



Encoder–Decoder Structure Fusing Depth Information for Outdoor Semantic Segmentation

Abstract
:1. Introduction
2. Materials and Methods
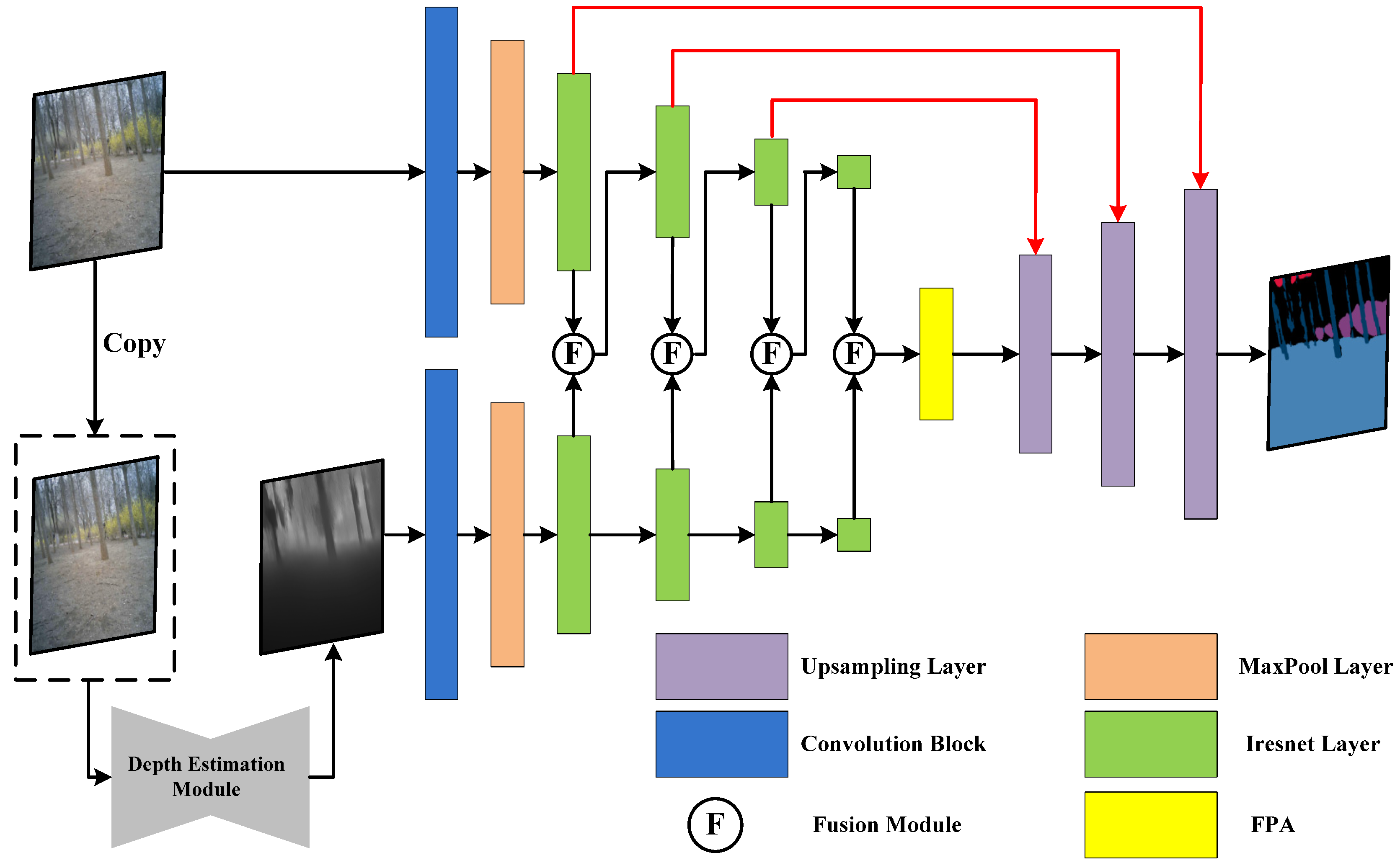
2.1. Semantic Segmentation Model
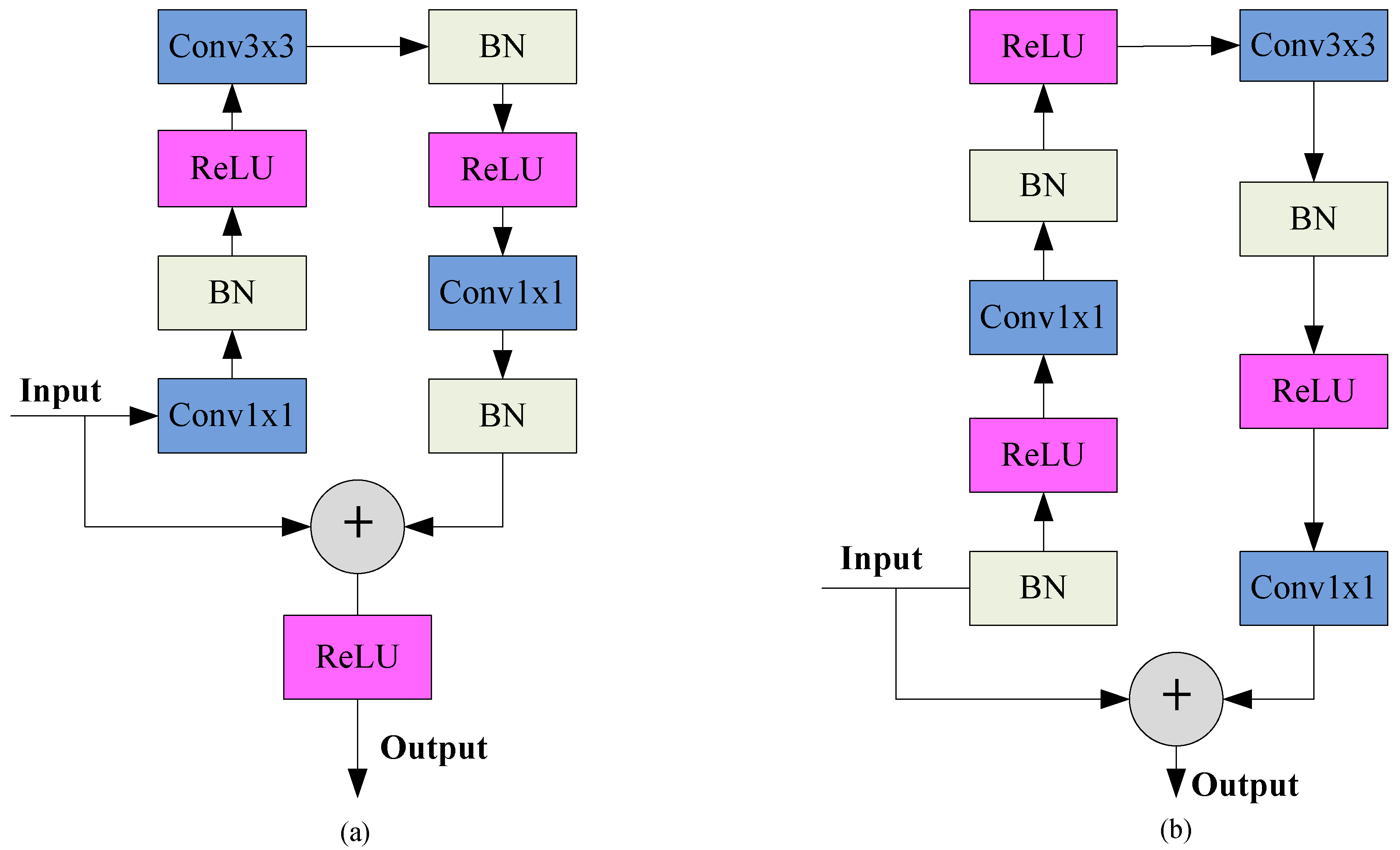
