
Efficient Information-Theoretic Large-Scale Semi-Supervised Metric Learning via Proxies


Abstract
:1. Introduction
- We propose a novel information-theoretic-based SSDML method called ISMLP, which simultaneously learns multiple proxy vectors as well as the Mahalanobis matrix. Specifically, we adopt the entropy regularization to mine the discriminant information of the unlabeled data.
- The merits of the proposed ISMLP lie in two folds: on the one hand, compared to those manifold-based SSDML methods, ISMLP does not rely on manifold assumptions. Thus, it can be applied to border scenes; the time complexity of ISMLP is linear with respect to the number of training instances, and thus can be easily extended to large-scale datasets.
- Extensive experimental results on classification and retrieval experiments can validate the superiority performance and in the meantime can be trained more efficiently than those compared methods.
2. Related Work
SERAPH Framework
3. Information-Theoretic Large-Scale Semi-Supervised Metric Learning via Proxies
3.1. Notations and Problem Definition
3.2. Learning From Proxy Vectors
3.3. Entropy Regularization
3.4. Joint Dimensional Reduction and Metric Learning
4. Optimization for ISMLP
| Algorithm 1: The optimization strategy of ISMLP. |

Output: The projection matrix and low-dimensionality Mahalanobis matrix ; |
Time Complexity of ISMLP
- Since the time complexity of solving the inverse of a matrix costs , evaluating the objective function in Equation (11) takes .
- Solving all the proxy vectors by using Equation (29) cost , where is the number of labeled data.
5. Experiment
5.1. Datasets, Evaluation Protocol and Compared Methods
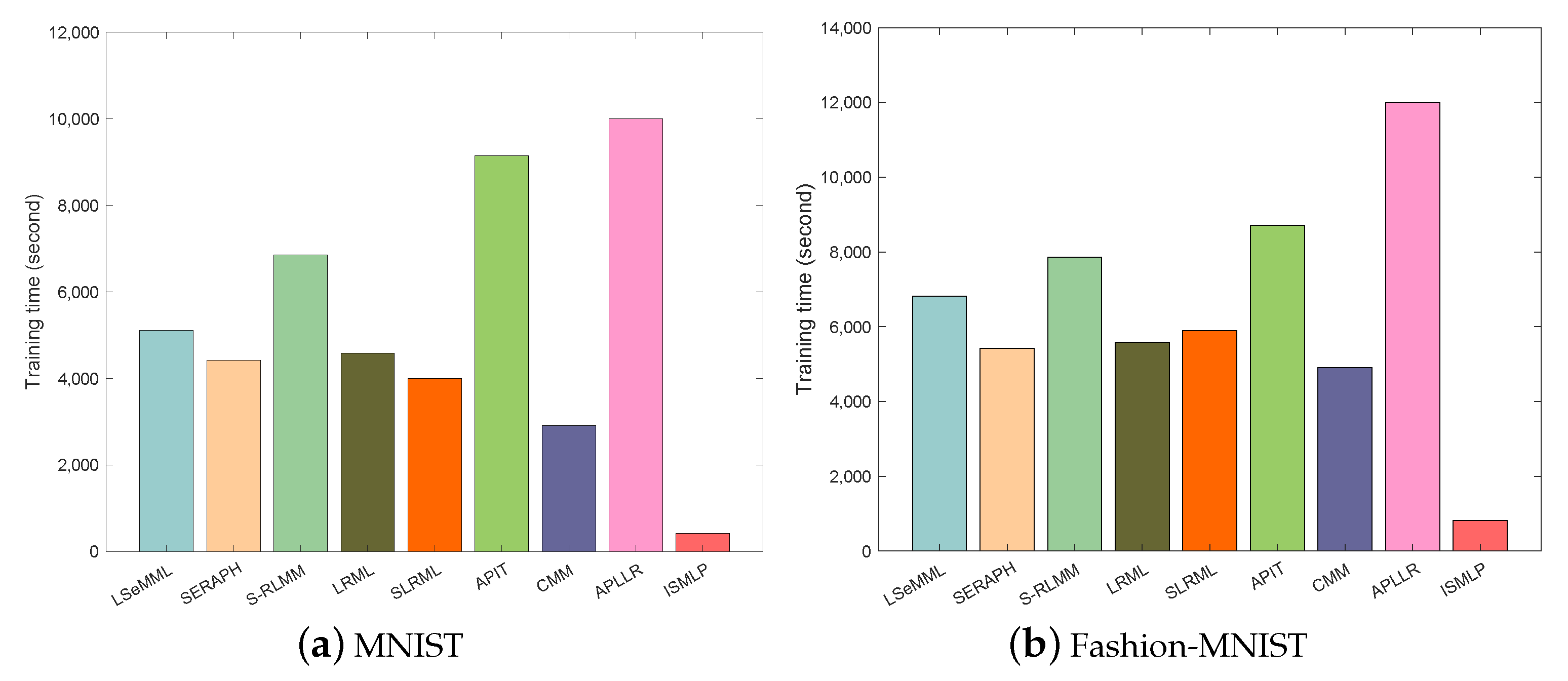
5.2. Classification Experimental Result on MNIST and Fashion-MNIST Datasets
5.3. Retrieval Performance on Corel 5K Dataset
5.4. Classification Performance on CUB-200 and Cars-196 Datasets
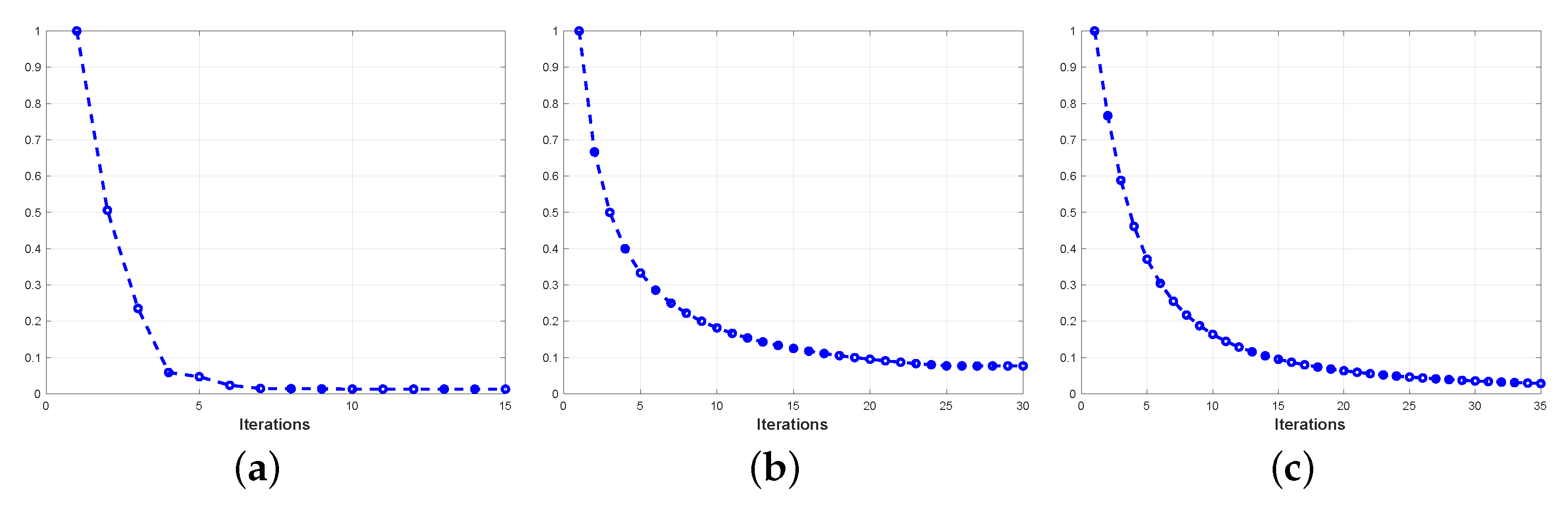
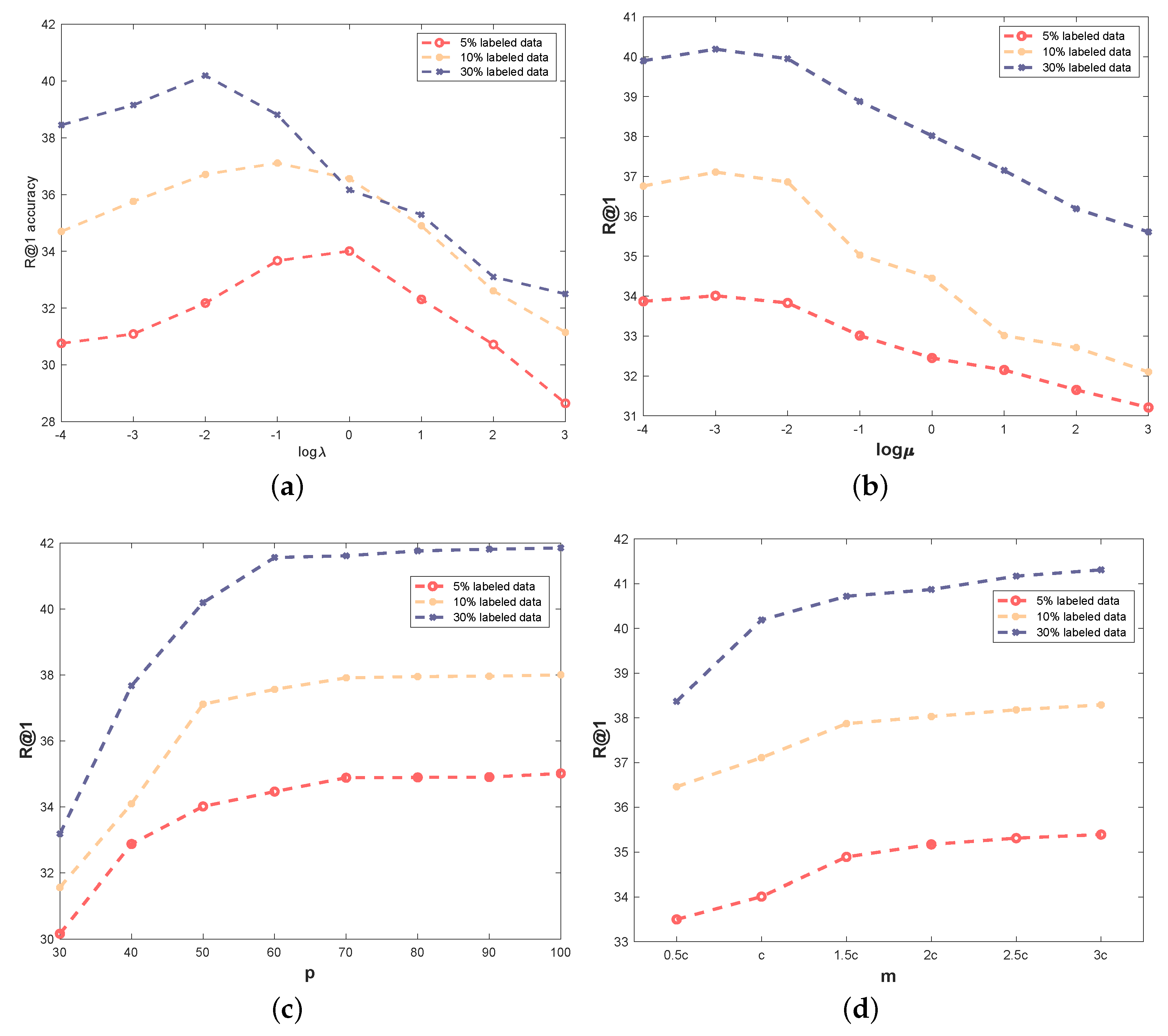
