1. Introduction
A knowledge graph (KG) organizes knowledge as a set of interlinked triples, and a triple ((head entity, relation, tail entity), simply represented as (h, r, t)) indicates the fact that two entities have a certain relation. The availability of formalized and rich structured knowledge has emerged as a valuable resource in facilitating various downstream tasks, such as question answering [
1,
2] and recommender systems [
3,
4].
Although KGs such as DBpedia [
5], Freebase [
6], and NELL [
7] contain large amounts of entities, relations, and triples, they are far from complete, which is an urgent issue for their broad application. To address this, researchers have introduced the concept of knowledge graph completion (KGC), which has garnered increasing interest. It utilizes knowledge reasoning techniques to automatically discover new facts based on existing ones in a KG [
8].
Currently, the methods of KGC can be classified into two major categories: (1) One type of method uses explicit reasoning rules. It obtains these rules through inductive learning and then deduces new facts. (2) Another method is based on representation learning instead of directly modeling rules, aiming to learn a distributed embedding for entities and relations and perform generalization in numerical space.
Rule-based reasoning is accurate and can provide interpretability for the inference results. These rules can be hand-crafted by domain experts [
9] or mined from KGs using an inductive algorithm like AMIE [
10]. Traditional methods like expert systems [
11,
12] utilize hard logical rules for making predictions. For example, as shown in
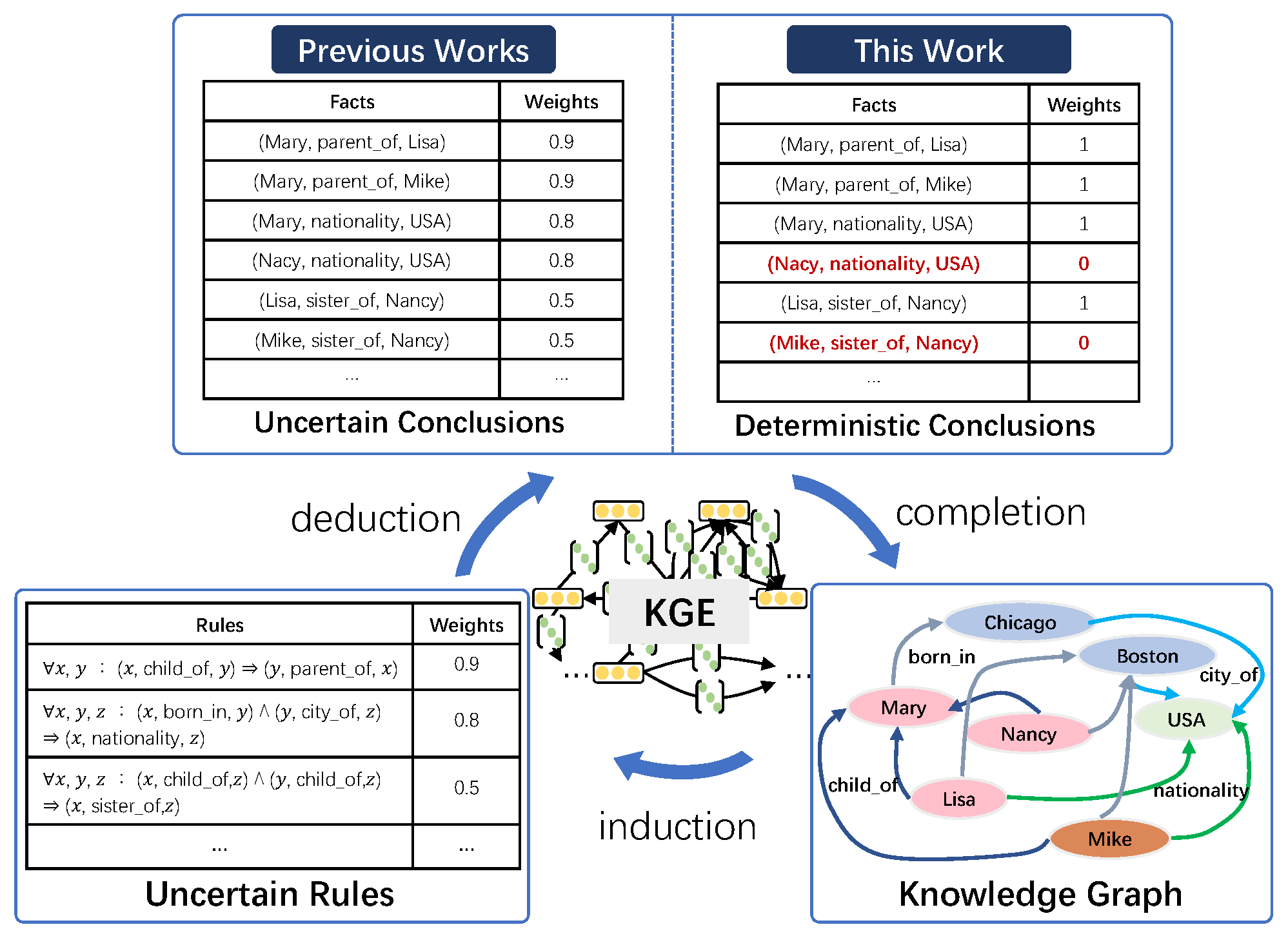
Figure 1, given the logical rule
and the two facts that (Chicago, city_of, USA) and (Mary, born_in, Chicago), we can infer the fact (Mary, nationality, USA). Based on forward reasoning, it is possible to derive numerous new facts (conclusions). However, acquiring sufficient and effective reasoning rules for large-scale KGs can be a challenging and costly task. Additionally, logical rules, in many instances, may be imperfect or even self-contradictory. Therefore, it is essential to effectively model the uncertainty of logical rules.
