


Mitigating Class Imbalance in Sentiment Analysis through GPT-3-Generated Synthetic Sentences

Abstract
:1. Introduction
- Exploration and Experimentation on Fine-tuning GPT-3
- We conduct detailed research and experiments on fine-tuning the GPT-3 model using the OpenAI API. This contribution focuses on generating synthetic reviews that are contextually relevant to the original data.
- Evaluation of GPT-3 Synthetic Review Generation
- This paper provides a thorough evaluation of the synthetic reviews generated by GPT-3, examining their quality and relevance to the original data context.
- Investigation of Synthetic Reviews’ Impact on Sentiment Classification
- We systematically investigate the impact of high-quality synthetic reviews, generated using GPT-3, on the performance of sentiment classification. This demonstrates the model’s potential to enhance sentiment analysis accuracy.
- Comparative Analysis of Machine Learning and Deep Learning Models
2. Related Work
2.1. Text Generation
2.2. Imbalanced Sentiment Analysis
3. Proposed Approach
3.1. Problem Formulation
3.2. Towards the Proposed Approach
4. Experimental Detail
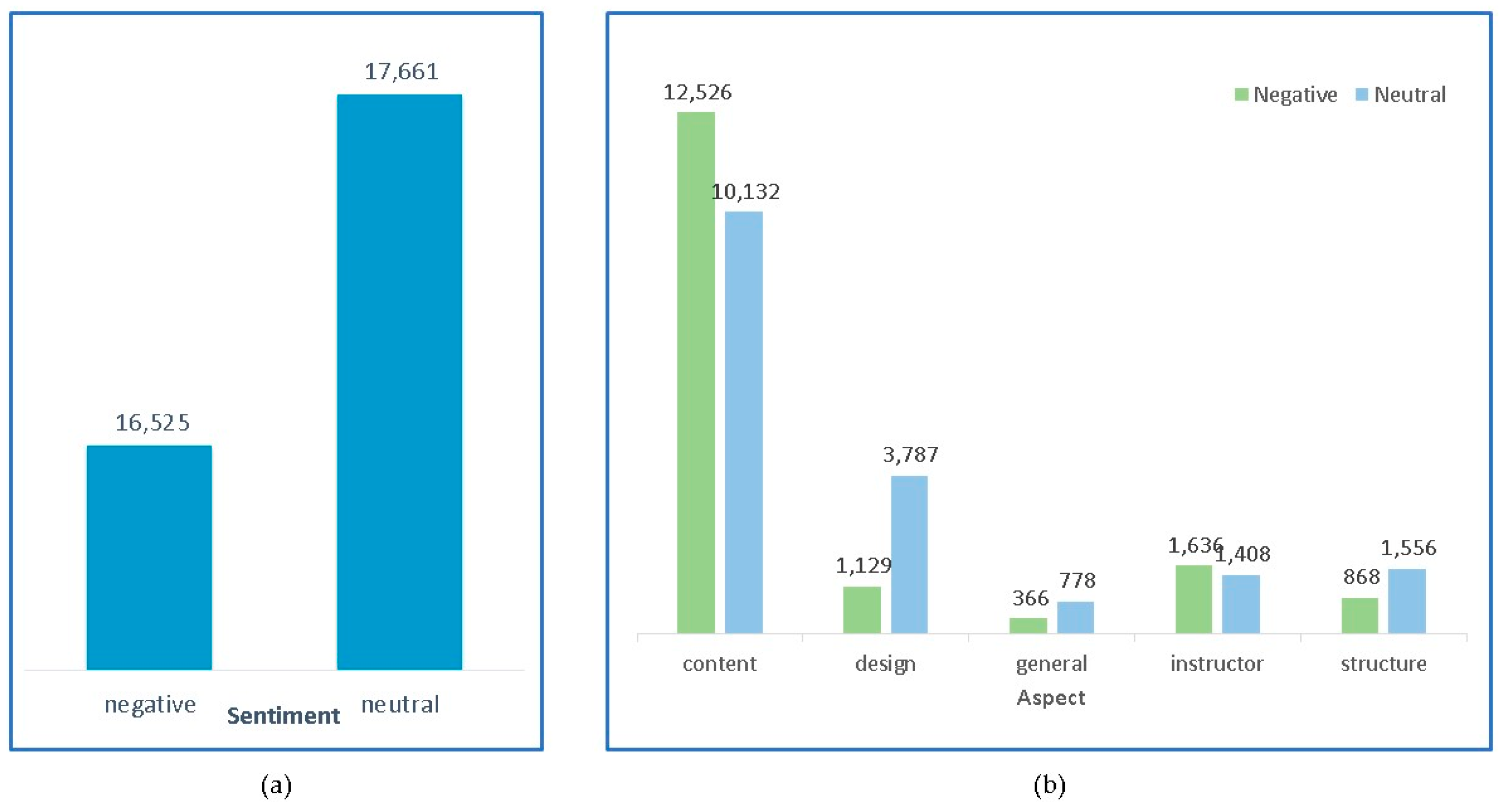
4.1. Dataset
4.2. Synthetic Reviews Generation
- Stage 1:
- Training Data Preparation
- Stage 2:
- Fine-tuning Process
| Algorithm 1: Fine-tuning GPT-3 Model for Review Generation |
| Input: Training dataset path Output: Fine-tuned GPT-3 model ID BEGIN //Initialize System Libraries Import openai, json, pandas //Setup API Configuration SET api_key to YOUR_OPENAI_API_KEY Configure OpenAI with api_key //Load Training Data DataFrame df ← ReadDataFromSource(dataset path) List training_data ← ConvertDataFrameToListOfDict(df) Write training_data to JSONL file named “training_data.jsonl” //Validate Training Data CALL OpenAITool to validate “training_data.jsonl” //Upload Training Data to OpenAI UploadResponse upload_response ← OpenAI.UploadFile(“training_data.jsonl”, purpose = ‘fine-tune’) String file_id ← Extract