5.5. Sensitivity Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, F. Semisupervised Metric Learning by Maximizing Constraint Margin. IEEE Trans. Syst. Man Cybern. Part B Cybern. A Publ. IEEE Syst. Man Cybern. Soc. 2011, 41, 931–939. [Google Scholar] [CrossRef]
- Bellet, A.; Habrard, A.; Sebban, M. Metric Learning; Springer Nature: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Wang, H.; Feng, L.; Zhang, J.; Liu, Y. Semantic Discriminative Metric Learning for Image Similarity Measurement. IEEE Trans. Multimed. 2016, 18, 1579–1589. [Google Scholar] [CrossRef]
- Feng, L.; Wang, H.; Jin, B.; Li, H.; Xue, M.; Wang, L. Learning a Distance Metric by Balancing KL-Divergence for Imbalanced Datasets. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 2384–2395. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Y.; Zhang, Z.; Fu, X.; Zhuo, L.; Xu, M.; Wang, M. Kernelized multiview subspace analysis by self-weighted learning. IEEE Trans. Multimed. 2020, 23, 3828–3840. [Google Scholar] [CrossRef]
- Wang, H.; Peng, J.; Chen, D.; Jiang, G.; Zhao, T.; Fu, X. Attribute-guided feature learning network for vehicle reidentification. IEEE Multimed. 2020, 27, 112–121. [Google Scholar]
- Wang, H.; Peng, J.; Zhao, Y.; Fu, X. Multi-path deep cnns for fine-grained car recognition. IEEE Trans. Veh. Technol. 2020, 69, 10484–10493. [Google Scholar] [CrossRef]
- Liu, Q.; Cao, W.; He, Z. Cycle optimization metric learning for few-shot classification. Pattern Recognit. 2023, 139, 109468. [Google Scholar] [CrossRef]
- Holkar, A.; Walambe, R.; Kotecha, K. Few-shot learning for face recognition in the presence of image discrepancies for limited multi-class datasets. Image Vis. Comput. 2022, 120, 104420. [Google Scholar]
- Gao, X.; Niu, S.; Wei, D.; Liu, X.; Wang, T.; Zhu, F.; Dong, J.; Sun, Q. Joint metric learning-based class-specific representation for image set classification. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Huang, K.; Wu, S.; Sun, B.; Yang, C.; Gui, W. Metric learning-based fault diagnosis and anomaly detection for industrial data with intraclass variance. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Gui, X.; Zhang, J.; Tang, J.; Xu, H.; Zou, J.; Fan, S. A Quadruplet Deep Metric Learning model for imbalanced time-series fault diagnosis. Knowl.