1. Introduction
In the semiconductor industry, wafer transfer robots perform missions to move wafers from position to position. They are usually operated at very high speeds to accomplish high productivity while maintaining precise position control. Since the robot consists of several interconnected components such as the motor, speed reducer, timing belt, and so on, wear in these components occurs over time, which causes a degradation in the performance of the robot, and ultimately leads to the failure to perform its intended function. In the field, however, many manufacturing lines often rely on corrective maintenance, that is, the robots are kept in operation until failure, despite the fact that failure causes downtime of the entire line and a significant loss in productivity. Therefore, it is important to develop a solution to monitor the robot’s health condition to prevent such failures in a proactive way.
Many researchers have investigated this issue for industrial robots for decades. Kim et al. [
1] proposed a fault detection method using vibration signals and phase-based time-domain averaging (PTDA) in the gearbox of an industrial robot. Capisani et al. [
2] proposed a physical-model-based fault presence detection method. Yang et al. [
3] proposed a data-based fault diagnosis method using the motor current signal of the ball screw. Cheng et al. [
4] detected faults through unsupervised clustering learning for abnormal gears induced by removing grease artificially. Chen et al. [
5] introduced a sliding window convolutional deformation autoencoder (SWCVAE) that can realize robot anomaly detection. While these papers have contributed significantly to the diagnoses of robot failures, their common limitation is that the object is a single component with binary fault conditions, which cannot capture the fault severity. Others, such as [
6], diagnosed small, intermediate, and high gearbox backlash in a joint robot using DWT signal preprocessing and an ANN. Kim et al. [
7] proposed a method to diagnose the severity of control cable wire damage. Huh et al. [
8] diagnosed soft and hard pitting gears based on a critical information map (CIM). These studies improved diagnoses considering different fault severities, but studied only a single component, not multiple components.
In fact, a robot is composed of several components, each of which has their own failure modes. The issue of multiple fault diagnosis (MFD) has been addressed by several authors. Guo et al. [
9] designed a level-based learning swarm optimizer–extreme learning machine (LLSO-ELM) model to further improve the generalization performance of ELM by combining it with LLSO, and classified a total of six failure modes for two components. Chen et al. [
10] diagnosed five failure modes for three components by combining the generalized frequency response function (GFRF) spectrum and a convolutional neural network (CNN). Long et al. [
11] proposed an attitude-data-based sparse auto-encoder–support vector machine (SAE-SVM) approach to diagnose transmission faults, implemented with eight failure modes for multi-joint industrial robots. Rohan et al. [
12] diagnosed two failure modes, the wear of gear teeth and bearings, using motor current signature analysis (MCSA) with discrete wavelet transform (DWT) to analyze the signals in the time–frequency domain. In those studies, the drawbacks are that the faults are assumed to be mutually exclusive and are considered in a binary manner, i.e., normal and fault. However, failure modes of components can occur interactively, which complicates the problem and may lead to misleading results unless this is accounted for. This is also addressed in the recent paper by [
13], in which the same challenge is stated for the PHM of industrial robots. In fields other than robotics, Qin et al. [
14] proposed a methodology based on a multi-scale convolutional neural network–long short-term memory neural network (MSCNN-LSTMNet) to diagnose the failure of multi-cylinder diesel engines under interactive failure.
Summing up the above literature on industrial robots, the common finding is that most of the studies have focused on the diagnosis at the component level with faults of binary or multiple severities, and with regard to a single or multiple components. As mentioned in the beginning, the degradation of each component affects the performance of the robot system, not in an additive, but in an interactive manner. This means that the interrelation between the system and components should be accounted for, which we call diagnosis at the system level. In fact, the degradation of a component cannot be defined on its own but should be defined as conditional on the failure of the system, meaning that as long as the system performs its function well, the components have not yet failed.
