

JAUNet: A U-Shape Network with Jump Attention for Semantic Segmentation of Road Scenes

Abstract
:1. Introduction
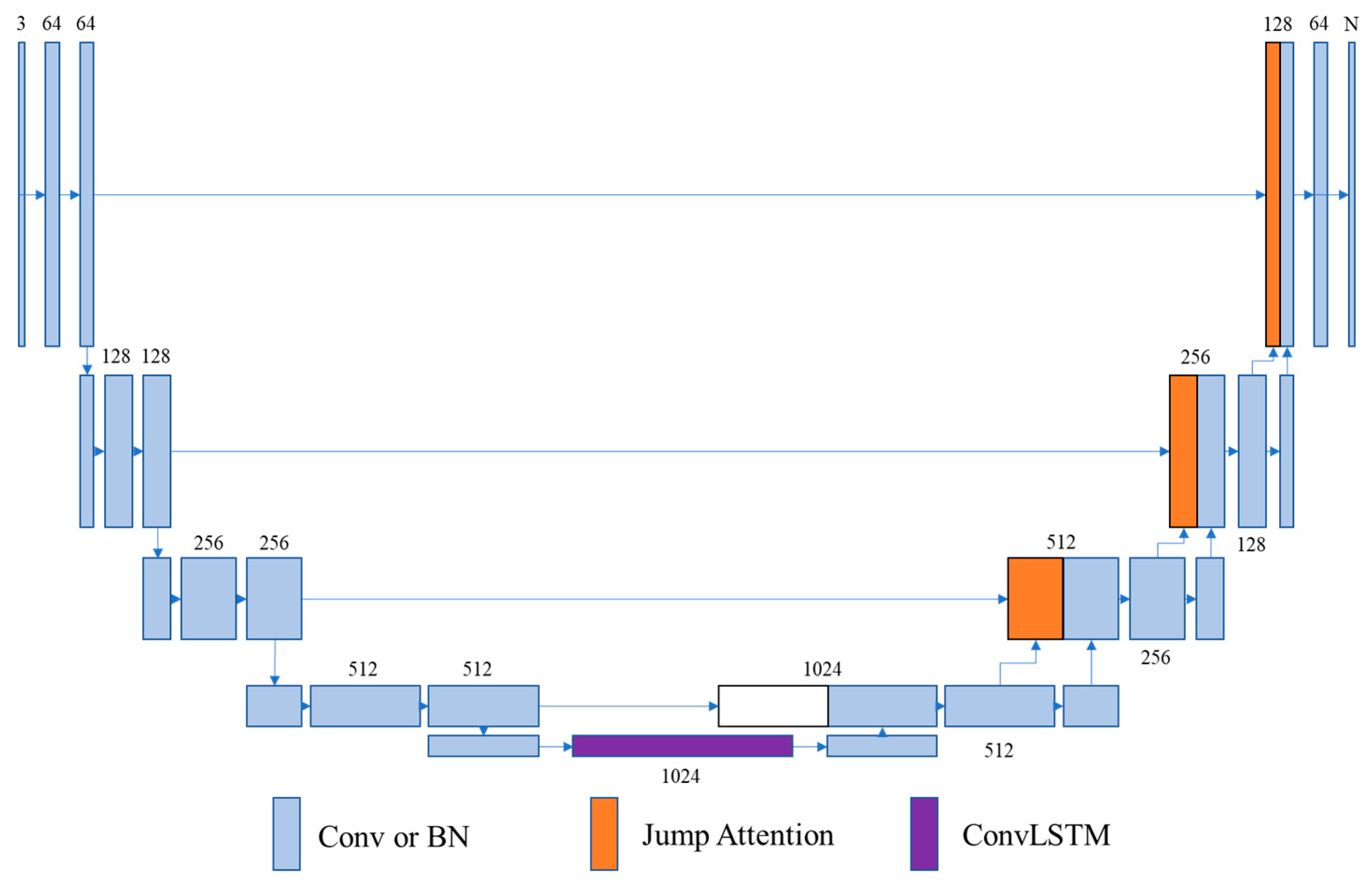
2. Materials and Methods
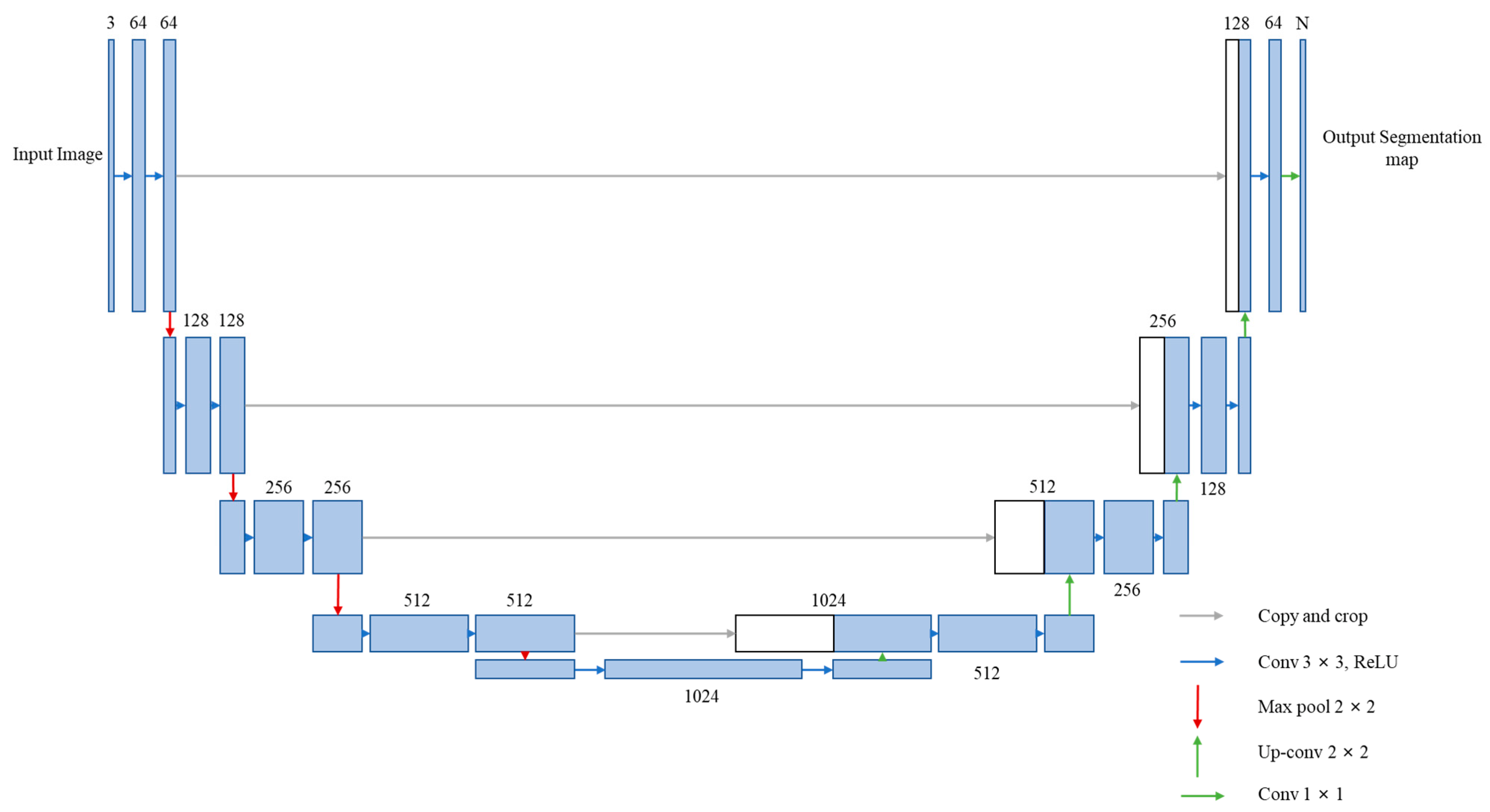
2.1. UNet Network Structure
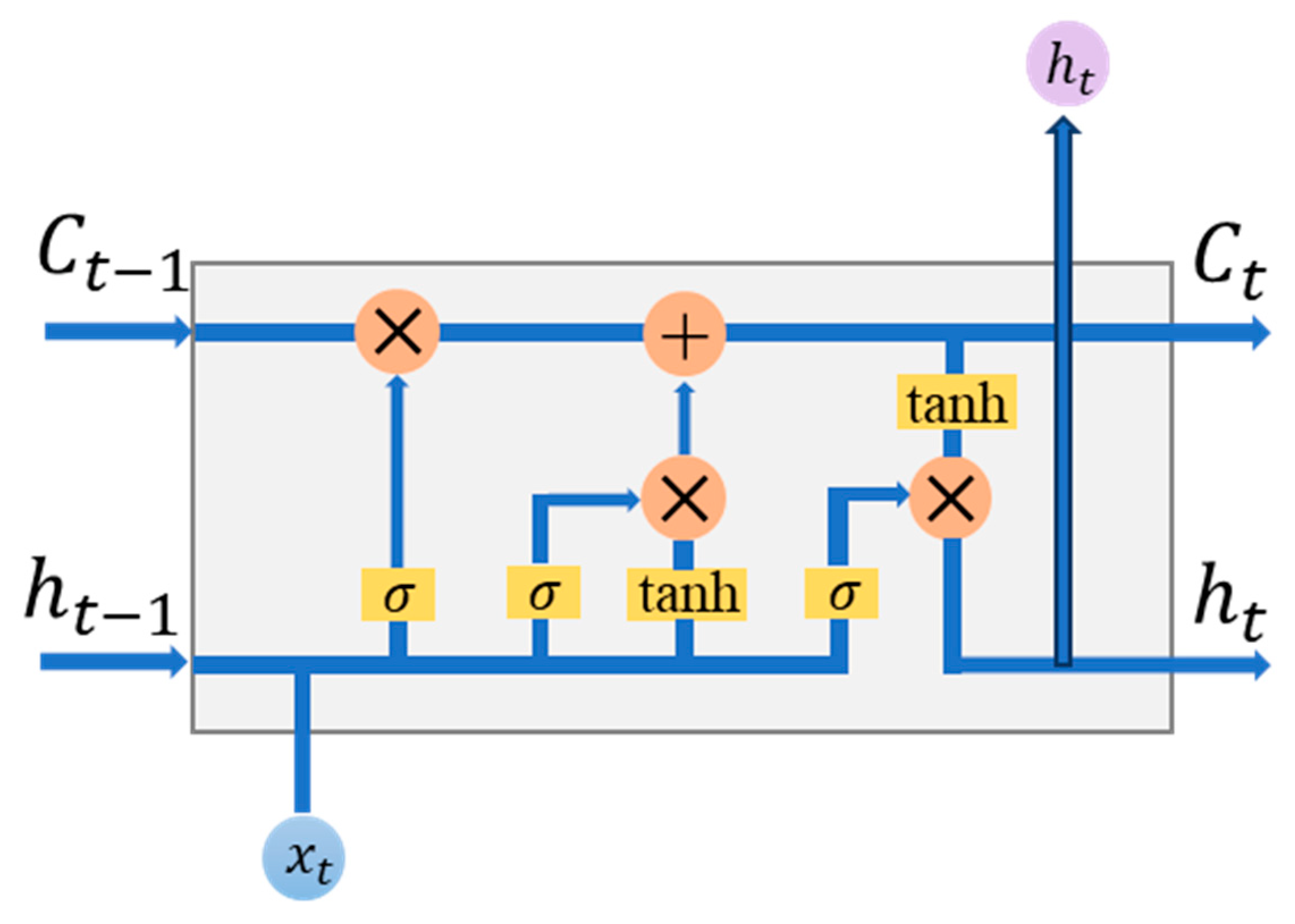
2.2. Convolutional LSTM (ConvLSTM) Network Structure
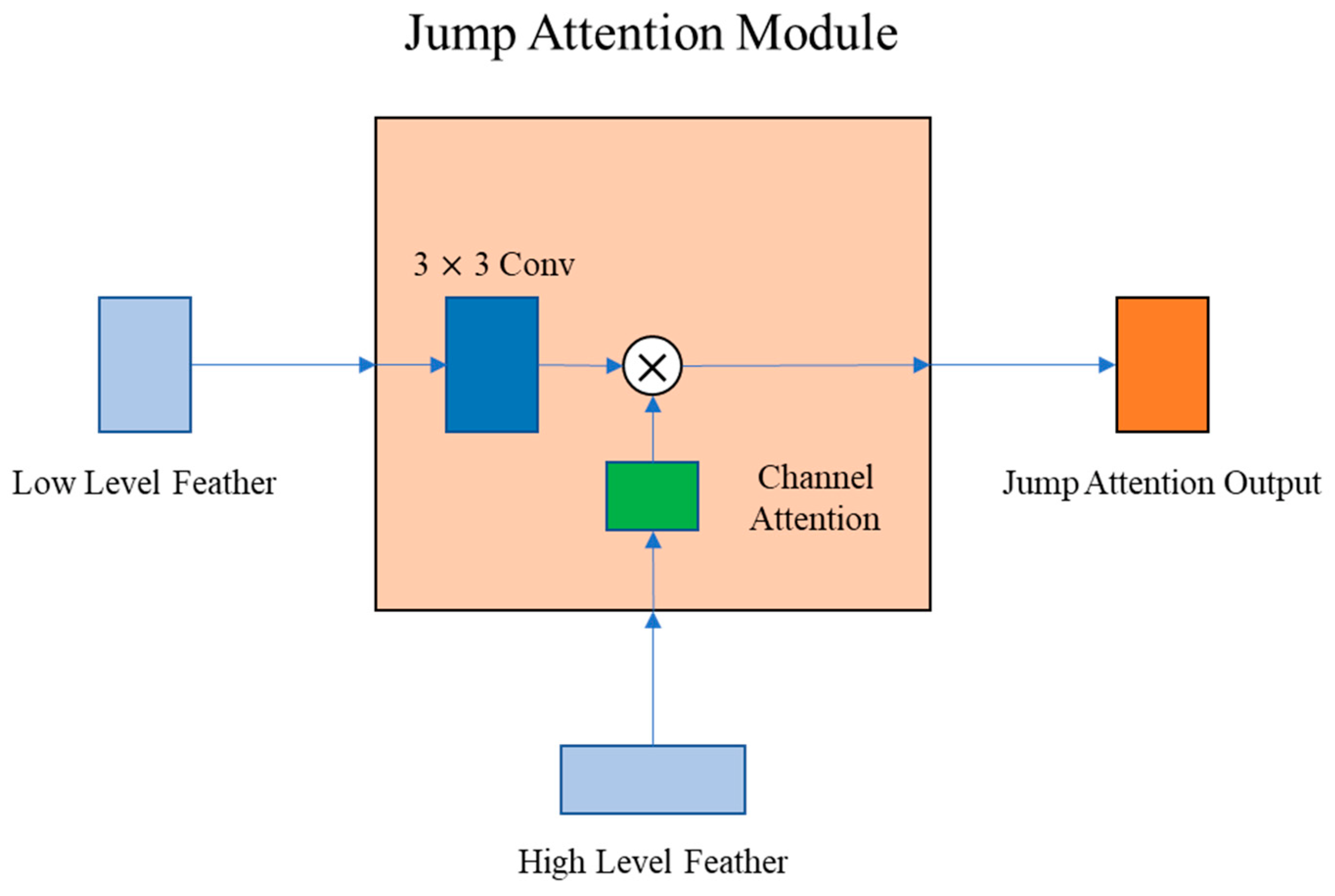
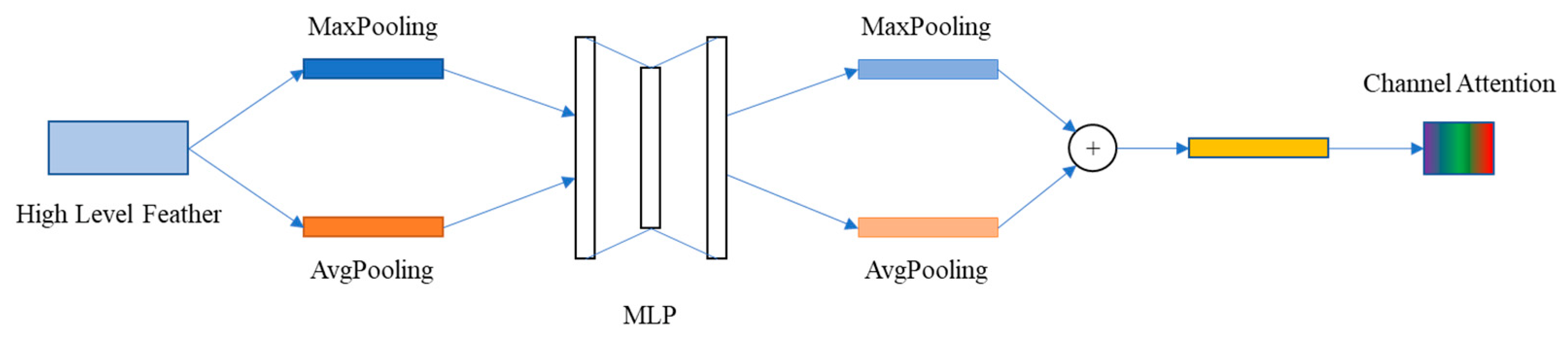
2.3. Jump Attention Module (JAM)
3. Results
3.1. Benchmark Dataset
3.1.1. CamVid Dataset
3.1.2. Cityscapes Dataset
3.2. Experimental Platform and Environment
3.3. Evaluation Indicators
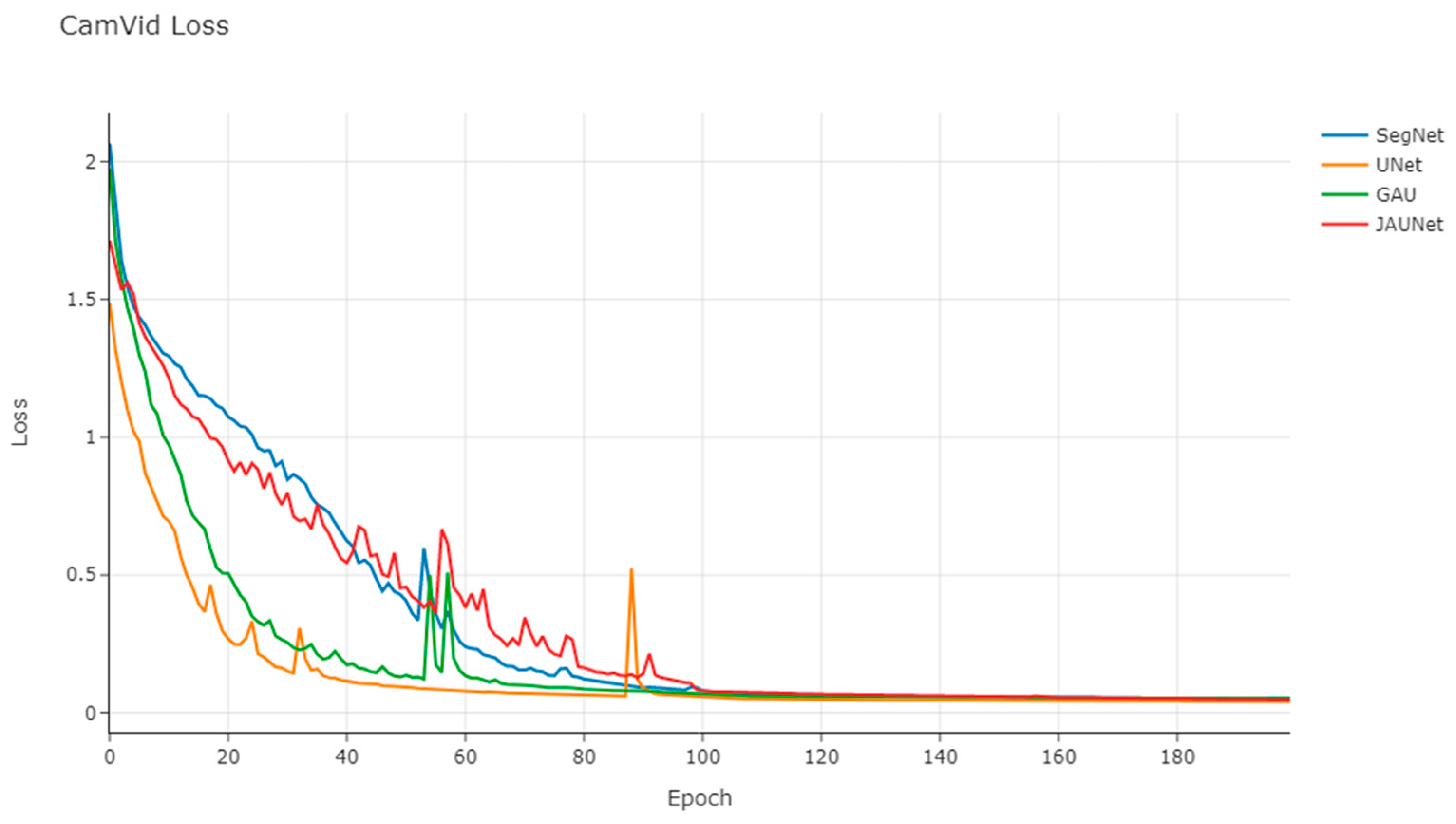
3.4. Loss Function
3.5. Experimental Evaluation
3.5.1. Ablation Experiments
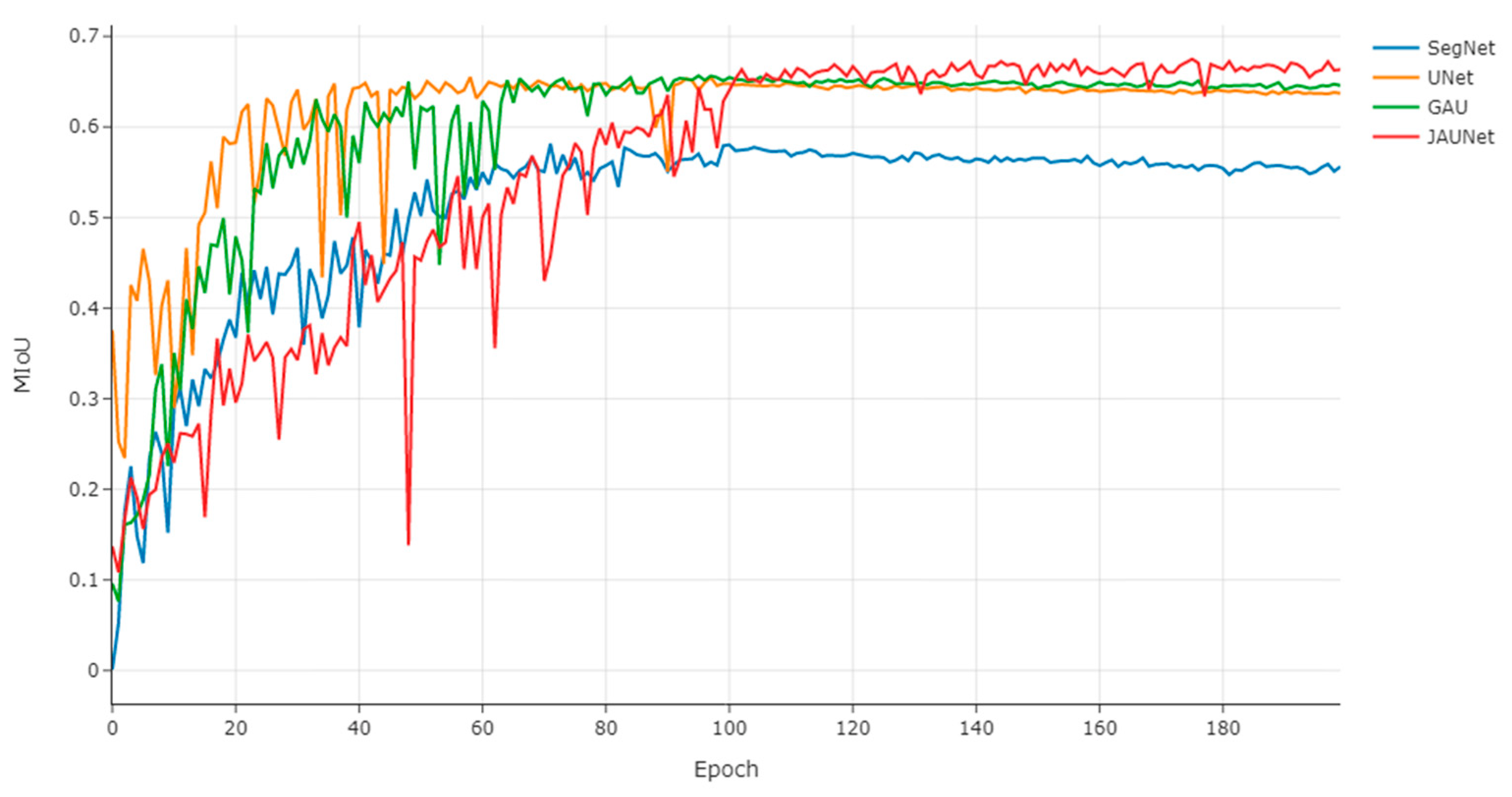
3.5.2. CamVid Dataset Results
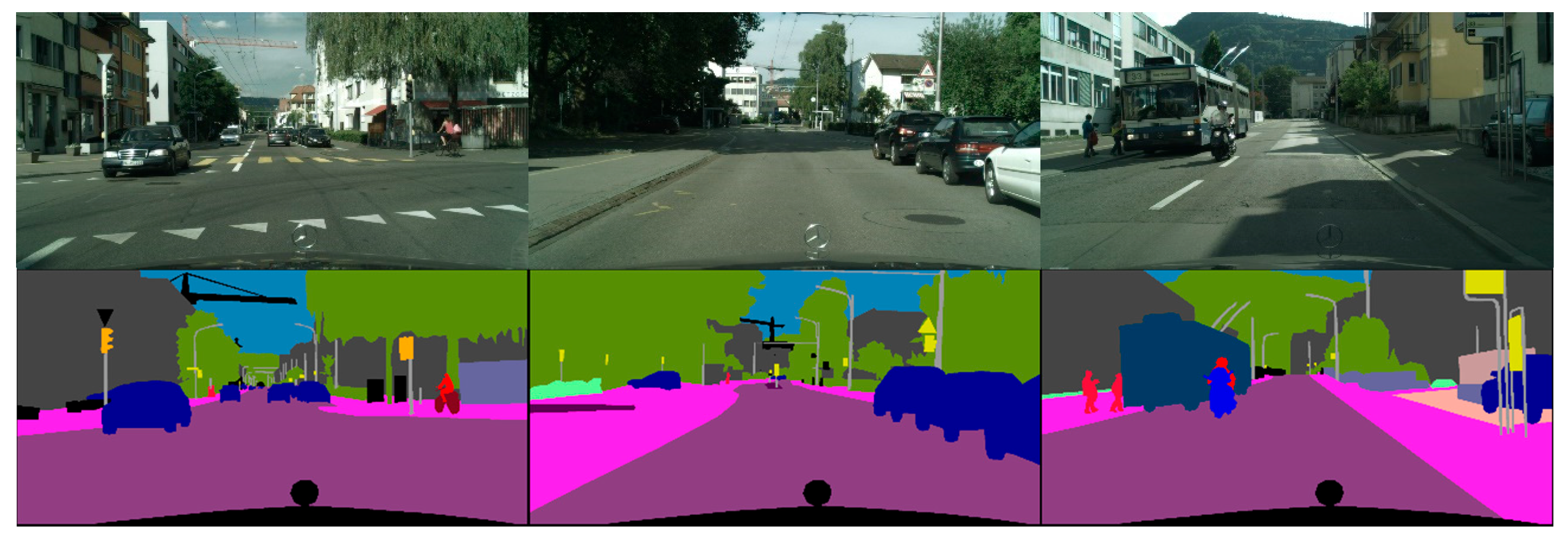
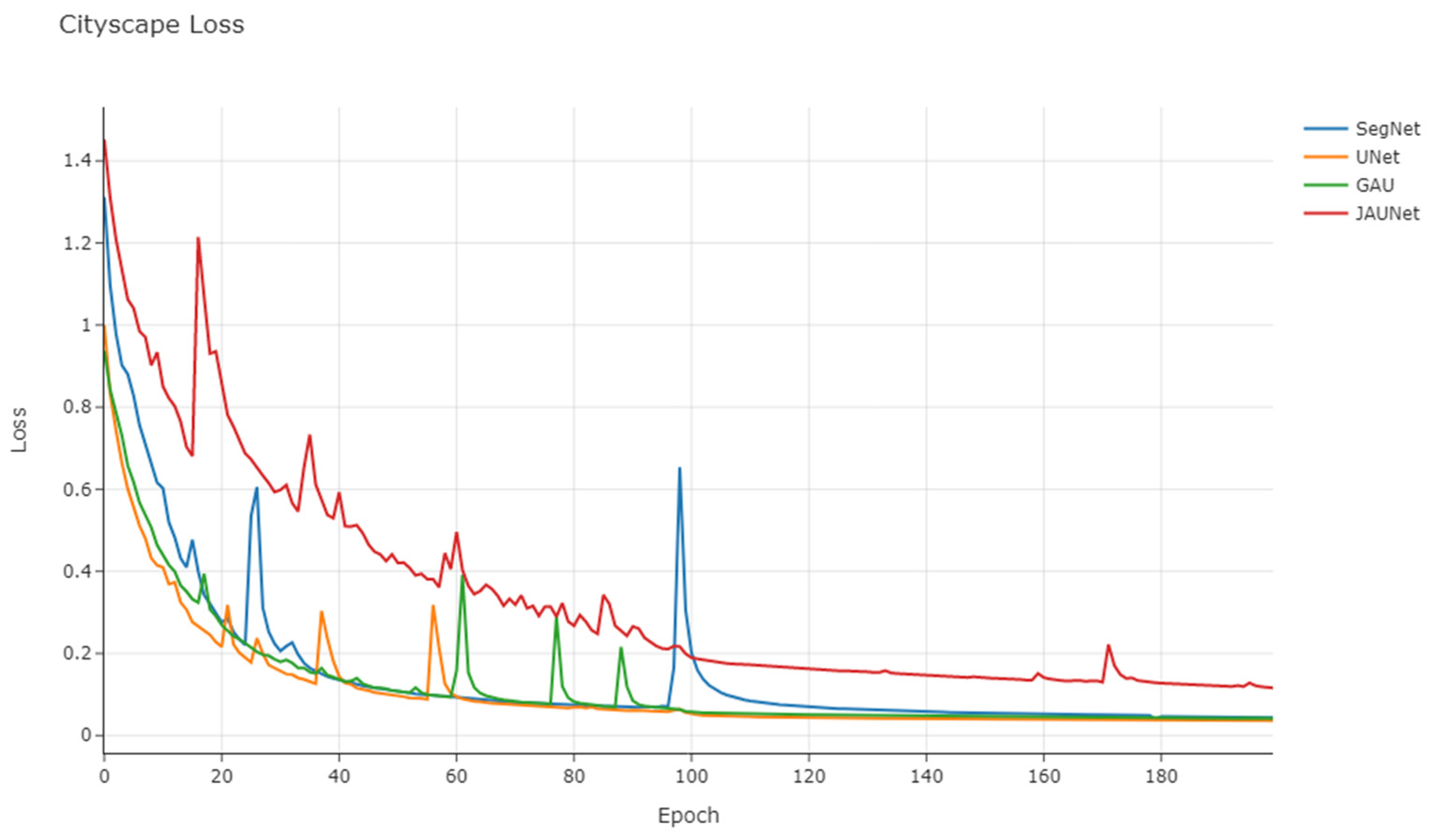
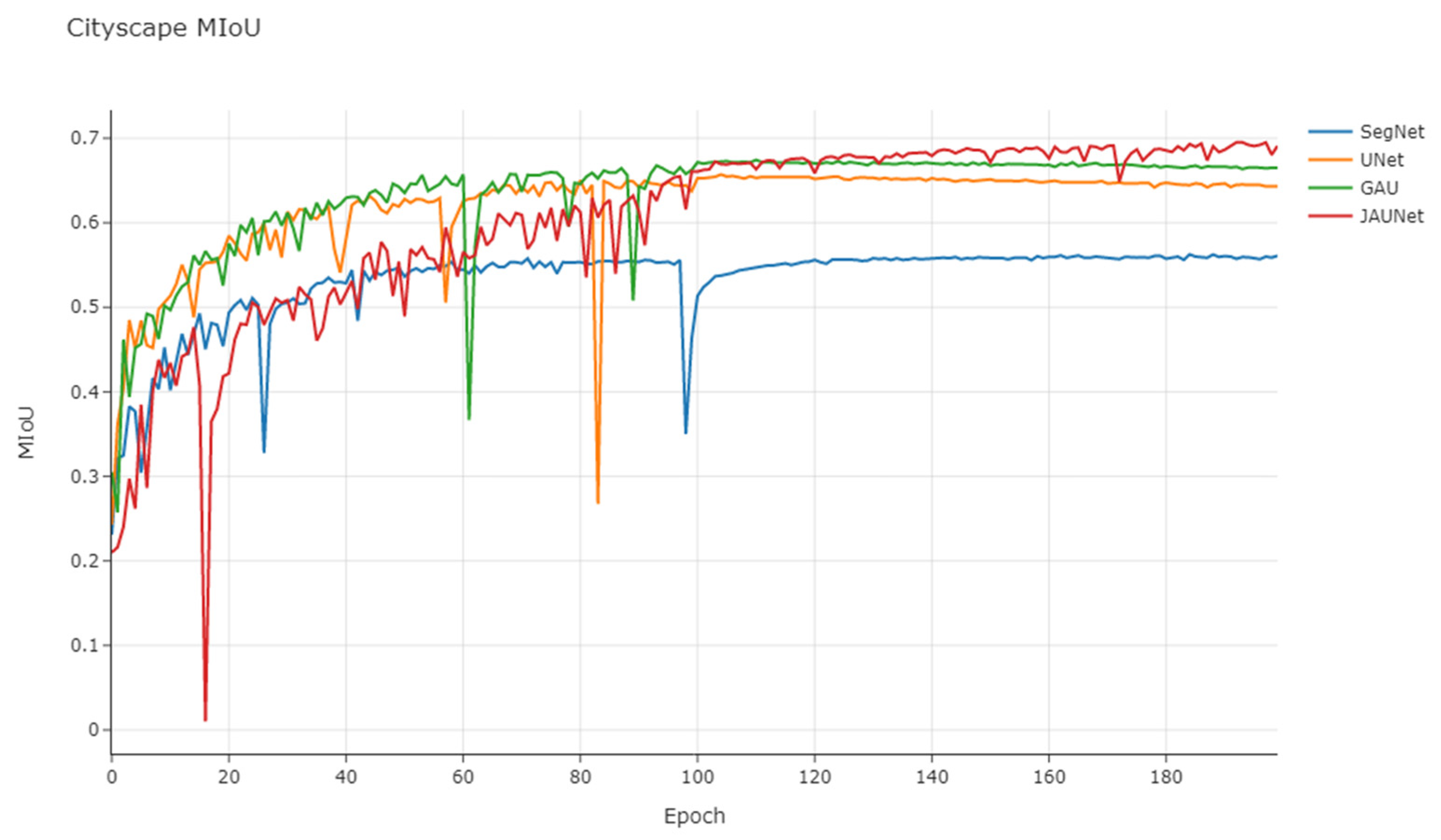
3.5.3. Cityscape Dataset Results
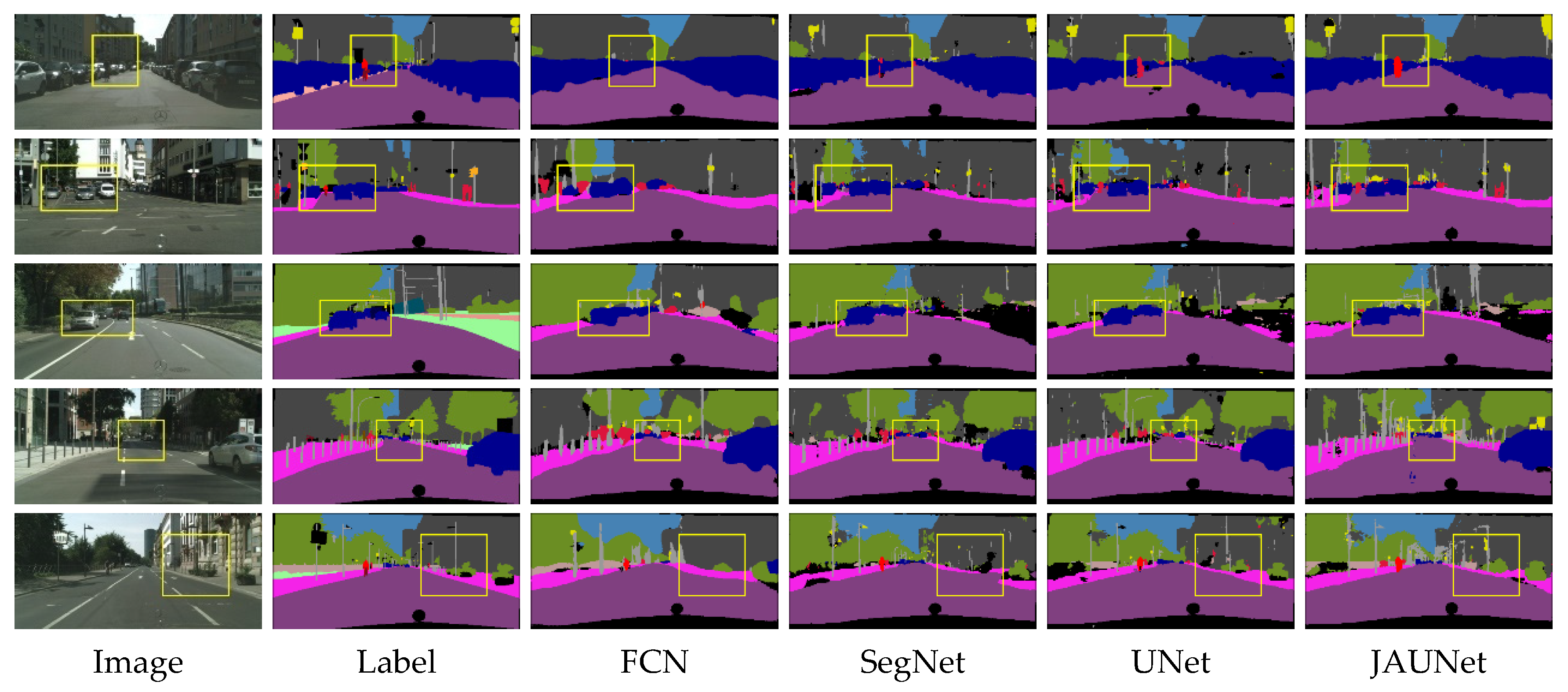
