

A Neural-Network-Based Landscape Search Engine: LSE Wisconsin

Abstract
:Featured Application
Abstract
1. Introduction
Background
2. Methods and Data
2.1. Data Extraction
2.2. A Priori Modeling
Model Metrics
2.3. Ad Hoc Querying
- Exclusion radius in miles (variable dist, values: 0–300): following Tobler’s First Law of Geography, it was expected that nearby locations would be highly similar and that users may want to exclude options within a certain distance in order to retrieve results from farther away. The default is 0, meaning that no locations are excluded due to nearness.
- Number of similar locations to retrieve (variable k, values: 1–10): The default is 5.
- Terrain model (variable resnet50_sim, vgg16_sim, or nasnet_sim, depending on using input from options “ResNet-50”, “VGG16”, and “NasNet”): The neural network model to use in comparing results.
- Criteria weight for terrain (variable terrain_scale, values of 0–1): Relative weight to use for terrain (default of 0.8). This gives end-users flexibility by allowing them to place more or less emphasis on terrain versus vegetation.
- Criteria weight for NDVI mean vs. NDVI standard deviation (variable veg_mean_scale, values 0–1): Relative weight to use for each of the two NDVI variables (default of 1). This allows users to place more or less emphasis on total vegetation (i.e., mean NDVI similarity) versus the amount of NDVI variability (i.e., NDVI standard deviation).
3. Case Studies
3.1. Observations of General Patterns
- resnet50_sim with vgg_16_sim
- resnet50_sim with nasnet_sim
- vgg16_sim with nasnet_sim
3.2. Individual Locations
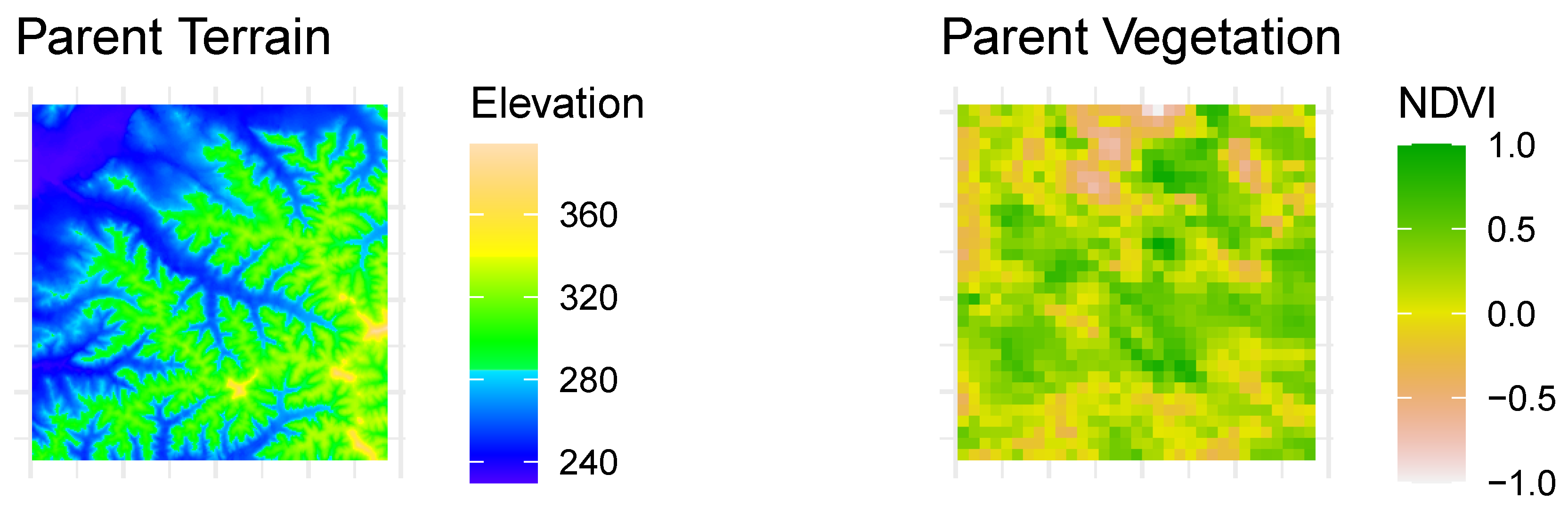
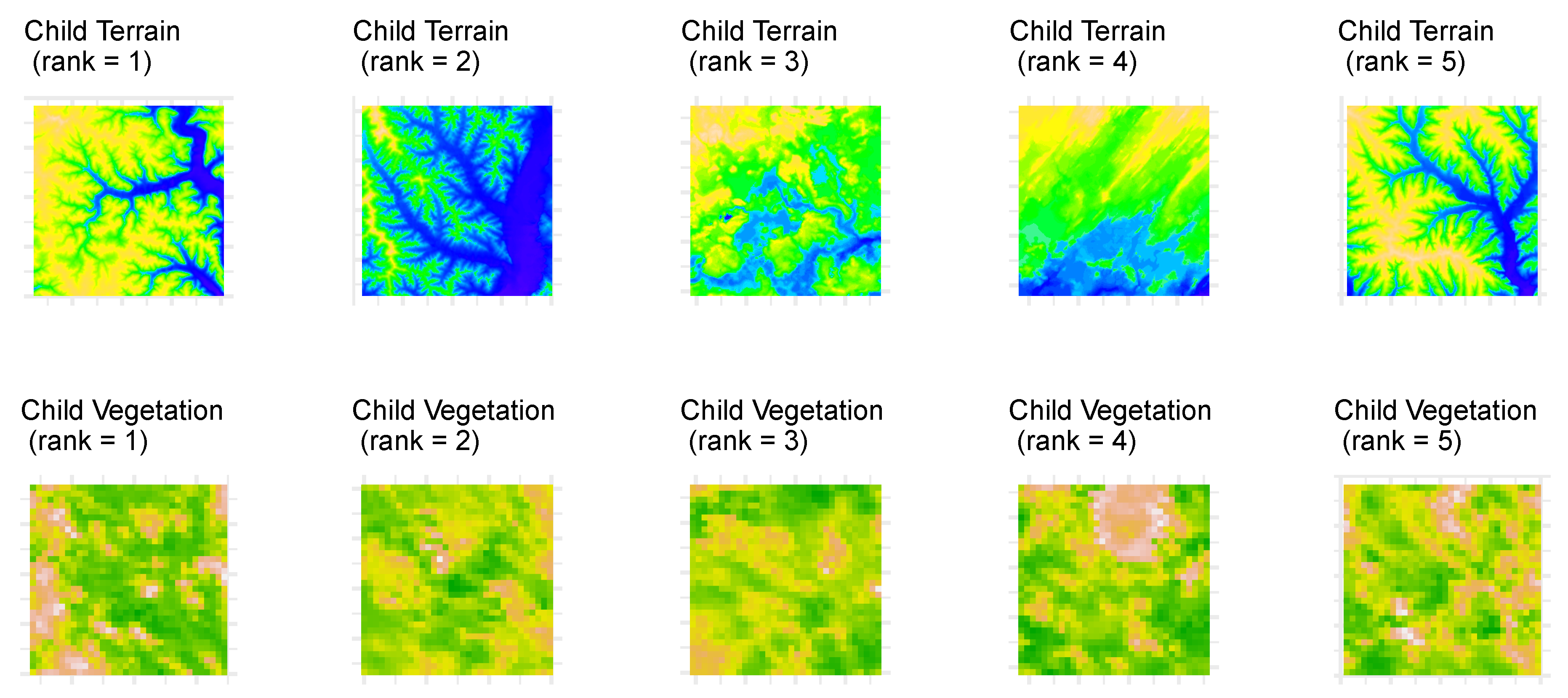
3.2.1. Location A: Western Wisconsin
- k = 5
- terrain_model = ‘resnet50’
- terrain_scale = 0.8
- veg_mean_scale = 1.0
- user_dist = 0
3.2.2. Location B: Northern Wisconsin
- k = 5
- terrain_model = ‘vgg16’
- terrain_scale = 0.5
- veg_mean_scale = 0.9
- user_dist = 0
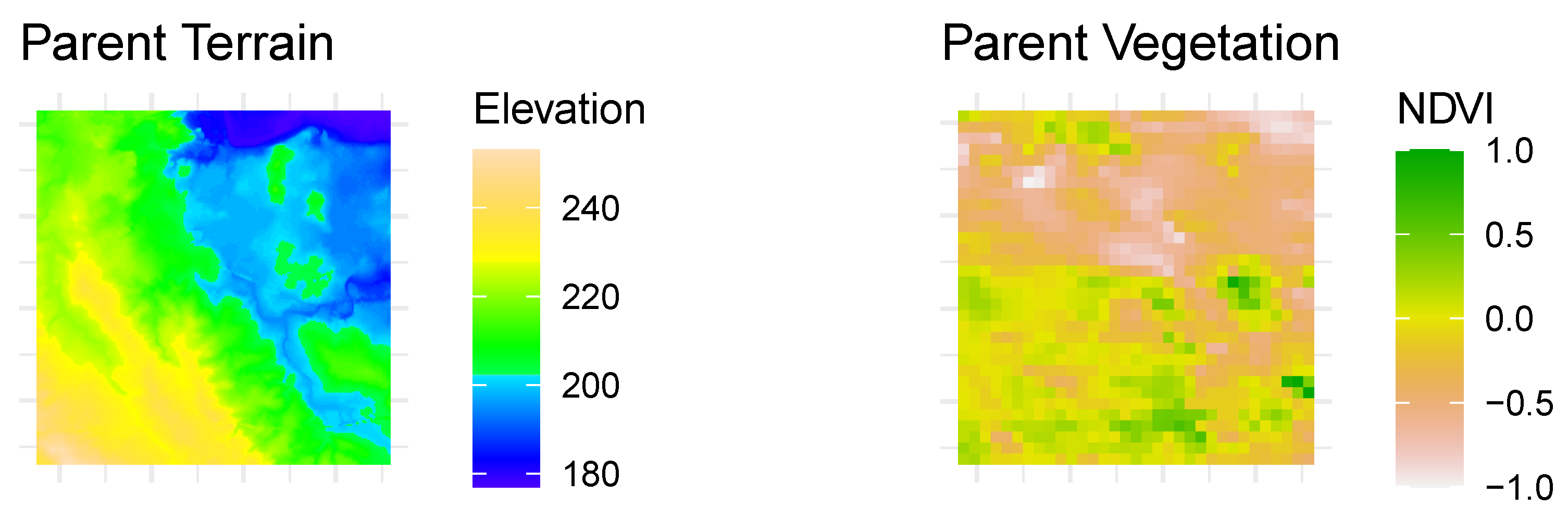
3.2.3. Location C: Urban Milwaukee
- k = 5
- terrain_model = ‘resnet50’
- terrain_scale = 0.2
- veg_mean_scale = 0.5
