
Improving Dimensionality Reduction Projections for Data Visualization

Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
1.3. Contributions
2. Materials and Methods
2.1. Background
- A new method for high-dimensional vector manipulation that improves a wide range of DR algorithms.
- A validation study that proves that our technique enhances the results in many scenarios.
- Data visualization examples that use document embeddings and provide evidence that the technique also works with other kinds of high-dimensional data.
2.2. Vector Manipulation
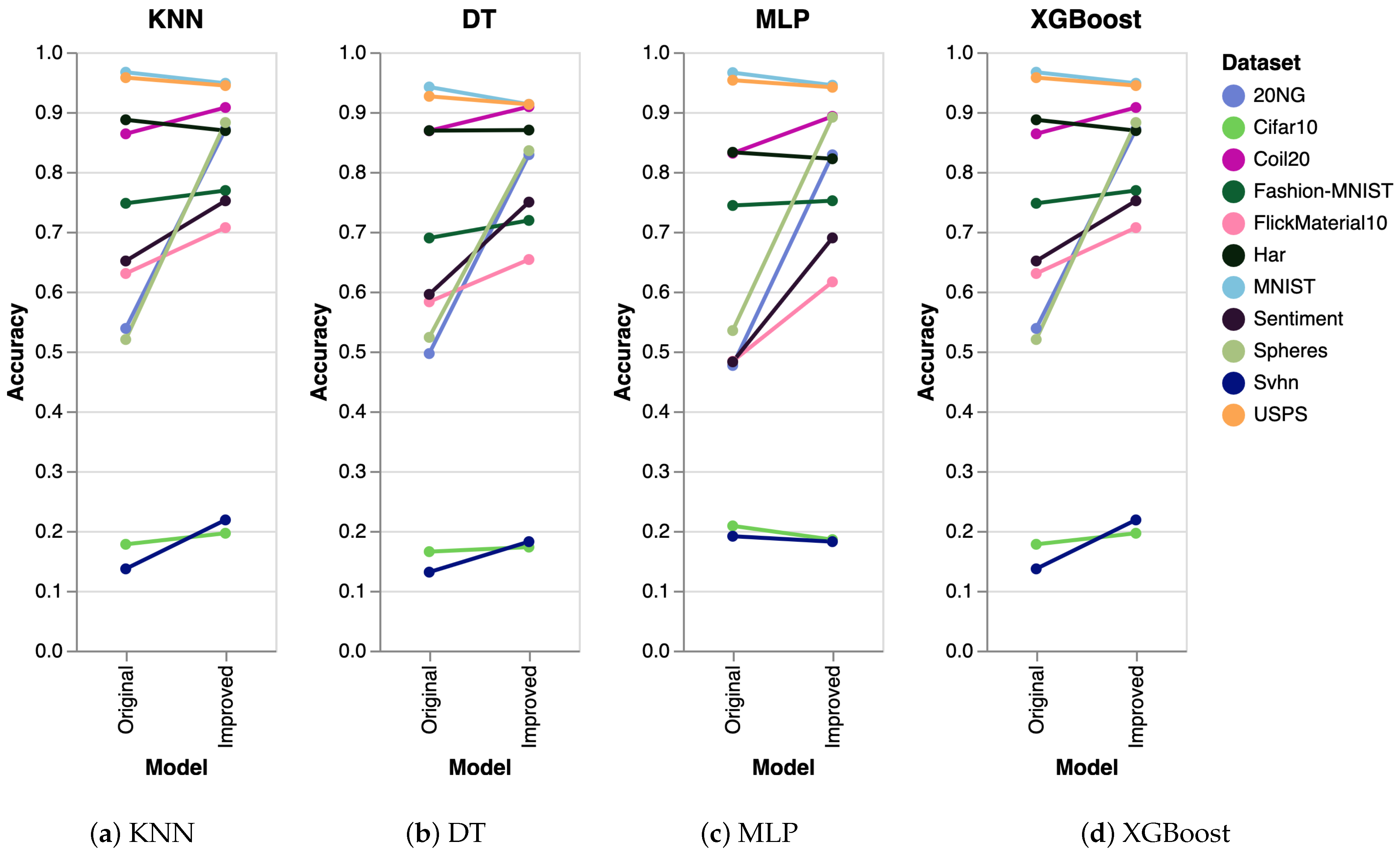
3. Validation
3.1. Datasets
3.2. Experiment Setup
- For each dataset d, a transformation is applied using our algorithm, giving the transformed dataset .
