
Vision Transformer Approach for Classification of Alzheimer’s Disease Using 18F-Florbetaben Brain Images



Abstract
:1. Introduction
1.1. Related Works
1.2. Organization of Article
2. Materials and Methods
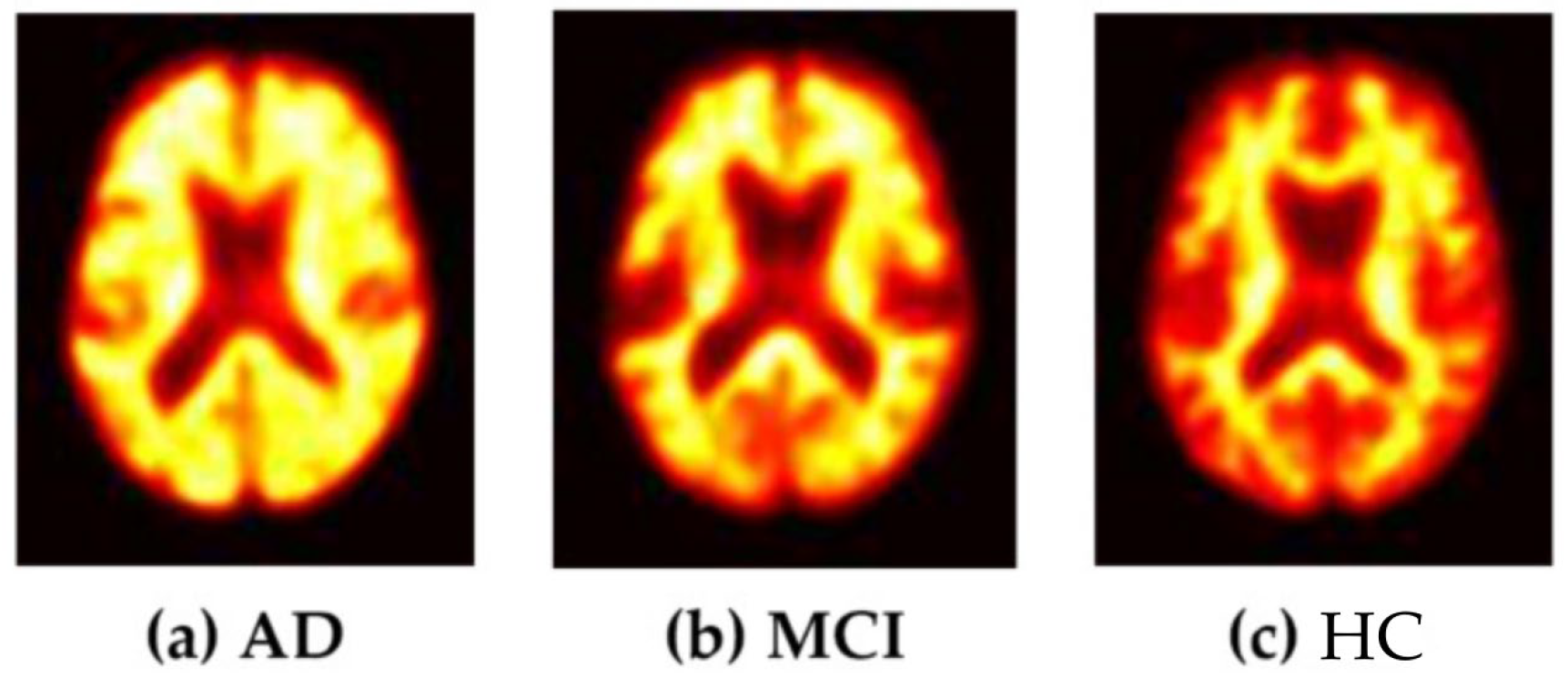
2.1. Data Acquisition
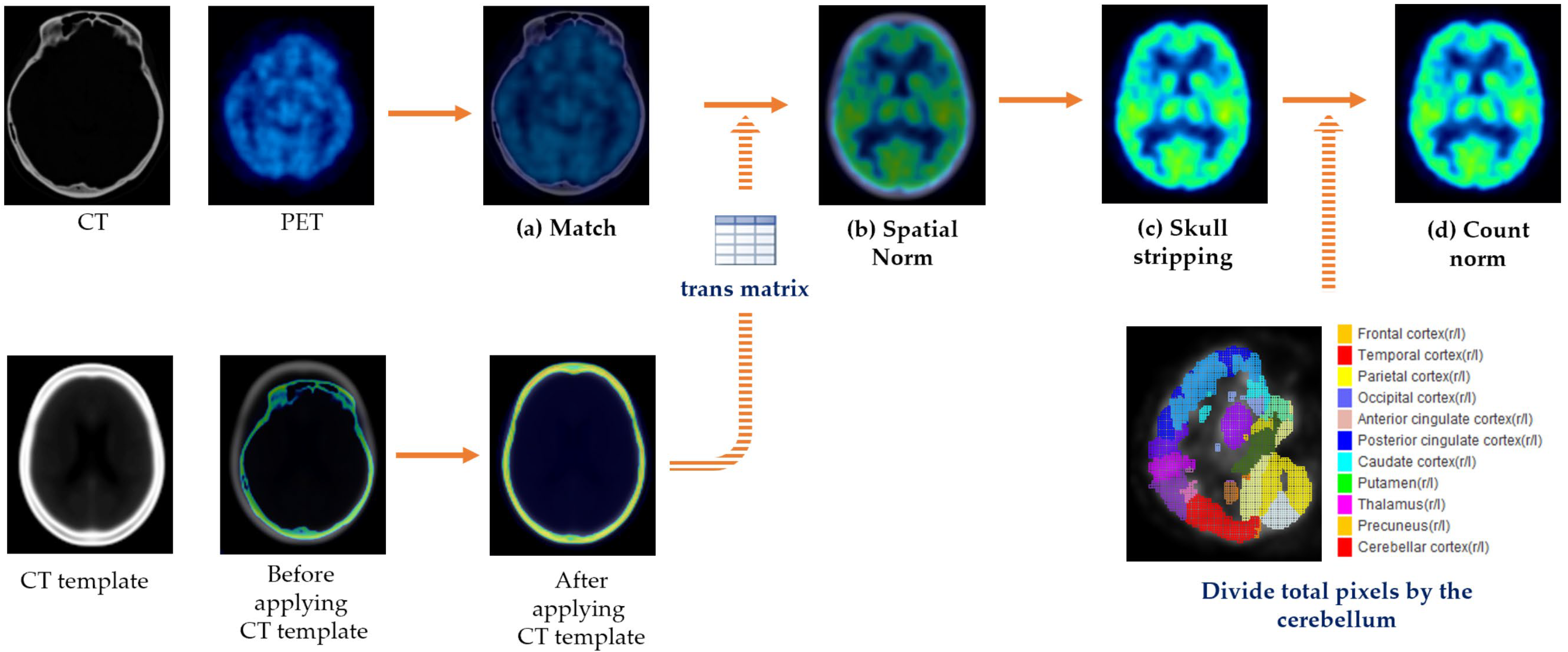
