1. Introduction
Fingerprints are one important piece of evidence used in law enforcement to identify criminals. To obtain the identity information of the criminal suspect, firstly, fingerprints collected at crime scenes usually require a fingerprint expert to manually mark the fingerprint features. Then, the collected fingerprint features are compared with the fingerprints recorded in the public security system database. Finally, the identity information of the suspect is obtained through fingerprint information [
1,
2,
3]. However, manual fingerprint identification is time-consuming and heavily dependent on experience, so it is difficult for manual fingerprints to complete the fingerprint comparison for large fingerprint databases. With the introduction of an automatic fingerprint identification system (AFIS) [
4], the scope of manual investigation is narrowed and the workload of fingerprint experts is greatly reduced. However, negative factors such as background noise, contaminants (blood, etc.), and human sabotage may affect the integrity of the collected fingerprint images [
5,
6,
7]. Insufficient effective area of fingerprint images will reduce the extractability of fingerprint features, which will directly lead to a decrease in fingerprint identification accuracy.
Researchers have tried to increase the effective area of fingerprints by using image inpainting methods. However, the existing fingerprint reconstruction methods can only recover small damages, but cannot recover serious and huge damaged areas. The fingerprints collected at the crime scene are severely damaged, which makes it impossible to effectively increase the effective area of the fingerprint by using the fingerprint recovery method. Although the damaged area of the image can be reconstructed using a GAN network, the new fingerprint image generated by the GAN network is not exactly the same as the ground truth. Therefore, extracting features from limited fingerprint areas is an important direction for partial fingerprint identification.
The minutiae-based method is a typical method in fingerprint image identification [
8,
9,
10]. Zhang et al. [
10] proposed a minutiae-based method to extract useful information from fingerprints. Firstly, the collected fingerprint image is segmented [
11,
12] to obtain the fingerprint foreground area. Secondly, enhancement operations on the segmented images are performed [
13,
14]. Then, the refined skeleton map of the ridge line of the fingerprint image is extracted via morphological transformation and the minutiae features on the thinned ridges are obtained via neighborhood analysis. Finally, the identification result is obtained by comparing the minutiae points [
15]. Due to the limited effective area of the partial fingerprint and the complex background, the minutiae extracted using the traditional algorithm are not enough for fingerprint identification.
To improve identification accuracy, many papers combine fingerprint minutiae points with other features such as ridge structure [
16,
17], orientation field information [
18], sweat pores [
19], etc. The feature-combination method improves the identification accuracy of low-quality fingerprints to a certain extent. However, the combined feature method is not suitable for partial fingerprints due to the incomplete and distorted ridgeline structure of the fingerprints collected on-site.
At present, deep learning has made a lot of achievements in the field of image identification due to its powerful feature extraction ability [
20,
21]. Compared with traditional identification methods, deep learning-based methods makes better use of the effective information of each fingerprint image to realize fingerprint identification. Chen et al. [
22] proposed a fingerprint identification algorithm based on support vector machines (SVMs). This method integrates fingerprint minutiae and region information and studies the effect of fingerprint region on the performance of partial fingerprint identification. The results show that with the reduction of the effective area of the fingerprint image, the identification accuracy of partial fingerprints will also decrease. Li et al. [
23] simulated a convolutional neural networks (CNNs)-based fingerprint image identification method and compared it with the traditional minutiae-based identification method. They found that the CNN-based method has fewer iterations and higher identification accuracy in the training process, but the network structure is still not ideal for the identification of partial fingerprints. Some researchers advocate improving the structure of the fingerprint feature extraction network to improve the identification accuracy. For example, Zhang et al. [
24] adopted different deep convolutional neural networks to learn high-level global features and low-level detail features of fingerprints, which could accurately identify high-resolution (2000 dpi) partial fingerprint images collected on mobile devices. However, this is not ideal for low-resolution fingerprint images. As far as we know, there is no identification method for partial fingerprint images.
In the process of fingerprint identification, extracting the features that can accurately describe the fingerprint information from the limited effective area of the partial fingerprint is a key step in identification. In this paper, a novel model named APFI is proposed for the identification of low-quality partial fingerprints. Firstly, a residual network model for partial fingerprint feature extraction is established. The Squeeze and Excitation module (SE module) [
25] is added to the network, which is utilized to weight features with cross-channels, focusing on details of partial fingerprints. Next, a specific loss function is designed to train the proposed model to make the features learned by the network more discriminative. The similarity of fingerprint images is defined by the angular distance between fingerprint features. Lastly, to verify the effectiveness of APFI, a home-made mutilated fingerprint dataset is built. Experiments on the home-made fingerprint datasets and the NIST-SD4 datasets show that the partial fingerprint identification method proposed in this paper has higher identification accuracy than other state-of-the-art methods. The contributions of our work can be summarized as follows:
- (a)
For the task of on-site partial fingerprinting, we propose APFI. APFI focuses on the effective area of the fingerprint, which enables it to extract fingerprint features efficiently when the fingerprint image is incomplete.