The methods used to determine knowledge graph embeddings (KGEs) learn how to embed entities and relations into a continuous low-dimensional space [
13,
14]. These embeddings maintain the semantic meaning of entities and relations, facilitating the prediction of missing triples. Additionally, these embeddings can be effectively trained using stochastic gradient descent (SGD). However, it is important to note that this approach does not fully capitalize on logical rules, which are instrumental in compactly encoding domain knowledge and have practical implications in various applications. It is worth mentioning that high-quality embeddings heavily rely on abundant data, making it challenging for these methods to generate meaningful representations for sparse entities [
15,
16].
In fact, both rule-based and embedding-based methods have advantages and disadvantages in the KGC task. Logical rules are accurate and interpretable, while embedding is flexible and computationally efficient. Recently, there has been research on combining the advantages of logical rules and KGEs to achieve more precise knowledge completion. Mixed techniques can infer missing triples effectively by exploiting and modeling uncertain logical rules. Some existing methods aim to learn KGEs and rules iteratively [
16], and some other methods also utilize soft rules or groundings of rules to regularize the learning of KGEs [
17,
18].
The integration of logical rules and knowledge graph embeddings can achieve more efficient and accurate knowledge completion. Current methods model uncertain rules and add soft labels to conclusions by t-norm-based fuzzy logic [
19]. They further utilize the conclusions to perform forward reasoning [
17] or to enhance the KGE [
16]. However, in most KGs, the facts are deterministic. Therefore, we believe that rules are uncertain, but conclusions are deterministic in knowledge reasoning, as shown in
Figure 1; each fact is only absolutely true or false. Previous methods associate each conclusion with a weight derived from the corresponding rule. In contrast, we propose inferring that all conclusions are true (e.g., (Mary, nationality, USA)) or not (e.g., (Mike, sister_of, Nancy)) (the other fact, i.e., (Mike, gender, male), indicates that Mike is not Nancy’s sister) by jointly modeling the deterministic KG and soft rules.
