
Automated Analysis of Open-Ended Students’ Feedback Using Sentiment, Emotion, and Cognition Classifications

 , , and
, , and 
Abstract
:1. Introduction
2. Related Work
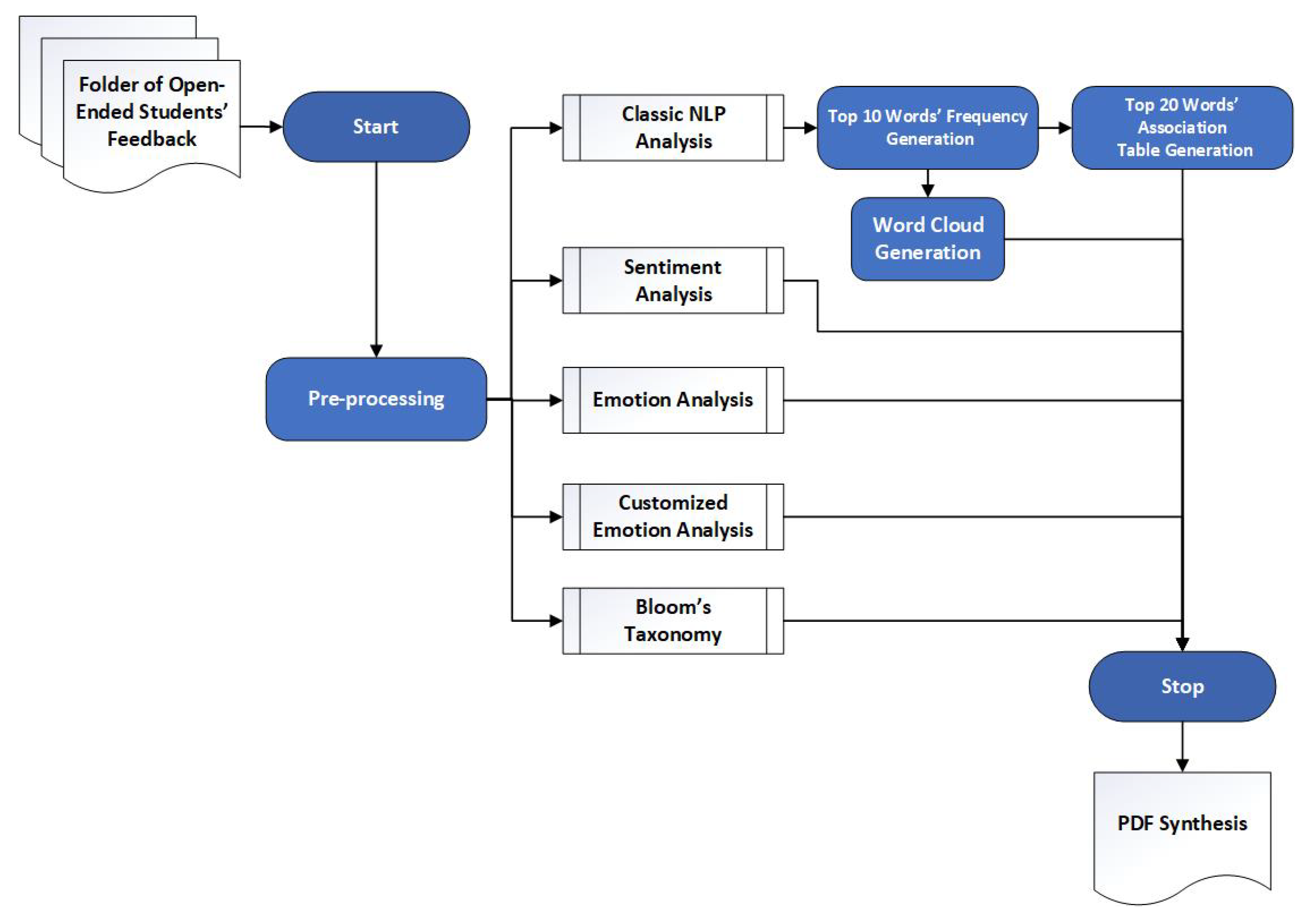
3. Components of the Application
4. Implementation and Analysis
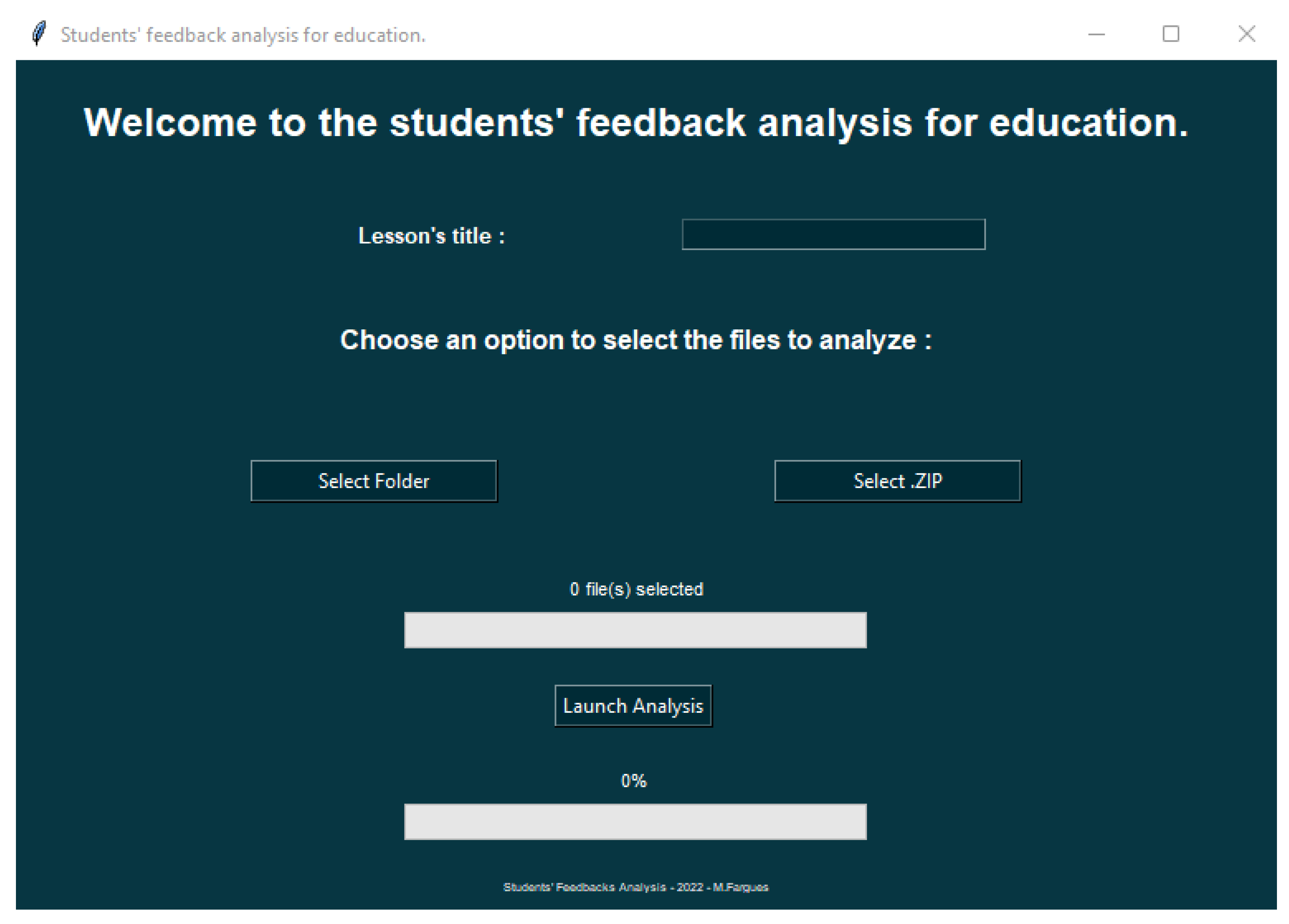
4.1. A User-Friendly Interface
4.2. The PDF Report
4.3. Pre-Processing of Input Files
4.4. Word Frequencies and Word Clouds
4.5. Sentiment Analysis
4.6. Emotional Analysis
4.7. Customized Emotional Analysis
4.7.1. Building the Dictionary
4.7.2. Infinitive Text
4.7.3. Taking Care of Negations: Not before Words
4.7.4. Word Counting and Exploitation
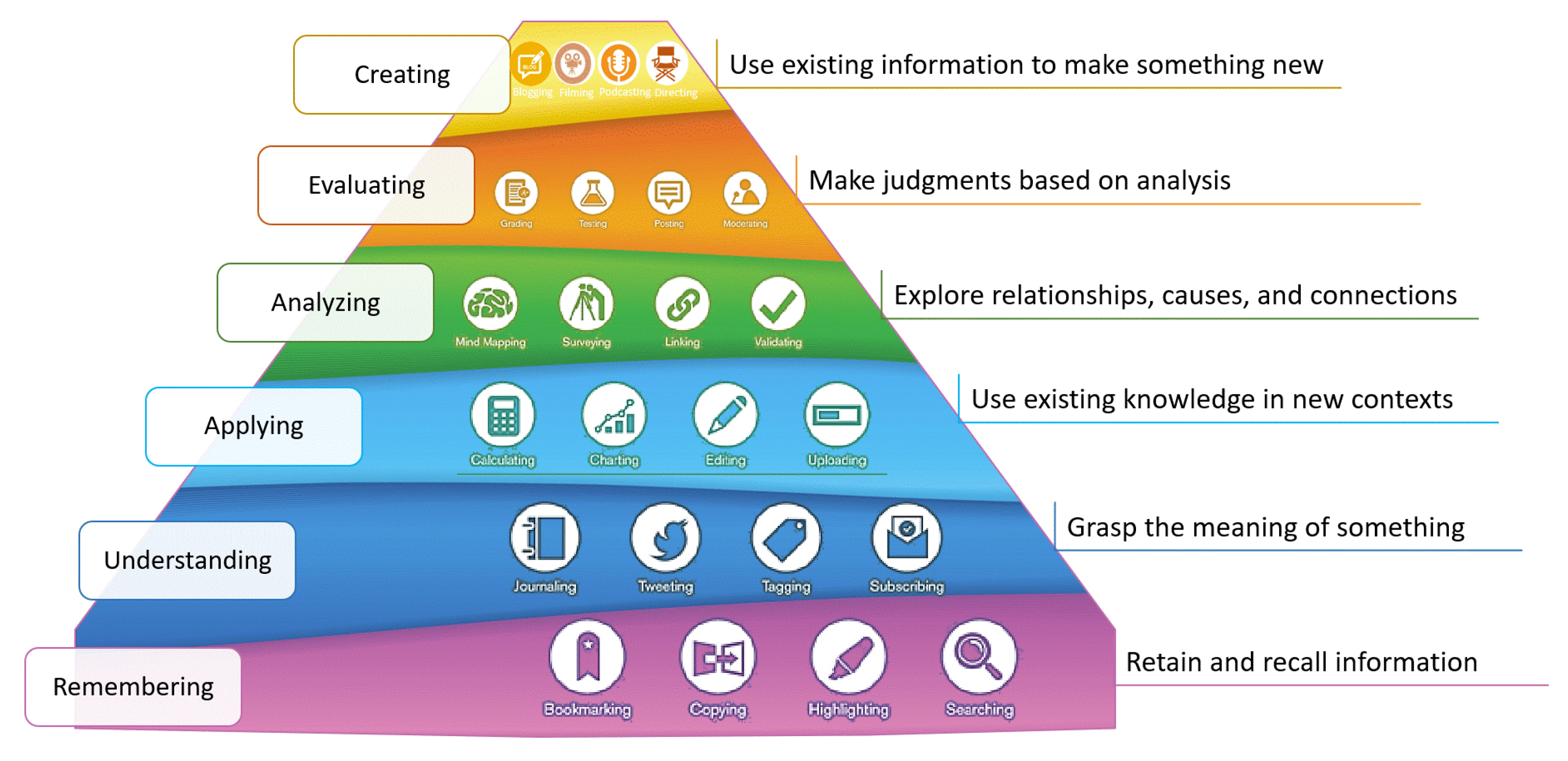
4.8. Classification According to Bloom’s Taxonomy
4.8.1. Building the Dictionary
4.8.2. Taking Care of Negations: Not before Words
4.8.3. Word Counting and Exploitation
5. Results and Discussion
5.1. Classic NLP Analysis
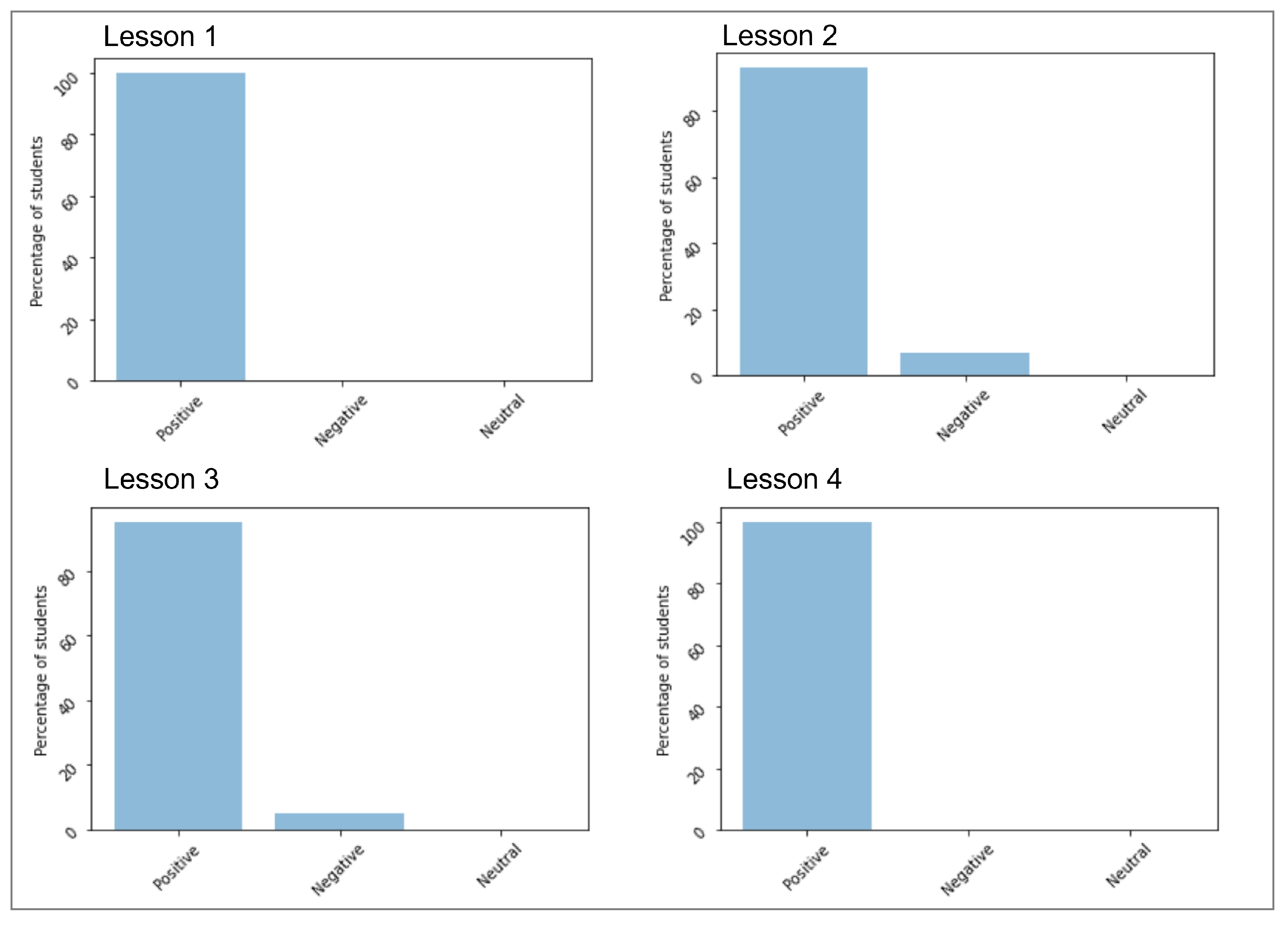
5.2. Sentiment Analysis
- Positive (score between 0.05 and 1);
- Negative (score between −0.05 and −1);
- Neutral (score between −0.05 and 0.05).
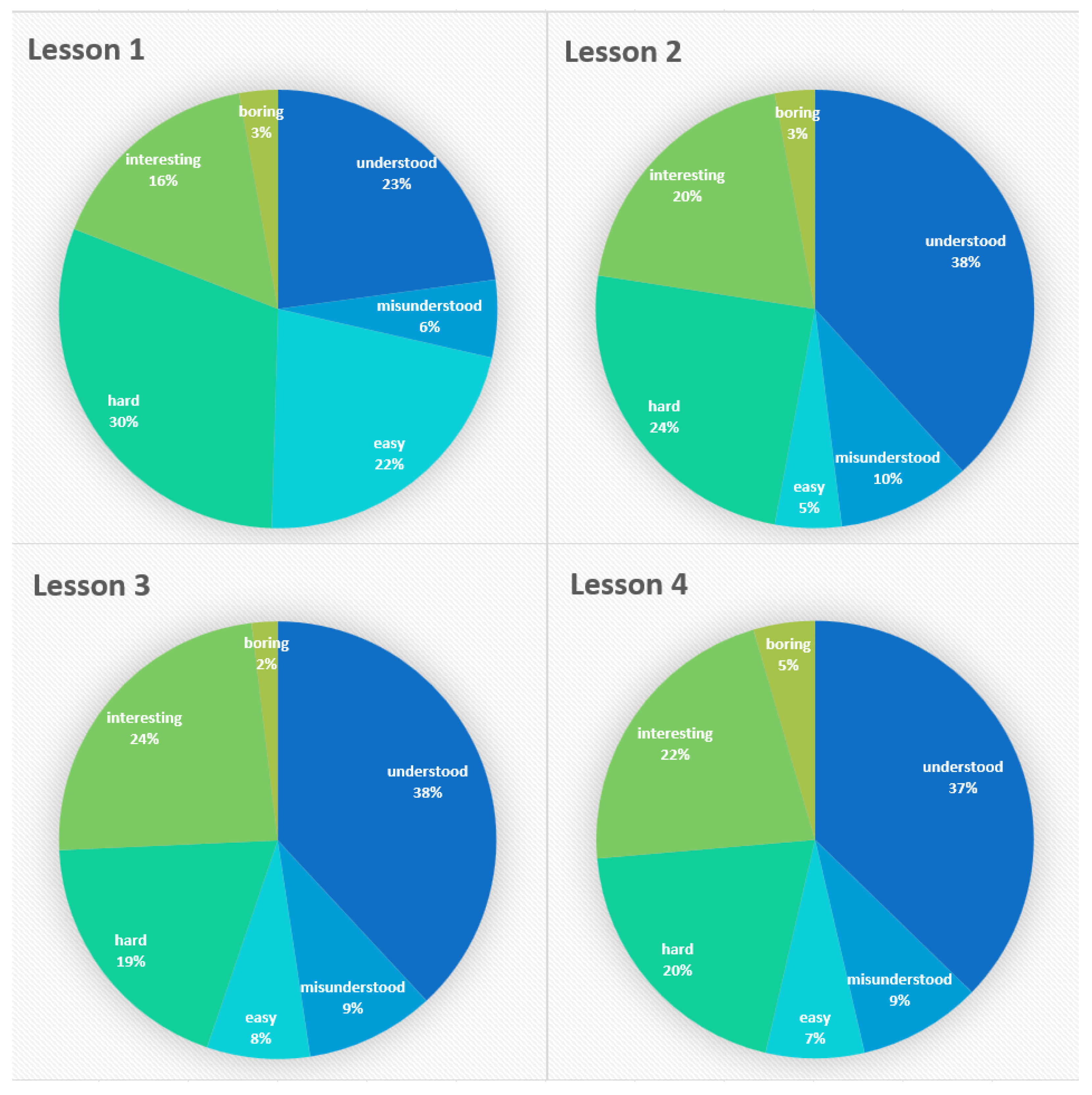
5.3. Emotion Analysis
5.4. Customized Emotion Analysis
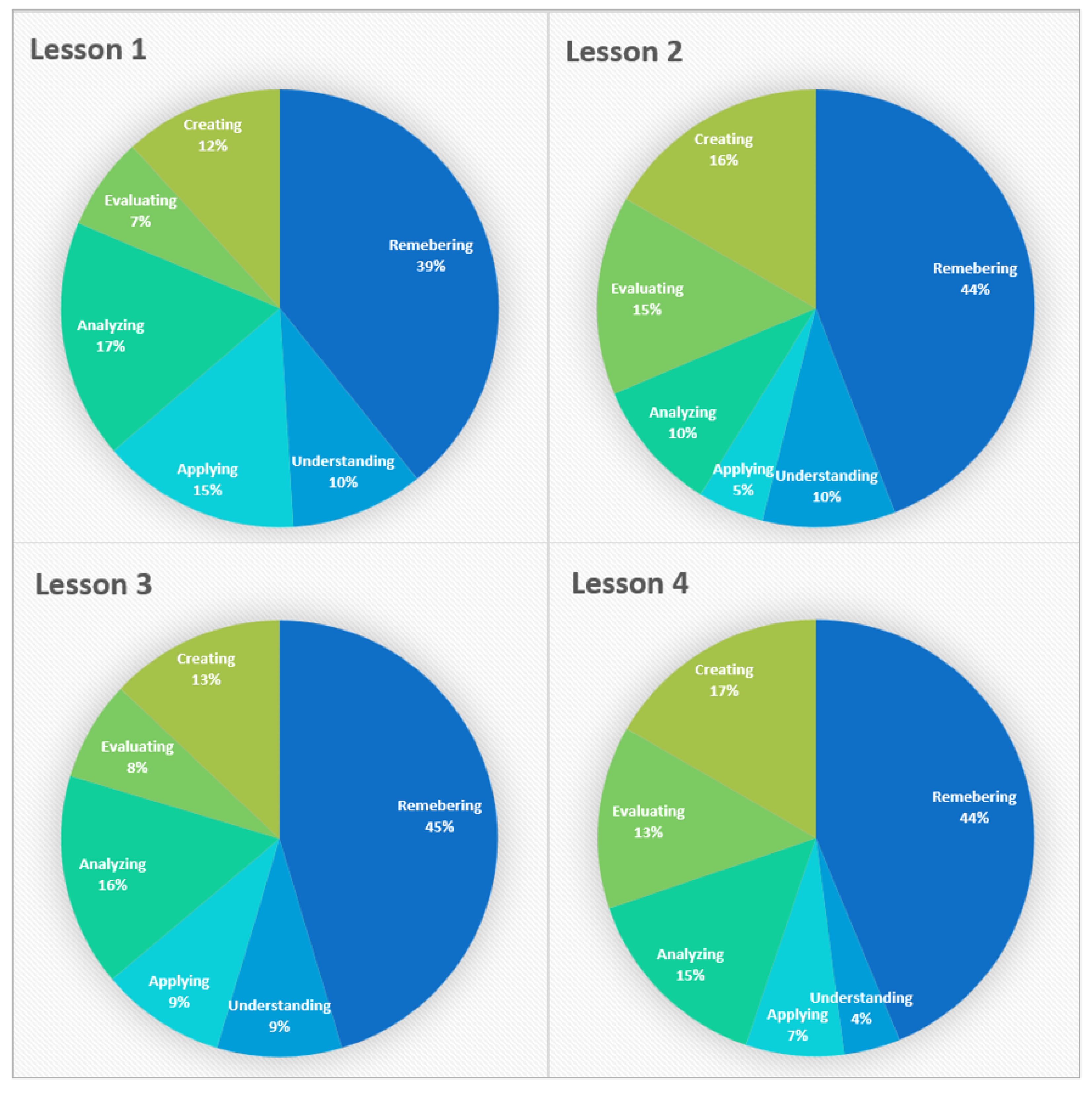
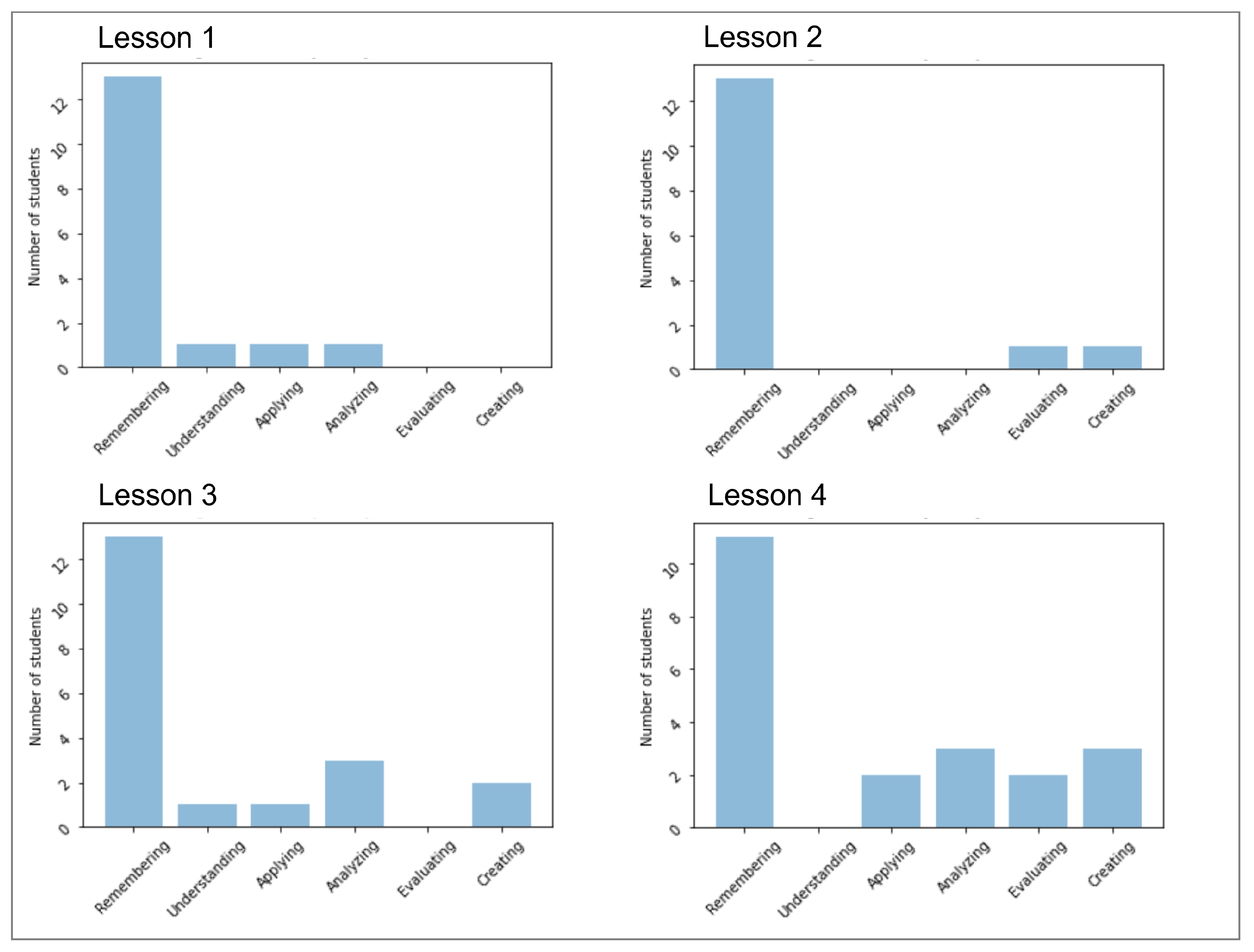
5.5. Bloom’s Taxonomy Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hedderich, M.A.; Lange, L.; Adel, H.; Strötgen, J.; Klakow, D. A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2545–2568. [Google Scholar] [CrossRef]