- (b)
During the training process, a specific loss function is used to train APFI, so that the features learned by the network are more discriminative. At the same time, to accurately calculate the similarity of the two fingerprint images, the angular distance is used to calculate the distance between the features.
- (c)
The SE module is used to adaptively modulate the features, so that the relevant information is retained and the irrelevant information is weakened. Experiments on a NIST-SD4 dataset and a home-made dataset demonstrate the effectiveness and competitiveness of our proposed model.
2. Related Works
Fingerprints are one of the most important pieces of evidence for identifying suspects. However, in practice, the fingerprints at the crime scene cannot be directly observed by human eyes. Prior to analysis and identification, latent fingerprints must be processed using some method. In this section, we briefly introduce the preprocessing steps of the incomplete fingerprints at the crime scene. At the same time, we review several existing state-of-the-art partial fingerprinting methods.
2.1. Preprocessing of Partial Fingerprints
The steps of fingerprint preprocessing at the crime scene are: fingerprint collection, fingerprint segmentation, and fingerprint enhancement. Since fingerprints at a crime scene cannot be seen directly with the human eye, investigators use fingerprint powder to make latent fingerprints visible and preserve the developed images as evidence. With the development of new materials and technologies [
26], fingerprint collection technology is becoming more and more mature.
The fingerprint image of the crime scene is divided into valid region of interest (ROI) and invalid background noise. The purpose of fingerprint segmentation is to segment valid fingerprint regions from the fingerprint background. In traditional fingerprint segmentation methods, the fingerprint image is evenly divided into local blocks. The quality of each local block is evaluated by indicators such as the mean and variance of the gray value. These methods work well for ordinary fingerprints, but do not perform well for crime scene fingerprints. Liu et al. [
27] proposed a latent fingerprint segmentation method based on deep UNets for crime scene fingerprints. They generated the latent fingerprints and their segmentation ground truth data for training. Their proposed method converts latent images to background and fingerprint regions through end-to-end training.
The fingerprints at the crime scene were severely damaged, and the ridge structure of the fingerprints was not clear.
For low-quality fingerprint identification, it is easy to extract false feature points, which reduces the accuracy of fingerprint identification. The goal of fingerprint enhancement is to restore the damaged ridge structure and improve the contrast between ridges and valleys. Wei et al. [
28] proposed a multi-task convolutional neural network (CNN) based method to recover fingerprint ridge structure from corrupted fingerprint images. Their method not only repairs minor damages, but also filters out some background noise. However, this method cannot restore severe and large damaged areas. Therefore, extracting features from limited fingerprint areas is an important direction for partial fingerprint identification.
2.2. Partial Fingerprint Identification
Traditional methods are usually based on minutiae descriptors [
29] for fingerprint identification. The corresponding relationship between minutiae is established by considering the similarity of minutiae descriptors, and then fingerprint comparison is performed. To improve the identification performance, many papers combine fingerprint minutiae points with other key information [
30,
31] as the feature representation of fingerprints, and then measure the similarity between them. Lee et al. [
32] add the ridge feature to the traditional detail feature identification, and the final identification score is the combination of the two identification stages. The identification scheme includes two stages of minutiae identification and ridge feature identification, and the results of the two matching stages are combined to obtain the final identification score. Liu et al. [
33] proposed a fingerprint identification field extraction algorithm based on dictionary learning and multi-scale sparse coding. Multi-scale dictionary learning is performed with high-quality fingerprint orientations from various scales, and fingerprint images are decomposed to obtain fingerprint texture images. On texture images, fingerprint patch orientations are iteratively estimated using a multi-scale sparse coding method. Xu et al. [
34] combined sweat pore features with fingerprint ridge features and achieved outstanding performance in high-resolution partial fingerprint identification. Javad et al. [
35] proposed a robust and fast identification system combining two indexing algorithms. One of the algorithms used triplet minutiae and the other used the orientation domain to retrieve fingerprints, reducing identification time without loss of accuracy.
For high-resolution fingerprint images, traditional algorithms have achieved excellent results. However, in partial fingerprints, complex background noise and partial ridge will affect the extraction of features. In addition, a large number of false feature points will be generated when the minutiae points of the partial fingerprint image are extracted, which reduces the accuracy of the fingerprint identification.