-Based Syst. 2022, 238, 107932. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Peng, J.; Jiang, G.; Wang, H. Adaptive Memorization with Group Labels for Unsupervised Person Re-identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 1. [Google Scholar] [CrossRef]
- Wang, H.; Peng, J.; Jiang, G.; Xu, F.; Fu, X. Discriminative feature and dictionary learning with part-aware model for vehicle re-identification. Neurocomputing 2021, 438, 55–62. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, J.; Wang, H.; Wang, M. Progressive learning with multi-scale attention network for cross-domain vehicle re-identification. Sci. China Inf. Sci. 2022, 65, 160103. [Google Scholar] [CrossRef]
- Liu, W.; Ma, S.; Tao, D.; Liu, J.; Liu, P. Semi-supervised sparse metric learning using alternating linearization optimization. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 1139–1148. [Google Scholar]
- Baghshah, M.S.; Shouraki, S.B. Semi-supervised metric learning using pairwise constraints. In Proceedings of the 21st International Joint Conference on Artificial Intelligence, Pasadena, CA, USA, 11–17 July 2009; pp. 1217–1222. [Google Scholar]
- Liang, J.; Zhu, P.; Dang, C.; Hu, Q. Semisupervised Laplace-Regularized Multimodality Metric Learning. IEEE Trans. Cybern. 2020, 52, 2955–2967. [Google Scholar] [CrossRef]
- Ying, S.; Wen, Z.; Shi, J.; Peng, Y.; Peng, J.; Qiao, H. Manifold preserving: An intrinsic approach for semisupervised distance metric learning. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 2731–2742. [Google Scholar] [CrossRef]
- Kr Dutta, U.; Chandra Sekhar, C. Affinity Propagation Based Closed-Form Semi-supervised Metric Learning Framework. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2018: 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Proceedings, Part I 27. Springer: Berlin/Heidelberg, Germany, 2018; pp. 556–565. [Google Scholar]
