
All-Year Dropout Prediction Modeling and Analysis for University Students

Abstract
:1. Introduction
2. Related Works
2.1. The Contribution Factors of Student Dropout
2.2. Student Dropout Prediction
3. Methodology
3.1. Data Description
3.2. Data Preprocessing and Feature Generation
- Mean value-based feature extraction approach. This method calculates the longitudinal average of each feature in the student data. For example, if a student in the 4th semester has four records of the number of scholarship awards, the mean value-based feature extraction approach calculates the mean of these four scholarship awards;
- Median value-based feature extraction approach. This method calculates the longitudinal median of each feature in the student data;
- Last semester data-based feature extraction approach. This method considers only the last valid semester data in the student data;
- First-semester data-based feature extraction approach. This method considers only the first valid semester data in the student data.
3.3. Machine Learning Models Used
- Four tree-based models: Decision Tree [38], which draws the different solutions of the decision as branches of the tree and uses the branching and pruning method to find the optimal solution. Random Forest [18], which consists of a bootstrap aggregation method that combines the predictions of many trees. LightGBM [39], which uses histogram-based algorithms and bucket continuous feature (attribute) values into discrete bins. XGBoost [17], which provides a parallel tree boosting to solve problems quickly
- One linear model: Logistic regression [40], which is a linear model for classification often used as a baseline model;
- One Kernel-based model: Support Vector Machine [41], which transforms a linearly inseparable problem in the original feature space into a linearly separable problem in a high-dimensional feature space.
3.4. SMOTE
4. Results and Discussion
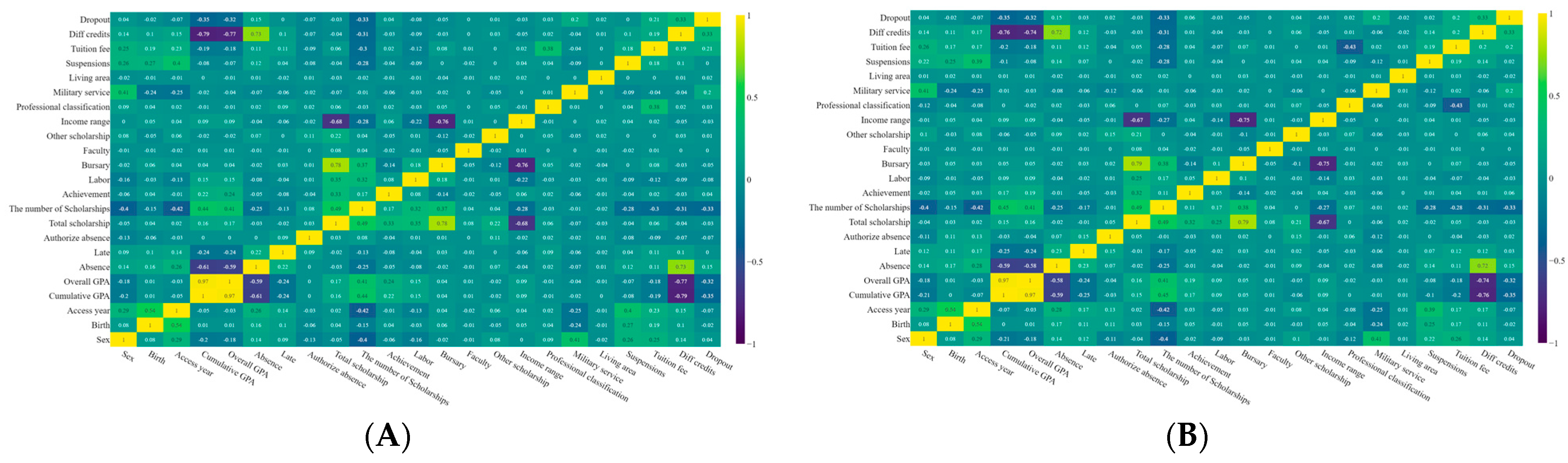
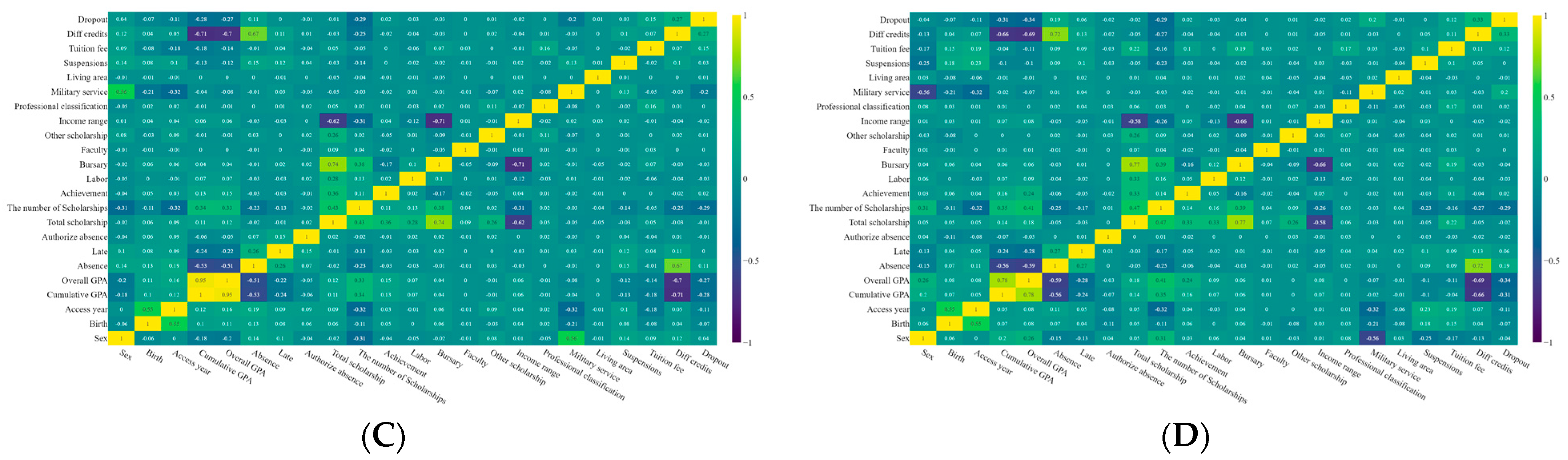
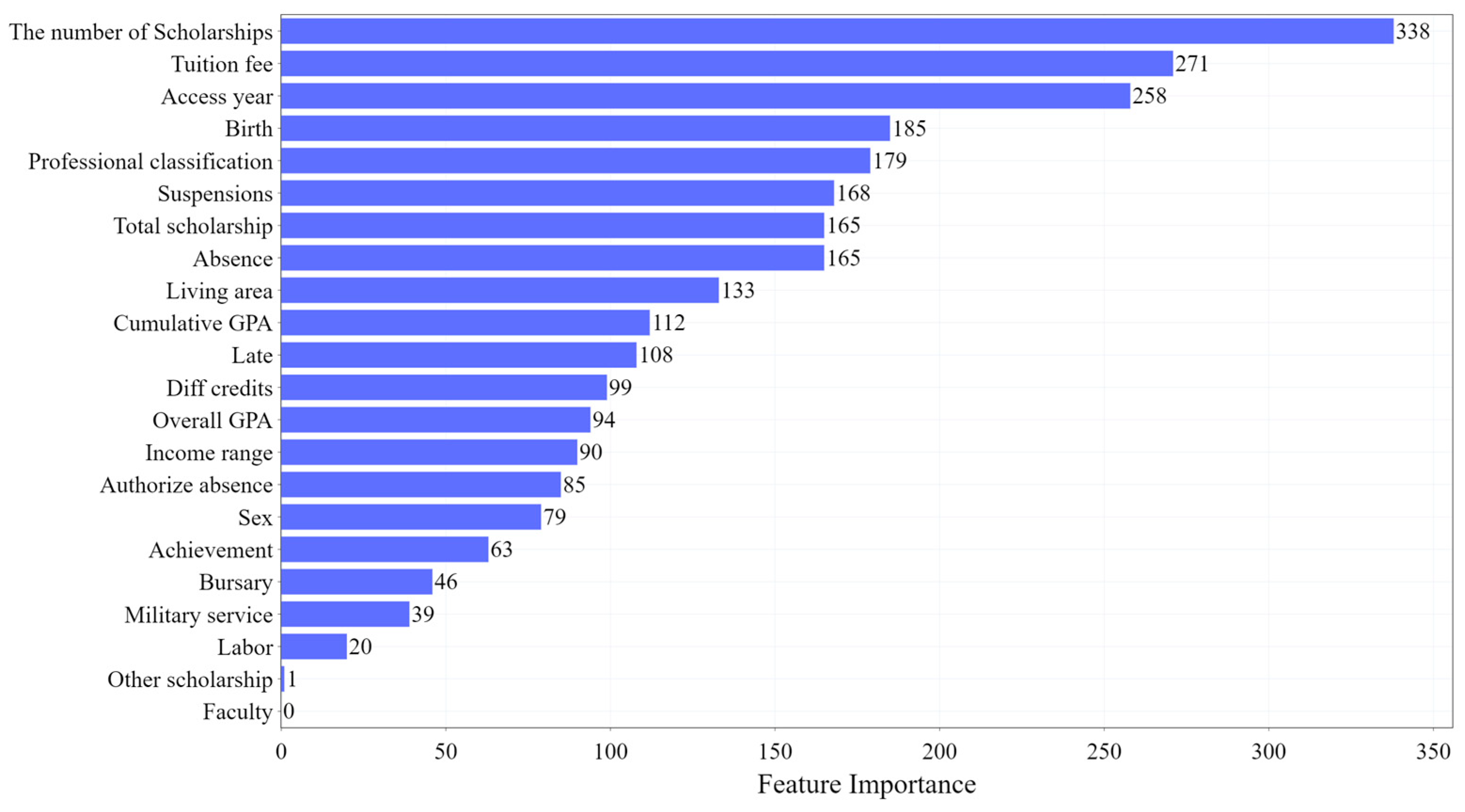
4.1. Feature Analysis
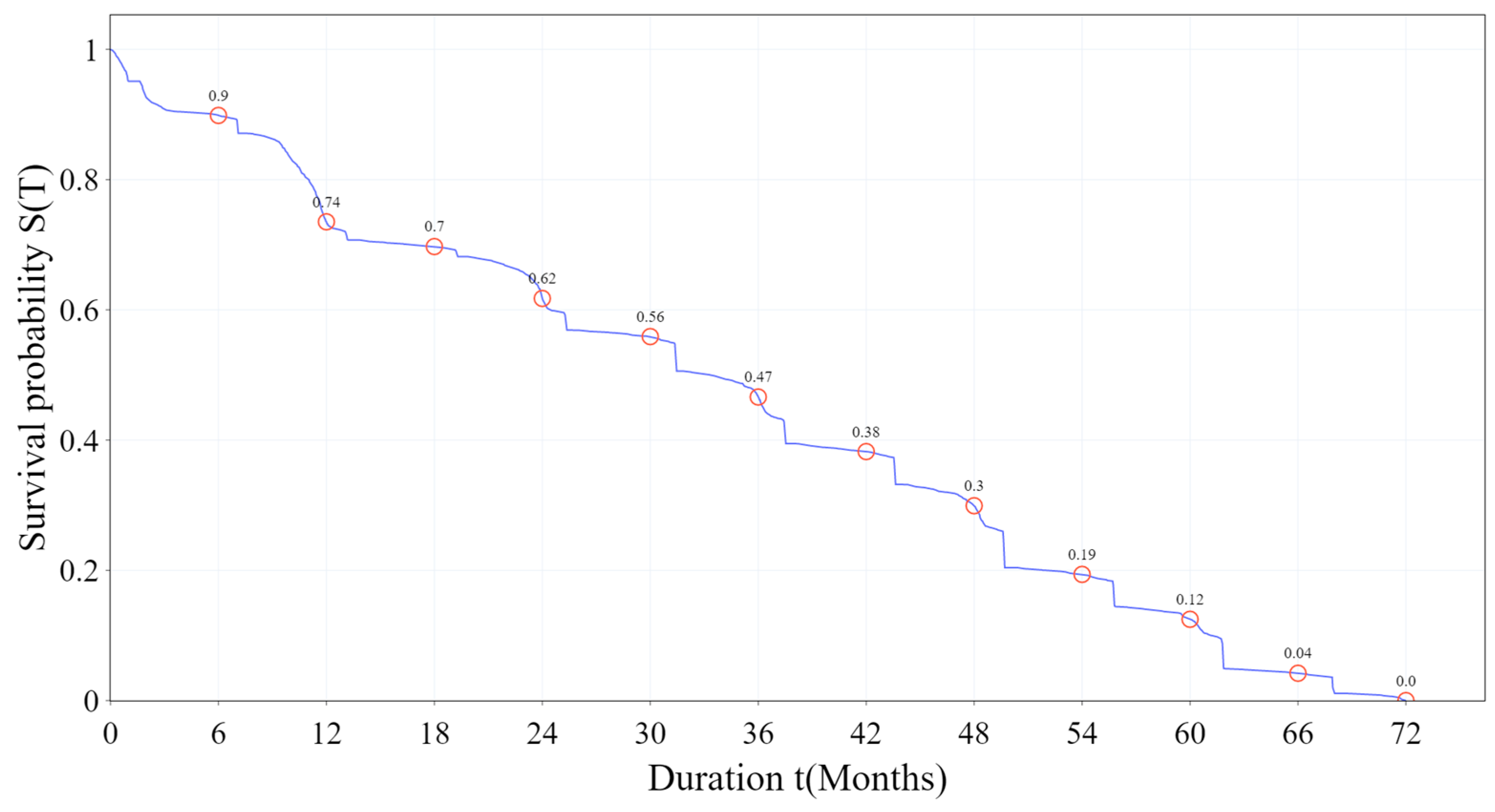