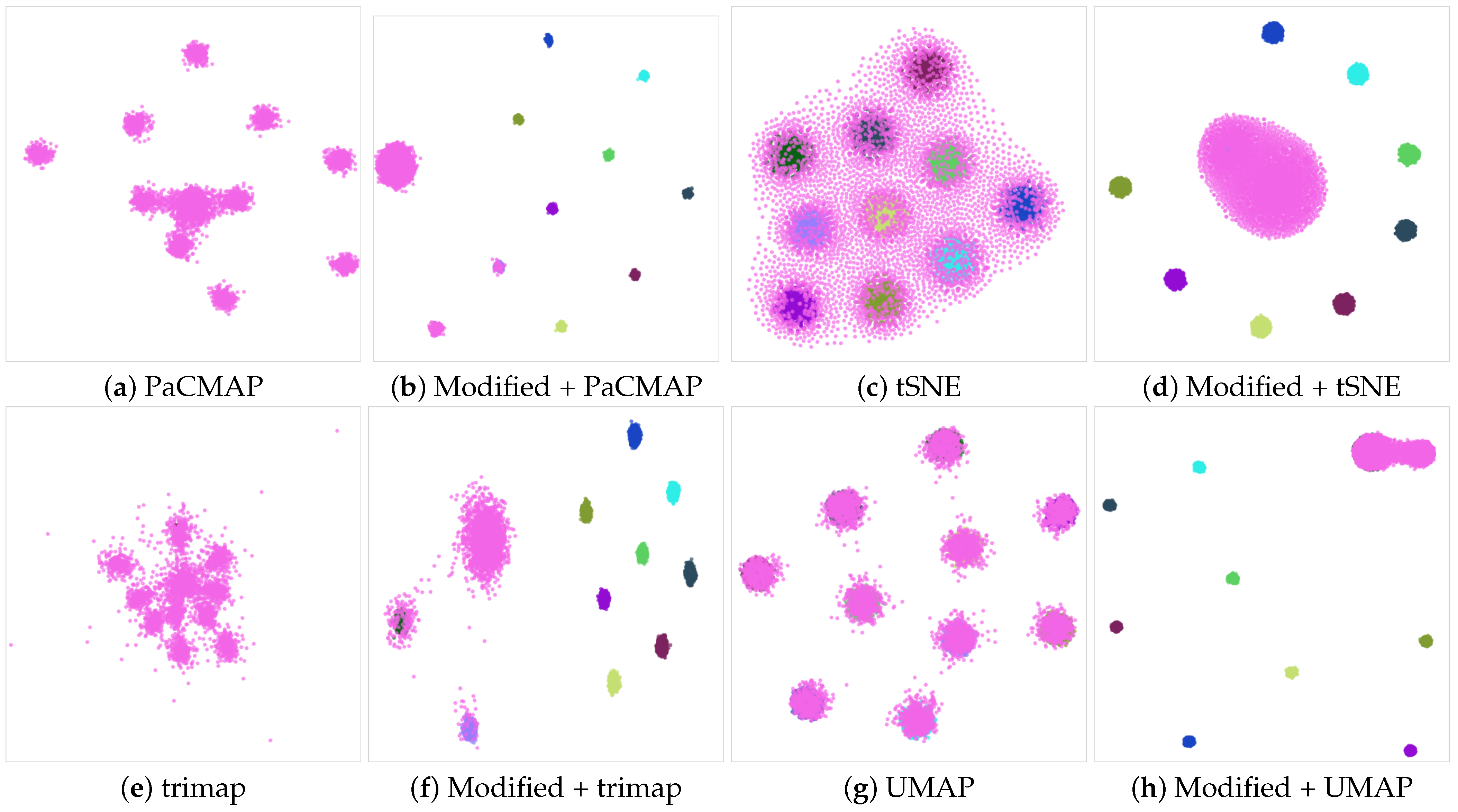
- We project both d and using PaCMAP, tSNE, trimap, and UMAP.
- Each projected set is evaluated five times with the linear SVM method, and the results are averaged.
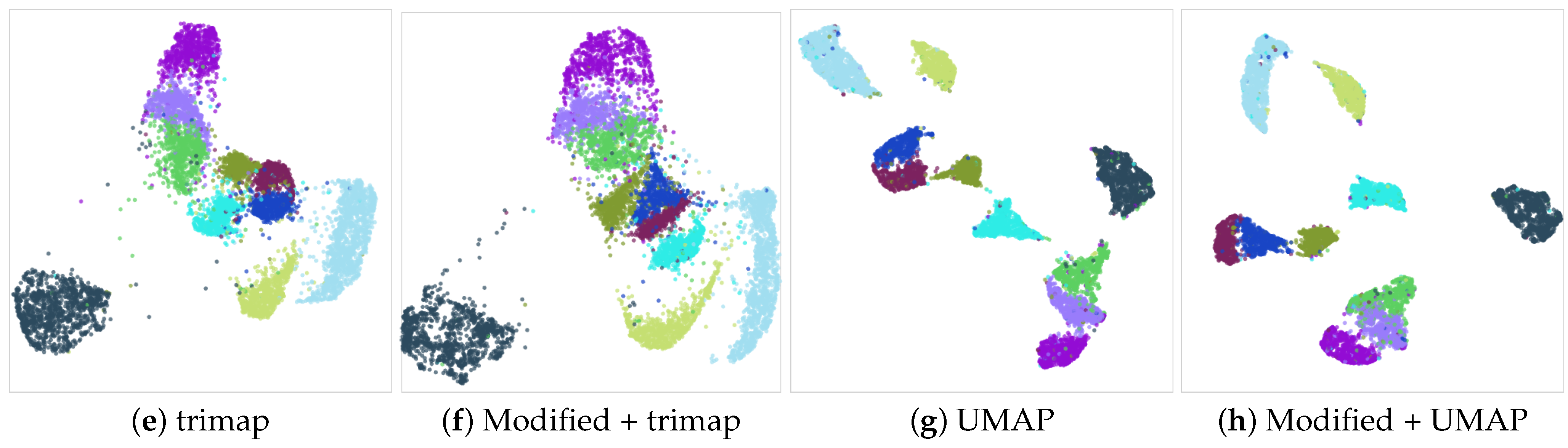
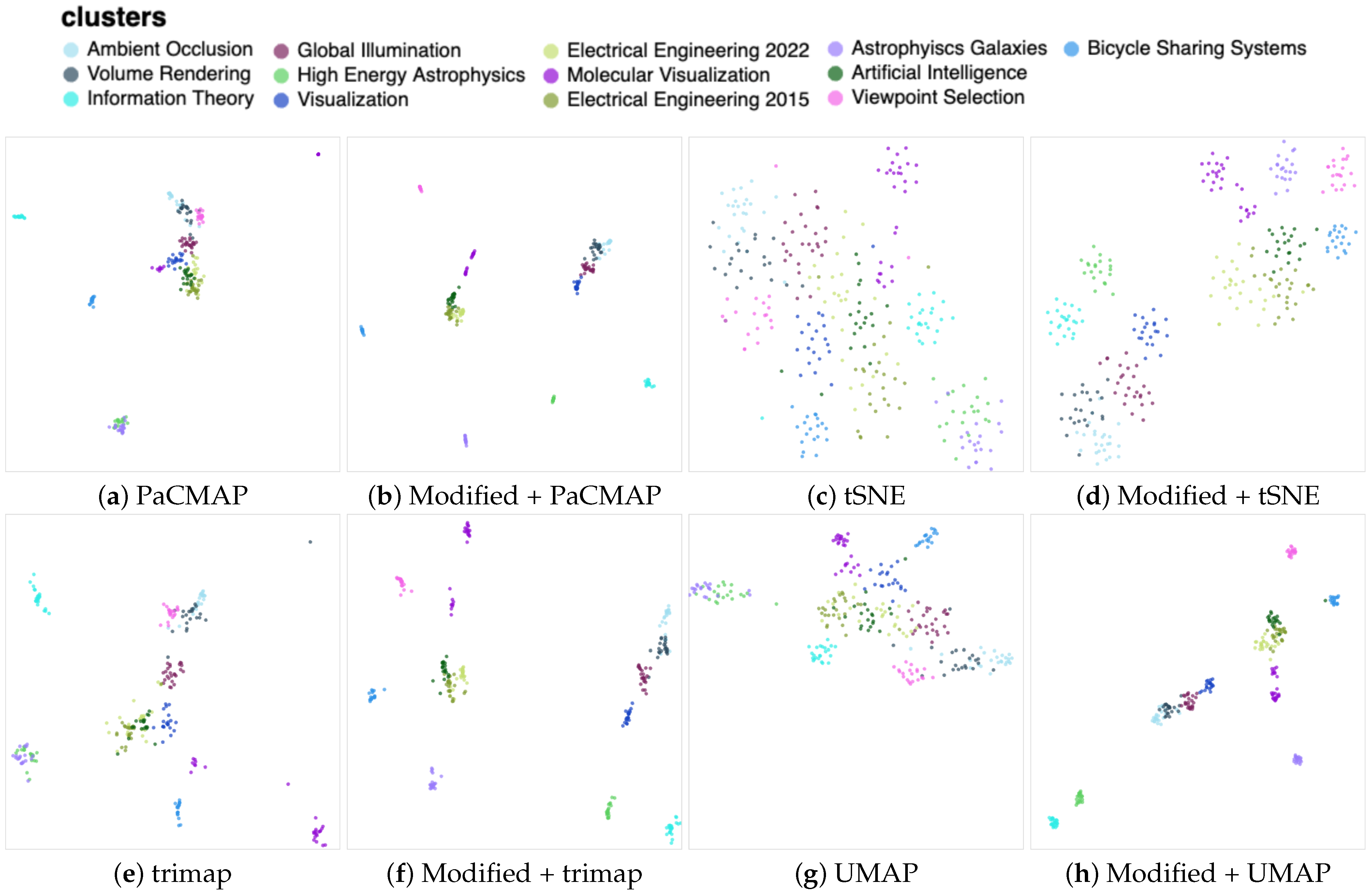
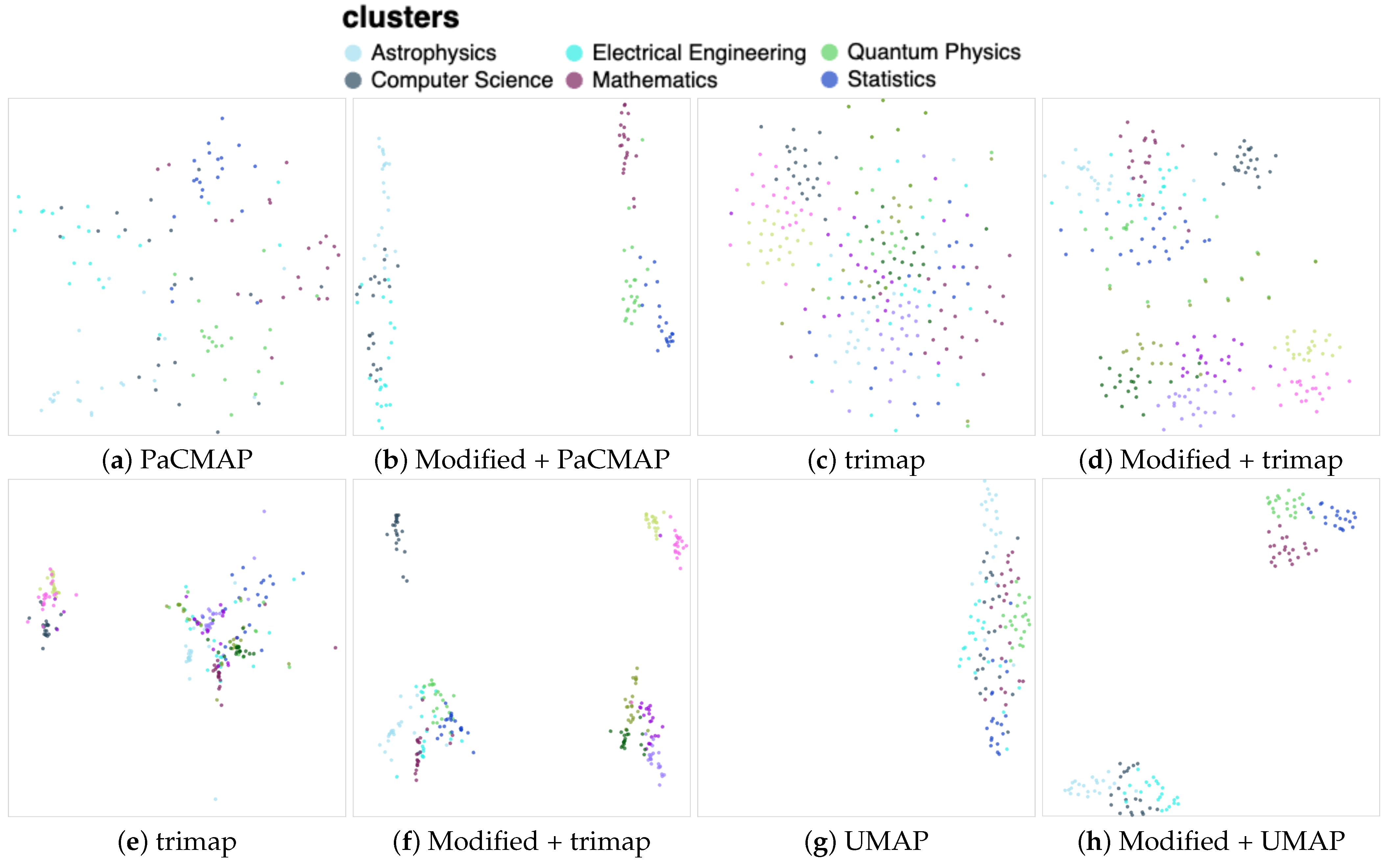
4. Document Visualization
4.1. Document Embeddings
4.1.1. Doc2vec Model Training
4.1.2. Synthetic Dataset Creation
4.1.3. Data Preprocessing
4.1.4. Clusters’ Quality Analysis
5. Conclusions and Future Work
5.1. Conclusions
5.2. Discussion
5.3. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DR | Dimensionality Reduction |
| DT | Decision Trees |
| KNN | K-Nearest Neighbors |
| MLP | Multilayer Perceptron |
| PaCMAP | Pairwise Controlled Manifold Approximation Projection |
| SVM | Support Vector Machines |
| trimap | Large-scale Dimensionality Reduction Using Triplets |
| t-SNE | t-Distributed Stochastic Neighbor Embedding |
| UMAP | Uniform Manifold Approximation and Projection |
| XGBoost | Extreme Gradient Boosting |
References
- Wang, Y.; Huang, H.; Rudin, C.; Shaposhnik, Y. Understanding how dimension reduction tools work: An empirical approach to deciphering t-SNE, UMAP, TriMAP, and PaCMAP for data visualization. J. Mach. Learn. Res. 2021, 22, 9129–9201. [Google Scholar]
- Hinterreiter, A.; Steinparz, C.; Schöfl, M.; Stitz, H.; Streit, M. Projection path explorer: Exploring visual patterns in projected decision-making paths. ACM Trans. Interact. Intell. Syst. 2021, 11, 22. [Google Scholar] [CrossRef]
- Becht, E.; McInnes, L.; Healy, J.; Dutertre, C.A.; Kwok, I.W.; Ng, L.G.; Ginhoux, F.; Newell, E.W. Dimensionality reduction for visualizing single-cell data using UMAP. Nat. Biotechnol. 2019, 37, 38–44. [Google Scholar] [CrossRef] [PubMed]
- Vlachos, M.; Domeniconi, C.; Gunopulos, D.; Kollios, G.; Koudas, N. Non-linear dimensionality reduction techniques for classification and visualization. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 645–651. [Google Scholar]
- Cunningham, J.P.; Ghahramani, Z. Linear dimensionality reduction: Survey, insights, and generalizations. J. Mach. Learn. Res. 2015, 16, 2859–2900. [Google Scholar]
- Lee, J.A.; Verleysen, M. Nonlinear Dimensionality Reduction; Springer: Berlin/Heidelberg, Germany, 2007; Volume 1. [Google Scholar]
- Ayesha, S.; Hanif, M.K.; Talib, R. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Inf. Fusion 2020, 59, 44–58. [Google Scholar] [CrossRef]
