
A Node Differential Privacy-Based Method to Preserve Directed Graphs in Wireless Mobile Networks

Abstract
:1. Introduction
2. Related Works
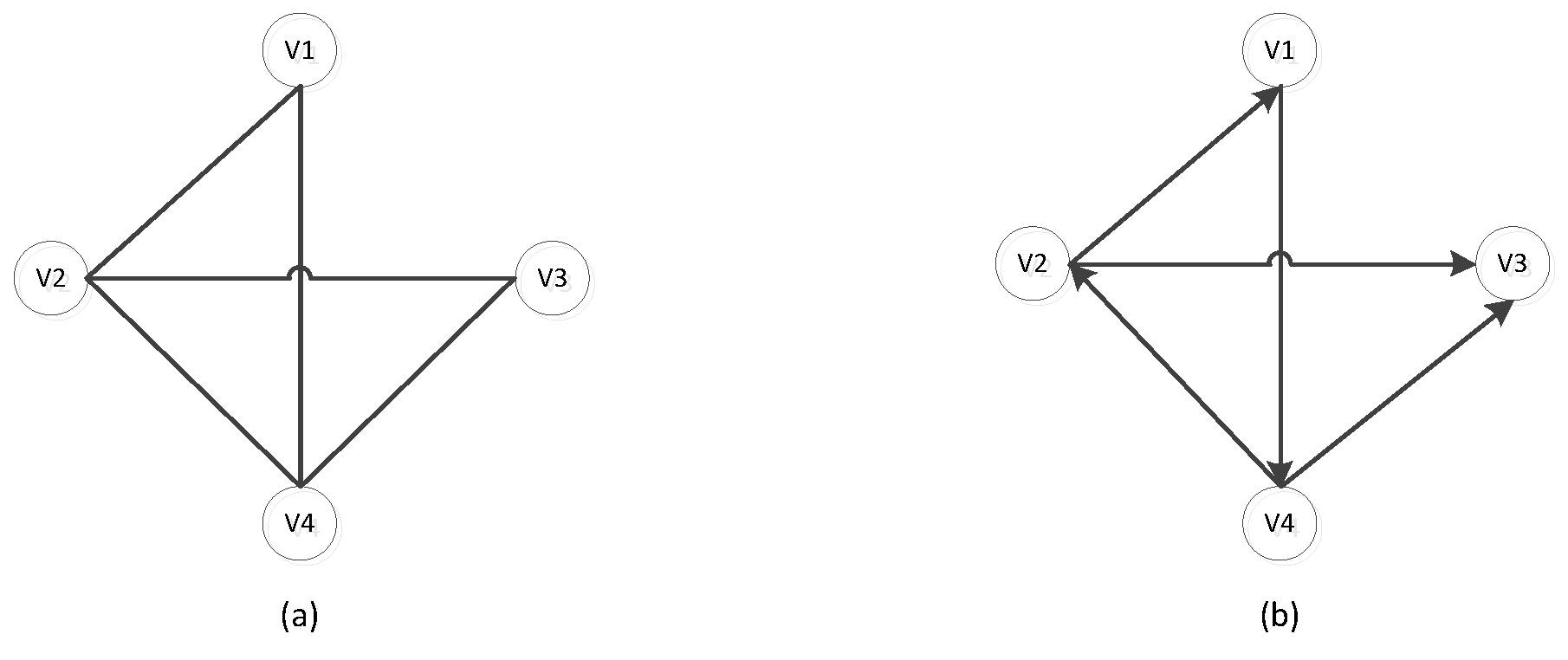
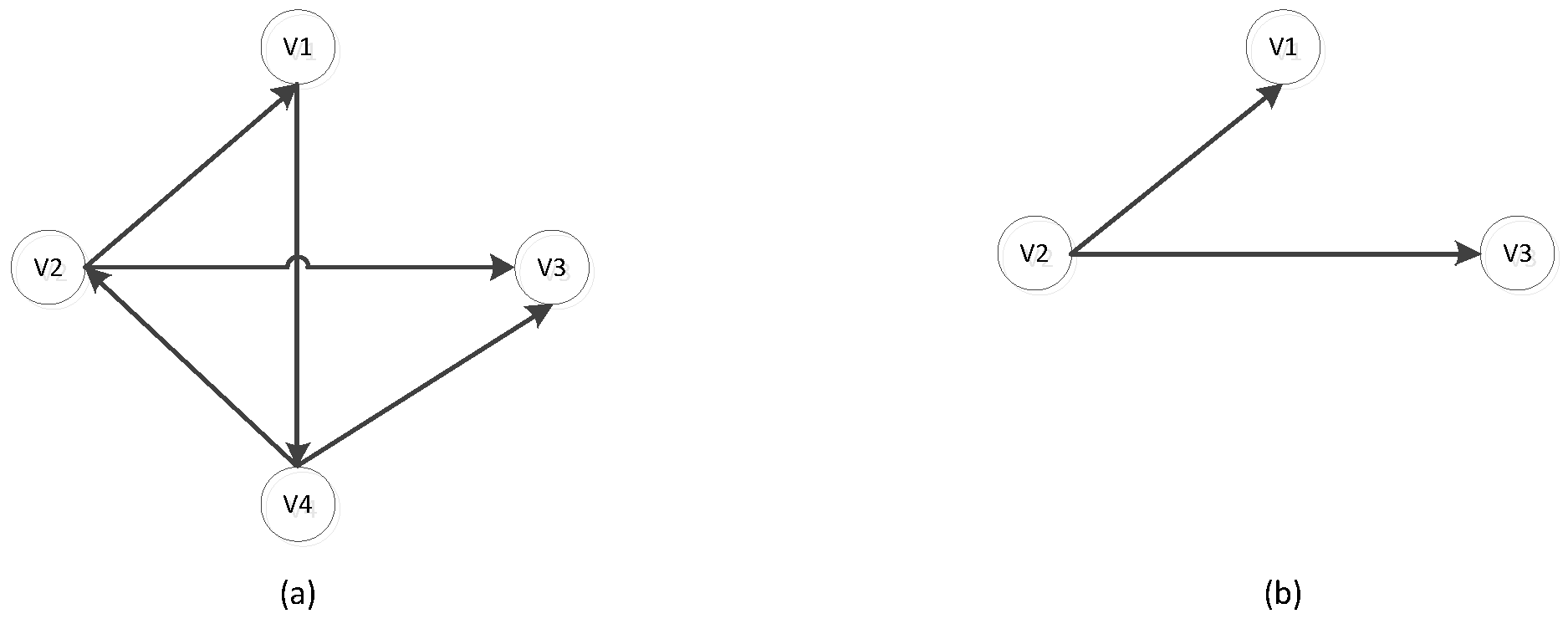
3. Preliminaries Knowledge
4. The Proposed Method
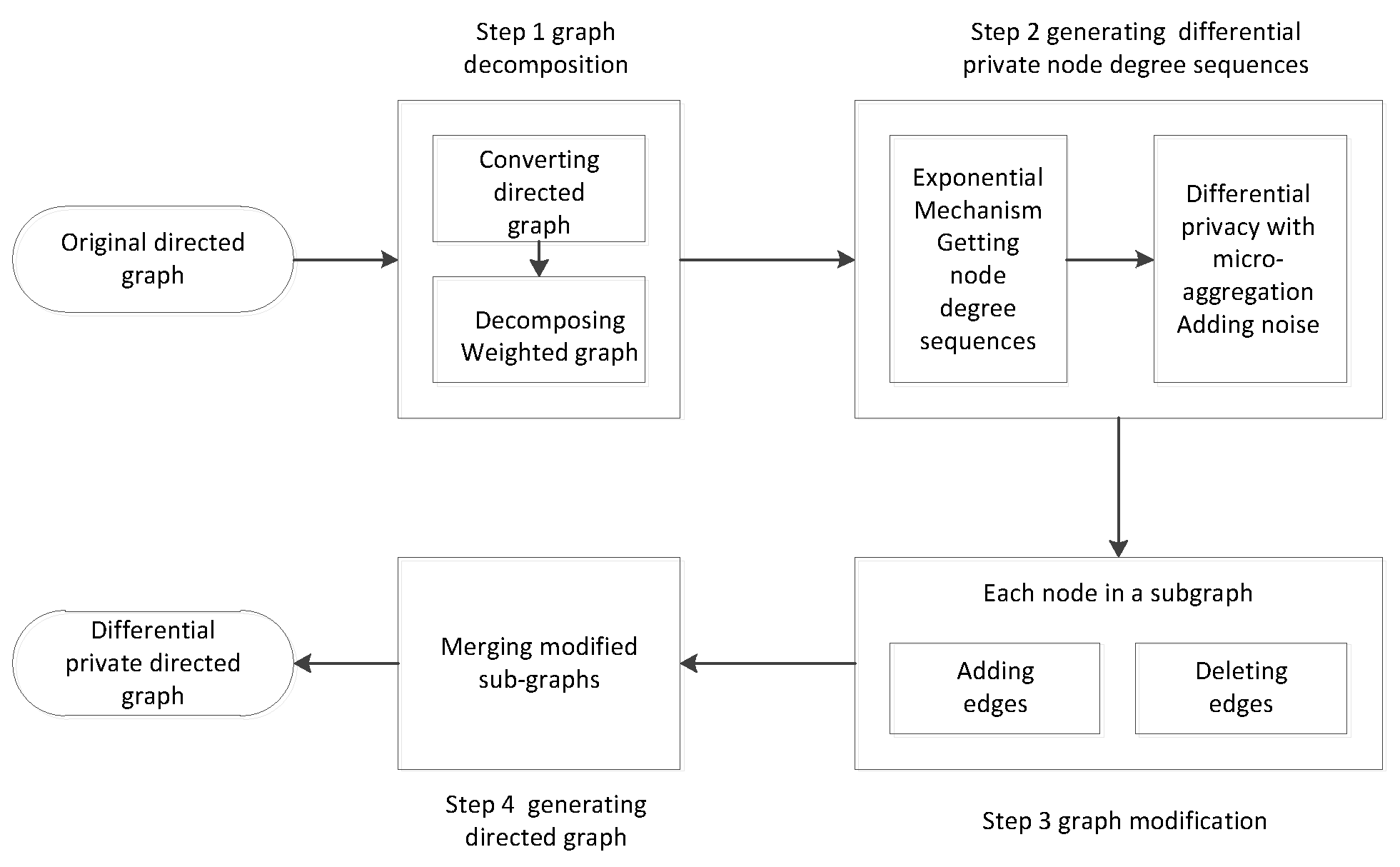
4.1. The Framework of Method
4.2. DGNDP (Synthetic Directed Graph Based on Node Differential Privacy) Algorithm
| Algorithm 1 DGNDP algorithm |
|
4.2.1. GSEM (Generating Degree Sequence Based on Exponent Mechanism) Algorithm
| Algorithm 2 GSEM algorithm |
|
4.2.2. ADPRA (Adding Noise Based on Differential Privacy with the Ranking Micro-Aggregation) Algorithm
| Algorithm 3 ADPRA algorithm |
|
4.2.3. GGM (Generating Synthetic Graph Based on Graph Modification) Algorithm
| Algorithm 4 GGM algorithm |
|
4.2.4. Analysis of DGNDP Algorithm
5. Experiments and Results
5.1. Data Sets
- (1)
- Physicians: This directed network captures innovation spread among 246 physicians in towns in Illinois, Peoria, Bloomington, Quincy, and Galesburg. A node represents a physician and an edge between two physicians shows that the left physician told that the right physician is his friend or that he turns to the right physician if he needs advice or is interested in a discussion. There are 240 nodes and 1098 edges.
- (2)
- Blogs: This directed network contains front-page hyperlinks between blogs in the context of the 2004 US election. A node represents a blog and an edge represents a hyperlink between two blogs. There are 1224 nodes and 19,025 edges.
- (3)
- Wikipedia−link: This network consists of the wikilinks of Wikipedia in the Gagauz language (gag). Nodes are Wikipedia articles and directed edges are wikilinks, i.e., hyperlinks within one wiki. There are 2929 nodes and 118,603 edges.
- (4)
- Gnutella: This is a network of Gnutella hosts from 2002. The nodes represent Gnutella hosts, and the directed edges represent connections between them. There are 12,717 nodes and 51,525 edges.
- (5)
- Twitter lists: This directed network contains Twitter user–user following information. A node represents a user. An edge indicates that the user represented by the left node follows the user represented by the right node. There are 23,370 nodes and 1,231,177 edges.
