
Application of Machine Learning Methods to Assess Filtration Properties of Host Rocks of Uranium Deposits in Kazakhstan

 , ,
, ,  and
and
Abstract
:1. Introduction
- Accurate determination of the lithological composition of the host rocks and the depth of permeable and impermeable strata using geophysical methods;
- Assessment of filtration properties of host rocks, for the correct assessment of recoverable reserves and production planning.
2. Related Works
3. Proposed Method
- Feature selection and dataset generation;
- Training and tuning machine learning models;
- Evaluation of results using standard quality metrics.
3.1. Data Preparation
3.2. Machine Learning Models
4. Data and Results
5. Conclusions
- Only the AR curve data were used; if the AR data were poorly recorded, the results would be unreliable.
- When interpreting data from acidified blocks, where the properties of rocks were distorted by the action of acid, the values of the AR turned out to be underestimated, and therefore, the calculation of the filtration properties was not correct.
- Since a downhole tool with a distance between electrodes of 1 m was used to record AR logs in the fields of Kazakhstan, it was possible to reliably measure the average resistivity value only for lithological layers with a thickness of more than 2 m. Therefore, the adopted technique was not suitable for thin intervals (<2 m).
- It was not applicable to fields where exploration had been carried out for a long time, and not all the necessary data were available.
- The learning process depended on the lithological code set by the expert, which could be wrong, especially in the case of acidified blocks.
- Exploring the possibility of transferring the trained model to similar fields for which there are no data required for training;
- Improving the reliability of determining the lithological code of the rock during lithological classification;
- Automatic identification of zones of technological acidification by the characteristic distortion of the AR curve.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Uranium Reserves, Which Countries Have the Largest Reserves? Available online: https://www.energy.com (accessed on 28 June 2023).
- World Nuclear Association. “Recent Uranium Production”, The Nuclear Fuel Report: Expanded Summary—Global Scenarios for Demand and Supply Availability 2019–2040. 2020. Available online: https://world-nuclear.org/getmedia/b488c502-baf9-4142-8d12-42bab97593c3/nuclear-fuel-report-2019-expanded-summary-final.pdf.aspx (accessed on 30 June 2023).
- International Energy Agency (IEA). Key World Energy Statistics. Also Available on Smartphones and Tablets. 2016. Available online: https://www.ourenergypolicy.org/wp-content/uploads/2016/09/KeyWorld2016.pdf (accessed on 30 June 2023).
- Mukhamediev, R.I.; Kuchin, Y.I.; Yakunin, K.O.; Mukhamedieva, E.L.; Kostarev, S.V. Preliminary results of the assessment of lithological classifiers for uranium deposits of the infiltration type. Cloud Sci. 2020, 7, 258–272. [Google Scholar]
- Guidelines for Determining the Coefficient of Filtration of Water-Bearing Rocks by Experimental Pumping, Energoizdat. 1981. Available online: https://www.geokniga.org/books/17383 (accessed on 15 June 2023).
