

Generating Image Descriptions of Rice Diseases and Pests Based on DeiT Feature Encoder

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
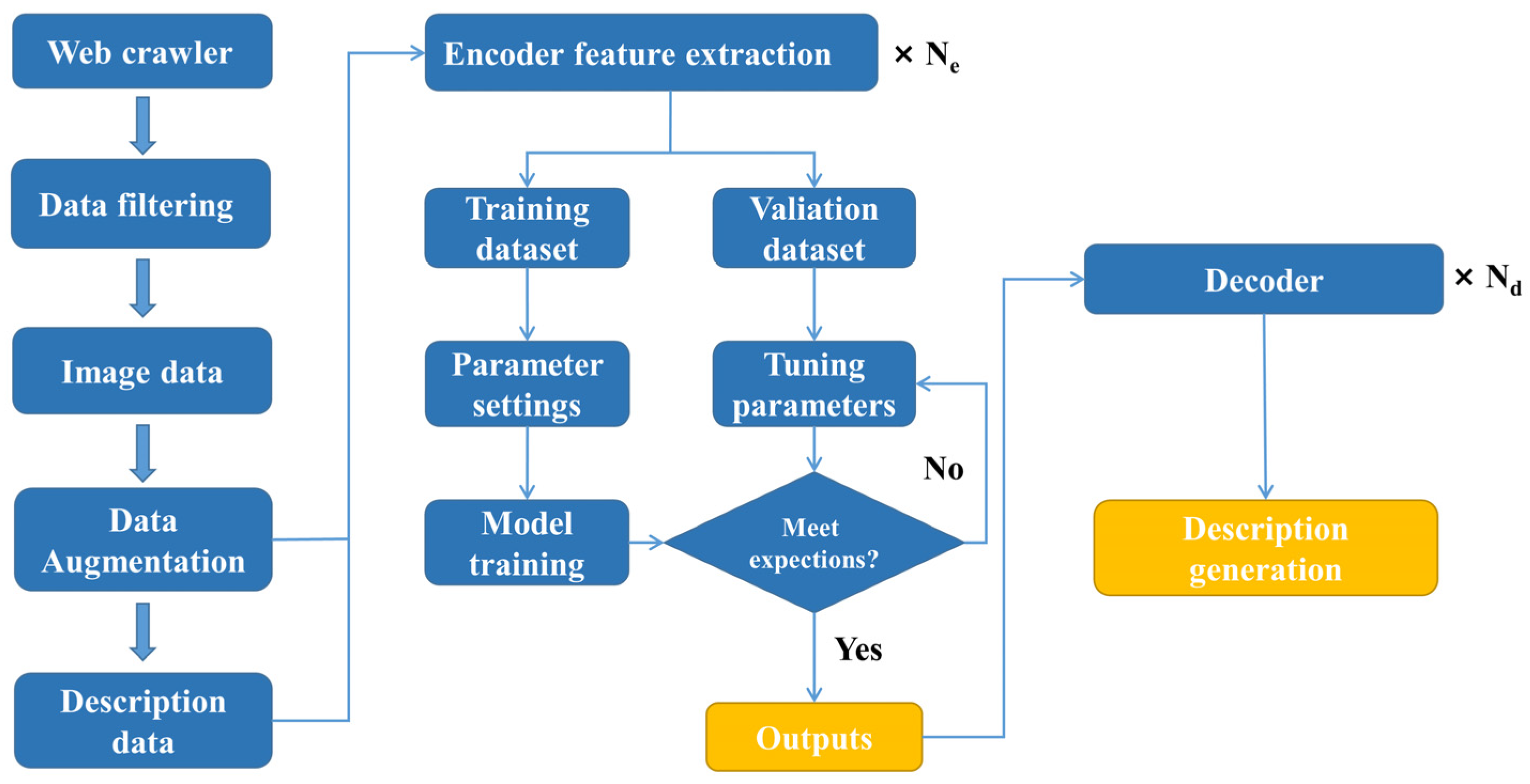
2.1. Research Framework
2.2. Dataset Construction
2.2.1. Data Collection
2.2.2. Data Preprocessing
- The images were named by serial numbers and saved as .jpg format images.
