
Crossband Filtering for Weighted Prediction Error-Based Speech Dereverberation



Abstract
:1. Introduction
2. Model Formulation
2.1. Signal Model and Crossband Filters
2.2. Problem Formulation
Extension to Crossband Filters
3. Proposed WPE with Crossband Filtering
3.1. Conventional WPE
3.1.1. Filter Estimation
| Algorithm 1 Conventional WPE Filter Estimation for First Channel |
| Input: |
| Observed multichannel signal in STFT domain |
| Small constant , filter length L, number of iterations N |
| for do |
| 1. Initialize |
| 2. for do |
| Compute: |
| Update: |
| Filter: |
| Enhanced signal: |
| Variances: |
| 3. end for |
| end for |
3.2. WPE with Crossband Filtering
4. Experimental Results
4.1. Data and Setup
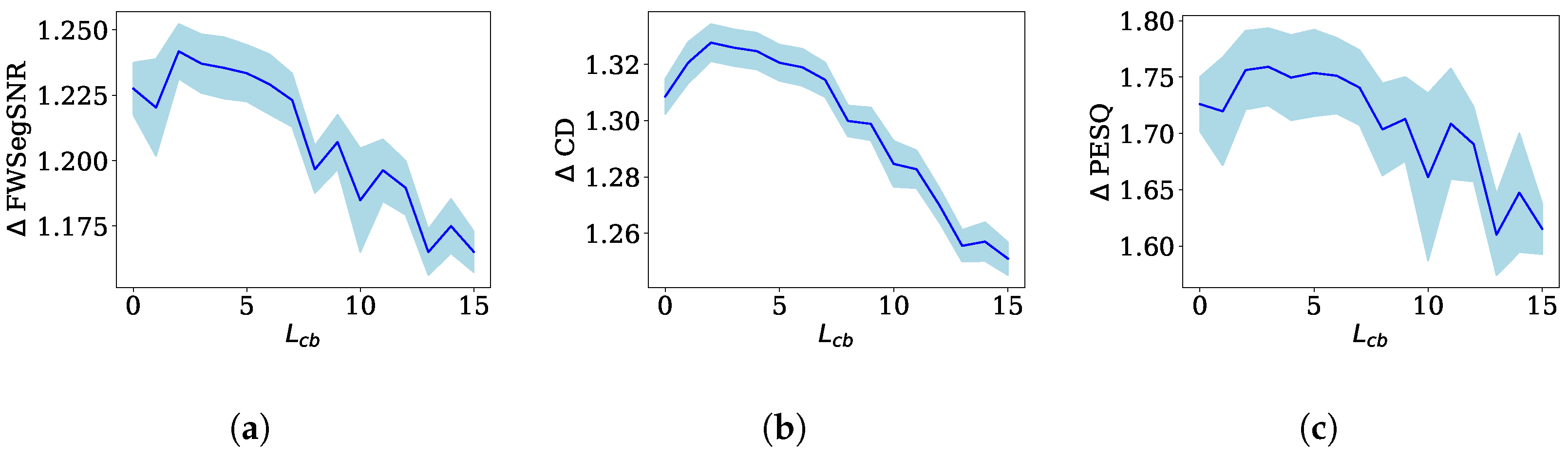
- Length extension (Ext.): In this first version of the proposed method, denoted as the “length extension”, we set the parameter equal to L. This design choice ensured that the samples from the crossband components, which introduced additional computational complexity, were included in the analysis. This specific experiment aimed to demonstrate the significance of the information contained in the crossband components in enhancing the dereverberation performance. While it did introduce computational complexity, this experimental approach allowed us to assess the true potential and effectiveness of the proposed method by leveraging the information-rich crossband components.