- Sorzano, C.O.S.; Vargas, J.; Montano, A.P. A survey of dimensionality reduction techniques. arXiv 2014, arXiv:1403.2877. [Google Scholar]
- Engel, D.; Hüttenberger, L.; Hamann, B. A survey of dimension reduction methods for high-dimensional data analysis and visualization. In Proceedings of the Visualization of Large and Unstructured Data Sets: Applications in Geospatial Planning, Modeling and Engineering-Proceedings of IRTG 1131 Workshop, Kaiserslautern, Germany, 10–11 June 2011; Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik: Wadern, Germany, 2012. [Google Scholar]
- Van Der Maaten, L.; Postma, E.; Van den Herik, J. Dimensionality reduction: A comparative. J. Mach. Learn Res. 2009, 10, 66–71. [Google Scholar]
- Sedlmair, M.; Brehmer, M.; Ingram, S.; Munzner, T. Dimensionality Reduction in the Wild: Gaps and Guidance; Tech. Rep. TR-2012-03; Department of Computer Science, University of British Columbia: Vancouver, BC, Canada, 2012. [Google Scholar]
- Huang, H.; Wang, Y.; Rudin, C.; Browne, E.P. Towards a comprehensive evaluation of dimension reduction methods for transcriptomic data visualization. Commun. Biol. 2022, 5, 719. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Wattenberg, M.; Viégas, F.; Johnson, I. How to use t-SNE effectively. Distill 2016, 1, e2. [Google Scholar] [CrossRef]
- Caillou, P.; Renault, J.; Fekete, J.D.; Letournel, A.C.; Sebag, M. Cartolabe: A web-based scalable visualization of large document collections. IEEE Comput. Graph. Appl. 2020, 41, 76–88. [Google Scholar] [CrossRef] [PubMed]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2020, arXiv:stat.ML/1802.03426. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Reykjavik, Iceland, 22–25 April 2014; pp. 1188–1196. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Silva, D.; Bacao, F. MapIntel: Enhancing Competitive Intelligence Acquisition through Embeddings and Visual Analytics. In Proceedings of the EPIA Conference on Artificial Intelligence, Lisbon, Portugal, 31 August–2 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 599–610. [Google Scholar]
- Abdullah, S.S.; Rostamzadeh, N.; Sedig, K.; Garg, A.X.; McArthur, E. Visual analytics for dimension reduction and cluster analysis of high dimensional electronic health records. Informatics 2020, 7, 17. [Google Scholar] [CrossRef]
- Humer, C.; Heberle, H.; Montanari, F.; Wolf, T.; Huber, F.; Henderson, R.; Heinrich, J.; Streit, M. ChemInformatics Model Explorer (CIME): Exploratory analysis of chemical model explanations. J. Cheminform. 2022, 14, 21. [Google Scholar] [CrossRef] [PubMed]