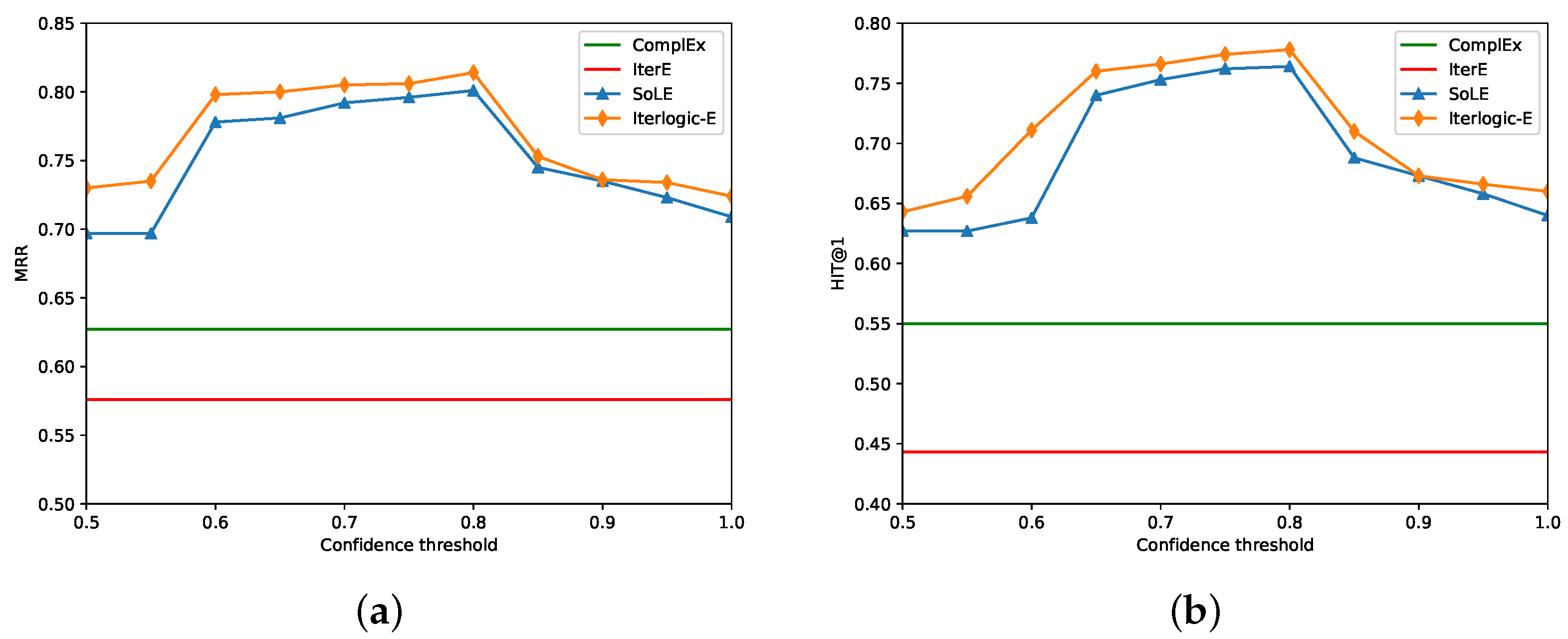
Specifically, we first mine soft rules from the knowledge graph and then infer conclusions as candidate facts. Second, the KG, conclusions, and weighted rules are also used as resources to learn embeddings. Third, by defining deterministic conclusion loss, the conclusion labels are modeled as 0–1 variables, and the confidence loss of a rule is also used to constrain the conclusions. Finally, the embedding learning stage removes the noise in the candidate conclusions, and then the proper conclusions are added back to the original KG. The above steps are performed iteratively. We empirically evaluate the proposed method on public datasets from two real large-scale KGs: DBpedia and Freebase. The experimental results show that our method Iterlogic-E (Iterative using logic rule for reasoning and learning Embedding) achieves state-of-the-art results on multiple evaluation metrics. Compared to the state-of-the-art model, Iterlogic-E also achieves improvements of 2.7%/4.3% in mean reciprocal rank (MRR) and 2.0%/4.0% in HITS@1.
