
CFSR: Coarse-to-Fine High-Speed Motion Scene Reconstruction with Region-Adaptive-Based Spike Distinction


Abstract
:1. Introduction
2. Related Works
2.1. Spike Data Representation
2.2. Reconstruction Methods
2.2.1. Texture from ISI
2.2.2. Texture from Playback
2.2.3. Spiking Neural Model
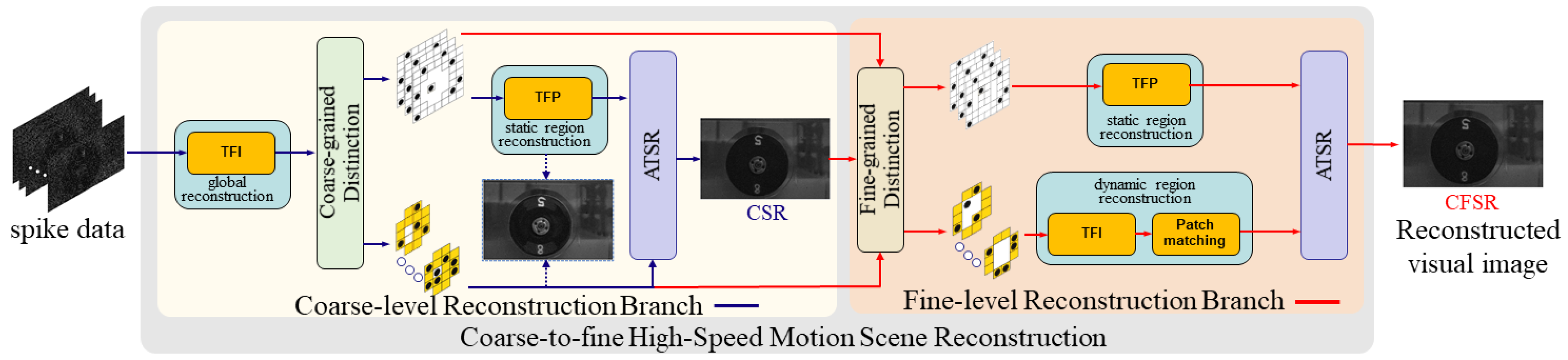
3. The CFSR Method
3.1. The Coarse-to-Fine High-Speed Motion Scene Reconstruction Framework
3.2. Coarse-Grained Reconstruction
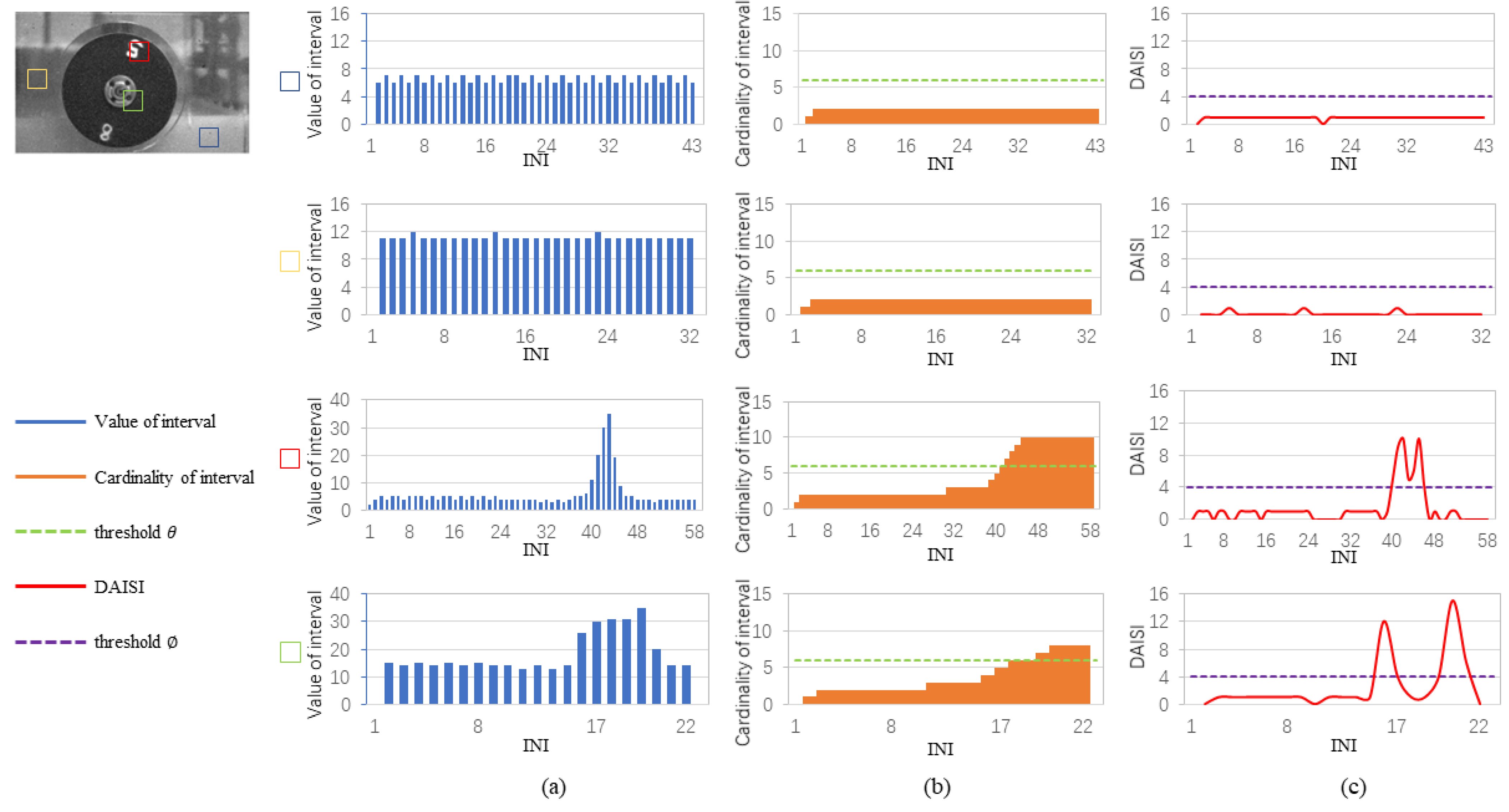
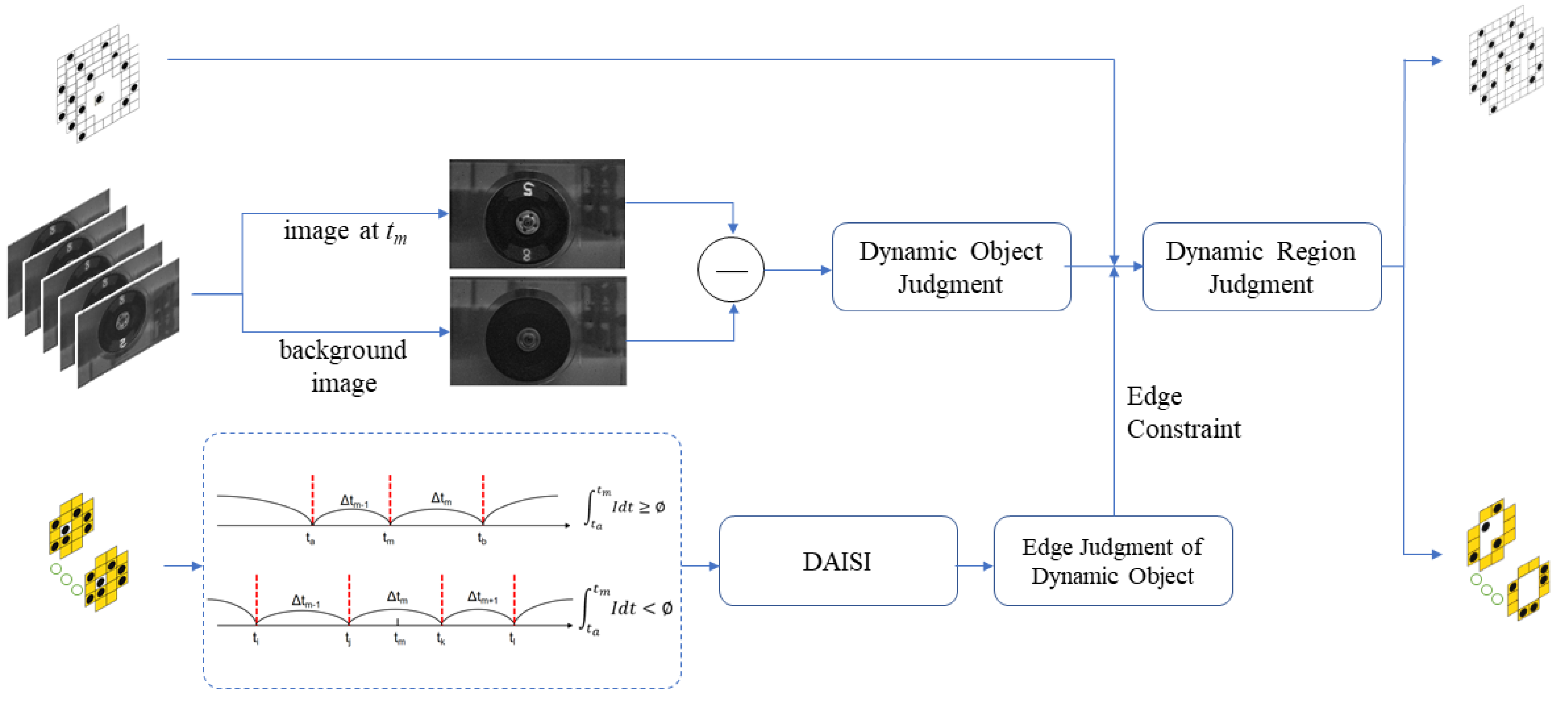
3.3. Fine-Grained Reconstruction
4. Experiment Results
4.1. Experimental Setting
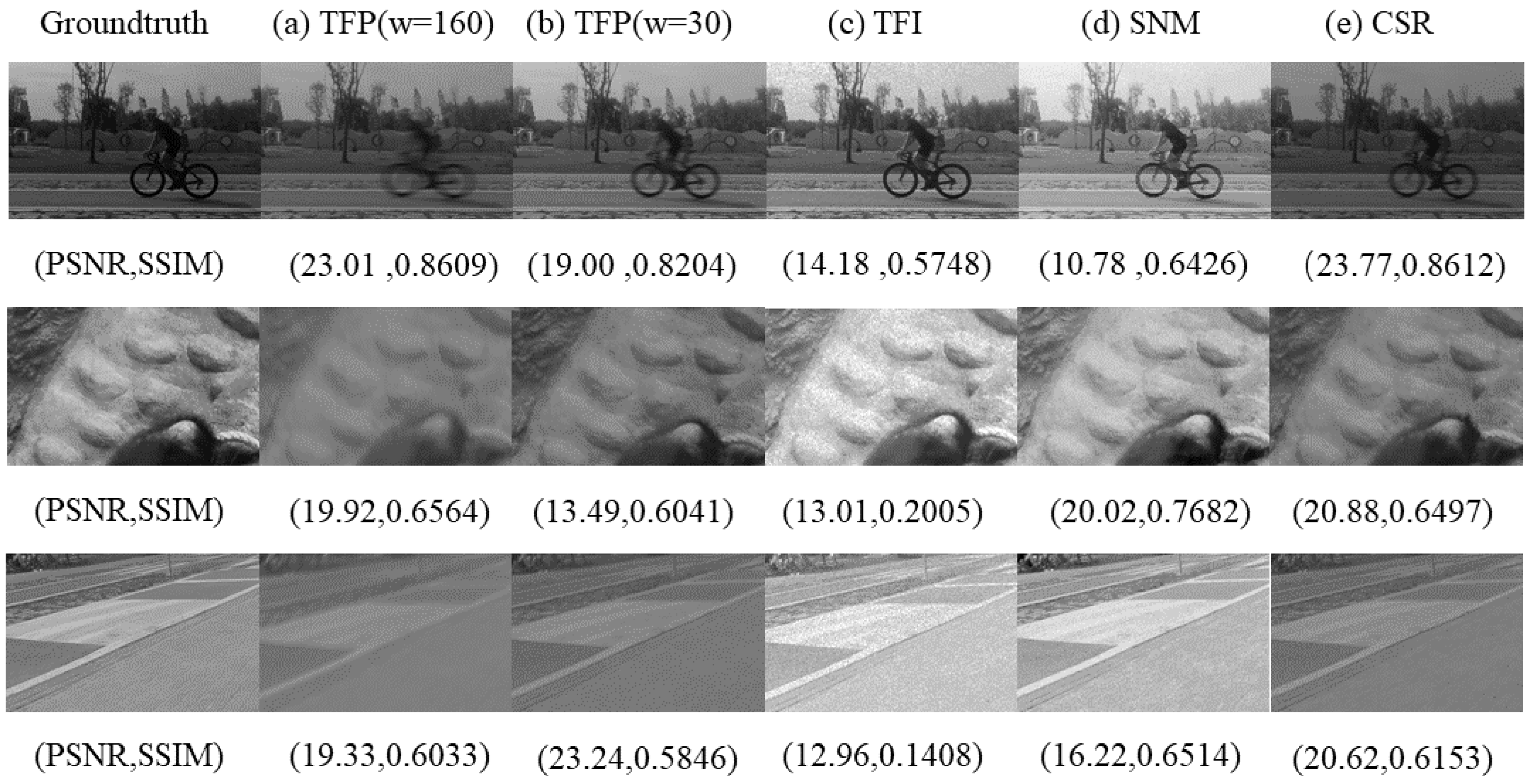
4.2. Visual Texture Reconstruction
4.3. Complexity Analysis
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Liu, C.; Huynh, D.Q.; Sun, Y.; Reynolds, M.; Atkinson, S. A Vision-Based Pipeline for Vehicle Counting, Speed Estimation, and Classification. IEEE Trans. Intell. Transp. Syst. 2021, 22, 7547–7560. [Google Scholar] [CrossRef]
- Sana, F.; Isselbacher, E.M.; Singh, J.P.; Heist, E.K.; Pathik, B.; Armoundas, A.A. Wearable Devices for Ambulatory Cardiac Monitoring. J. Am. Coll. Cardiol. 2020, 75, 1582–1592. [Google Scholar] [CrossRef] [PubMed]
- Litzenberger, M.; Posch, C.; Bauer, D.; Belbachir, A.N.; Schon, P.; Kohn, B.; Garn, H. Embedded vision system for real-time object tracking using an asynchronous transient vision sensor. In Proceedings of the 2006 IEEE 12th Digital Signal Processing Workshop & 4th IEEE Signal Processing Education Workshop, Teton National Park, WY, USA, 24–27 September 2006; pp. 173–178. [Google Scholar]