3.6. Summary of Segmentation Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mehrotra, R.; Namuduri, K.R.; Ranganathan, N. Gabor filter-based edge detection. Pattern Recognit. 1992, 25, 1479–1494. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Mikolov, T.; Kombrink, S.; Burget, L.; Černocký, J.; Khudanpur, S. Extensions of recurrent neural network language model. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 5528–5531. [Google Scholar]
- Wang, Z.; Xia, M.; Lu, M.; Pan, L.; Liu, J. Parameter Identification in Power Transmission Systems Based on Graph Convolution Network. IEEE Trans. Power Deliv. 2021, 37, 3155–3163. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Gao, J.; Weng, L.; Xia, M.; Lin, H. MLNet: Multichannel feature fusion lozenge network for land segmentation. J. Appl. Remote Sens. 2022, 16, 016513. [Google Scholar] [CrossRef]
- Chen, B.; Xia, M.; Qian, M.; Huang, J. MANet: A multi-level aggregation network for semantic segmentation of high-resolution remote sensing images. Int. J. Remote Sens. 2022, 43, 5874–5894. [Google Scholar] [CrossRef]
- Song, L.; Xia, M.; Weng, L.; Lin, H.; Qian, M.; Chen, B. Axial Cross Attention Meets CNN: Bi-Branch Fusion Network for Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 32–43. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters—Improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Bilinski, P.; Prisacariu, V. Dense decoder shortcut connections for single-pass semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6596–6605. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the Twenty-ninth Conference on Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Hong, S.; Noh, H.; Han, B. Decoupled deep neural network for semi-supervised semantic segmentation. In Proceedings of the Twenty-ninth Conference on Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Lu, C.; Xia, M.; Lin, H. Multi-scale strip pooling feature aggregation network for cloud and cloud shadow segmentation. Neural Comput. Appl. 2022, 34, 6149–6162. [Google Scholar] [CrossRef]
- Miao, S.; Xia, M.; Qian, M.; Zhang, Y.; Liu, J.; Lin, H. Cloud/shadow segmentation based on multi-level feature enhanced network for remote sensing imagery. Int. J. Remote Sens. 2022, 43, 5940–5960. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Keskar, N.S.; Socher, R. Improving generalization performance by switching from adam to sgd. arXiv 2017, arXiv:1712.07628. [Google Scholar]
- Sturgess, P.; Alahari, K.; Ladicky, L.; Torr, P.H. Combining appearance and structure from motion features for road scene understanding. In Proceedings of the BMVC-British Machine Vision Conference, London, UK, 7–10 September 2009. [Google Scholar]
- Tighe, J.; Lazebnik, S. Superparsing: Scalable nonparametric image parsing with superpixels. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; pp. 352–365. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Soplin, N.E.Y.; Heymann, J.; Wiesner, M.; Chen, N. Espnet: End-to-end speech processing toolkit. arXiv 2018, arXiv:1804.00015. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Li, H.; Xiong, P.; Fan, H.; Sun, J. Dfanet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9522–9531. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Han, W.; Zhang, Z.; Zhang, Y.; Yu, J.; Chiu, C.-C.; Qin, J.; Gulati, A.; Pang, R.; Wu, Y. Contextnet: Improving convolutional neural networks for automatic speech recognition with global context. arXiv 2020, arXiv:2005.03191. [Google Scholar]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. Cgnet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware | Manufacturer | Model |
|---|---|---|
| CPU | INTEL, Santa Clara, CA, USA | Core i7-12700 |
| GPU | NVIDIA, Santa Clara, CA, USA | Geforce RTX3070 |
| Memory | G. SKILL, Taipei, Taiwan, China | F4-3200C16D 8 GB × 4 |
| SSD | Samsung, Yongin, Gyeonggi-do, Korea | 980pro 1TB |
| Software | Version |
|---|---|
| Windows 11 | 22H2 |
| Conda | 4.13.0 |
| Python | 3.9.12 |
| Pytorch | 1.12.0 |
| Cudatoolkit | 11.3.1 |
| Matplotlib | 3.5.1 |
| Numpy | 1.22.3 |
| PA | MPA | FWIoU | ||
|---|---|---|---|---|
| 1 | 0 | 80.7 | 64.4 | 72.3 |
| 0.8 | 0.2 | 82.5 | 64.2 | 74.0 |
| 0.6 | 0.4 | 83.0 | 63.1 | 74.2 |
| 0.4 | 0.6 | 79.3 | 64.2 | 70.5 |
| 0.2 | 0.8 | 77.3 | 64.5 | 69.4 |
| Network | Speed/fps | Params/M | MIoU | FWIoU |
|---|---|---|---|---|
| UNet [14] | 39.51 | 7.76 | 63.7 | 72.6 |
| UNet + ConvLSTM | 25.39 | 26.58 | 64.1 | 70.1 |