5.2. Metrics and Parameters
5.2.1. Metrics and Parameters in Privacy Preservation
5.2.2. Metrics and Parameters in Data Utility
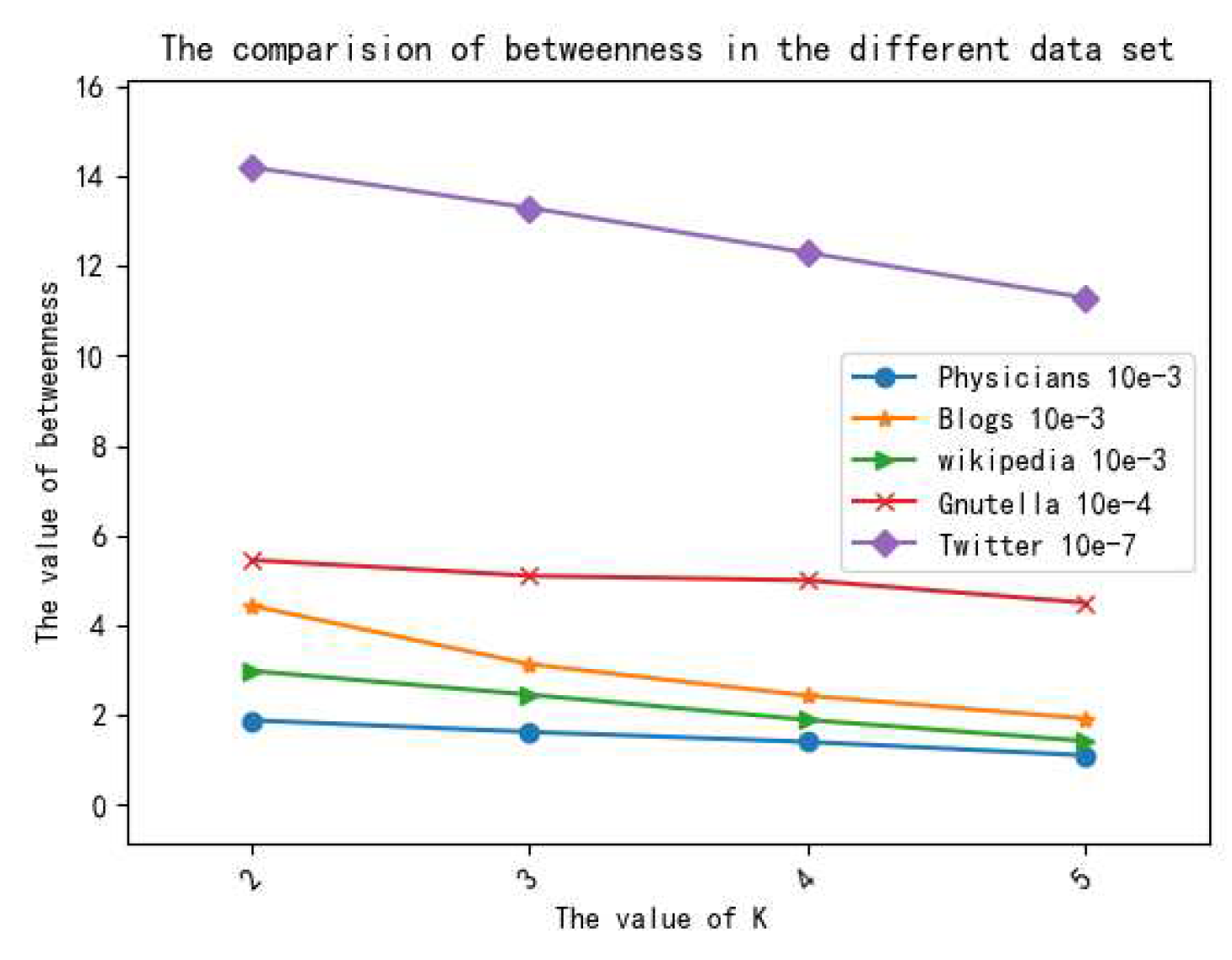
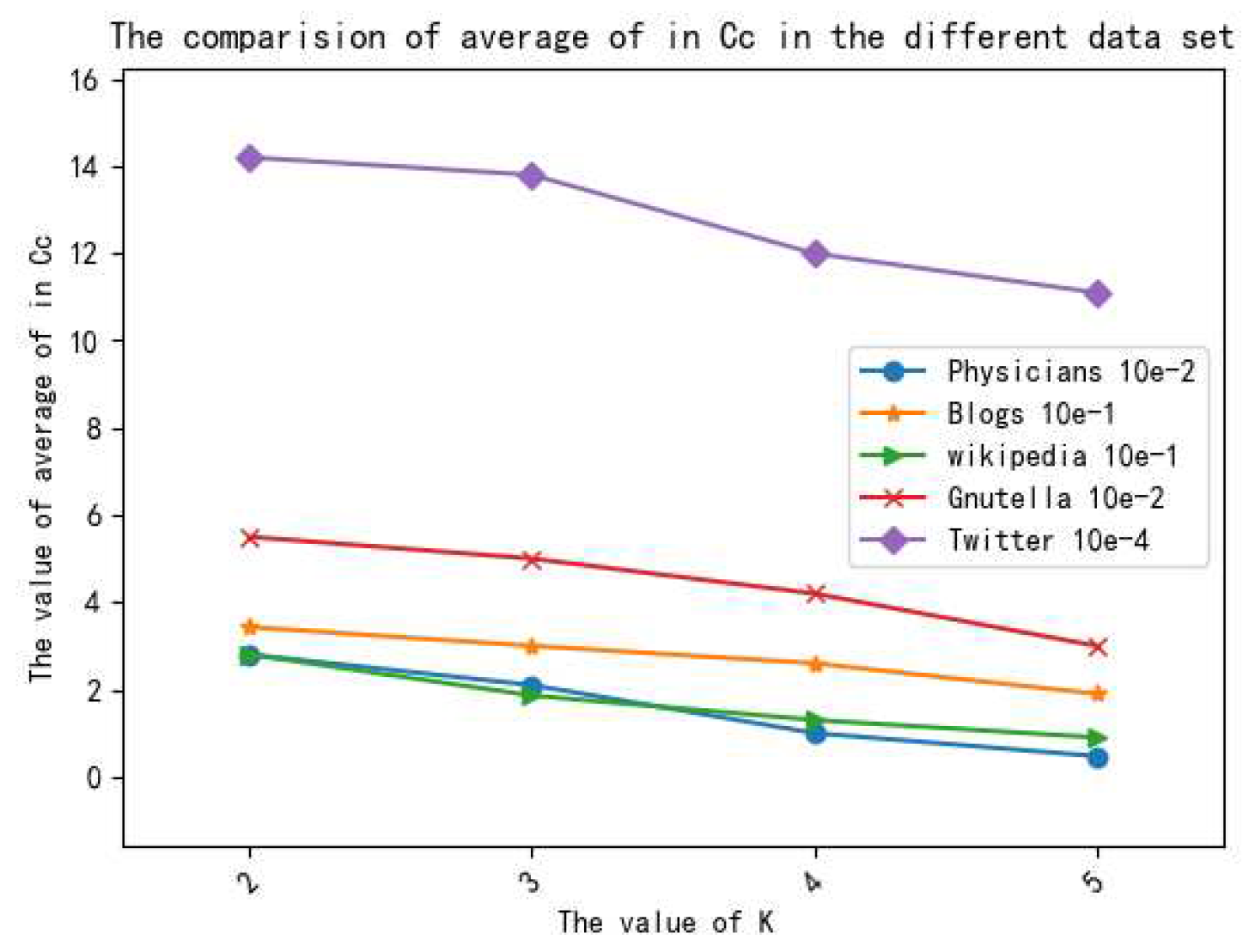
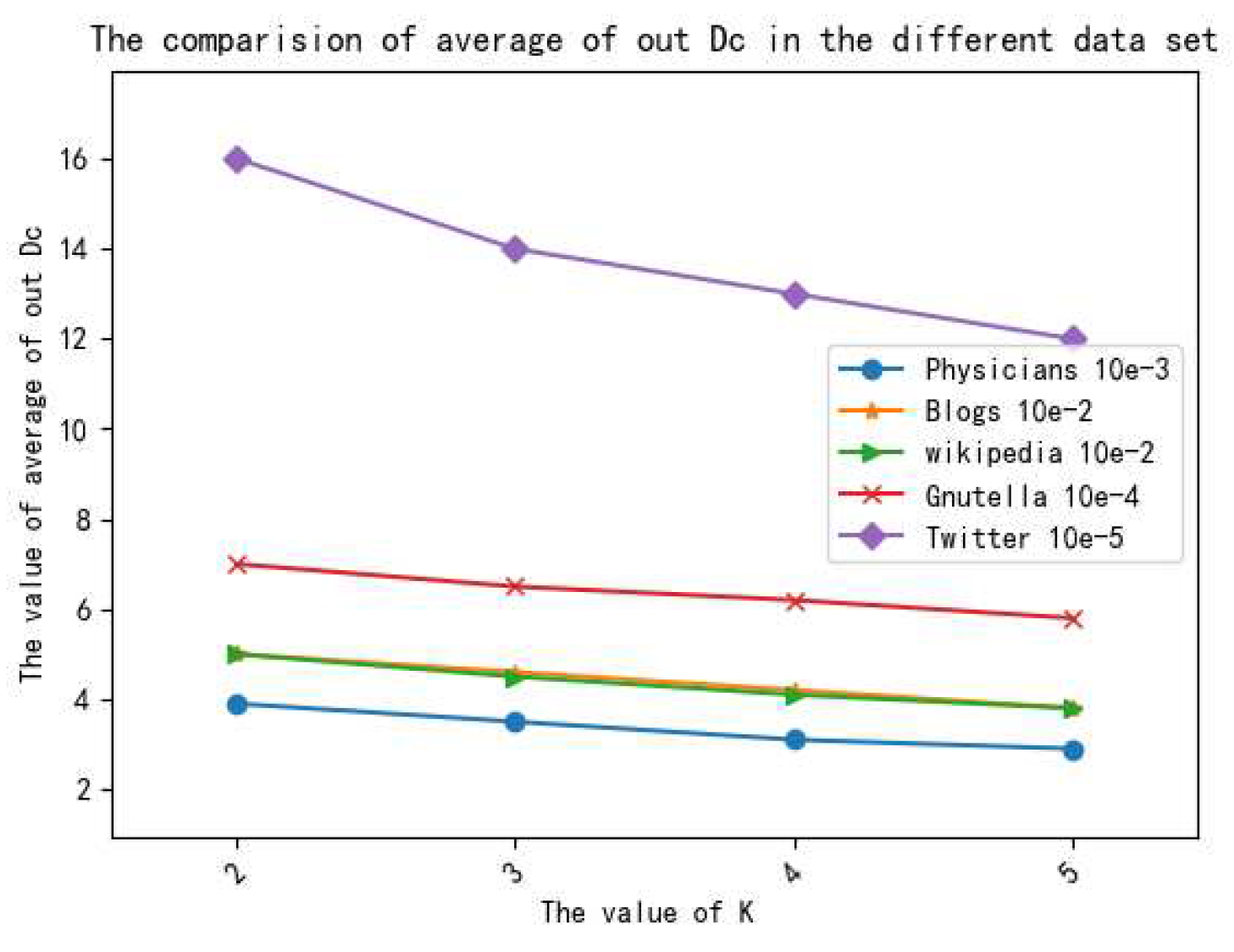
5.3. Results and Discussion
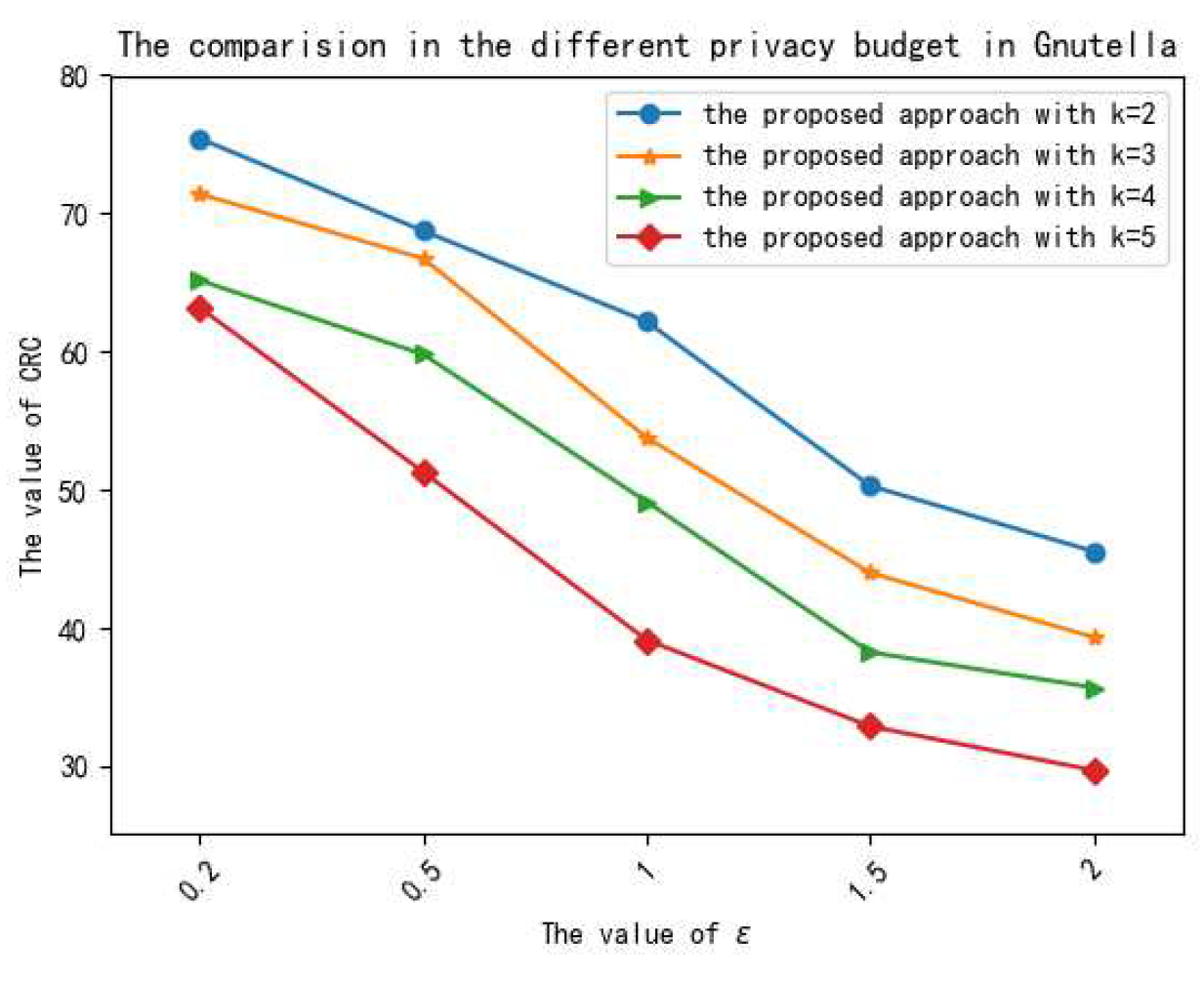
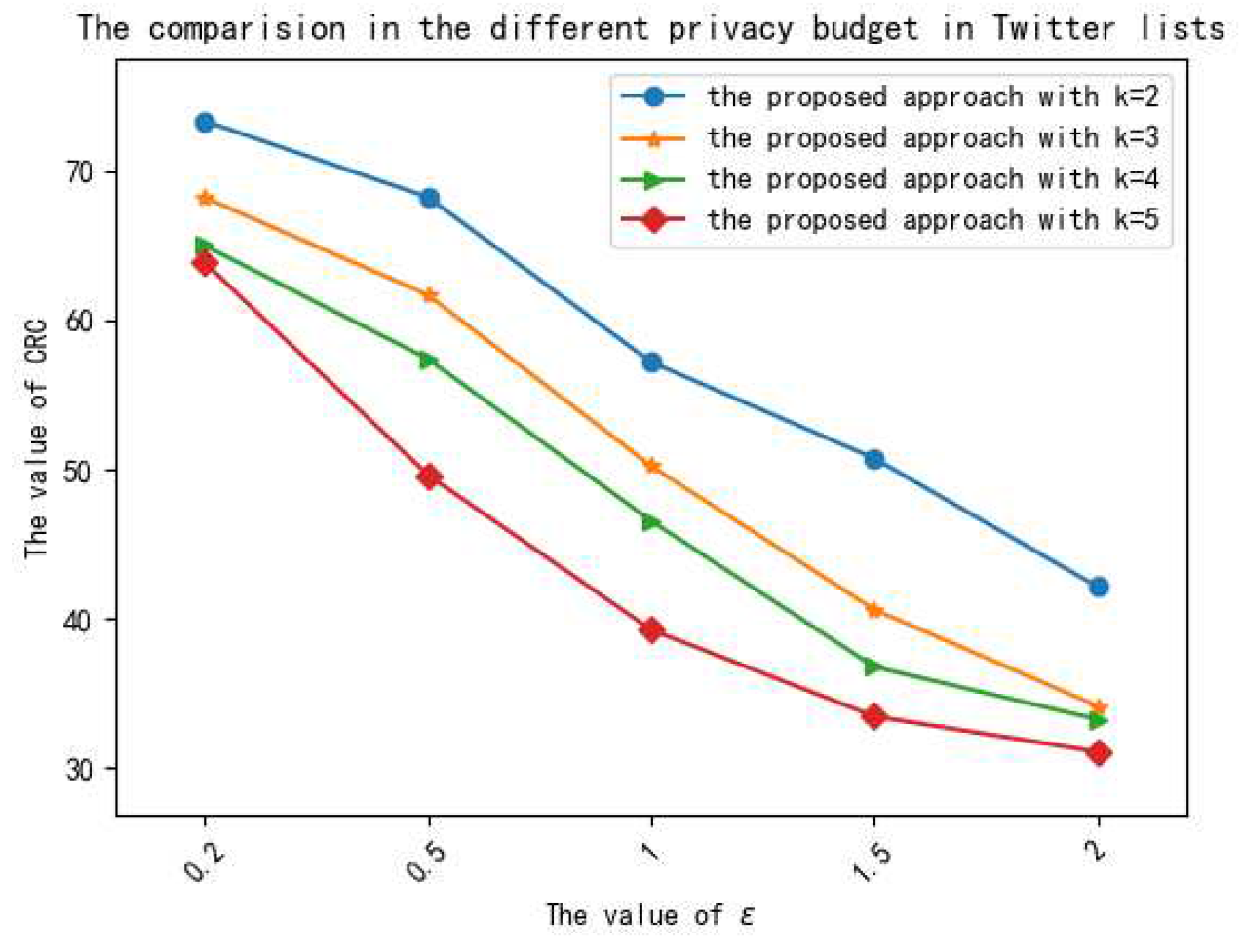
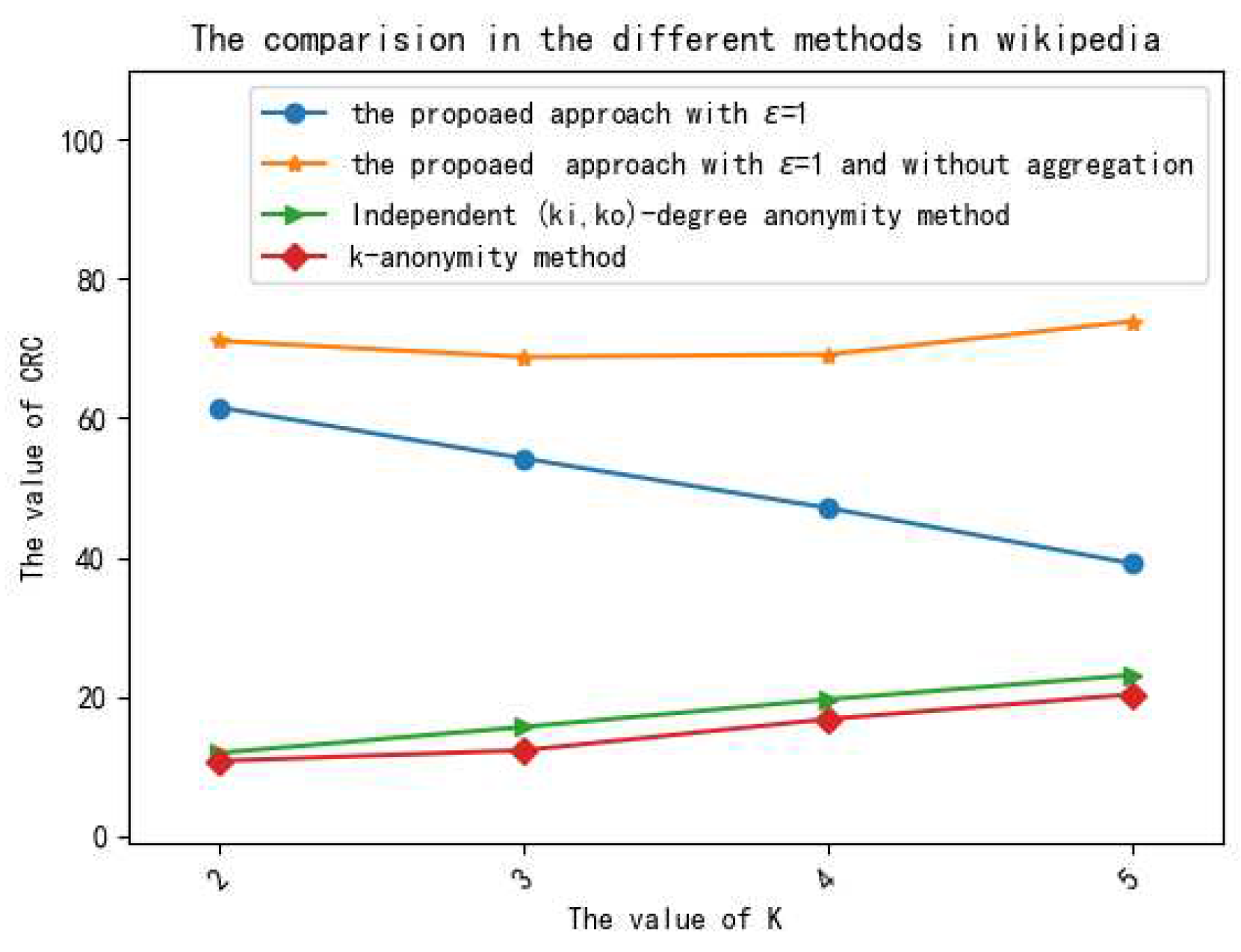
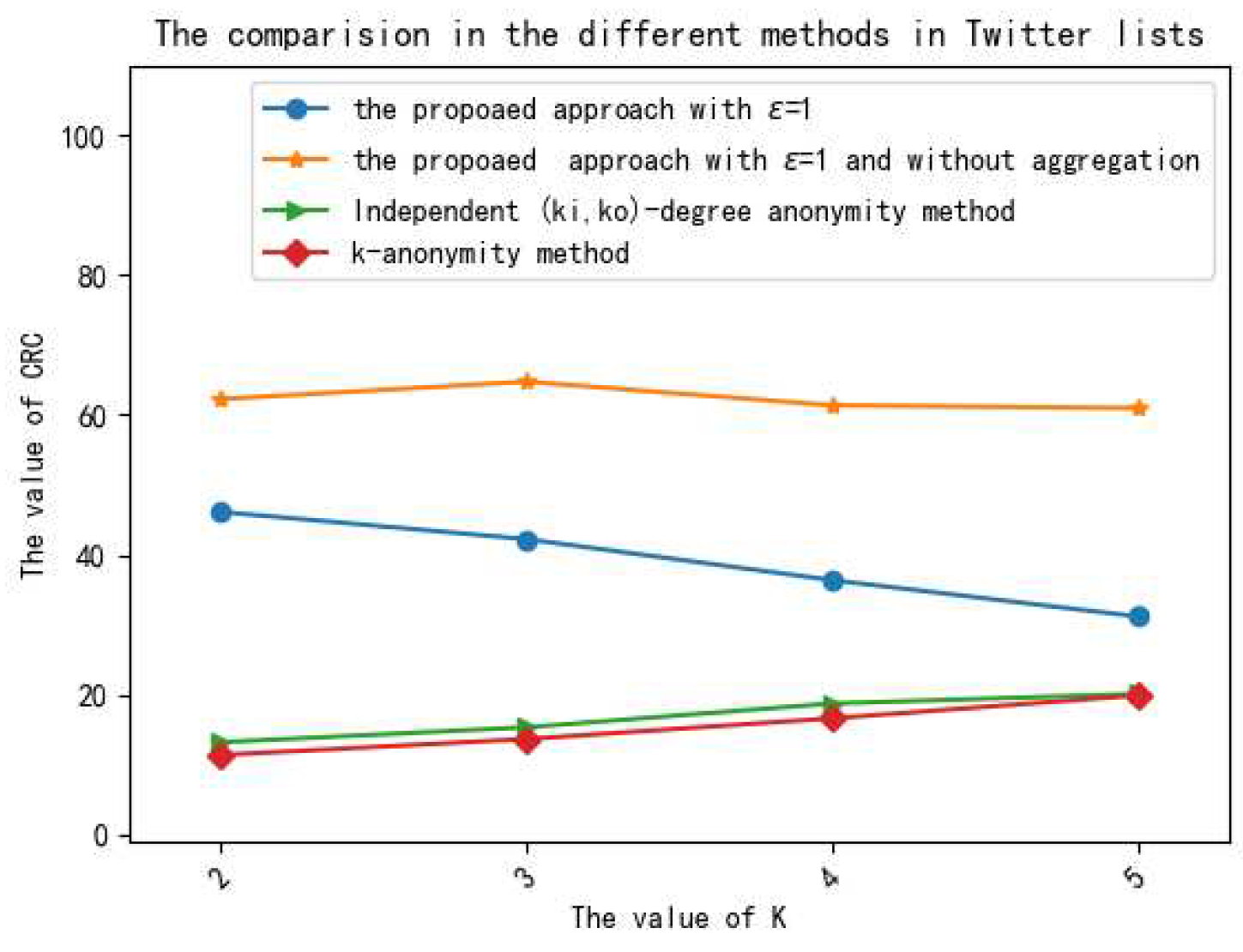
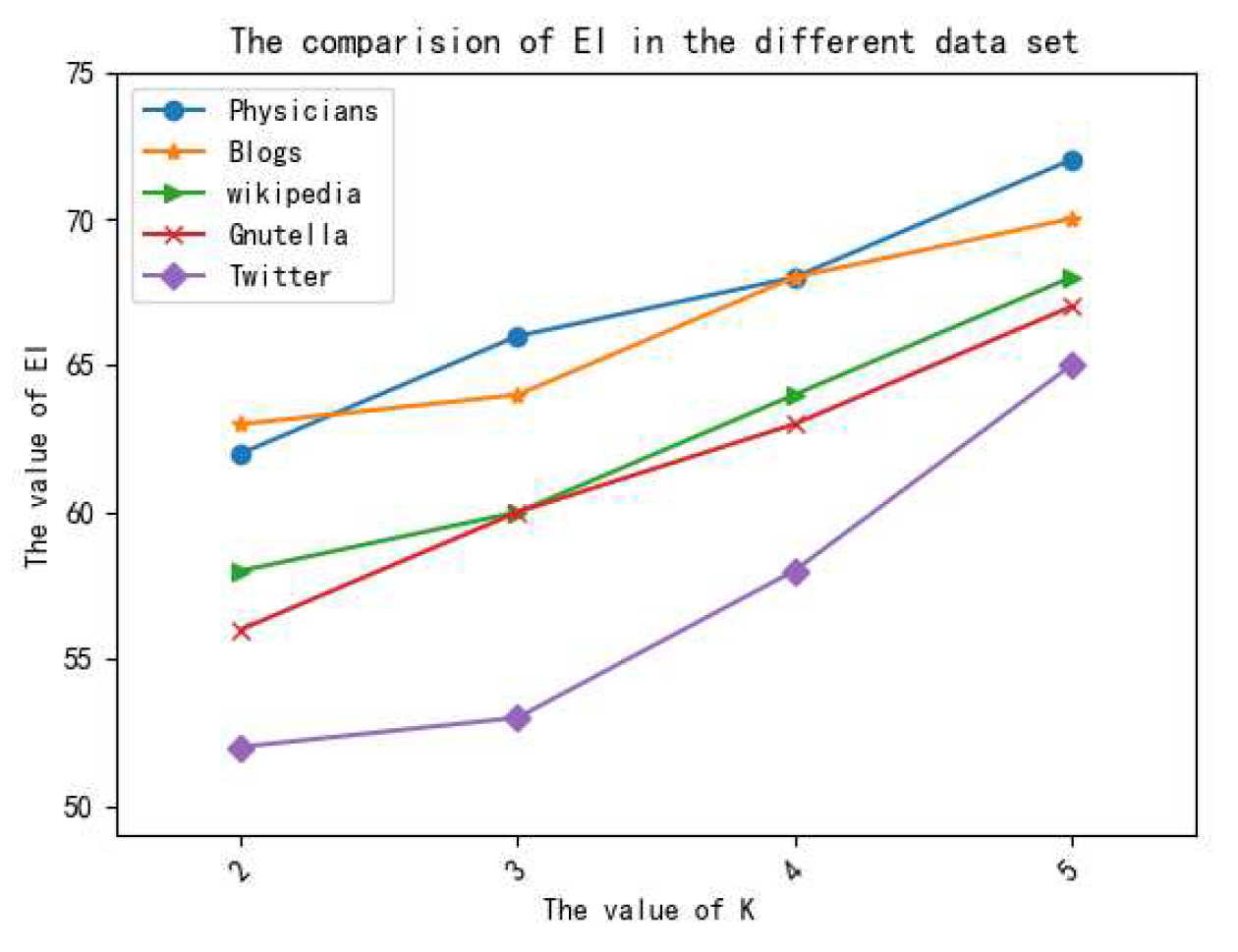
5.3.1. Analysis of Privacy Preservation
5.3.2. Analysis of Data Utility
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Letaief, K.B.; Chen, W.; Shi, Y.; Shi, Y.; Zhang, J.; Zhang, Y.J.A. The roadmap to 6G: AI empowered wireless networks. IEEE Commun. Mag. 2019, 57, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Sharma, T.; Chehri, A.; Fortier, P. Review of optical and wireless backhaul networks and emerging trends of next generation 5G and 6G technologies. Trans. Emerg. Telecommun. Technol. 2021, 32, e4155. [Google Scholar] [CrossRef]
- Van Hoboken, J.; Fathaigh, R.O. Smartphone platforms as privacy regulators. Comput. Law Secur. Rev. 2021, 41, 105557. [Google Scholar] [CrossRef]
- Weichbroth, P.; Łysik, Ł. Mobile security: Threats and best practices. Mob. Inf. Syst. 2020, 2020, 8828078. [Google Scholar] [CrossRef]
- Liu, K.K.; Terzi, E. Towards Identity Anonymization on Graphs. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008. [Google Scholar]