- Mukhamediev, R.I.; Popova, Y.; Kuchin, Y.; Zaitseva, E.; Kalimoldayev, A.; Symagulov, A.; Levashenko, V.; Abdoldina, F.; Gopejenko, V.; Yakunin, K.; et al. Review of Artificial Intelligence and Machine Learning Technologies: Classification, Restrictions, Opportunities and Challenges. Mathematics 2022, 10, 2552. [Google Scholar]
- Mukhamediev, R.I.; Symagulov, A.; Kuchin, Y.; Yakunin, K.; Yelis, M. From classical machine learning to deep neural networks: A simplified scientometric review. Appl. Sci. 2021, 11, 5541. [Google Scholar] [CrossRef]
- Merembayev, T.; Yunussov, R.; Yedilkhan, A. Machine learning algorithms for stratigraphy classification on uranium deposits. Procedia Comput. Sci. 2019, 150, 46–52. [Google Scholar] [CrossRef]
- Cracknell, M.J. Machine Learning for Geological Mapping: Algorithms and Applications. Ph.D. Thesis, University of Tasmania, Hobart, TAS, Australia, 2014. [Google Scholar]
- Sun, T.; Li, H.; Wu, K.; Chen, F.; Zhu, Z.; Hu, Z. Data-driven predictive modeling of mineral prospectivity using machine learning and deep learning methods: A case study from southern Jiangxi Province, China. Minerals 2020, 10, 102. [Google Scholar] [CrossRef]
- Dogan, A.; Birant, D.; Kut, A. Multi-target regression for quality prediction in a mining process. In Proceedings of the 2019 4th International Conference on Computer Science and Engineering (UBMK), Samsun, Turkey, 11–15 September 2019; pp. 639–644. [Google Scholar]
- Deng, C.; Pan, H.; Fang, S.; Konate, A.A.; Qin, R. Support vector machine as an alternative method for lithology classification of crystalline rocks. J. Geophys. Eng. 2017, 14, 341–349. [Google Scholar] [CrossRef]
- Kumar, C.; Chatterjee, S.; Oommen, T.; Guha, A. Automated lithological mapping by integrating spectral enhancement techniques and machine learning algorithms using AVIRIS-NG hyperspectral data in Gold-bearing granite-greenstone rocks in Hutti, India. Int. J. Appl. Earth Obs. Geoinf. 2020, 86, 102006. [Google Scholar]
- Cracknell, M.J.; Reading, A.M. Geological mapping using remote sensing data: A comparison of five machine learning algorithms, their response to variations in the spatial distribution of training data and the use of explicit spatial information. Comput. Geosci. 2014, 63, 22–33. [Google Scholar]
- Harris, J.R.; Grunsky, E.C. Predictive lithological mapping of Canada’s North using Random Forest classification applied to geophysical and geochemical data. Comput. Geosci. 2015, 80, 9–25. [Google Scholar] [CrossRef]
- Kuchin, Y.I.; Mukhamediev, R.I.; Yakunin, K.O. One method of generating synthetic data to assess the upper limit of machine learning algorithms performance. Cogent Eng. 2020, 7, 1718821. [Google Scholar] [CrossRef]
- Khan, H.; Srivastav, A.; Kumar Mishra, A.; Anh Tran, T. Machine learning methods for estimating permeability of a reservoir International. J. Syst. Assur. Eng. Manag. 2022, 13, 2118–2131. [Google Scholar]