| UNet + 1 × JAM | 38.95 | 9.34 | 63.9 | 72.5 |
| UNet + 2 × JAM | 37.60 | 11.22 | 64.5 | 72.1 |
| UNet + 3 × JAM | 36.34 | 15.31 | 65.5 | 73.1 |
| UNet + 4 × JAM | 31.22 | 18.50 | 65.3 | 72.8 |
| UNet + 3 × JAM + ConvLSTM | 35.23 | 33.91 | 66.3 | 74.2 |
| Network | Input Size | Speed/fps | Params/M | MIoU | FWIoU | GFLOPs |
|---|---|---|---|---|---|---|
| ALE [31] | 360 × 480 | - | - | 53.6 | 62.1 | - |
| SuperParsing [32] | 360 × 480 | - | - | 42.0 | 52.0 | - |
| FCN-ResNet34 | 360 × 480 | 157.10 | 21.34 | 49.1 | 60.5 | 55.89 |
| ENet [33] | 360 × 480 | 135.4 | 0.37 | 51.3 | 63.2 | 3.83 |
| SegNet [15] | 360 × 480 | 46.18 | 29.45 | 55.6 | 66.9 | 104.54 |
| ESPNet [34] | 360 × 480 | 132.00 | 0.36 | 55.6 | 67.2 | 3.31 |
| PSPNet-ResNet18 | 360 × 480 | 25.98 | 46.64 | 57.1 | 68.8 | 123.69 |
| GAU [20] | 360 × 480 | 38.15 | 7.94 | 64.5 | 72.3 | 81.64 |
| DeepLab-LFOV [4] | 360 × 480 | 122.53 | 15.31 | 61.6 | 69.3 | 125.00 |
| ICNet [35] | 360 × 480 | 27.8 | 26.5 | 67.1 | 74.5 | 28.3 |
| DFANet A [36] | 360 × 480 | 120 | 7.8 | 64.7 | 72.8 | 3.4 |
| DFANet B [36] | 360 × 480 | 160 | 4.8 | 59.3 | 69.0 | 2.1 |
