
Aircraft Target Interpretation Based on SAR Images

Abstract
:1. Introduction
- (1)
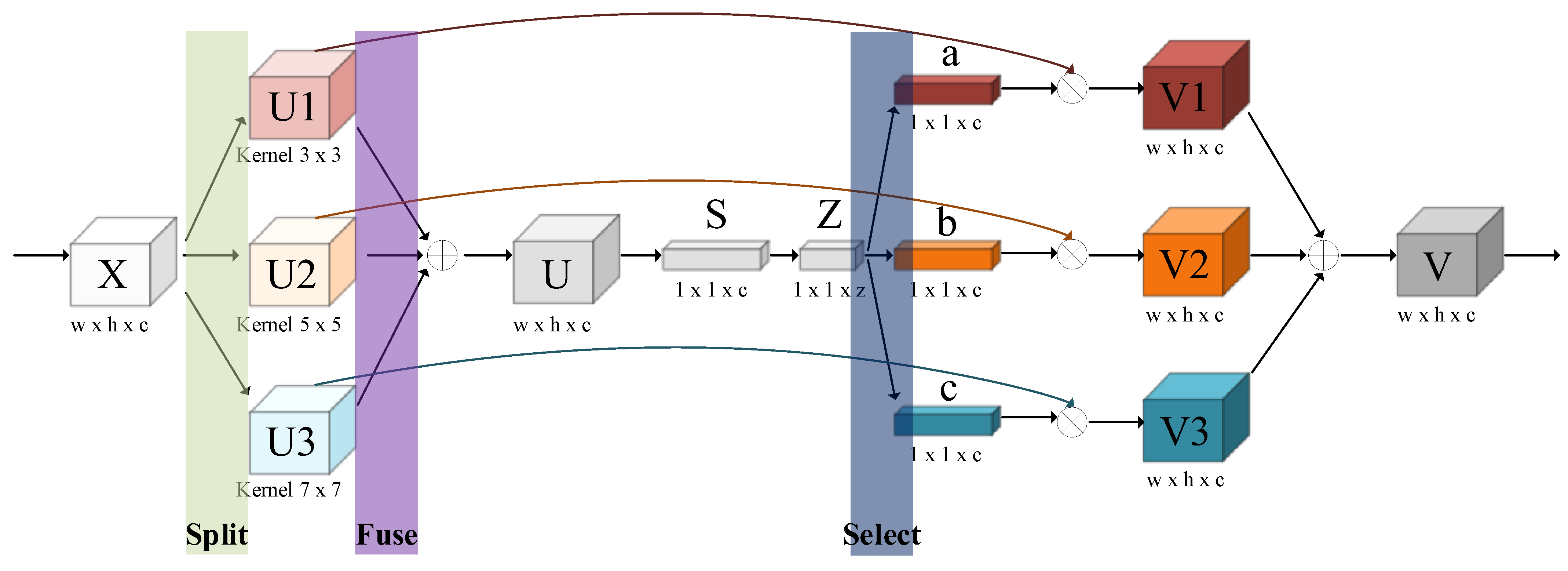
- This paper proposed the multi-scale receptive field and channel attention (MRFCA) module based on SENet [26] and the inception network [27]. The MRFCA module was integrated into the backbone of YOLOv5s, which can change the adaptively receptive field for the multi-scale targets and capture more relevant information and critical features.
