

Robust Image Inpainting Forensics by Using an Attention-Based Feature Pyramid Network

Abstract
:1. Introduction
- (1)
- We use a forensic network to detect traces left by deep learning-based inpainting methods. The network employs a feature pyramid to extract multi-scale inpainting features. To fully utilize multi-scale feature information, we employ MSCA to optimize high-level features and fuse the optimized high- and low-level features for inpainting forensics. The efficacy of the attention module and feature fusion module is verified through ablation analysis.
- (2)
- We design a fusion loss function to assess the quality of not only the fused feature maps but also the high-level feature maps. Experimental results demonstrate that the fused loss function can optimize the training process and enhance the performance of our network.
- (3)
- To indicate the generalization performance of our network, we employ six state-of-the-art deep learning-based image inpainting methods to set up a diverse inpainting test dataset. Extensive experiments show that the employed AFPN can achieve good detection performance across diverse inpainting test datasets. Furthermore, we assess the robustness of the proposed methods on JPEG compression and additive noise attacks.
2. Related Works
2.1. Inpainting Forensics Methods
2.2. Attention Mechanisms
2.3. AFPN
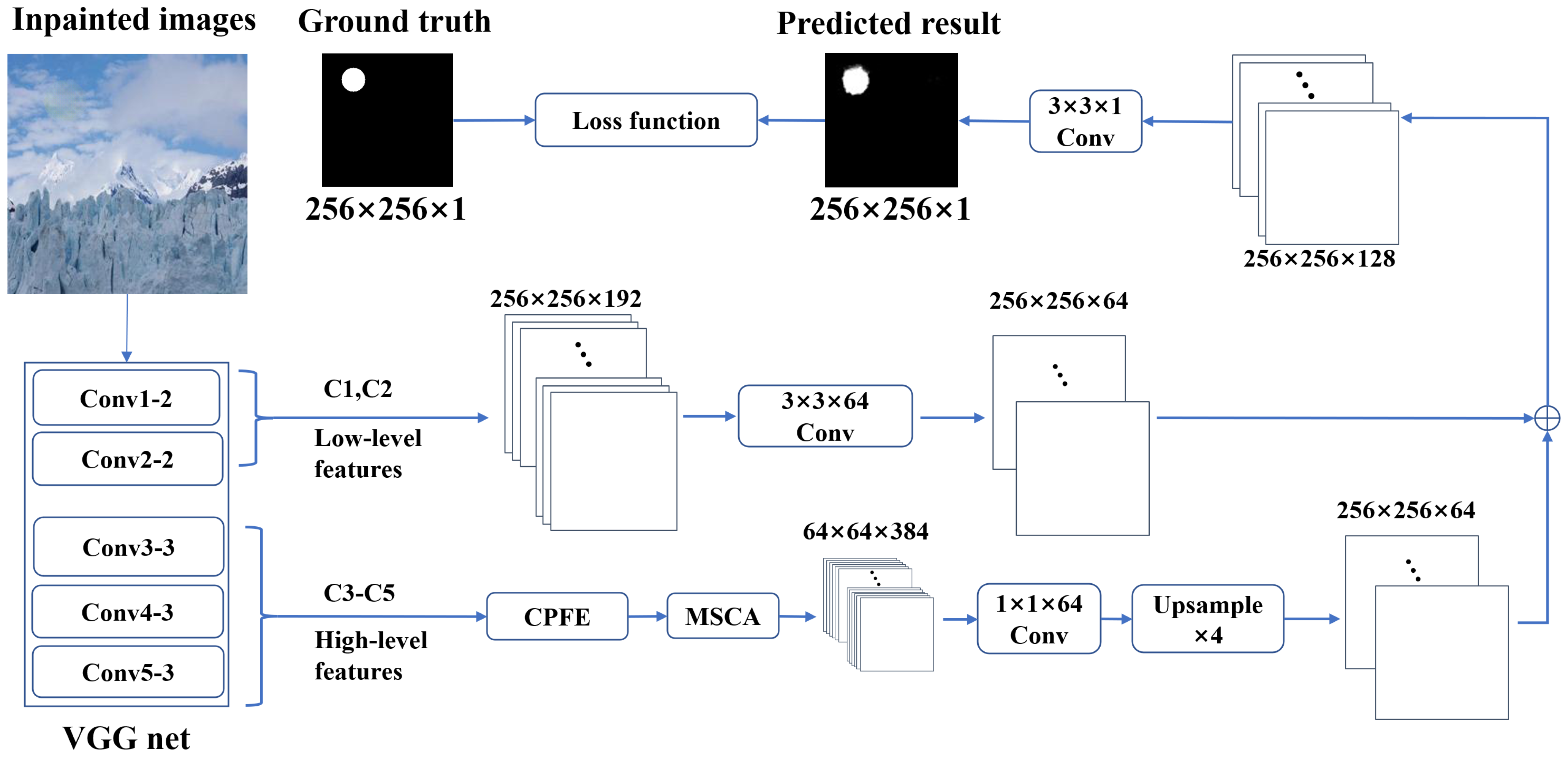
3. Methods
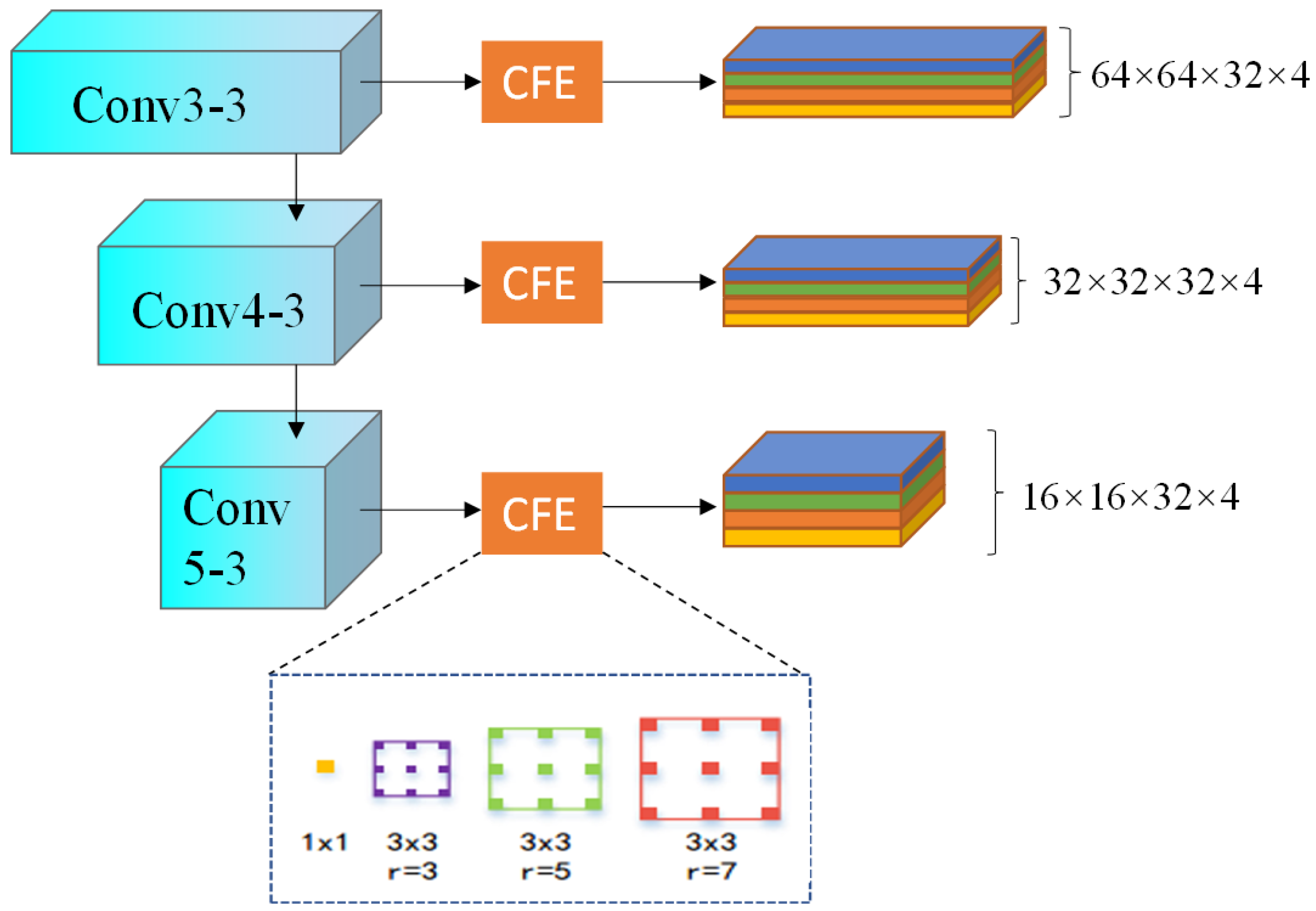
3.1. Multi-Scale Feature Extraction
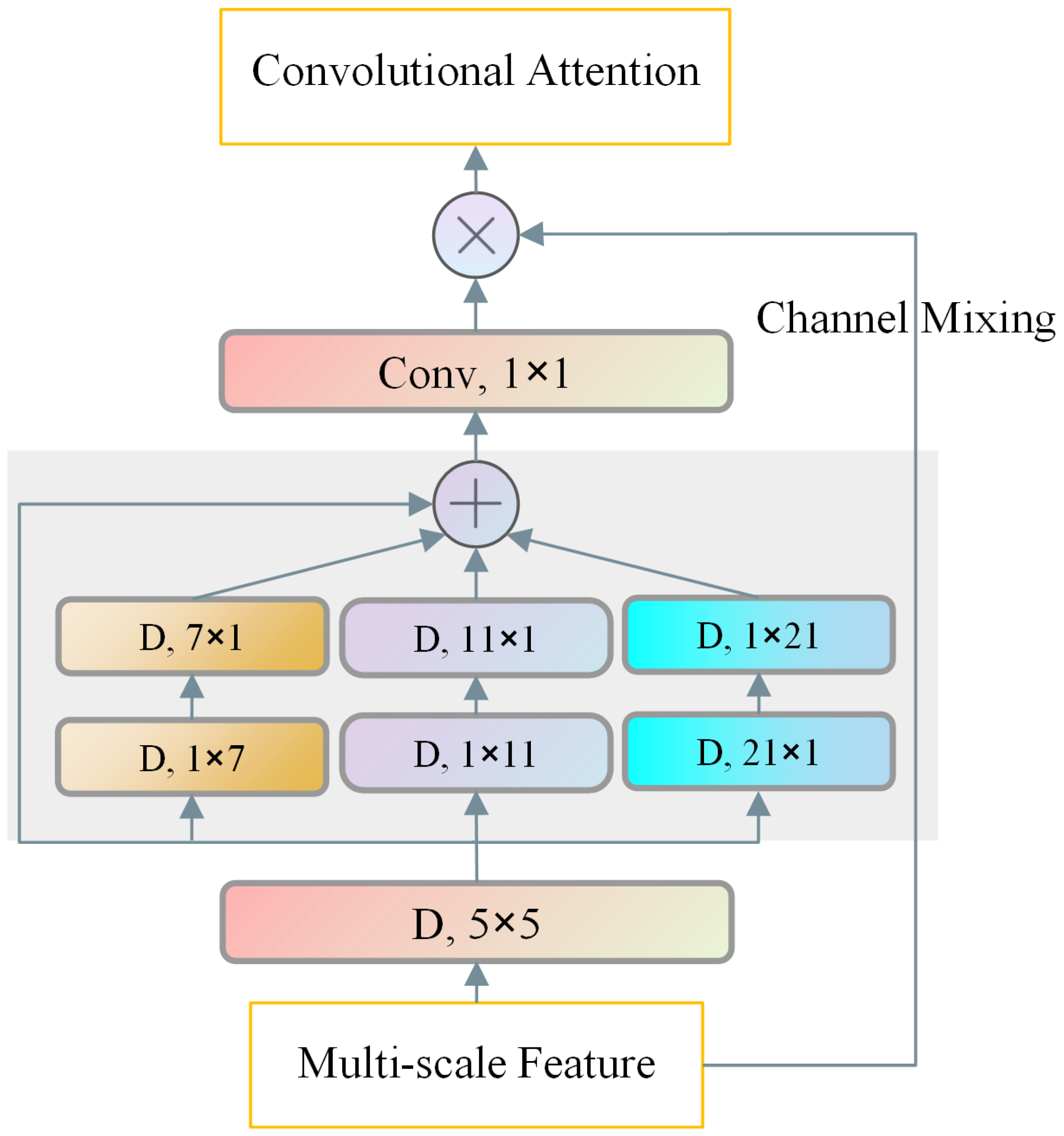
3.2. Attention Mechanism
3.3. Loss Function
4. Experiments
4.1. Training and Testing Datasets
4.2. Quantitative Comparisons
4.3. Qualitative Comparisons