4.2. Kaplan–Meier Curve for Student Dropout
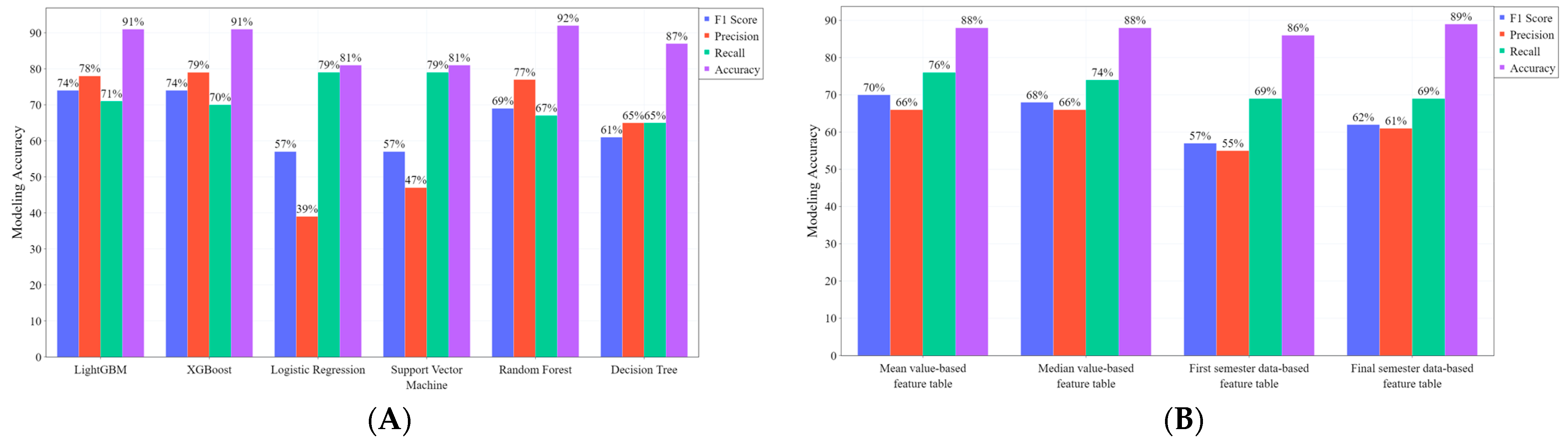
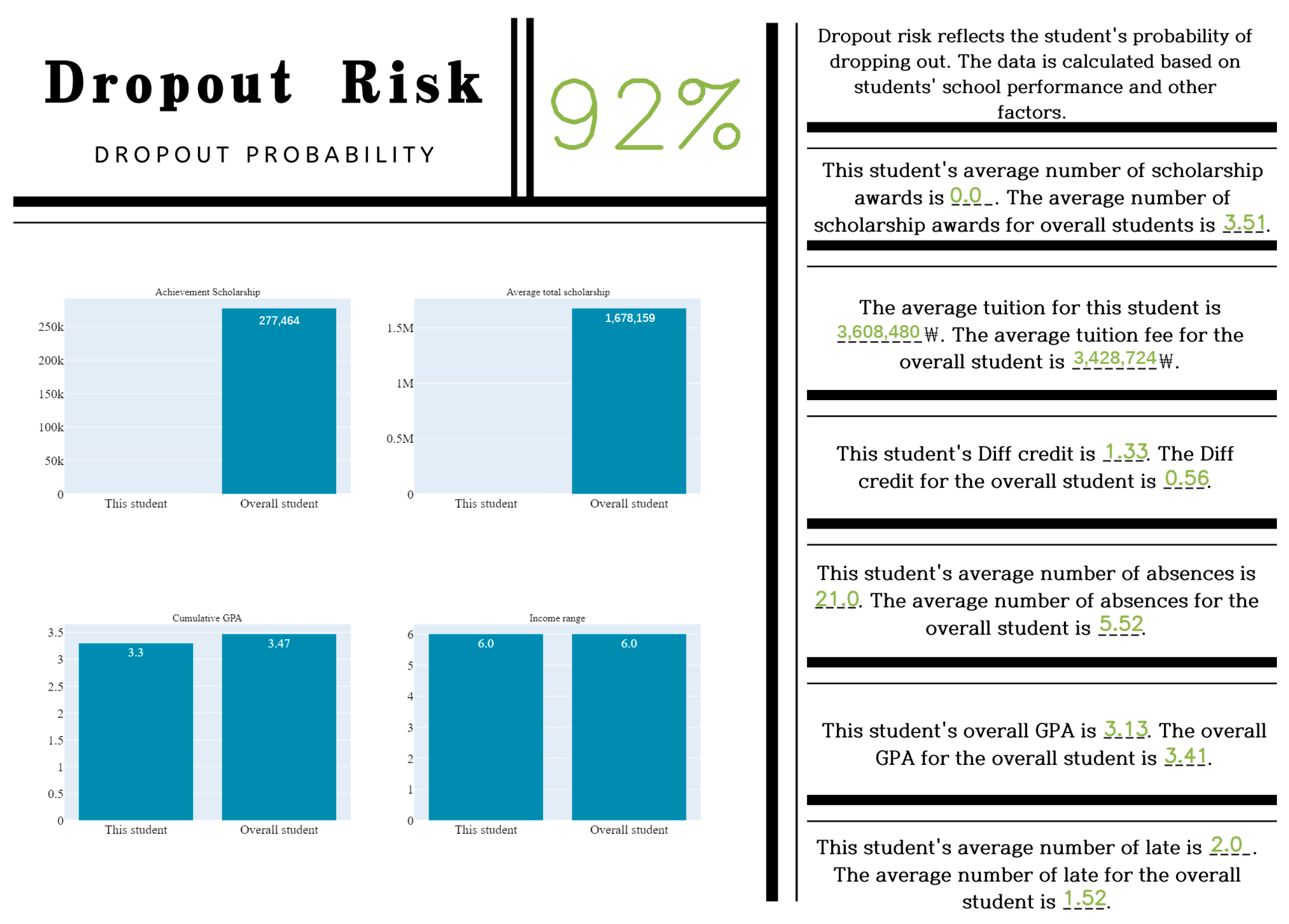
4.3. Model Test Results
- Training set: 70% of all graduates and dropouts, a total of 25,244 pieces of student data;
- Test set: 30% of all graduates and dropouts, a total of 10,818 pieces of student data;
- Prediction set: a total of 23,948 students in school or suspended from school were used to predict the possible dropouts in the future.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- UNESCO. How Many Students Are at Risk of not Returning to School? Available online: http://www.unesco.org/open-access/terms-use-ccbysa-en (accessed on 16 August 2022).