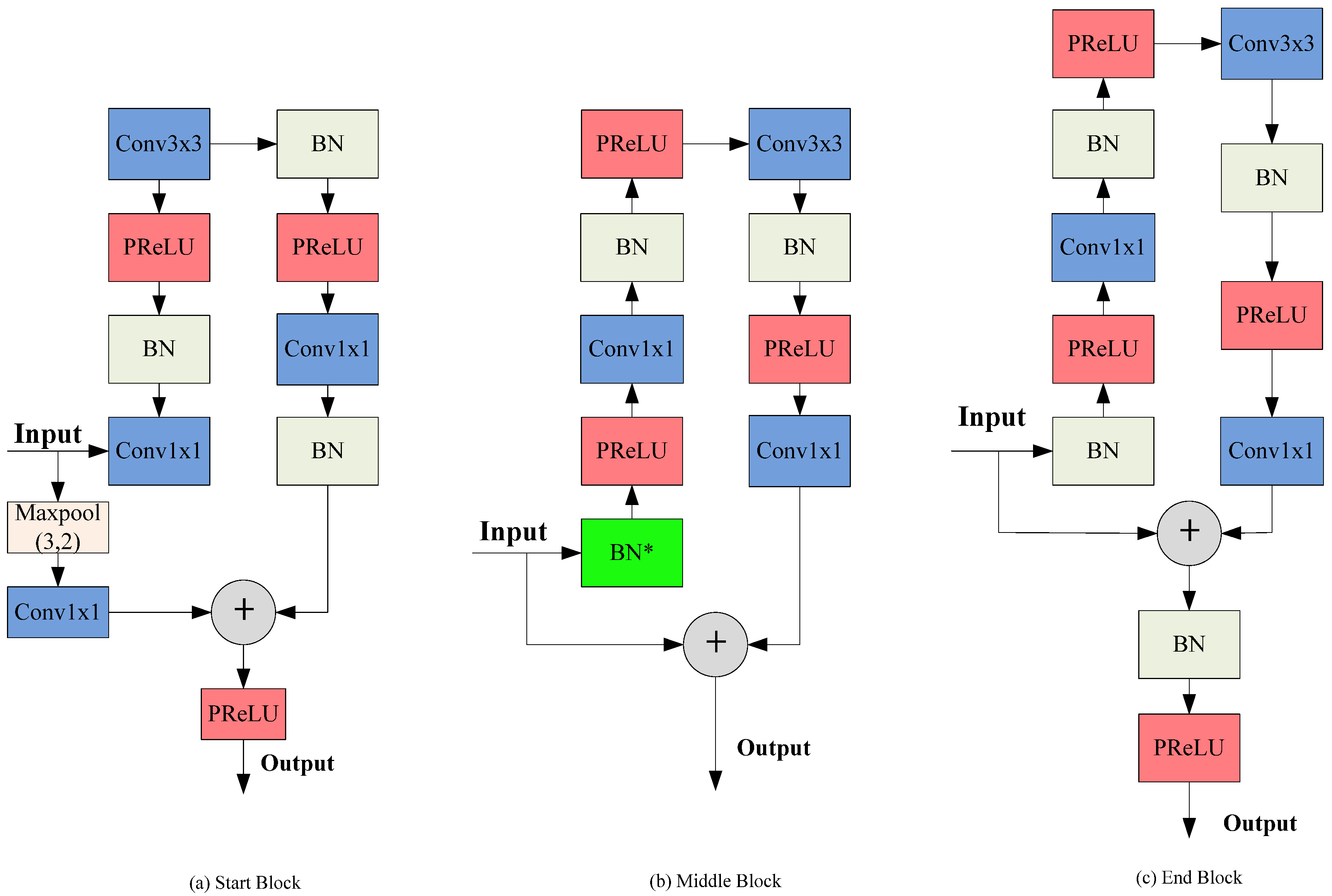
2.1.1. The Encoder Module
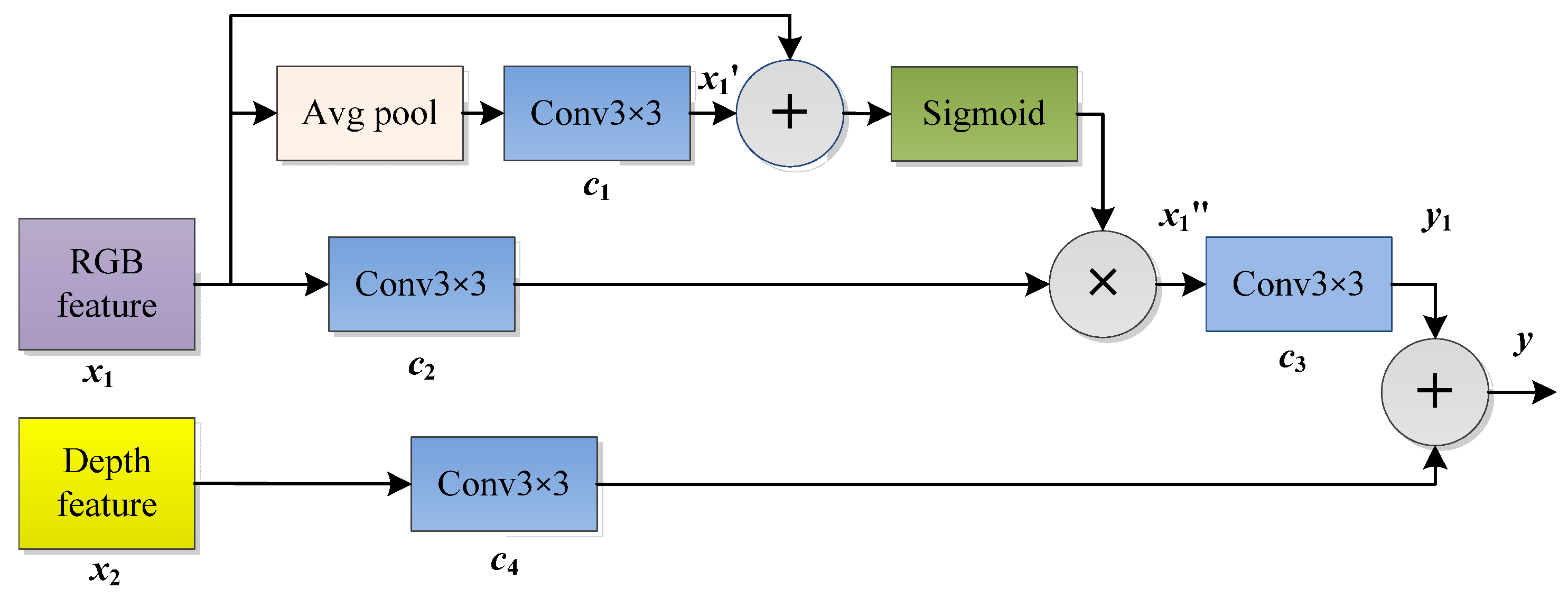
2.1.2. Self–Calibrating Fusion Architecture
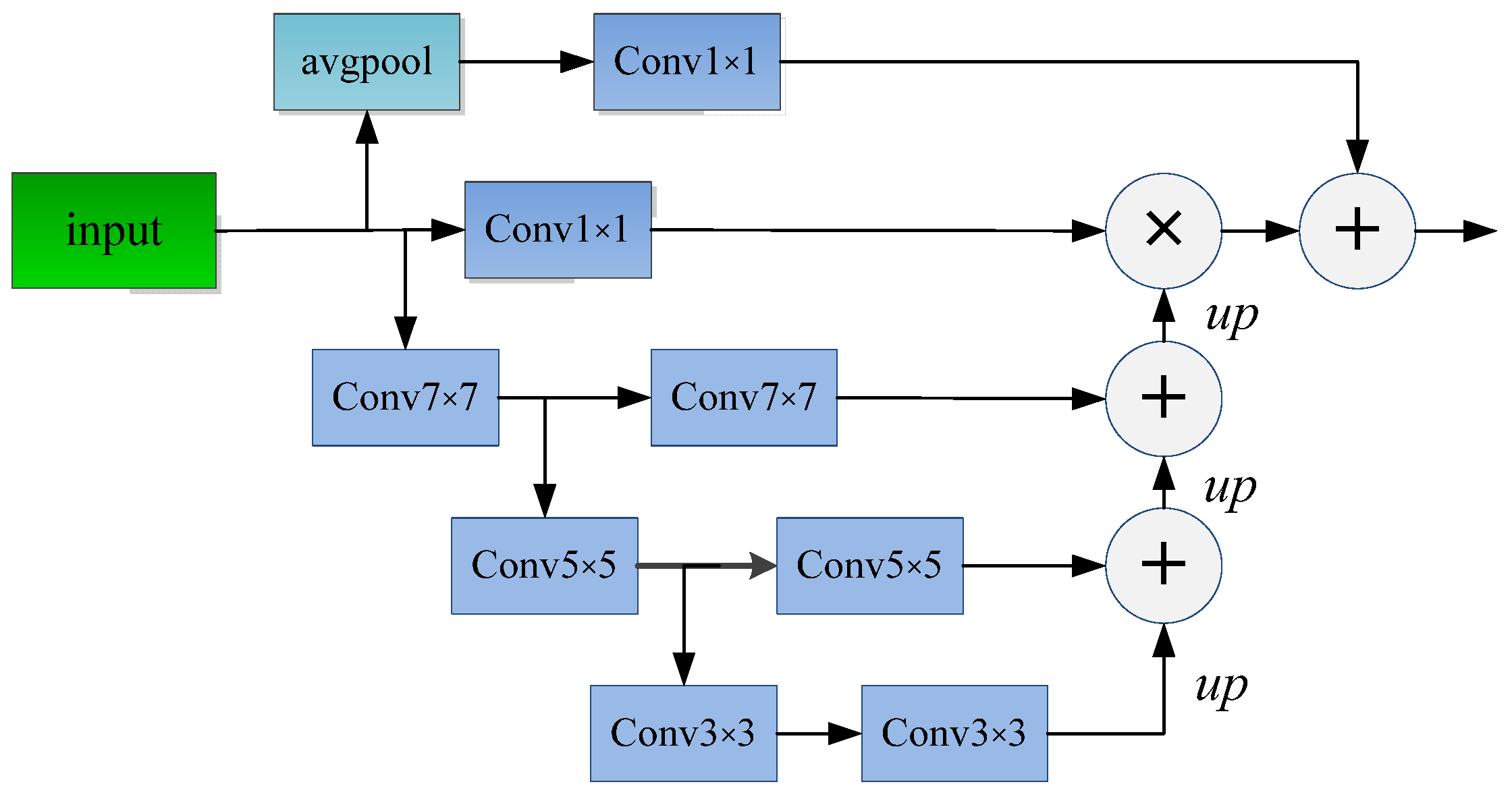
2.1.3. Feature Pyramid Attention Mechanism
2.1.4. The Decoder Module
2.2. Data Augmentation
- Random horizontal flip. Input images and the target ground truth are both horizontally flipped with a 0.5 probability.
- Random rotation. Input images and the target ground truth are both rotated with a random value.
- Scale. Input images and the target ground truth are both scaled by a random number u ∈ [0.5, 2].
- Random crop. Input images and the target ground truth are both center–cropped and then restored to the original size.