- Alhawiti, K.M. Natural Language Processing and its Use in Education. Int. J. Adv. Comput. Sci. Appl. 2014, 5, 72–76. [Google Scholar] [CrossRef]
- Litman, D. Natural Language Processing for Enhancing Teaching and Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar] [CrossRef]
- Elouazizi, N.; Birol, G.; Jandciu, E.; Öberg, G.; Welsh, A.; Han, A.; Campbell, A. Automated Analysis of Aspects of Written Argumentation. In Proceedings of the 7th International Learning Analytics & Knowledge Conference (LAK’17), Vancouver, BC, Canada, 13–17 March 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 606–607. [Google Scholar] [CrossRef]
- Gao, Y.; Davies, P.M.; Passonneau, R.J. Automated Content Analysis: A Case Study of Computer Science Student Summaries. In Proceedings of the 13th Workshop on Innovative Use of NLP for Building Educational Applications, New Orleans, LA, USA, 5 June 2018; Association for Computational Linguistics: New Orleans, Louisiana, 2018; pp. 264–272. [Google Scholar] [CrossRef]
- Altrabsheh, N.; Cocea, M.; Fallahkhair, S. Learning Sentiment from Students’ Feedback for Real-Time Interventions in Classrooms. In Adaptive and Intelligent Systems; Bouchachia, A., Ed.; Springer International Publishing: Cham, Switzerland, 2014; pp. 40–49. [Google Scholar]