- user_dist = 150
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
Abbreviations
| CNN | Convolutional Neural Network |
| DEM | Digital Elevation Model |
| NDVI | Normalized Difference Vegetation Index |
| NN | Neural Network |
| NN | NasNet |
| DL | Deep Learning |
| USGS | United States Geological Survey |
| DNR | Department of Natural Resources |
| GDAL | Geospatial Data Abstraction Library |
| GIScience | Geographic Information Science |
| NASA | National Air and Space Administration |
| MODIS | Moderate Resolution Imaging Spectrometer |
| VGG | Visual Geometry Group |
References
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Pei, H.; Owari, T.; Tsuyuki, S.; Zhong, Y. Application of a Novel Multiscale Global Graph Convolutional Neural Network to Improve the Accuracy of Forest Type Classification Using Aerial Photographs. Remote Sens. 2023, 15, 1001. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Xia, F.; Lou, Z.; Sun, D.; Li, H.; Quan, L. Weed resistance assessment through airborne multimodal data fusion and deep learning: A novel approach towards sustainable agriculture. Int. J. Appl. Earth Obs. Geoinf. 2023, 120, 103352. [Google Scholar] [CrossRef]
- Wen, L.; Cheng, Y.; Fang, Y.; Li, X. A comprehensive survey of oriented object detection in remote sensing images. Expert Syst. Appl. 2023, 224, 119960. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Zhang, N.; Zhang, Y.; Zhao, Z.; Xu, D.; Ben, G.; Gao, Y. Deep Learning-Based Object Detection Techniques for Remote Sensing Images: A Survey. Remote Sens. 2022, 14, 2385. [Google Scholar] [CrossRef]
- Li, J.; Hong, D.; Gao, L.; Yao, J.; Zheng, K.; Zhang, B.; Chanussot, J. Deep learning in multimodal remote sensing data fusion: A comprehensive review. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102926. [Google Scholar] [CrossRef]
- Chen, J.; Hong, H.; Song, B.; Guo, J.; Chen, C.; Xu, J. MDCT: Multi-Kernel Dilated Convolution and Transformer for One-Stage Object Detection of Remote Sensing Images. Remote Sens. 2023, 15, 371. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Xue, X.; Jiang, Y.; Shen, Q. Deep learning for remote sensing image classification: A survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1264. [Google Scholar] [CrossRef] [Green Version]