- Council of Economic Advisers. Investing in Higher Education: Benefits, Challenges, and the State of Student Debt. 2016. Available online: https://obamawhitehouse.archives.gov/sites/default/files/page/files/20160718_cea_student_debt.pdf (accessed on 26 December 2022).
- Del Savio, A.A.; Galantini, K.; Pachas, A. Exploring the relationship between mental health-related problems and undergraduate student dropout: A case study within a civil engineering program. Heliyon 2022, 8, e09504. [Google Scholar] [CrossRef] [PubMed]
- Contreras, D.; González, L.; Láscar, S.; López, V. Negative teacher–student and student–student relationships are associated with school dropout: Evidence from a large-scale longitudinal study in Chile. Int. J. Educ. Dev. 2022, 91, 102576. [Google Scholar] [CrossRef]
- Masserini, L.; Bini, M. Does joining social media groups help to reduce students’ dropout within the first university year? Socioecon. Plann. Sci. 2021, 73, 100865. [Google Scholar] [CrossRef]
- Dahal, T.; Topping, K.; Levy, S. Educational factors influencing female students’ dropout from high schools in Nepal. Int. J. Educ. Res. 2019, 98, 67–76. [Google Scholar] [CrossRef]
- Oliveira Silva, G.; Aredes, N.D.A.; Galdino-Júnior, H. Academic performance, adaptation and mental health of nursing students: A cross-sectional study. Nurse Educ. Pract. 2021, 55, 103145. [Google Scholar] [CrossRef]
- Heredia, D.; Amaya, Y.; Barrientos, E. Student Dropout Predictive Model Using Data Mining Techniques. IEEE Lat. Am. Trans. 2015, 13, 3127–3134. [Google Scholar] [CrossRef]
- Araque, F.; Roldán, C.; Salguero, A. Factors influencing university drop out rates. Comput. Educ. 2009, 53, 563–574. [Google Scholar] [CrossRef]
- Prenkaj, B.; Distante, D.; Faralli, S.; Velardi, P. Hidden space deep sequential risk prediction on student trajectories. Futur. Gener. Comput. Syst. 2021, 125, 532–543. [Google Scholar] [CrossRef]
- Fei, M.; Yeung, D.-Y. Temporal Models for Predicting Student Dropout in Massive Open Online Courses. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; IEEE: Pitscatway, NJ, USA, 2015; pp. 256–263. [Google Scholar]
- Xing, W.; Chen, X.; Stein, J.; Marcinkowski, M. Temporal predication of dropouts in MOOCs: Reaching the low hanging fruit through stacking generalization. Comput. Hum. Behav. 2016, 58, 119–129. [Google Scholar] [CrossRef]
- Song, Z.; Park, H.-J.; Thapa, N.; Yang, J.-G.; Harada, K.; Lee, S.; Shimada, H.; Park, H.; Park, B.-K. Carrying Position-Independent Ensemble Machine Learning Step-Counting Algorithm for Smartphones. Sensors 2022, 22, 3736. [Google Scholar] [CrossRef]
- Moreira da Silva, D.E.; Solteiro Pires, E.J.; Reis, A.; de Moura Oliveira, P.B.; Barroso, J. Forecasting Students Dropout: A UTAD University Study. Futur. Internet 2022, 14, 76. [Google Scholar] [CrossRef]
- Kabathova, J.; Drlik, M. Towards Predicting Student’s Dropout in University Courses Using Different Machine Learning Techniques. Appl. Sci. 2021, 11, 3130. [Google Scholar] [CrossRef]
- Del Bonifro, F.; Gabbrielli, M.; Lisanti, G.; Zingaro, S.P. Student Dropout Prediction. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer International Publishing: Midtown Manhattan, NY, USA, 2020; Volume 12163 LNAI, pp. 129–140. ISBN 9783030522360. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Pellagatti, M.; Masci, C.; Ieva, F.; Paganoni, A.M. Generalized mixed-effects random forest: A flexible approach to predict university student dropout. Stat. Anal. Data Min. ASA Data Sci. J. 2021, 14, 241–257. [Google Scholar] [CrossRef]
- Meedech, P.; Iam-On, N.; Boongoen, T. Prediction of Student Dropout Using Personal Profile and Data Mining Approach. In Intelligent and Evolutionary Systems; Springer: Cham, Switzerland, 2016; pp. 143–155. ISBN 9783319270005. [Google Scholar]
