In this section, we first present the utilized data, evaluation metrics, and experimental setting. Then, we conduct experiments to answer the following questions:
6.3. Evaluation Metrics
The standard metrics widely used for evaluating the performance of classification models include
precision (
P),
recall (
R),
F1-score (
F1), and
accuracy. Given the built emotion recognition model and the set of emotion classes
M, we can compute the evaluation metrics to evaluate the model’s performance with respect to each emotion label
m as outlined below:
where
represents the true positives, signifying the number of examples in the dataset correctly identified by the model as emotion
m, while
represents the true negatives, denoting the number of examples correctly identified by the model as
not belonging to emotion
m. On the other hand,
denotes the false positives, indicating the number of examples incorrectly labeled by the model as emotion
m, and
represents the false negatives, signifying the number of examples erroneously labeled by the model as
not belonging to emotion
m.
The F1-score is a balanced performance metric that calculates the harmonic mean of precision and recall. The equation of the F1-score is:
To evaluate the overall performance of the models we developed in our experiments and to compare their performance with state-of-the-art methods from the literature, we must assess the model’s performance across multiple metrics. These metrics include accuracy, as well as the macro average, micro average, and weighted average of three key metrics: precision, recall, and F1-score. This is conducted as follows:
The macro average for the
precision,
recall, and
F1-score metrics are determined by computing the average of these metrics for each emotion class separately, assigning equal importance to each class. This method treats every emotion class equally, regardless of its frequency, and the calculations are carried out using the following formulas:
where
denotes the total number of emotion classes present in the dataset.
The micro average focuses on the overall performance across all classes, with a significant emphasis on dominant classes, assigning them greater weight. The calculations for the micro average are determined by the following formulas:
The weighted average considers the proportion of each emotion class when computing the metric averages. It strikes a balance between micro and macro averaging, taking into account both the overall performance and the significance of each class. These calculations are determined using the following formulas:
where
represents the total number of examples in the dataset belonging to the emotion class
m and
denotes the summation of the total examples for each emotion class in the dataset, which is equal to the dataset’s overall size.
6.4. Experimental Setup
Regarding our experiments involving self-training, we set the number of iterations to 20, and in each iteration, a sample of 3000 unlabeled data was automatically annotated.