- Jasiewicz, J.; Netzel, P.; Stepinski, T.F. Landscape similarity, retrieval, and machine mapping of physiographic units. Geomorphology 2014, 221, 104–112. [Google Scholar] [CrossRef]
- Dilts, T.E.; Yang, J.; Weisberg, P.J. The Landscape Similarity Toolbox: New tools for optimizing the location of control sites in experimental studies. Ecography 2010, 33, 1097–1101. [Google Scholar] [CrossRef]
- Pilliod, D.S.; Jeffries, M.I.; Welty, J. Land Treatment Exploration Tool. Available online: https://susy.mdpi.com/user/assigned/production_form/1c6eec251f1a7967167a5f989ab777ab (accessed on 6 August 2023).
- Gomes, R.; Kamrowski, C.; Langlois, J.; Rozario, P.; Dircks, I.; Grottodden, K.; Martinez, M.; Tee, W.Z.; Sargeant, K.; LaFleur, C.; et al. A Comprehensive Review of Machine Learning Used to Combat COVID-19. Diagnostics 2022, 12, 1853. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Ye, M.; Ruiwen, N.; Chang, Z.; He, G.; Tianli, H.; Shijun, L.; Yu, S.; Tong, Z.; Ying, G. A Lightweight Model of VGG-16 for Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6916–6922. [Google Scholar] [CrossRef]
- Ganakwar, P.; Date, S. Convolutional neural network-VGG16 for road extraction from remotely sensed images. Int. J. Res. Appl. Sci. Eng. Technol. (IJRASET) 2020, 8, 916–922. [Google Scholar] [CrossRef]
- Khaleghian, S.; Ullah, H.; Kræmer, T.; Hughes, N.; Eltoft, T.; Marinoni, A. Sea Ice Classification of SAR Imagery Based on Convolution Neural Networks. Remote Sens. 2021, 13, 1734. [Google Scholar] [CrossRef]
- Zhu, F.; Li, J.; Zhu, B.; Li, H.; Liu, G. UAV remote sensing image stitching via improved VGG16 Siamese feature extraction network. Expert Syst. Appl. 2023, 229, 120525. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015. [Google Scholar] [CrossRef]
- Alsabhan, W.; Alotaiby, T. Automatic Building Extraction on Satellite Images Using Unet and ResNet50. Comput. Intell. Neurosci. 2022, 2022, 5008854. [Google Scholar] [CrossRef]