In summary, our main contributions are as follows:
We propose a novel KGC method, Iterlogic-E, which jointly models logical rules and KGs in the framework of a KGE. Iterlogic-E combines the advantages of rules and embeddings in knowledge reasoning. Iterlogic-E models the conclusion labels as 0–1 variables and uses a confidence regularizer to eliminate the uncertain conclusions.
We propose a novel iterative learning paradigm that strikes a good balance between efficiency and scalability. Iterlogic-E not only densifies the KG but can also filters out incorrect conclusions.
Compared to traditional reasoning methods, Iterlogic-E offers better interpretability in determining conclusions. It not only knows why the conclusion holds but also knows which is true and which is false.
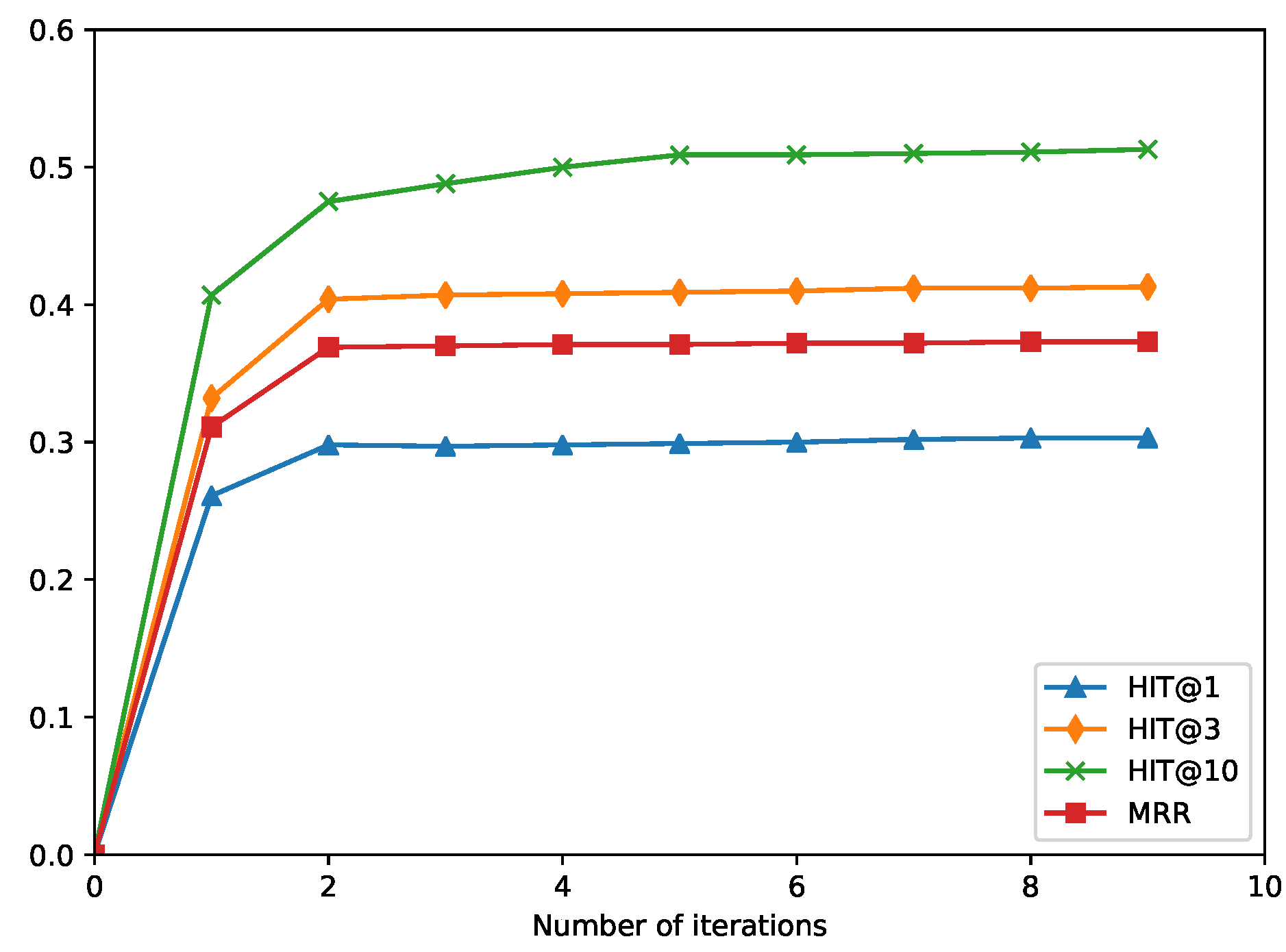
We empirically evaluate the performance of Iterlogic-E with the task of link prediction on multiple benchmark datasets. The experimental results demonstrate that Iterlogic-E can outperform other methods on multiple evaluation metrics. The qualitative analysis confirms that Iterlogic-E exhibits higher robustness for rules with varying confidence levels.