- Gehrig, D.; Rebecq, H.; Gallego, G.; Scaramuzza, D. Asynchronous, photometric feature tracking using events and frames. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 750–765. [Google Scholar]
- Maqueda, A.I.; Loquercio, A.; Gallego, G.; García, N.; Scaramuzza, D. Event-based vision meets deep learning on steering prediction for self-driving cars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5419–5427. [Google Scholar]
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 × 128 120 db 15 μs latency asynchronous temporal contrast vision sensor. IEEE J. -Solid-State Circuits 2008, 43, 566–576. [Google Scholar] [CrossRef]
- Berner, R.; Brandli, C.; Yang, M.; Liu, S.; Delbruck, T. A 240 × 180 10 mw 12 μs latency sparse-output vision sensor for mobile applications. In Proceedings of the 2013 Symposium on VLSI Circuits, Kyoto, Japan, 12–14 June 2013; pp. C186–C187. [Google Scholar]
- Hu, Y.; Liu, H.; Pfeiffer, M.; Delbruck, T. Dvs benchmark datasets for object tracking, action recognition, and object recognition. Front. Neurosci. 2016, 10, 405. [Google Scholar] [CrossRef] [PubMed]
- Barranco, F.; Fermuller, C.; Aloimonos, Y.; Delbruck, T. A dataset for visual navigation with neuromorphic methods. Front. Neurosci. 2016, 10, 49. [Google Scholar] [CrossRef] [PubMed]
- Binas, J.; Neil, D.; Liu, S.C.; Delbruck, T. Ddd17: End-to-end davis driving dataset. arXiv 2017, arXiv:1711.01458. [Google Scholar]
