1. Introduction
Severe weather and extreme terrain bring great challenges to long-distance transmission lines, and mechanical failures of transmission towers will lead to serious economic losses and even threaten personal safety. The excessive stress on the towers of transmission lines is the root cause of tower overturning and tower collapse [
1]. To obtain the size of the tower strain, Huang et al. of Xi’an Engineering University proposed a method based on a fiber optic grating sensor for tower stress monitoring of transmission lines, which mainly uses a grating fiber sensor attached to the surface of the measured pole and determines the size of the stress change by measuring the grating reflection wavelength or transmission wavelength. This method involves the preparation, laying, and demodulation of grating fiber, which makes its cost too high [
2]. Xiong et al. of Changsha College used BeiDou differential positioning technology to monitor the size and direction of key pole and node displacements. However, it is difficult to achieve accurate monitoring of small deformations of pylons with the current satellite positioning technology, and the supplementation of other sensors, such as tilt sensors, is also needed [
3]. In this paper, we used multisensor fusion technology based on tilt sensors, wind speed sensors, and historical weather data to build a relevant dataset for analyzing tower fault information. The proposed system uses inclination sensors and wind direction sensors to measure tower data and, meanwhile, combines real-time weather data such as real-time temperature, humidity, and current rainfall to construct a dataset and train a support vector machine model to classify faults.
In this paper, we also predicted four types of faults: tower icing, conductor galloping, tower base settlement, and water corrosion. These faults are often accompanied by changes in the environmental characteristics around the tower, thus we selected temperature
, humidity
, wind direction
, wind
, rainfall (snow)
, water accumulation
, and tilt size
as the fault features and trained a classification model to classify the four faults: tower icing, conductor galloping, tower base settlement, and water corrosion [
4]. The sensor is supposed to collect a variety of data during the operation of the tower, and the vast majority of these data are generated during the normal operation of the tower, which will create two problems: first, the fault sample data is too small to completely cover all fault types; second, the amounts of fault data and normal operation data are unbalanced. Either problem will have a large negative impact on the accuracy of the machine learning process. The inadequacy of fault sample data can be compensated by extending the sampling time of the sensors, but this approach will further increase the imbalance of the data. Therefore, a data processing method that can improve the data balance is needed [
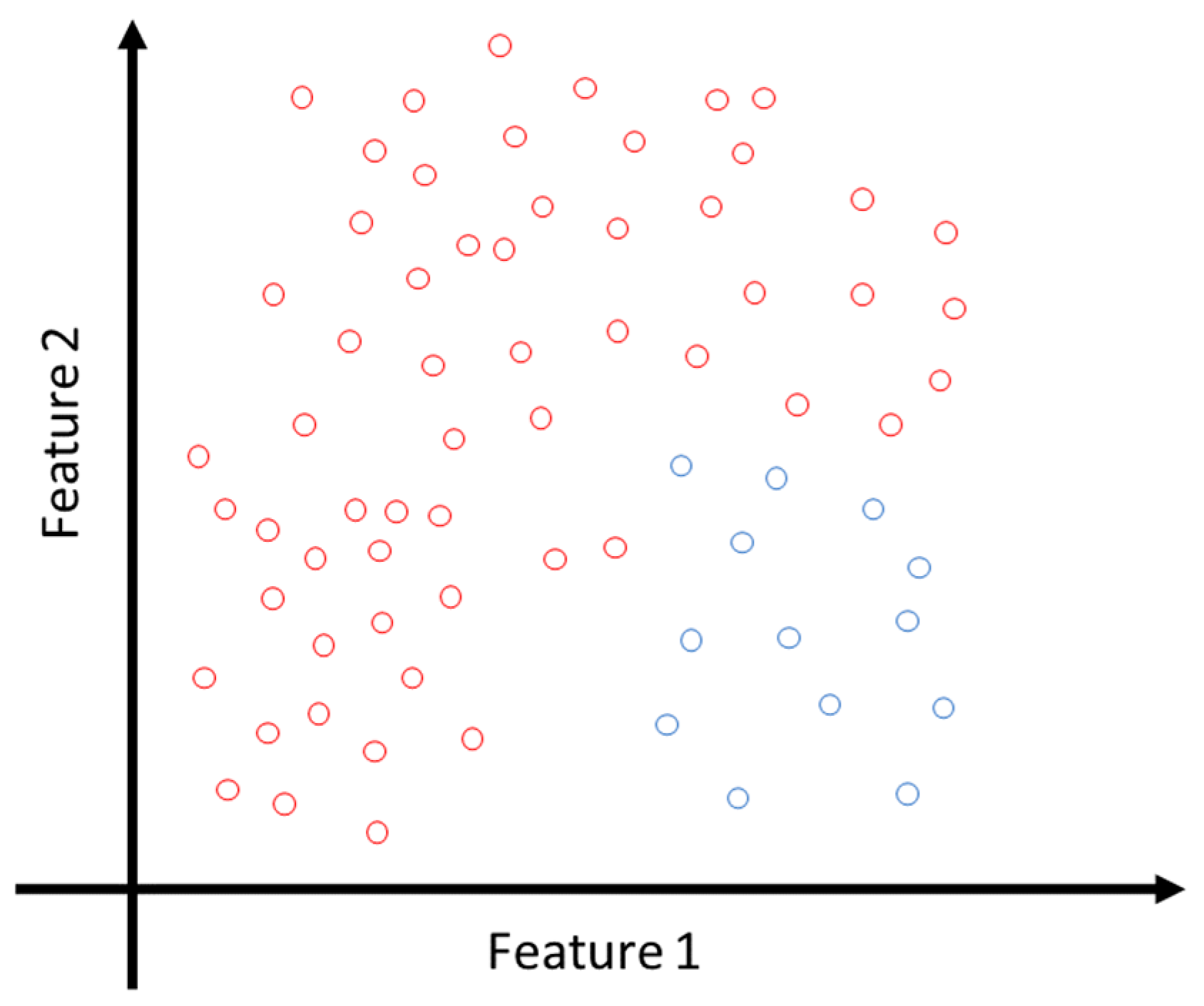