- Burch, M.; Kuipers, T.; Qian, C.; Zhou, F. Comparing dimensionality reductions for eye movement data. In Proceedings of the 13th International Symposium on Visual Information Communication and Interaction, Eindhoven, The Netherlands, 8–10 December 2020; pp. 1–5. [Google Scholar]
- Dorrity, M.W.; Saunders, L.M.; Queitsch, C.; Fields, S.; Trapnell, C. Dimensionality reduction by UMAP to visualize physical and genetic interactions. Nat. Commun. 2020, 11, 1537. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Liu, J.; Zhang, M.; Mei, Q. Visualizing large-scale and high-dimensional data. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 287–297. [Google Scholar]
- Amid, E.; Warmuth, M.K. TriMap: Large-scale dimensionality reduction using triplets. arXiv 2019, arXiv:1910.00204. [Google Scholar]
- Jeon, H.; Ko, H.K.; Lee, S.; Jo, J.; Seo, J. Uniform Manifold Approximation with Two-phase Optimization. In Proceedings of the 2022 IEEE Visualization and Visual Analytics (VIS), Oklahoma City, OK, USA, 16–21 October 2022; pp. 80–84. [Google Scholar]
- Sedlmair, M.; Munzner, T.; Tory, M. Empirical guidance on scatterplot and dimension reduction technique choices. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2634–2643. [Google Scholar] [CrossRef]
- Espadoto, M.; Martins, R.M.; Kerren, A.; Hirata, N.S.; Telea, A.C. Toward a quantitative survey of dimension reduction techniques. IEEE Trans. Vis. Comput. Graph. 2019, 27, 2153–2173. [Google Scholar] [CrossRef]
- Olobatuyi, K.; Parker, M.R.; Ariyo, O. Cluster weighted model based on TSNE algorithm for high-dimensional data. Int. J. Data Sci. Anal. 2023. [Google Scholar] [CrossRef]
- Allaoui, M.; Kherfi, M.L.; Cheriet, A. Considerably improving clustering algorithms using UMAP dimensionality reduction technique: A comparative study. In Proceedings of the International Conference on Image and Signal Processing, Marrakesh, Morocco, 4–6 June 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 317–325. [Google Scholar]
- Church, K.; Gale, W. Inverse document frequency (idf): A measure of deviations from poisson. In Natural Language Processing Using Very Large Corpora; Springer: Berlin/Heidelberg, Germany, 1999; pp. 283–295. [Google Scholar]
- Sparck Jones, K. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; KDD’16. ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall PTR: London, UK, 1994. [Google Scholar]
- LeCun, Y.; Cortes, C. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 15 May 2023).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/ (accessed on 27 July 2023).