2.2. Data Preprocessing
2.2.1. Image Acquisition and Preprocessing
2.2.2. Conversion of 3D Images to 2D Images and Data Augmentation
2.3. Pretrained Models Used in the Study
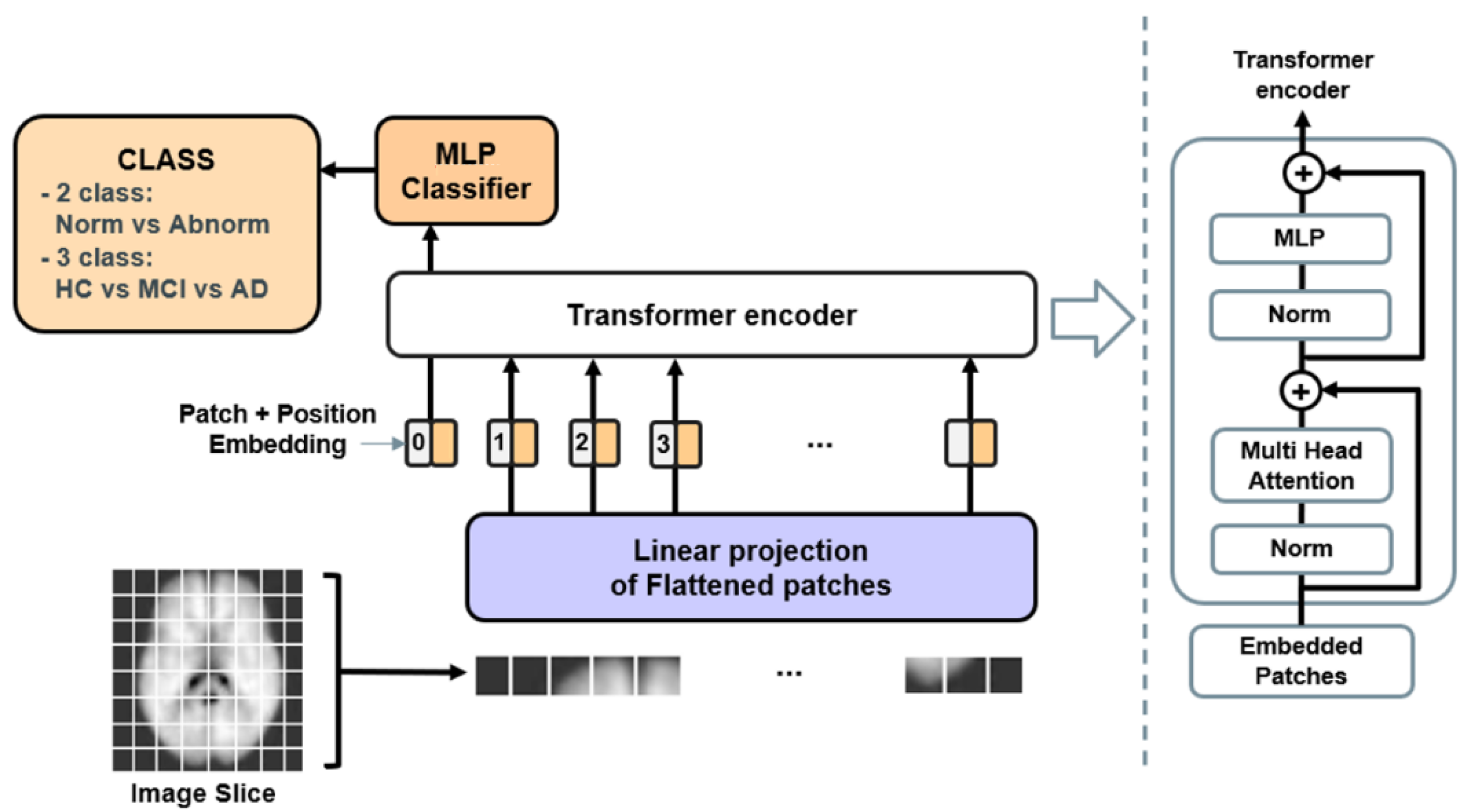
2.3.1. ViT Architecture
- (1)
- represents the original image size.
- (2)
- is the input to the ViT after flattening the original image:
- (3)
- represents the number of patches, with N being the sequence length of the transformer. P is the size of the patch, which is a square. The resolution of the original image is (H, W) and the patch resolution of each image is (P, P).