3. The Proposed Method
This section presents our proposed method, Iterlogic-E. We begin by providing a comprehensive overview of our method, which entails the iterative learning process. Subsequently, we delve into the two components of Iterlogic-E: rule mining and reasoning, as well as embedding learning. Finally, we examine the space and time complexity of Iterlogic-E while also discussing its connections to related research [
16,
17,
18].
3.1. Overview
Given a KG
,
,
is a relation and
are entities. As discussed in
Section 1, on the one hand, embedding learning methods do not make full use of logical rules and suffer from data sparsity. On the other hand, high-quality rules are challenging to obtain efficiently and can only cover some facts in KGs. Our goal is to improve the embedding quality by explicitly modeling the reasoned conclusions of logical rules and discarding incorrect conclusions.
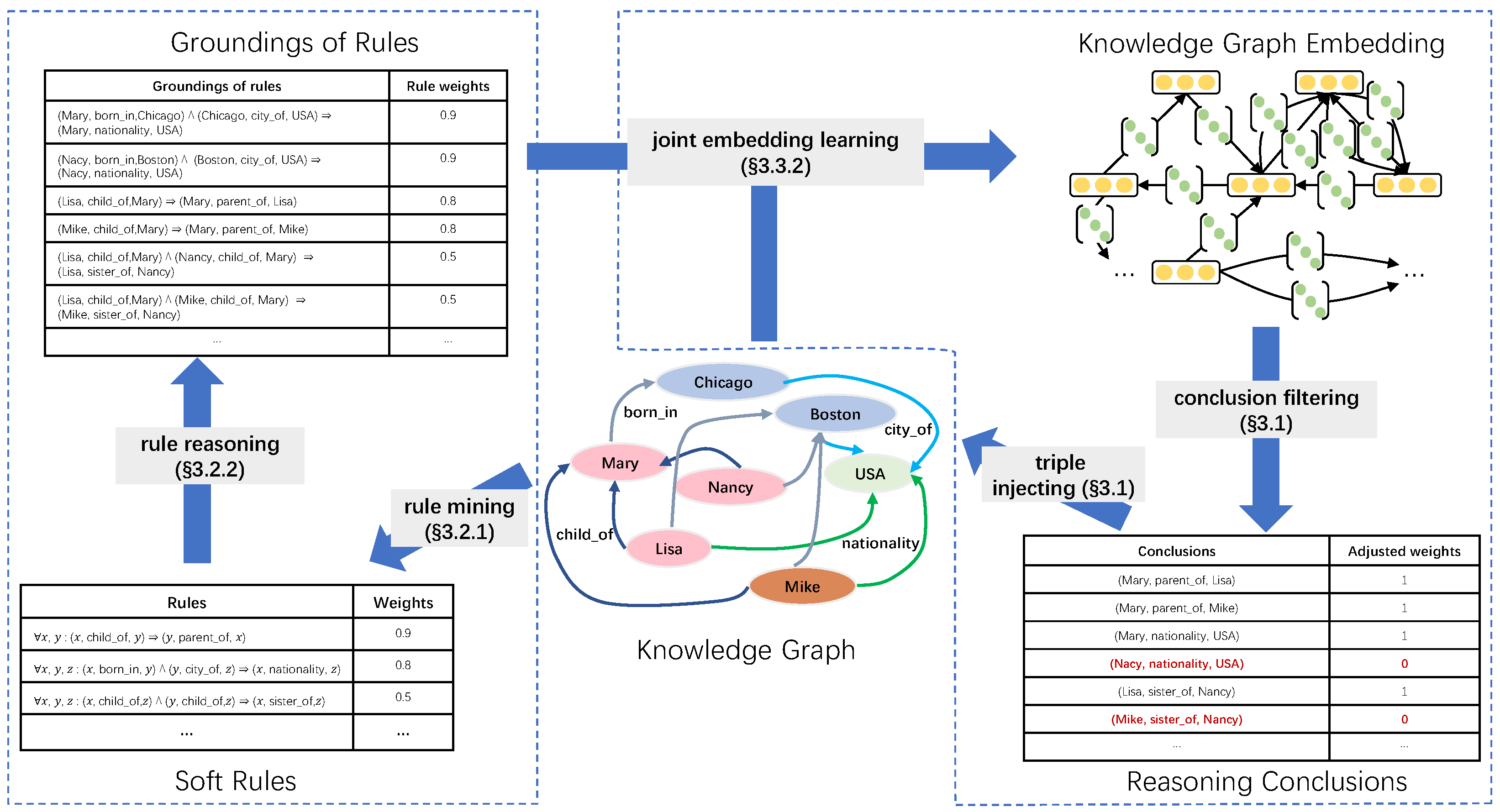
Figure 2 shows the overview of Iterlogic-E given a toy knowledge graph. Iterlogic-E is a general framework that can fuse different KGE models.
The Iterlogic-E approach consists of two iterative steps: rule mining and reasoning, and embedding learning. The first step, rule mining and reasoning, involves two modules: rule mining and rule reasoning. The rule mining module requires input of mining configuration parameters, such as the maximum length of rules and the confidence threshold of rules, in addition to KG triples. Then, it automatically obtains the soft rules from these inputs. The KG triples and the extracted soft rules are input into the rule reasoning module to infer new triples. After that, the new triples are appended