- Cutrone, L.A.; Chang, M. Automarking: Automatic Assessment of Open Questions. In Proceedings of the 10th IEEE International Conference on Advanced Learning Technologies, Sousse, Tunisia, 5–7 July 2010; pp. 143–147. [Google Scholar] [CrossRef]
- Kastrati, Z.; Dalipi, F.; Imran, A.S.; Pireva Nuci, K.; Wani, M.A. Sentiment Analysis of Students’ Feedback with NLP and Deep Learning: A Systematic Mapping Study. Appl. Sci. 2021, 11, 3986. [Google Scholar] [CrossRef]
- Hynninen, T.; Knutas, A.; Hujala, M. Sentiment analysis of open-ended student feedback. In Proceedings of the 43rd International Convention on Information, Communication and Electronic Technology, Opatija, Croatia, 28 September–2 October 2020; pp. 755–759. [Google Scholar] [CrossRef]
- Nasim, Z.; Rajput, Q.; Haider, S. Sentiment analysis of student feedback using machine learning and lexicon based approaches. In Proceedings of the International Conference on Research and Innovation in Information Systems, Seoul, Republic of Korea, 16–17 July 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ren, P.; Yang, L.; Luo, F. Automatic scoring of student feedback for teaching evaluation based on aspect-level sentiment analysis. Educ. Inf. Technol. 2022, 28, 797–814. [Google Scholar] [CrossRef]
- Brown, R.B. Contemplating the Emotional Component of Learning: The Emotions and Feelings Involved when Undertaking an MBA. Manag. Learn. 2000, 31, 275–293. [Google Scholar] [CrossRef]