At present, fingerprint identification technology based on deep learning has attracted the attention of researchers. Wu et al. [
36] proposed a fingerprint classification model based on convolutional neural networks, which achieved good results in various databases and improved the fingerprint identification rate at the same time. Hidir et al. [
37] used the transfer learning method to design a fingerprint identification model (DCNN) based on deep convolutional neural networks. The experimental results show that the designed DCNN model can be effectively used in fingerprint identification and classification. Zeng et al. [
38] combined two loss functions to train the designed convolutional neural network. However, this method has certain limitations. On the one hand, the two loss functions will produce different feature distributions, so it may not be a natural choice to combine features. On the other hand, contrastive loss will be affected by data expansion in the training process and the computational cost will increase, which makes it impossible to quickly complete fingerprint identification for a large database. Cao et al. [
39] utilize CNN to extract templates (two minutiae ones and one texture one) to realize fuzzy fingerprint identification. The identification scores of each template of the input fingerprint and the reference fingerprint are fused to obtain the final identification result. Although this method has achieved good results, the calculation process is too cumbersome to quickly complete fingerprint identification for large databases.
3. The Proposed Method
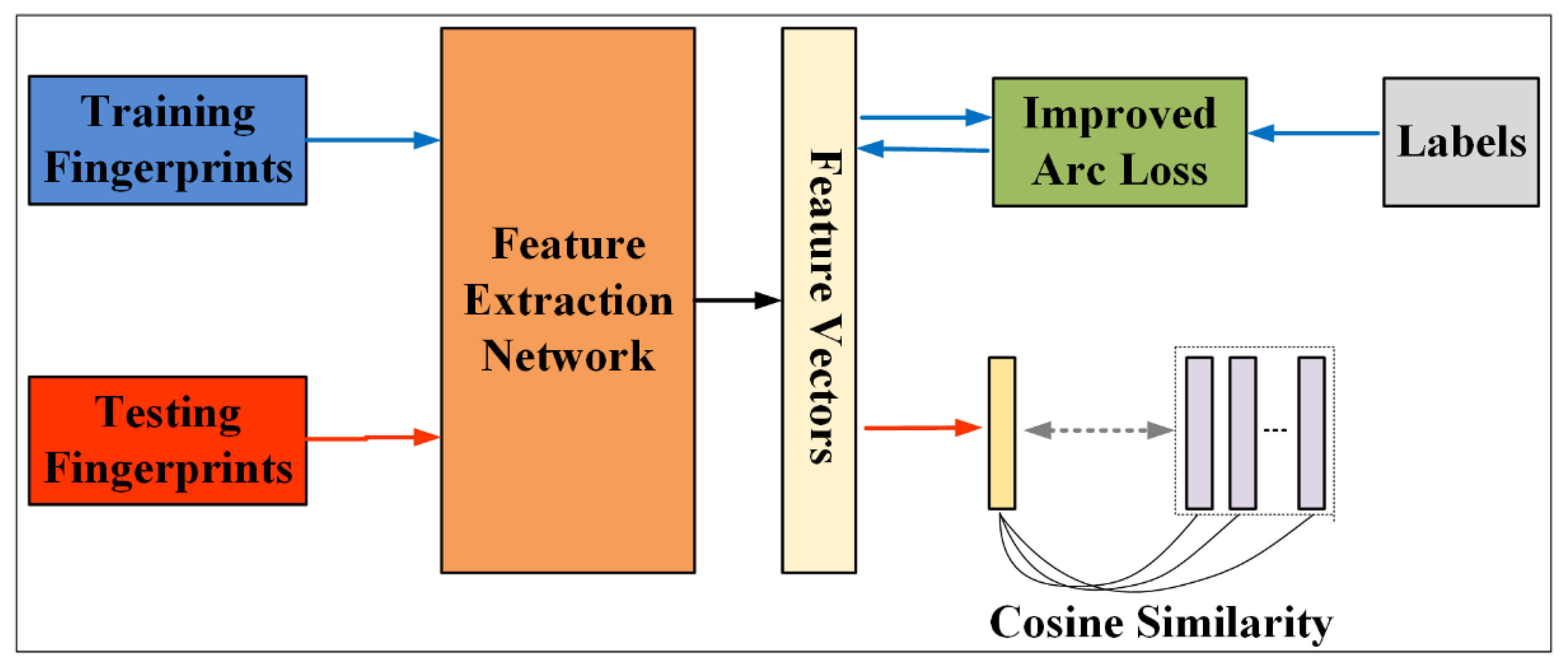
Figure 1 shows the overall structure of APFI. The model structure of APFI includes a training phase and a verification phase. The model structure proposed in this paper is divided into a training phase and a verification phase. The training phase is seen as the process of training the classifier, indicated by blue arrows in
Figure 1. In the training phase, we train the proposed feature extraction network. We optimize the network with an additive angular margin loss (Arc-Loss) so that the network can learn discriminative large-margin features. During verification phase, compare the input fingerprint to each identity in the database. The distance between the feature vector of the input image and the feature vector of the image in the database is calculated to judge the similarity degree of the two images. To further refine the fingerprint features extracted using the training network, the SE module is embedded in the feature extraction network. At the same time, the Arc-Loss is improved. The improved loss function is more suitable for the identification of partial fingerprints. The feature extraction network framework proposed in this paper is analyzed in
Section 3.1. The loss function is introduced in detail in
Section 3.2.