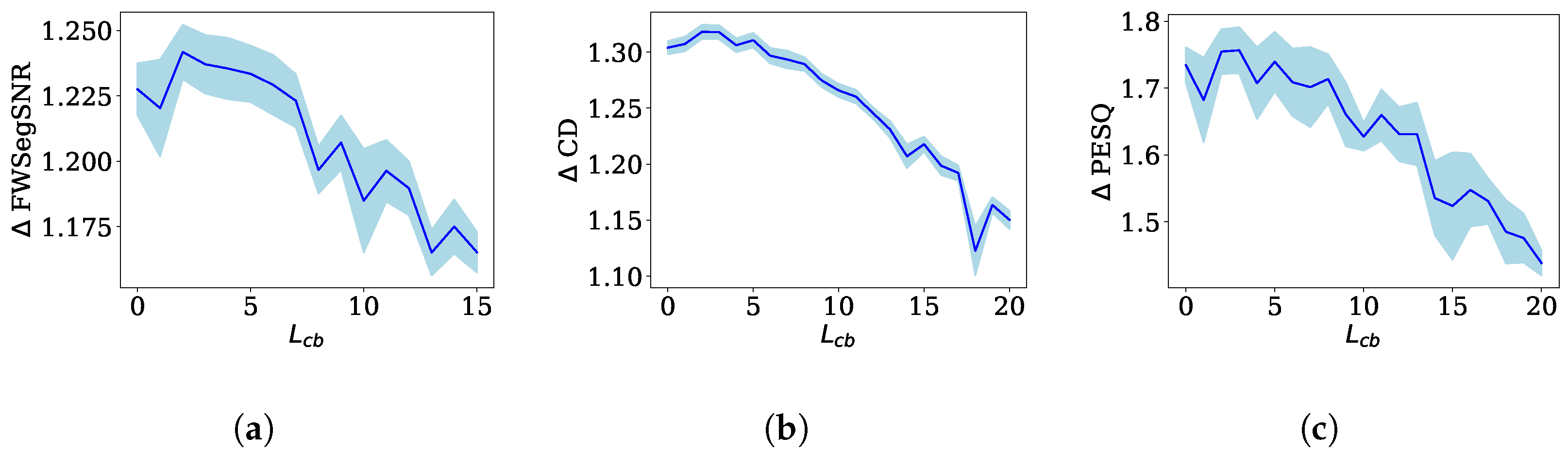
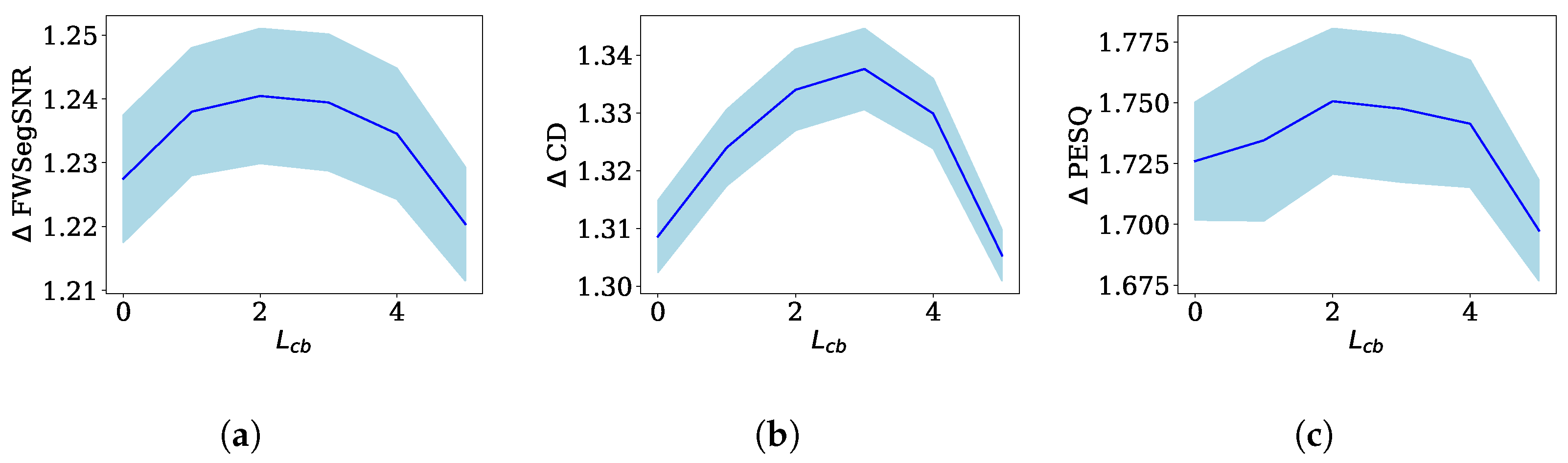
- Length preservation (Pres.): In the second version of the proposed method, denoted as “length preservation”, we established to equal L. To maintain comparable computational complexity to the conventional WPE method, we introduced a modification by discarding the two most recent samples from the band-to-band component for every sample utilized in the crossband components. This adjustment allowed us to strike a balance between computational efficiency and the evaluation of the relative importance of early samples from the crossband components and late samples from the band-to-band component. By discarding the two latest samples from the band-to-band component, we aimed to explore the tradeoff between the temporal characteristics of the crossband and band-to-band components. This experimental design enabled us to assess the respective significance of early samples from the crossband components and late samples from the band-to-band component in the dereverberation process.
