

Effective Human Motor Imagery Recognition via Segment Pool Based on One-Dimensional Convolutional Neural Network with Bidirectional Recurrent Attention Unit Network
Abstract
:1. Introduction
2. Methods
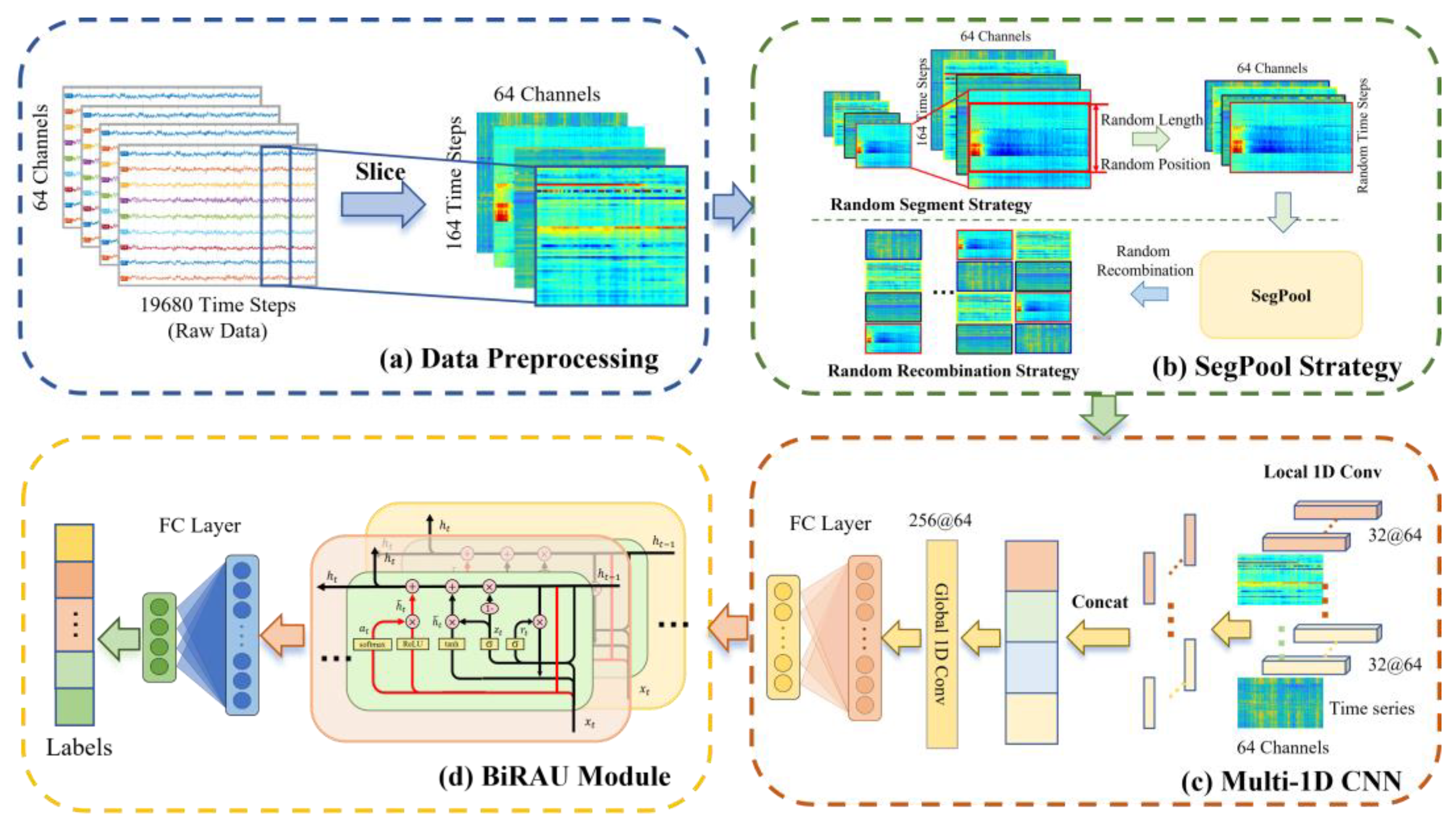
2.1. Overview
2.2. Data Preprocessing
2.3. Model
3. Experiments and Results
3.1. Ablation Experiment
3.2. Parameter Settings
3.3. Classification Performance on Individual Level
3.4. Classification Performance at Group Level
3.5. Comparison with Existing Studies
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alotaiby, T.; El-Samie FE, A.; Alshebeili, S.A.; Ahmad, I. A review of channel selection algorithms for EEG signal processing. EURASIP J. Adv. Signal Process. 2015, 2015, 66. [Google Scholar] [CrossRef] [Green Version]
- Xie, X.; Yang, Y. Study on classification algorithm of motor imagination EEG signal. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence and Computer Engineering (ICAICE), Hangzhou, China, 5–7 November 2021; pp. 605–609. [Google Scholar] [CrossRef]
- Roy, Y.; Banville, H.; Albuquerque, I.; Gramfort, A.; Falk, T.H.; Faubert, J. Deep learning-based electroencephalography analysis: A systematic review. J. Neural Eng. 2019, 16, 051001. [Google Scholar] [CrossRef] [PubMed]
- Lotte, F.; Bougrain, L.; Clerc, M. Electroencephalography (EEG)-Based Brain-Computer Interfaces. In Wiley Encyclopedia of Electrical and Electronics Engineering; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar] [CrossRef] [Green Version]
- Dose, H.; Møller, J.S.; Iversen, H.K.; Puthusserypady, S. An end-to-end deep learning approach to MI-EEG signal classification for BCIs. Expert Syst. Appl. 2018, 114, 532–542. [Google Scholar] [CrossRef]
- Tang, X.; Li, W.; Li, X.; Ma, W.; Dang, X. Motor imagery EEG recognition based on conditional optimization empirical mode decomposition and multi-scale convolutional neural network. Expert Syst. Appl. 2020, 149, 113285. [Google Scholar] [CrossRef]
- Wang, P.; Jiang, A.; Liu, X.; Shang, J.; Zhang, L. LSTM-Based EEG Classification in Motor Imagery Tasks. IEEE Trans. Neural Syst. Rehabil. Eng. A Publ. IEEE Eng. Med. Biol. Soc. 2018, 26, 2086–2095. [Google Scholar] [CrossRef] [PubMed]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Orgeron, J. EEG Signals Classification Using LSTM-Based Models and Majority Logic. Master’s Thesis, Georgia Southern University, Statesboro, GA, USA, 2022. Available online: https://digitalcommons.georgiasouthern.edu/etd/2391 (accessed on 1 July 2022).