- Casas-Roma, J.; Herrera-Joancomartı, J.; Torra, V. A survey of graph-modification techniques for privacy-preserving on networks. Artif. Intell. Rev. 2017, 47, 341–366. [Google Scholar] [CrossRef]
- Ying, X.; Wu, X. Randomizing Social Networks: A Spectrum Preserving Approach. In Proceedings of the SIAM International Conference on Data Mining, SDM, Atlanta, GA, USA, 24–26 April 2008. [Google Scholar]
- Mortazavi, R.; Erfani, S.H. GRAM: An efficient (k, l) graph anonymization method. Expert Syst. Appl. 2020, 153, 113454. [Google Scholar] [CrossRef]
- Tai, C.H.; Yu, P.S.; Yang, D.N.; Chen, M.S. Privacy-Preserving Social Network Publication Against Friendship Attacks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 April 2011. [Google Scholar]
- Zhou, B.; Pei, J.; Luk, W.S. A Brief Survey on Anonymization Techniques for Privacy Preserving Publishing of Social Network Data. ACM Sigkdd Explor. Newsl. 2008, 10, 12–22. [Google Scholar] [CrossRef]
- Tian, Y.L.; Zhang, Z.Y.; Xiong, J.; Chen, L.; Ma, J.F. Achieving graph clustering privacy preservation based on structure entropy in social IoT. IEEE Internet Things J. 2021, 9, 2761–2777. [Google Scholar] [CrossRef]
- Zhang, H.; Lin, L.; Xu, L.; Wang, X. Graph partition based privacy-preserving scheme in social networks. J. Netw. Comput. Appl. 2021, 195, 103214. [Google Scholar] [CrossRef]
- Dwork, C. Differential Privacy. In International Colloquium on Automata, Languages, and Programming; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Jiang, H.; Pei, J.; Yu, D.; Yu, J.; Gong, B.; Cheng, X. Applications of differential privacy in social network analysis: A survey. IEEE Trans. Knowl. Data Eng. 2021, 35, 108–127. [Google Scholar] [CrossRef]