4.4. Ablation Studies
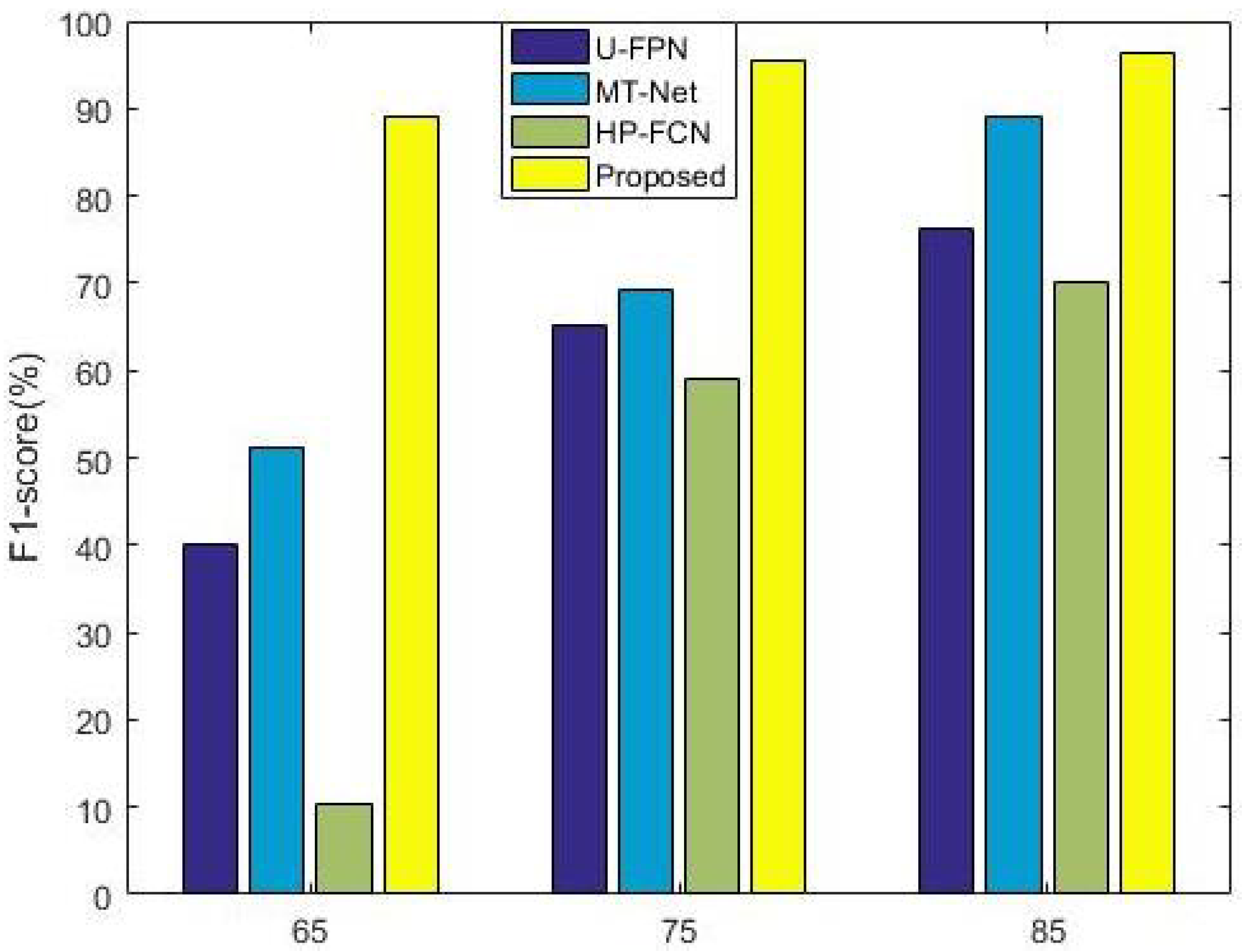
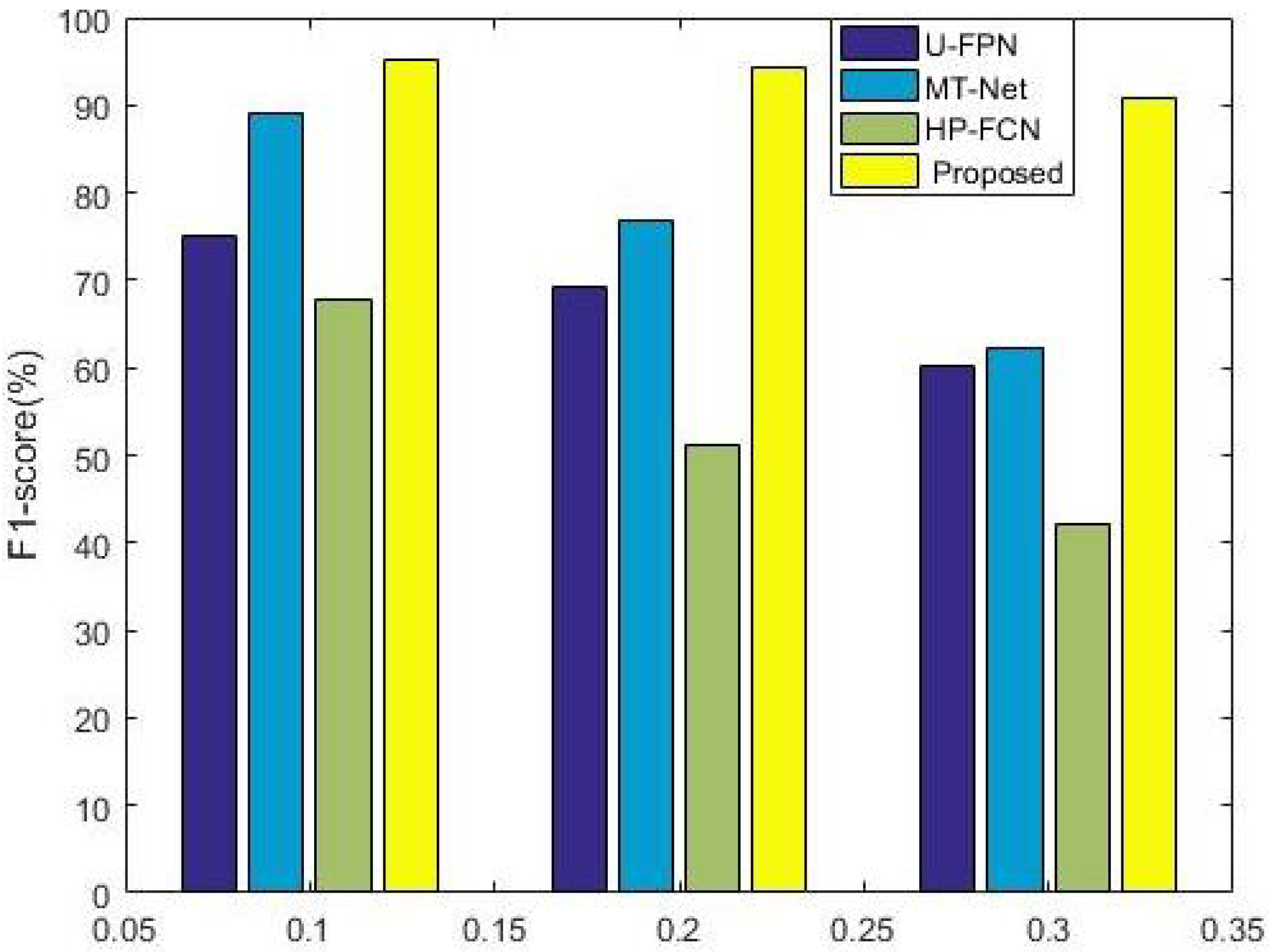
4.5. Robustness Evaluations
4.6. Limitations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tyagi, S.; Yadav, D. A detailed analysis of image and video forgery detection techniques. Vis. Comput. 2023, 39, 813–833. [Google Scholar] [CrossRef]
- Liang, Y.; Fang, Y.; Luo, S.; Chen, B. Image resampling detection based on convolutional neural network. In Proceedings of the 2019 15th International Conference on Computational Intelligence and Security (CIS), Macao, China, 13–16 December 2019; pp. 257–261. [Google Scholar]
- Lamba, M.; Mitra, K. Multi-patch aggregation models for resampling detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2967–2971. [Google Scholar]
- Ding, H.; Chen, L.; Tao, Q.; Fu, Z.; Dong, L.; Cui, X. DCU-Net: A dual-channel U-shaped network for image splicing forgery detection. Neural Comput. Appl. 2023, 35, 5015–5031. [Google Scholar]
- Babu, S.T.; Rao, C.S. Efficient detection of copy-move forgery using polar complex exponential transform and gradient direction pattern. Multimed. Tools Appl. 2023, 82, 10061–10075. [Google Scholar]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th annual conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 23–28 July 2000; pp. 417–424. [Google Scholar]
- Esedoglu, S.; Shen, J. Digital inpainting based on the Mumford–Shah–Euler image model. Eur. J. Appl. Math. 2002, 13, 353–370. [Google Scholar] [CrossRef] [Green Version]
- Hays, J.; Efros, A.A. Scene completion using millions of photographs. ACM Trans. Graph. 2007, 26, 4-es. [Google Scholar]