- Wong, P.M.; Henderson, D.J.; Brooks, L.J. Reservoir permeability determination from well log data using artificial neural networks: An example from the Ravva field, offshore India. In Proceedings of the Petroleum Development under Challenging Environments (with Special Emphasis on Gas), Kuala Lumpur, Malaysia, 14–16 April 1997; pp. 149–155. [Google Scholar]
- Matinkia, M.; Hashami, R.; Mehrad, M.; Hajsaeedi, M.R.; Velayati, A. Prediction of permeability from well logs using a new hybrid machine learning algorithm. Petroleum 2023, 9, 108–123. [Google Scholar] [CrossRef]
- Rezaee, M.R.; Jafari, A.; Kazemzadeh, E. Relationships between permeability, porosity and pore throat size in carbonate rocks using regression analysis and neural networks. J. Geophys. Eng. 2006, 3, 370–376. [Google Scholar] [CrossRef]
- Lim, J.S. Reservoir properties determination using fuzzy logic and neural networks from well data in offshore Korea. J. Pet. Sci. Eng. 2005, 49, 182–192. [Google Scholar] [CrossRef]
- Antoniuk, V.; Bezrodna, I.; Petrokushyn, O. Multiple regressions and ann techniques to predict permeability from pore structure for terrigenous reservoirs, west-shebelynska area Monitoring. Eur. Assoc. Geosci. Eng. 2019, 2019, 1–5. [Google Scholar]
- Elkatatny, S.; Mahmoud, M.; Tariq, Z.; Abdulraheem, A. New insights into the prediction of heterogeneous carbonate reservoir permeability from well logs using artificial intelligence network. Neural Comput. Appl. 2018, 30, 2673–2683. [Google Scholar] [CrossRef]
- Fajana, A.O.; Ayuk, M.A.; Enikanselu, P.A. Application of multilayer perceptron neural network and seismic multi-attribute transforms in reservoir characterization of Pennay field, Niger Delta. J. Pet. Explor. Prod. Technol. 2019, 9, 31–49. [Google Scholar] [CrossRef]
- Ahmadi, M.A.; Ahmadi, M.R.; Hosseini, S.M.; Ebadi, M. Connectionist model predicts the porosity and permeabil-ity of petroleum reservoirs by means of petro-physical logs: Application of artificial intelligence. J. Pet. Sci. Eng. 2014, 123, 183–200. [Google Scholar] [CrossRef]
- Talebkeikhah, M.; Sadeghtabaghi, Z.; Shabani, M. A comparison of machine learning approaches for prediction of permeability using well log data in the hydrocarbon reservoirs. J. Hum. Earth Future 2021, 2, 82–99. [Google Scholar] [CrossRef]
- Zhong, Z.; Carr, T.R.; Wu, X.; Wang, G. Application of a convolutional neural network in permeability prediction: A case study in the Jacksonburg-Stringtown oil field, West Virginia, USA. Geophysics 2019, 84, 363–373. [Google Scholar] [CrossRef]
- Kanfar, R.; Shaikh, O.; Yousefzadeh, M.; Mukerji, T. Real-time well log prediction from drilling data using deep learning. In Proceedings of the International Petroleum Technology Conference, Dhahran, Saudi Arabia, 13 January 2020. [Google Scholar]
