

IFE-Net: An Integrated Feature Extraction Network for Single-Image Dehazing

Abstract
:1. Introduction
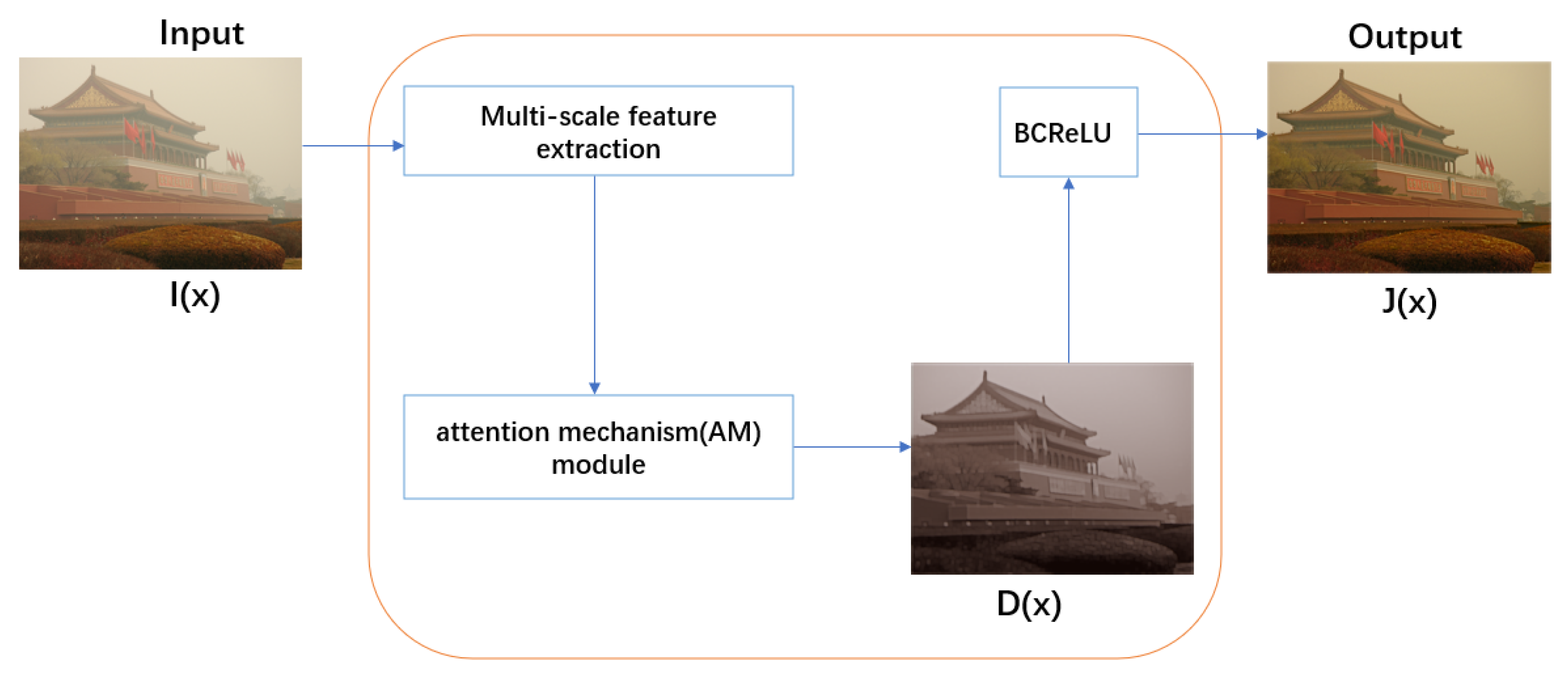
- IFE-Net directly produces the clean image from a hazy image, rather than estimating the transmission map and atmospheric light separately. All parameters of IFE-Net are estimated in a unified model.