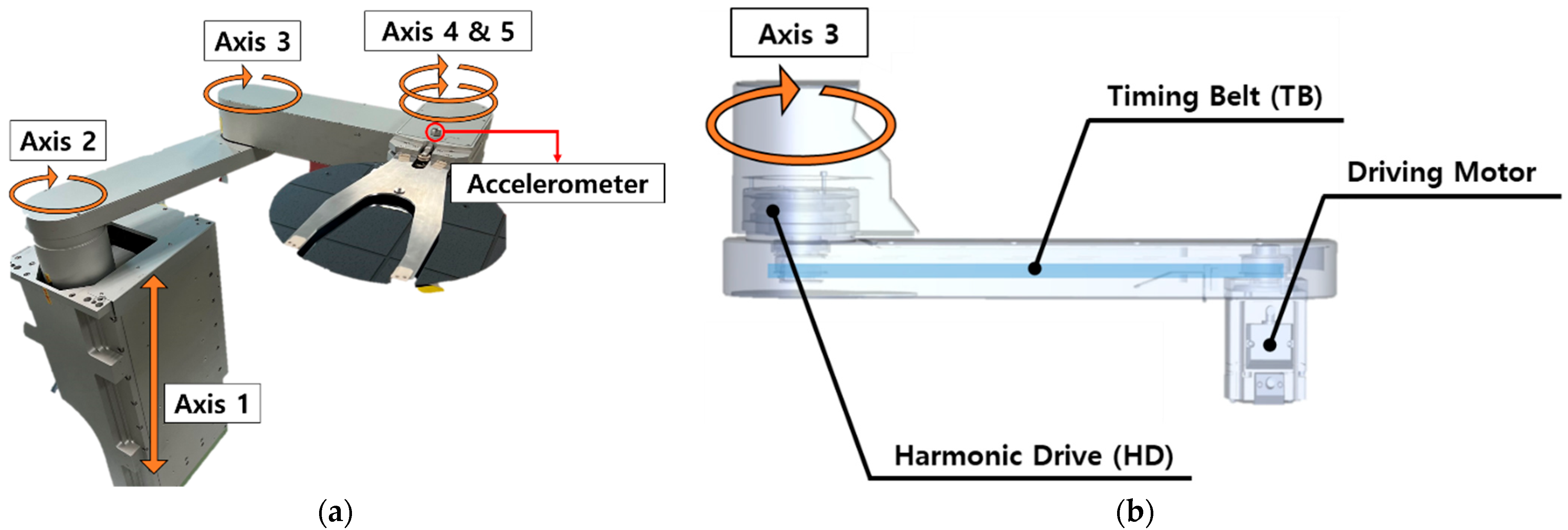
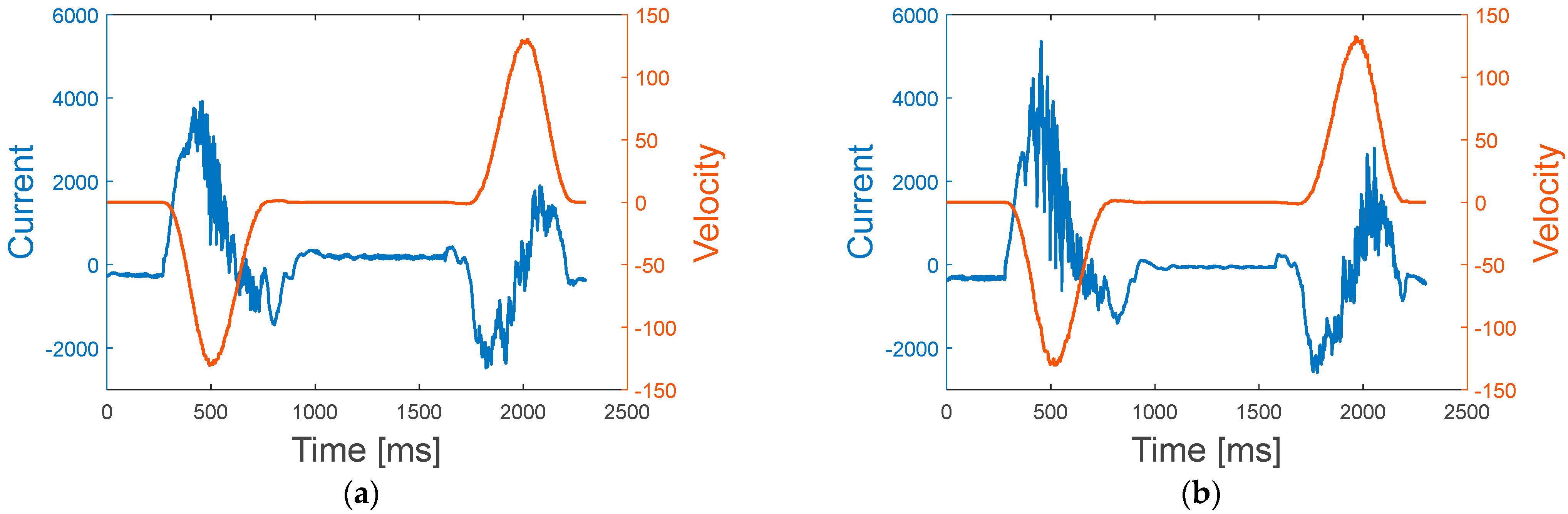
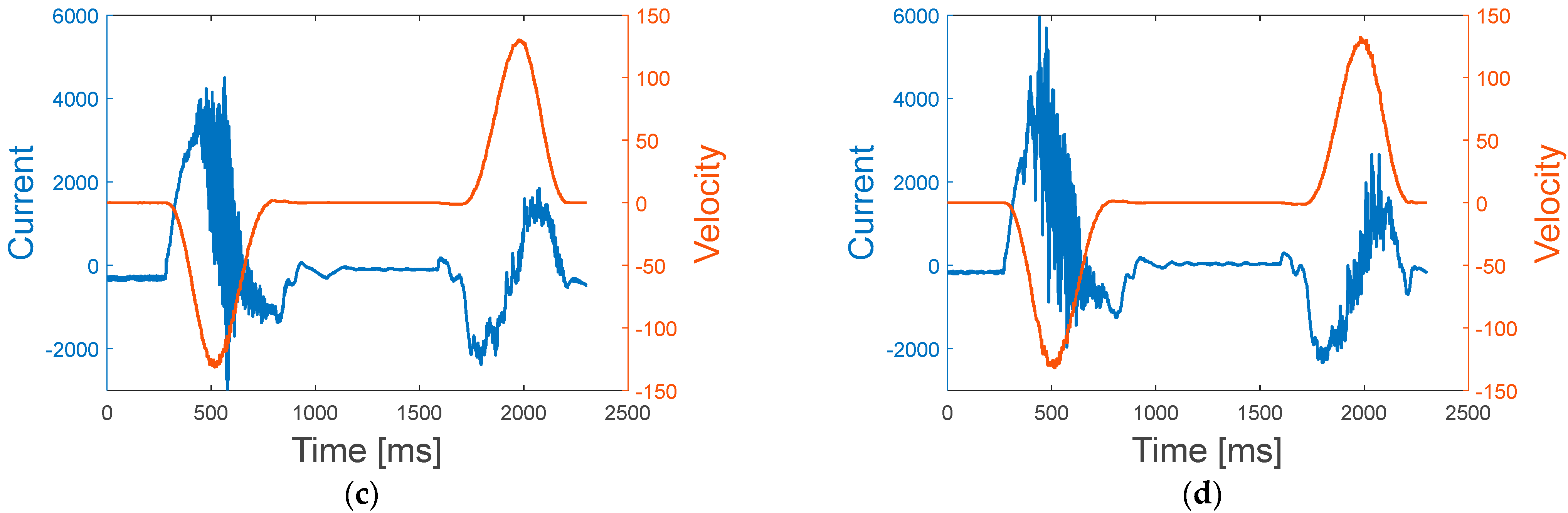
Motivated by this issue, this paper proposes a procedure of how to conduct a system-level diagnosis for a system with multiple components. The method is demonstrated by applying it to a wafer transfer robot with two components, a harmonic drive (HD) and timing belt (TB), which are known as the most critical components responsible for robot failure [
15]. To this end, a test rig is constructed, in which a robot is operated under various fault conditions with different severities. During the operation, the motor signal acquired to control its motion is exploited to diagnose the health of the system and its components. According to the robot company, the system performance is defined by a vibration magnitude of the end-effector during the operation, which is measured by an accelerometer. If the value exceeds a certain threshold, it is regarded as failure, that is, the robot fails to deliver the wafer to the target position, and the operation is aborted. In order to relate the motor control signal with the faults of the components, features are extracted by using the wavelet packet decomposition (WPD), which is known to be effective for nonstationary signals. A framework for system-level diagnosis is constructed, which enables the estimation of the current state of health of each component and the system performance. It consists of two models: the artificial neural network (ANN) for the diagnosis of component health and the Gaussian process regression (GPR) for the estimation of system health.
To summarize, the contributions of the proposed work are as follows: First, multiple components with multiple degradation severities are examined to perform fault diagnosis of the robots. Second, the method leverages motor control signals, which are acquired automatically during operation, eliminating the need for supplementary sensors. Third, a framework for system-level diagnosis is proposed, assessing the component health in relation to the system performance, which is contrasted to the conventional component-level strategies.
The rest of the paper is organized as follows:
Section 2 presents the proposed methodology and theoretical background for the algorithms.
Section 3 gives a brief explanation of the industrial wafer transfer robot and the designed experiment. Then,
Section 4 presents the result of proposed methodology with the datasets of the designed experiment. Lastly, conclusions and potential future works are presented in
Section 5.
2. Methodology
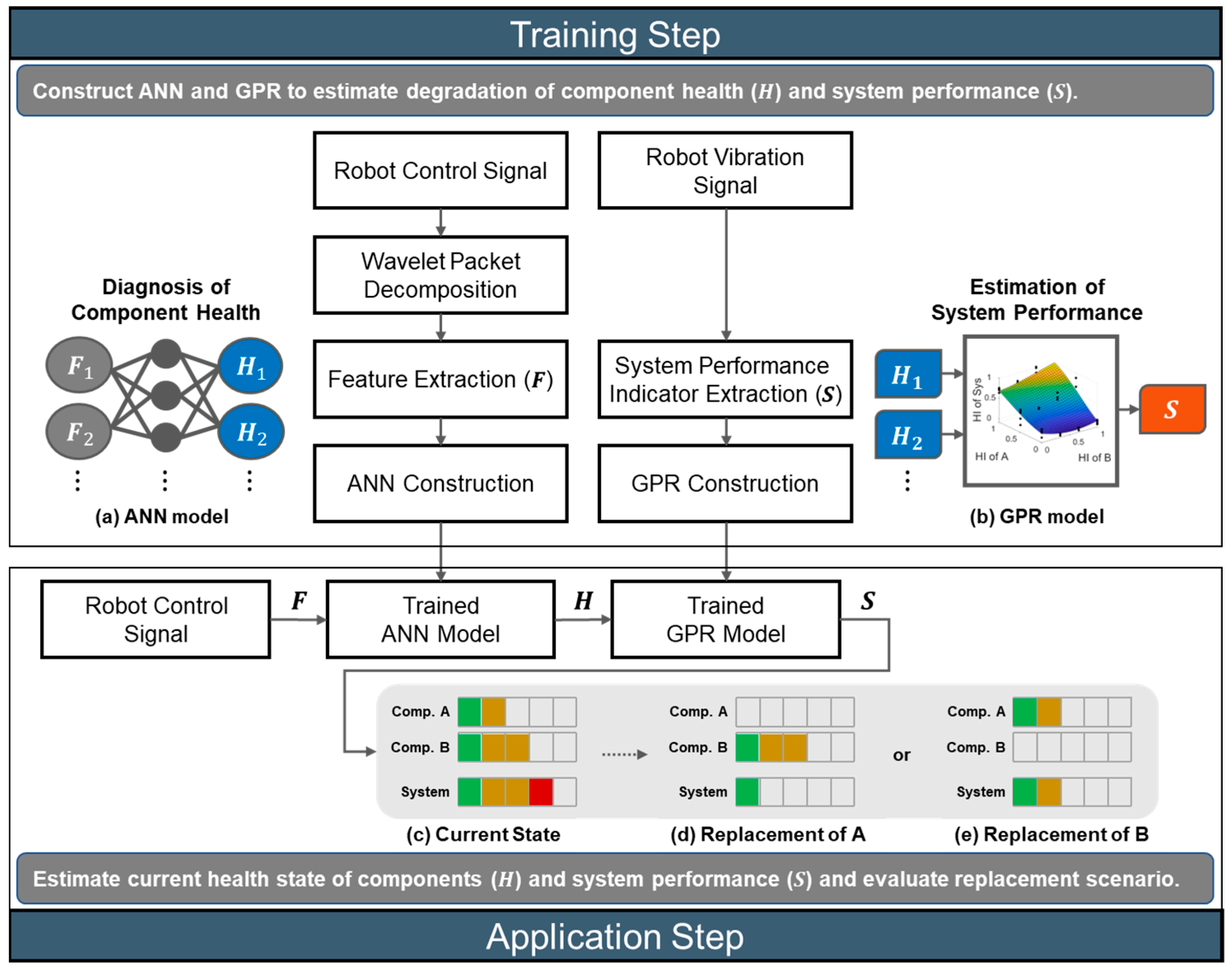
The proposed methodology is illustrated in
Figure 1, which addresses the system-level diagnosis framework. It consists of two steps: (1) training and (2) application. In the model training, two models are constructed to estimate the health of each component (
) by using the features (
) from the motor control signal and to estimate the resulting degradation of the system performance (
).
In order to construct the models, artificial faults of different severities are seeded into the components, and this can simulate the health degradation of each component, which is given by
1,
2, … in the figure. The robots are operated under each fault condition, during which the informative features are extracted and selected from the motor signals that control the motion. These are denoted by
1,
2, … in the figure. A vibration signal is also acquired from the end-effector by the accelerometer, by which the root mean square (RMS) values are computed as a measure of system performance. These are denoted by
1,
2, … in the figure. In the feature extraction, wavelet packet decomposition (WPD), which is appropriate for nonstationary signals, is employed, in which the signals are decomposed into the time–frequency domain. The statistical features and wavelet energy (WE) are extracted for each decomposed coefficient. A hybrid score based on the Spearman correlation and Fisher discriminant ratio (FDR) is then applied to select the most informative features among the features pool. Once the data are prepared by this method, the artificial neural network (ANN) model is constructed to relate the features set (
) with the health (
) of each component as shown in
Figure 1a. A Gaussian process regression (GPR) model is also constructed to relate the health (
) of each component with the system performance (
) as shown in
Figure 1b.