- Lan, S.; Xin, H.; Yingjie, W.; Yongyi, G. Sensitivity reduction of degree histogram publication under node differential privacy via mean filtering. Concurr. Comput. Pract. Exp. 2021, 33, e5621. [Google Scholar] [CrossRef]
- Cheng, X.; Su, S.; Xu, S.; Xiong, L.; Xiao, K.; Zhao, M. A two-phase algorithm for differentially private frequent subgraph mining. IEEE Trans. Knowl. Data Eng. 2018, 30, 1411–1425. [Google Scholar] [CrossRef] [PubMed]
- Ding, X.; Zhang, X.; Bao, Z.; Jin, H. Privacy-Preserving Triangle Counting in Large Graphs. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018. [Google Scholar]
- Karwa, V.; Slavković, A. Inference using noisy degrees: Differentially private β-model and synthetic graphs. Ann. Stat. 2016, 44, 87–122. [Google Scholar] [CrossRef]
- Iftikhar, M.; Wang, Q.; Lin, Y. dK-Microaggregation: Anonymizing Graphs with Differential Privacy Guarantees. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Casas-Roma, J.; Salas, J.; Malliaros, F.D.; Vazirgiannis, M. k-Degree anonymity on directed networks. Knowl. Inf. Syst. 2019, 61, 1743–1768. [Google Scholar] [CrossRef]
- Zhang, X.L.; Liu, J.; Bi, H.J.; Li, J.; Wang, A.Y. Personalized K-InOut-Degree Anonymity Method for Large-scale Social Networks Based on Hierarchical Community Structure. Int. J. Netw. Secur. 2021, 23, 314–325. [Google Scholar]