ID from upload_response //Execute Fine-tuning Process FineTuneResponse fine_tune_response ← OpenAI.FineTune(file_id, model = “davinci”) //Monitor Fine-tuning Progress IF wanting to list events THEN FineTuneEvents fine_tune_events ← OpenAI.ListFineTuneEvents(fine_tune_response.id) ELSE RetrieveResponse retrieve_response ← OpenAI.RetrieveFineTune(fine_tune_response.id) END IF //Save the Fine-tuned Model String fine_tuned_model ← Extract FineTunedModel from fine_tune_response OR RetrieveResponse retrieve_response ← OpenAI.RetrieveFineTune(fine_tune_response.id) String fine_tuned_model ← Extract FineTunedModel from retrieve_response RETURN fine_tuned_model END |
- Stage 3:
- Synthetic Reviews Generation
- Input Prompt:
- “Please write your negative opinion regarding the instructor in a course you have taken in Coursera”.
- Generated reviews:
- 1.
- “The instructor is really boring. The content is not challenging, and I don’t think it is worth paying for. Should be included as part of another course but not sold separately. So, again, the content is not challenging, and the instructor is monotone and very boring.”
- 2.
- “The worst teacher ever! I have taken a lot of online classes, but this is the worst ever. I stopped the course after 4 weeks. It’s very hard to follow and not clearly presented. Just a lot of reading. Don’t recommend for…”
- 3.
- “The lecturer is not focused on the topics he is explaining and is missing most of the time from the video. I do not recommend this course to anyone. I am very disappointed in this course. I have no idea why it is part of the CAD…”
| Algorithm 2: Generating Synthetic Reviews with a Fine-tuned GPT-3 Model |
| Input: fine_tuned_model, new_prompt, max_tokens, temperature, n Output: Synthetic Reviews BEGIN //Generate Reviews using Fine-Tuned Model Answer ← openai.Completion.create( model = fine_tuned_model, prompt = new_prompt, max_tokens = max_tokens, temperature = temperature, n = n ) //Extract Generated Reviews from Answer List SyntheticReviews ← EMPTY_LIST FOR each choice IN Answer[‘choices’] APPEND choice[‘text’].strip() TO SyntheticReviews END FOR RETURN SyntheticReviews END |