We evaluated the efficiency of our proposed method in the context of Arabic emotion recognition; therefore, we selected pretrained language models specifically tailored for the Arabic language. The chosen models were pretrained on a substantial corpus of Arabic text, encompassing both MSA and dialectal Arabic.
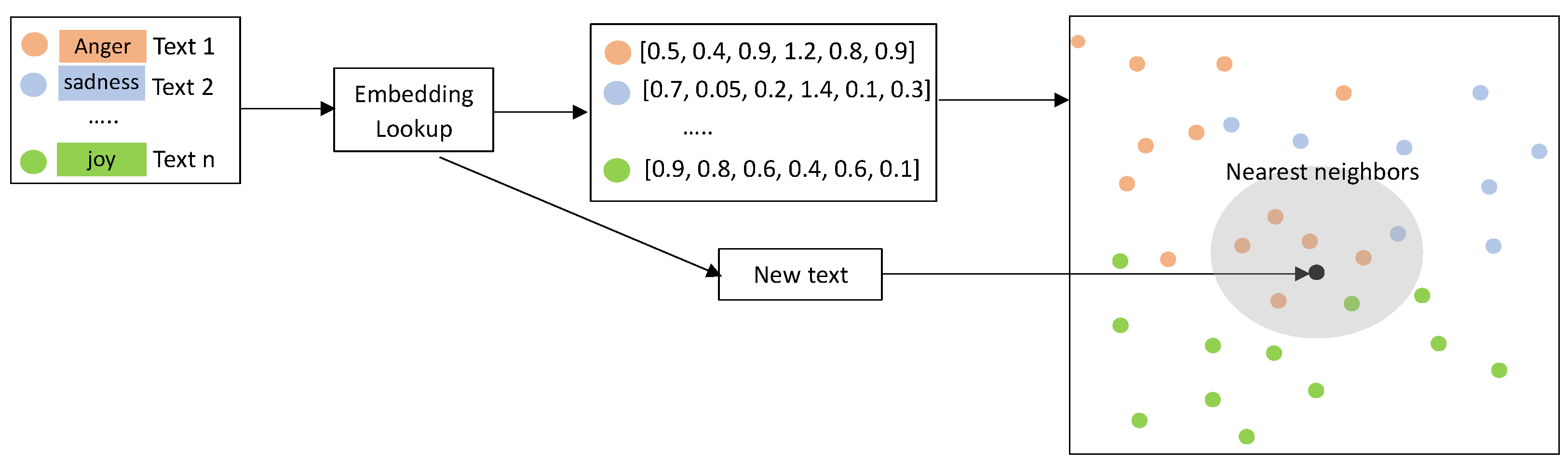
For few-shot models, particularly in one of the methods utilized in our study, the nearest neighbor embedding lookup method, we selected the MARBERTv2 large model [
56] as a pretrained model. This model was employed to generate a single embedding vector for each text in the training dataset. In order to perform similarity searches of the embeddings, we used the FAISS index, an index created and managed using the Facebook AI Similarity Search (FAISS) library [
100], which presents efficient algorithms to quickly search and cluster embedding vectors [
78]. In the data augmentation technique, sentence transformations such as word swaps and deletions were randomly carried out using the
NLPAug Python library. Additionally, contextual word embeddings of a language model were leveraged to introduce modifications to sentences, including synonym replacement and word insertion. The AraBERTv0.2-Twitter model [
51] was utilized for this purpose. We intentionally opted for a different model than the one used in the aforementioned embedding lookup method, with the aim of increasing the variety among the models used. For back translation, neural machine translation models were used to translate between Arabic (ar) and English (en) in both directions. Specifically, the
OPUS-MT-tc-big-ar-en and
OPUS-MT-tc-big-en-ar models were utilized for these translations [
101,
102].
For zero-shot classification, we utilized the XLM-RoBERTa-large-xnli model as a text entailment model. This model was built by fine-tuning the XLM-RoBERTa-large model [
103] on a combination of XNLI data in 15 languages, including Arabic. The XLM-RoBERTa-large model itself is a multilingual language model pretrained on text in 100 languages.
To apply transfer learning and construct a fine-tuned model for our proposed approach, depicted in
Figure 2, we conducted fine-tuning of the AraBERTv0.2-Twitter model [
51] on the training set in our experiments.
We utilized scikit-learn to construct machine learning models, specifically SVM, Naive Bayes, and Logistic Regression. In the case of multinomial Naive Bayes, we employed an additive smoothing parameter (alpha) set to 1. For Logistic Regression, we set the regularization parameter (C) to 0.01. As for SVM, we configured the regularization parameter (C) to 1, the kernel to ‘rbf’ (radial basis function), and the gamma to ‘scale’.
We determined the training and test sets from each labeled dataset as follows:
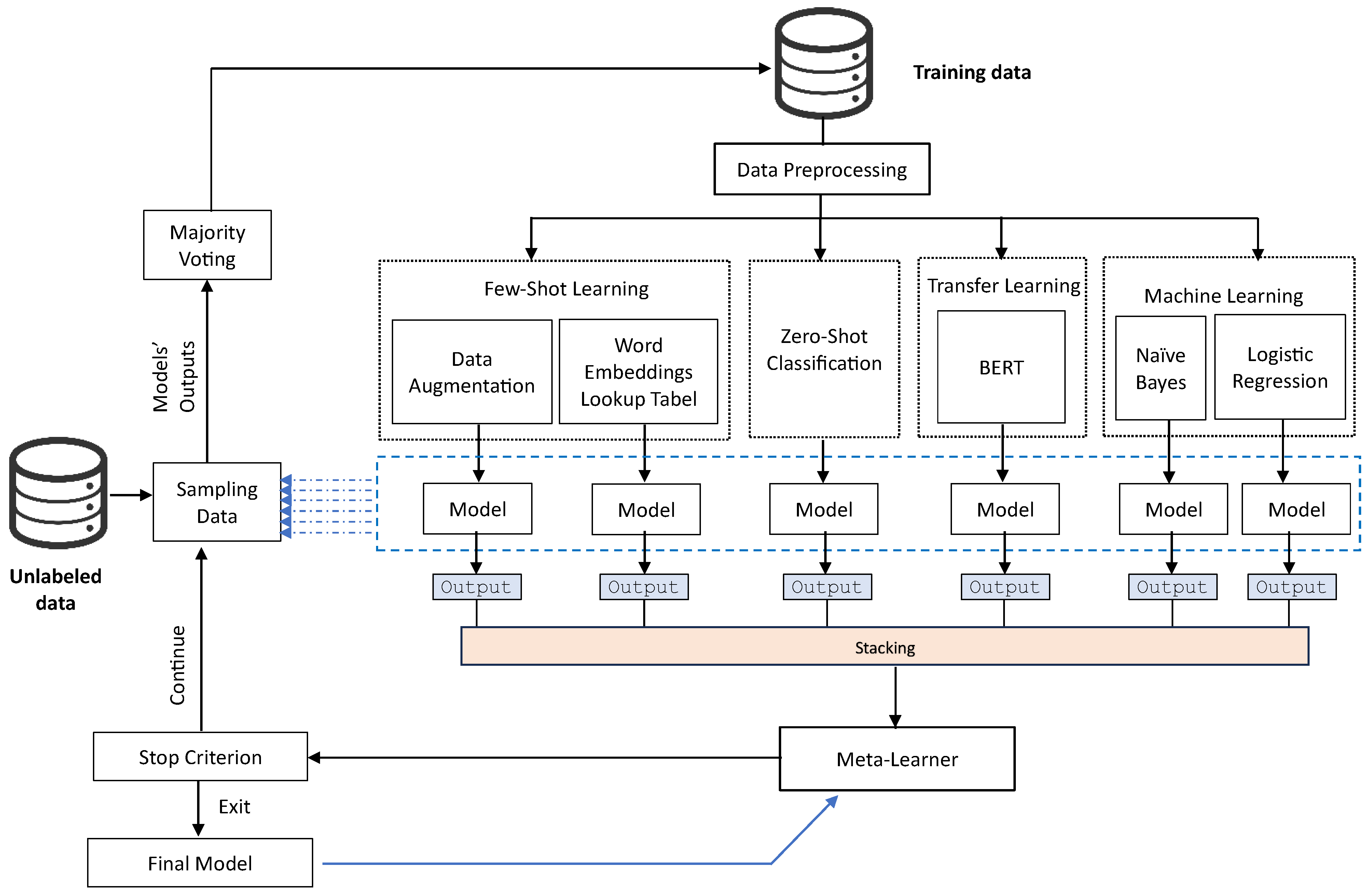
Training: Our proposed method does not require a large amount of labeled data to initiate the algorithm, as illustrated in