- Chen, Y.; Zhang, H.; Liu, L.; Tao, J.; Zhang, Q.; Yang, K.; Xia, R.; Xie, J. Research on image inpainting algorithm of improved total variation minimization method. J. Ambient. Intell. Humaniz. Comput. 2021, 14, 5555–5564. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, L.; Phonevilay, V.; Gu, K.; Xia, R.; Xie, J.; Zhang, Q.; Yang, K. Image super-resolution reconstruction based on feature map attention mechanism. App. Intell. 2021, 51, 4367–4380. [Google Scholar]
- Suvorov, R.; Logacheva, E.; Mashikhin, A.; Remizova, A.; Ashukha, A.; Silvestrov, A.; Kong, N.; Goka, H.; Park, K.; Lempitsky, V. Resolution-robust large mask inpainting with fourier convolutions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 2149–2159. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Free-form image inpainting with gated convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4471–4480. [Google Scholar]
- Zheng, C.; Cham, T.-J.; Cai, J. Pluralistic image completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1438–1447. [Google Scholar]
- Chen, Y.; Liu, L.; Tao, J.; Xia, R.; Zhang, Q.; Yang, K.; Xiong, J.; Chen, X. The improved image inpainting algorithm via encoder and similarity constraint. Vis. Comput. 2021, 37, 1691–1705. [Google Scholar]
- Zhao, S.; Cui, J.; Sheng, Y.; Dong, Y.; Liang, X.; Chang, E.I.; Xu, Y. Large scale image completion via co-modulated generative adversarial networks. arXiv 2021, arXiv:2103.10428. [Google Scholar]
- Wan, Z.; Zhang, J.; Chen, D.; Liao, J. High-fidelity pluralistic image completion with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 4692–4701. [Google Scholar]