5]. This article uses the metrological data of imaging in the Jilin area provided by Jilin Provincial Metrological Bureau to build the fault sample. The fault sample dataset has seven features. However, in the image representation, in order to intuitively represent the unbalanced dataset, only two-dimensional images can be drawn here. The two-dimensional characteristics of positive and negative samples in the fault sample data are selected here, and the unbalanced two-dimensional dataset in two-dimensional coordinates is drawn in
Figure 1, which shows the representation of an unbalanced 2D dataset in 2D coordinates.
For most datasets, there are two general ways to improve data balance: the oversampling method and the undersampling method. Oversampling is to repeat positive proportional data for categories with small sample numbers, and undersampling is to discard a portion of the data for sample species with a larger number of samples, thus making the number of samples under each category equal, such as with the K-nearest neighbor (KNN) algorithm and boosting algorithms [
6]. Traditional oversampling techniques use random sampling, which simply copies the sample data to make the number of samples increase rapidly. This approach may cause overfitting problems: as the number of replicates of the samples increases, the error information in the samples will also be amplified, thus making the model in the learning process continue to fit the error information. The information learned from such models is too specific and insufficient, thus it will appear that the training set works well, but the test set works poorly [
7]. In this paper, the SMOTE algorithm as improved based on the stochastic process is used. Its basic idea is to analyze the minority class samples and synthesize new samples via manual interpolation based on the characteristics of the minority class samples to increase the balance of the dataset.
Figure 2 shows the process of a random selection of proximal points by using the SMOTE algorithm and the process of randomly generating new samples at the proximity point using the SMOTE algorithm.
Support vector machine theory first came from statistics as a binary linear classifier. In 1992, kernel methods were proposed by Bernhard E. Boser, Isabelle M. Guyon, and Vapnik. The introduction of kernel functions made support vector machine theory available for solving nonlinear classification problems [
8].
Support vector machines are essentially binary classifiers, and when dealing with multiclassification problems, their algorithms must be improved. Currently, there are two methods for multiclassification using support vector machines: the direct method and the indirect method. The direct method directly modifies the objective function and combines the parameter solutions of multiple classification surfaces into one optimization problem and achieves multiclass classification by solving that optimization problem at once. This method is simple in principle but not easy to implement, and it is only applicable to small- and medium-sized problems and cannot be applied on a large scale. Indirect methods, i.e., constructing multiple binary solvers to transform a multiclassification problem into multiple binary problems, are more widely used, such as the one-vs-one method, the one-vs-all method, the derived directed acyclic graph method, and the binary tree method [
9,
10,
11].