- (2)
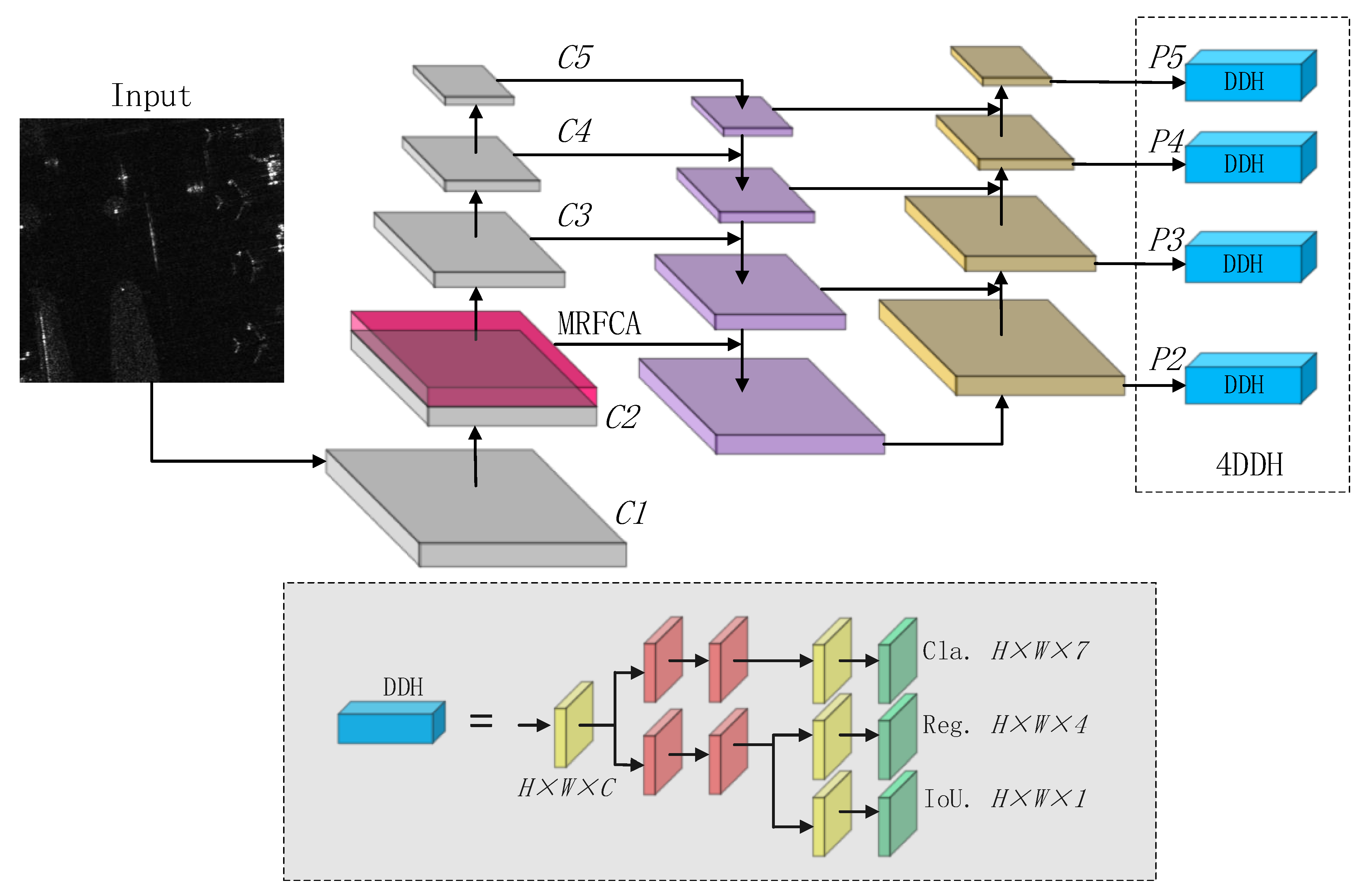
- An additional detector was integrated into the YOLOv5s. All the detect heads adopt decoupled operations. The new four decoupled detection heads (4DDH) structure can improve detectability for multi-scale targets and enhance detection precision for small targets.
- (3)
- Flip, scaling, and mosaic data augmentation methods were fused to enhance the diversity of datasets and the generalization ability of the model and prevent overfitting [28].
- (4)
- This paper adopted the K-means++ to replace the original K-means algorithm to improve the network convergence speed and detection accuracy [29].