- Petrosian, A.; Prokhorov, D.; Homan, R.; Dasheiff, R.; Wunsch, D. Recurrent neural network based prediction of epileptic seizures in intra- and extracranial EEG. Neurocomputing 2000, 30, 201–218. [Google Scholar] [CrossRef]
- Supakar, R.; Satvaya, P.; Chakrabarti, P. A deep learning based model using RNN-LSTM for the Detection of Schizophrenia from EEG data. Comput. Biol. Med. 2022, 151, 106225. [Google Scholar] [CrossRef] [PubMed]
- Najafi, T.; Jaafar, R.; Remli, R.; Wan Zaidi, W.A. A Classification Model of EEG Signals Based on RNN-LSTM for Diagnosing Focal and Generalized Epilepsy. Sensors 2022, 22, 7269. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Zhao, S.; Dong, Q.; Cui, Y.; Chen, Y.; Han, J.; Xie, L.; Liu, T. Recognizing Brain States Using Deep Sparse Recurrent Neural Network. IEEE Trans. Med. Imaging 2019, 38, 1058–1068. [Google Scholar] [CrossRef] [PubMed]
- Schalk, G.; McFarland, D.J.; Hinterberger, T.; Birbaumer, N.; Wolpaw, J.R. BCI2000: A general-purpose brain-computer interface (BCI) system. IEEE Trans. Biomed. Eng. 2004, 51, 1034–1043. [Google Scholar] [CrossRef] [PubMed]
- Goldberger, A.L.; Amaral, L.A.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, E215–E220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Altaheri, H.; Muhammad, G.; Alsulaiman, M.; Amin, S.U.; Altuwaijri, G.A.; Abdul, W.; Bencherif, M.A.; Faisal, M. Deep learning techniques for classification of electroencephalogram (EEG) motor imagery (MI) signals: A review. Neural Comput. Appl. 2023, 35, 14681–14722. [Google Scholar] [CrossRef]
- Baig, M.Z.; Aslam, N.; Shum, H.P.H. Filtering techniques for channel selection in motor imagery EEG applications: A survey. Artif. Intell. Rev. 2020, 53, 1207–1232. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Shi, E.; Wu, L.; Wang, R.; Yu, S.; Liu, Z.; Xu, S.; Liu, T.; Zhao, S. Differentiating brain states via multi-clip random fragment strategy-based interactive bidirectional recurrent neural network. Neural Netw. 2023, 165, 1035–1049. [Google Scholar] [CrossRef] [PubMed]
- Niu, Z.; Zhong, G.; Yue, G.; Wang, L.-N.; Yu, H.; Ling, X.; Dong, J. Recurrent attention unit: A new gated recurrent unit for long-term memory of important parts in sequential data. Neurocomputing 2023, 517, 1–9. [Google Scholar] [CrossRef]
- Wang, F.; Tax, D. Survey on the attention based RNN model and its applications in computer vision. arXiv 2016, arXiv:1601.06823. Available online: https://www.semanticscholar.org/paper/Survey-on-the-attention-based-RNN-model-and-its-in-Wang-Tax/f660ea723b62f69b9f4c439724a6b73357e1d3c3 (accessed on 25 January 2016).