- The Python code implemented a perceptual hashing algorithm [42,43] (it generates compact digital signatures from multimedia data by emphasizing perceptually significant features to enable efficient content-based similarity comparisons between media files) to remove similar images without human intervention and reduce the workload of image selection.
- The noisy data that could not meet the requirements were manually eliminated.
2.2.3. Data Preprocessing
2.3. Experimental Platform
3. Image Caption Model
3.1. Model Structure
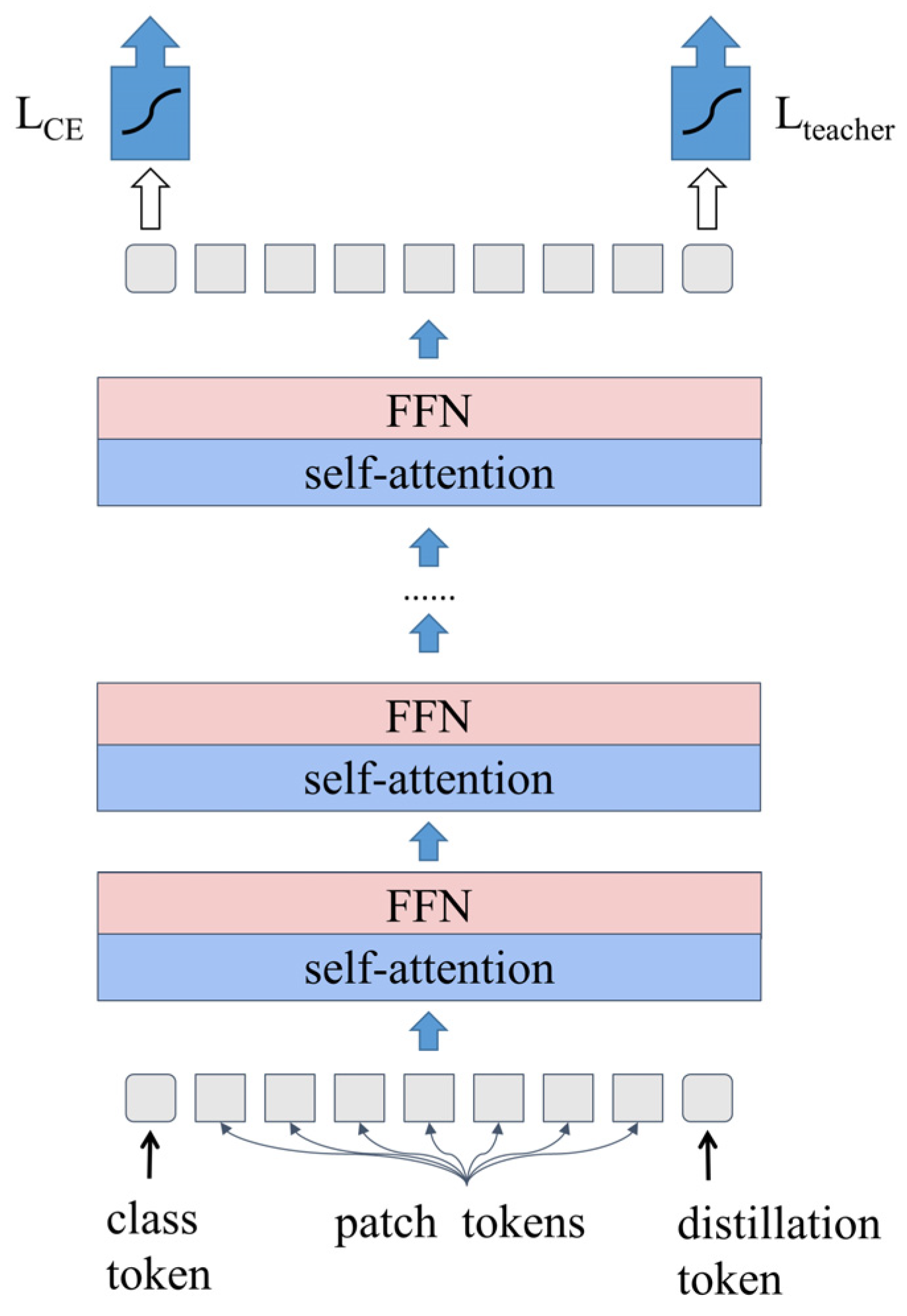
3.1.1. DeiT
3.1.2. Image Feature Encoder
3.1.3. Decoder
3.2. Evaluation Metrics
4. Results and Analysis
4.1. Model Training
4.2. Ablation Experiments
4.3. Image Description Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Asibi, A.E.; Chai, Q.; Coulter, J.A. Rice Blast: A Disease with Implications for Global Food Security. Agronomy 2019, 9, 451. [Google Scholar] [CrossRef]
- Huang, S.W.; Wang, L.; Liu, L.M.; Fu, Q.; Zhu, D.F. Nonchemical pest control in China rice: A review. Agron. Sustain. Dev. 2014, 34, 275–291. [Google Scholar] [CrossRef]
- Singh, P.; Mazumdar, P.; Harikrishna, J.A.; Babu, S. Sheath blight of rice: A review and identification of priorities for future research. Planta 2019, 250, 1387–1407. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Liu, J.; Lyu, Y.; Huang, Z.; Zhang, X.; Sun, B.; Li, P.; Jing, X.; Li, H.; Zhang, C. A Review of Vector-Borne Rice Viruses. Viruses 2022, 14, 2258. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Yu, J.; Han, Y. Understanding the effective receptive field in semantic image segmentation. Multimed. Tools Appl. 2018, 77, 22159–22171. [Google Scholar] [CrossRef]
- Girish, K.; Visruth, P.; Vicente, O.; Sagnik, D.; Siming, L.; Yejin, C.; Berg, A.C.; Berg, T.L. Babytalk: Understanding and generating simple image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1601–1608. [Google Scholar]
- Kuznetsova, P.; Ordonez, V.; Berg, T.L.; Choi, Y. TREETALK: Composition and Compression of Trees for Image Descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 351–362. [Google Scholar] [CrossRef]
- Mitchell, M.; Han, X.; Dodge, J.; Mensch, A.; Daumé, I. Midge: Generating Image Descriptions From Computer Vision Detections. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012. [Google Scholar]
- Karpathy, A.; Joulin, A.; Li, F.F. Deep Fragment Embeddings for Bidirectional Image Sentence Mapping. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; Volume 3. [Google Scholar]