- Casas-Roma, J. Privacy-Preserving on Graphs Using Randomization and Edge-Relevance. In Proceedings of the Modeling Decisions for Artificial Intelligence, Tokyo, Japan, 29–31 October 2014. [Google Scholar]
- Yu, F.; Chen, M.; Yu, B.; Li, W.; Ma, L.; Gao, H. Privacy preservation based on clustering perturbation algorithm for social network. Multimed. Tools Appl. 2018, 77, 11241–11258. [Google Scholar] [CrossRef]
- Boldi, P.; Bonchi, F.; Gionis, A.; Tassa, T. Injecting uncertainty in graphs for identity obfuscation. Proc. Vldb Endow. 2012, 5, 1376–1387. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Yan, J.; Liu, Z.W.Z.H.; Zhou, Y.H. A Privacy-Preserving Approach in Friendly-Correlations of Graph Based on Edge-Differential Privacy. J. Inf. Sci. Eng. 2019, 35, 821–837. [Google Scholar]
- Macwan, K.R.; Patel, S.J. k-NMF Anonymization in Social Network Data Publishing. Computer J. 2018, 61, 601–613. [Google Scholar] [CrossRef]
- Medková, J. Anonymization of Geosocial Network Data by the (k, l)-Degree Method with Location Entropy Edge Selection. In Proceedings of the 15th International Conference on Availability, Reliability and Security, Online, 25–28 August 2020. [Google Scholar]
- Kadhiwala, B.; Patel, S.J. A Novel k-Anonymization Approach to Prevent Insider Attack in Collaborative Social Network Data Publishing. In Proceedings of the International Conference on ISS, Hyderabad, India, 16–20 December 2019. [Google Scholar]