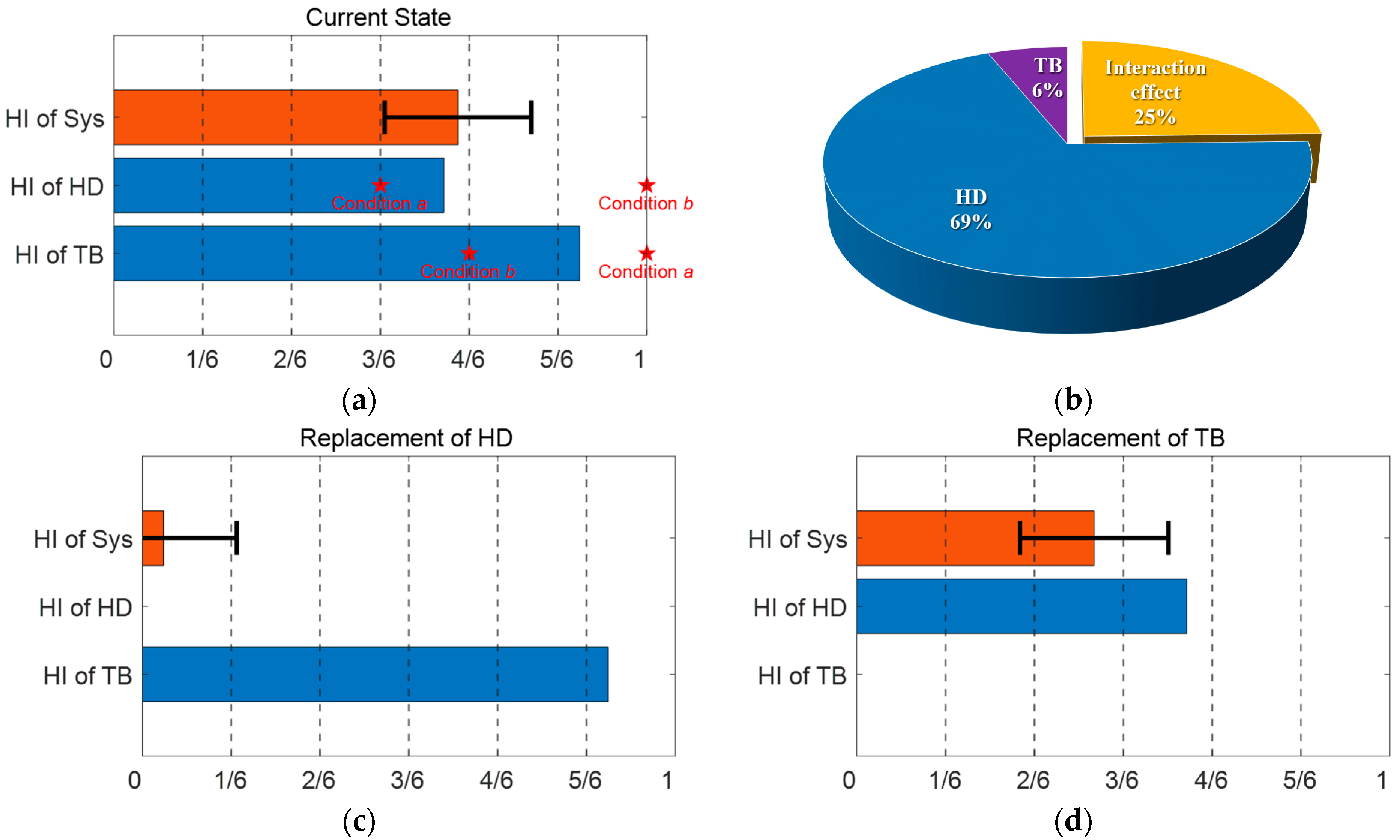
After the construction of the models, they are applied to diagnose the health of a new robot by using the motor control signal. Introducing the health indicator (HI) as 0 and 1 for the normal and failure, respectively, the results may be represented by a bar chart as in
Figure 1c, which shows the current state of health of each component as well as the system performance. In this figure, they are given by 0.4, 0.6, and 0.8 for the components A, B, and system as an illustration. Note that the degradation of system performance stems from these components. Once this is available, one can further develop the replacement strategy by conducting a what-if study: if only the component A or B is replaced, i.e., the HI of A or B is restored to 0, then the HI of the system will be restored to 0.2 or 0.4 as shown in
Figure 1d,e, respectively. In this illustration, it is better to replace A since the system restores to the better condition 0.2 than the alternative, 0.4. Note that simply replacing the worse component B in HI, which is illustrated in
Figure 1e in this case, does not always result in the better restoration of system performance. This is because of the nonlinear and interactive nature of components and system in terms of health degradation, which is why the system-level diagnosis framework is necessary.