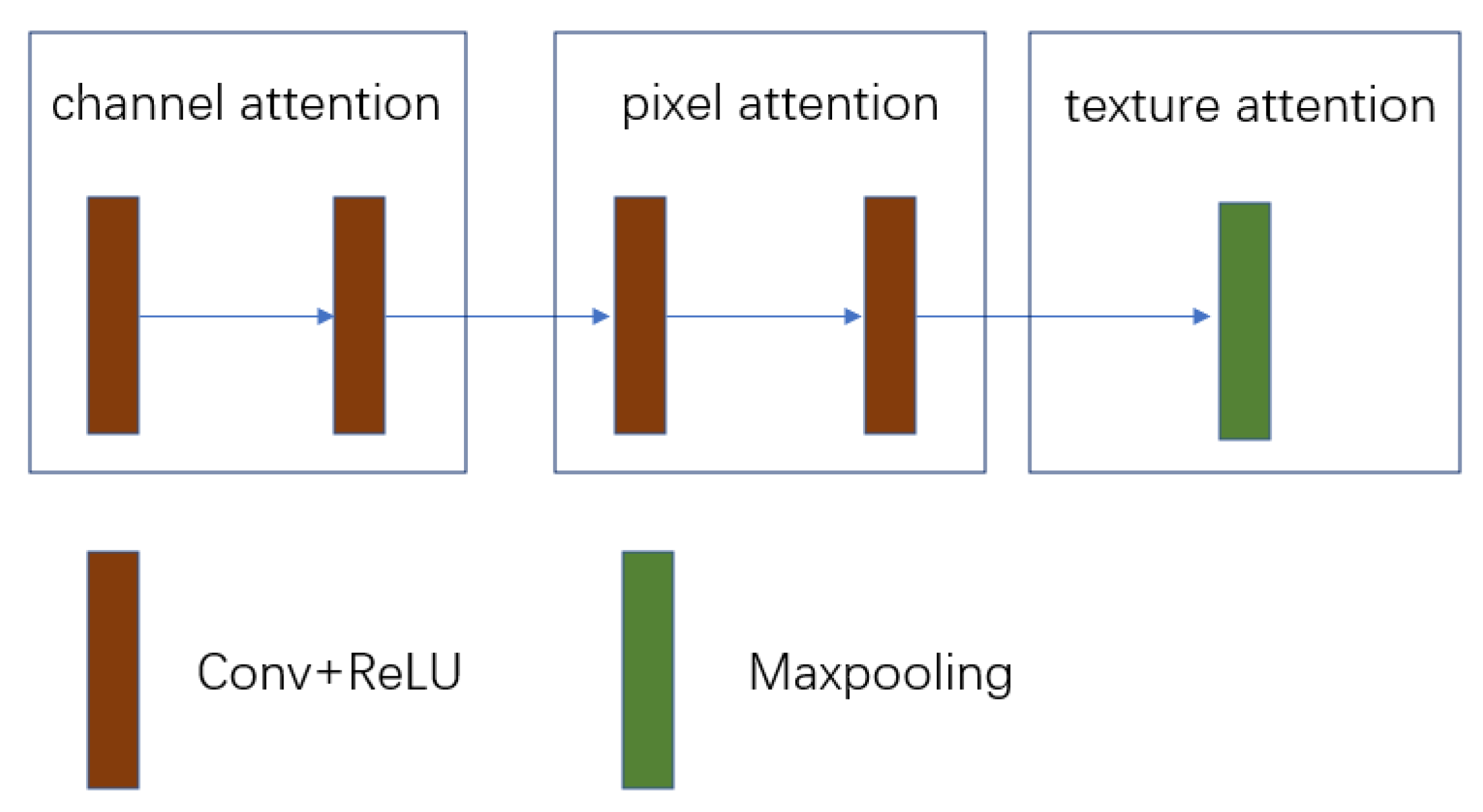
- We propose a novel attention mechanism (AM) module, which consists of a channel attention mechanism, pixel attention mechanism, and texture attention. This module has different weighted information for different features and focuses more on strong features in areas with thick haze.
- A bilateral constrained rectifier linear unit (BCReLU) is proposed in IFE-Net. To our knowledge, no one else has proposed BCReLU. Its significance in obtaining image restoration is demonstrated through experiments.