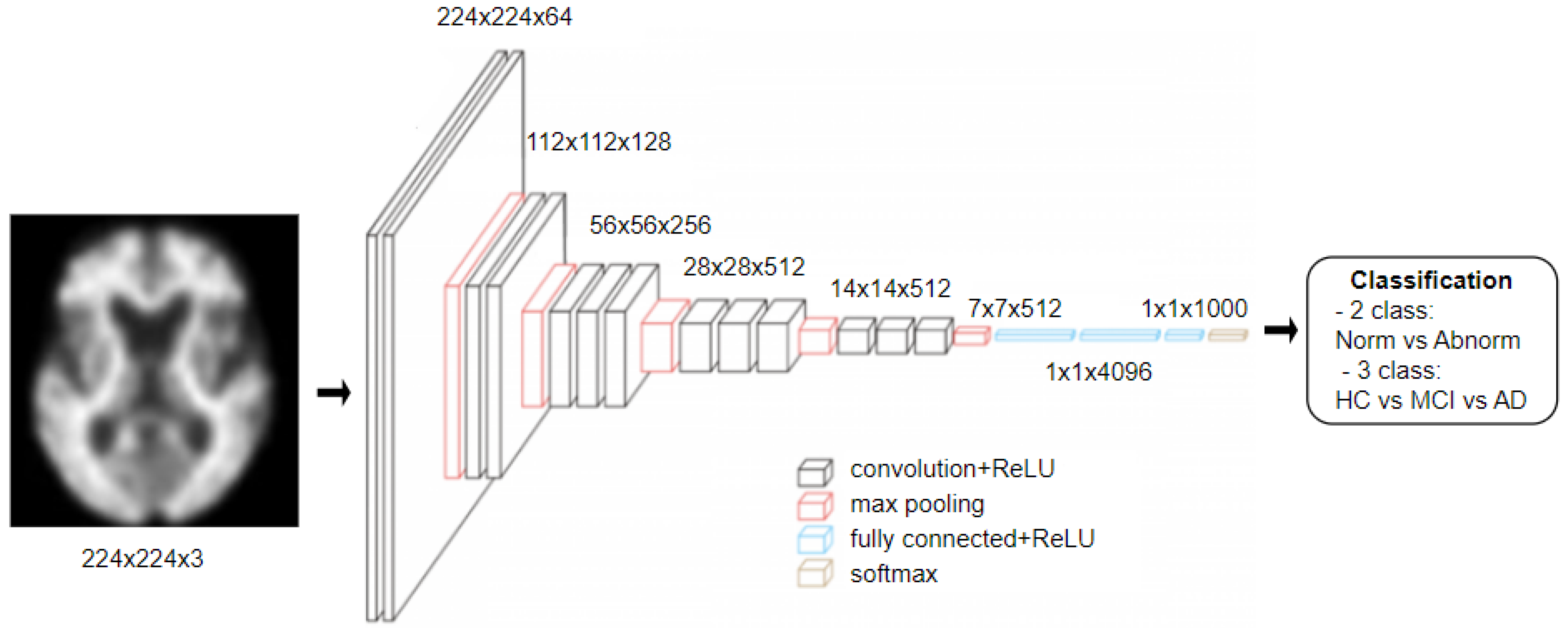
2.3.2. VGG19 Architecture
3. Experiments and Results
3.1. Experimental Setting
3.2. Classification Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Botirovich, E.O.; Zoxirovna, X.N. Nursing Care for Patients with Cognitive Impairment and Dementia. Eur. J. Mod. Med. Pract. 2022, 2, 55–56. [Google Scholar]
- World Health Organization. Global Status Report on the Public Health Response to Dementia. Available online: https://www.who.int/publications/i/item/9789240033245 (accessed on 11 November 2022).