- Wang, S.; Saharia, C.; Montgomery, C.; Pont-Tuset, J.; Noy, S.; Pellegrini, S.; Onoe, Y.; Laszlo, S.; Fleet, D.J.; Soricut, R. Imagen editor and editbench: Advancing and evaluating text-guided image inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18359–18369. [Google Scholar]
- Chang, I.; Yu, J.; Chang, C. A forgery detection algorithm for exemplar-based inpainting images using multi-region relation. Image Vis. Comput. 2013, 31, 57–71. [Google Scholar] [CrossRef]
- Li, H.; Luo, W.; Huang, J. Localization of diffusion-based inpainting in digital images. IEEE Trans. Inf. Forensics Secur. 2017, 12, 3050–3064. [Google Scholar]
- Li, H.; Huang, J. Localization of deep inpainting using high-pass fully convolutional network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8301–8310. [Google Scholar]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. Mantra-net: Manipulation tracing network for detection and localization of image forgeries with anomalous features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9543–9552. [Google Scholar]
- Wu, H.; Zhou, J. IID-Net: Image inpainting detection network via neural architecture search and attention. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1172–1185. [Google Scholar]
- Zhang, Y.; Ding, F.; Kwong, S.; Zhu, G. Feature pyramid network for diffusion-based image inpainting detection. Inf. Sci. 2021, 572, 29–42. [Google Scholar] [CrossRef]
- Zhu, X.; Lu, J.; Ren, H.; Wang, H.; Sun, B. A transformer–CNN for deep image inpainting forensics. Image Vis. Comput. 2022, 1–15. [Google Scholar] [CrossRef]
- Dong, C.; Chen, X.; Hu, R.; Cao, J.; Li, X. Mvss-net: Multi-view multi-scale supervised networks for image manipulation detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3539–3553. [Google Scholar]