| BiSeNetV1_X [37] | 720 × 960 | 175.00 | 49.00 | 65.6 | 73.1 | 8.70 |
| BiSeNetV1_R [37] | 720 × 960 | 116.30 | 5.8 | 68.7 | 75.9 | 32.4 |
| JAUNet | 360 × 480 | 35.23 | 33.91 | 66.3 | 74.2 | 137.76 |
| Network | Pretrain | Speed/fps | Params/M | MIoU | FWIoU | GFLOPs |
|---|---|---|---|---|---|---|
| FCN-ResNet34 | No | 157.10 | 21.34 | 49.1 | 62.1 | 55.89 |
| ENet | No | 41.70 | 0.36 | 58.3 | 65.3 | 4.35 |
| SegNet | No | 35.13 | 29.45 | 56.1 | 65.1 | 104.54 |
| FastSCNN | No | 198.41 | 1.10 | 62.8 | 67.8 | 1.76 |
| ContextNet [38] | No | 176.60 | 0.88 | 65.5 | 71.2 | 1.78 |
| PSPNet-ResNet18 | No | 18.73 | 46.64 | 63.4 | 69.6 | 123.69 |
| GAU | No | 35.23 | 7.94 | 66.5 | 73.2 | 81.64 |
| CGNet [39] | No | 44.70 | 0.50 | 65.6 | 71.1 | 7.00 |
| EDANet | No | 105.50 | 0.68 | 67.3 | 73.2 | 9.00 |
| ICNet | No | 30.3 | 26.5 | 69.0 | 76.3 | 28.3 |
| DFANet A’ | No | 100 | 7.8 | 70.3 | 77.1 | 3.4 |
| DFANet B | No | 120 | 4.8 | 67.1 | 71.9 | 2.1 |
| BiSeNetV1_X | ImageNet | 105.80 | 5.80 | 68.4 | 75.8 | 14.90 |
| BiSeNetV1_R | ImageNet | 65.50 | 49.00 | 74.7 | 81.3 | 55.3 |