- Liu, M.; Qi, N.; Shi, Y.; Yin, B. An Attention Fusion Network For Event-Based Vehicle Object Detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3363–3367. [Google Scholar] [CrossRef]
- Wang, Z.W.; Duan, P.; Cossairt, O.; Katsaggelos, A.; Huang, T.; Shi, B. Joint Filtering of Intensity Images and Neuromorphic Events for High-Resolution Noise-Robust Imaging. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1606–1616. [Google Scholar] [CrossRef]
- Brandli, C.; Berner, R.; Yang, M.; Liu, S.C.; Delbruck, T. A 240 × 180 130 db 3 μs latency global shutter spatiotemporal vision sensor. IEEE J. Solidst. Circ. 2014, 49, 2333–2341. [Google Scholar] [CrossRef]
- Posch, D.M.C.; Wohlgenannt, R. An asynchronous time-based image sensor. In Proceedings of the IEEE International Symposium on Circuits and Systems, Geneva, Switzerland, 28–31 May 2000; pp. 2130–2133. [Google Scholar]
- Gould, S.; Arfvidsson, J.; Kaehler, A.; Sapp, B.; Messner, M.; Bradski, G.; Baumstarck, P.; Chung, S.; Ng, A.Y. Arfvidsson, Peripheral-foveal vision for real-time object recognition and tracking in video. In International Joint Conference on Artificial Intelligence; Morgan Kaufmann Publishers, Inc.: San Francisco, CA, USA, 2007. [Google Scholar]
- Zhao, J.; Yu, Z.; Ma, L.; Ding, Z.; Zhang, S.; Tian, Y.; Huang, T. Modeling The Detection Capability of High-Speed Spiking Cameras. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 4653–4657. [Google Scholar] [CrossRef]
- Dong, S.; Huang, T.; Tian, Y. Spike camera and its coding methods. In Proceedings of the Data Compression Conference, (DCC), Snowbird, UT, USA,, 4–7 April 2017; p. 437. [Google Scholar]