- Jian, X.; Yunquan, Z.; Yue, Q. Remote Sensing Image Classification Based on Different Convolutional Neural Network Models. In Proceedings of the 2021 6th International Symposium on Computer and Information Processing Technology (ISCIPT), Changsha, China, 11–13 June 2021; pp. 312–316. [Google Scholar] [CrossRef]
- Firat, H.; Hanbay, D. Classification of Hyperspectral Images Using 3D CNN Based ResNet50. In Proceedings of the 2021 29th Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkey, 9–11 June 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, C.; Zhao, R.; Shi, Z. Remote-Sensing Image Captioning Based on Multilayer Aggregated Transformer. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Alafandy, K.A.; Omara, H.; Lazaar, M.; Achhab, M.A. Using Classic Networks for Classifying Remote Sensing Images: Comparative Study. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 770–780. [Google Scholar] [CrossRef]
- Li, L.; Tian, T.; Li, H. Classification of Remote Sensing Scenes Based on Neural Architecture Search Network. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; pp. 176–180. [Google Scholar] [CrossRef]
- Chang, W.; Cheng, J.; Allaire, J.; Sievert, C.; Schloerke, B.; Xie, Y.; Allen, J.; McPherson, J.; Dipert, A.; Borges, B. Shiny: Web Application Framework for R, R package version 1.7.1.; 2021. [Google Scholar]
- Wickham, H.; Girlich, M.; Ruiz, E. Dbplyr: A ’Dplyr’ Back End for Databases, R package version 2.2.0; 2022. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Similarity Rank | Distance (mi.) | Total Similarity Score | Resnet-50 Similarity | VGG16 Similatiry | Nasnet Similarity | NDVI Mean Similarity | NDVI SD Similatiry | Parent ID | Child ID |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 71 | 0.974 | 0.968 | 0.738 | 0.953 | 0.998 | 0.820 | 1521 | 2073 |
| 2 | 5 | 0.972 | 0.966 | 0.349 | 0.888 | 0.995 | 0.980 | 1521 | 1520 |
| 3 | 171 | 0.971 | 0.970 | 0.613 | 0.923 | 0.973 | 0.986 | 1521 | 450 |
| 4 | 139 | 0.970 | 0.967 | 0.676 | 0.952 | 0.985 | 0.797 | 1521 | 150 |
| 5 | 119 | 0.969 | 0.972 | 0.808 | 0.983 | 0.957 | 0.895 | 1521 | 2289 |