- Tanaka, H. Group task-related component analysis (gTRCA): A multivariate method for inter-trial reproducibility and inter-subject similarity maximization for EEG data analysis. Sci. Rep. 2020, 10, 84. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiaoling, L. Motor imagery-based EEG signals classification by combining temporal and spatial deep characteristics. Int. J. Intell. Comput. Cybern. 2020, 13, 437–453. [Google Scholar] [CrossRef]
- Khademi, Z.; Ebrahimi, F.; Kordy, H.M. A transfer learning-based CNN and LSTM hybrid deep learning model to classify motor imagery EEG signals. Comput. Biol. Med. 2022, 143, 105288. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Sbj1 | Sbj2 | Sbj3 | Sbj4 | Sbj5 | Mean |
|---|---|---|---|---|---|---|
| 1DCNN + BiLSTM | 99.02% | 95.06% | 51.48% | 96.75% | 93.75% | 87.21% |
| 1DCNN + BiRNN | 96.87% | 97.38% | 97.43% | 94.56% | 97.20% | 96.69% |
| BiRAU | 51.19% | 50.15% | 49.61% | 50.83% | 51.19% | 50.59% |
| Local 1D CNN + BiRAU | 90.91% | 99.55% | 95.92% | 99.53% | 97.03% | 96.59% |
| Global 1D CNN + BiRAU | 99.43% | 96.98% | 97.89% | 97.83% | 97.81% | 97.99% |
| 1DCNN-BiRAU | 99.72% | 99.61% | 99.15% | 99.77% | 99.16% | 99.48% |
| Local CNN (Filters) | Global CNN (Filters) | BiRAU (Layers–Neurons) | Sbj1 | Sbj2 | Sbj3 | Sbj4 | Sbj5 | Mean |
|---|---|---|---|---|---|---|---|---|
| 16 | 256 | 2-32 | 85.39% | 73.05% | 68.35% | 89.22% | 80.24% | 79.25% |
| 32 | 256 | 2-32 | 93.93% | 86.01% | 82.12% | 95.93% | 93.28% | 90.25% |
| 64 | 256 | 2-32 | 93.51% | 67.90% | 69.50% | 87.17% | 86.57% | 80.93% |
| 32 | 64 | 2-32 | 88.25% | 71.05% | 69.18% | 87.28% | 75.55% | 78.26% |
| 32 | 128 | 2-32 | 86.87% | 81.78% | 76.18% | 81.98% | 78.07% | 80.98% |
| 32 | 512 | 2-32 | 90.35% | 67.56% | 65.85% | 89.83% | 85.45% | 79.81% |
| 32 | 256 | 1-32 | 88.76% | 61.46% | 67.78% | 87.30% | 77.76% | 76.61% |
| 32 | 256 | 3-32 | 86.89% | 64.88% | 73.36% | 96.67% | 75.77% | 80.45% |
| 32 | 256 | 2-64 | 92.56% | 67.46% | 69.35% | 76.82% | 82.60% | 77.76% |
| Work | Binary Classification Mean. acc. | Four-Category Classification Mean. acc. | Method |
|---|---|---|---|
| Dose et al. (2018) [5] | 86.49% | 68.51% | CNNs |
| H. Wang et al. (2019) [13] | 81.10% | 79.78% | DSRNN |
| Xiaoling et al. (2020) [22] | 90.08% | N/A | TS-CNN |
| Khademi et al. (2022) [23] | N/A | 90.00% | ResNet50-LSTM |
| Ours | 99.47% | 90.90% | 1DCNN-BiRAU |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, H.; Yue, C.; Shi, E.; Yu, S.; Kang, Y.; Wu, J.; Wang, J.; Zhang, S. Effective Human Motor Imagery Recognition via Segment Pool Based on One-Dimensional Convolutional Neural Network with Bidirectional Recurrent Attention Unit Network. Appl. Sci. 2023, 13, 9233. https://doi.org/10.3390/app13169233
Hu H, Yue C, Shi E, Yu S, Kang Y, Wu J, Wang J, Zhang S. Effective Human Motor Imagery Recognition via Segment Pool Based on One-Dimensional Convolutional Neural Network with Bidirectional Recurrent Attention Unit Network. Applied Sciences. 2023; 13(16):9233. https://doi.org/10.3390/app13169233
Chicago/Turabian StyleHu, Huawen, Chenxi Yue, Enze Shi, Sigang Yu, Yanqing Kang, Jinru Wu, Jiaqi Wang, and Shu Zhang. 2023. "Effective Human Motor Imagery Recognition via Segment Pool Based on One-Dimensional Convolutional Neural Network with Bidirectional Recurrent Attention Unit Network" Applied Sciences 13, no. 16: 9233. https://doi.org/10.3390/app13169233
APA StyleHu, H., Yue, C., Shi, E., Yu, S., Kang, Y., Wu, J., Wang, J., & Zhang, S. (2023). Effective Human Motor Imagery Recognition via Segment Pool Based on One-Dimensional Convolutional Neural Network with Bidirectional Recurrent Attention Unit Network. Applied Sciences, 13(16), 9233. https://doi.org/10.3390/app13169233