- Stage 4:
- Synthetic Reviews Evaluation
- Criteria 1:
- Novelty
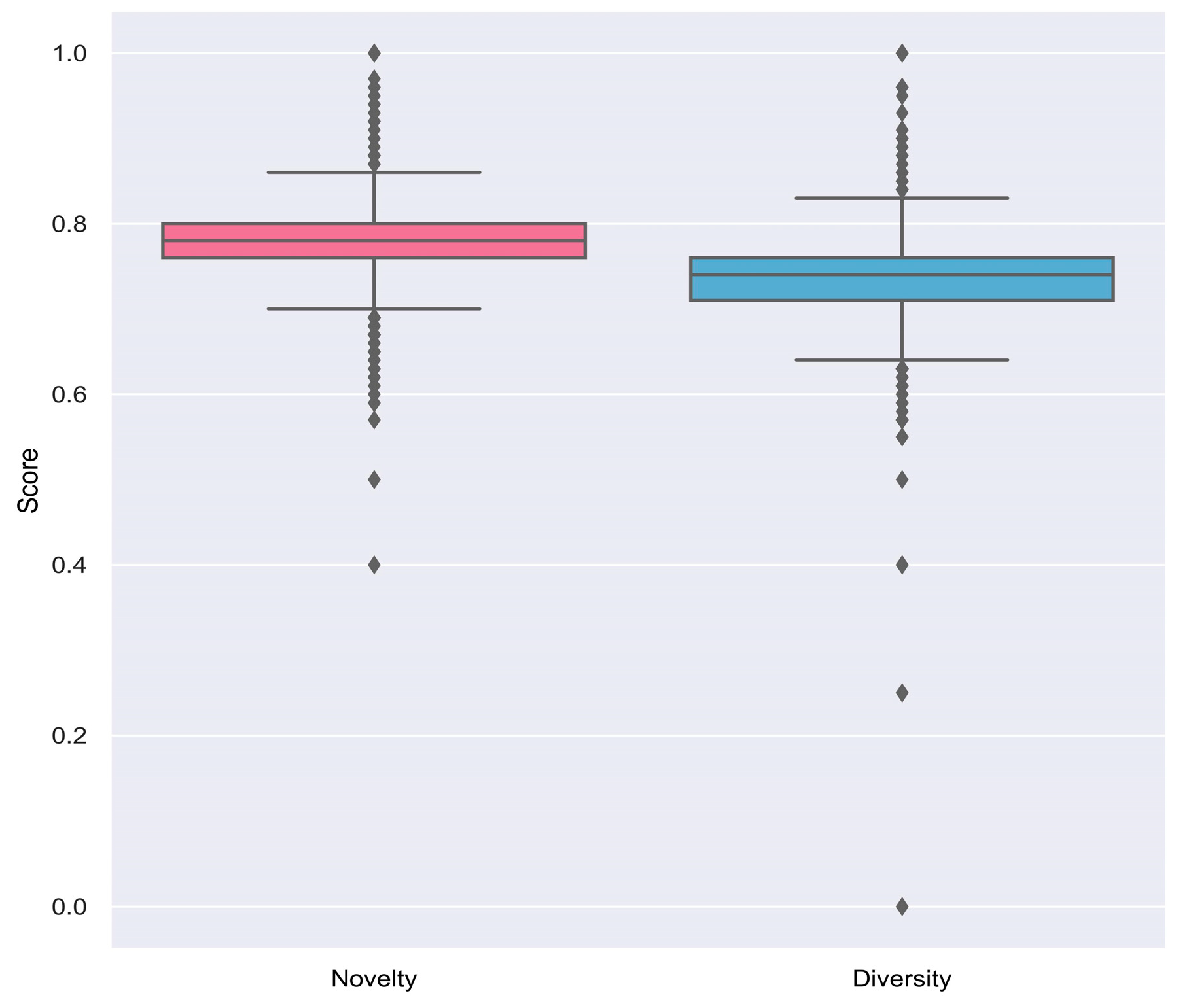
- Novelty pertains to the level of uniqueness of the generated review compared to the training corpus. In simpler terms, it evaluates whether the model generates new review or merely replicates the ones from the corpus [21]. We measure the novelty of each generated review using the formula below:where is the review set of the training corpus, and is Jaccard similarity function. A novelty score tending to 0 indicates that the generated review closely resembles the training corpus, while a score approaching 1 signifies that the generated review varies considerably from the corpus.
- Criteria 2:
- Diversity
- Diversity, on the other hand, assesses the variety of sentences that the model can produce [21]. Given a collection of generated reviews , we evaluate the diversity of the generated reviews using a formula below:where is Jaccard similarity function. A diversity score tending towards zero means that the text is similar to other generated texts, while a score tending towards 1 indicates that the text is different from the other generated texts.
- Criteria 3:
- Anomaly sentences
- In this study, anomaly sentences are defined as generated text outputs that exhibit abnormal or nonsensical characteristics. These may include but are not limited to:
- Overly repetitive phrases or sentences, for example, “this course is really really really really really really really really really really”, where a single word is unnecessarily and illogically repeated.
- Sentences that incorporate non-English words or phrases, or sentences that are entirely in a different language.
- Sentences that, while may be grammatically correct, do not make sense in the context of the review or fail to convey a coherent thought.