- Fineman, S. Emotion and Management Learning. Manag. Learn. 1997, 28, 13–25. [Google Scholar] [CrossRef]
- Churches, A. Bloom’s digital taxonomy. In Bloom’s Revised Digital Taxonomy Map; Tech & Learning: Washington, DC, USA, 2008; pp. 6–8. [Google Scholar]
- Anderson, L.W.; Sosniak, L.A.; Bloom, B.S. Bloom’s Taxonomy: A Forty-Year Retrospective; University of Chicago Press: Chicago, IL, USA, 1996. [Google Scholar]
- Krathwohl, D.R. A Taxonomy for Learning, Teaching and Assessing: A Revision of Bloom’s Taxonomy of Educational Objectives; Longman: New York, NY, USA, 2008. [Google Scholar]
- Bloom, B.S. Taxonomy of Educational Objectives, Handbook I: The Cognitive Domain; David McKay Co., Inc.: Philadelphia, PA, USA, 1956. [Google Scholar]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimed. Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef] [PubMed]
- Ferreira-Mello, R.; André, M.; Pinheiro, A.; Costa, E.; Romero, C. Text mining in education. WIREs Data Min. Knowl. Discov. 2019, 9, e1332. [Google Scholar] [CrossRef]
- Ahadi, A.; Singh, A.; Bower, M.; Garrett, M. Text Mining in Education & A Bibliometrics-Based Systematic Review. Educ. Sci. 2022, 12, 210. [Google Scholar] [CrossRef]
- Lugini, L.; Litman, D.; Godley, A.; Olshefski, C. Annotating Student Talk in Text-based Classroom Discussions. In Proceedings of the 13th Workshop on Innovative Use of NLP for Building Educational Applications, New Orleans, LA, USA, 5 June 2018; Association for Computational Linguistics: New Orleans, Louisiana, 2018; pp. 110–116. [Google Scholar] [CrossRef]