- Iftikhar, M.; Wang, Q. dK-Projection: Publishing Graph Joint Degree Distribution with Node Differential Privacy. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Delhi, India, 11–14 May 2021; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Sun, H.; Xiao, X.; Khalil, I.; Yang, Y.; Qin, Z.; Wang, H.; Yu, T. Analyzing Subgraph Statistics from Extended Local Views with Decentralized Differential Privacy. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019. [Google Scholar]
- Lv, T.; Li, H.; Tang, Z.; Fu, F.; Cao, J.; Zhang, J. Publishing Triangle Counting Histogram in Social Networks Based on Differential Privacy. Secur. Commun. Netw. 2021, 2021, 7206179. [Google Scholar] [CrossRef]
- Task, C.; Clifton, C. What Should We Protect? Defining Differential Privacy for Social Network Analysis. In State of the Art Applications of Social Network Analysis; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Karwa, V.; Slavković, A.B. Differentially Private Graphical Degree Sequences and Synthetic Graphs. In Proceedings of the International Conference on Privacy in Statistical Databases, Palermo, Italy, 26–28 September 2012. [Google Scholar]
- Qin, Z.; Yu, T.; Yang, Y.; Khalil, I.; Xiao, X.; Ren, K. Generating Synthetic Decentralized Social Graphs with Local Differential Privacy. Proceedings of Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Xueqin, Z.; Qianru, Z.; Chunhua, G. Published Weighted Social Networks Privacy Preservation Based on Community Division. In Proceedings of the Conference on Communication and Network Security, Tokyo, Japan, 24–26 November 2017. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| K | Physicians | Hamsterster Friendships | Wikipedia−Link | Gnutella | Twitter Lists | |