- Sun, P.; Yang, L. Low-rank supervised and semi-supervised multi-metric learning for classification. Knowl.-Based Syst. 2022, 236, 107787. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Jiang, G.; Peng, J.; Deng, R.; Fu, X. Towards Adaptive Consensus Graph: Multi-view Clustering via Graph Collaboration. IEEE Trans. Multimed. 2022, 1–13. [Google Scholar] [CrossRef]
- Jiang, G.; Peng, J.; Wang, H.; Mi, Z.; Fu, X. Tensorial Multi-View Clustering via Low-Rank Constrained High-Order Graph Learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5307–5318. [Google Scholar] [CrossRef]
- Yin, Y.; Shah, R.R.; Zimmermann, R. Learning and fusing multimodal deep features for acoustic scene categorization. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1892–1900. [Google Scholar]
- Wang, H.; Yao, M.; Jiang, G.; Mi, Z.; Fu, X. Graph-Collaborated Auto-Encoder Hashing for Multiview Binary Clustering. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–13. [Google Scholar] [CrossRef]
- Niu, G.; Dai, B.; Yamada, M.; Sugiyama, M. Information-theoretic semi-supervised metric learning via entropy regularization. Neural Comput. 2014, 26, 1717–1762. [Google Scholar] [CrossRef]
- Li, Y.; Tian, X.; Tao, D. Regularized large margin distance metric learning. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016; pp. 1015–1022. [Google Scholar]
- Ye, H.J.; Zhan, D.C.; Li, N.; Jiang, Y. Learning multiple local metrics: Global consideration helps. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1698–1712. [Google Scholar] [CrossRef]
- Movshovitz-Attias, Y.; Toshev, A.; Leung, T.K.; Ioffe, S.; Singh, S. No fuss distance metric learning using proxies. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 360–368. [Google Scholar]
- Goldberger, J.; Hinton, G.E.; Roweis, S.; Salakhutdinov, R.R. Neighbourhood components analysis. Adv. Neural Inf. Process. Syst. 2004, 17. [Google Scholar]
- Hoi, S.C.; Liu, W.; Chang, S.F. Semi-supervised distance metric learning for collaborative image retrieval and clustering. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2010, 6, 1–26. [Google Scholar] [CrossRef]
- Deng, H.; Meng, X.; Deng, F.; Feng, L. UNIT: A unified metric learning framework based on maximum entropy regularization. Appl. Intell. 2023, 1–21. [Google Scholar] [CrossRef]