- The experiments show that IFE-Net performs well both qualitatively and quantitatively. The extensive experimental results also illustrate the effectiveness of IFE-Net.
2. Related Work
3. The Proposed Method
3.1. The Transformed Atmospheric Scattering Model
3.2. Network Design
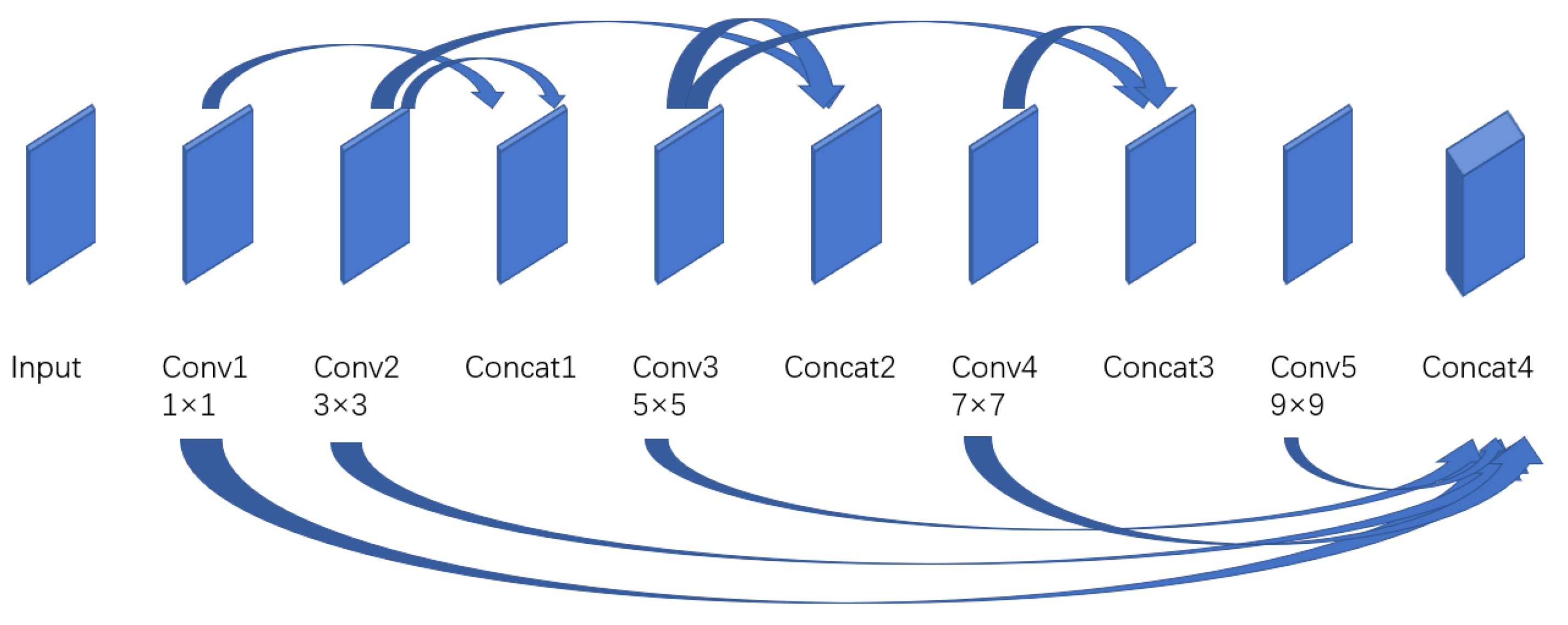
3.2.1. Multiscale Feature Extraction
3.2.2. Attention Mechanism
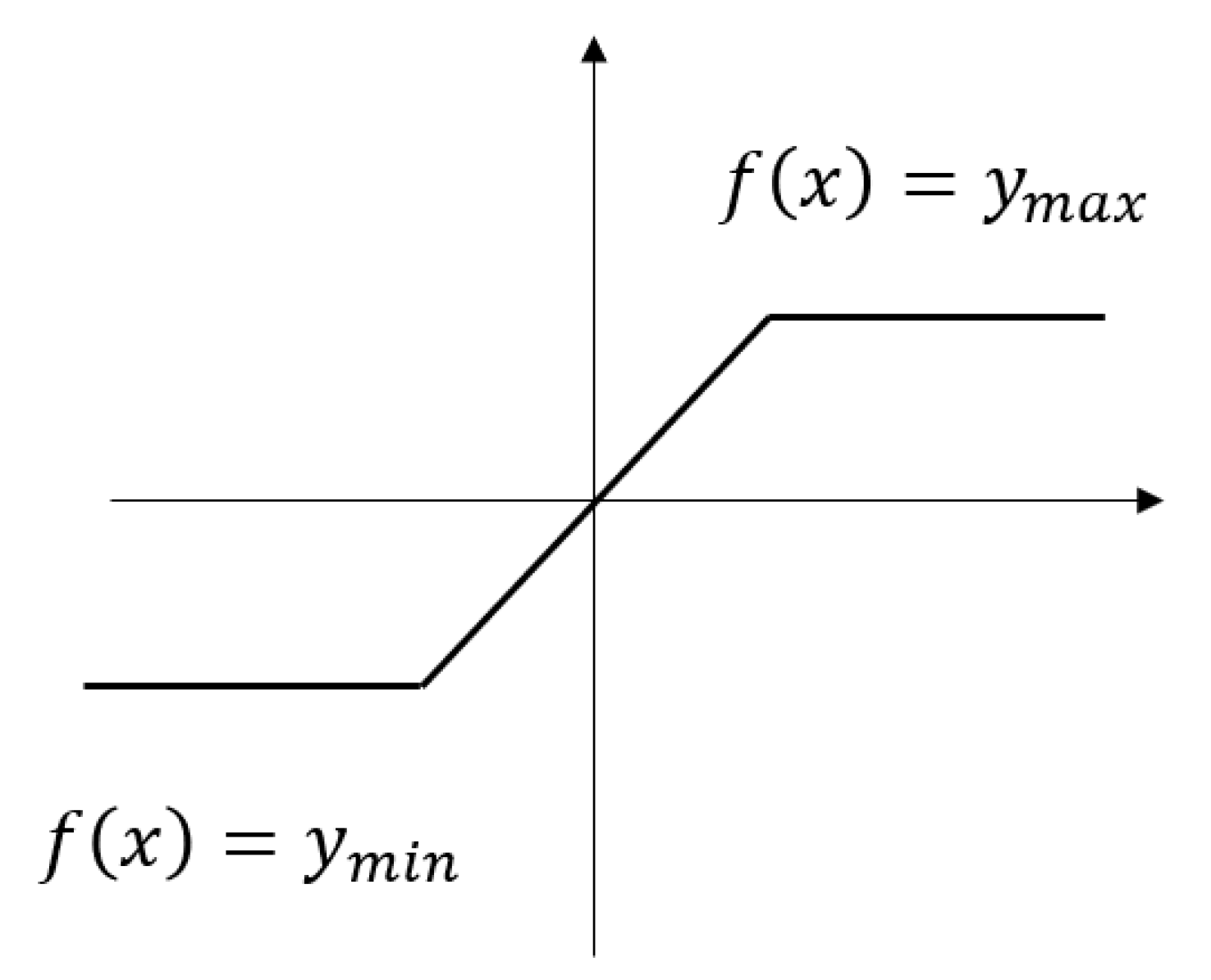
3.2.3. Bilateral Constrained Rectifier Linear Unit
4. Experiments
4.1. Datasets and Implementation Details
4.2. Quantitative Results on Synthetic Images
4.3. Qualitative Results on Real-World Images
4.4. Ablation Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cucchiara, R.; Grana, C.; Piccardi, M.; Prati, A. Detecting moving objects, ghosts, and shadows in video streams. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1337–1342. [Google Scholar] [CrossRef]
- Jung, C.R. Efficient background subtraction and shadow removal for monochromatic video sequences. IEEE Trans. Multimed. 2009, 11, 571–577. [Google Scholar] [CrossRef]
- Sanin, A.; Sanderson, C.; Lovell, B.C. Improved shadow removal for robust person tracking in surveillance scenarios. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 141–144. [Google Scholar]
- Zhang, W.; Zhao, X.; Morvan, J.; Chen, L. Improving shadow suppression for illumination robust face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 611–624. [Google Scholar] [CrossRef] [PubMed]
- Cartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley and Sons, Inc.: New York, NY, USA, 1976; 421p. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Chromatic framework for vision in bad weather. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2000 (Cat. No.PR00662), Hilton Head, SC, USA, 13–15 June 2020; Volume 1, pp. 598–605. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- Sulami, M.; Glatzer, I.; Fattal, R.; Werman, M. Automatic recovery of the atmospheric light in hazy images. In Proceedings of the Computational Photography (ICCP), Santa Clara, CA, USA, 2–4 May 2014; pp. 1–11. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Air-light estimation using haze-lines. In Proceedings of the Computational Photography (ICCP), Evanston, IL, USA, 13–15 May 2017; pp. 1–9. [Google Scholar]
