron. Sci. Technol. 2022, 20, 100171. [Google Scholar] [CrossRef]
- Kershenbaum, A.; Sayigh, L.S.; Janik, V.M. The encoding of individual identity in dolphin signature whistles: How much information is needed? PLoS ONE 2013, 8, e77671. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Padovese, B.; Frazao, F.; Kirsebom, O.S.; Matwin, S. Data augmentation for the classification of North Atlantic right whales upcalls. J. Acoust. Soc. Am. 2021, 149, 2520–2530. [Google Scholar] [CrossRef] [PubMed]
- Tukey, J.W. Comparing Individual Means in the Analysis of Variance. Biometrics 1949, 5, 99–114. [Google Scholar] [CrossRef] [PubMed]
- Jones, B.; Zapetis, M.; Samuelson, M.M.; Ridgway, S. Sounds produced by bottlenose dolphins (Tursiops): A review of the defining characteristics and acoustic criteria of the dolphin vocal repertoire. Bioacoustics 2020, 29, 399–440. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ketten, D.R. Underwater ears and the physiology of impacts: Comparative liability for hearing loss in sea turtles, birds, and mammals. Bioacoustics 2008, 17, 312–315. [Google Scholar] [CrossRef]
- Erbe, C.; Marley, S.A.; Schoeman, R.P.; Smith, J.N.; Trigg, L.E.; Embling, C.B. The Effects of Ship Noise on Marine Mammals—A Review. Front. Mar. Sci. 2019, 6, 606. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ResNets | AUC |
|---|---|
| ResNet50(1) | 0.960 |
| ResNet50(1)_DA | 0.964 |
| ResNet50(5)_DA | 0.972 |
| ResNet50(10)_DA | 0.973 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nanni, L.; Cuza, D.; Brahnam, S. Building Ensemble of Resnet for Dolphin Whistle Detection. Appl. Sci. 2023, 13, 8029. https://doi.org/10.3390/app13148029
Nanni L, Cuza D, Brahnam S. Building Ensemble of Resnet for Dolphin Whistle Detection. Applied Sciences. 2023; 13(14):8029. https://doi.org/10.3390/app13148029
Chicago/Turabian StyleNanni, Loris, Daniela Cuza, and Sheryl Brahnam. 2023. "Building Ensemble of Resnet for Dolphin Whistle Detection" Applied Sciences 13, no. 14: 8029. https://doi.org/10.3390/app13148029
APA StyleNanni, L., Cuza, D., & Brahnam, S. (2023). Building Ensemble of Resnet for Dolphin Whistle Detection. Applied Sciences, 13(14), 8029. https://doi.org/10.3390/app13148029