- Chapelle, O.; Zien, A. Semi-supervised classification by low density separation. In Proceedings of the International Workshop on Artificial Intelligence and Statistics, PMLR, Bridgetown, Barbados, 6–8 January 2005; pp. 57–64. [Google Scholar]
- Grandvalet, Y.; Bengio, Y. Semi-supervised learning by entropy minimization. Adv. Neural Inf. Process. Syst. 2004, 17. [Google Scholar]
- Harandi, M.; Salzmann, M.; Hartley, R. Joint dimensionality reduction and metric learning: A geometric take. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1404–1413. [Google Scholar]
- Davis, J.V.; Kulis, B.; Jain, P.; Sra, S.; Dhillon, I.S. Information-theoretic metric learning. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 209–216. [Google Scholar]
- Absil, P.A.; Mahony, R.; Sepulchre, R. Optimization Algorithms on Matrix Manifolds; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- Lee, J.M.; Lee, J.M. Smooth Manifolds; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Bonnabel, S. Stochastic gradient descent on Riemannian manifolds. IEEE Trans. Autom. Control 2013, 58, 2217–2229. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Duygulu, P.; Barnard, K.; de Freitas, J.F.; Forsyth, D.A. Object recognition as machine translation: Learning a lexicon for a fixed image vocabulary. In Proceedings of the 7th European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002; pp. 97–112. [Google Scholar]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. Caltech-UCSD Birds 200; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Dutta, U.K.; Harandi, M.; Shekhar, C.C. Semi-supervised metric learning: A deep resurrection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 7279–7287. [Google Scholar]
- Nguyen, B.; Ferri, F.J.; Morell, C.; De Baets, B. An efficient method for clustered multi-metric learning. Inf. Sci. 2019, 471, 149–163. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, W.; Wu, L.; Lin, X.; Fang, M.; Pan, S. Iterative Views Agreement: An Iterative Low-Rank based Structured Optimization Method to Multi-View Spectral Clustering. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016; pp. 2153–2159. [Google Scholar]