2.3. Loss Function
3. Experimentation
3.1. Brief Overview of Depth Estimation Methods
3.2. Training Dataset
3.3. Training Details
3.4. Evaluation Criteria
- I.
- Pixel accuracy (PA):
- II.
- Intersection over union (IoU):
- III.
- Mean intersection over union (mIoU):
- IV.
- Frequency weighted intersection over union(FWIoU):where is the total number of categories, indicates that the predicted category is i and the real category is also i and indicates that the predicted category is j and the real category is i.
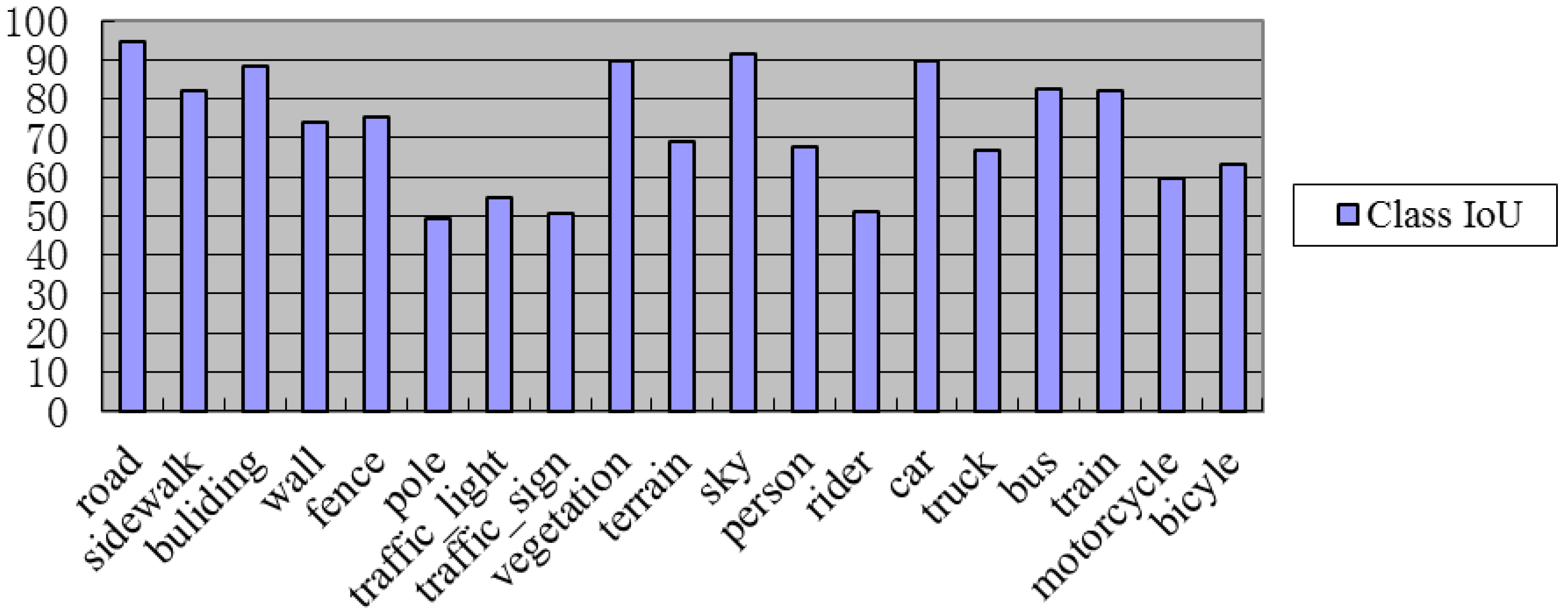
3.4.1. IoU Results for Different Object Classifications within the Cityscapes Dataset
3.4.2. mIoU Results for the Cityscapes Dataset
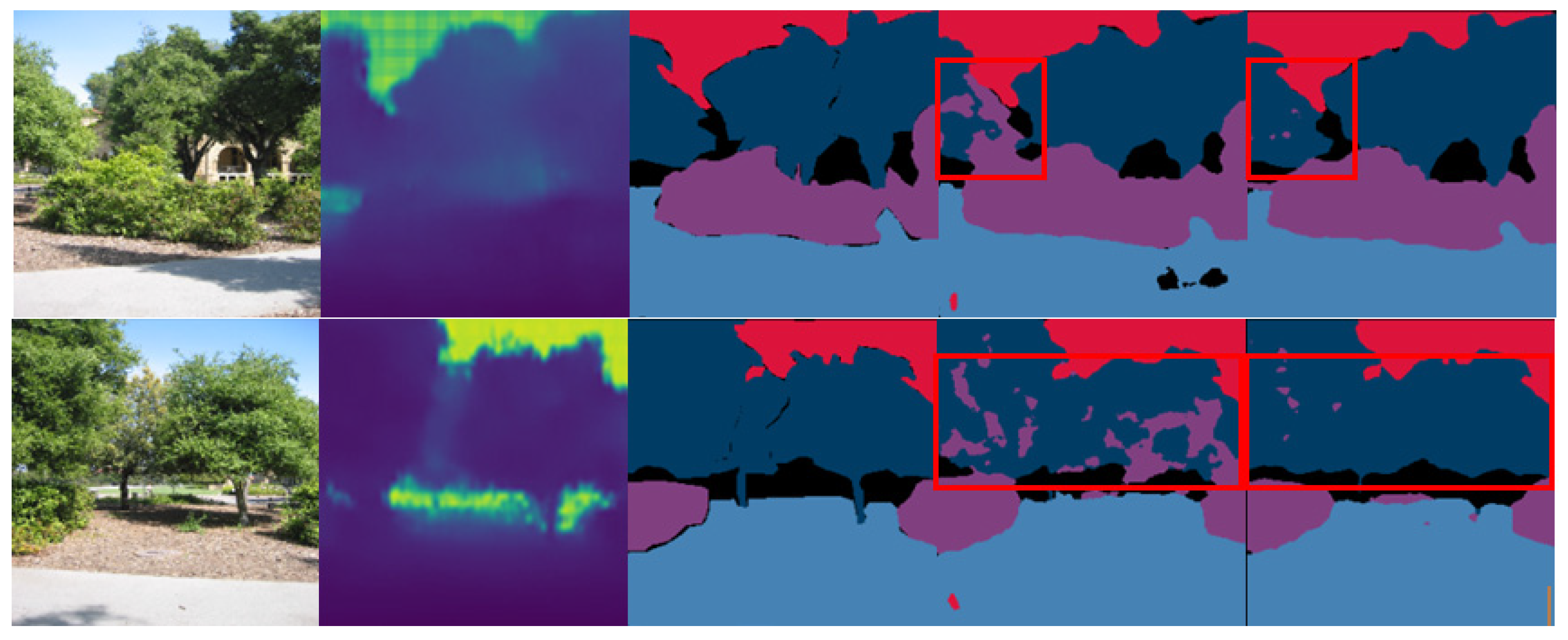
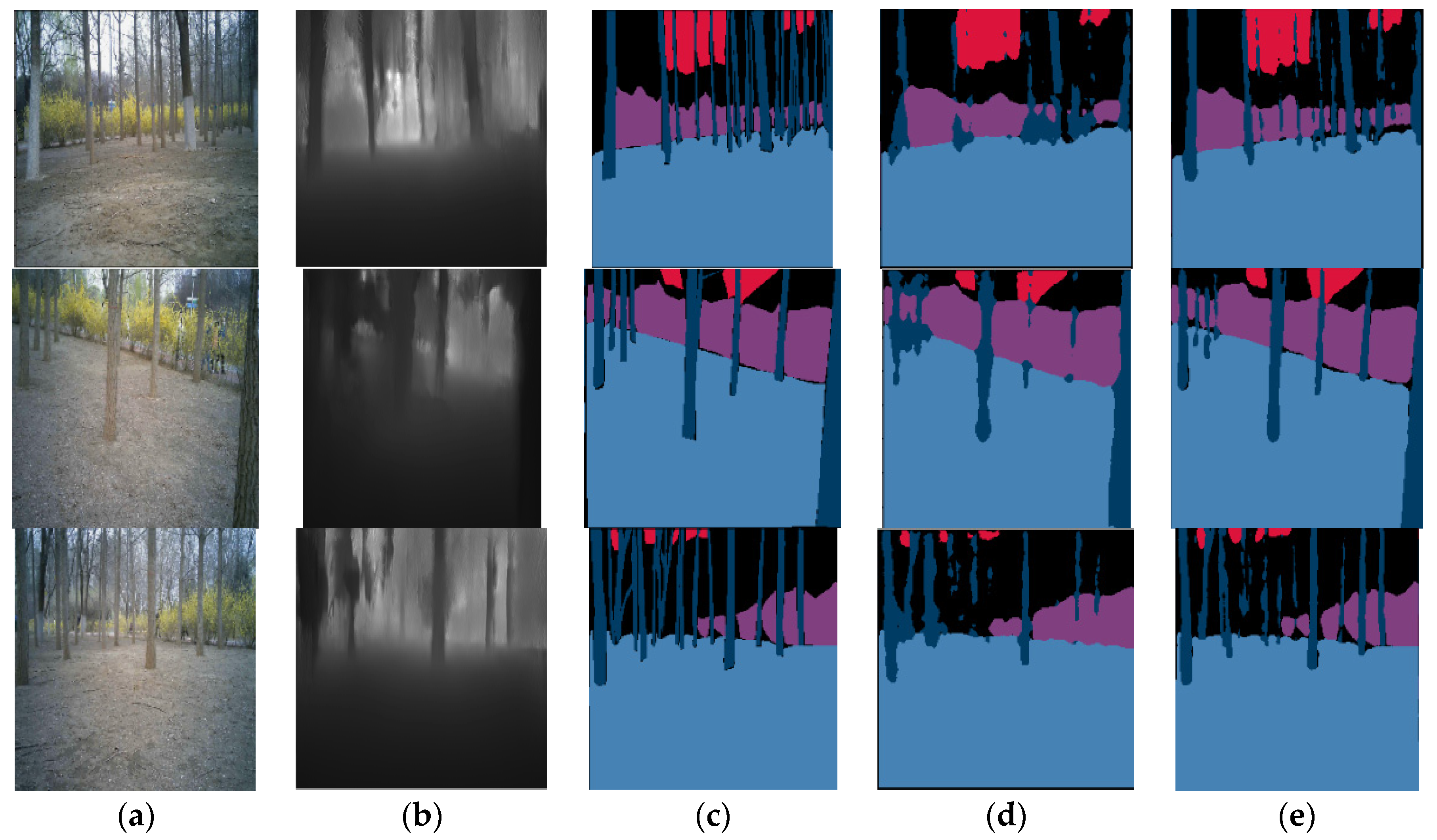
3.5. Experimental Results for the Forest Scene
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, Y.; Wang, H.; Liu, X.; He, H.R.; Gu, Q.; Sun, W. Learning to See the Hidden Part of the Vehicle in the Autopilot Scene. Electronics 2019, 8, 331. [Google Scholar] [CrossRef]
- Fusic, S.J.; Hariharan, K.; Sitharthan, R. Scene terrain classification for autonomous vehicle navigation based on semantic segmentation method. Trans. Inst. Meas. Control 2022, 44, 2574–2587. [Google Scholar] [CrossRef]
- Karri, M.; Annavarapu, C.S.R.; Acharya, U.R. Explainable multi–module semantic guided attention based network for medical image segmentation. Comput. Biol. Med. 2022, 151, 106231. [Google Scholar] [CrossRef] [PubMed]
- Yi, S.; Li, J.J.; Jiang, G. CCTseg: A cascade composite transformer semantic segmentation network for UAV visual perception. Measurement 2022, 151, 106231. [Google Scholar]
- Otsu, N. A threshold selection method from gray–level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Cong, S.P.; Sun, J.Z. Application of Watershed Algorithm for Segmenting Overlapping Cells in Microscopic Image. J. Image Graph. 2016, 103, 3505–3511. [Google Scholar]
- Shi, J.; Malik, J.M. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- AI–Awar, B.; Awad, M.M.; Jarlan, L.; Courault, D. Evaluation of Nonparametric Machine–Learning Algorithms for an Optimal Crop Classification Using Big Data Reduction Strategy. Remote Sens. Earth Syst. Sci. 2022, 5, 141–153. [Google Scholar]
