5.3. Results
To assess the performance of the proposed method, its performance was compared with those of other methods through simulation. Before moving to the presentation of the results, we describe the choices of parameters of different methods used in this study. The splrep() function from the Scipy library [
51] was used to find the B-spline representation of the observed profile data. The key parameters affecting the interpolation include the degree
of the spline, the number of knots
, and the smoothing condition
. In this study, we fixed
to 3 (the most commonly used value) and
to 5 to get a smoother profile. Moreover, we set
(interpolating).
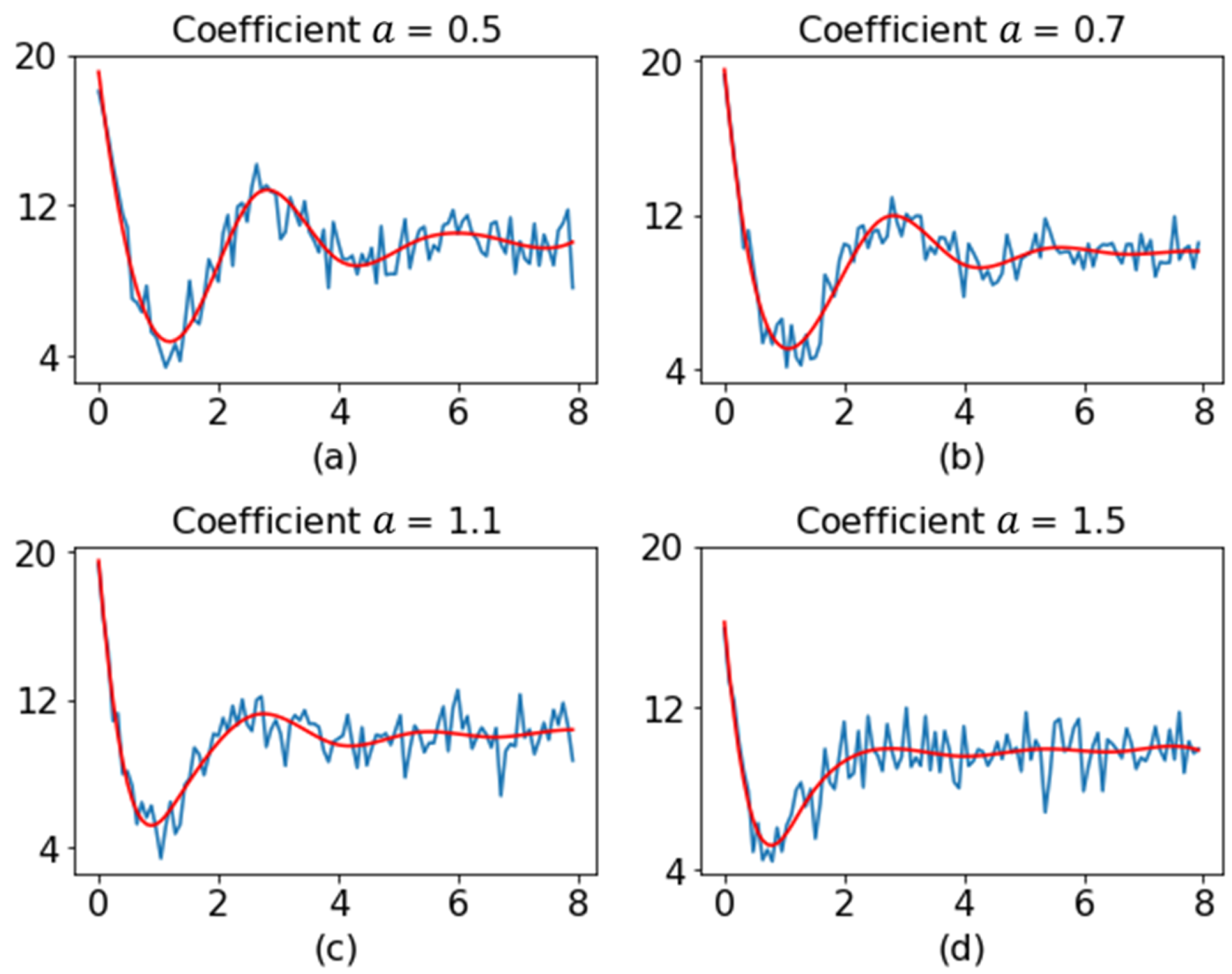
Figure 7 shows the original profile and the smoothed profile for different values of coefficient
.