- Viggen, E.M.; Merciu, I.A.; Løvstakken, L.; Måsøy, S.E. Automatic interpretation of cement evaluation logs from cased boreholes using supervised deep neural networks. J. Pet. Sci. Eng. 2020, 195, 107539. [Google Scholar] [CrossRef]
- Romanenkova, E.; Rogulina, A.; Shakirov, A.; Stulov, N.; Zaytsev, A.; Ismailova, L.; Kovalev, D.; Katterbauer, K.; AlShehri, A. Similarity learning for wells based on logging data. J. Pet. Sci. Eng. 2022, 215, 110690. [Google Scholar] [CrossRef]
- Du, S.; Wang, R.; Wei, C.; Wang, Y.; Zhou, Y.; Wang, J.; Song, H. The connectivity evaluation among wells in reservoir utilizing machine learning methods. IEEE Access 2020, 8, 47209–47219. [Google Scholar] [CrossRef]
- Sudakov, O.; Burnaev, E.; Koroteev, D. Driving digital rock towards machine learning: Predicting permeability with gradient boosting and deep neural networks. Comput. Geosci. 2019, 127, 91–98. [Google Scholar] [CrossRef]
- Physical Basis for Determining the Lithological and Filtration Properties of Rocks of the Productive Horizon. 2018. Available online: https://ozlib.com/832945/tehnika/fizicheskie_osnovy_metoda (accessed on 10 July 2023).
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3149–3157. [Google Scholar]
- Al Daoud, E. Comparison between XGBoost, LightGBM and CatBoost using a home credit dataset. Int. J. Comput. Inf. Eng. 2019, 13, 6–10. [Google Scholar]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Galushkin, A.I. Theory of Neural Networks; Hotline-Telecom; Springer: Berlin/Heidelberg, Germany, 2010; p. 496. [Google Scholar]
- Yu, H.F.; Huang, F.L.; Lin, C.J. Dual coordinate descent methods for logistic regression and maximum entropy models. Mach. Learn. 2011, 85, 41–75. [Google Scholar] [CrossRef]
- Santosa, F.; Symes, W. Linear inversion of band-limited reflection seismograms. SIAM J. Sci. Stat. Comput. 1986, 7, 1307–1330. [Google Scholar] [CrossRef]
- Tikhonov, A.N.; Goncharsky, A.V.; Stepanov, V.V.; Yagola, A.G.; Tikhonov, A.N.; Goncharsky, A.V.; Yagola, A.G. Numerical Methods for the Approximate Solution of Ill-Posed Problems on Compact Sets; Springer: Dordrecht, The Netherlands, 1995; pp. 65–79. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Applications to nonorthogonal problems. Technometrics 1970, 12, 69–82. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Mukhamediev, R.I.; Kuchin, Y.; Amirgaliyev, Y.; Yunicheva, N.; Muhamedijeva, E. Estimation of Filtration Properties of Host Rocks in Sandstone-Type Uranium Deposits Using Machine Learning Methods. IEEE Access 2022, 10, 18855–18872. [Google Scholar] [CrossRef]
- Zaitseva, E.; Levashenko, V. Construction of a reliability structure function based on uncertain data. IEEE Trans. Reliab. 2016, 65, 1710–1723. [Google Scholar] [CrossRef]




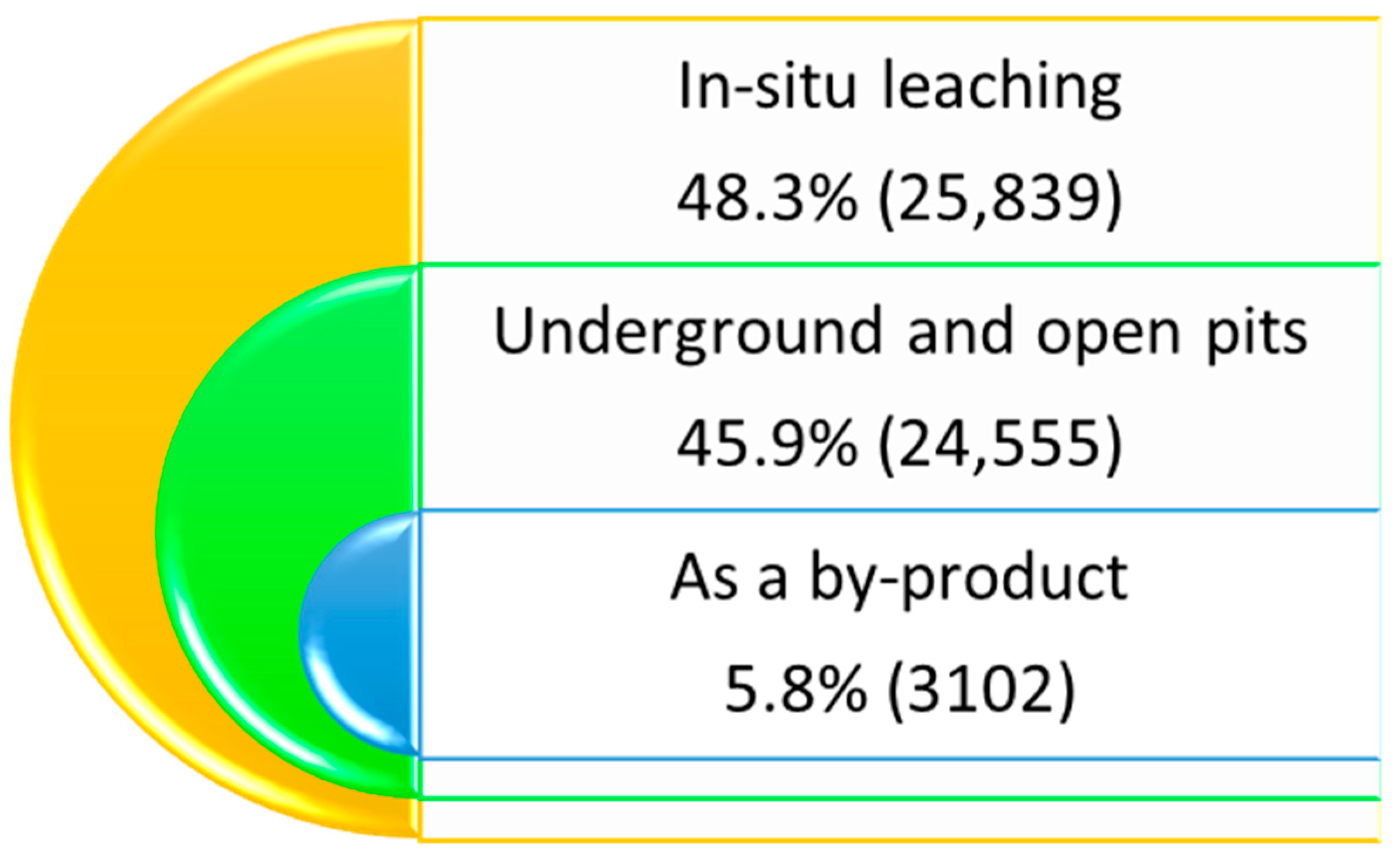{kind=link}
{kind=link}
{kind=link}