| Similarity Rank | Distance (mi.) | Total Similarity Score | Resnet-50 Similarity | VGG16 Similarity | Nasnet Similarity | NDVI Mean Similarity | NDVI SD Similarity | Parent ID | Child ID |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 183 | 0.890 | 0.705 | 0.812 | 0.957 | 0.968 | 0.959 | 117 | 1548 |
| 2 | 226 | 0.884 | 0.937 | 0.811 | 0.974 | 0.959 | 0.942 | 117 | 1772 |
| 3 | 124 | 0.884 | 0.953 | 0.840 | 0.949 | 0.921 | 0.983 | 117 | 1286 |
| 4 | 194 | 0.881 | 0.695 | 0.785 | 0.948 | 0.978 | 0.965 | 117 | 1797 |
| 5 | 283 | 0.872 | 0.792 | 0.831 | 0.944 | 0.917 | 0.872 | 117 | 2309 |
| Similarity Rank | Distance (mi.) | Total Similarity Score | Resnet-50 Similarity | VGG16 Similarity | Nasnet Similarity | NDVI Mean Similarity | NDVI SD Similarity | Parent ID | Child ID |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 262 | 0.982 | 0.964 | 0.676 | 0.785 | 0.995 | 0.978 | 2276 | 767 |
| 2 | 253 | 0.962 | 0.971 | 0.415 | 0.838 | 0.994 | 0.927 | 2276 | 873 |
| 3 | 241 | 0.962 | 0.916 | 0.194 | 0.921 | 0.971 | 0.975 | 2276 | 876 |
| 4 | 213 | 0.954 | 0.861 | 0.428 | 0.781 | 0.961 | 0.995 | 2276 | 996 |
| 5 | 214 | 0.954 | 0.892 | 0.508 | 0.942 | 0.943 | 0.997 | 2276 | 1274 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haffner, M.; DeWitte, M.; Rozario, P.F.; Ovando-Montejo, G.A. A Neural-Network-Based Landscape Search Engine: LSE Wisconsin. Appl. Sci. 2023, 13, 9264. https://doi.org/10.3390/app13169264
Haffner M, DeWitte M, Rozario PF, Ovando-Montejo GA. A Neural-Network-Based Landscape Search Engine: LSE Wisconsin. Applied Sciences. 2023; 13(16):9264. https://doi.org/10.3390/app13169264
Chicago/Turabian StyleHaffner, Matthew, Matthew DeWitte, Papia F. Rozario, and Gustavo A. Ovando-Montejo. 2023. "A Neural-Network-Based Landscape Search Engine: LSE Wisconsin" Applied Sciences 13, no. 16: 9264. https://doi.org/10.3390/app13169264
APA StyleHaffner, M., DeWitte, M., Rozario, P. F., & Ovando-Montejo, G. A. (2023). A Neural-Network-Based Landscape Search Engine: LSE Wisconsin. Applied Sciences, 13(16), 9264. https://doi.org/10.3390/app13169264