In determining the distance threshold, the current study set the type I error
in order to be consistent with the study of Zou et al. [
55].
Figure 8 depicts histograms of the calculated distances for different contamination rates. In the normality test (Anderson–Darling test), a
-
greater than the significance level (usually 0.05) indicated the distances had a normal distribution. The results of the normality test conducted in this study indicated that
was an appropriate distance threshold.
Most of the parameters of the three outlier-detection algorithms were set to default values, which could provide a satisfactory performance. For the IF algorithm, the number of trees was set to 200. In phase I analysis, the IC data were assumed to indicate the preponderance of the dataset [
15]. The
-value of the LOF algorithm was chosen to be 120, which was slightly larger than half the number of samples in the dataset.
We now present the results of the comparative study. First, we compare the performance of various methods when the contamination rate is unknown and estimated according to the proposed method described earlier.
Table 1,
Table 2 and
Table 3 present the average type I errors, type II errors, and
scores of various considered algorithms, respectively. All results were obtained from the evaluation of 1000 datasets. For a clear comparison, we also provide the standard deviation of each performance metric. In what follows, the results of the MHD-C and PPOD algorithms are presented from [
33] and [
55], respectively. The results of the LOF, EE, and IF algorithms were obtained in the current research.
When the true contamination rates are 0.1, 0.2, and 0.3, the contamination rates estimated using the proposed approach are 0.15, 0.24, and 0.33, respectively. As shown in
Table 1, regardless of the contamination rate, when the coefficient
is equal to 0.7, the type I error of LOF is smaller than that of MHD-C. The type I error of MHD-C is rapidly enhanced when the coefficient
is large. When the coefficient
is greater than 0.7, the type I errors of LOF are larger than those of MHD-C. The type I error of the PPOD algorithm approaches 0.05 only when the coefficient
is equal to 0.7. For other values of coefficient
, the PPOD algorithm yields a stable type I error but is much greater than 0.05. In all cases, the type I errors of the LOF and EE algorithms are close to the prespecified 0.05. The type I error of the IF algorithm is significantly larger than the prespecified 0.05. As mentioned earlier, using PCA-processed data in the IF algorithm did not improve its performance. Taking the case with parameter
,
as an example, the type I error of IF is 0.089, while that without PCA is 0.072. Except for the IF algorithm, we notice that the type I errors of other methods start to decrease as
becomes larger.
From
Table 2, it is readily apparent that regardless of the contamination rate and the size of coefficient
, the type II errors of the LOF and EE algorithms are less than or equal to those of MHD-C. LOF and EE perform almost equally well. The PPOD algorithm produces a stable type II error when the coefficient
, but performs worse than MHD-C when
. In all outlier-detection methods, IF has the highest type II error. Moreover, the type II errors of the different considered algorithms increase with the contamination rate.
Table 3 shows the
score of each considered method. For methods MHD-C and PPOD, this study can only use the mean values of the type I and type II errors to estimate the
score due to a lack of availability of original data. Therefore, the standard deviation of the
value is not provided in
Table 3. Several trends can be observed from this table. The
scores of the LOF and EE algorithms are unaffected by the size of coefficient
and remain stable. The LOF algorithm has higher
scores than all the other algorithms; however, when the coefficient
increases, the
scores of other algorithms increase considerably. This result can be explained by the fact that as the coefficient
increases, the type II error decreases substantially, which results in a considerable increase in the
score. It is worth noting that when the coefficient
, the
score of the MHD-C algorithm is considerably lower than that of the LOF and EE algorithms. However, when the coefficient
, the
scores of the MHD-C algorithm are all close to the ideal value of 1.0.
The variation in the performance of the MHD-C algorithm may be attributed to the method of performance evaluation. The adopted evaluation framework is based on the assumption that there is only one size of coefficient in each dataset. However, in practical applications, each collected dataset may contain a variety of outlying profiles with different sizes of coefficient , and this affects the estimation of type I and type II errors.
Another interesting observation is that the performance of the PPOD and IF algorithms is similar. When the coefficient is equal to 0.7, the scores of both methods are very low, but as the coefficient increases, their scores stabilize.