The one-vs-one method constructs a binary classifier in any two classes of training samples, and for the
-class classification problem, the one-vs-one method constructs
binary classifiers. The one-vs-all method treats each class of samples as one positive sample and the remaining samples as negative samples, thus for the
-class classification problem, the one-vs-all method must only construct
binary classifiers. Compared with the one-vs-one method, the computational effort of the one-vs-all method is much smaller than that of the one-vs-one method, but there are certain disadvantages of the one-vs-all method in solving the classification problem, such as the unbalanced number of positive and negative samples, the need to train all models when adding new categories or other elements, and the existence of some areas in which the samples within its range meet two or more hyperplane equations at the same time.
Figure 3 show the classification schematics of the same set of two-dimensional data under the one-vs-one and one-vs-all methods, respectively. Under the premise of classification by using the one-vs-all method, there exist two classes of transition areas between hyperplanes [
12,
13]. For these areas, some discriminative methods are proposed, such as a “voting” scheme, in which the area is marked as the category with the highest number of points [
14].
In the literature [
15], a discrimination method for such transition areas was proposed: for sample points in a transition area, the class to which the sample belongs can be determined from the distance between the sample and two adjacent hyperplanes. Islam et al. concluded that in the transition area, the feature points belonging to the class are instead more distant than the hyperplanes of the class. This discriminative method, compared with the previous discriminative methods, no longer assigns the transition area to a certain class completely but divides it specifically according to the actual situation, which improves classification accuracy and precision to a certain extent. However, this method must discriminate each feature sample in the transition area in a targeted manner, and when the number of feature samples in the area is large or the number of sample classes is large, this method is not efficient. A one-time means is still needed to solve the problem.
Based on the method proposed in the literature [
15], this paper proposes a CSH-SVM improvement algorithm that no longer calculates the distance between each sample located in the transition interval and the adjacent hyperplane. The transition interval is partitioned with the existing hyperplane equation to form a new hyperplane equation. Combined with the SMOTE algorithm to process the unbalanced samples, the four conditions of tower icing, conductor galloping, tower base settlement, and water corrosion are finally classified and predicted, and preventive measures can be taken when the tower has mechanical failure precursors. This improved algorithm has a faster response speed for the classification prediction of new samples because it no longer calculates the distance between samples and hyperplane frequently. On the premise of reducing the amount of calculation, it has better classification efficacy, which can well solve the problem of fault prediction and classification in practical engineering applications, thus improving the safety and service life of monitoring objects as well as reducing the loss of personnel and property.
2. Tower Mechanical Structure Modeling
The tilt sensor should be placed at the location where the displacement changes the most when the tower is deformed, and a finite element model of the tower must be constructed to achieve this purpose. First, the design modeler was used to modeling the mechanical structure of the tower, and the mechanical model was input to ANSYS Workbench platform for finite element analysis of the tower’s mechanical structure. Through the finite element analysis results, the placement position of the tilt sensor was analyzed to achieve the best monitoring effect [
16].
Taking the MZ2-27 cathead linear tower as an example, the main material of the tower adopts angle steel as the material, the main material is Q345 steel, and the oblique material is Q235 steel. These relevant material parameters were imported into the design modeler, and the bolts were used to attach the main material and the oblique material, which can eliminate part of the stress generated by the tower vibration and reduce the shaking amplitude of the tower. Therefore, the tower cannot be regarded as a truss structure but should be simulated and analyzed as a mixed steel frame and truss structure. The parameters related to the main material and diagonal material are shown in
Table 1.
Usually, the main material is regarded as a beam structure, which not only bears axial pressure and tension but also bends at a certain degree; the oblique material is regarded as a rod structure, which only bears axial strain and theoretically does not produce bending. Different from the classic ANSYS version, the Workbench platform set the line body as a beam element by default and eliminated the direct switch between beam element and rod element. Therefore, two solutions are proposed in this paper: one is to force the unit type of the oblique material to change to a Link180 unit through the command flow; the other is to use the beam unit instead of the rod unit and set the connection nodes on both sides of the beam unit to be hinged, releasing the rotation degrees of freedom in three directions to achieve accurate modeling. Because the oblique material of the tower generating a small bending moment is more realistic, and because the cross-sectional area of the line body must be recalculated if Method 1 is adopted, Method 2 was chosen for the mixed modeling of the truss and rigid frame.