- Nene, S.A.; Nayar, S.K.; Murase, H. Columbia Object Image Library (Coil-20); Technical Report; Columbia University: New York, NY, USA, 1996. [Google Scholar]
- Reyes-Ortiz, J.; Anguita, D.; Ghio, A.; Oneto, L.; Parra, X. Human Activity Recognition Using Smartphones. UCI Mach. Learn. Repos. 2012. [Google Scholar] [CrossRef]
- Kotzias, D. Sentiment Labelled Sentences. UCI Mach. Learn. Repos. 2015. [Google Scholar] [CrossRef]
- Yuval, N. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–17 December 2011. [Google Scholar]
- Hull, J.J. A database for handwritten text recognition research. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 550–554. [Google Scholar] [CrossRef]
- Sharan, L.; Rosenholtz, R.; Adelson, E. Material perception: What can you see in a brief glance? J. Vis. 2009, 9, 784. [Google Scholar] [CrossRef]
- Lang, K. 20 Newsgroups Dataset. Available online: https://www.cs.cmu.edu/afs/cs/project/theo-20/www/data/news20.html (accessed on 15 May 2023).
- Cutura, R.; Holzer, S.; Aupetit, M.; Sedlmair, M. VisCoDeR: A tool for visually comparing dimensionality reduction algorithms. In Proceedings of the Esann, Bruges, Belgium, 25–27 April 2018. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; COLT’92. Association for Computing Machinery: New York, NY, USA, 1992; pp. 144–152. [Google Scholar] [CrossRef]
- Chuang, J.; Ramage, D.; Manning, C.; Heer, J. Interpretation and trust: Designing model-driven visualizations for text analysis. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 443–452. [Google Scholar]
- Landauer, T.K.; Laham, D.; Derr, M. From paragraph to graph: Latent semantic analysis for information visualization. Proc. Natl. Acad. Sci. USA 2004, 101, 5214–5219. [Google Scholar] [CrossRef]
- Kim, K.; Lee, J. Sentiment visualization and classification via semi-supervised nonlinear dimensionality reduction. Pattern Recognit. 2014, 47, 758–768. [Google Scholar] [CrossRef]
- Harris, Z.S. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Lo, K.; Wang, L.L.; Neumann, M.; Kinney, R.; Weld, D. S2ORC: The Semantic Scholar Open Research Corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Toronto, ON Canada, 2020; pp. 4969–4983. [Google Scholar] [CrossRef]