- Vidyamol, K.; Prakash, M.S. An Improved Dark Channel Prior for Fast Dehazing of Outdoor Images. In Proceedings of the 2022 13th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 3–5 October 2022; pp. 1–6. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. PAMI 2011, 33, 2341–2353. [Google Scholar]
- Raikwar, S.; Tapaswi, S. Accurate and Robust Atmospheric Light Estimation for Single Image Dehazing. In Proceedings of the 2020 IEEE 7th Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), Prayagraj, India, 27–29 November 2020; pp. 1–4. [Google Scholar]
- Qasim, M.; Raja, G. SPIDE-Net: Spectral Prior-Based Image Dehazing and Enhancement Network. IEEE Access 2022, 10, 120296–120311. [Google Scholar] [CrossRef]
- Ajith, A.P.; Vidyamol, K.; Devassy, B.R.; Manju, P. Dark Channel Prior based Single Image Dehazing of Daylight Captures. In Proceedings of the 2023 Advanced Computing and Communication Technologies for High Performance Applications (ACCTHPA), Ernakulam, India, 20–21 January 2023; pp. 1–6. [Google Scholar]
- Sharma, T.; Nalla, B.T.; Verma, N.K.; Vasikarla, S. FR-HDNet: Faster RCNN based Haze Detection Network for Image Dehazing. In Proceedings of the 2022 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washinghton, DC, USA, 11–13 October 2022; pp. 1–8. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Joint transmission map estimation and dehazing using deep networks. arXiv 2017, arXiv:1708.00581. [Google Scholar] [CrossRef]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 2016; pp. 1674–1682. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Zhang, H.; Patel, M.V. Densely connected pyramid dehazing network. IEEE Conf. Comput. Vis. Pattern Recognit. 2008, 2008, 3194–3203. [Google Scholar]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated fusion network for single image dehazing. arXiv 2018, arXiv:1804.00213. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. An all-in-one network for dehazing and beyond. arXiv 2017, arXiv:1707.06543. [Google Scholar]
- Laha, S.; Foroosh, H. Haar Wavelet-Based Attention Network for Image Dehazing. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3948–3952. [Google Scholar]
- Raj, N.B.; Venketeswaran, N. Single Image Haze Removal using a Generative Adversarial Network. In Proceedings of the International Conference on Wireless Communications Signal Processing and Networking (WiSPNET), Chennai, India, 4–6 August 2018. [Google Scholar]