- Liu, Z.; Gong, P.; Wang, J. Attention-Based feature pyramid network for object detection. In Proceedings of the 2019 8th International Conference on Computing and Pattern Recognition, Beijing, China, 23–25 October 2019; pp. 117–121. [Google Scholar]
- Wu, H.; Dong, B.; Ding, L.; Dong, Y. Attention feature pyramid network for scene text detection. In Proceedings of the 2022 IEEE 8th International Conference on Computer and Communications, Chengdu, China, 9–12 December 2022; pp. 1726–1731. [Google Scholar]
- Jiao, L.; Kang, C.; Dong, S.; Chen, P.; Li, G.; Wang, R. An attention-based feature pyramid network for single-stage small object detection. Multimed. Tools Appl. 2023, 82, 18529–18544. [Google Scholar]
- Hu, M.; Li, Y.; Fang, L.; Wang, S. A2-FPN: Attention aggregation based feature pyramid network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15343–15352. [Google Scholar]
- Sun, Y.; Dai, D.; Zhang, Q.; Wang, Y.; Xu, S.; Lian, C. MSCA-Net: Multi-scale contextual attention network for skin lesion segmentation. Pattern Recognit. 2023, 139, 109524. [Google Scholar]
- Guo, M.; Lu, C.; Hou, Q.; Liu, Z.; Cheng, M.; Hu, S. Segnext: Rethinking convolutional attention design for semantic segmentation. arXiv 2022, arXiv:2209.08575. [Google Scholar]
- Wu, Q.; Sun, S.-J.; Zhu, W.; Li, G.-H.; Tu, D. Detection of digital doctoring in exemplar-based inpainted images. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; pp. 1222–1226. [Google Scholar]
- Lin, G.; Chang, M.; Chen, Y. A passive-blind forgery detection scheme based on content-adaptive quantization table estimation. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 421–434. [Google Scholar]