2.1. Feature Extraction by Wavelet Packet Decomposition
In the robot operation, the signals acquired from the motor are nonstationary. In this case, approaches based on the time–frequency domain such as the wavelet transform are more appropriate than those on the frequency domain such as the fast Fourier transform. In this study, wavelet packet decomposition (WPD) is employed for the purpose of feature extraction, which is briefly described as follows:
Wavelet packet consists of a set of linearly combined wavelet functions, which are generated using the following recursive relationship [
16,
17]:
where
is the scaling function,
is the wavelet function, and
is an integer from 0 to
. Functions
and
represent coefficients of low-pass and high-pass filter of Quadrature mirror filters (QMF) which are related to each other by
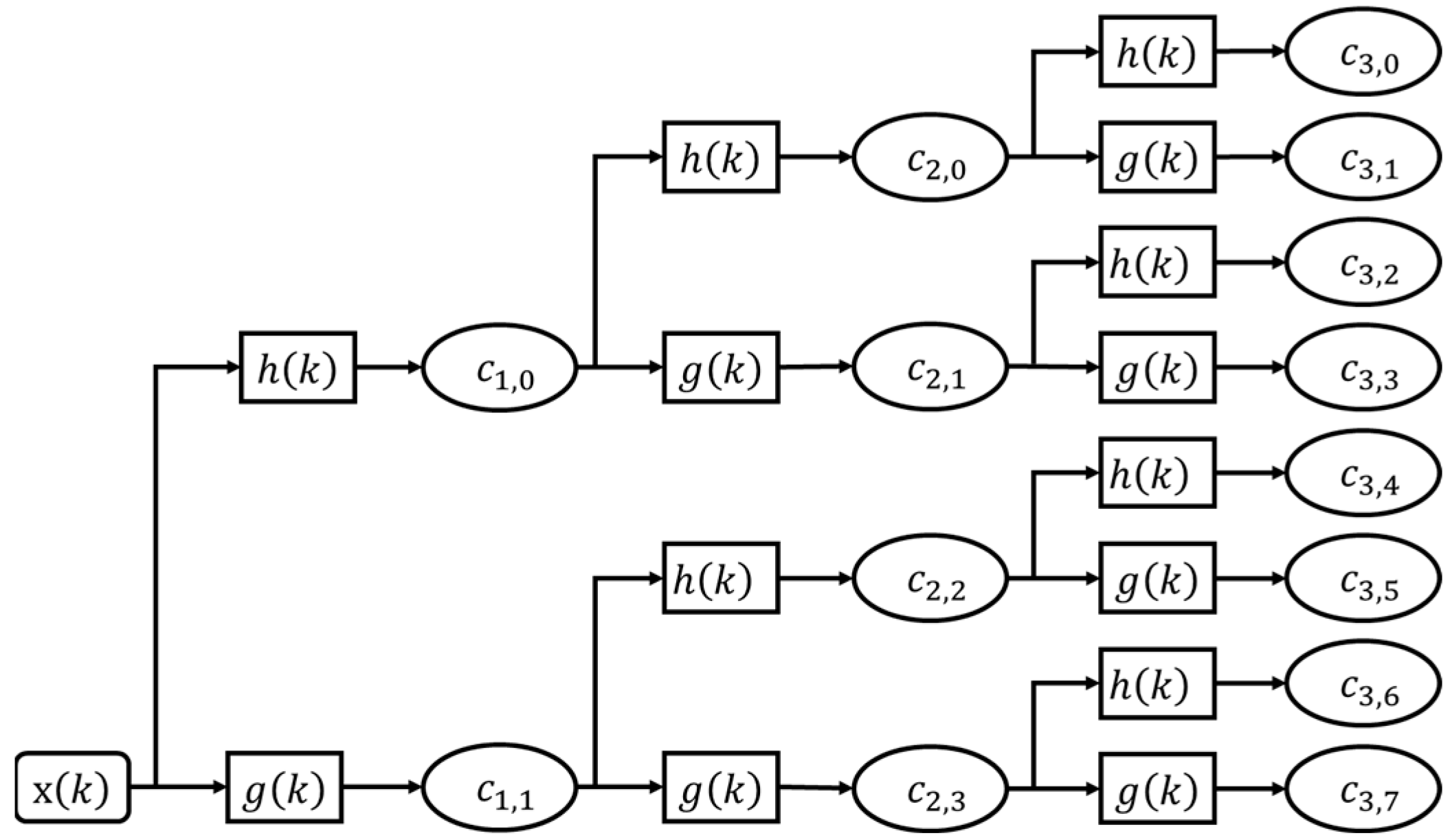
. For each step of the decomposition, the input signal
is decomposed into approximation in low frequency and detail in high frequency, which is expressed recursively as:
where
denotes the wavelet coefficients at the
-th level,
-th sub-frequency band. As a result, the original signal
can be expressed as the sum of the coefficients as follows:
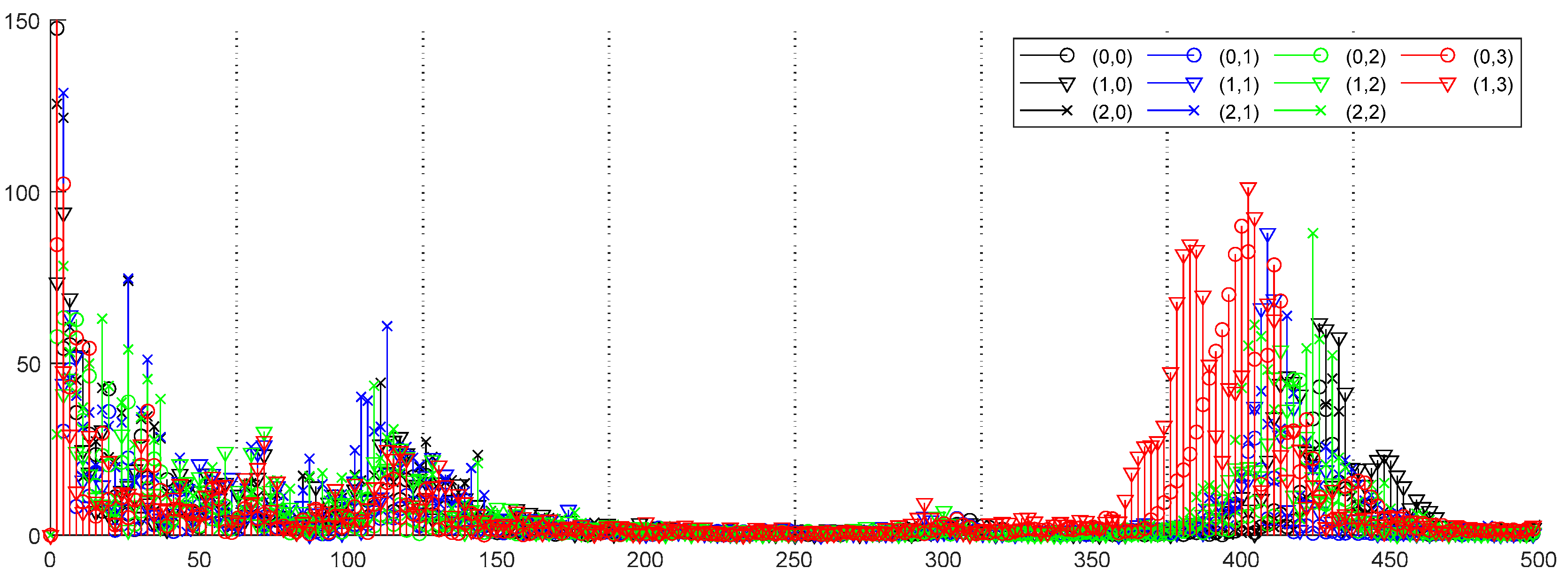
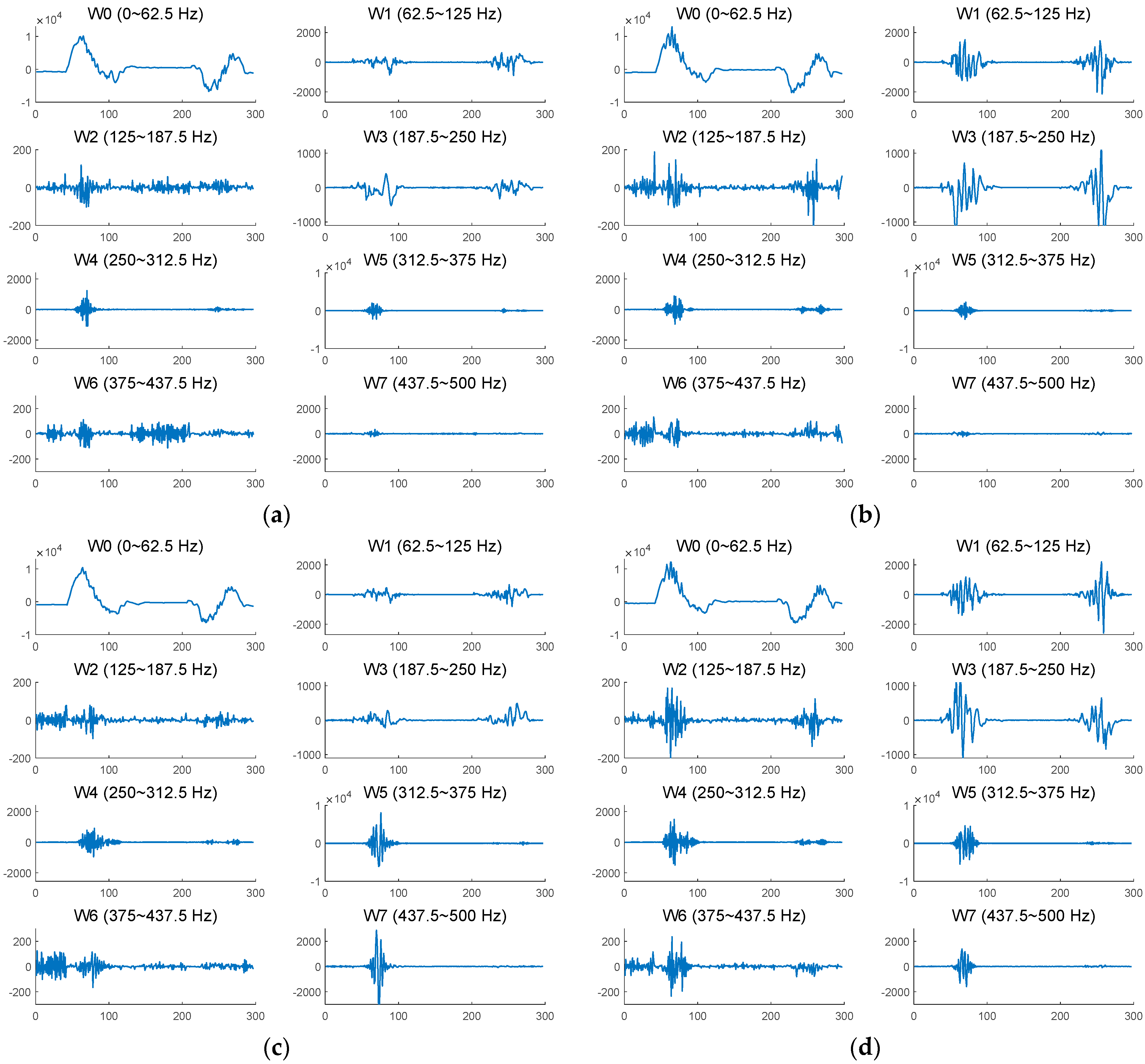
An example of a 3-level decomposition of the signal
using the WPD is shown in
Figure 2.