| UNet | No | 36.73 | 7.76 | 64.3 | 70.5 | 119.03 |
| ConvLSTM_UNet | No | 19.23 | 26.58 | 64.9 | 70.1 | 137.53 |
| JAUNet | No | 28.51 | 33.91 | 69.1 | 76.3 | 137.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, Z.; Liu, K.; Hou, J.; Yan, F.; Zang, Q. JAUNet: A U-Shape Network with Jump Attention for Semantic Segmentation of Road Scenes. Appl. Sci. 2023, 13, 1493. https://doi.org/10.3390/app13031493
Fan Z, Liu K, Hou J, Yan F, Zang Q. JAUNet: A U-Shape Network with Jump Attention for Semantic Segmentation of Road Scenes. Applied Sciences. 2023; 13(3):1493. https://doi.org/10.3390/app13031493
Chicago/Turabian StyleFan, Zhiyong, Kailai Liu, Jianmin Hou, Fei Yan, and Qiang Zang. 2023. "JAUNet: A U-Shape Network with Jump Attention for Semantic Segmentation of Road Scenes" Applied Sciences 13, no. 3: 1493. https://doi.org/10.3390/app13031493
APA StyleFan, Z., Liu, K., Hou, J., Yan, F., & Zang, Q. (2023). JAUNet: A U-Shape Network with Jump Attention for Semantic Segmentation of Road Scenes. Applied Sciences, 13(3), 1493. https://doi.org/10.3390/app13031493