2. Related Work
2.1. YOLOv5s Network
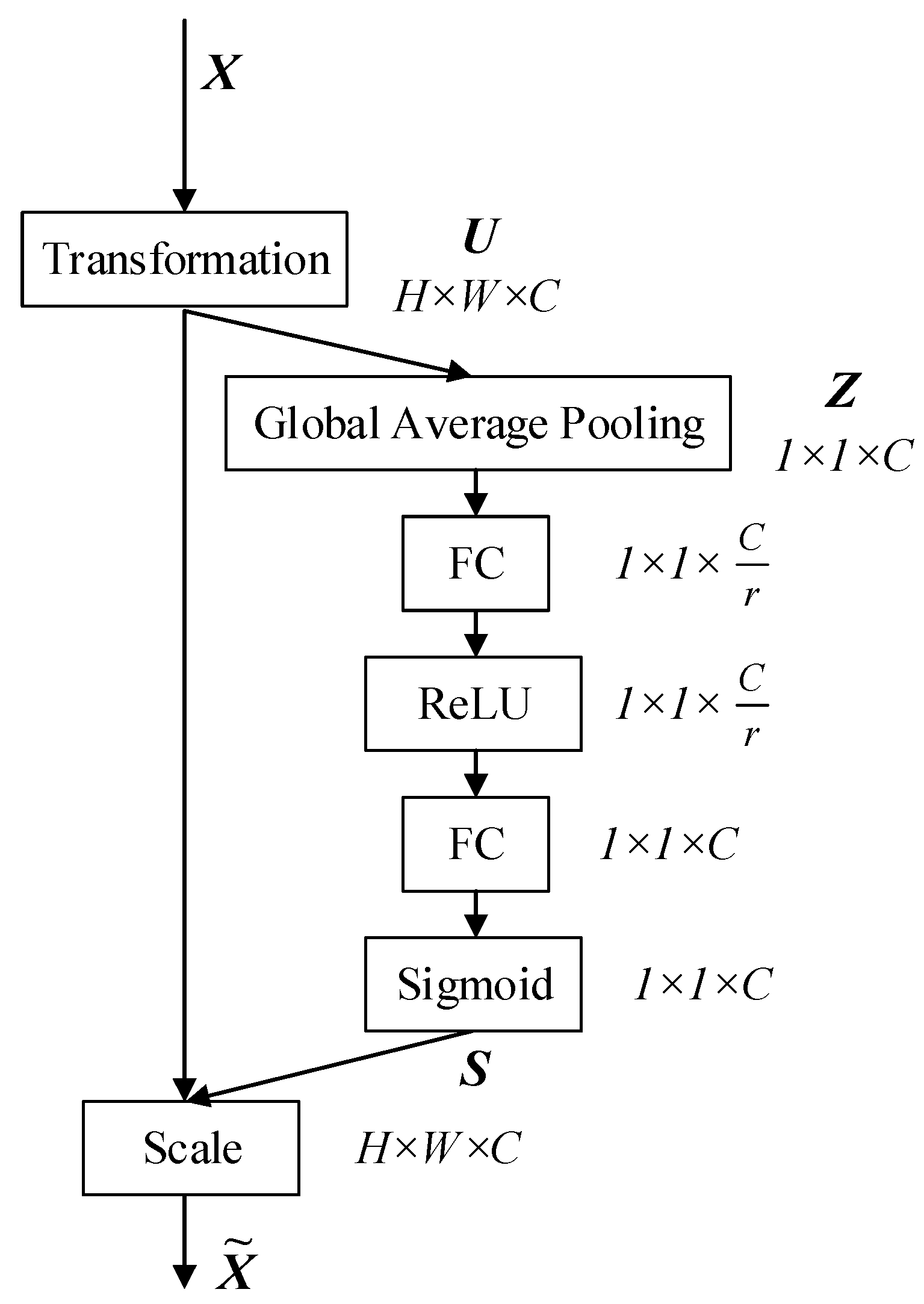
2.2. Channel Attention Mechanism
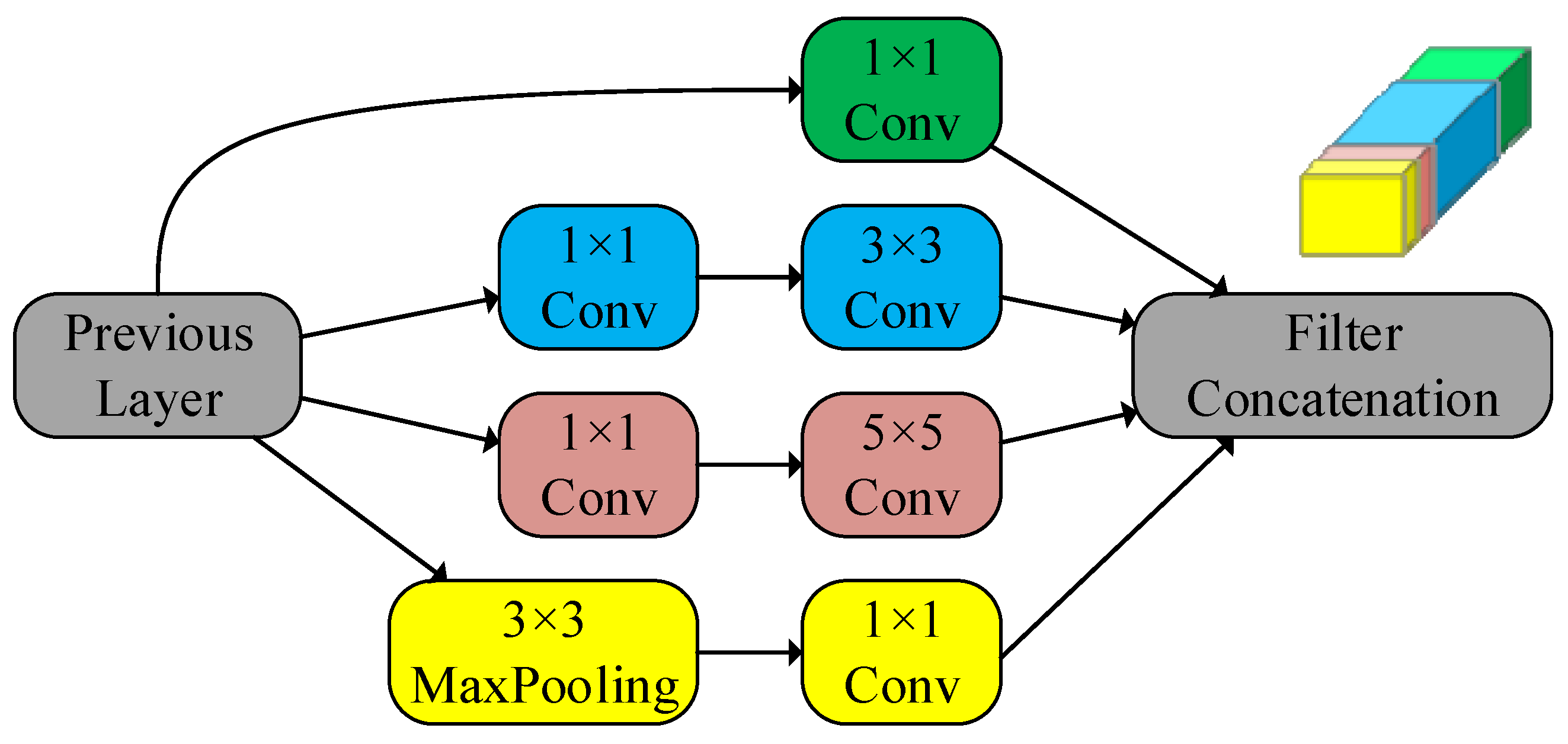
2.3. Inception Network
3. Method
3.1. Multi-Scale Receptive Field and Channel Attention Fusion (MRFCA)
3.2. Four Decoupled Detection Heads (4DDH)
3.3. Data Augmentation Method
3.4. Optimization Method of Adaptive Anchor Box
- Randomly selected initial clustering anchor boxes from the dataset. ( is the width of the anchor box, is the height of the anchor box).
- Calculate the distance from all bounding boxes to as follows: ( represents the total number of all bounding boxes)
- Classify bounding boxes into the relevant clusters based on the principle of nearest distance. Finally, classify all bounding boxes into clusters.
- Recalculate the new clustering center boxes , then repeat steps two, three, and four until the clustering anchor boxes remain unchanged.