- Behfar, Q.; Ramirez Zuniga, A.; Martino-Adami, P.V. Aging, Senescence, and Dementia. J. Prev. Alzheimer’s Dis. 2022, 9, 523–531. [Google Scholar] [CrossRef]
- Rasmussen, J.; Langerman, H. Alzheimer’s disease—Why we need early diagnosis. Degener. Neurol. Neuromuscul. Dis. 2019, 9, 123–130. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jack, C.R., Jr.; Bennett, D.A.; Blennow, K.; Carrillo, M.C.; Dunn, B.; Haeberlein, S.B.; Holtzman, D.M.; Jagust, W.; Jessen, F.; Karlawish, J.; et al. Contributors NIA-AA Research Framework: Toward a biological definition of Alzheimer’s disease. Alzheimers Dement. 2018, 14, 535–562. [Google Scholar] [CrossRef]
- Mecocci, P.; Boccardi, V. The impact of aging in dementia: It is time to refocus attention on the main risk factor of dementia. Ageing Res. Rev. 2020, 65, 101210. [Google Scholar] [CrossRef]
- Aggarwal, R.; Sounderajah, V.; Martin, G.; Ting, D.S.W.; Karthikesalingam, A.; King, D.; Ashrafian, H.; Darzi, A. Diagnostic accuracy of deep learning in medical imaging: A systematic review and meta-analysis. Npj Digit. Med. 2021, 4, 65. [Google Scholar] [CrossRef]
- Varoquaux, G.; Cheplygina, V. Machine learning for medical imaging: Methodolaogical failures and recommendations for the future. Npj Digit. Med. 2022, 5, 48. [Google Scholar] [CrossRef] [PubMed]
- Salahuddin, Z.; Woodruff, H.C.; Chatterjee, A.; Lambin, P. Transparency of deep neural networks for medical image analysis: A review of interpretability methods. Comput. Biol. Med. 2022, 140, 105111. [Google Scholar] [CrossRef]
- Acquarelli, J.; van Laarhoven, T.; Postma, G.J.; Jansen, J.J.; Rijpma, A.; van Asten, S.; Heerschap, A.; Buydens, L.M.C.; Marchiori, E. Convolutional neural networks to predict brain tumor grades and Alzheimer’s disease with MR spectroscopic imaging data. PLoS ONE 2022, 17, e0268881. [Google Scholar] [CrossRef]
- Samhan, L.F.; Alfarra, A.H.; Abu-Naser, S.S. Classification of Alzheimer’s Disease Using Convolutional Neural Networks. Int. J. Acad. Inf. Syst. Res. 2022, 6, 18–23. [Google Scholar]
- Kang, W.; Lin, L.; Zhang, B.; Shen, X.; Wu, S.; Alzheimer’s Disease Neuroimaging Initiative. Multi-model and multi-slice ensemble learning architecture based on 2D convolutional neural networks for Alzheimer’s disease diagnosis. Comput. Biol. Med. 2021, 136, 104678. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformer. In European Conference on Computer Vision—ECCV 2020, 16th European Conference, Glasgow, UK, August 23–28, 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Guo, J.; Han, K.; Wu, H.; Tang, Y.; Chen, X.; Wang, Y.; Xu, C. Cmt: Convolutional neural networks meet vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12175–12185. [Google Scholar]
- Lyu, Y.; Yu, X.; Zhu, D.; Zhang, L. Classification of Alzheimer’s Disease via Vision Transformer: Classification of Alzheimer’s Disease via Vision Transformer. In Proceedings of the 15th International Conference on PErvasive Technologies Related to Assistive Environments, Corfu Island, Greece, 29 June–1 July 2022; pp. 463–468. [Google Scholar]