- Kuznetsova, P.; Ordonez, V.; Berg, A.C.; Berg, T.L.; Choi, Y. Collective generation of natural image descriptions. In Proceedings of the Meeting of the Association for Computational Linguistics: Long Papers, Jeju Island, Republic of Korea, 8–14 July 2012. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. arXiv 2014, arXiv:1411.4555. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Comput. Sci. 2014. peer reviewed. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Mao, J.; Wei, X. Explain Images with Multimodal Recurrent Neural Networks. arXiv 2014, arXiv:1410.1090. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Zhang, W.; He, X.Y.; Lu, W.Z. Exploring Discriminative Representations for Image Emotion Recognition With CNNs. IEEE Trans. Multimed. 2020, 22, 515–523. [Google Scholar] [CrossRef]
- Huang, L.; Wang, W.; Xia, Y.; Chen, J. Adaptively Aligned Image Captioning via Adaptive Attention Time. arXiv 2019, arXiv:1909.09060. [Google Scholar]
- Ke, L.; Pei, W.; Li, R.; Shen, X.; Tai, Y.W. Reflective Decoding Network for Image Captioning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.C.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. arXiv 2015, arXiv:1502.03044. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. arXiv 2017, arXiv:1707.07998. [Google Scholar]
- Guo, L.; Liu, J.; Tang, J.; Li, J.; Luo, W.; Lu, H. Aligning Linguistic Words and Visual Semantic Units for Image Captioning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Xie, Z.; Feng, Y.; Hu, Y.; Liu, H. Generating image description of rice pests and diseases using a ResNet18 feature encoder. Trans. Chin. Soc. Agric. Eng. 2022, 38, 197–206. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Li, G.; Zhu, L.; Liu, P.; Yang, Y. Entangled Transformer for Image Captioning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on Attention for Image Captioning. arXiv 2019, arXiv:1908.06954. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-Memory Transformer for Image Captioning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Liu, W.; Chen, S.; Guo, L.; Zhu, X.; Liu, J. CPTR: Full Transformer Network for Image Captioning. arXiv 2021, arXiv:2101.10804. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Jégou, H. Training data-efficient image transformers & distillation through attention. arXiv 2020, arXiv:2012.12877. [Google Scholar]