- Wang, Y. Survey on deep multi-modal data analytics: Collaboration, rivalry, and fusion. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–25. [Google Scholar]
- Deng, H.; Meng, X.; Wang, H.; Feng, L. Hierarchical multi-view metric learning with HSIC regularization. Neurocomputing 2022, 510, 135–148. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Class | Instance | Feature | Train, Validation, Test |
|---|---|---|---|---|---|
| MNIST | Image | 10 | 70,000 | 784 | 50,000, 10,000, 10,000 |
| Fashion-MNIST | Image | 10 | 70,000 | 784 | 50,000, 10,000, 10,000 |
| Corel 5K | Image | 50 | 5000 | 2048 | 4000, 500, 500 |
| CUB-200 | Image | 200 | 11,788 | 2048 | 4994, 1000, 5794 |
| Cars-196 | Image | 196 | 16,185 | 2048 | 7144, 1000, 8041 |
| EUCLID | LSeMML | SERAPH | S-RLMM | LRML | SLRML | APIT | CMM | APLLR | LMNN | SSML-DR | ISMLP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5% labeled data | 0.296 ± 0.005 | 0.228 ± 0.010 | 0.231 ± 0.014 | 0.241 ± 0.027 | 0.221 ± 0.011 | 0.208 ± 0.008 | 0.228 ± 0.010 | 0.245 ± 0.021 | 0.209 ± 0.022 | 0.261 ± 0.022 | 0.200 ± 0.013 | 0.211 ± 0.018 |
| 10% labeled data | 0.240 ± 0.007 | 0.191 ± 0.013 | 0.184 ± 0.011 | 0.211 ± 0.016 | 0.201 ± 0.010 | 0.221 ± 0.015 | 0.198 ± 0.011 | 0.227 ± 0.017 | 0.189 ± 0.009 | 0.231 ± 0.021 | 0.175 ± 0.012 | 0.170 ± 0.015 |
| 30% labeled data | 0.186 ± 0.006 | 0.131 ± 0.012 | 0.140 ± 0.007 | 0.127 ± 0.014 | 0.153 ± 0.012 | 0.130 ± 0.009 | 0.146 ± 0.008 | 0.150 ± 0.016 | 0.128 ± 0.007 | 0.143 ± 0.010 | 0.120 ± 0.016 | 0.116 ± 0.011 |
| EUCLID | LSeMML | SERAPH | S-RLMM | LRML | SLRML | APIT | CMM | APLLR | LMNN | SSML-DR | ISMLP | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5% labeled data | 0.355 ± 0.008 | 0.281 ± 0.017 | 0.289 ± 0.014 | 0.291 ± 0.017 | 0.295 ± 0.012 | 0.278 ± 0.008 | 0.298 ± 0.012 | 0.302 ± 0.012 | 0.285 ± 0.013 | 0.292 ± 0.019 | 0.248 ± 0.010 | 0.252 ± 0.014 |