- Plagge, M. Using artificial neural networks to predict first-year traditional students second year retention rates. In Proceedings of the 51st ACM Southeast Conference on—ACMSE ’13, New York, NY, USA, 4–6 April 2013; ACM Press: New York, NY, USA, 2013; p. 1. [Google Scholar]
- Opazo, D.; Moreno, S.; Álvarez-Miranda, E.; Pereira, J. Analysis of First-Year University Student Dropout through Machine Learning Models: A Comparison between Universities. Mathematics 2021, 9, 2599. [Google Scholar] [CrossRef]
- Nagy, M.; Molontay, R. Predicting Dropout in Higher Education Based on Secondary School Performance. In Proceedings of the 2018 IEEE 22nd International Conference on Intelligent Engineering Systems (INES), Las Palmas de Gran Canaria, Spain, 21–23 June 2018; IEEE: Pitscatway, NJ, USA, 2018; pp. 000389–000394. [Google Scholar]
- Respondek, L.; Seufert, T.; Hamm, J.M.; Nett, U.E. Linking changes in perceived academic control to university dropout and university grades: A longitudinal approach. J. Educ. Psychol. 2020, 112, 987–1002. [Google Scholar] [CrossRef]
- Rovira, S.; Puertas, E.; Igual, L. Data-driven system to predict academic grades and dropout. PLoS ONE 2017, 12, e0171207. [Google Scholar] [CrossRef] [Green Version]
- Sosu, E.M.; Pheunpha, P. Trajectory of University Dropout: Investigating the Cumulative Effect of Academic Vulnerability and Proximity to Family Support. Front. Educ. 2019, 4, 6. [Google Scholar] [CrossRef] [Green Version]
- Aina, C.; Baici, E.; Casalone, G.; Pastore, F. The Economics of University Dropouts and Delayed Graduation: A Survey. SSRN Electron. J. 2018. [Google Scholar] [CrossRef]
- Lee, Y.H.; Kim, K.S.; Lee, K.H. The effect of tuition fee constraints on financial management: Evidence from Korean private universities. Sustain. 2020, 12, 5066. [Google Scholar] [CrossRef]
- Stinebrickner, R.; Stinebrickner, T.R. A Major in Science? Initial Beliefs and Final Outcomes for College Major and Dropout. Rev. Econ. Stud. 2014, 81, 426–472. [Google Scholar] [CrossRef]
- Santos, K.J.d.O.; Menezes, A.G.; de Carvalho, A.B.; Montesco, C.A.E. Supervised Learning in the Context of Educational Data Mining to Avoid University Students Dropout. In Proceedings of the 2019 IEEE 19th International Conference on Advanced Learning Technologies (ICALT), Maceió, Brazil, 15–18 July 2019; IEEE: Pitscatway, NJ, USA, 2019; pp. 207–208. [Google Scholar]
- Sivakumar, S.; Venkataraman, S.; Selvaraj, R. Predictive Modeling of Student Dropout Indicators in Educational Data Mining using Improved Decision Tree. Indian J. Sci. Technol. 2016, 9, 87032. [Google Scholar] [CrossRef] [Green Version]
- Sarra, A.; Fontanella, L.; Di Zio, S. Identifying Students at Risk of Academic Failure Within the Educational Data Mining Framework. Soc. Indic. Res. 2019, 146, 41–60. [Google Scholar] [CrossRef]
- Cardona, T.A.; Cudney, E.A. Predicting Student Retention Using Support Vector Machines. Procedia Manuf. 2019, 39, 1827–1833. [Google Scholar] [CrossRef]
- Kemper, L.; Vorhoff, G.; Wigger, B.U. Predicting student dropout: A machine learning approach. Eur. J. High. Educ. 2020, 10, 28–47. [Google Scholar] [CrossRef]
- Prenkaj, B.; Velardi, P.; Stilo, G.; Distante, D.; Faralli, S. A Survey of Machine Learning Approaches for Student Dropout Prediction in Online Courses. ACM Comput. Surv. 2021, 53, 1–34. [Google Scholar] [CrossRef]
- Lehr, C.A.; Johnson, D.R.; Bremer, C.D.; Cosio, A.; Thompson, M. Increasing Rates of School Completion: Moving From Policy and Research to Practice; National Center on Secondary Education and Transition: Minneapolis, MN, USA, 2004. [Google Scholar]
- Song, Y.Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 2017, 3147–3155. [Google Scholar]
- DeMaris, A. A Tutorial in Logistic Regression. J. Marriage Fam. 1995, 57, 956. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Lee, S.; Chung, J.Y. The Machine Learning-Based Dropout Early Warning System for Improving the Performance of Dropout Prediction. Appl. Sci. 2019, 9, 3093. [Google Scholar] [CrossRef] [Green Version]