The MZ2-27 cat-head-type linear tower is an overhanging tower. The force characteristic of the overhanging tower is that both sides of the conductor are not broken, thus the load of an overhanging tower is mainly composed of the wind load and ice load. Wind load includes line wind load, tower wind load, and insulator string wind load, and ice load mainly refers to the ice load of the conductor and the ground wire. In the Workbench platform, the stress of the tower under each working condition was calculated, and the load under each working condition was calculated by taking the wind speed of 10m/s and the conductor and ground wire’s icing thickness of 20mm as an example [
17]. Relevant calculation formulas for line wind load, tower wind load, and insulator string wind load are provided in the literature [
18].
The formula for calculating the line wind load is as follows:
where
is the standard value of horizontal wind load (kN) perpendicular to the wire and ground direction;
is the wind pressure unevenness coefficient;
is the wind pressure height variation coefficient;
is the body coefficient of the conductor or ground;
is the wind load adjustment coefficient of the conductor and ground of the 500 kV and 750 kV lines;
is the outer diameter of the conductor, ground, or the calculated outer diameter when icing (m);
is the pole tower horizontal distance (m);
is the guide, ground, and insulator string ice wind load increase factor;
is the angle between the wind direction and the direction of the wire or ground (°);
is the standard value of the base wind pressure (kN);
is the wind speed at the base height of 10 m (m/s).
The formula for calculating the wind load on the tower is as follows:
where
is the standard value of the tower wind load (kN);
is the body type coefficient of the member;
is the increase coefficient of the wind load of the tower member over ice;
is the calculated value of the projected area of the windward side member (m
2);
is the wind load adjustment coefficient of the tower.
The formula for calculating insulator string wind load is as follows:
where
is the insulator string wind load standard value (kN);
is the calculated value of insulator string bearing wind pressure area (m
2).
The wire and ground wire ice loads are related to the maximum tension of the conductor and ground wire. The values of the conductor and ground wire ice load under a 20 mm icing degree are shown in
Table 2 [
19,
20,
21]. The calculation formula of the maximum tension of conductor and ground wire is as follows:
where
is the maximum tension of the wire and ground wire;
is the calculated pull-off force of the wire and ground wire;
is the safety factor of the wire and ground wire;
is the new line coefficient, which is usually 0.95 in conservative calculations.
The MZ2-27 cat-head-type linear tower is an overhanging tower with bifurcated wire. The tower under a 20 mm icing degree carries 50% of the maximum tension of the conductor and 100% of the maximum tension of the ground wire.
The ice-covered load of the tower is the gross value of the wire icing load and ground wire icing load. Thus, the formula for the ice-covered load of the tower can be derived as follows:
where
is the standard value of the ice load (kN);
is the calculated pull-off force of the wire (kN);
is the safety coefficient of the wire;
is the calculated pull-off force of the ground wire (kN);
is the safety coefficient of the ground wire.
The results of the equivalent force analysis are shown in
Figure 4. According to the calculation, the equivalent stress of the MZ2-27 cat-head type linear tower ranges from about 254.02 MPa to 317.52 Mpa, the maximum displacement point is 18.4 mm, and the height of the point is 9.63 m from the main rod of the tower to the ground when the wind speed is 10 m/s and the ice coating thickness of the conductor and ground wire is 20 mm. For the MZ2-27 cat-head type linear tower, a trigonometric function is needed to calculate the angle change of the monitoring point at a specific height. The included angle between the tower’s main material and the horizontal ground is about 77.42°, and the sine value of the included angle is 0.976. Combined with the distance between the tower foot and the monitoring point in the direction of the main material, the angle of the monitoring point at a specific height can be inversely calculated. The resulting angular deflection and the height at which the point is located meet the following equation:
where
is the size of the angle change;
is the size of the displacement of the point (m);
is the height of the point (m). Therefore, when the wind speed of the tower is 10 m/s and the ice coating thickness of the conductor and ground wire is 20 mm, the angle change at 9.63 m from the tower foot is about 0.214°.