- Parihar, A.S.; Singh, K.; Ganotra, A.; Yadav, A. Contrast Aware Image Dehazing using Generative Adversarial Network. In Proceedings of the 2022 2nd International Conference on Intelligent Technologies (CONIT), Hubli, India, 25–27 June 2022; pp. 1–6. [Google Scholar]
- Bai, H.; Pan, J.; Xiang, X.; Tang, J. Self-guided image dehazing using progressive feature fusion. IEEE Trans. Image Process. 2022, 31, 1217–1229. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Grid dehazenet: Attention-based multi-scale network for image dehazing. ICCV 2019, 2019, 7314–7323. [Google Scholar]
- Dong, J.; Pan, J. Physics-Based Feature Dehazing Networks; Springer: Berlin/Heidelberg, Germany, 2020; pp. 188–204. [Google Scholar]
- Deng, Q.; Huang, Z.; Tsai, C.; Lin, C. Hardgan: A haze-Aware Representation Distillation Gan for Single Image Dehazing; Springer: Berlin/Heidelberg, Germany, 2020; pp. 722–738. [Google Scholar]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–21 June 2021; pp. 10551–10560. [Google Scholar]
- Wang, C.; Shen, H.; Fan, F.; Shao, M.; Yang, C.; Luo, J.; Deng, L. Eaa-net: A novel edge assisted attention network for single image dehazing. KBS 2021, 228, 107279. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef]
- Agrawal, S.C.; Jalal, A.S. Linear Fusion of Multi-Scale Transmissions for Image Dehazing. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–6. [Google Scholar]
- Ye, F.; Wu, K.; Zhang, R.; Wang, M.; Meng, X.; Li, D. Multi-Scale Feature Fusion Based on PVTv2 for Deep Hash Remote Sensing Image Retrieval. Remote Sens. 2023, 15, 4729. [Google Scholar] [CrossRef]
- Zong, P.; Li, J.; Hua, Z. Lightweight Multi-scale Attentional Network for Single Image Dehazing. In Proceedings of the 2022 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Xi’an, China, 28–30 October 2022; pp. 401–405. [Google Scholar]
- Shit, S.; Das, D.K.; Sur, A.; Ray, D.N.; Banik, B.C.; Rana, A. Encoder and Decoder-Based Feature Fusion Network for Single Image Dehazing. In Proceedings of the 2023 3rd International Conference on Artificial Intelligence and Signal Processing (AISP), Vijayawada, India, 18–20 March 2023; pp. 1–5. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature Fusion Attention Network for Single Image Dehazing. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11908–11915. [Google Scholar] [CrossRef]