At the verification phase, as shown by the red arrow in
Figure 1, the fingerprint image was input into the feature extraction network to obtain the feature, and the distance between it and each fingerprint feature in the database was calculated. The smaller the feature distance, the greater the similarity between the two images. We find that cosine distance [
40] is more suitable to represent the differences between fingerprint features than Euclidean distance commonly used in the past. For the fingerprints of the same label, their feature angle is close to 0 degrees, and the cosine of the feature angle is close to 1. For fingerprints of different labels, their characteristic angle is close to 90 degrees, and the cosine of the characteristic angle is close to 0. The cosine distance calculation formula is as follows, where
and
represent the feature vectors of the two fingerprints to be verified, respectively.
3.1. Feature Extraction Network
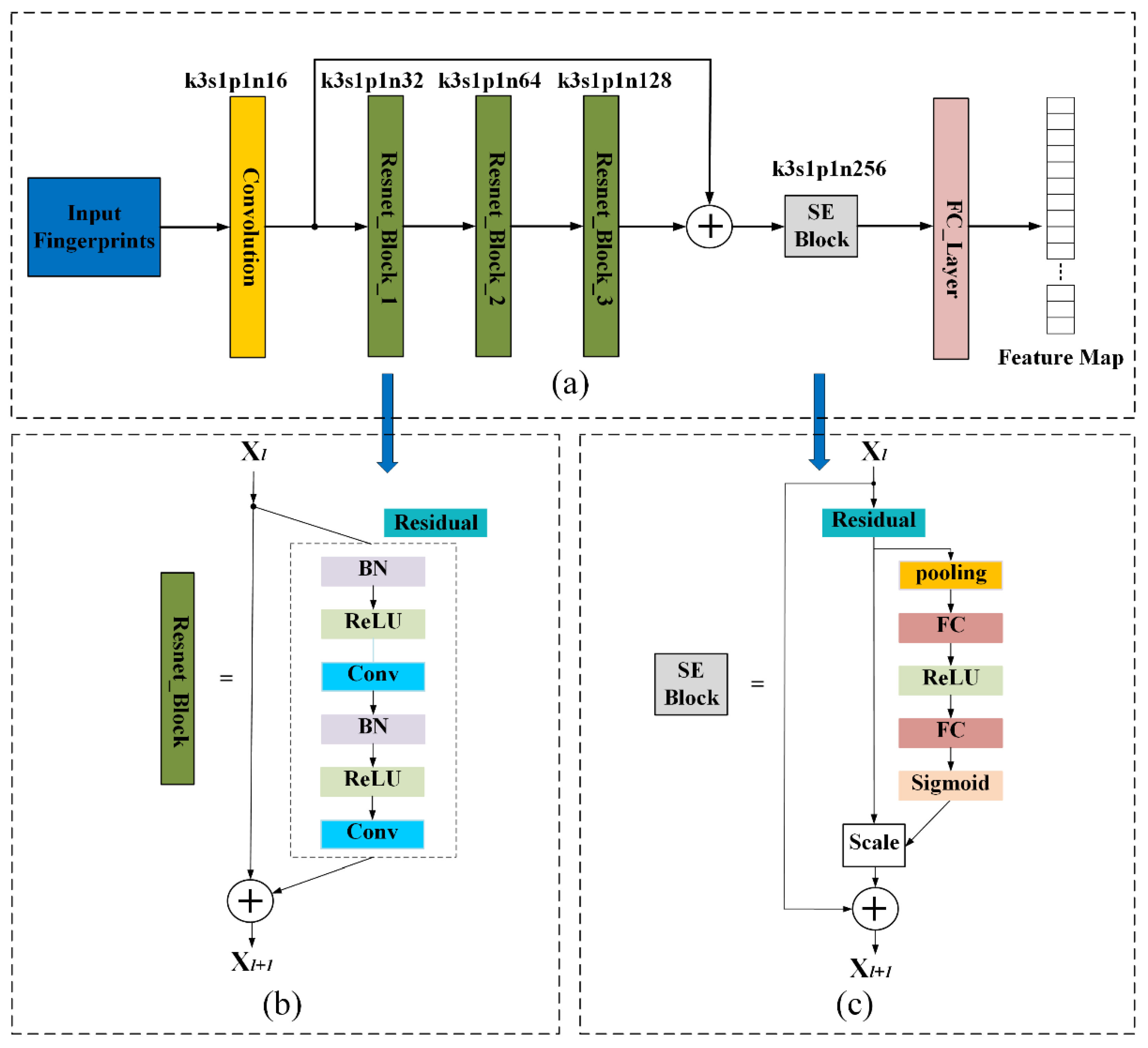
The feature extraction network architecture is shown in
Figure 2a–c as the overall structure diagram of the feature extraction network model, the detailed diagram of the residual module, and the detailed diagram of the SE module. The network proposed in this paper consists of one convolution layer for sensing fingerprint images, three residual modules, one SE module and one fully connected layer (FC layer). K3s1p1n16 means that the kernel size is 3 × 3, the stride size is 1, the padding size is 1, and the channel size is 16. The same applies to the other expressions of
Figure 2a.