Figure 2. It only necessitates a small number of labeled examples to initiate the training process. Consequently, we selected only 10 examples per emotion class from each dataset as a starting point. Therefore, for ArPanEmo (which has 11 classes), we initiated with 110 labeled examples, while for AETD (with 8 classes), we initiated the training process of our proposed method with 80 labeled examples. Bear in mind that during iterations, more training examples are added from unlabeled data after being auto-labeled using the six base models and majority voting, as explained in
Section 6.1.
To train the meta-learner in our proposed method, we applied a 2-fold cross-validation, where the six base models were trained on one fold and the second fold was used to generate predictions. The predictions made by the six base classifiers on the entire training dataset were employed as input features to train the meta-learner, as explained in
Section 4.
Test: To evaluate our proposed method on the ArPanEmo dataset, we utilized a holdout test set. The set of ArPanEmo for testing was originally specified and released with the dataset by [
62], allocating 20% of the dataset for the test set, which contains 2227 tweets. Regarding the AETD dataset, the exact set for testing is not specified by [
39]. Therefore, we employed a 5-fold cross-validation approach for evaluating the data (not for training). This involved removing the 80 examples used in the training data, as mentioned earlier, and dividing the remaining AETD dataset into 5 folds. We then evaluated our proposed method on each fold and computed the average evaluation metrics. This allowed us to compare the performance of our proposed method with methods in the literature that utilized ArPanEmo and AETD for evaluation.
The PC used for conducting the experiments has a GPU (Nvidia GeForce RTX 3070), CPU @ 4.01 GHz, RAM with 32.0 GB, and a 952 GB SSD hard disk.
6.6. Ablation Experiments (RQ2)
Our proposed method depends on two main components: (a) a stacking ensemble model that combines the predictions from diverse models employing various learning paradigms, and (b) self-training using majority voting among the diverse models to automatically expand the set of labeled training data, as shown in
Figure 1. In order to dissect the impact of these two components and provide a deeper understanding of their individual contributions to the overall results, we conducted ablation experiments.
In the first experiment, we examined the influence of the stacking ensemble model. We utilized the complete manually labeled training data of the benchmark datasets (i.e., a high-resource scenario). In the second experiment, we conducted an analysis of the performance of self-training with majority voting, isolating it from the stacking ensemble model. During the self-training experiments, we did not use the entire set of training labeled data and, instead, initiated the training process with only 10 labeled examples per emotion class from the benchmark datasets.