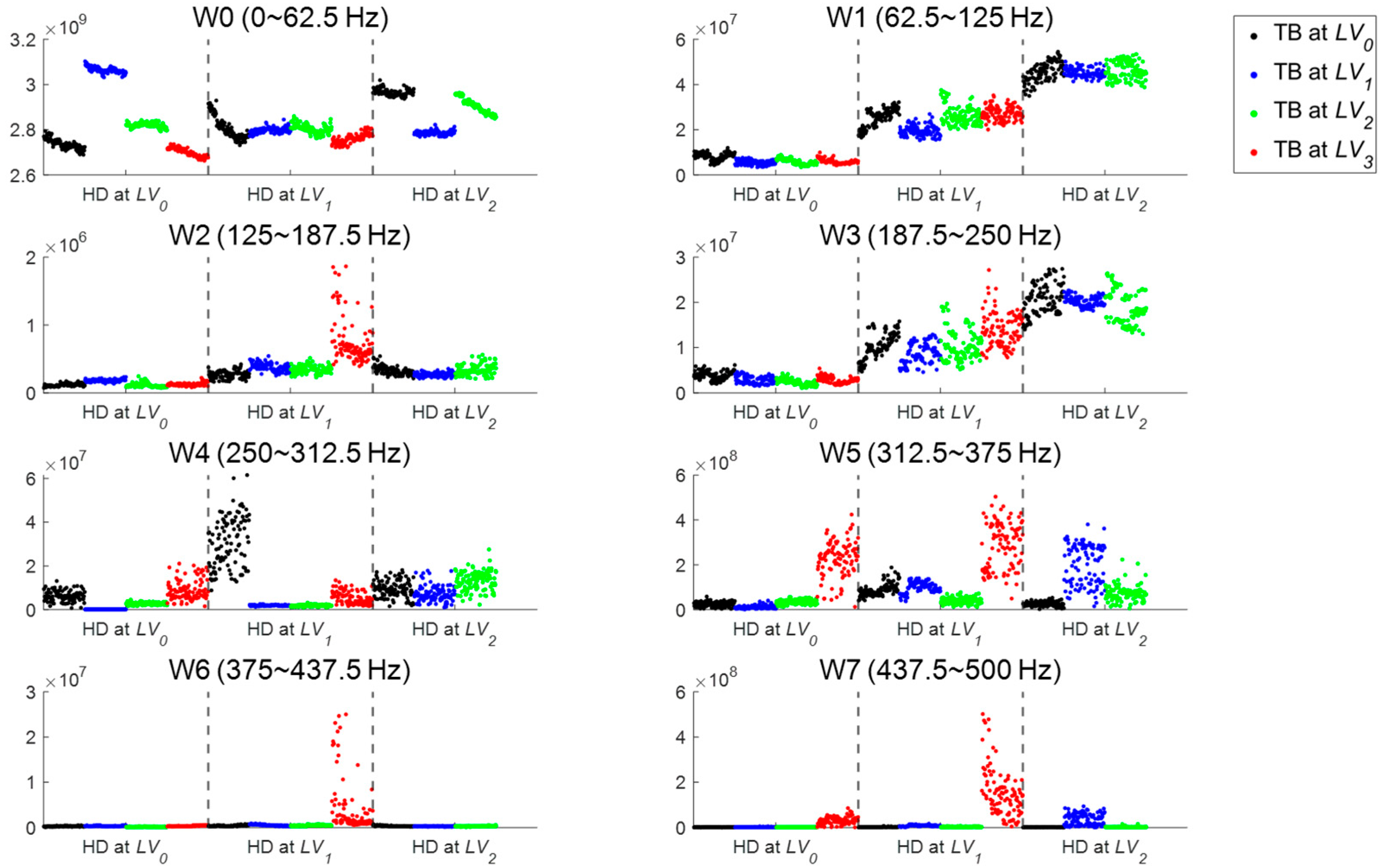
Given the decomposed coefficients, wavelet energy (WE) is extracted as a feature for each frequency band, which is defined as below.
Also, 13 statistical time-domain features commonly used in the fault diagnosis are extracted for each band, as shown in
Table 1 [
18,
19,
20].
2.2. Feature Selection
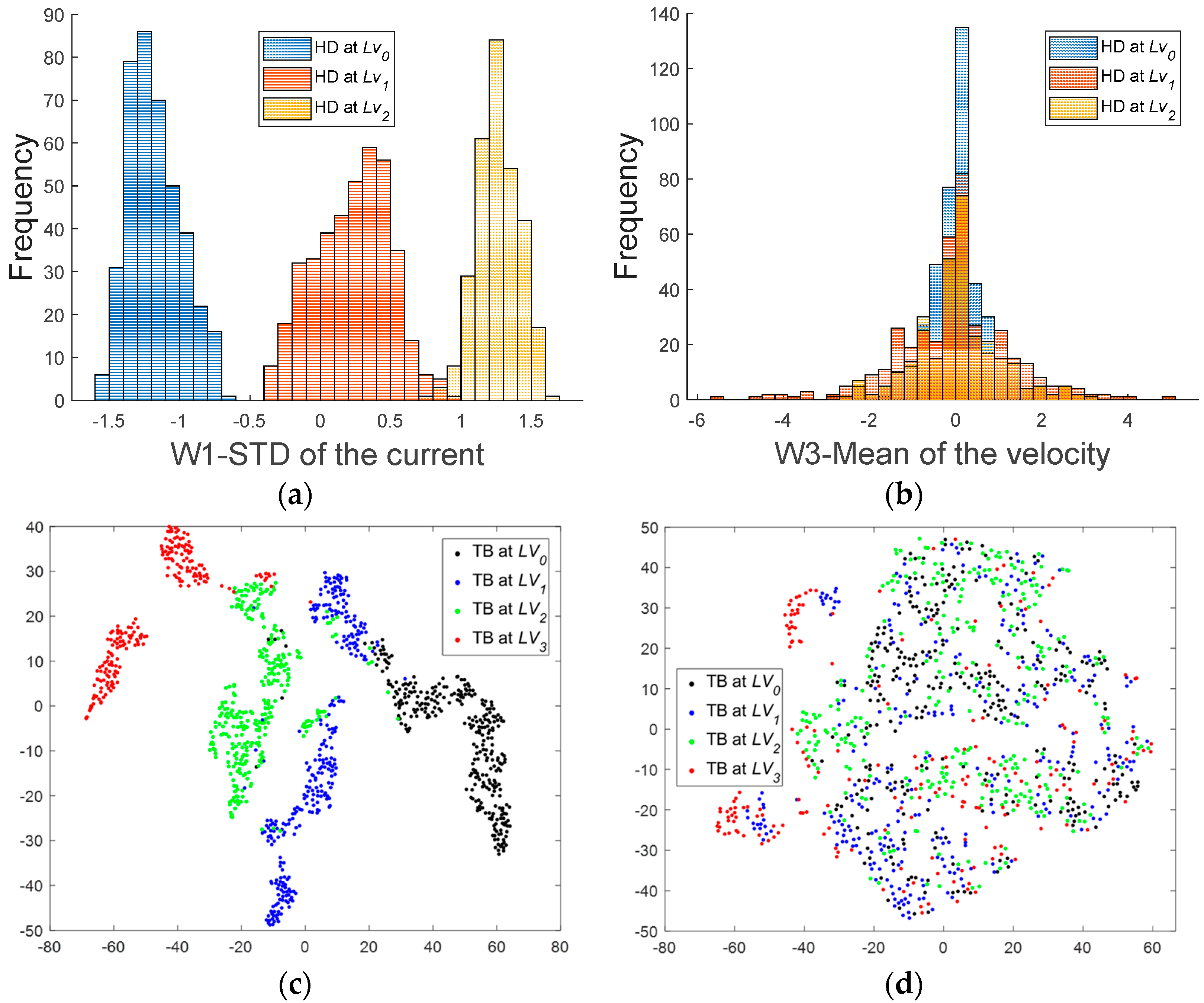
Among the extracted features, it is necessary to find the most informative ones for more efficient and accurate diagnostic performance. For this purpose, a score metric is introduced, which accounts for the two following aspects: First, the features should present a consistent trend as the fault severity rises, which is an important factor as the health indicator. Second, Spearman correlation (named
here) is employed to evaluate this, which is defined as
where
and
denote the rank variables of feature
and fault severity
. The
is calculated for each component. Next, the features should have good separability of the individual faults and their severities. This can be evaluated by the Fisher discriminant ratio (FDR) defined as follows:
where
and
represent the variances of between-class and within-class, respectively, in which each class denotes the individual fault with different severities.
By combining the two metrics, a hybrid score is defined for each component. For example, assume that we have three components A, B, and C, and we have acquired signals for each component under the fault conditions with the number of severities being
,
, and
, respectively. For example, if
, it means that the fault is applied to the component A with 4 severities: normal (no fault), small, medium, and large degree of fault. Then the total number of conditions is
. For each fault condition, a large number of features is obtained by decomposing the signal through WPD and extracting the features. For an individual feature, the correlation of component A can be defined as
where
represents the correlation of the feature with respect to the fault severity A when B and C are at the severity level
and
, respectively. Since this is performed for
to
and
to
to result in
number of
, these are summed to obtain a single representative value. Then the result is replaced by absolute value since the
can be negative. The same process is applied to obtain
to evaluate the separability of fault severity of component A, which is defined as
Once the two metrics
and
are calculated, they are combined into a single score by introducing weight parameter
. Before proceeding, however, the metric values are normalized since they differ in scale. Min–max algorithm is applied to the whole features so that they vary within the interval [0, 1], by assigning 0 and 1 to the minimum and maximum values. Then, the hybrid score for component A is given by
where the symbol
indicates the metrics are normalized by min–max algorithm. In this way, the score is calculated for all the components A, B, and C for each feature.