to the embedding learning step as candidate conclusions. In the embedding learning step, relations are modeled as a linear mapping operation, and triple plausibility is represented as the correlation between the head and tail entities after the operation. Finally, the incorrect conclusions are filtered out by labeling the conclusions with their scores (In the experiments, we choose the conclusion with a normalized score of more than 0.99 as the true conclusion). The true conclusion will be added back to the original KG triples, and then the rule reasoning module will be performed to start the next cycle of iterative training.
3.2. Rule Mining and Reasoning
The first step is composed of the rule mining module and the rule reasoning module. We introduce these two modules in detail below.
3.2.1. Rule Mining
Soft rules are extracted from the knowledge graph (KG) using the advanced rule mining method AMIE+ [
20]. AMIE+ applies partial closed-world assumption (PCA) confidence to estimate the reliability of a rule since its partial completeness assumption is more suited to real-world KGs. The PCA confidence of a rule
R in a KB is defined as the following formula:
is the body (also called premise) of rule , and the of a rule indicates the number of groundings in the knowledge base that supports the rule. Additionally, AMIE+ defines various restriction types to help extract applicable rules, e.g., the maximum length of the rule. The rule mining module takes as input the KG triples and employs the AMIE+ algorithm to generate soft rules. We execute the rule mining module only once to optimize efficiency, even though the rules could be re-mined in each iteration.