- Chong, C.; Sheikh, U.U.; Samah, N.A.; Sha’ameri, A.Z. Analysis on Reflective Writing Using Natural Language Processing and Sentiment Analysis. IOP Conf. Ser. Mater. Sci. Eng. 2020, 884, 012069. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Ullah, I.; Shamshirb, S.; Khundi, F.M.; Habib, A. Fuzzy-Based Sentiment Analysis System for Analyzing Student Feedback and Satisfaction. Comput. Mater. Contin. 2020, 62, 631–655. [Google Scholar] [CrossRef]
- Okoye, K.; Arrona-Palacios, A.; Camacho-Zuñiga, C.; Achem, J.A.; Escamilla, J.; Hosseini, S. Towards teaching analytics: A contextual model for analysis of students’ evaluation of teaching through text mining and machine learning classification. Educ. Inf. Technol. 2022, 27, 3891–3933. [Google Scholar] [CrossRef] [PubMed]
- Zad, S.; Jimenez, J.; Finlayson, M. Hell Hath No Fury? Correcting Bias in the NRC Emotion Lexicon. In Proceedings of the 5th Workshop on Online Abuse and Harms, Online, 5–6 August 2021; pp. 102–113. [Google Scholar] [CrossRef]
- Banage, T.G.S.; Kumara, A.B.; Paik, I. Bloom’s Taxonomy and Rules Based Question Analysis Approach for Measuring the Quality of Examination Papers. Int. J. Knowl. Eng. 2019, 5, 20–24. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Al-Shabi, M.A. Evaluating the performance of the most important Lexicons used to Sentiment analysis and opinions Mining. Int. J. Comput. Sci. Netw. Secur. 2020, 20, 51–57. [Google Scholar]