- Dong, S.; Zhu, L.; Xu, D.; Tian, Y.; Huang, T. An efficient coding method for spike camera using inter-spike intervals. In Proceedings of the Data Compression Conference, (DCC), Snowbird, UT, USA, 26–29 March 2019; p. 568. [Google Scholar]
- Zhu, L.; Dong, S.; Huang, T.; Tian, Y. A retina-inspired sampling method for visual texture reconstruction. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1432–1437. [Google Scholar]
- Culurciello, E.; Cummings, R.E.; Boahen, K.A. A biomorphic digital image sensor. IEEE J. -Solid-State Circuits 2003, 38, 281–294. [Google Scholar] [CrossRef]
- Zhao, J.; Xiong, R.; Zhao, R.; Wang, J.; Ma, S.; Huang, T. Motion Estimation for Spike Camera Data Sequence via Spike Interval Analysis. In Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP), Macau, China, 1–4 December 2020; pp. 371–374. [Google Scholar] [CrossRef]
- Zhao, J.; Xiong, R.; Liu, H.; Zhang, J.; Huang, T. Spk2ImgNet: Learning to Reconstruct Dynamic Scene from Continuous Spike Stream. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 11991–12000. [Google Scholar] [CrossRef]
- Zhu, L.; Dong, S.; Li, J.; Huang, T.; Tian, Y. Retina-like visual image reconstruction via spiking neural model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zheng, Y.; Zheng, L.; Yu, Z.; Shi, B.; Tian, Y.; Huang, T. High-speed Image Reconstruction through Short-term Plasticity for Spiking Cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Hu, Z.; Lu, G.; Guo, J.; Liu, S.; Jiang, W.; Xu, D. Coarse-to-fine Deep Video Coding with Hyperprior-guided Mode Prediction. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 5911–5920. [Google Scholar]