| 10% labeled data | 0.281 ± 0.009 | 0.242 ± 0.012 | 0.248 ± 0.011 | 0.237 ± 0.012 | 0.241 ± 0.017 | 0.239 ± 0.007 | 0.247 ± 0.013 | 0.258 ± 0.016 | 0.227 ± 0.012 | 0.261 ± 0.010 | 0.218 ± 0.009 | 0.210 ± 0.012 |
| 30% labeled data | 0.235 ± 0.006 | 0.180 ± 0.014 | 0.172 ± 0.009 | 0.178 ± 0.012 | 0.172 ± 0.011 | 0.181 ± 0.008 | 0.187 ± 0.011 | 0.191 ± 0.013 | 0.188 ± 0.012 | 0.192 ± 0.010 | 0.168 ± 0.011 | 0.162 ± 0.012 |
| LSeMML | SERAPH | S-RLMM | LRML | SLRML | APIT | CMM | ISMLP | |
|---|---|---|---|---|---|---|---|---|
| Time complexity |
| 5%Labeled Data | 10%Labeled Data | 30%Labeled Data | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@2 | R@4 | R@8 | R@1 | R@2 | R@4 | R@8 | R@1 | R@2 | R@4 | R@8 | |
| EUCLID | 25.75 | 29.82 | 32.73 | 34.82 | 26.85 | 32.57 | 34.12 | 36.45 | 29.68 | 32.22 | 36.90 | 39.29 |
| LSeMML | 32.84 | 34.54 | 36.90 | 38.73 | 34.53 | 36.72 | 38.13 | 40.65 | 35.90 | 37.81 | 39.72 | 42.20 |
| SERAPH | 33.11 | 35.61 | 37.81 | 39.98 | 35.02 | 36.87 | 38.42 | 41.97 | 37.83 | 39.24 | 42.69 | 44.73 |
| S-RLMM | 32.83 | 34.81 | 36.31 | 38.71 | 34.63 | 36.59 | 38.20 | 40.21 | 38.80 | 40.68 | 42.98 | 43.73 |
| LRML | 31.10 | 33.68 | 36.83 | 38.50 | 33.76 | 35.80 | 37.81 | 39.69 | 37.33 | 39.84 | 42.38 | 44.16 |
| SLRML | 33.63 | 34.19 | 37.24 | 39.42 | 35.82 | 37.67 | 39.29 | 42.19 | 37.90 | 39.19 | 40.57 | 42.78 |
| APIT | 32.52 | 34.57 | 37.99 | 38.68 | 34.68 | 36.85 | 39.09 | 36.98 | 37.81 | 40.83 | 42.68 | 44.73 |
| CMM | 32.13 | 34.11 | 36.73 | 38.10 | 34.82 | 37.40 | 37.49 | 39.80 | 37.86 | 40.13 | 41.68 | 42.68 |
| APLLR | 31.16 | 33.29 | 35.73 | 37.96 | 33.24 | 36.76 | 39.85 | 42.48 | 36.66 | 39.83 | 42.08 | 45.71 |
| LMNN | 29.71 | 32.90 | 35.84 | 37.80 | 31.84 | 33.59 | 37.85 | 39.84 | 33.83 | 35.49 | 39.90 | 41.83 |
| SSML-DR | 34.00 | 35.95 | 38.34 | 40.50 | 36.84 | 39.00 | 43.19 | 45.54 | 38.26 | 42.18 | 45.40 | 48.21 |
| ISMLP | 34.42 | 36.82 | 38.90 | 41.70 | 36.99 | 39.24 | 44.45 | 46.02 | 39.84 | 42.80 | 45.61 | 48.90 |
| 5%Labeled Data | 10%Labeled Data | 30%Labeled Data | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@2 | R@4 | R@8 | R@1 | R@2 | R@4 | R@8 | R@1 | R@2 | R@4 | R@8 | |