4.2. Performance Measure
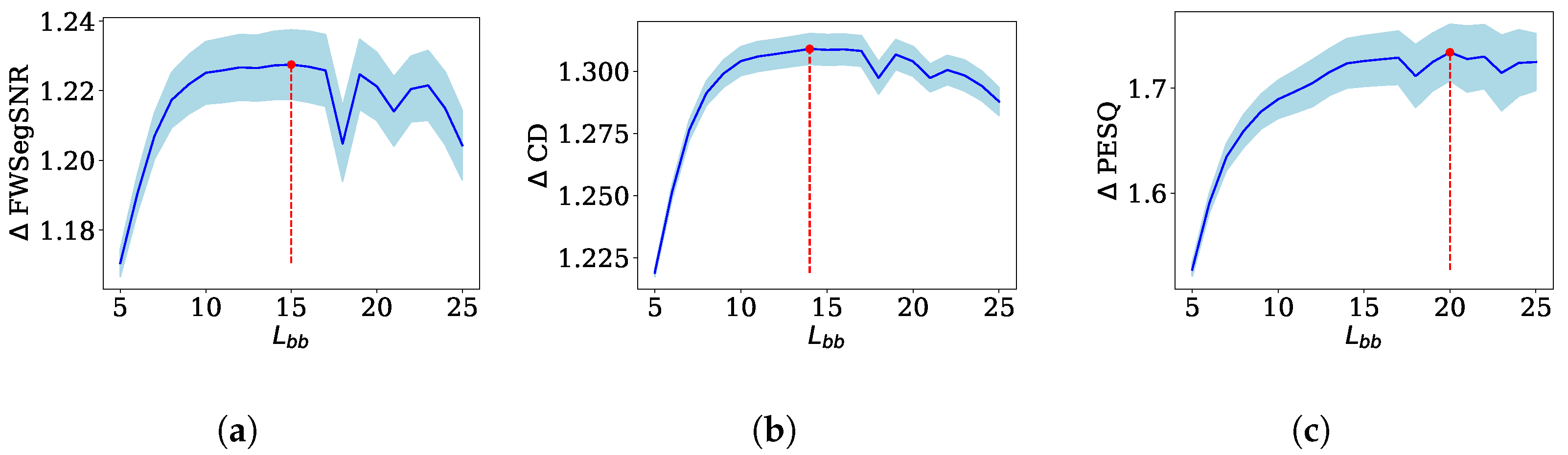
4.3. Optimal Band-to-Band Length
4.4. Crossband Filtering—Length Extension
4.4.1. Optimal FWSegSNR ()
4.4.2. Optimal CD ()
4.4.3. Optimal PESQ ()
4.5. Crossband Filtering—Length Preservation
4.5.1. Optimal FWSegSNR ()
4.5.2. Optimal CD ()
4.5.3. Optimal PESQ ()
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Benesty, J.; Chen, J.; Huang, Y. Microphone Array Signal Processing; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; Volume 1. [Google Scholar]
- Brandstein, M.; Ward, D. Microphone Arrays: Signal Processing Techniques and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Rosenbaum, T.; Cohen, I.; Winebrand, E. Attenuation Of Acoustic Early Reflections In Television Studios Using Pretrained Speech Synthesis Neural Network. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 7422–7426. [Google Scholar]
- Boothroyd, A. Room Acoustics and Speech Perception. Semin. Hear. 2004, 25, 155–166. [Google Scholar] [CrossRef]
- Schmid, D.; Enzner, G.; Malik, S.; Kolossa, D.; Martin, R. Variational Bayesian inference for multichannel dereverberation and noise reduction. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1320–1335. [Google Scholar] [CrossRef]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time–frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Zheng, C.; Li, X.; Schwarz, A.; Kellermann, W. Statistical analysis and improvement of coherent-to-diffuse power ratio estimators for dereverberation. In Proceedings of the 2016 IEEE International Workshop on Acoustic Signal Enhancement (IWAENC), Xi’an, China, 13–16 September 2016; IEEE: New York, NY, USA, 2016; pp. 1–5. [Google Scholar]
- Williamson, D.S.; Wang, D. Time-frequency masking in the complex domain for speech dereverberation and denoising. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1492–1501. [Google Scholar] [CrossRef]
- Schwartz, O.; Gannot, S.; Habets, E.A. An expectation-maximization algorithm for multimicrophone speech dereverberation and noise reduction with coherence matrix estimation. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1495–1510. [Google Scholar] [CrossRef]
- Inoue, S.; Kameoka, H.; Li, L.; Seki, S.; Makino, S. Joint separation and dereverberation of reverberant mixtures with multichannel variational autoencoder. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 96–100. [Google Scholar]
- Habets, E.A.P.; Benesty, J.; Cohen, I.; Gannot, S.; Dmochowski, J. New Insights Into the MVDR Beamformer in Room Acoustics. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 158–170. [Google Scholar] [CrossRef]
- Habets, E.A.P.; Benesty, J. A Two-Stage Beamforming Approach for Noise Reduction and Dereverberation. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 945–958. [Google Scholar] [CrossRef]
- Habets, E.A. Speech dereverberation using statistical reverberation models. In Speech Dereverberation; Springer: Berlin/Heidelberg, Germany, 2010; pp. 57–93. [Google Scholar]
- Lebart, K.; Boucher, J.M.; Denbigh, P.N. A new method based on spectral subtraction for speech dereverberation. Acta Acust. United Acust. 2001, 87, 359–366. [Google Scholar]
- Schwartz, O.; Gannot, S.; Habets, E.A. Multi-microphone speech dereverberation and noise reduction using relative early transfer functions. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 240–251. [Google Scholar] [CrossRef]