In both ablation experiments, we developed six base classifiers, which included Naive Bayes, Logistic Regression, few-shot methods (i.e., nearest neighbor embedding lookup and data augmentation), a zero-shot classification model, and a transfer learning-based model using BERT. These diverse base classifiers are necessary for building both the stacking ensemble model and self-training with majority voting. Consequently, we also examined their performances in both settings (i.e., with stacking ensemble in a high-resource condition and with self-training using majority voting). The following subsections illustrate the results of the ablation study.
6.6.1. Analysis of Our Diverse Model Stacking Ensemble in a High-Resource Scenario
We developed a stacking ensemble of the aforementioned six base classifiers. All of these models were trained using the complete manually labeled training data of the benchmark datasets. The performance of the stacking ensemble model and that of the individual base classifiers on the AETD and ArPanEmo datasets is presented in
Table 8 and
Table 9, respectively.
The results obtained from both the AETD and ArPanEmo datasets clearly indicate that the stacking ensemble model effectively harnesses the strengths of all the base models when evaluated separately from self-training using the complete datasets of manually labeled data. When using transfer learning alone by fine-tuning the BERT-based model, a weighted average F1-score of 78.85% was achieved on the AETD dataset. On the other hand, training an emotion recognizer using the Naive Bayes algorithm and the AETD dataset resulted in a weighted average F1-score of 65.41%. However, the stacking ensemble of diverse models outperformed these individual models, achieving a weighted average F1-score of 80.77% on the AETD dataset.
The overall performance of the stacking ensemble model on ArPanEmo, as shown in
Table 9, does not differ from that when using AETD dataset. The stacking ensemble model outperformed all six base classifiers, achieving a weighted average F1-score equal to 69.07%. This indicates that the meta-learner, which resulted from learning and combining the predictions of multiple base classifiers, yields superior results and improves predictive performance by leveraging the strengths of these base classifiers.
6.6.2. Analysis of Self-Training with Majority Voting
Regarding the second component of our proposed method, which is self-training with majority voting, as previously mentioned, we initiated the training process with only 10 labeled examples per emotion class from the benchmark datasets. In each iteration, additional data were automatically labeled by the base classifiers and incorporated into the training data through majority voting. Specifically, new data with its predictions were considered confident and included in the training dataset for subsequent iterations if at least 5 out of the 6 classifiers reached a consensus on its prediction.
Table 10 and
Table 11 show the performance of self-training with majority voting on the AETD and ArPanEmo datasets.
Self-training with majority voting obviously demonstrated improved results compared to most individual base classifiers but fell short of the performance achieved by the fine-tuned BERT model. It yielded a weighted average F1-score of 78.12% on the AETD dataset, whereas the BERT model achieved a higher weighted average F1-score of 81.66%. The same results can be noticed when evaluating self-training on ArPanEmo, where the weighted average F1-score was 67.39%, while the fine-tuned BERT model outperformed it with a weighted average F1-score of 69.08%.
When comparing self-training with the stacking ensemble, it is evident that self-training with majority voting yielded a lower weighted average F1-score than the stacking ensemble model. This indicates the stacking ensemble model’s ability to effectively leverage the strengths of the six base classifiers. However, it is worth noting that the F1-score of 78.12% achieved by self-training is still a good result, especially considering that self-training with majority voting initiates the training process with a limited number of manually labeled examples. On the other hand, the precision of self-training with majority voting is 79.64% on the AETD dataset, which is higher than the recall of 76.65%. This may be partially attributed to our strict condition for accepting a newly annotated label in majority voting, where it must receive the consensus of at least 5 out of the 6 votes from the base classifiers.
Self-training with majority voting obviously produces better results compared to five of the six base classifiers, falling about 1 to 3 points behind the fine-tuned BERT model. Nevertheless, self-training offers the advantage of gradually expanding the labeled data with minimal human intervention over iterations. On the other hand, the stacking ensemble of diverse models demonstrates more effective harnessing of the individual base models’ strengths than self-training in terms of the final predictive performance. In our proposed method, we integrate the stacking ensemble model with self-training to exploit self-training’s ability to automatically increase labeled data and the efficiency of the stacking ensemble model when combining predictions from a diverse set of base models. Our approach is specifically designed for low-resource settings, where labeled data are limited. Thus, the next section delves into the examination of our proposed approach in low-resource scenarios.
6.7. Low-Resource Scenarios (RQ3)
This section conducts a comparative analysis of our proposed method’s performance in low-resource scenarios against the six base models. As previously explained, these base models include Naive Bayes, Logistic Regression, few-shot learning methods (i.e., nearest neighbor embedding lookup and data augmentation), a zero-shot classification model, and transfer learning (BERT-based models).