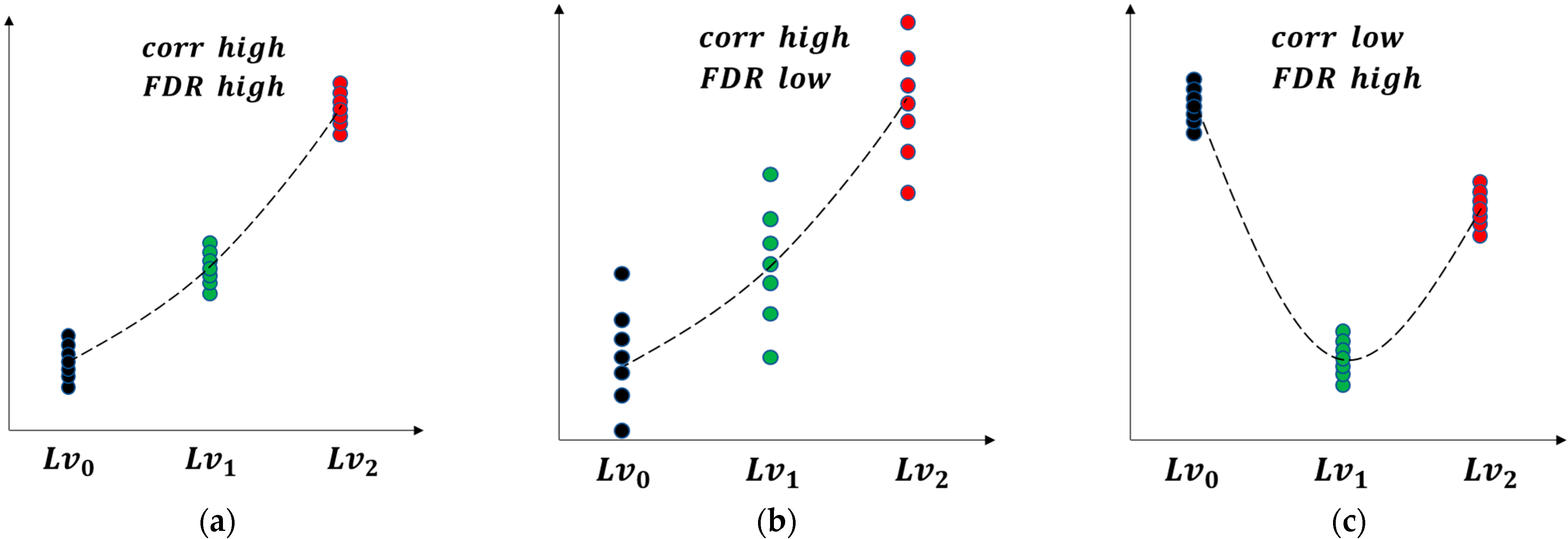
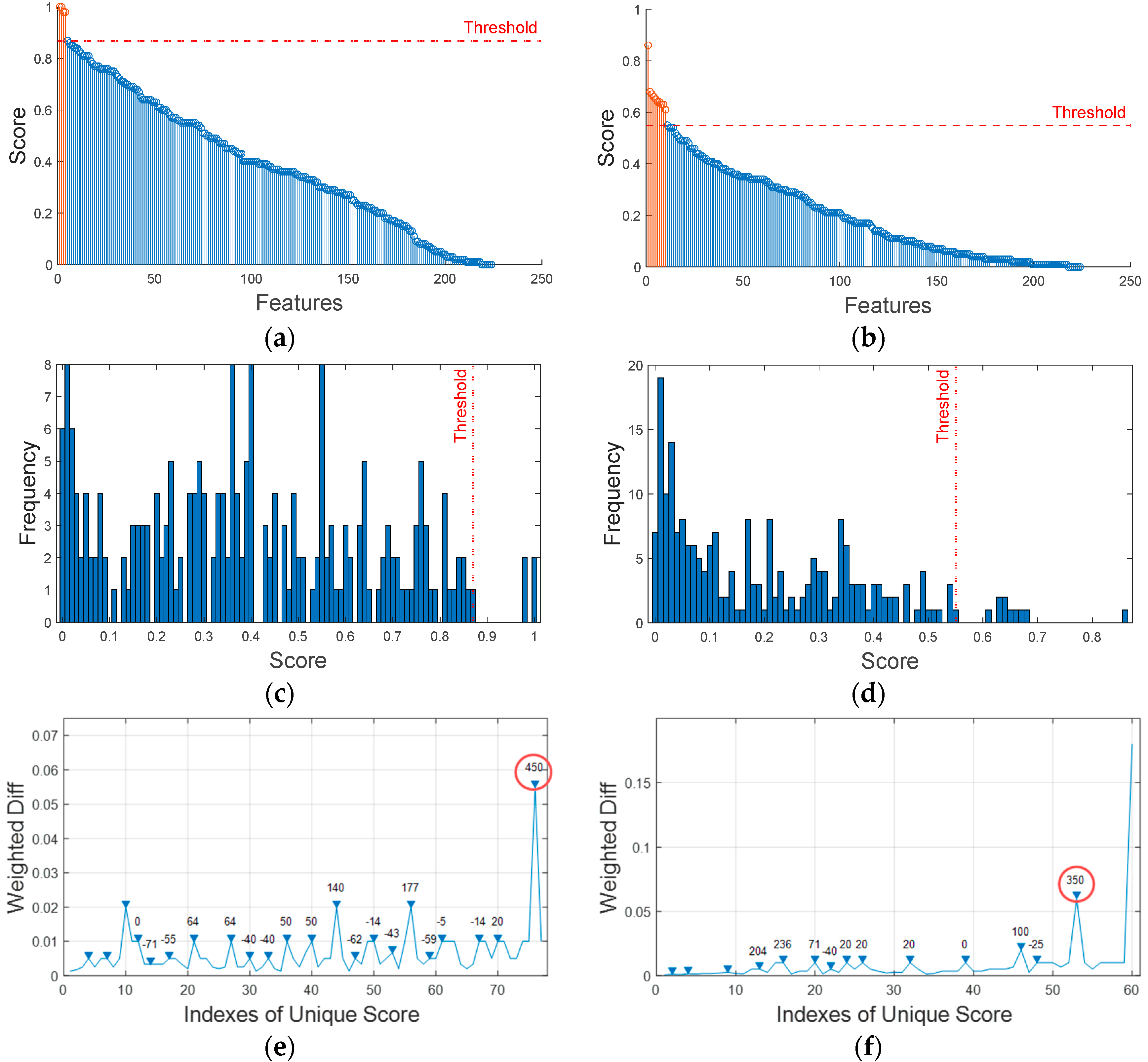
The reason why we need to consider the two metrics together is illustrated in
Figure 3, which shows three cases where, in
Figure 3a,
is low but
is high, in
Figure 3b,
is high but
is low, and in
Figure 3c, both are high. While
Figure 3a shows high separability, it is less useful since it is not consistent with respect to the fault progression. Likewise,
Figure 3b is also less useful due to the large variance, even though the
is high. For this reason, the feature should have higher values in both metrics.
Once the score is obtained for all the features by using Equation (11), the next step is to select a few good features with a high score. While this can be performed arbitrarily, it is achieved in a more objective manner by applying the formula based on the risk priority number (RPN) threshold estimation [
21]. The idea is to divide the whole features into negligible parts, characterized by a gradual change, and the significant part, with a steep increase in score. It was originally developed to select failure modes with highest RPN in the failure mode, effect, and criticality analysis (FMECA), but the authors believe that it is applicable here too. The process begins with setting a unique score and calculating the frequency of each score. The weighted finite difference is defined by dividing the finite difference by the frequency of the unique score as follows:
where
is the index of the unique score. It indicates that the smaller the frequency of the unique score and the larger the finite difference, the larger the weighted finite difference and the greater the variation between the two consecutive values. Then, the peak, namely the local maxima, is obtained to indicate a significant increase in two consecutive unique scores, which is obtained by the following equations:
In the final step, maximum peak is identified and the corresponding score value is used as the threshold to identify the most significant features. Further details will be addressed in the subsequent case study.
Sometimes, the selected features are dependent on each other, that is, show a similar trend in terms of fault severity. An example is that of variance and standard deviation. In this case, the two are highly redundant and just one is enough to conduct the diagnosis. To this end, Pearson correlation is computed for pairs of features combination. If the value is close to 1, remove either one in the resulting features. Finally, one obtains the selection of features for each component that fulfills all the criteria: consistent trend, separability, and independency.
2.3. Model Construction
As mentioned in
Figure 1, two models, ANN and GPR, are utilized for the diagnosis of component health and system performance, respectively. The reason for choosing these models is that they are established techniques, easy, and have been universally applied in the field of fault diagnosis for a long time.