- Miyoshi, M.; Kaneda, Y. Inverse filtering of room acoustics. IEEE Trans. Acoust. Speech Signal Process. 1988, 36, 145–152. [Google Scholar] [CrossRef]
- Jukić, A.; van Waterschoot, T.; Gerkmann, T.; Doclo, S. Multi-channel linear prediction-based speech dereverberation with sparse priors. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 1509–1520. [Google Scholar] [CrossRef]
- Kinoshita, K.; Delcroix, M.; Nakatani, T.; Miyoshi, M. Suppression of late reverberation effect on speech signal using long-term multiple-step linear prediction. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 534–545. [Google Scholar] [CrossRef]
- Nakatani, T.; Yoshioka, T.; Kinoshita, K.; Miyoshi, M.; Juang, B.H. Speech dereverberation based on variance-normalized delayed linear prediction. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 1717–1731. [Google Scholar] [CrossRef]
- Yoshioka, T.; Nakatani, T. Generalization of multi-channel linear prediction methods for blind MIMO impulse response shortening. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 2707–2720. [Google Scholar] [CrossRef]
- Kinoshita, K.; Delcroix, M.; Gannot, S.; Habets, E.A.; Haeb-Umbach, R.; Kellermann, W.; Leutnant, V.; Maas, R.; Nakatani, T.; Raj, B.; et al. A summary of the REVERB challenge: State-of-the-art and remaining challenges in reverberant speech processing research. EURASIP J. Adv. Signal Process. 2016, 2016, 7. [Google Scholar] [CrossRef]
- Li, B.; Sainath, T.N.; Narayanan, A.; Caroselli, J.; Bacchiani, M.; Misra, A.; Shafran, I.; Sak, H.; Pundak, G.; Chin, K.K.; et al. Acoustic Modeling for Google Home. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 399–403. [Google Scholar]
- Kinoshita, K.; Delcroix, M.; Kwon, H.; Mori, T.; Nakatani, T. Neural Network-Based Spectrum Estimation for Online WPE Dereverberation. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 384–388. [Google Scholar]
- Ikeshita, R.; Kamo, N.; Nakatani, T. Blind signal dereverberation based on mixture of weighted prediction error models. IEEE Signal Process. Lett. 2021, 28, 399–403. [Google Scholar] [CrossRef]
- Kamo, N.; Ikeshita, R.; Kinoshita, K.; Nakatani, T. Importance of Switch Optimization Criterion in Switching WPE Dereverberation. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 176–180. [Google Scholar]
- Huang, G.; Benesty, J.; Cohen, I.; Chen, J. Kronecker product multichannel linear filtering for adaptive weighted prediction error-based speech dereverberation. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1277–1289. [Google Scholar] [CrossRef]
- Portnoff, M. Time-frequency representation of digital signals and systems based on short-time Fourier analysis. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 55–69. [Google Scholar] [CrossRef]
- Avargel, Y.; Cohen, I. System identification in the short-time Fourier transform domain with crossband filtering. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1305–1319. [Google Scholar] [CrossRef]
- Avargel, Y.; Cohen, I. On multiplicative transfer function approximation in the short-time Fourier transform domain. IEEE Signal Process. Lett. 2007, 14, 337–340. [Google Scholar] [CrossRef]
- Nakatani, T.; Yoshioka, T.; Kinoshita, K.; Miyoshi, M.; Juang, B.H. Speech dereverberation in short time Fourier transform domain with crossband effect compensation. In Proceedings of the 2008 Hands-Free Speech Communication and Microphone Arrays, Trento, Italy, 6–8 May 2008; IEEE: New York, NY, USA, 2008; pp. 220–223. [Google Scholar]