- Bonta, V.; Kumaresh, N.; Janardhan, N. A Comprehensive Study on Lexicon Based Approaches for Sentiment Analysis. Asian J. Comput. Sci. Technol. 2019, 8, 1–6. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lesson ID | Alias | Total Number of Students’ Files | NO. of Ignored Files (with Images) | NO. of Analysed Files |
|---|---|---|---|---|
| 101496550 | Lesson 1 | 31 | 15 | 16 |
| 102078874 | Lesson 2 | 30 | 15 | 15 |
| 103999562 | Lesson 3 | 40 | 20 | 20 |
| 104161929 | Lesson 4 | 42 | 21 | 21 |
| Remembering | Understanding | Applying | Analyzing | Evaluating | Creating |
|---|---|---|---|---|---|
| Copying Defining Finding Locating Quoting Listening Googling Repeating Outlining Highlighting Memorizing Networking Searching Identifying Selecting Duplicating Matching Bookmarking Bullet-pointing | Annotating Tweeting Associating Tagging Summarizing Relating Categorizing Paraphrasing Predicting Comparing Contrasting Commenting Interpreting Grouping Inferring Estimating Extending Gathering Exemplifying Expressing | Acting out Articulate Reenact Loading Determining Displaying Judging Executing Examining Implementing Sketching Experimenting Hacking Interviewing Painting Preparing Playing Integrating Presenting Charting | Calculating Breaking- down Correlating Deconstructing Linking Mashing Mind-mapping