|---|---|---|---|---|---|---|
| 3 | 0.2 | 72.32 | 74.38 | 69.13 | 71.38 | 68.18 |
| 3 | 0.5 | 61.25 | 58.23 | 57.79 | 60.32 | 56.67 |
| 3 | 1 | 50.13 | 47.62 | 57.21 | 49.76 | 45.23 |
| 3 | 1.5 | 43.62 | 41.87 | 38.11 | 43.98 | 40.62 |
| 3 | 2 | 38.78 | 36.05 | 25.74 | 36.32 | 34.17 |
| K | Physicians | Hamsterster Friendships | Wikipedia−Link | Gnutella | Twitter Lists | |
|---|---|---|---|---|---|---|
| 2 | 1 | 56.39 | 52.14 | 50.89 | 54.67 | 51.22 |
| 3 | 1 | 50.13 | 47.62 | 45.21 | 49.76 | 45.23 |
| 4 | 1 | 45.82 | 43.68 | 40.31 | 45.33 | 41.87 |
| 5 | 1 | 41.22 | 39.98 | 36.74 | 40.79 | 38.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, J.; Zhou, Y.; Lu, L. A Node Differential Privacy-Based Method to Preserve Directed Graphs in Wireless Mobile Networks. Appl. Sci. 2023, 13, 8089. https://doi.org/10.3390/app13148089
Yan J, Zhou Y, Lu L. A Node Differential Privacy-Based Method to Preserve Directed Graphs in Wireless Mobile Networks. Applied Sciences. 2023; 13(14):8089. https://doi.org/10.3390/app13148089
Chicago/Turabian StyleYan, Jun, Yihui Zhou, and Laifeng Lu. 2023. "A Node Differential Privacy-Based Method to Preserve Directed Graphs in Wireless Mobile Networks" Applied Sciences 13, no. 14: 8089. https://doi.org/10.3390/app13148089
APA StyleYan, J., Zhou, Y., & Lu, L. (2023). A Node Differential Privacy-Based Method to Preserve Directed Graphs in Wireless Mobile Networks. Applied Sciences, 13(14), 8089. https://doi.org/10.3390/app13148089