During training, to avoid the phenomenon of gradient vanish, the residual module is added into the network model, as shown in
Figure 2b. The residual unit contains two convolutional layers and two batch normalization (BN) layers, as shown in the structure within the dotted line in
Figure 2b. Then, to preserve more shallow information, the output of the first convolution layer and the output of the fourth residual block are connected together as the input of SE module. In view of the flexibility of the SE structure, the SE structure is added to the existing residual module, as shown in
Figure 2c. The SE structure can be added to the existing network without disrupting the original main structure of the network. The SE block enables the network to pay more attention to channel characteristics while suppressing non-critical channel characteristics. This structure is beneficial to extract important feature information in the partial fingerprint image and improve the network running speed. Finally, the output of SE module is used as the input of FC layer to obtain the final feature.
3.2. Loss Function
It is very important to design a suitable loss function in a deep learning-based partial fingerprint identification task. The improved Arc-Loss function [
40] is used to train the network to learn high-resolution features.
Arc-Loss has made remarkable achievements in face identification. This section briefly introduces Arc-Loss, and then makes improvements based on it. The expression of Arc-Loss is shown as follows.
where
N is the batch size,
n is the class number, and
is the embedding feature of the
i-th sample.
denotes the angle between the weight
and
. Then the weight
is fixed by
normalization. For the sake of simplicity, fix the bias
and fix
.
Arc-Loss adds an extra angular margin m to improve intra-class compactness and inter-class differentiation. With the increase in m, for different categories of features, the two features gradually move away so that the boundaries between different features are clear. For features of the same category, the two feature spaces are compressed to make the same features more compact. As the angular margin increases, the learning task becomes more difficult, and the feature discrimination learned from the network is better. Therefore, Arc-Loss can extract partial fingerprint features more effectively.
Partial fingerprints have smaller effective areas than normal fingerprint images. To make the loss function more suitable for partial fingerprinting, we increase the constraint of the loss function. We multiply a factor a greater than 1 before the angle. As the coefficient a increases, the features of the same category are more aggregated. Therefore, defining the loss in this way will force the model to learn features with larger distances between classes and smaller distances within classes. The improved loss function is shown in Equation (6); we set
m as 0.5 and set
a as 1.5, which is obtained from experiments.
4. Experimental Analysis
In this section, public datasets NIST-SD4 and a home-made dataset are used to evaluate APFI and several other fingerprinting methods. Firstly, we briefly describe the home-made partial fingerprint dataset. Second, we introduce the relevant parameter settings and experimental conditions during the experiment. Third, we conduct comparative experiments on multiple methods in public dataset NIST-SD4 and home-made dataset and present the identification results in this section. Finally, we performed some ablation experiments to confirm the correctness of the structure.
To verify the generalization performance of the model, the datasets are divided into five groups randomly, then four folds of datasets are combined as training data, and the remaining dataset is considered as test data. The experiments are repeated five times so that every fold has a chance to be the test data. The result is calculated as the average of five experiments.
4.1. Dataset
A partial fingerprint dataset is established in this section, due to the lack of publicly available partial fingerprint database. To simulate the state of fingerprints collected at the crime scene, fingerprint images were collected by pressing. The image was resized to 300 × 300. In this dataset, a 2000-class of fingerprint images was collected from 200 volunteers. There are 200 images for each class, and the home-made partial fingerprint dataset contains 40,000 images in total.
To verify the generalization ability of the proposed algorithm, the public dataset NIST Special Database 4 (NIST-SD4) is used to further test the proposed method. The NIST-SD4 dataset contains 4000 (2000 pairs) grayscale fingerprint image pairs, each with a size of pixels. Fingerprint images can be classified into five categories based on fingerprint patterns.