Organizing Appraising Advertising Dividing Deducing Distinguishing Illustrating Questioning Structuring Integrating Attributing Estimating Explaining | Arguing Validating Testing Scoring Assessing Criticizing Commenting Debating Defending Detecting Grading Hypothesizing Measuring Moderating Posting Predicting Rating Reflecting Reviewing Editorializing | Blogging Building Animating Adapting Collaborating Composing Directing Devising Podcasting Writing Filming Programming Simulating Role playing Solving Mixing Facilitating Managing Negotiating leading |
| Correlation | |
|---|---|
| database, nosql | 0.7445189320116243 |
| database, not | 0.6990950777289033 |
| database, store | 0.676294010356556 |
| database, data | 0.6109001287282151 |
| database, type | 0.5527805688124333 |
| database, relate | 0.5065160024362998 |
| data, store | 0.6503310481300625 |
| data, database | 0.6109001287282151 |
| data, table | 0.5059633235464172 |
| use, table | 0.6715488196512599 |
| use, relate | 0.6300322498066675 |
| use, inform | 0.6047209393116116 |
| use, store | 0.5161765495475054 |
| use, nosql | 0.5052344607758218 |
| Lesson ID | Lesson | Anger | Anticipation | Disgust | Fear | Joy | Sadnes | Surprise | Trust |
|---|---|---|---|---|---|---|---|---|---|
| 101496550 | Lesson 1 | 15 | 16 | 15 | 16 | 16 | 16 | 16 | 16 |
| 102078874 | Lesson 2 | 13 | 15 | 8 | 13 | 14 | 12 | 13 | 13 |
| 103999562 | Lesson 3 | 16 | 19 | 8 | 17 | 17 | 14 | 15 | 18 |