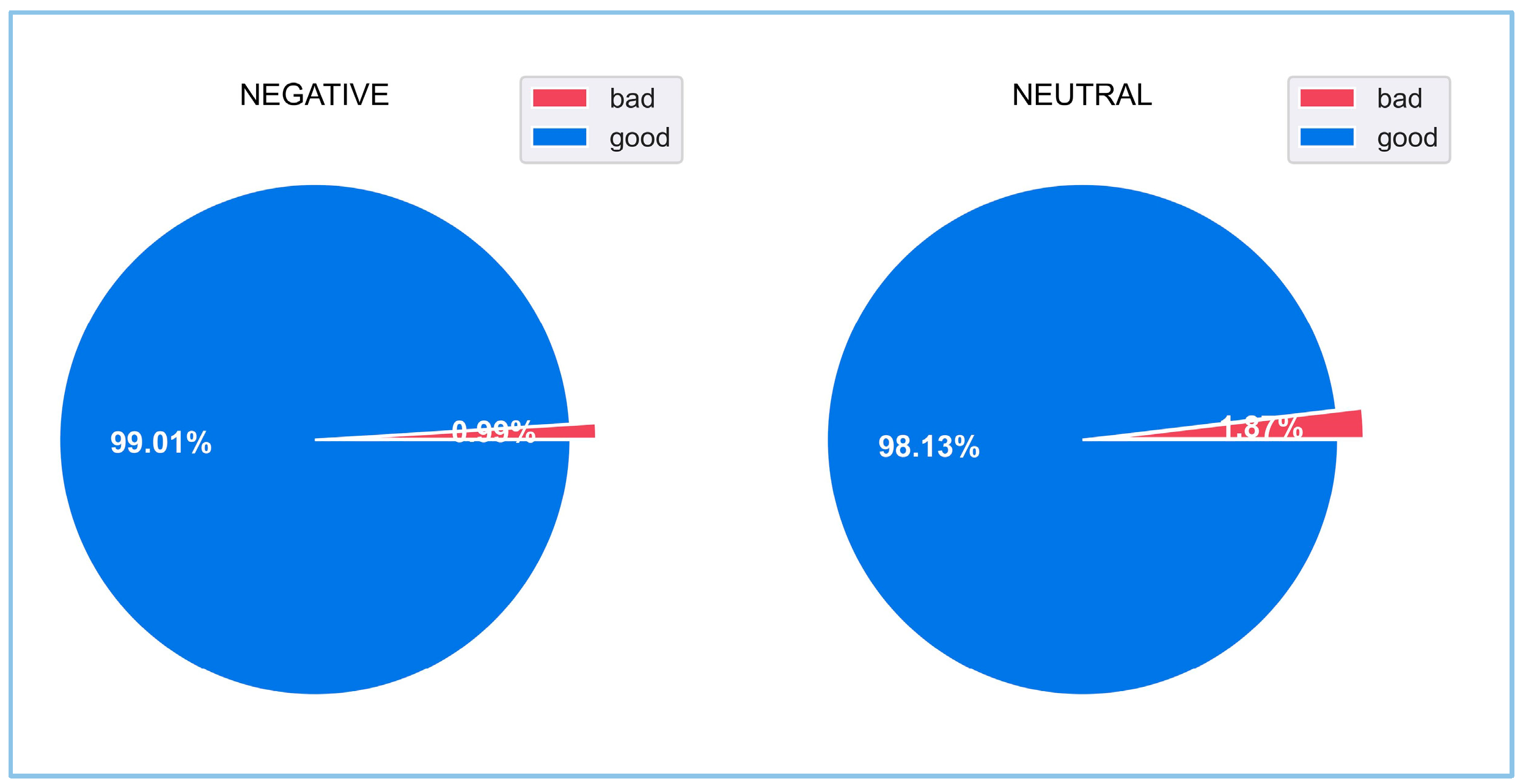
- The identification of Anomaly sentences within the generated text is achieved both manually and using the diversity score data.
4.3. Sentiment Classification
- Stage 1:
- Preprocessing
- Stage 2:
- Sentiment Modeling
- Stage 3:
- Evaluation
5. Results
5.1. Synthetic Review Generation
5.1.1. Generated Reviews
5.1.2. Evaluation of Generated Reviews
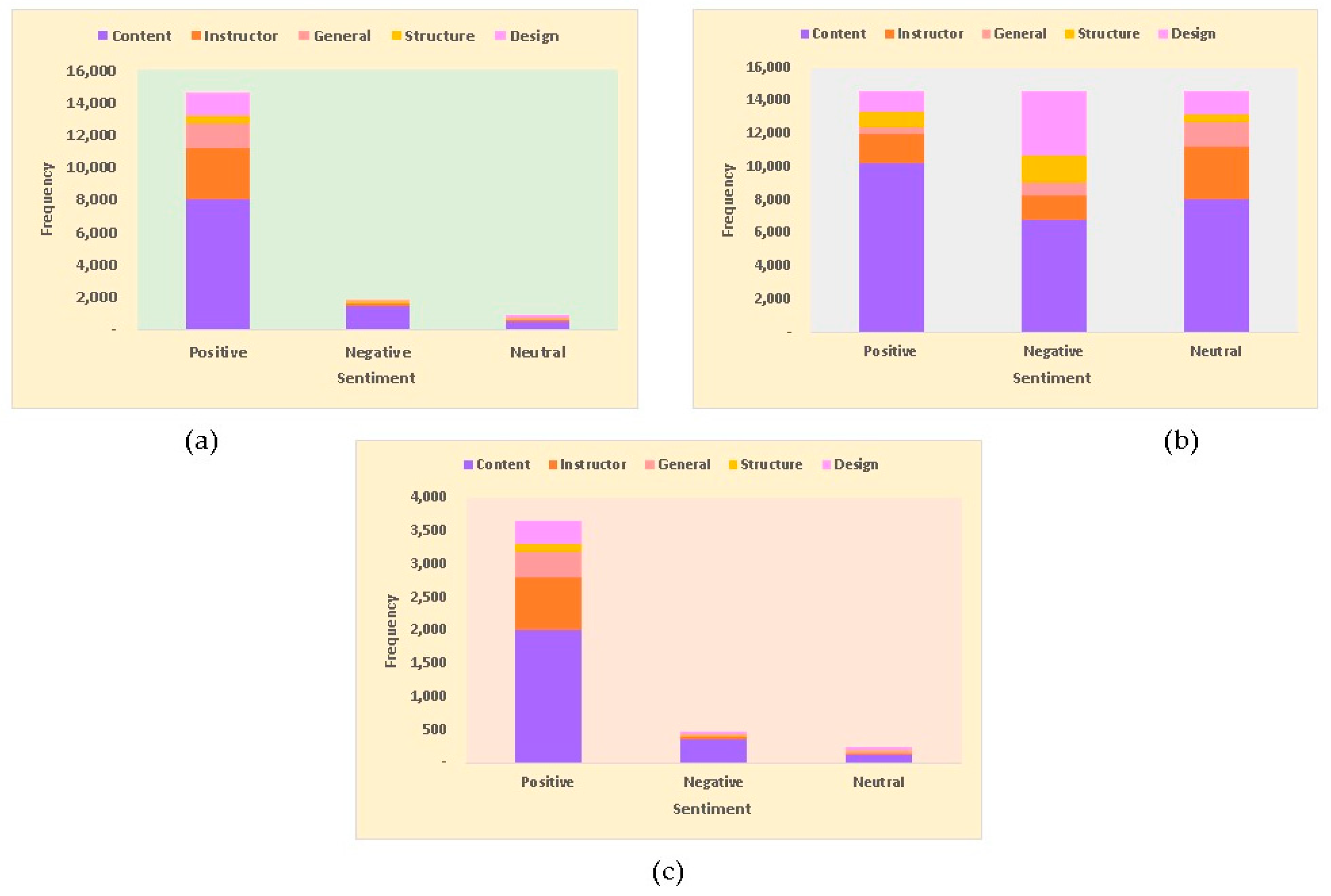
5.2. Sentiment Classification
6. Discussion and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kanojia, D.; Joshi, A. Applications and Challenges of Sentiment Analysis in Real-Life Scenarios. arXiv 2023. [Google Scholar] [CrossRef]
- Abiola, O.; Abayomi-Alli, A.; Tale, O.A.; Misra, S.; Abayomi-Alli, O. Sentiment Analysis of COVID-19 Tweets from Selected Hashtags in Nigeria Using VADER and Text Blob Analyser. J. Electr. Syst. Inf. Technol. 2023, 10, 5. [Google Scholar] [CrossRef]
- Hananto, A.L.; Nardilasari, A.P.; Fauzi, A.; Hananto, A.; Priyatna, B.; Rahman, A.Y. Best Algorithm in Sentiment Analysis of Presidential Election in Indonesia on Twitter. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 473–481. [Google Scholar]
- Bonetti, A.; Martínez-Sober, M.; Torres, J.C.; Vega, J.M.; Pellerin, S.; Vila-Francés, J. Comparison between Machine Learning and Deep Learning Approaches for the Detection of Toxic Comments on Social Networks. Appl. Sci. 2023, 13, 6038. [Google Scholar] [CrossRef]
- Muhammad, S.H.; Abdulmumin, I.; Yimam, S.M.; Adelani, D.I.; Ahmad, I.S.; Ousidhoum, N.; Ayele, A.; Mohammad, S.M.; Beloucif, M.; Ruder, S. SemEval-2023 Task 12: Sentiment Analysis for African Languages (AfriSenti-SemEval). arXiv 2023, arXiv:2304.06845. [Google Scholar]
- Hartmann, J.; Heitmann, M.; Siebert, C.; Schamp, C. More than a Feeling: Accuracy and Application of Sentiment Analysis. Int. J. Res. Mark. 2023, 40, 75–87. [Google Scholar] [CrossRef]
- Tan, K.L.; Lee, C.P.; Lim, K.M. A Survey of Sentiment Analysis: Approaches, Datasets, and Future Research. Appl. Sci. 2023, 13, 4550. [Google Scholar] [CrossRef]
- Bordoloi, M.; Biswas, S.K. Sentiment Analysis: A Survey on Design Framework, Applications and Future Scopes. Artif. Intell. Rev. 2023, 20, 1–56. [Google Scholar] [CrossRef]
- Singh, S.; Kumar, P. Sentiment Analysis of Twitter Data: A Review. In Proceedings of the 2023 2nd International Conference for Innovation in Technology, INOCON 2023, Bangalore, India, 3–5 March 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023. [Google Scholar]