- Sarraf, S.; Sarraf, A.; DeSouza, D.D.; Anderson, J.A.E.; Kabia, M.; Alzheimer’s Disease Neuroimaging Initiative. OViTAD: Optimized vision transformer to predict various stages of Alzheimer’s disease using resting-state fMRI and structural MRI data. Brain Sci. 2023, 13, 260. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y.; Jin, W.; Bai, J.; Liu, R.; Zhen, H. SMIL-DeiT: Multiple Instance Learning and Self-supervised Vision Transformer network for Early Alzheimer’s disease classification. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–6. [Google Scholar]
- Mirzaei, G.; Adeli, H. Machine learning techniques for diagnosis of Alzheimer disease, mild cognitive disorder, and other types of dementia. Biomed. Signal Process. Control 2021, 72, 103293. [Google Scholar] [CrossRef]
- Castellazzi, G.; Cuzzoni, M.G.; Ramusino, M.C.; Martinelli, D.; Denaro, F.; Ricciardi, A.; Vitali, P.; Anzalone, N.; Bernini, S.; Palesi, F.; et al. A Machine Learning Approach for the Differential Diagnosis of Alzheimer and Vascular Dementia Fed by MRI Selected Features. Front. Neuroinform. 2020, 14, 25. [Google Scholar] [CrossRef] [PubMed]
- Kruthika, K.; Rajeswari; Maheshappa, H. Multistage classifier-based approach for Alzheimer’s disease prediction and retrieval. Inform. Med. Unlocked 2019, 14, 34–42. [Google Scholar] [CrossRef]
- Richhariya, B.; Tanveer, M.; Rashid, A. Diagnosis of Alzheimer’s disease using universum support vector machine based recursive feature elimination (USVM-RFE). Biomed. Signal Process. Control 2020, 59, 101903. [Google Scholar] [CrossRef]
- Liang, G.; Xing, X.; Liu, L.; Zhang, Y.; Ying, Q.; Lin, A.L.; Jacobs, N. Alzheimer’s disease classification using 2d convolutional neural networks. In Proceedings of the 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society, Virtual, 1–5 November 2021. [Google Scholar]
- Yoon, H.J.; Jeong, Y.J.; Kang, D.-Y.; Kang, H.; Yeo, K.K.; Jeong, J.E.; Park, K.W.; Choi, G.E.; Ha, S.-W. Effect of Data Augmentation of F-18-Florbetaben Positron-Emission Tomography Images by Using Deep Learning Convolutional Neural Network Architecture for Amyloid Positive Patients. J. Korean Phys. Soc. 2019, 75, 597–604. [Google Scholar] [CrossRef]
- Hu, Z.; Wang, Z.; Jin, Y.; Hou, W. VGG-TSwinformer: Transformer-based deep learning model for early Alzheimer’s disease prediction. Comput. Methods Programs Biomed. 2023, 229, 107291. [Google Scholar] [CrossRef] [PubMed]
- Carcagnì, P.; Leo, M.; Del Coco, M.; Distante, C.; De Salve, A. Convolution Neural Networks and Self-Attention Learners for Alzheimer Dementia Diagnosis from Brain MRI. Sensors 2023, 23, 1694. [Google Scholar] [CrossRef]
- Kadri, R.; Bouaziz, B.; Tmar, M.; Gargouri, F. Multimodal deep learning based on the combination of EfficientNetV2 and ViT for Alzheimer’s disease early diagnosis enhanced by SAGAN data augmentation. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 2022, 14, 313–325. [Google Scholar]
- Jang, J.; Hwang, D. M3T: Three-dimensional Medical image classifier using Multi-plane and Multi-slice Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20718–20729. [Google Scholar]
- Kushol, R.; Masoumzadeh, A.; Huo, D.; Kalra, S.; Yang, Y.-H. Addformer: Alzheimer’s Disease Detection from Structural Mri Using Fusion Transformer. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Zhu, J.; Tan, Y.; Lin, R.; Miao, J.; Fan, X.; Zhu, Y.; Liang, P.; Gong, J.; He, H. Efficient self-attention mechanism and structural distilling model for Alzheimer’s disease diagnosis. Comput. Biol. Med. 2022, 147, 105737. [Google Scholar] [CrossRef]