- Liang, Z.; Yang, G.; Ding, X.; Li, L. An efficient forgery detection algorithm for object removal by exemplar-based image inpainting. J. Vis. Commun. Image Represent. 2015, 30, 75–85. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the International Conference on Machine Learning, Amsterdam, The Netherlands, 7–10 July 2017; pp. 1243–1252. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3085–3094. [Google Scholar]
- Wang, L.; Song, Z.; Zhang, X.; Wang, C.; Zhang, G.; Zhu, L.; Li, J.; Liu, H. SAT-GCN: Self-attention graph convolutional network-based 3D object detection for autonomous driving. Knowl. Based Syst. 2023, 259, 110080. [Google Scholar]
- Lei, X.; Xia, Y.; Wang, A.; Jian, X.; Zhong, H.; Sun, L. Mutual information based anomaly detection of monitoring data with attention mechanism and residual learning. Mech. Syst. Signal Process. 2023, 182, 109607. [Google Scholar]
- Dubey, S.; Olimov, F.; Rafique, M.A.; Kim, J.; Jeon, M. Label-attention transformer with geometrically coherent objects for image captioning. Inf. Sci. 2023, 623, 812–831. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar]
- Wu, H.; Zhou, J.; Li, Y. Deep generative model for image inpainting with local binary pattern learning and spatial attention. IEEE Trans. Multimed. 2021, 24, 4016–4027. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the COMPSTAT’2010, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar]
- Gloe, T.; Böhme, R. The Dresden Image Database for Benchmarking Digital Image Forensics. J. Digit. Forensic Pract. 2010, 3, 150–159. [Google Scholar]