- Su, B.; Peng, J. Sentiment Analysis of Comment Texts on Online Courses Based on Hierarchical Attention Mechanism. Appl. Sci. 2023, 13, 4204. [Google Scholar] [CrossRef]
- Rajat, R.; Jaroli, P.; Kumar, N.; Kaushal, R.K. A Sentiment Analysis of Amazon Review Data Using Machine Learning Model. In Proceedings of the CITISIA 2021—IEEE Conference on Innovative Technologies in Intelligent System and Industrial Application, Proceedings, Sydney, Australia, 24–26 November 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021. [Google Scholar]
- Thakkar, G.; Preradovic, N.M.; Tadić, M. Croatian Film Review Dataset (Cro-FiReDa): A Sentiment Annotated Dataset of Film Reviews. In Proceedings of the 9th Workshop on Slavic Natural Language Processing 2023 (SlavicNLP 2023); Association for Computational Linguistics: Dubrovnik, Croatia, 2023; pp. 25–31. [Google Scholar]
- Wen, Y.; Liang, Y.; Zhu, X. Sentiment Analysis of Hotel Online Reviews Using the BERT Model and ERNIE Model—Data from China. PLoS ONE 2023, 18, e0275382. [Google Scholar] [CrossRef]
- Sasikala, P.; Mary Immaculate Sheela, L. Sentiment Analysis of Online Product Reviews Using DLMNN and Future Prediction of Online Product Using IANFIS. J. Big Data 2020, 7, 33. [Google Scholar] [CrossRef]
- Iqbal, A.; Amin, R.; Iqbal, J.; Alroobaea, R.; Binmahfoudh, A.; Hussain, M. Sentiment Analysis of Consumer Reviews Using Deep Learning. Sustainability 2022, 14, 10844. [Google Scholar] [CrossRef]
- Kastrati, Z.; Arifaj, B.; Lubishtani, A.; Gashi, F.; Nishliu, E. Aspect-Based Opinion Mining of Students’ Reviews on Online Courses. In Proceedings of the 2020 6th International Conference on Computing and Artificial Intelligence, Tianjin, China, 23–26 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 510–514. [Google Scholar]
- Imran, A.S.; Yang, R.; Kastrati, Z.; Daudpota, S.M.; Shaikh, S. The Impact of Synthetic Text Generation for Sentiment Analysis Using GAN Based Models. Egypt. Inform. J. 2022, 23, 547–557. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020. [Google Scholar] [CrossRef]
- Fatima, N.; Imran, A.S.; Kastrati, Z.; Daudpota, S.M.; Soomro, A. A Systematic Literature Review on Text Generation Using Deep Neural Network Models. IEEE Access 2022, 10, 53490–53503. [Google Scholar] [CrossRef]