- Hodosh, M.; Young, P.; Hockenmaier, J. Framing Image Description as a Ranking Task: Data, Models and Evaluation Metrics. In Proceedings of the International Conference on Artificial Intelligence, Phuket, Thailand, 26–27 July 2015; pp. 853–899. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft COCO: Common Objects in Context; Springer International Publishing: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Lu, X.Y.; Yang, R.; Zhou, J.; Jiao, J.; Liu, F.; Liu, Y.F.; Su, B.F.; Gu, P.W. A hybrid model of ghost-convolution enlightened transformer for effective diagnosis of grape leaf disease and pest. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 1755–1767. [Google Scholar] [CrossRef]
- Nazari, K.; Ebadi, M.J.; Berahmand, K. Diagnosis of Alternaria disease and leafminer pest on tomato leaves using image processing techniques. J. Sci. Food Agric. 2022, 102, 6907–6920. [Google Scholar] [CrossRef]
- Chao, D.W.; Jun, S.S.; Bin, S.W. An algorithm of image hashing based on image dictionary of CBIR. Microcomput. Its Appl. 2010. [Google Scholar] [CrossRef]
- Yumei, Y.; Yi, P.; Junhui, Q. Research on the Image Similarity Retrieval Algorithm Based on Double Hash. Inf. Commun. Technol. 2019. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002. [Google Scholar]
- Satanjeev, B. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the Second Workshop on Statistical Machine Translation, Ann Arbor, MI, USA, 25–30 June 2005; pp. 228–231. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of summaries. In Proceedings of the Workshop on Text Summarization Branches Out (WAS 2004), Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. CIDEr: Consensus-based Image Description Evaluation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Latin Name | Number of Sample Images | Number of Actual Field Images |
|---|---|---|---|
| Rice bacterial blight | Xanthomonas oryzae pv. Oryzae | 179 | 34 |
| Rice bacterial streak disease | Xanthomonas oryzicoia pv. Oryzicola | 372 | 45 |
| Rice bakanae disease | Fusarium moniliforme Sheld | 150 | 19 |
| Rice three chemical borers | Tryporyza incertulas (Walker) | 144 | 19 |
| Rice brown spot | Cochliobolus miyabeanus | 264 | 48 |
| Rice planthopper | Laodelphax striatellus Fallén | 252 | 34 |
| Rice blast | Pyricularia oryzae Cavara | 276 | 46 |
| Rice false smut | Ustilaginoidea oryzae | 240 | 41 |
| Rice sheath blight | Rhizoctonia solani | 298 | 39 |
| Rice thrip | Stenchaetothrips biformis | 108 | 17 |
| Image | Manually Annotated Reference Sentences |
|---|---|
 Bacterial blight |
|
| |
| |
| |
|
| Models | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | CIDEr | ROUGE-L | METEOR |