- Ranjan, A.; Black, M.J. Optical flow estimation using a spatial pyramid network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4161–4170. [Google Scholar]
- Gollisch, T.; Markus, M. Rapid neural coding in the retina with relative spike latencies. Science 2008, 319, 1108–1111. [Google Scholar] [CrossRef] [PubMed]
- Geman, S.; Geman, D. Stochastic relaxation, gibbs distributions, and the bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef] [PubMed]
- Bi, G.; Poo, M. Synaptic modifications in cultured hippocampal neurons: Dependence on spike timing, synaptic strength, and postsynaptic cell type. J. Neurosci. 1998, 18, 10464–10472. [Google Scholar] [CrossRef] [PubMed]
- Diehl, P.U.; Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef] [PubMed]
- Stauffer, C.; Grimson, W. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins, CO, USA, 23–25 June 1999; pp. 246–252. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A Randomized Correspondence Algorithm for Structural Image Editing. ACM Trans. Graph 2009, 28, 24. [Google Scholar] [CrossRef]
- Liu, L.; Hua, Y.; Zhao, Q.; Huang, H.; Bovik, A.C. Blind image quality assessment by relative gradient statistics and adaboosting neural network. Signal Process. Image Commun. 2016, 40, 1–15. [Google Scholar] [CrossRef]
- Ferzli, R.; Karam, L.J. A No-Reference Objective Image Sharpness Metric Based on the Notion of Just Noticeable Blur (JNB). IEEE Trans. Image Process. 2009, 18, 717–728. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Method | Rotation1 | Rotation2 | Car | Mean |