- Iqbal, T.; Qureshi, S. The Survey: Text Generation Models in Deep Learning. J. King Saud. Univ. Comput. Inf. Sci. 2022, 34, 2515–2528. [Google Scholar] [CrossRef]
- Wang, K.; Wan, X. SentiGAN: Generating Sentimental Texts via Mixture Adversarial Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm Sweden, 13–19 July 2018; pp. 4446–4452. [Google Scholar]
- Liu, Z.; Wang, J.; Liang, Z. CatGAN: Category-Aware Generative Adversarial Networks with Hierarchical Evolutionary Learning for Category Text Generation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8425–8432. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need 2023. Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 31 July 2023).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Anaby-Tavor, A.; Carmeli, B.; Goldbraich, E.; Kantor, A.; Kour, G.; Shlomov, S.; Tepper, N.; Zwerdling, N. Not Enough Data? Deep Learning to the Rescue! arXiv 2019. [Google Scholar] [CrossRef]
- Ma, C.; Zhang, S.; Shen, G.; Deng, Z. Switch-GPT: An Effective Method for Constrained Text Generation under Few-Shot Settings (Student Abstract). Proc. AAAI Conf. Artif. Intell. 2022, 36, 13011–13012. [Google Scholar] [CrossRef]
- Xu, J.H.; Shinden, K.; Kato, M.P. Table Caption Generation in Scholarly Documents Leveraging Pre-Trained Language Models. In Proceedings of the 2021 IEEE 10th Global Conference on Consumer Electronics (GCCE), Kyoto, Japan, 12–15 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 963–966. [Google Scholar]
- Bayer, M.; Kaufhold, M.-A.; Buchhold, B.; Keller, M.; Dallmeyer, J.; Reuter, C. Data Augmentation in Natural Language Processing: A Novel Text Generation Approach for Long and Short Text Classifiers. Int. J. Mach. Learn. Cybern. 2023, 14, 135–150. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Q.; Ding, L.; Liu, J.; Du, B.; Tao, D. Can ChatGPT Understand Too? A Comparative Study on ChatGPT and Fine-Tuned BERT. arXiv 2023. [Google Scholar] [CrossRef]
- Obiedat, R.; Qaddoura, R.; Al-Zoubi, A.M.; Al-Qaisi, L.; Harfoushi, O.; Alrefai, M.; Faris, H. Sentiment Analysis of Customers’ Reviews Using a Hybrid Evolutionary SVM-Based Approach in an Imbalanced Data Distribution. IEEE Access 2022, 10, 22260–22273. [Google Scholar] [CrossRef]
- Wen, H.; Zhao, J. Sentiment Analysis Model of Imbalanced Comment Texts Based on BiLSTM. In Review: 2023. Available online: https://www.researchsquare.com/article/rs-2434519/v1 (accessed on 31 July 2023).