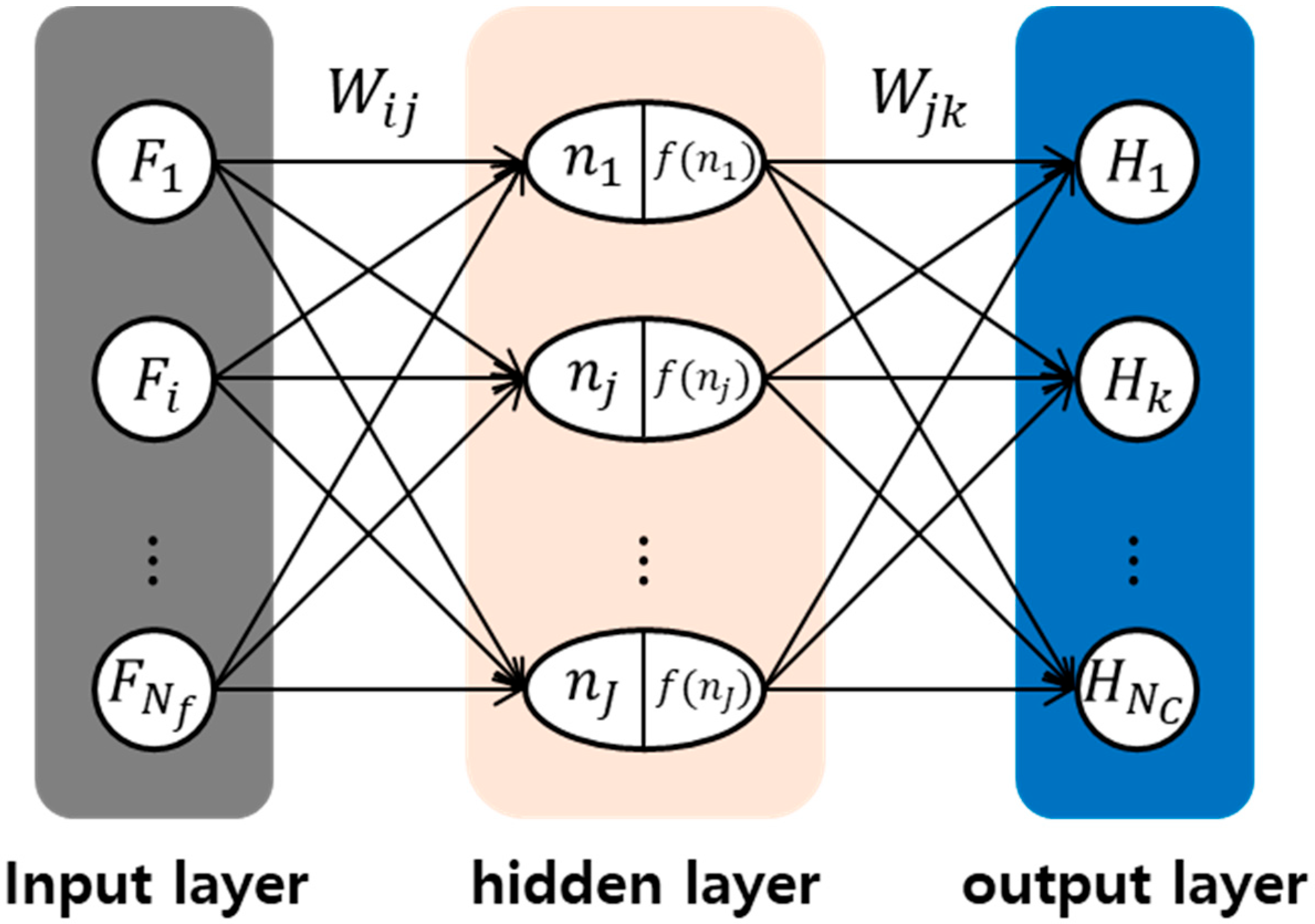
ANN and GPR are employed for the diagnosis of component health and the estimation of system health, respectively. ANN is widely used for data-driven diagnostics, since it can map various input variables onto the output data such as the health degradation. The structure of ANN is composed of an input layer, one or more hidden layers, and an output layer, as shown in
Figure 4 [
22]. Each layer contains neurons (nodes) and weights. In this paper, the set of selected features
with dimension
from the motor signal is used as the input and the degradation level of the components
with dimension
, which is the number of components, is given for the output. The ANN is trained using the data of
and
, acquired for various fault conditions, to determine the optimum weights that represent the nonlinear relationship between the input and output. To enhance the accuracy of ANN, the number of nodes in hidden layers are optimized through k-fold cross-validation.
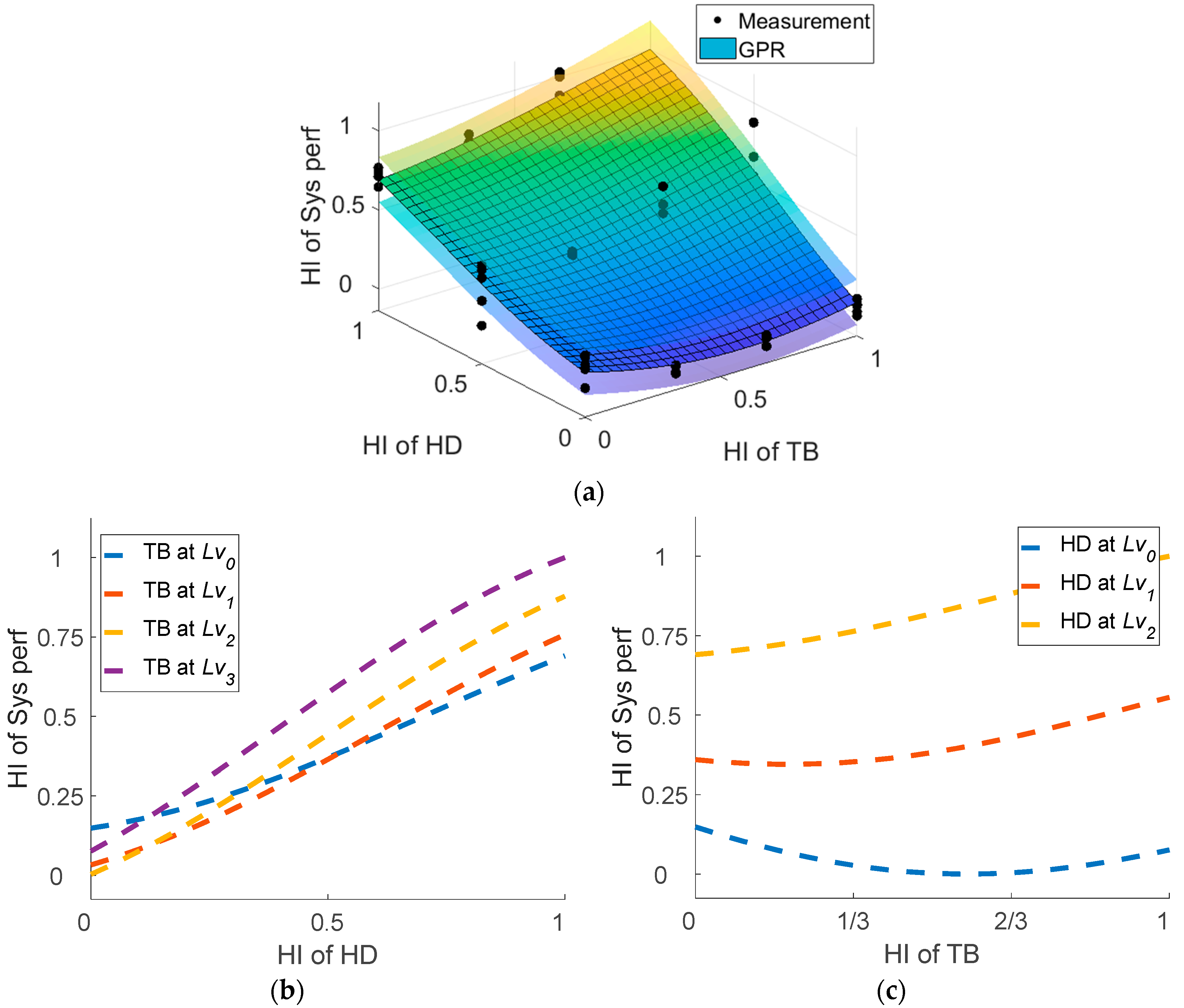
The GPR is used to estimate the system health
based on the fault severity
of the components, which is identified by ANN. Denoting
and
by
with the dimension as the number of components and
, respectively, the GPR is represented by the global function
and the covariance function
as follows [
23,
24,
25]:
where
represents the Gaussian process. Generally, the covariance function consists of two parts,
, where
is the functional part, while
is the noise part, which are given as follows:
where
,
and
are hyperparameters associated with the scaling factor, length-scale, and noise variance that need to be estimated. Generally, these hyperparameters are optimized by maximizing the log-likelihood function, giving the training dataset,
. The advantage of using GPR is that it cannot only represent the nonlinear relationship between input
and output
, but also provide the distribution of the function to quantify the uncertainty of the model or measurement by means of the confidence interval.