3.2.2. Rule Reasoning
The logical rule set is denoted as
, where
f takes the form
. In this rule,
x,
y, and
z represent variables for different entities, while
,
, and
represent different relations. The left side of the ⇒ symbol represents the premise of the rule, which consists of multiple connected atoms. On the right side, we have a single atom representing the conclusion of the rule. These Hore rules are closed [
25], meaning that the intermediate entity is shared by the continuous relations, and the first and last entities of the premise appear as the head and tail entities of the conclusion. Such rules can provide interpretive insights. A rule’s length is equal to the number of atoms in the premise. For example,
is a length-2 rule. This rule reflects the reality that, most likely, a person’s nationality is the country in which he or she was born. The rule
f has a confidence level of 0.8. The higher the confidence of the rule, the more likely it is to hold.
The reasoning procedure consists of instantiating the rule’s premise and obtaining a large number of fresh conclusion triples. One of the most common approaches is forward chaining, also known as the match–select–act cycle, which works in three-phase cycles. Forward chaining matches the current facts in the KG with all known rule premises to determine which rules can be satisfied in one cycle. Finally, the selected rule’s conclusions are derived, and if the conclusions are not already in the KG, they are added as new facts. This cycle should be repeated until no new conclusions are derived. However, if soft rules are used, forward reasoning will lead to incorrect conclusions. Therefore, we run one reasoning cycle in every iteration.
3.3. Embedding Learning
This section introduces a joint embedding learning approach that allows the embedding model to simultaneously learn from KG triples, conclusion triples, and soft rule confidence. First, we will examine a basic KGE model and describe how to incorporate soft rule conclusions. Finally, we detail the overall training goal.
3.3.1. A Basic KGE Model
Different KGE models have different score functions that aim to obtain a suitable function to map the triple score to a continuous true value in [0, 1], i.e.,
, which indicates the probability that the triple holds. We follow [
17,
18] and choose ComplEx [
26] as a basic KGE model. It is important to note that our proposed framework can be combined with an arbitrary KGE model. Theoretically, using a better base model can continue improving performance. Therefore, we also experiment with RotatE as a base model. Below, we elaborate on the methods of ComplEx and RotatE. ComplEx assumes that the entity and relation embeddings exist in a complex space, i.e.,
and
, where
d is the dimensionality of the complex space. Using plurals to represent entities and relations can better model antisymmetric and symmetric relations (e.g., kinship and marriage) [
26]. Through a multilinear dot product, ComplEx scores every triple. In contrast to ComplEx, RotatE defines the functional mapping induced by each relation
r as an element-wise rotation from the head entity
h to the tail entity
t:
We utilize the
function to extract the real part of a complex value, and ∘ is the Hadmard (or element-wise) product. Additionally, the
function is employed to construct a diagonal matrix from the variable
r. Furthermore, we define
as the conjugate of the variable
t, and
is the
i-th entry of a vector.
where
is the sigmoid function and
is the score function. By minimizing the logistic loss function, ComplEx learns the relation and entity embeddings:
where
is negative triples and
is the label of a triple.
3.3.2. Joint Modeling KG and Conclusions of Soft Rules
To model the conclusion label as a 0–1 variable, based on the current KGE model’s scoring function, we follow ComplEx and use the function
defined in Equation (
2) or Equation (
3) as the scoring function for conclusion triples:
where
is the set of conclusion triples derived from rule
f. Aiming to regularize this scoring function so that it approaches 0 or 1 and to distinguish between true and false conclusions, we use a quadratic function with a symmetry axis of 0.5. Therefore, the conclusion score is the smallest when close to 0 or 1. Therefore, we define the deterministic conclusion loss
as follows:
According to the definition of rule confidence in [
10], the confidence of a rule
f in a KB
is the proportion of true conclusions among the true conclusions and false conclusions. Therefore, we can define the confidence loss of a rule as follows:
where
is the PCA confidence of rule
f. Therefore, the loss of the conclusions of all the rules
can be defined as follows:
where
is the set of all rules. To learn the KGE and rule conclusions at the same time, we minimize the global loss over a soft rule set
and a labeled triple set
(including negative and positive examples). The overall training objective of Iterlogic-E is
where the
function denotes the score function, and
is the Softplus activation function. In Algorithm 1, we detail the embedding learning procedure of our method. We further impose
regularization on embedding
to avoid overfitting. Following [
18,
47], we also imposed nonnegative constraints (NNE) on the entity embedding to learn more effective features.