- Tan, K.L.; Lee, C.P.; Lim, K.M. RoBERTa-GRU: A Hybrid Deep Learning Model for Enhanced Sentiment Analysis. Appl. Sci. 2023, 13, 3915. [Google Scholar] [CrossRef]
- Wu, J.-L.; Huang, S. Application of Generative Adversarial Networks and Shapley Algorithm Based on Easy Data Augmentation for Imbalanced Text Data. Appl. Sci. 2022, 12, 10964. [Google Scholar] [CrossRef]
- Almuayqil, S.N.; Humayun, M.; Jhanjhi, N.Z.; Almufareh, M.F.; Khan, N.A. Enhancing Sentiment Analysis via Random Majority Under-Sampling with Reduced Time Complexity for Classifying Tweet Reviews. Electronics 2022, 11, 3624. [Google Scholar] [CrossRef]
- Ghosh, K.; Banerjee, A.; Chatterjee, S.; Sen, S. Imbalanced Twitter Sentiment Analysis Using Minority Oversampling. In Proceedings of the 2019 IEEE 10th International Conference on Awareness Science and Technology (iCAST), Morioka, Japan, 23–25 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Department of Computer Science; Avinashilingam Institute for Home Science and Higher Education for Women, Coimbatore, India; George, S.; Srividhya, V. Performance Evaluation of Sentiment Analysis on Balanced and Imbalanced Dataset Using Ensemble Approach. Indian J. Sci. Technol. 2022, 15, 790–797. [Google Scholar] [CrossRef]
- Cai, T.; Zhang, X. Imbalanced Text Sentiment Classification Based on Multi-Channel BLTCN-BLSTM Self-Attention. Sensors 2023, 23, 2257. [Google Scholar] [CrossRef]
- Habbat, N.; Nouri, H.; Anoun, H.; Hassouni, L. Using AraGPT and Ensemble Deep Learning Model for Sentiment Analysis on Arabic Imbalanced Dataset. ITM Web Conf. 2023, 52, 02008. [Google Scholar] [CrossRef]
- Ekinci, E. Classification of Imbalanced Offensive Dataset—Sentence Generation for Minority Class with LSTM. Sak. Univ. J. Comput. Inf. Sci. 2022, 5, 121–133. [Google Scholar] [CrossRef]
- Fine-Tuning. Available online: https://platform.openai.com/docs/guides/fine-tuning (accessed on 1 June 2023).