- Jozwicki, D.; Sharma, P.; Mann, I.; Hoppe, U.P. Segmentation of PMSE Data Using Random Forests. Remote Sens. 2022, 14, 2976. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real–World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep Convolutional networks for large–scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Cao, L.M.; Yang, Z.W. Use square root affinity to regress labels in semantic segmentation. arXiv 2021, arXiv:2103.04990. [Google Scholar]
- Li, Z.; Sun, Y.; Zhang, L.; Tang, J. CTNet: Context–Based Tandem Network for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9904–9917. [Google Scholar] [CrossRef] [PubMed]
- Lin, Q.; Dong, Y.S.; Li, X.L. Multi–stage context refinement network for semantic segmentation. Neurocomputing 2023, 535, 53–63. [Google Scholar]
- Sun, L.; Yang, K.; Hu, X.; Hu, W.; Wang, K. Real–Time Fusion Network for RGB–D Semantic Segmentation Incorporating Unexpected Obstacle Detection for Road–Driving Images. IEEE Robot. Autom. Lett. 2020, 5, 5558–5565. [Google Scholar] [CrossRef]
- Hu, X.X.; Yang, K.L.; Fei, L. ACNET: Attention Based Network to Exploit Complementary Features for RGBD Semantic Segmentation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1440–1444. [Google Scholar]
- Zhou, W.; Lv, S.; Lei, J.; Luo, T.; Yu, L. RFNet: Reverse Fusion Network with Attention Mechanism for RGB–D Indoor Scene Understanding. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 598–603. [Google Scholar] [CrossRef]
- Ying, X.W.; Chuah, M.C. UCTNet: Uncertainty–Aware Cross–Modal Transformer Network for Indoor RGB–D Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 20–37. [Google Scholar]
- Hung, S.W.; Lo, S.Y.; Hang, H.M. Incorporating Luminance, Depth and Color Information by a Fusion–Based Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2374–2378. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2024–2039. [Google Scholar] [CrossRef]