4.2. Training Detail
Data Preprocessing: During training, the fingerprint image is evenly divided into local blocks with a size of
, as shown in
Figure 3. We use the method in [
41] to enhance fingerprint images. In order to enrich the number of samples, the image was randomly flipped during the training, and the fingerprint image was randomly rotated between −30 and 30 degrees. During training, stochastic gradient descent (SGD) is used to update the network parameters. We set momentum to 0.9 and weight decay to
. The learning initial rate is set to 0.1, and is divided by 10 at the 14 K, 22 K iterations. The training process is finished at 30 K iterations.
4.3. Testing Detail
During the verification process, to verify the identification accuracy of the proposed method for fingerprints with different degrees of incompleteness, we established four fingerprint verification sets with different effective areas. They are the complete fingerprint image, the fingerprint image with an effective area of 75%, the fingerprint image with an effective area of 50%, and the fingerprint image with an effective area of 25%. The location of the valid image portion of each validation set is random, as shown in
Figure 4.
4.4. Experiments on Home-Made Dataset
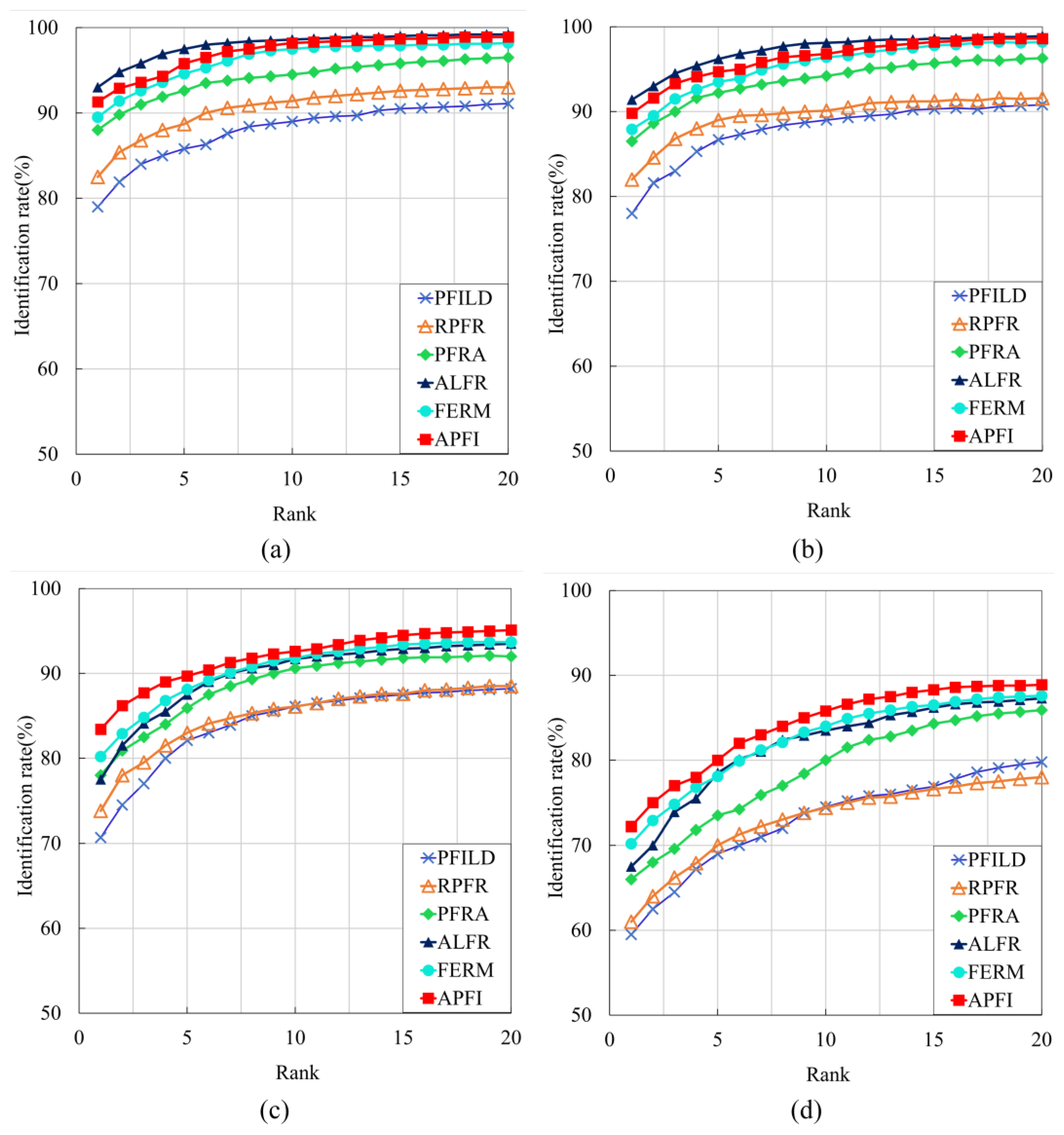
In this section, the proposed method is compared with several advanced fingerprint identification methods proposed in other related papers on our home-made dataset. Methods include PFILD [
35], RPFR [
42], PFRA [
38], ALFR [
39], and FERM [
23]. PFILD combines minutiae with texture features to recognize fingerprint images. RPFR describes a partial fingerprint identification algorithm based on SIFT. PFRA proposed a fingerprint image identification method based on deep learning. ALFR uses CNN to extract 3 templates for fingerprint retrieval. FERM improves the structure of the CNN network, and combines the incomplete fingerprint image and the fingerprint feature map as the input of the CNN network model. For evaluating different registration methods, we used a cumulative match characteristic curve (CMC) in the home-made dataset, as shown in
Figure 5. It is obvious that the identification method based on deep learning (PFRA, ALFR, APFI, FERM) has better performance than the method based on minutiae (PFILD, RPFR). The method based on deep learning is more accurate for feature extraction of low-quality fingerprint images. For fingerprint images with 100% and 75% effective area, the identification rate of ALFR is slightly higher than that of this paper. For fingerprint images with an effective area of 100%, the rank-1 recognition rates of APFI and ALFR are 91.3% and 93%, respectively. Meanwhile, for fingerprint images with an effective area of 75%, the rank-1 recognition rates of APFI and ALFR are 89.8% and 91.4%, respectively.