- Yan, Z.; Li, X.; Li, M.; Zuo, W.; Shan, S. Shift-net: Image inpainting via deep feature rearrangement. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Yu, T.; Guo, Z.; Jin, X.; Wu, S.; Chen, Z.; Li, W.; Zhang, Z.; Liu, S. Region normalization for image inpainting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12733–12740. [Google Scholar]
- Nazeri, K.; Ng, E.; Joseph, T.; Qureshi, F.Z.; Ebrahimi, M. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv 2019, arXiv:1901.00212. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Retrain | Test Dataset | Mean | |||||
|---|---|---|---|---|---|---|---|---|
| GC | CA | SN | EC | SA | RN | |||
| MT-Net | - 1 | 14.17 | 28.80 | 72.63 | 67.55 | 60.14 | 35.22 | 46.41 |
| MT-Net | GC | 92.10 2 | 19.02 | 32.78 | 10.62 | 2.38 | 10.80 | 15.12 |
| HP-FCN | - | 0.04 | 0.22 | 0.38 | 0.42 | 0.05 | 1.98 | 0.52 |
| HP-FCN | GC | 76.93 | 35.75 | 81.43 | 8.57 | 55.78 | 56.58 | 52.51 |
| U-FPN | - | 31.12 | 28.60 | 19.26 | 10.41 | 20.74 | 23.55 | 22.28 |
| U-FPN | GC | 80.14 | 70.40 | 70.26 | 72.18 | 87.28 | 82.22 | 76.45 |
| MVSS-Net | - | 1.86 | 76.22 | 94.08 | 83.52 | 67.63 | 77.07 | 66.73 |
| Proposed | GC | 98.91 | 87.03 3 | 94.69 | 84.21 | 94.55 | 85.53 | 89.20 |
| Feature fusion method | Low-Level | ✓ 1 | ||||||
| Low-High | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| High-Level | ✓ | |||||||
| Attention | w/o Att | ✓ | ||||||
| CA | ✓ | |||||||
| MSCA | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Loss | HF Loss | ✓ | ||||||
| Focal Loss | ✓ | |||||||
| Focal-HF | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Recall | 98.21 2 | 91.76 | 94.74 | 95.94 | 93.79 | 97.10 | 96.01 | |
| Precision | 99.62 | 99.11 | 98.42 | 98.05 | 98.95 | 98.25 | 99.04 | |
| IoU | 97.85 | 91.01 | 93.32 | 94.15 | 92.87 | 95.45 | 95.12 | |
| F1 | 98.91 | 95.29 | 96.54 | 96.98 | 96.30 | 97.67 | 97.50 | |