- Dubey, H.; Gopal, V.; Cutler, R.; Matusevych, S.; Braun, S.; Eskimez, E.S.; Thakker, M.; Yoshioka, T.; Gamper, H.; Aichner, R. ICASSP 2022 Deep Noise Suppression Challenge. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022. [Google Scholar]
- Allen, J.B.; Berkley, D.A. Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]
- Kinoshita, K.; Delcroix, M.; Yoshioka, T.; Nakatani, T.; Habets, E.; Haeb-Umbach, R.; Leutnant, V.; Sehr, A.; Kellermann, W.; Maas, R.; et al. The REVERB challenge: A common evaluation framework for dereverberation and recognition of reverberant speech. In Proceedings of the 2013 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 20–23 October 2013; IEEE: New York, NY, USA, 2013; pp. 1–4. [Google Scholar]
- Ma, J.; Hu, Y.; Loizou, P.C. Objective measures for predicting speech intelligibility in noisy conditions based on new band-importance functions. J. Acoust. Soc. Am. 2009, 125, 3387–3405. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Ma, H.T.; Chen, F. A new data-driven band-weighting function for predicting the intelligibility of noise-suppressed speech. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; IEEE: New York, NY, USA, 2017; pp. 492–496. [Google Scholar]
- Kubichek, R. Mel-cepstral distance measure for objective speech quality assessment. In Proceedings of the IEEE Pacific Rim Conference on Communications Computers and Signal Processing, Victoria, BC, Canada, 19–21 May 1993; Volume 1, pp. 125–128. [Google Scholar] [CrossRef]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; Proceedings (Cat. No. 01CH37221). IEEE: New York, NY, USA, 2001; Volume 2, pp. 749–752. [Google Scholar]
- ANSI/ASA S3.5-1997; Methods for Calculation of the Speech Intelligibility Index. American National Standard: Washington, DC, USA, 1997.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measure | Optimal Gain | Optimal | |
|---|---|---|---|
| FWSegSNR | 14 | 1.23 | 2 |
| 15 | 1.24 | 2 | |
| 20 | 1.22 | 2 | |
| CD | 14 | 1.33 | 2 |
| 15 | 1.32 | 2 | |
| 20 | 1.31 | 2 | |
| PESQ | 14 | 1.76 | 4 |
| 15 | 1.76 | 3 | |
| 20 | 1.75 | 3 |
| Measure | Optimal Gain | Optimal | |
|---|---|---|---|
| FWSegSNR | 14 | 1.24 | 2 |
| 15 | 1.24 | 2 | |
| 20 | 1.23 | 5 | |
| CD | 14 | 1.33 | 2 |
| 15 | 1.34 | 3 | |
| 20 | 1.33 | 5 | |
| PESQ | 14 | 1.74 | 2 |
| 15 | 1.75 | 3 | |
| 20 | 1.77 | 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosenbaum, T.; Cohen, I.; Winebrand, E. Crossband Filtering for Weighted Prediction Error-Based Speech Dereverberation. Appl. Sci. 2023, 13, 9537. https://doi.org/10.3390/app13179537
Rosenbaum T, Cohen I, Winebrand E. Crossband Filtering for Weighted Prediction Error-Based Speech Dereverberation. Applied Sciences. 2023; 13(17):9537. https://doi.org/10.3390/app13179537
Chicago/Turabian StyleRosenbaum, Tomer, Israel Cohen, and Emil Winebrand. 2023. "Crossband Filtering for Weighted Prediction Error-Based Speech Dereverberation" Applied Sciences 13, no. 17: 9537. https://doi.org/10.3390/app13179537
APA StyleRosenbaum, T., Cohen, I., & Winebrand, E. (2023). Crossband Filtering for Weighted Prediction Error-Based Speech Dereverberation. Applied Sciences, 13(17), 9537. https://doi.org/10.3390/app13179537