4. Experimental Results and Analysis
4.1. Experimental Environment
4.2. Experimental Evaluation
4.3. Experiment Analysis
4.4. Ablation Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef]
- Cui, Y.; Zhou, G.; Yang, J. Yamaguchi On the iterative censoring for target detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2011, 8, 641–645. [Google Scholar] [CrossRef]
- Ao, W.; Xu, F.; Li, Y.; Wang, H. Detection and discrimination of ship targets in complex background from spaceborne ALOS-2 SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 536–550. [Google Scholar] [CrossRef]
- Gao, G.; Ouyang, K.; Zhou, S.; Luo, Y.; Liang, S. Scheme of parameter estimation for generalized gamma distribution and its application to ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1812–1832. [Google Scholar] [CrossRef]
- Leng, X.; Ji, K.; Zhou, S.; Xing, X. Ship detection based on complex signal kurtosis in single-channel SAR imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 57, 6447–6461. [Google Scholar] [CrossRef]
- Wang, X.; Chen, C. Ship detection for complex background SAR images based on a multiscale variance weighted image entropy method. IEEE Geosci. Remote Sens. Lett. 2017, 14, 184–187. [Google Scholar] [CrossRef]
- Zhang, X.; Tan, Z.; Wang, Y. SAR target recognition based on multi-feature multiple representation classifier fusion. J. Radars 2017, 6, 492–502. [Google Scholar] [CrossRef]
- Cheng, J.; Li, L.; Wang, X. SAR target recognition under the framework of sparse representation. J. Univ. Electron. Sci. Technol. China 2014, 43, 524–529. [Google Scholar]
- Wu, Q.; Sun, H.; Sun, X.; Zhang, D.; Fu, K. Aircraft recognition in high-resolution optical satellite remote sensing images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 112–116. [Google Scholar]
- Ge, L.; Xian, S.; Fu, K.; Wang, H. Interactive geospatial object extraction in high resolution remote sensing images using shape-based global minimization active contour model. Pattern Recognit. Lett. 2013, 34, 1186–1195. [Google Scholar]
- Xiao, Z.; Liu, Q.; Tang, G.; Zhai, X. Elliptic Fourier transformation-based histograms of oriented gradients for rotationally invariant object detection in remote-sensing images. Int. J. Remote Sens. 2015, 36, 618–644. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Berg, A.C.; Fu, C.; Szegedy, C.; Anguelov, D.; Erhan, D.; Reed, S.; Liu, W. SSD: Single shot multi-box detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Farhadi, A.; Redmon, J. Yolov3, An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhou, G.; Lu, B. A Multi-Scale Rebar Detection Network with an Embedded Attention Mechanism. Appl. Sci. 2023, 13, 8233. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar] [CrossRef]
- Tan, S.; Yan, J.; Jiang, Z.; Huang, L. Approach for improving YOLOv5 network with application to remote sensing target detection. J. Appl. Remote Sens. 2021, 15, 036512. [Google Scholar] [CrossRef]
- Yu, X.; Wu, S.; Lu, X.; Gao, G. Adaptive weighted multiscale feature fusion for small drone object detection. J. Appl. Remote Sens. 2022, 16, 034517. [Google Scholar] [CrossRef]
- Huang, M.; Xu, Y.; Qian, L.; Shi, W.; Zhang, Y.; Bao, W.; Wang, N.; Liu, X.; Xiang, X. The QXS-SAROPT dataset for deep learning in SAR-optical data fusion. arXiv 2021, arXiv:2103.08259v2. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Li, Z.; Li, C.; Deng, L.; Fan, Y.; Xiao, X.; Ma, H.; Qin, J.; Zhu, L. Improved AlexNet with Inception-V4 for Plant Disease Diagnosis. Comput. Intell. Neurosci. 2022, 2022, 5862600. [Google Scholar] [CrossRef] [PubMed]
- Kumar, T.; Mileo, A.; Brennan, R.; Bendechache, M. Image Data Augmentation Approaches: A Comprehensive Survey and Future directions. arXiv 2023, arXiv:2301.02830v4. [Google Scholar] [CrossRef]
- Goicovich, I.; Olivares, P.; Román, C.; Vázquez, A.; Poupon, C.; Mangin, J.F.; Guevara, P.; Hernández, C. Fiber Clustering Acceleration with a Modified Kmeans++ Algorithm Using Data Parallelism. Front. Neuroinform. 2021, 15, 727859. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Lin, Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2117–2125. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Yang, J.; Wang, W.; Li, X.; Hu, X. Selective kernel networks. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar] [CrossRef]
- Dhivyaa, C.R.; Kandasamy, N.; Rajendran, S. Integration of dilated convolution with residual dense block network and multi-level feature detection network for cassava plant leaf disease identification. Concurr. Comput. Pract. Exp. 2022, 34, e6879. [Google Scholar]
- 2021 Gaofen Challenge on Automated High-Resolution Earth Observation Image Interpretation. Available online: http://gaofen-challenge.com (accessed on 1 October 2021).