- Marquez-Vera, C.; Morales, C.R.; Soto, S.V. Predicting School Failure and Dropout by Using Data Mining Techniques. IEEE Rev. Iberoam. Tecnol. Del Aprendiz. 2013, 8, 7–14. [Google Scholar] [CrossRef]
- Csalódi, R.; Abonyi, J. Integrated Survival Analysis and Frequent Pattern Mining for Course Failure-Based Prediction of Student Dropout. Mathematics 2021, 9, 463. [Google Scholar] [CrossRef]
- Neumann, I.; Jeschke, C.; Heinze, A. First Year Students’ Resilience to Cope with Mathematics Exercises in the University Mathematics Studies. J. Für Math. 2021, 42, 307–333. [Google Scholar] [CrossRef]
- Venegas-Muggli, J.I. Higher education dropout of non-traditional mature freshmen: The role of sociodemographic characteristics. Stud. Contin. Educ. 2020, 42, 316–332. [Google Scholar] [CrossRef]
- Wild, S.; Schulze Heuling, L. Student dropout and retention: An event history analysis among students in cooperative higher education. Int. J. Educ. Res. 2020, 104, 101687. [Google Scholar] [CrossRef]
- Rodríguez-Hernández, C.F.; Musso, M.; Kyndt, E.; Cascallar, E. Artificial neural networks in academic performance prediction: Systematic implementation and predictor evaluation. Comput. Educ. Artif. Intell. 2021, 2, 100018. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Sample Size | Features | Best Method | Metrics | Result |
|---|---|---|---|---|---|
| Plagge [22] | 5955 | Academic performance | Artificial Neural Networks | Accuracy | 0.75 |
| Nagy and Molontay [24] | 15,825 | High school data, Personal detail | Gradient Boosted Tree | Accuracy AUC (area under the curve) | 0.74 0.81 |
| Cardona and Cudney [34] | 282 | High school data, Academic grade | Support Vector Machine | Accuracy | 0.78 |
| Del Bonifro et al. [16] | 15,000 | High school data, Academic grade, Personal detail | Support Vector Machine | Accuracy Sensitivity Specificity | 0.86 |
| 0.88 | |||||
| 0.86 | |||||
| Kemper et al. [35] | 3176 | Academic grade | Decision Tree | Accuracy Sensitivity Specificity | 0.89 |
| 0.41 | |||||
| 0.97 | |||||
| Kabathova and Drlik [15] | 261 | Academic performance | Random Forest | Accuracy | 0.93 |
| Precision | 0.86 | ||||
| Recall | 0.96 | ||||
| F1 Score | 0.91 | ||||
| Moreira da Silva et al. [14] | 331 | Academic grade, Personal detail | XGBoost | Accuracy | 0.90 |
| Precision | 0.82 | ||||
| Recall | 0.92 | ||||
| F1 Score | 0.87 | ||||
| AUC | 0.95 |
| Category | Attribute | Type | Details |
|---|---|---|---|
| Student’s grade | Cumulative GPA | Numeric | The grade point average of all grades a student has secured in a semester or term |
| Overall GPA | Numeric | An average of all cumulative GPAs that a student has secured in all semesters and all the courses in an academic term | |
| Diff credits | Numeric | The difference between the applied credits and the credits taken. | |
| Student’s attendance | Absence | Numeric | The number of absences |
| Late | Numeric | The number of lates | |
| Authorize absence | Numeric | The number of authorized lates | |
| Student’s scholarship | Total scholarship | Numeric | Total scholarship amount received per semester |
| The number of scholarships | Numeric | The number of scholarship types received per semester | |
| Achievement | Numeric | Achievement scholarship amount received per semester | |
| Bursary | Numeric | Bursaries for underprivileged students scholarships amount received per semester | |
| Other scholarship | Numeric | Other scholarship amounts received per semester | |
| Labor | Numeric | Labor scholarship amount received per semester | |
| Faculty | Numeric | Faculty scholarship amount received per semester | |
| Student’s personal background | Income range | Numeric | The income range of the student’s family |