| 104161929 | Lesson 4 | 14 | 20 | 11 | 18 | 19 | 16 | 16 | 19 |
| Lesson | Remebering | Understanding | Applying | Analyzing | Evaluating | Creating |
|---|---|---|---|---|---|---|
| Lesson 1 | 16 | 12 | 15 | 15 | 10 | 8 |
| Lesson 2 | 13 | 9 | 8 | 11 | 11 | 9 |
| Lesson 3 | 18 | 10 | 9 | 11 | 7 | 10 |
| Lesson 4 | 18 | 8 | 7 | 12 | 7 | 15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fargues, M.; Kadry, S.; Lawal, I.A.; Yassine, S.; Rauf, H.T. Automated Analysis of Open-Ended Students’ Feedback Using Sentiment, Emotion, and Cognition Classifications. Appl. Sci. 2023, 13, 2061. https://doi.org/10.3390/app13042061
Fargues M, Kadry S, Lawal IA, Yassine S, Rauf HT. Automated Analysis of Open-Ended Students’ Feedback Using Sentiment, Emotion, and Cognition Classifications. Applied Sciences. 2023; 13(4):2061. https://doi.org/10.3390/app13042061
Chicago/Turabian StyleFargues, Melanie, Seifedine Kadry, Isah A. Lawal, Sahar Yassine, and Hafiz Tayyab Rauf. 2023. "Automated Analysis of Open-Ended Students’ Feedback Using Sentiment, Emotion, and Cognition Classifications" Applied Sciences 13, no. 4: 2061. https://doi.org/10.3390/app13042061
APA StyleFargues, M., Kadry, S., Lawal, I. A., Yassine, S., & Rauf, H. T. (2023). Automated Analysis of Open-Ended Students’ Feedback Using Sentiment, Emotion, and Cognition Classifications. Applied Sciences, 13(4), 2061. https://doi.org/10.3390/app13042061