We initiated the training process of our proposed method with 80 labeled examples (10 examples per emotion class) from the AETD dataset.
Table 12 shows the results of our proposed method on the AETD test set at the beginning stage using only the 10 examples per emotion class without going through iterations using self-training. The table also compares our proposed method with each base model in a low-resource setting.
The results show the impact of the first component of our proposed method, where a stacking ensemble model that combines different models is used on a limited amount of labeled data. We can see that our proposed method achieved the highest performance, with an accuracy of 39.96% and a weighted average F1-score of 39.47%. The second-best performing approach is the zero-shot model, which resulted in an accuracy of 37.5% and a weighted average F1-score of 33.27%. Next in line are the ML algorithms and few-shot learning methods. In the third, fourth, fifth, and sixth places are Logistic Regression, Naive Bayes, the embedding lookup method, and the data augmentation method, with weighted average F1-scores equal to 33.73%, 32.92%, 31.21%, and 21.88%, respectively. In terms of weighted average precision, the few-shot learning method, namely embedding lookup, achieved a higher result, equal to 35.58%, compared to the other few-shot learning method (i.e., data augmentation) and the other two ML algorithms (i.e., Naive Bayes and Logistic Regression).
The lowest results were obtained when using transfer learning to fine-tune a model on a small amount of labeled data. The fine-tuned BERT model yielded a weighted average F1-score, precision, and recall of 11.14%, 20.09%, and 15.63%, respectively. The accuracy was also equal to 15.63%.
At the end of the training (i.e., after 20 iterations of self-training), the size of the training data had expanded from 80 to 22,544 examples. At this final stage, our proposed method still achieved the highest performance in all evaluation metrics compared to other approaches. Specifically, the accuracy, weighted average F1-score, precision, and recall were all equal to 83.15%, 83.19%, 83.31%, and 83.15%, respectively.
Table 13 displays the results of our proposed method and other methods at the final stage after completing the 20 iterations on the test set.
The second-best performing model was not the zero-shot model, as it was in the first stage when starting with a low-resource setting (i.e., the start point with limited labeled data). Indeed, the second-best performing model in the final stage was the fine-tuned BERT-based model, which achieved an accuracy of 81.65%, along with a weighted average F1-score of 81.66%, precision of 81.73%, and recall of 81.86%. On the other hand, in the final stage, the zero-shot model ranked last, with an accuracy of 34.03% and a weighted average F1-score, precision, and recall of 30.93%, 42.67%, and 34.03%, respectively.
The performance of ML algorithms in the final stage was enhanced. Naive Bayes and Logistic Regression achieved weighted average F1-scores of 68.94% and 63.63%, respectively, showing an increase of 36.02% and 29.9% from the first stage. The few-shot models also demonstrated improvement after 20 iterations compared to the results they obtained in the first stage, achieving a weighted average F1-score of 58.28% and 63.56% for the embedding lookup and data augmentation methods, respectively.
Regarding the ArPanEmo dataset, all methods, including our proposed approach, were trained on a small number of labeled data (10 examples per class, resulting in 110 labeled examples from ArPanEmo). At this stage, no iterations were applied.
Table 14 shows the results of our proposed method and the other methods when trained on a small number of labeled data.
Our proposed method achieved the highest performance, with an accuracy of 31.53%. The weighted average F1-score, precision, and recall were 31.24%, 31.47%, and 31.53%, respectively. The second-best performing model was the zero-shot classification method, with an accuracy of 26.36%. The data augmentation method ranked third, with an accuracy of 25.04% and a weighted average F1-score of 24.42%. The model with the lowest performance when trained on a small number of labeled data was the fine-tuned BERT-based model, which achieved an accuracy of 14.03% and a weighted average F1-score of 9.15%.
Increasing the number of labeled training examples using self-training improved the overall performance of all models. At the final stage of training, when reaching the 20th iteration, the number of training examples increased to 21,135 labeled examples. The most significant positive impact was on the performance of our proposed approach, with accuracy increasing to 72.28%, while the weighted average F1-score, precision, and recall were 72.12%, 72.81%, and 72.28%, respectively.
Table 15 displays the performance results of our proposed model on a large amount of automatically labeled data, as well as the results of the other models.
The second-best performing model was the fine-tuned BERT-based model on the 21K examples. The ML algorithms and few-shot methods ranked third, fourth, fifth, and sixth. The last model with the lowest values of evaluation metrics was the zero-shot model, which achieved an accuracy of 24.54%, while the weighted average F1-score, precision, and recall were 21.20%, 30.72%, and 24.54%, respectively.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}