5. Conclusions and Future Work
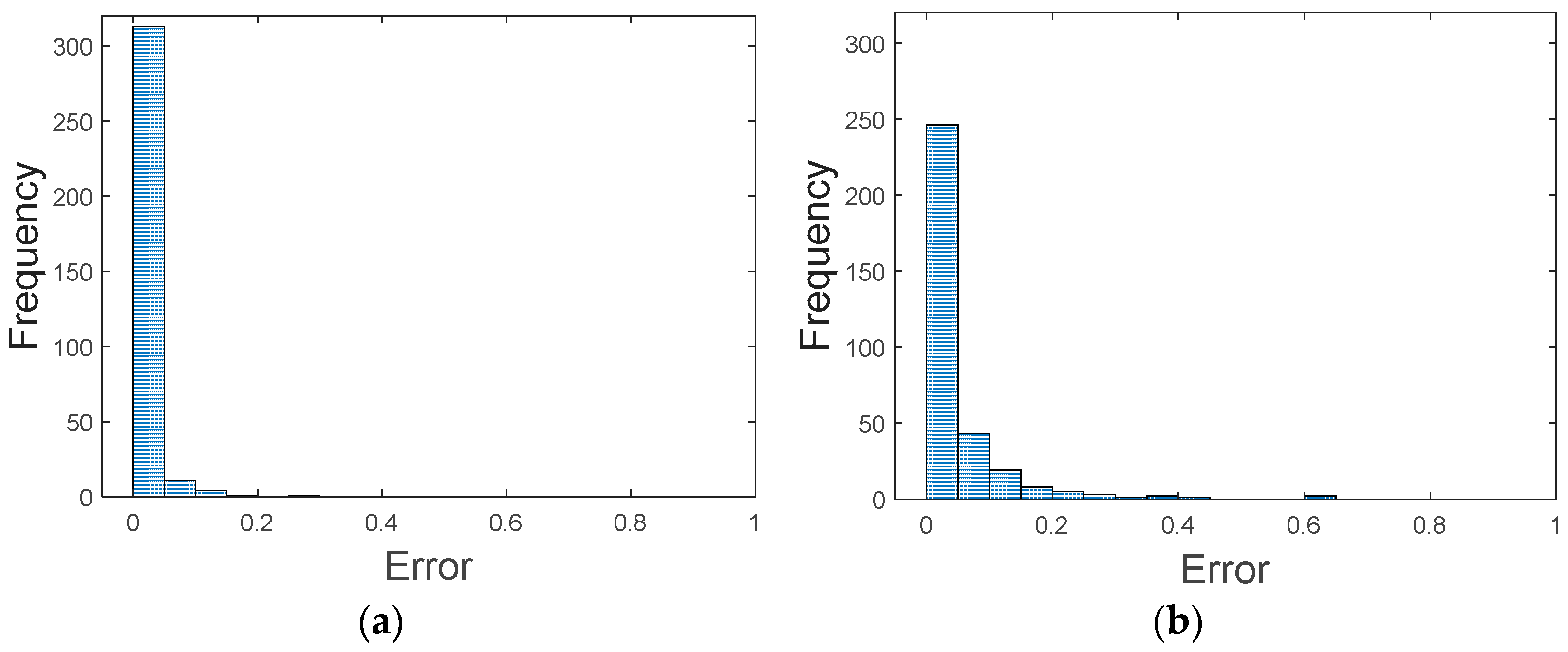
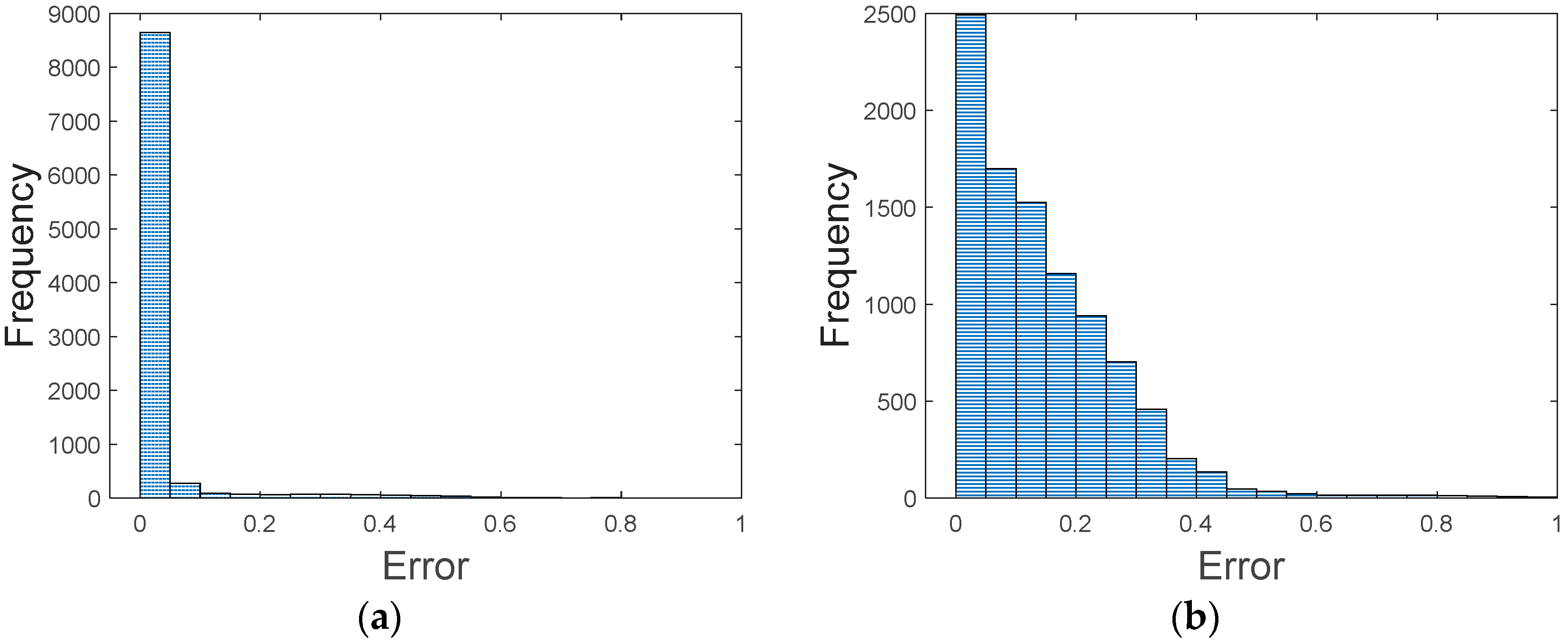
It is crucial to diagnose the condition of industrial robots to prevent losses caused by downtime in manufacturing plants. In this paper, we proposed a methodology to conduct a system-level diagnosis for wafer transfer robots that consists of two critical components (harmonic drive and timing belt), the degradation of which leads to the failure of the system, characterized by end-effector vibration. The procedure is summarized as follows: First, informative features are extracted from the motor control signal through signal processing techniques which apply the WPD for feature extraction and the RPN formula of hybrid score for feature selection. Second, an ANN is established to model the relation between extracted features and the HI of components. The model achieves RMS errors of 0.0275 and 0.0902 for the HD and TB, for the HI in the range of 0 to 1. Third, GPR is applied to build the relationship between HIs of components and the system. Before construction, it is found that the interaction between the two components, the HD and TB, is significant: the F-value 5.38 in ANOVA for the interaction is similar in magnitude to 4.09 for the TB. Finally, the ANN and GPR models are applied to the new robot in operation, in which the current state of health of the two components, as well as the system performance, are estimated, and a maintenance strategy is determined by evaluating how well the system performance is restored by the replacement of each component. Using the example mentioned in
Section 4.4 as an illustration, the HIs of the two components and the system are 0.62, 0.87, and 0.65. After the replacement of each component to a new one, the system HI is restored to 0.04 and 0.45, respectively, which indicates that replacing the HD leads to three times better system health.
The contributions of the proposed methodology can be stated as follows: First, the authors have examined multiple components and their fault severities, which can account for the interaction relationship in degradation between the components and system. Second, motor control signals are exploited, which are acquired automatically during operation with no additional use of sensors. Third, a hybrid score and an RPN-based formula are applied to select the most appropriate features for the diagnosis in a more objective way. Last, but not least, a system-level approach is proposed, which evaluates the state of health of the components, conditional on the system performance, as opposed to the traditional component-level approach. Thanks to this, a proper maintenance policy can be developed to decide which component to replace and how well the system health is restored.
However, several critical challenges remain in the implementation of this study: First, the model development requires costly and time-consuming experiments for fault seeding and operation for a variety of degradation conditions. In this study, only two components with three or four severity levels are considered, which have operated under 12 different conditions. The number of cases will increase exponentially for more components and severity levels, which requires an efficient strategy for the design of experiments. Second, in the fault seeding process, a good domain knowledge is critical, which includes the type of failure modes, ways of fault seeding, and the degree of degradation. Unless this is properly addressed, the result will be significantly different from those in the field, and hence, will be useless. In this study, the artificial faults are based on the literature on robot faults, which have, however, been empirical or intuitive. Third, the proposed model is developed based on a specific operation profile such as a simple round trip of a wafer at a certain speed. If the profile changes or becomes more complex, the resulting features and subsequent ANN and GPR models will be changed accordingly. Since we cannot do this every time the profile changes, a more general strategy is needed to address this issue. Lastly, there is a difference in the sampling rate in the data acquisition of the motor signal between our study and the field, which are 1 kHz and 50 Hz, respectively. Due to issues with data storage and handling, lower sampling rates are used in the field. In this case, a different strategy should be developed, because the frequency band and resolution may be different. Future studies will be performed to overcome these challenges. Towards this objective, we plan to generalize our methodology for a few different operation profiles with lower sampling rates used in the field, and validate its performance.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}