- Liu, L.; Liu, S.; Zhang, L.; To, X.V.; Nasrallah, F.; Chandra, S.S. Cascaded Multi-Modal Mixing Transformers for Alzheimer’s Disease Classification with Incomplete Data. arXiv 2022, arXiv:2210.00255. [Google Scholar]
- Wang, C.; Li, Y.; Tsuboshita, Y.; Sakurai, T.; Goto, T.; Yamaguchi, H.; Yamashita, Y.; Sekiguchi, A.; Tachimori, H.; Alzheimer’s Disease Neuroimaging Initiative. A high-generalizability machine learning framework for predicting the progression of Alzheimer’s disease using limited data. Npj Digit. Med. 2022, 5, 43. [Google Scholar] [CrossRef] [PubMed]
- Eroglu, Y.; Yildirim, M.; Cinar, A. mRMR-based hybrid convolutional neural network model for classification of Alzheimer’s disease on brain magnetic resonance images. Int. J. Imaging Syst. Technol. 2022, 32, 517–527. [Google Scholar] [CrossRef]
- Barthel, H.; Gertz, H.J.; Dresel, S.; Peters, O.; Bartenstein, P.; Buerger, K.; Hiemeyer, F.; Wittemer-Rump, S.M.; Seibyl, J.; Reininger, C.; et al. Cerebral amyloid-B PET with florbetaben (18F) in patients with Alzheimer’s disease and healthy controls: A mlticenter phase 2 diagnostic study. Lancet Neurol. 2011, 10, 424–435. [Google Scholar] [CrossRef] [PubMed]
- Chlap, P.; Min, H.; Vandenberg, N.; Dowling, J.; Holloway, L.; Haworth, A. A review of medical image data augmentation techniques for deep learning applications. J. Med. Imaging Radiat. Oncol. 2021, 65, 545–563. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:14091556. [Google Scholar]
- Lee, S.Y.; Kang, H.; Jeong, J.H.; Kang, D.Y. Performance evaluation in [18F] Florbetaben brain PET images classification using 3D Convolutional Neural Network. PLoS ONE 2021, 16, e0258214. [Google Scholar] [CrossRef]
- Xiao, J.; Wang, J.; Cao, S.; Li, B. Application of a Novel and Improved VGG-19 Network in the Detection of Workers Wearing Masks. J. Phys. Conf. Ser. 2020, 1518, 012041. [Google Scholar] [CrossRef]
- Manimurugan, S. Classification of Alzheimer’s disease from MRI Images using CNN based Pre-trained VGG-19 Model. J. Comput. Sci. Intell. Technol. 2020, 1, 15–21. [Google Scholar]
- Lu, S.; Xia, Y.; Cai, W.; Fulham, M.; Feng, D.D. Early identification of mild cognitive impairment using incomplete random forest-robust support vector machine and FDG-PET imaging. Comput. Med. Imaging Graph. 2017, 60, 35–41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xing, X.; Liang, G.; Zhang, Y.; Khanal, S.; Lin, A.-L.; Jacobs, N. Advit: Vision Transformer On Multi-Modality Pet Images For Alzheimer Disease Diagnosis. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Ilias, L.; Askounis, D. Multimodal Deep Learning Models for Detecting Dementia From Speech and Transcripts. Front. Aging Neurosci. 2022, 14, 830943. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subjects | M/F | Age Range | BAPL Score 1 | BAPL Score 2 | BAPL Score 3 | |
|---|---|---|---|---|---|---|
| AD | 224 | 102/122 | 47–90 | 39 | 25 | 156 |
| MCI | 113 | 44/69 | 44–86 | 61 | 17 | 35 |
| HC | 50 | 18/32 | 37–80 | 48 | 2 | 0 |
| a. BAPL Score Ratios of train, validation, and test Sets | ||||||
| Train/Validation Set Ratio | Test Set Ratio | |||||
| BAPL 1 | BAPL 2 | BAPL 3 | BAPL 1 | BAPL 2 | BAPL 3 | |
| AD | 8 | 4 | 28 | 2 | 1 | 7 |
| MCI | 24 | 8 | 8 | 6 | 2 | 2 |
| HC | 39 | 1 | 0 | 9 | 1 | 0 |
| b. The number of train, validation, and test sets in the original data | ||||||