| EUCLID | 24.63 | 28.16 | 31.34 | 34.73 | 25.68 | 30.65 | 33.87 | 35.71 | 28.56 | 31.89 | 34.17 | 38.81 |
| LSeMML | 33.26 | 34.54 | 37.15 | 39.27 | 34.58 | 37.18 | 39.46 | 42.17 | 36.19 | 39.43 | 41.87 | 44.98 |
| SERAPH | 32.19 | 34.61 | 36.25 | 39.89 | 35.18 | 37.26 | 39.48 | 43.16 | 37.30 | 39.56 | 42.43 | 45.25 |
| S-RLMM | 34.37 | 36.81 | 37.18 | 39.96 | 36.58 | 38.78 | 40.41 | 44.34 | 38.48 | 41.68 | 44.15 | 47.28 |
| LRML | 32.82 | 35.33 | 36.83 | 37.41 | 33.72 | 35.41 | 37.19 | 39.71 | 38.18 | 41.29 | 43.21 | 45.87 |
| SLRML | 34.37 | 36.19 | 38.98 | 40.57 | 35.42 | 38.42 | 40.76 | 43.87 | 37.57 | 39.58 | 42.81 | 46.10 |
| APIT | 33.46 | 35.72 | 37.99 | 39.51 | 34.71 | 36.78 | 39.18 | 41.57 | 38.24 | 41.58 | 43.79 | 46.28 |
| CMM | 34.19 | 35.45 | 36.73 | 39.10 | 35.88 | 38.04 | 40.00 | 43.06 | 37.60 | 39.87 | 41.81 | 45.28 |
| APLLR | 32.67 | 35.34 | 35.73 | 37.76 | 33.26 | 36.87 | 39.19 | 42.62 | 36.62 | 39.89 | 42.28 | 45.78 |
| LMNN | 31.30 | 33.53 | 35.84 | 36.92 | 32.19 | 34.48 | 36.49 | 38.84 | 34.39 | 36.62 | 40.19 | 44.17 |
| SSML-DR | 35.35 | 37.53 | 39.47 | 41.38 | 37.01 | 39.46 | 42.87 | 44.59 | 39.84 | 42.69 | 45.92 | 47.25 |
| ISMLP | 34.01 | 36.52 | 38.72 | 40.29 | 37.11 | 40.38 | 43.48 | 45.81 | 40.19 | 43.58 | 46.39 | 48.41 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.; Wang, H. Efficient Information-Theoretic Large-Scale Semi-Supervised Metric Learning via Proxies. Appl. Sci. 2023, 13, 8993. https://doi.org/10.3390/app13158993
Chen P, Wang H. Efficient Information-Theoretic Large-Scale Semi-Supervised Metric Learning via Proxies. Applied Sciences. 2023; 13(15):8993. https://doi.org/10.3390/app13158993
Chicago/Turabian StyleChen, Peng, and Huibing Wang. 2023. "Efficient Information-Theoretic Large-Scale Semi-Supervised Metric Learning via Proxies" Applied Sciences 13, no. 15: 8993. https://doi.org/10.3390/app13158993
APA StyleChen, P., & Wang, H. (2023). Efficient Information-Theoretic Large-Scale Semi-Supervised Metric Learning via Proxies. Applied Sciences, 13(15), 8993. https://doi.org/10.3390/app13158993