- Li, X.; Li, L.; Alexander, L.; Wang, W.; Wang, X. RGB–D object recognition algorithm based on improved double stream convolution recursive neural network. Opto–Electron. Eng. 2021, 48, 200069. [Google Scholar]
- Ge, Y.; Chen, Z.-M.; Zhang, G.; Heidari, A.; Chen, H.; Teng, S. Unsupervised domain adaptation via style adaptation and boundary enhancement for medical semantic segmentation. Neurocomputing 2023, 550, 126469. [Google Scholar] [CrossRef]
- Du, C.; Teng, J.; Li, T.; Liu, Y.; Yuan, T.; Wang, Y.; Yuan, Y.; Zhao, H. On Uni–Modal Feature Learning in Supervised Multi–Modal Learning. arXiv 2023, arXiv:2305.01233. [Google Scholar]
- Tang, M.X.; Chen, S.N.; Kan, J.M. Encoder–Decoder Structure with the Feature Pyramid for Depth Estimation from a Single Image. IEEE Access 2021, 9, 22640–22650. [Google Scholar] [CrossRef]
- Chen, S.N.; Tang, M.X.; Kan, J.M. Monocular Image Depth Prediction without Depth Sensors: An Unsupervised Learning Method. Appl. Soft Comput. 2020, 97, 106804. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Duta, I.C.; Liu, L.; Zhu, F.; Shao, L. Improved Residual Networks for Image and Video Recognition. arXiv 2020, arXiv:2004.04989. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi–path Refinement Networks for High–Resolution Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5168–5177. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder–Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1743–1751. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high–performance deep learning library. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Oršic, M.; Krešo, I.; Bevandic, P.; Segvic, S. In Defense of Pre-Trained ImageNet Architectures for Real–Time Semantic Segmentation of Road–Driving Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12599–12608. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S. Enet: A deep neural network architecture for real–time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Romera, E.; Alvarez, J.M.; Bergasa, L.M. Erfnet: Efficient residual factorized convnet for real–time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272. [Google Scholar] [CrossRef]