- Wang, X.; Hong, W.; Liu, Y.; Hu, D.; Xin, P. SAR Image Aircraft Target Recognition Based on Improved YOLOv5. Appl. Sci. 2023, 13, 6160. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Map Level | P2 | P3 | P4 | P5 |
|---|---|---|---|---|
| Original YOLOv5s | - | (10, 13) | (30, 61) | (116, 90) |
| (16, 30) | (62, 45) | (156, 198) | ||
| (33, 23) | (59, 119) | (373, 326) | ||
| Improved YOLOv5s | (16, 15) | (35, 37) | (65, 79) | (94, 74) |
| (23, 25) | (47, 61) | (73, 55) | (121, 98) | |
| (34, 24) | (54, 43) | (85, 108) | (146, 135) |
| Parameter | Configuration |
|---|---|
| CPU | Inter(R) Core(TM) i7-7820X CPU @ 3.60 GHz |
| GPU | NVIDIA TITAN Xp |
| Accelerator | CUDA 10.2 |
| Architecture | Pytorch 1.9 |
| Language | Python 3.8 |
| Method | Backbone | mAP50 | mAP75 | mAP50~95 | S-Target mAP50~95 | L-Target mAP50~95 |
|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet-50 | 85.9 | 70.3 | 55.7 | 46.1 | 59.8 |
| Retina-Net | ResNet-50 | 81.2 | 66.2 | 52.2 | 43.2 | 57.2 |
| SSD | VGG-16 | 80.5 | 65.3 | 51.8 | 41.8 | 56.9 |
| YOLOv3 | DarKnet-53 | 84.4 | 70.3 | 58.3 | 49.0 | 62.6 |
| YOLOv5s | CSPDarknet53 | 85.1 | 71.6 | 61.0 | 50.5 | 65.9 |
| Ours | Improved | 91.4 | 79.3 | 70.3 | 63.6 | 72.4 |
| C2 | C3 | C4 | C5 | mAP50 | mAP75 | mAP50~950 | S-Target mAP50~95 | L-Target mAP50~95 |
|---|---|---|---|---|---|---|---|---|
| × | × | × | × | 85.1 | 71.6 | 61.0 | 50.5 | 65.9 |
| √ | × | × | × | 89.3 | 76.2 | 67.5 | 59.6 | 69.9 |
| × | √ | × | × | 89.0 | 75.8 | 66.9 | 59.0 | 69.6 |
| × | × | √ | × | 88.6 | 75.3 | 66.2 | 58.2 | 69.2 |
| × | × | × | √ | 88.1 | 74.8 | 65.3 | 57.0 | 68.8 |
| Index | FS | FSM | 4DDH | MRFCA | K-Mean++ | mAP50 | mAP75 | mAP50~95 | S-Target mAP50~95 | L-Target mAP50~95 |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | × | × | × | × | × | 85.1 | 71.6 | 61.0 | 50.5 | 65.9 |
| YOLOv5s+ | √ | × | × | × | × | 86.5 | 72.5 | 61.6 | 51.2 | 66.4 |
| YOLOv5s+ | × | √ | × | × | × | 87.3 | 73.5 | 63.2 | 53.8 | 67.3 |
| YOLOv5s+ | × | √ | √ | × | × | 88.1 | 74.5 | 65.3 | 57.1 | 68.2 |
| YOLOv5s+ | × | √ | × | √ | × | 89.3 | 76.2 | 67.5 | 59.6 | 69.9 |
| YOLOv5s+ | × | √ | √ | √ | × | 90.6 | 78.6 | 69.7 | 63.1 | 72.0 |
| YOLOv5s+ | × | √ | × | × | √ | 88.1 | 74.2 | 63.8 | 54.3 | 67.7 |
| YOLOv5s+ | × | √ | √ | √ | √ | 91.4 | 79.3 | 70.3 | 63.6 | 72.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Hong, W.; Liu, Y.; Hu, D.; Xin, P. Aircraft Target Interpretation Based on SAR Images. Appl. Sci. 2023, 13, 10023. https://doi.org/10.3390/app131810023
Wang X, Hong W, Liu Y, Hu D, Xin P. Aircraft Target Interpretation Based on SAR Images. Applied Sciences. 2023; 13(18):10023. https://doi.org/10.3390/app131810023
Chicago/Turabian StyleWang, Xing, Wen Hong, Yunqing Liu, Dongmei Hu, and Ping Xin. 2023. "Aircraft Target Interpretation Based on SAR Images" Applied Sciences 13, no. 18: 10023. https://doi.org/10.3390/app131810023
APA StyleWang, X., Hong, W., Liu, Y., Hu, D., & Xin, P. (2023). Aircraft Target Interpretation Based on SAR Images. Applied Sciences, 13(18), 10023. https://doi.org/10.3390/app131810023