- Tarel, J.P.; Hautiere, N. Fast visibility restoration from a single color or gray level image. In Proceedings of the IEEE 12th International Conference on Computer Vision, 29 September–2 October 2009; pp. 2201–2208. [Google Scholar]
- Wang, W.; Yuan, X.; Wu, X.; Liu, Y. Fast image dehazing method based on linear transformation. IEEE Trans. Multimedia 2017, 19, 1142–1155. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 154–169. [Google Scholar]
- Li, B.; Gou, Y.; Gu, S.; Liu, J.Z.; Zhou, J.T.; Peng, X. You only look yourself: Unsupervised and untrained single image dehazing neural network. Int. J. Comput. Vis. 2021, 129, 1754–1767. [Google Scholar] [CrossRef]
- Liu, J.; Liu, W.; Sun, J.; Zeng, T. Rank-one prior: Toward real-time scene recovery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 April 2021; pp. 14802–14810. [Google Scholar]
- Purkayastha, P.; Choudhary, M.S.; Kumar, M. Steerable Pyramid-based Multi-Scale Fusion Algorithm for Single Image Dehazing. In Proceedings of the 2023 International Conference on Device Intelligence, Computing and Communication Technologies, (DICCT), Dehradun, India, 17–18 March 2023; pp. 552–557. [Google Scholar]
- Zhao, L.; Zhang, Y.; Cui, Y. An attention encoder-decoder network based on generative adversarial network for remote sensing image dehazing. IEEE Sensors J. 2022, 22, 10890–10900. [Google Scholar] [CrossRef]
- Zhong, T.; Cheng, M.; Dong, X.; Wu, N. Seismic random noise attenuation by applying multiscale denoising convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Zhang, J.; Shao, M.; Wan, Z.; Li, Y. Multi-scale feature mapping network for hyperspectral image super-resolution. Remote. Sens. 2021, 13, 4180. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 5786. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Orr, G.B.; Müller, K. Efficient Backprop; Springer: Berlin/Heidelberg, Germany, 1998; pp. 9–48. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar]
- Fu, M.; Liu, H.; Yu, Y.; Chen, J.; Wang, K. DW-GAN: A Discrete Wavelet Transform GAN for NonHomogeneous Dehazing. arXiv 2021. [Google Scholar] [CrossRef]
- Song, Y.; Zhou, Y.; Qian, H.; Du, X. Rethinking Performance Gains in Image Dehazing Networks. arXiv 2022, arXiv:2209.11448. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking Single-Image Dehazing and Beyond. IEEE Trans. Image Process. 2019, 28, 492–505. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Indicators | ReLU | Tanh | Sigmoid | BCRelu |