- He, L.; Lu, J.; Wang, G.; Song, S.; Zhou, J. SOSD–Net: Joint semantic object segmentation and depth estimation from monocular images. Neurocomputing 2021, 440, 251–263. [Google Scholar] [CrossRef]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3D: Learning 3D Scene Structure from a Single Still Image. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 824–840. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SwiftNet [38] | RFNet [16] | Our Method |
|---|---|---|---|
| Road | 94.9 | 96.1 | 94.8 |
| Sidewalk | 54.9 | 61.6 | 82.3 |
| Wall | 47.3 | 56.9 | 74.1 |
| Fence | 57.7 | 60.4 | 75.3 |
| Vegetation | 90.8 | 91.1 | 89.7 |
| Terrain | 57.1 | 57.1 | 69.1 |
| Sky | 91.9 | 91.8 | 91.7 |
| Bus | 80.6 | 83.4 | 82.4 |
| Train | 60.4 | 73.9 | 82.0 |
| Network | RGB–D | mIoU |
|---|---|---|
| FCN8s [11] | N | 65.3% |
| DeepLabV2–CRF [39] | N | 70.4% |
| ENet [40] | N | 58.3% |
| ERFNet [41] | N | 65.8% |
| ERF–PSPNet [41] | N | 64.1% |
| SwiftNet [38] | N | 70.4% |
| ARLoss [13] | N | 71.0% |
| LDFNet [20] | G | 68.48% |
| RFNet [16] | G | 72.5% |
| ESOSD–Net [42] | P | 68.2% |
| Our method | P | 73.0% |
| Method | Dataset | RGB–D | mIoU | PA |
|---|---|---|---|---|
| Hu et al. [17] | P | Yes | 69.87% | 93.67% |
| Y | Yes | 71.17% | 94.42% | |
| Our method | P | Yes | 73.94% | 96.95% |
| Y | Yes | 75.11% | 97.45% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Tang, M.; Dong, R.; Kan, J. Encoder–Decoder Structure Fusing Depth Information for Outdoor Semantic Segmentation. Appl. Sci. 2023, 13, 9924. https://doi.org/10.3390/app13179924
Chen S, Tang M, Dong R, Kan J. Encoder–Decoder Structure Fusing Depth Information for Outdoor Semantic Segmentation. Applied Sciences. 2023; 13(17):9924. https://doi.org/10.3390/app13179924
Chicago/Turabian StyleChen, Songnan, Mengxia Tang, Ruifang Dong, and Jiangming Kan. 2023. "Encoder–Decoder Structure Fusing Depth Information for Outdoor Semantic Segmentation" Applied Sciences 13, no. 17: 9924. https://doi.org/10.3390/app13179924
APA StyleChen, S., Tang, M., Dong, R., & Kan, J. (2023). Encoder–Decoder Structure Fusing Depth Information for Outdoor Semantic Segmentation. Applied Sciences, 13(17), 9924. https://doi.org/10.3390/app13179924