|---|---|---|---|---|---|---|---|
| AlexNet | 72.1 | 59.1 | 50.9 | 44.8 | 162.8 | 63.8 | 37.3 |
| VGG16 | 71.1 | 58.3 | 50.5 | 43.8 | 161.6 | 62.5 | 36.0 |
| ResNet101 | 70.4 | 57.8 | 50.0 | 44.4 | 173.1 | 64.5 | 36.9 |
| ResNet18 | 71.8 | 60.1 | 52.3 | 46.4 | 174.9 | 64.8 | 38.2 |
| InceptionV3 | 70.9 | 58.7 | 50.7 | 45.0 | 172.4 | 64.8 | 38.2 |
| MobileNetV2 | 71.7 | 59.5 | 51.5 | 45.3 | 174.1 | 64.3 | 37.5 |
| DeiT | 76.4 | 63.2 | 53.9 | 47.3 | 177.1 | 65.0 | 37.0 |
| Image | Predicted Results |
|---|---|
 1. Rice bacterial streak |
|
 2. Rice bacterial blight |
|
 3. Rice blast |
|
 4. Planthopper |
|
| Models | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | CIDEr | ROUGE-L | METEOR |
|---|---|---|---|---|---|---|---|
| AlexNet | 63.6 | 47.0 | 37.4 | 30.8 | 103.9 | 51.2 | 29.6 |
| VGG16 | 63.3 | 47.5 | 38.4 | 32.1 | 107.5 | 51.9 | 29.9 |
| ResNet101 | 62.9 | 45.8 | 36.4 | 29.9 | 104.3 | 51.4 | 29.5 |
| ResNet18 | 62.6 | 47.2 | 38.0 | 31.7 | 110.7 | 52.7 | 31.0 |
| InceptionV3 | 63.8 | 47.1 | 37.8 | 31.5 | 109.2 | 52.0 | 30.2 |
| MobileNetV2 | 65.0 | 47.9 | 38.0 | 31.0 | 107.9 | 52.2 | 30.1 |
| DeiT | 68.8 | 50.8 | 40.0 | 32.2 | 112.0 | 54.1 | 31.0 |
| Category | Accuracy % |
|---|---|
| Rice bacterial blight | 79.49 |
| Rice bacterial streak disease | 82.22 |
| Rice bakanae disease | 52.63 |
| Rice three chemical borers | 89.47 |
| Rice brown spot | 72.92 |
| Rice planthopper | 100.00 |
| Rice blast | 100.00 |
| Rice false smut | 100.00 |
| Rice sheath blight | 100.00 |
| Rice thrip | 100.00 |
| Average | 87.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, C.; Hu, Y.; Liu, H.; Huang, P.; Zhu, Y.; Dai, D. Generating Image Descriptions of Rice Diseases and Pests Based on DeiT Feature Encoder. Appl. Sci. 2023, 13, 10005. https://doi.org/10.3390/app131810005
Ma C, Hu Y, Liu H, Huang P, Zhu Y, Dai D. Generating Image Descriptions of Rice Diseases and Pests Based on DeiT Feature Encoder. Applied Sciences. 2023; 13(18):10005. https://doi.org/10.3390/app131810005
Chicago/Turabian StyleMa, Chunxin, Yanrong Hu, Hongjiu Liu, Ping Huang, Yikun Zhu, and Dan Dai. 2023. "Generating Image Descriptions of Rice Diseases and Pests Based on DeiT Feature Encoder" Applied Sciences 13, no. 18: 10005. https://doi.org/10.3390/app131810005
APA StyleMa, C., Hu, Y., Liu, H., Huang, P., Zhu, Y., & Dai, D. (2023). Generating Image Descriptions of Rice Diseases and Pests Based on DeiT Feature Encoder. Applied Sciences, 13(18), 10005. https://doi.org/10.3390/app131810005