|---|---|---|---|---|
| PSNR (SOTS) | 24.59 | 20.07 | 18.61 | 24.63 |
| SSIM (SOTS) | 0.904 | 0.901 | 0.859 | 0.905 |
| PSNR (ITS) | 25.31 | 23.97 | 22.21 | 25.62 |
| SSIM (ITS) | 0.905 | 0.924 | 0.902 | 0.925 |
| Evaluation Indicators | DCP | Dehaze-Net | AOD | FFA | GCA | DWGAN | GUNet | IFE |
|---|---|---|---|---|---|---|---|---|
| PSNR | 20.37 | 20.66 | 22.51 | 20.87 | 19.52 | 14.27 | 21.97 | 24.38 |
| SSIM | 0.913 | 0.886 | 0.928 | 0.909 | 0.902 | 0.815 | 0.921 | 0.942 |
| Evaluation Indicators | DCP | Dehaze-Net | AOD | FFA | GCA | DWGAN | GUNet | IFE |
|---|---|---|---|---|---|---|---|---|
| PSNR | 21.37 | 21.34 | 22.12 | 21.31 | 23.05 | 20.56 | 19.382 | 24.63 |
| SSIM | 0.892 | 0.857 | 0.903 | 0.881 | 0.889 | 0.901 | 0.924 | 0.905 |
| Evaluation Indicators | DCP | Dehaze-Net | AOD | FFA | GCA | DWGAN | GUNet | IFE |
|---|---|---|---|---|---|---|---|---|
| PSNR | 20.32 | 18.71 | 22.39 | 18.48 | 27.77 | 14.79 | 19.26 | 25.62 |
| SSIM | 0.887 | 0.888 | 0.917 | 0.887 | 0.936 | 0.850 | 0.899 | 0.925 |
| Metrics | DCP | Dehaze-Net | AOD | FFA | GCA | DWGAN | GUNet | IFE |
|---|---|---|---|---|---|---|---|---|
| Time (In seconds) | 0.1294 | 0.6221 | 0.0194 | 0.6089 | 0.0592 | 0.1330 | 0.1106 | 0.0249 |
| Dataset | SOTS | ITS | ||
|---|---|---|---|---|
| Metric | PSNR | SSIM | PSNR | SSIM |
| AOD | 22.12 | 0.903 | 22.39 | 0.917 |
| AOD + AM | 24.13 | 0.904 | 23.99 | 0.920 |
| IFE without AM | 23.16 | 0.902 | 23.77 | 0.921 |
| IFE + AM | 24.63 | 0.905 | 25.62 | 0.925 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leng, C.; Liu, G. IFE-Net: An Integrated Feature Extraction Network for Single-Image Dehazing. Appl. Sci. 2023, 13, 12236. https://doi.org/10.3390/app132212236
Leng C, Liu G. IFE-Net: An Integrated Feature Extraction Network for Single-Image Dehazing. Applied Sciences. 2023; 13(22):12236. https://doi.org/10.3390/app132212236
Chicago/Turabian StyleLeng, Can, and Gang Liu. 2023. "IFE-Net: An Integrated Feature Extraction Network for Single-Image Dehazing" Applied Sciences 13, no. 22: 12236. https://doi.org/10.3390/app132212236
APA StyleLeng, C., & Liu, G. (2023). IFE-Net: An Integrated Feature Extraction Network for Single-Image Dehazing. Applied Sciences, 13(22), 12236. https://doi.org/10.3390/app132212236