| Regression Model | Abbreviation | Method | References |
|---|---|---|---|
| XGBoost | XGB | Ensemble learning method based on the gradient boosted trees algorithm. | [35] |
| LightGBM | LGBM | Ensemble learning method based on the gradient boosted trees algorithm. | [36,37,38] |
| Random forest | RF | Ensemble learning method based on bagging technique. | [39] |
| Support vector machines | SVM | Method is based on the kernel trick. | [40] |
| Artificial neural network | ANN | Feed forward neural network. | [41,42] |
| Linear regression | LR | Modeling impact of independent variables to target variable based on linear approach. | [43] |
| Lasso regression | Lasso | Based on the use of such a regularization mechanism that not only helps in reducing over-fitting but can help in feature selection. | [44] |
| Ridge regression | Ridge | A regularization mechanism is used to prevent over-fitting. | [45] |
| Elastic net | elasticnet | Hybrid of ridge regression and lasso regularization. | [46] |
| Evaluation Index | Equation | Explanation |
|---|---|---|
| Mean absolute error | where n is the sample size; is the actual value of the target variable for the i-th sample; is the estimated value for the i-th sample. | |
| Mean squared error | ||
| Determination coefficient | ||
| Linear correlation coefficient (or Pearson correlation coefficient) | where . |
| Input Data | Regressor_Name | MAE | MSE | R2 | R | Duration |
|---|---|---|---|---|---|---|
| AR | XGB | 3.432 | 21.94 | 0.562 | 0.759 | 0.557 |
| RF | 3.519 | 22.96 | 0.541 | 0.739 | 0.320 | |
| Lasso | 4.666 | 28.84 | 0.423 | 0.723 | 0.000 | |
| LR | 3.786 | 23.18 | 0.537 | 0.733 | 0.016 | |
| elasticnet | 6.289 | 50.75 | −0.014 | 0.000 | 0.000 | |
| LGBM | 3.397 | 19.81 | 0.604 | 0.780 | 0.157 | |
| Ridge | 3.488 | 21.57 | 0.569 | 0.760 | 0.010 | |
| SVM | 3.613 | 25.68 | 0.487 | 0.193 | 0.000 | |
| MLP | 3.999 | 23.88 | 0.523 | 0.736 | 0.495 | |
| SP | XGB | 6.4580 | 63.01 | 0.259 | 0.172 | 0.731 |
| RF | 6.5580 | 75.65 | −0.312 | 0.036 | 0.357 | |
| Lasso | 6.2890 | 50.75 | 0.386 | 0.000 | 0.000 | |
| LR | 6.2570 | 49.30 | 0.415 | 0.277 | 0.000 | |
| elasticnet | 6.2890 | 50.75 | 0.386 | 0.000 | 0.000 | |
| LGBM | 6.2600 | 50.60 | 0.389 | 0.118 | 0.151 | |
| Ridge | 6.4590 | 55.56 | 0.289 | 0.104 | 0.010 | |
| SVM | 6.9040 | 81.00 | −0.419 | 0.171 | 0.000 | |
| MLP | 7.5120 | 80.91 | −0.217 | −0.229 | 0.569 | |
| AR + SP | XGB | 3,780 | 25.86 | 0.509 | 0.715 | 0.406 |
| RF | 4.449 | 33.01 | 0.373 | 0.724 | 0.490 | |
| Lasso | 5.305 | 38.06 | 0.277 | 0.757 | 0.000 | |
| LR | 4.627 | 33.40 | 0.365 | 0.770 | 0.000 | |
| elasticnet | 6.809 | 60.94 | −0.158 | 0.000 | 0.000 | |
| LGBM | 4.420 | 30.97 | 0.412 | 0.738 | 0.160 | |
| Ridge | 5,770 | 80.78 | −0.535 | 0.490 | 0.020 | |
| SVM | 6.554 | 58.63 | −0.114 | 0.178 | 0.000 | |
| MLP | 4,870 | 34.74 | 0.340 | 0.708 | 0.547 | |