For fingerprint images with 50% and 25% effective area, APFI achieves better performance. For fingerprint images with 50% effective area, the rank-1 identification rate is 83.2% and the rank-20 identification rate is 94.9%. For fingerprint images with 25% effective area, the rank-1 identification rate is 72.2% and the rank-20 identification rate is 88.9%. This shows that APFI has more advantages in the identification of partial fingerprints.
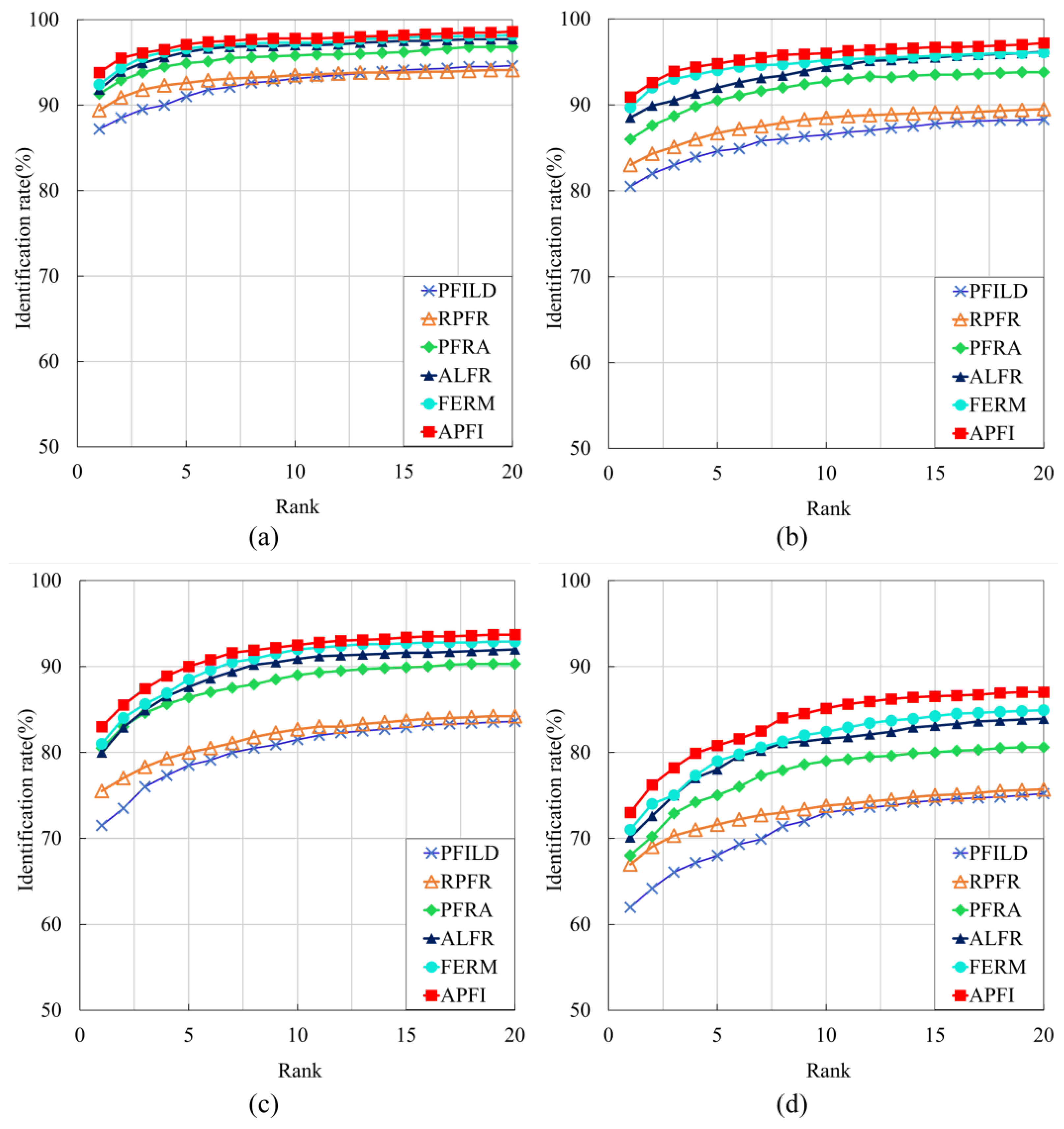
4.5. Experiments on NIST Dataset
To demonstrate the generalization ability of APFI, the identification accuracy of the proposed method and several methods (PFILD, RPFR, PFRA, ALFR, and FERM) introduced in
Section 4.4 are compared on the NIST-SD4 dataset. The experimental results are shown in
Figure 6. The CMC curves show that the deep-learning-based identification methods (PFRA, ALFR, APFI, FERM) perform significantly better than the minutiae-based identification methods (PFILD, RPFR) on the NIST-SD4 dataset. This proves that the deep learning-based method has better fingerprint feature extraction ability.