As the contamination rate increases, the scores of the LOF and EE algorithms increase. This indicates that the LOF and EE algorithms have lower false negative rates. However, the scores of the PPOD and IF algorithms decrease with an increase in the contamination rate. The score of the LOF algorithm is marginally higher than that of the EE algorithm, and these algorithms have similar type I and type II errors. The score of the IF algorithm is substantially lower than those of the other algorithms.
In the above comparisons, type I and type II errors were assessed separately for different parameters . This evaluation method does not quite match the situation of practical application. The dataset collected in SPC phase I usually contains normal profiles and outlying profiles of various variation sizes (different parameter ). The variation of parameter has the greatest impact on type II errors, so we compare the performance of different algorithms when parameter is the smallest (). This represents the most difficult situation to detect. The proposed method achieves a superior performance as compared to traditional methods. The type I error, type II error, and score of LOF are 0.049, 0.001, and 0.951, respectively, and for MHD-C, which is the second best, are 0.081, 0.015, and 0.899, respectively.
We subsequently compared the performance of various methods given known contamination rates. Under this condition, only the three outlier-detection algorithms were are considered. This is because when the contamination rate is known, the outlier-detection algorithms are advantageous compared to the MHD-C and PPOD algorithms, and the comparison results will be biased. Therefore, we chose to compare only outlier-detection algorithms.
Table 4,
Table 5 and
Table 6 summarizes the type I errors, type II errors, and
scores of the three outlier-detection algorithms, respectively.
Table 4 indicates that when the contamination rate is less than 0.3 (i.e.,
), the type I error of the LOF algorithm is marginally lower than that of the EE algorithm. When the contamination rate is 0.3, the type I error of the EE algorithm is marginally lower than that of the LOF algorithm. Moreover, the type I error of the IF algorithm is considerably higher than those of the other two algorithms.
Table 5 presents the type II errors of the three outlier algorithms. We can see that the results have the same trend as those for the type I errors, that is, the type II error of the LOF algorithm is close to that of the EE algorithm, whereas the IF algorithm has a considerably higher type II error than the other two algorithms. When the coefficient
is higher than 0.9, the type II errors of the LOF and EE algorithms approach 0, while the IF algorithm still has a very high type II error. As presented in
Table 6, the
scores of the LOF and EE algorithms are almost equal to 1 when the coefficient
is greater than or equal to 0.9. The IF algorithm has high type I and type II errors and poor
performance.
It should be noted that the collected dataset may contain profiles with different sizes of coefficient
. The evaluation framework employed in previous relevant studies [
33,
55] is based on the assumption that only one size of coefficient
exists in each dataset. This approach might produce biased estimates of overall performance. The type I error obtained using the method of Nie et al. [
33] might be affected by the outlying profiles with the smallest value of coefficient
. In contrast, the method proposed in this study can maintain a stable performance under variation of coefficient
.
To verify the aforementioned statement, we conducted an additional experiment. For each contamination rate, we generated an additional 1000 datasets, each of which included different values of coefficient
. The results of this experiment are shown in
Table 7,
Table 8 and
Table 9. As presented in
Table 7, the LOF and EE algorithms keep the same type I error under different values of coefficient
. The type I error of the IF algorithm is highly dependent on the value of coefficient
. Therefore, the EE and LOF algorithms outperform the IF algorithm.
Table 7 and
Table 8 indicate that the IF algorithm seems to have the highest type I and type II errors and leads to an unsatisfactory
performance, as shown in
Table 9. The results in
Table 7,
Table 8 and
Table 9 indicate that the performance of the LOF and EE algorithms is not substantially affected by variations in the magnitudes of the outlier profiles.
When the contamination rate is known, the type I errors of the three outlier-detection algorithms are lower than when the estimated contamination rate is used. This is because the type I error of the proposed method is a fixed value. With known contamination rates, while type I errors are significantly reduced, the type II errors of the three outlier-detection algorithms are also slightly increased.
In all cases, the LOF and EE algorithms have quite close performance, and both substantially outperform the IF algorithm. This result can be attributed to the characteristics of profiles in the OOC state. In the future, different types of profiles and their anomaly types can be studied to compare the performance of various outlier-detection algorithms in further detail.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}