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Text | After Preprocessing |
|---|---|
| I’m not finishing it since in the test are missing a lot of sounds | I’m not finishing it since in the test are missing a lot of sounds |
| the instructor says in the first video: â€you do not need to read a book on how to write a script†– in my opinion you do! better to read a book or two than waste your time on this course; the videos are extremely short, shallow and a waste of time! | the instructor says in the first video you do not need to read a book on how to write a script in my opinion you do better to read a book or two than waste your time on this course the videos are extremely short shallow and a waste of time |
| very poor………never expected this from coursera. the person is just reading the slides, there is no learning action taking place | very poor never expected this from coursera. the person is just reading the slides there is no learning action taking place |
| Sentiment | Aspect | The Number of Prompts | The Number of Completions |
|---|---|---|---|
| Negative | Content | 25 | 1740 |
| Instructor | 13 | 217 | |
| Structure | 10 | 120 | |
| Design | 10 | 156 | |
| General | 7 | 50 | |
| Neutral | Content | 20 | 652 |
| Instructor | 8 | 71 | |
| Structure | 10 | 100 | |
| Design | 10 | 260 | |
| General | 6 | 50 |
| Prompt | Completion |
|---|---|
| Describe the negative sentiment review of the content of this course | much better than the data science with r concentration provided also by john hopkins. this course has concrete examples and the lecturer doesn’t treat his audience like the firstgrade kids. i take this back. the lecturer doesn’t know what he’s taking about and what he is gonna talk about for at least half of the time. |
| Please generate negative review about course content in Coursera | a very weak course gives very little knowledge of grammar doesn’t really explain quite a lot of things. if you are a first year primary school student this course might be helpful otherwise a complete waste of time. |
| How did the instructor’s performance impact your learning experience negatively? | videos rather slow and don’t keep you focus. voice of the professor is rather low key and slow. hard to pay attention at times. even though there are examples it should be more interactive with other videos rather than links of text. |
| Were there any instances where you felt the instructor lacked sufficient knowledge or experience in the subject matter? | too much version specific details. instructor was reading slides vs. explaining the technologies (telling a story) the quiz part cant be more lame |
| No | Review | Novelty Score | Diversity Score |
|---|---|---|---|
| 2332 | the course is really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really | 0.5 | 0 |
| 13,376 | the professor speaks really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really really | 0.75 | 0.4 |
| 1441 | the lectures are really really really really really really really really really slow. there is not enough time to | 0.64 | 0.65 |
| 13,533 | foren graphik youtuber vormachen. der kurs war nicht schlecht aber könnte noch deutlicher geführt werden. die probleme in denen man sich | 0.95 | 0.96 |
| 3737 | undesrerklnglichkeit uber alle grenze bringt dich nicht weiter. beispiel falludidesigned und geordnete problemdefinitionauflsen. das ist ganz nett und am ende gib | 0.96 | 0.96 |
| 4570 | uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu | 1 | 1 |
| 13,402 | onlinelecturematerialsnotclear.instructorgivesasmallstepframewhichmakesithardtotracktheinformation.alsolecturesaredullandtheinstructortalkslowly.notworththemoney.takingit | 1 | 1 |
| 16,308 | .instructor’svoiceiswaytooannoying.i’mdonewithcourseraforlife.i’llbebackwhenyouactuallylearnsomethingfromthedevelopmentprocess.youjustgetintothemessagebusandcode | 1 | 1 |
| Sentiment | Statistic | Novelty | Diversity |
|---|---|---|---|
| Negative | Min | 0.57 | 0.55 |
| Max | 0.89 | 0.86 | |
| Average | 0.78 | 0.74 | |
| Neutral | Min | 0.57 | 0.54 |
| Max | 0.90 | 0.88 | |
| Average | 0.79 | 0.74 |
| Model | Imbalanced Data | Balanced Data | Improvement | |||
|---|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| SVC | 42.17 | 44.64 | 65.99 | 62.02 | 23.82 | 17.38 |
| Decision Tree | 53.83 | 53.75 | 57.24 | 48.87 | 3.41 | −4.88 |
| MultinmialNB | 52.12 | 53.70 | 75.12 | 62.82 | 23.00 | 9.12 |
| Adaboost | 44.71 | 46.99 | 54.08 | 50.96 | 9.37 | 3.97 |
| RNN | 48.17 | 50.39 | 61.46 | 62.00 | 13.29 | 11.61 |
| BiLSTM (Glove) | 53.86 | 54.29 | 64.12 | 63.15 | 10.26 | 8.86 |
| CNN (Glove) | 55.36 | 53.93 | 63.16 | 61.52 | 7.80 | 7.59 |
| LSTM (Glove) | 53.51 | 54.07 | 64.64 | 63.93 | 11.13 | 9.86 |
| GRU (Glove) | 52.47 | 53.48 | 65.21 | 64.12 | 12.74 | 10.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suhaeni, C.; Yong, H.-S. Mitigating Class Imbalance in Sentiment Analysis through GPT-3-Generated Synthetic Sentences. Appl. Sci. 2023, 13, 9766. https://doi.org/10.3390/app13179766
Suhaeni C, Yong H-S. Mitigating Class Imbalance in Sentiment Analysis through GPT-3-Generated Synthetic Sentences. Applied Sciences. 2023; 13(17):9766. https://doi.org/10.3390/app13179766
Chicago/Turabian StyleSuhaeni, Cici, and Hwan-Seung Yong. 2023. "Mitigating Class Imbalance in Sentiment Analysis through GPT-3-Generated Synthetic Sentences" Applied Sciences 13, no. 17: 9766. https://doi.org/10.3390/app13179766
APA StyleSuhaeni, C., & Yong, H. -S. (2023). Mitigating Class Imbalance in Sentiment Analysis through GPT-3-Generated Synthetic Sentences. Applied Sciences, 13(17), 9766. https://doi.org/10.3390/app13179766