| Hyperparameter Setting | Recall | Precision | IoU | F1 |
|---|---|---|---|---|
| 98.21 | 99.62 | 97.85 | 98.91 | |
| 97.93 | 96.61 | 95.85 | 97.87 | |
| 2 | 94.13 | 99.67 | 96.18 | 98.12 |
| Pre-Trained Model | Recall | Precision | IoU | F1 |
|---|---|---|---|---|
| VGG-16 | 98.21 | 99.62 | 97.85 | 98.91 |
| ResNet-50 | 99.20 | 99.56 | 97.83 | 98.84 |
| Swin-T | 99.30 | 99.74 | 98.21 | 99.16 |
| QF | Recall | Precision | IoU | F1 |
|---|---|---|---|---|
| 85 | 94.46 | 98.24 | 92.89 | 96.31 |
| 75 | 92.52 | 98.35 | 91.11 | 95.35 |
| 65 | 80.60 | 99.61 | 80.35 | 89.10 |
| Std | Recall | Precision | IoU | F1 |
|---|---|---|---|---|
| 0.1 | 92.37 | 98.29 | 90.90 | 95.24 |
| 0.2 | 90.20 | 98.92 | 89.32 | 94.36 |
| 0.3 | 83.70 | 99.32 | 83.22 | 90.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Zhang, Y.; Wang, Y.; Tian, J.; Wu, F. Robust Image Inpainting Forensics by Using an Attention-Based Feature Pyramid Network. Appl. Sci. 2023, 13, 9196. https://doi.org/10.3390/app13169196
Chen Z, Zhang Y, Wang Y, Tian J, Wu F. Robust Image Inpainting Forensics by Using an Attention-Based Feature Pyramid Network. Applied Sciences. 2023; 13(16):9196. https://doi.org/10.3390/app13169196
Chicago/Turabian StyleChen, Zhuoran, Yujin Zhang, Yongqi Wang, Jin Tian, and Fei Wu. 2023. "Robust Image Inpainting Forensics by Using an Attention-Based Feature Pyramid Network" Applied Sciences 13, no. 16: 9196. https://doi.org/10.3390/app13169196
APA StyleChen, Z., Zhang, Y., Wang, Y., Tian, J., & Wu, F. (2023). Robust Image Inpainting Forensics by Using an Attention-Based Feature Pyramid Network. Applied Sciences, 13(16), 9196. https://doi.org/10.3390/app13169196