Experiments on the NIST-4 dataset show that APFI has a higher identification rate than other methods. As the effective area of fingerprint images decreases, the advantages of APFI are more obvious. For fingerprint images with an effective area of 50%, the rank-1 identification rate of APFI is 2.5% higher than other methods, and the rank-20 identification rate of APFI is 1.7% higher than other methods. For fingerprint images with an effective area of 25%, the rank-1 identification rate of APFI is 2.9% higher than other methods, and the rank-20 identification rate of APFI is 3.1% higher than other methods. This evidences that the proposed identification model has stronger generalization ability and robustness.
4.6. Ablation Experiments
We utilize two ablation experiments to observe the effect of loss function and SE module in the proposed model. In
Section 4.6.1, we train the network with different loss functions without changing other network structures. In
Section 4.6.2, we train the feature extraction network with and without SE blocks separately.
4.6.1. Effect of Loss Function
In this section, different loss functions are used to train the network under the same network structure so as to select the most suitable loss function. Four advanced loss functions (Arc-Loss, Triplet Loss [
43], Contrast Loss [
44], Improved Arc-Loss) are used to train our proposed feature extraction network. Meanwhile, the performance of each loss function is compared on a home-made dataset with different effective areas. The experimental results are shown in
Table 1, in which the best results are marked in bold. The improved Arc-Loss achieves excellent results in fingerprint identification of different effective areas, and achieves the highest identification rate when the effective area is 50% and 25%. This indicates that improved Arc-Loss has better extraction ability for partial fingerprints and is more suitable for the identification of partial fingerprints compared with other loss functions.
4.6.2. Effect of SE Module
This section discusses the influence of the SE module on feature extraction and trains feature extraction networks with SE block and without SE block, respectively. The results are shown in
Table 2. Compared with the network without SE module, the network with SE module has better performance, which proves that adding SE module in the network has a positive effect on feature extraction of partial fingerprint images. The weight value of each channel can be calculated through the SE module, which makes the network pay more attention to the information in the important channel. This structure enables the network to accurately obtain the important feature information while ignoring the unimportant fingerprint features during the feature extraction of a low-quality partial fingerprint.
5. Conclusions
In this paper, we propose a novel deep learning-based model named APFI for partial fingerprint identification. Firstly, compared to existing partial fingerprint identification methods, the proposed model focuses on feature extraction in partial fingerprint images. We refer to the method of face recognition and use the improved Arc-Loss to train the proposed model. Arc-Loss can reduce the distance of intra-class features and increase the distance of inter-class features. The model proposed in this paper is more efficient and avoids an excessively long data processing stage. Secondly, the SE module is added to the feature extraction network to focus on the important channel information and ignore the unimportant channel information. Thirdly, we use angular distance to measure the similarity of fingerprint features. On the one hand, the angular distance fits better with the loss function used in this paper. On the other hand, the angular distance is more adapted to the fingerprint structure. Finally, experimental results on the home-made dataset and the NIST SD4 dataset evidence that the method proposed in this paper achieves better results than other methods. However, when the effective area of the fingerprint is less than 25%, the fingerprint image identification accuracy does not meet the requirements. In the future, we will work on optimizing the model structure and computational complexity of the partial fingerprint identification network to speed up identification. At the same time, we intend to further study the enhancement and restoration of partial fingerprint images to improve the identification accuracy of fingerprints.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}