- Alvarez, J.E.; Bast, H. A Review of Word Embedding and Document Similarity Algorithms Applied to Academic Text. Bachelor Thesis, University of Freiburg, Freiburg im Breisgau, Germany, 2017. [Google Scholar]
- Rehurek, R.; Sojka, P. Gensim–Python Framework for Vector Space Modelling; NLP Centre, Faculty of Informatics, Masaryk University: Brno, Czech Republic, 2011; Volume 3. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Gómez, J.; Vázquez, P.P. An Empirical Evaluation of Document Embeddings and Similarity Metrics for Scientific Articles. Appl. Sci. 2022, 12, 5664. [Google Scholar] [CrossRef]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Dimensions | Samples | Classes |
|---|---|---|---|
| 20NG | 99 | 18,844 | 20 |
| Cifar10 | 1024 | 3250 | 10 |
| Coil20 | 400 | 1440 | 20 |
| Fashion-MNIST | 784 | 10,000 | 10 |
| FlickMaterial10 | 1534 | 997 | 10 |
| Har | 561 | 735 | 6 |
| MNIST | 784 | 70,000 | 10 |
| Sentiment | 200 | 2748 | 2 |
| Spheres | 101 | 10,000 | 11 |
| Svhn | 1024 | 732 | 9 |
| USPS | 255 | 9298 | 10 |
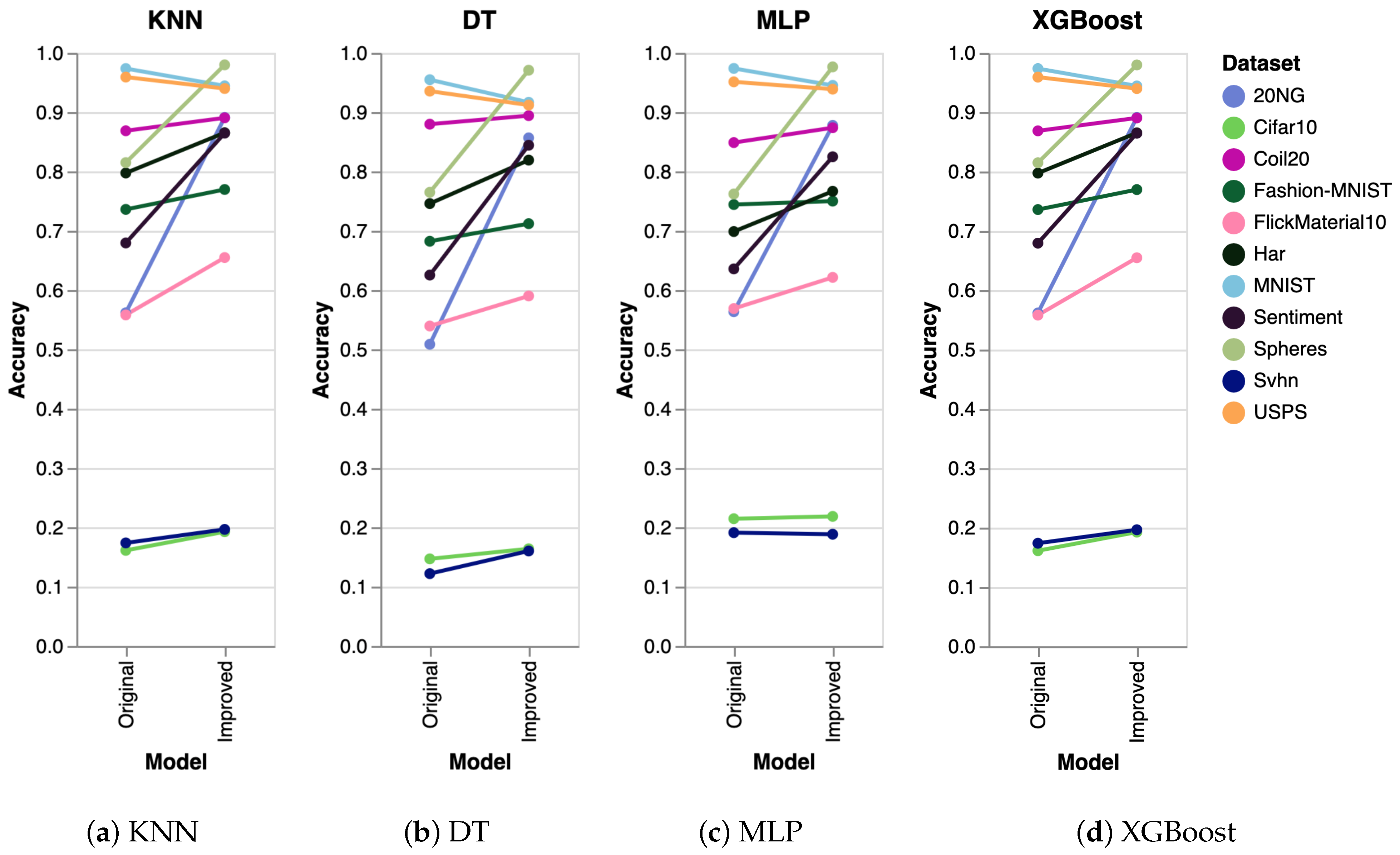
| Dataset | Original + PaCMAP (SVM) | Improved + PaCMAP (SVM) |
|---|---|---|
| 20NG | 0.5156 | 0.8605 |
| Cifar10 | 0.2029 | 0.2252 |
| Coil20 | 0.8278 | 0.8639 |
| Fashion-MNIST | 0.7232 | 0.7424 |
| FlickMaterial10 | 0.5433 | 0.6047 |
| Har | 0.7285 | 0.7982 |
| MNIST | 0.9733 | 0.9416 |
| Sentiment | 0.6177 | 0.7898 |
| Spheres | 0.6653 | 0.9755 |
| Svhn | 0.1855 | 0.1955 |
| USPS | 0.9476 | 0.9401 |
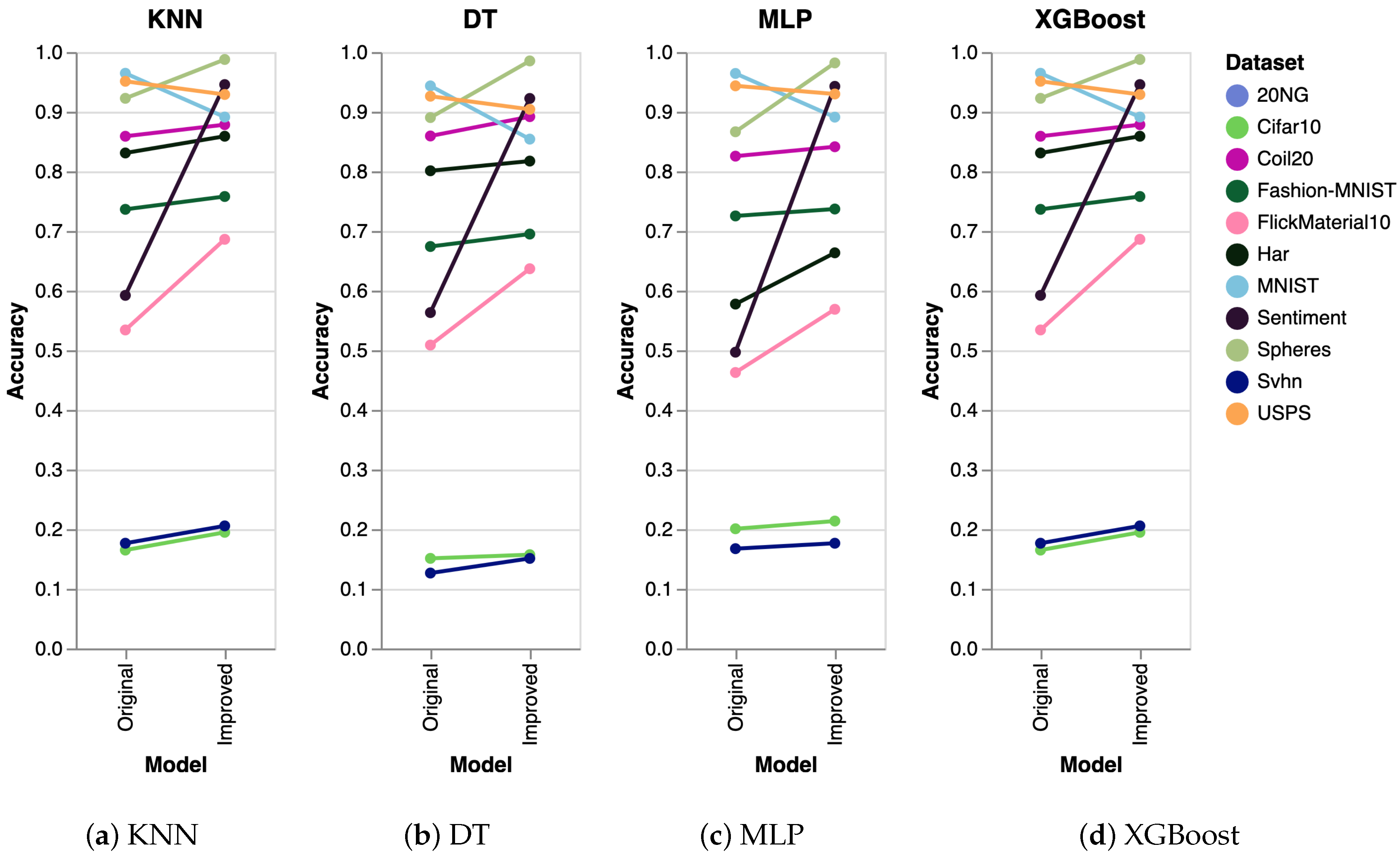
| Dataset | Original + tSNE (SVM) | Improved + tSNE (SVM) |
|---|---|---|
| 20NG | 0.4646 | 0.7854 |
| Cifar10 | 0.2031 | 0.2306 |
| Coil20 | 0.8319 | 0.8185 |
| Fashion-MNIST | 0.7222 | 0.7373 |
| FlickMaterial10 | 0.5633 | 0.6207 |
| Har | 0.8588 | 0.8317 |
| MNIST | 0.9666 | 0.9174 |
| Sentiment | 0.5852 | 0.8252 |
| Spheres | 0.7626 | 0.8933 |
| Svhn | 0.1909 | 0.1982 |
| USPS | 0.9528 | 0.9333 |