| Train/Validation | Test | |||||
| BAPL 1 | BAPL 2 | BAPL 3 | BAPL 1 | BAPL 2 | BAPL 3 | |
| AD | 8 | 4 | 28 | 2 | 1 | 7 |
| MCI | 24 | 8 | 8 | 6 | 2 | 2 |
| HC | 39 | 1 | 0 | 9 | 1 | 0 |
| Sum | (Train) 90 | (Validation) 30 | 30 | |||
| c. The number of train, validation, and test sets in the augmented data | ||||||
| Train/Validation | Test | |||||
| BAPL 1 | BAPL 2 | BAPL 3 | BAPL 1 | BAPL 2 | BAPL 3 | |
| AD | 56 | 28 | 196 | 2 | 1 | 7 |
| MCI | 168 | 56 | 56 | 6 | 2 | 2 |
| HC | 273 | 7 | 0 | 9 | 1 | 0 |
| Sum | (Train) 630 | (Validation) 210 | 30 | |||
| Hyper-Parameter | Value |
|---|---|
| Batch size | 16 |
| Epochs | 100 |
| Input size | 224 |
| Dropout | 0.1 |
| Learning rate | 0.001 |
| Model | Data Set | ACC | Recall | Precision | F1 Score |
|---|---|---|---|---|---|
| ViT | original data | 0.8000 | 0.6000 | 0.7500 | 0.6667 |
| ViT | augmented data | 0.7000 | 0.1000 | 1.0000 | 0.1818 |
| VGG19 | original data | 0.7333 | 0.6000 | 0.6000 | 0.6000 |
| VGG19 | augmented data | 0.6667 | 0.1000 | 0.5000 | 0.1667 |
| Predictive Class | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| ViT Model | VGG19 Model | ||||||||
| Original Data | Augmented Data | Original Data | Augmented Data | ||||||
| 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | ||
| Actual Class | 0 | 6 | 4 | 1 | 9 | 6 | 4 | 1 | 9 |
| 1 | 2 | 18 | 0 | 20 | 4 | 16 | 1 | 19 | |
| Model | Data Set | ACC | Recall | Precision | F1 Score |
|---|---|---|---|---|---|
| ViT | original data | 0.5667 | 0.5667 | 0.5278 | 0.5455 |
| ViT | augmented data | 0.5333 | 0.5333 | 0.5056 | 0.5174 |
| VGG19 | original data | 0.6667 | 0.6667 | 0.6794 | 0.6660 |
| VGG19 | augmented data | 0.4667 | 0.4667 | 0.3286 | 0.3673 |
| Predictive Class | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ViT Model | VGG19 Model | ||||||||||||
| Original Data | Augmented Data | Original Data | Augmented Data | ||||||||||
| 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 | 2 | ||
| Actual Class | 0 | 3 | 7 | 0 | 6 | 2 | 2 | 8 | 3 | 0 | 2 | 5 | 3 |
| 1 | 1 | 5 | 4 | 1 | 4 | 5 | 1 | 4 | 2 | 1 | 2 | 7 | |
| 2 | 0 | 3 | 7 | 0 | 2 | 8 | 1 | 3 | 8 | 0 | 0 | 10 | |
| Data Set | 2 Class | 3 Class | ||
|---|---|---|---|---|
| ViT | VGG19 | ViT | VGG19 | |
| original data | 0.6893 | 0.8119 | 0.6429 | 0.6429 |
| augmented data | 0.7689 | 0.9671 | 0.7778 | 0.8260 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, H.; Jeon, S.; Seol, Y.; Kim, S.; Kang, D. Vision Transformer Approach for Classification of Alzheimer’s Disease Using 18F-Florbetaben Brain Images. Appl. Sci. 2023, 13, 3453. https://doi.org/10.3390/app13063453
Shin H, Jeon S, Seol Y, Kim S, Kang D. Vision Transformer Approach for Classification of Alzheimer’s Disease Using 18F-Florbetaben Brain Images. Applied Sciences. 2023; 13(6):3453. https://doi.org/10.3390/app13063453
Chicago/Turabian StyleShin, Hyunji, Soomin Jeon, Youngsoo Seol, Sangjin Kim, and Doyoung Kang. 2023. "Vision Transformer Approach for Classification of Alzheimer’s Disease Using 18F-Florbetaben Brain Images" Applied Sciences 13, no. 6: 3453. https://doi.org/10.3390/app13063453
APA StyleShin, H., Jeon, S., Seol, Y., Kim, S., & Kang, D. (2023). Vision Transformer Approach for Classification of Alzheimer’s Disease Using 18F-Florbetaben Brain Images. Applied Sciences, 13(6), 3453. https://doi.org/10.3390/app13063453