| Professional classification | Numeric | Student’s professional classification | |
| Military service | Nominal | Whether the student has served in the military. | |
| Living area | Numeric | Living area | |
| Suspensions | Numeric | Total semester number of suspensions of schooling | |
| Tuition fee | Numeric | Tuition fees per semester | |
| Sex | Nominal | Sex of the student | |
| Birth | Numeric | Year of birth | |
| Access year | Numeric | Year of enrollment | |
| Student’s status | Dropout | Nominal | Student status: Yes (Dropout) or No (Not dropout) |
| Year of Admission | Number of Students in School | Number of Student Graduates | Number of Student Dropouts | Sum | Dropout Rate |
|---|---|---|---|---|---|
| 2010 | 6 | 4578 | 845 | 5429 | 0.16 |
| 2011 | 24 | 4524 | 852 | 5400 | 0.16 |
| 2012 | 54 | 4483 | 869 | 5406 | 0.16 |
| 2013 | 126 | 4259 | 738 | 5123 | 0.14 |
| 2014 | 371 | 3914 | 794 | 5079 | 0.16 |
| 2015 | 935 | 3086 | 680 | 4701 | 0.14 |
| 2016 | 1923 | 2349 | 588 | 4860 | 0.12 |
| 2017 | 2870 | 1290 | 519 | 4679 | 0.11 |
| 2018 | 4033 | 336 | 432 | 4801 | 0.09 |
| 2019 | 4178 | 280 | 336 | 4794 | 0.07 |
| 2020 | 4614 | 0 | 259 | 4873 | 0.05 |
| 2021 | 4814 | 0 | 51 | 4865 | 0.01 |
| Sum | 23,948 | 29,099 | 6963 | 60,010 | 0.13 |
| Actual | |||
|---|---|---|---|
| Positive | Negative | ||
| Predicted | Positive | True positive (TP) | False positive (FP) |
| Negative | False negative (FN) | True negative (TN) | |
| Feature Table | Model Name | F1 Score | Precision | Recall | Accuracy |
|---|---|---|---|---|---|
| Mean value-based feature table | LightGBM | 0.79 | 0.81 | 0.78 | 0.94 |
| XGBoost | 0.77 | 0.76 | 0.79 | 0.93 | |
| Logistic Regression | 0.61 | 0.50 | 0.78 | 0.80 | |
| Support Vector Machine | 0.62 | 0.51 | 0.78 | 0.80 | |
| Random Forest | 0.75 | 0.77 | 0.73 | 0.93 | |
| Decision Tree | 0.66 | 0.63 | 0.70 | 0.89 | |
| Average | 0.70 | 0.66 | 0.76 | 0.88 | |
| Median value-based feature table | LightGBM | 0.77 | 0.80 | 0.74 | 0.92 |
| XGBoost | 0.78 | 0.83 | 0.74 | 0.93 | |
| Logistic Regression | 0.57 | 0.44 | 0.79 | 0.81 | |
| Support Vector Machine | 0.57 | 0.44 | 0.79 | 0.81 | |
| Random Forest | 0.75 | 0.80 | 0.71 | 0.93 | |
| Decision Tree | 0.66 | 0.65 | 0.68 | 0.85 | |
| Average | 0.68 | 0.66 | 0.74 | 0.88 | |
| First-semester data-based feature table | LightGBM | 0.68 | 0.72 | 0.65 | 0.85 |
| XGBoost | 0.68 | 0.75 | 0.63 | 0.87 | |
| Logistic Regression | 0.43 | 0.29 | 0.81 | 0.81 | |
| Support Vector Machine | 0.43 | 0.29 | 0.81 | 0.80 | |
| Random Forest | 0.66 | 0.72 | 0.61 | 0.93 | |
| Decision Tree | 0.55 | 0.50 | 0.60 | 0.91 | |
| Average | 0.57 | 0.55 | 0.69 | 0.86 | |
| Final semester data-based feature table | LightGBM | 0.73 | 0.79 | 0.67 | 0.93 |
| XGBoost | 0.73 | 0.82 | 0.65 | 0.93 | |
| Logistic Regression | 0.47 | 0.34 | 0.78 | 0.83 | |
| Support Vector Machine | 0.47 | 0.34 | 0.78 | 0.84 | |
| Random Forest | 0.71 | 0.79 | 0.64 | 0.92 | |
| Decision Tree | 0.60 | 0.57 | 0.63 | 0.86 | |
| Average | 0.62 | 0.61 | 0.69 | 0.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Z.; Sung, S.-H.; Park, D.-M.; Park, B.-K. All-Year Dropout Prediction Modeling and Analysis for University Students. Appl. Sci. 2023, 13, 1143. https://doi.org/10.3390/app13021143
Song Z, Sung S-H, Park D-M, Park B-K. All-Year Dropout Prediction Modeling and Analysis for University Students. Applied Sciences. 2023; 13(2):1143. https://doi.org/10.3390/app13021143
Chicago/Turabian StyleSong, Zihan, Sang-Ha Sung, Do-Myung Park, and Byung-Kwon Park. 2023. "All-Year Dropout Prediction Modeling and Analysis for University Students" Applied Sciences 13, no. 2: 1143. https://doi.org/10.3390/app13021143
APA StyleSong, Z., Sung, S. -H., Park, D. -M., & Park, B. -K. (2023). All-Year Dropout Prediction Modeling and Analysis for University Students. Applied Sciences, 13(2), 1143. https://doi.org/10.3390/app13021143