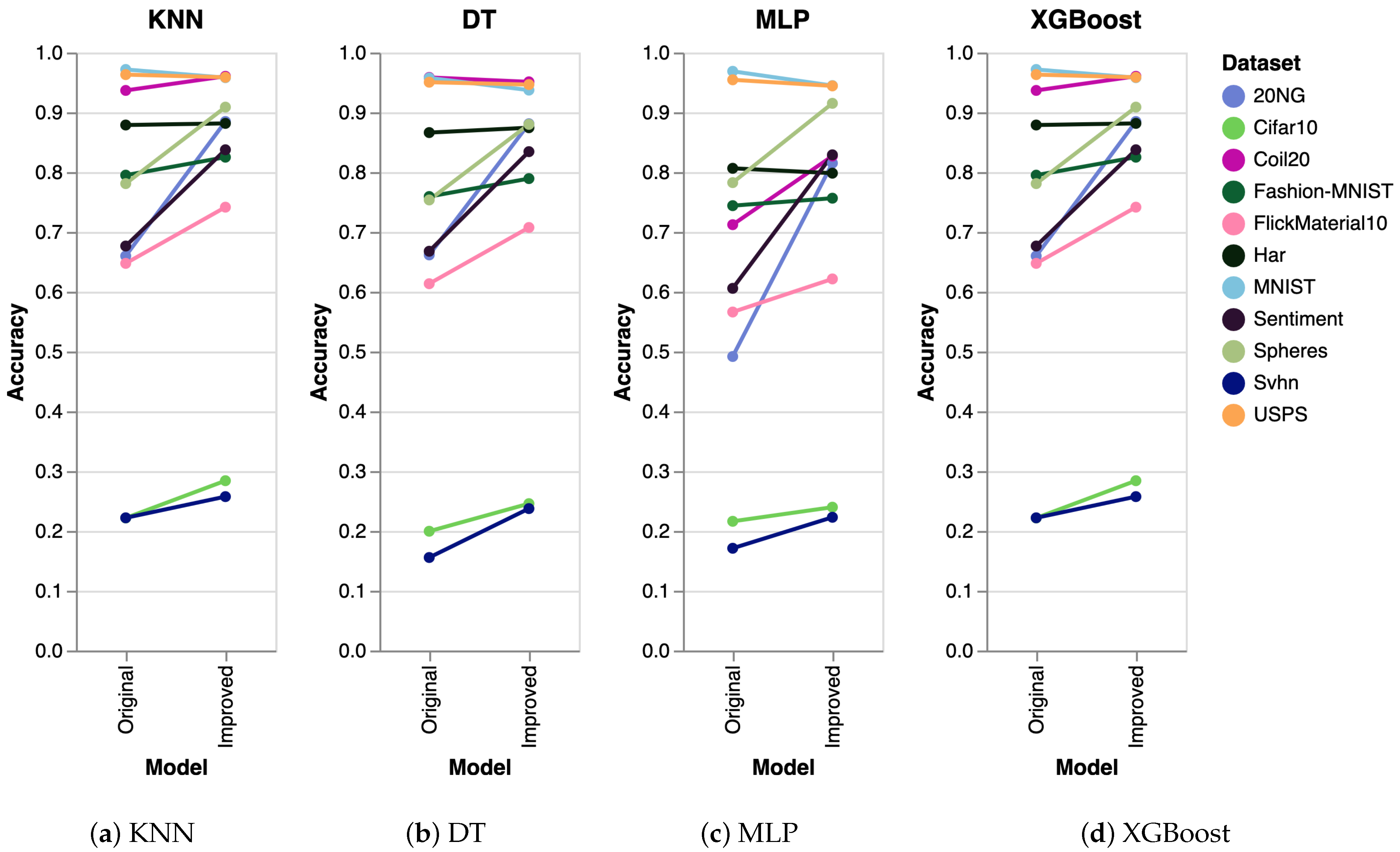
| Dataset | Original + Trimap (SVM) | Improved + Trimap (SVM) |
|---|---|---|
| 20NG | - | - |
| Cifar10 | 0.1914 | 0.2273 |
| Coil20 | 0.7977 | 0.8236 |
| Fashion-MNIST | 0.7161 | 0.7251 |
| FlickMaterial10 | 0.4780 | 0.6100 |
| Har | 0.6688 | 0.7620 |
| MNIST | 0.9636 | 0.8706 |
| Sentiment | 0.4812 | 0.9522 |
| Spheres | 0.7686 | 0.9757 |
| Svhn | 0.1891 | 0.1964 |
| USPS | 0.9387 | 0.9237 |
| Dataset | Original + UMAP (SVM) | Improved + UMAP (SVM) |
|---|---|---|
| 20NG | 0.4859 | 0.8076 |
| Cifar10 | 0.2062 | 0.2195 |
| Coil20 | 0.7894 | 0.8634 |
| Fashion-MNIST | 0.7247 | 0.7343 |
| FlickMaterial10 | 0.5833 | 0.6900 |
| Har | 0.8235 | 0.8054 |
| MNIST | 0.9650 | 0.9243 |
| Sentiment | 0.5927 | 0.6327 |
| Spheres | 0.5213 | 0.8933 |
| Svhn | 0.1955 | 0.2045 |
| USPS | 0.9520 | 0.9380 |
| Dataset | Improved + PaCMAP | Improved + tSNE | Improved + Trimap | Improved + UMAP |
|---|---|---|---|---|
| 20NG | - | |||
| Cifar10 | ||||
| Coil20 | ||||
| Fashion-MNIST | ||||
| FlickMaterial10 | ||||
| Har | ||||
| MNIST | ||||
| Sentiment | ||||
| Spheres | ||||
| Svhn | ||||
| USPS |
| Name of the Cluster | Number of Articles |
|---|---|
| Artificial Intelligence (AI) | 20 |
| Astrophysics Galaxies (APG) | 20 |
| Bicycle Sharing Systems (BSS) | 19 |
| Computer Graphics—Ambient Occlusion (AO) | 24 |
| Electrical Engineering 2022 (EE22) | 22 |
| Electrical Engineering 2015 (EE15) | 24 |
| Global Illumination (GI) | 25 |
| High-Energy Astrophysics (HEAP) | 20 |
| Information Theory (IT) | 23 |
| Molecular Visualization in Virtual Reality (MVVR) | 20 |
| Viewpoint Selection (VS) | 19 |
| Visualization (Vis) | 20 |
| Volume Rendering (VolRend) | 22 |
| AI | APG | BSS | AO | EE15 | EE22 | GI | HEAP | IT | MVVR | VS | Vis | VolRend | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AI | 0.144 | 0.102 | 0.130 | 0.129 | 0.091 | 0.104 | 0.116 | 0.096 | 0.129 | 0.121 | 0.125 | 0.114 | 0.123 |
| APG | 0.102 | 0.290 | 0.213 | 0.195 | 0.077 | 0.093 | 0.106 | 0.249 | 0.189 | 0.200 | 0.192 | 0.099 | 0.190 |