| AR + lito code | XGB | 2.976 | 15.93 | 0.682 | 0.829 | 0.709 |
| RF | 2.964 | 15.77 | 0.665 | 0.829 | 0.344 | |
| Lasso | 4.666 | 28.84 | 0.423 | 0.723 | 0.000 | |
| LR | 3.385 | 18.48 | 0.631 | 0.799 | 0.000 | |
| elasticnet | 6.289 | 50.75 | −0.014 | 0.000 | 0.000 | |
| LGBM | 2.875 | 14.52 | 0.710 | 0.845 | 0.149 | |
| Ridge | 3.196 | 25.24 | 0.495 | 0.728 | 0.010 | |
| SVM | 3.593 | 23.48 | 0.531 | 0.254 | 0.000 | |
| MLP | 3,250 | 18.12 | 0.638 | 0.800 | 0.559 | |
| SP + lito code | XGB | 4,801 | 36.85 | 0.300 | 0.551 | 0.425 |
| RF | 5.013 | 41.81 | 0.206 | 0.535 | 0.320 | |
| Lasso | 6.918 | 63.00 | −0.197 | −0.033 | 0.000 | |
| LR | 5.208 | 39.53 | 0.249 | 0.587 | 0.000 | |
| elasticnet | 6.809 | 60.94 | −0.158 | 0.000 | 0.000 | |
| LGBM | 4,880 | 36.26 | 0.311 | 0.601 | 0.175 | |
| Ridge | 5,883 | 119.05 | −1.262 | 0.229 | 0.010 | |
| SVM | 6.140 | 60.65 | −0.152 | 0.235 | 0.000 | |
| MLP | 6.380 | 62.02 | −0.178 | −0.271 | 0.573 | |
| AR+SP+ lito code | XGB | 3.538 | 22.084 | 0.580 | 0.764 | 0.453 |
| RF | 4.032 | 27.889 | 0.470 | 0.754 | 0.496 | |
| Lasso | 5.305 | 38.055 | 0.277 | 0.757 | 0.016 | |
| LR | 4.188 | 26.522 | 0.496 | 0.806 | 0.000 | |
| elasticnet | 6.809 | 60.940 | −0.158 | 0.000 | 0.000 | |
| LGBM | 3.856 | 25.013 | 0.525 | 0.781 | 0.165 | |
| Ridge | 5.637 | 96.590 | −0.835 | 0.439 | 0.020 | |
| SVM | 6.366 | 55.389 | −0.052 | 0.154 | 0.000 | |
| MLP | 4.538 | 31.637 | 0.399 | 0.726 | 0.569 | |
| Current method | 13.89 | 192.93 | 0.32 | 0.584 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kuchin, Y.; Mukhamediev, R.; Yunicheva, N.; Symagulov, A.; Abramov, K.; Mukhamedieva, E.; Zaitseva, E.; Levashenko, V. Application of Machine Learning Methods to Assess Filtration Properties of Host Rocks of Uranium Deposits in Kazakhstan. Appl. Sci. 2023, 13, 10958. https://doi.org/10.3390/app131910958
Kuchin Y, Mukhamediev R, Yunicheva N, Symagulov A, Abramov K, Mukhamedieva E, Zaitseva E, Levashenko V. Application of Machine Learning Methods to Assess Filtration Properties of Host Rocks of Uranium Deposits in Kazakhstan. Applied Sciences. 2023; 13(19):10958. https://doi.org/10.3390/app131910958
Chicago/Turabian StyleKuchin, Yan, Ravil Mukhamediev, Nadiya Yunicheva, Adilkhan Symagulov, Kirill Abramov, Elena Mukhamedieva, Elena Zaitseva, and Vitaly Levashenko. 2023. "Application of Machine Learning Methods to Assess Filtration Properties of Host Rocks of Uranium Deposits in Kazakhstan" Applied Sciences 13, no. 19: 10958. https://doi.org/10.3390/app131910958
APA StyleKuchin, Y., Mukhamediev, R., Yunicheva, N., Symagulov, A., Abramov, K., Mukhamedieva, E., Zaitseva, E., & Levashenko, V. (2023). Application of Machine Learning Methods to Assess Filtration Properties of Host Rocks of Uranium Deposits in Kazakhstan. Applied Sciences, 13(19), 10958. https://doi.org/10.3390/app131910958