|---|---|---|---|---|---|
| TFI [18] | 25.1455 | 40.1673 | 53.6904 | 39.6677 | |
| TFP [20] | 23.5241 | 35.9377 | 43.6953 | 34.3858 | |
| SNM [24] | 39.9200 | 60.2485 | 58.1364 | 52.7683 | |
| CSR | 24.3537 | 37.6037 | 55.8144 | 39.2573 | |
| STD | CFSR | 50.6763 | 75.0012 | 68.4223 | 64.6998 |
| TFI | 0.9101 | 0.8189 | 0.9572 | 0.8954 | |
| TFP | 0.8115 | 0.6153 | 0.5075 | 0.6448 | |
| SNM | 0.8254 | 0.6376 | 0.6511 | 0.7041 | |
| CSR | 0.8811 | 0.6781 | 0.7564 | 0.7719 | |
| CPBD [34] | CFSR | 0.9262 | 0.6905 | 0.8109 | 0.8092 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, S.; Qi, N.; Zhu, Q.; Xu, W.; Jin, S. CFSR: Coarse-to-Fine High-Speed Motion Scene Reconstruction with Region-Adaptive-Based Spike Distinction. Appl. Sci. 2023, 13, 2424. https://doi.org/10.3390/app13042424
Du S, Qi N, Zhu Q, Xu W, Jin S. CFSR: Coarse-to-Fine High-Speed Motion Scene Reconstruction with Region-Adaptive-Based Spike Distinction. Applied Sciences. 2023; 13(4):2424. https://doi.org/10.3390/app13042424
Chicago/Turabian StyleDu, Shangdian, Na Qi, Qing Zhu, Wei Xu, and Shuang Jin. 2023. "CFSR: Coarse-to-Fine High-Speed Motion Scene Reconstruction with Region-Adaptive-Based Spike Distinction" Applied Sciences 13, no. 4: 2424. https://doi.org/10.3390/app13042424
APA StyleDu, S., Qi, N., Zhu, Q., Xu, W., & Jin, S. (2023). CFSR: Coarse-to-Fine High-Speed Motion Scene Reconstruction with Region-Adaptive-Based Spike Distinction. Applied Sciences, 13(4), 2424. https://doi.org/10.3390/app13042424