3. Construction of Tower Mechanical Failure Dataset Based on SMOTE Algorithm
In the process of the long-term monitoring of towers, it was found that the original dataset composed of fault information has the following characteristics: the number of samples generated by normal operation of towers is much larger than the number of samples where faults occur, the frequency of occurrence of various types of mechanical faults is different, and it is impossible to artificially control the number of samples generated by each type of fault, resulting in a poorly balanced dataset which is difficult to use directly in the machine learning process. Thus, the SMOTE algorithm was chosen to process the original dataset [
22]. There are three steps in the process of implementing the SMOTE algorithm. First, the known sample points were edited to remove the points that do not play a significant role in the classification process to avoid computational overload during the subsequent process. Then, the KNN algorithm was used to select the K similar sample points that are closest to the sample point
. Last, M sample points
(
) were randomly selected among the K similar sample points. In practice, the value of M was usually taken as 5, which ensured that the operation was not too large while at the same time making the sample points grow quickly. M sample points were linked to the original sample point
, and any point during the period was taken as the new sample point
. The new sample points were constructed according to the SMOTE random formula, where
is a random number from 0 to 1 [
23]. Repeating this process under this condition, any number of sample points corresponding to the category can be obtained.
The SmoteOverSampling function was required for processing the dataset using the SMOTE algorithm, and the Vienna development method (VDM) algorithm was referenced in this function to calculate the nominal attribute distances [
24]. In the SmoteOverSampling function, the parameters that can be adjusted are C, k, and type. The parameter C is the cost vector, which refers to the size of the cost of a sample being misclassified to another class in the classification problem. Adjusting the parameter C controls the proportion of each class in the new dataset processed with the SMOTE algorithm. In this paper, the ratio of positive class to negative class samples should be controlled as 1:1, thus the parameter C should take the value of [1, 1]. The introduced KNN algorithm must introduce the parameter k, which indicates that the value is taken for the k proximity sample points around each known sample point. In the general case, the parameter k value was taken as 5. In the parameter type, two options, nominal or numeric, are available. Under nominal, the SMOTE algorithm uses VDM to process the nominal attributes to calculate the distance, and under numeric, the SMOTE algorithm uses Euclidean distance to process the nominal attributes. Thus, the nominal option was chosen as the value of the parameter type [
25]. Processing the dataset with the SMOTE algorithm helped to improve classification accuracy.
Figure 5 shows the comparison results of some data in the fault sample data under two-dimensional characteristics before and after processing. In the preprocessing dataset, each sample contained two features, and the ratio of positive to negative samples is 20:100. The new dataset increased the number of positive samples with the same number of negative samples, making the ratio of positive to negative samples achieve 100:100.
The original dataset and the new dataset were validated separately using LibSVM. In the validation process, the proportion of test samples was 30% of all samples, and the number of the test samples of the original dataset was 36, among which the number of positive samples was 6 and the number of negative samples was 30. The number of test samples of the new dataset after SMOTE algorithm processing was 60, among which the number of both positive and negative samples was 30. Without normalization, as shown in
Figure 6, the validation accuracy of the original dataset was 88.89%, and misclassification occurred four times, all of which occurred in the positive samples. As shown in
Figure 7, the validation accuracy of the new dataset was 91.67% and misclassification occurred five times. It is concluded that in unbalanced samples, the classifier is more likely to classify the samples to the side with a larger number, and the dataset obtained with the SMOTE algorithm is better balanced and has higher prediction accuracy.
In practice, due to the randomness of the SMOTE algorithm, it leads to the problem that the generated new samples and the original samples will overlap or nearly overlap, especially in a dataset with a small number of features. At this time, the number of effective samples that really work is still lower than the actual number of samples, thus in low-dimensional data, the value of parameter C should be changed appropriately so that the number of new samples of a certain category is slightly larger than the expected number, which can eliminate the influence of duplicate samples on the classification results to some extent and compensate for the number of effective samples to some extent.
6. Patents
This manuscript has produced four Chinese patents, namely:
Changchun Power Supply Company of State Grid Jilin Electric Power Co., Ltd., and Changchun University of Technology. “A big data based online monitoring system and method for transmission line tower posture.” Patent No.: CN114719909A. Authorization time: 8 July 2022.
Changchun Power Supply Company of State Grid Jilin Electric Power Co., Ltd., and Changchun University of Technology. “A method for predicting icing galloping of overhead transmission lines based on multi-information fusion.” Patent No.: CN114676540A. Authorization time: 28 June 2022.
Changchun Power Supply Company of State Grid Jilin Electric Power Co., Ltd., and Changchun University of Technology. “Wind power supply system blade deformation detection circuit.” Patent No.: CN216922368U. Authorization time: 8 July 2022.
Changchun Power Supply Company of State Grid Jilin Electric Power Co., Ltd., and Changchun University of Technology. “Online monitoring circuit of transmission tower state based on the Internet of Things.” Patent No.: CN216927421U. Authorization time: 8 July 2022.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}