| Algorithm 1: Iterative learning algorithm of Iterlogic-E |
| | - Input:
Knowledge graph , soft logical rules , the number of iterative learning steps M. - Output:
Relation and entity embeddings ( consists of two matrices: one containing the vector representation of all entities, and the other containing the vector representation of all relations).
|
| 1 | Randomly initialize relation and entity embeddings |
| 2 | for to N do |
| 3 | | |
| 4 | | if n/[N/M] == 0 then |
| 5 | | | Generate a set of conclusions by rule grounding from |
| 6 | | | |
| 7 | | end |
| 8 | | Sample a batch triples from |
| 9 | | Generate negative examples |
| 10 | | |
| 11 | | for each to N do |
| 12 | | | |
| 13 | | | |
| 14 | | end |
| 15 | | Update by gradient backpropagation of Equation (10)
|
| 16 | | |
| 17 | | for each do |
| 18 | | | if then |
| 19 | | | | |
| 20 | | | end |
| 21 | | end |
| 22 | | |
| 23 | end |
| 24 | return |
3.4. Discussion
3.4.1. Complexity
In the representation learning step, relations and entities are represented as complex value vectors, following the approach of ComplEx. This results in a space complexity of , where d represents the dimensionality of the embedding space. The number of relations is denoted as , while the number of entities is denoted as . Each iteration of the learning process has a time complexity of , where and , respectively, represent the number of new conclusions or labeled triples in a batch, as illustrated in Algorithm 1.
Iterlogic-E shares similarities with ComplEx in terms of space and time complexity, as both increase linearly with d. However, the number of new conclusions in a batch is typically much smaller than the number of initial triples, specifically, . Consequently, Iterlogic-E’s time complexity is similar to ComplEx’s, which only requires per iteration.
Considering the efficiency of the rule mining module and practical constraints, such as a confidence threshold higher than 0.7 and a maximum rule length of three, the space and time complexities of the rule grounding stage are insignificant compared to that of the embedding learning stage. Hence, it can be disregarded when evaluating the space and time complexity of Iterlogic-E.
3.4.2. Connection to Related Works
IterE [
16] also uses iterative learning, which defines several types of rules with OWL2. However, IterE does not modify the process of embedding learning and is limited by rules that will yield numerous noisy conclusions. IterE uses a pruning strategy that utilizes traversal and random selection to obtain rules. Furthermore, they only improve the prediction effect of sparse entities but still need to improve on standard datasets. By contrast, Iterlogic-E uses the AMIE+ rule mining system [
20] to mine high-confidence rules, and the quality of the rules obtained in this way is higher because it uses the KG to evaluate the reliability of the rules thoroughly. SoLE enhances KGE by jointly modeling the groundings of rules and facts and directly utilizes uncertain rules for the forward chain without eliminating incorrect grounding.
Moreover, SoLE [
17] uses t-norm-based fuzzy logic [
19] to model grounding, significantly increasing the time complexity. Our proposed method avoids the abovementioned problems without increasing the number of parameters. SLRE [
18] uses rule-based regularization that merely enforces the relation to satisfying constraints introduced by soft rules. However, it does not use rules for reasoning and cannot benefit from the interpretability and accuracy advantages. In addition, SLRE has strict requirements on the form of the rules, while our method can utilize various forms of rules more simply and flexibly via the rule reasoning module.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