| BSS | 0.130 | 0.213 | 0.374 | 0.214 | 0.106 | 0.111 | 0.128 | 0.201 | 0.223 | 0.234 | 0.231 | 0.162 | 0.217 |
| AO | 0.129 | 0.195 | 0.214 | 0.397 | 0.095 | 0.111 | 0.250 | 0.186 | 0.213 | 0.239 | 0.286 | 0.161 | 0.346 |
| EE15 | 0.091 | 0.077 | 0.106 | 0.095 | 0.115 | 0.092 | 0.080 | 0.079 | 0.097 | 0.091 | 0.099 | 0.080 | 0.098 |
| EE22 | 0.104 | 0.093 | 0.111 | 0.111 | 0.092 | 0.117 | 0.105 | 0.088 | 0.109 | 0.102 | 0.110 | 0.093 | 0.116 |
| GI | 0.116 | 0.106 | 0.128 | 0.250 | 0.080 | 0.105 | 0.227 | 0.106 | 0.121 | 0.148 | 0.178 | 0.137 | 0.221 |
| HEAP | 0.096 | 0.249 | 0.201 | 0.186 | 0.079 | 0.088 | 0.106 | 0.248 | 0.181 | 0.185 | 0.180 | 0.099 | 0.185 |
| IT | 0.129 | 0.189 | 0.223 | 0.213 | 0.097 | 0.109 | 0.121 | 0.181 | 0.312 | 0.208 | 0.231 | 0.123 | 0.215 |
| MVVR | 0.121 | 0.200 | 0.234 | 0.239 | 0.091 | 0.102 | 0.148 | 0.185 | 0.208 | 0.313 | 0.232 | 0.161 | 0.241 |
| VS | 0.124 | 0.195 | 0.232 | 0.270 | 0.096 | 0.107 | 0.168 | 0.181 | 0.223 | 0.259 | 0.301 | 0.163 | 0.274 |
| Vis | 0.115 | 0.099 | 0.163 | 0.160 | 0.080 | 0.093 | 0.136 | 0.099 | 0.121 | 0.158 | 0.163 | 0.194 | 0.174 |
| VolRend | 0.123 | 0.190 | 0.217 | 0.346 | 0.098 | 0.116 | 0.221 | 0.185 | 0.215 | 0.241 | 0.291 | 0.176 | 0.347 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rafieian, B.; Hermosilla, P.; Vázquez, P.-P. Improving Dimensionality Reduction Projections for Data Visualization. Appl. Sci. 2023, 13, 9967. https://doi.org/10.3390/app13179967
Rafieian B, Hermosilla P, Vázquez P-P. Improving Dimensionality Reduction Projections for Data Visualization. Applied Sciences. 2023; 13(17):9967. https://doi.org/10.3390/app13179967
Chicago/Turabian StyleRafieian, Bardia, Pedro Hermosilla, and Pere-Pau Vázquez. 2023. "Improving Dimensionality Reduction Projections for Data Visualization" Applied Sciences 13, no. 17: 9967. https://doi.org/10.3390/app13179967
APA StyleRafieian, B., Hermosilla, P., & Vázquez, P. -P. (2023). Improving Dimensionality Reduction Projections for Data Visualization. Applied Sciences, 13(17), 9967. https://doi.org/10.3390/app13179967