

Influence of Training Parameters on Real-Time Similar Object Detection Using YOLOv5s


Abstract
:1. Introduction
2. Related Works
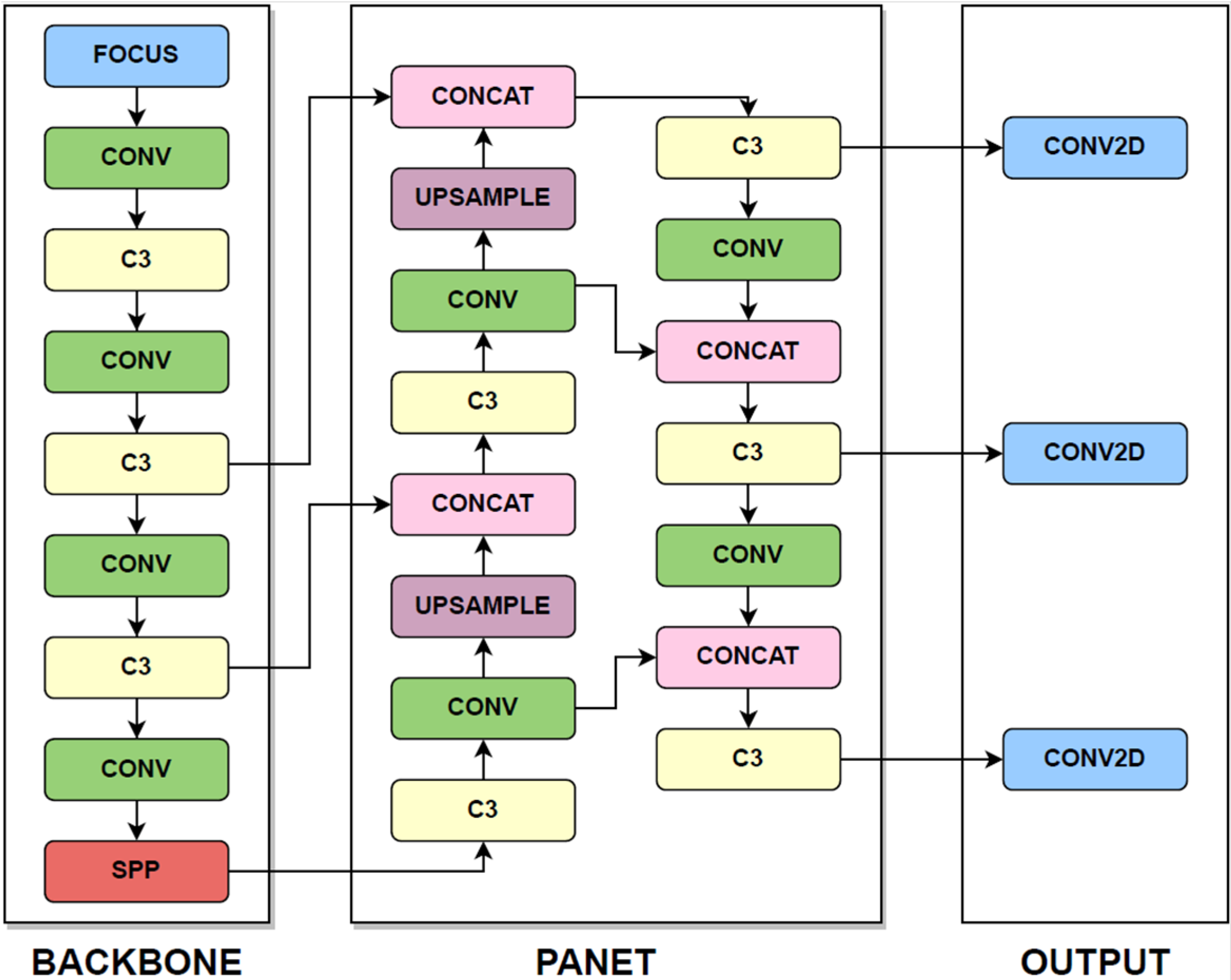
3. Review of YOLO Group Algorithms
4. Experimental Investigation
4.1. Dataset
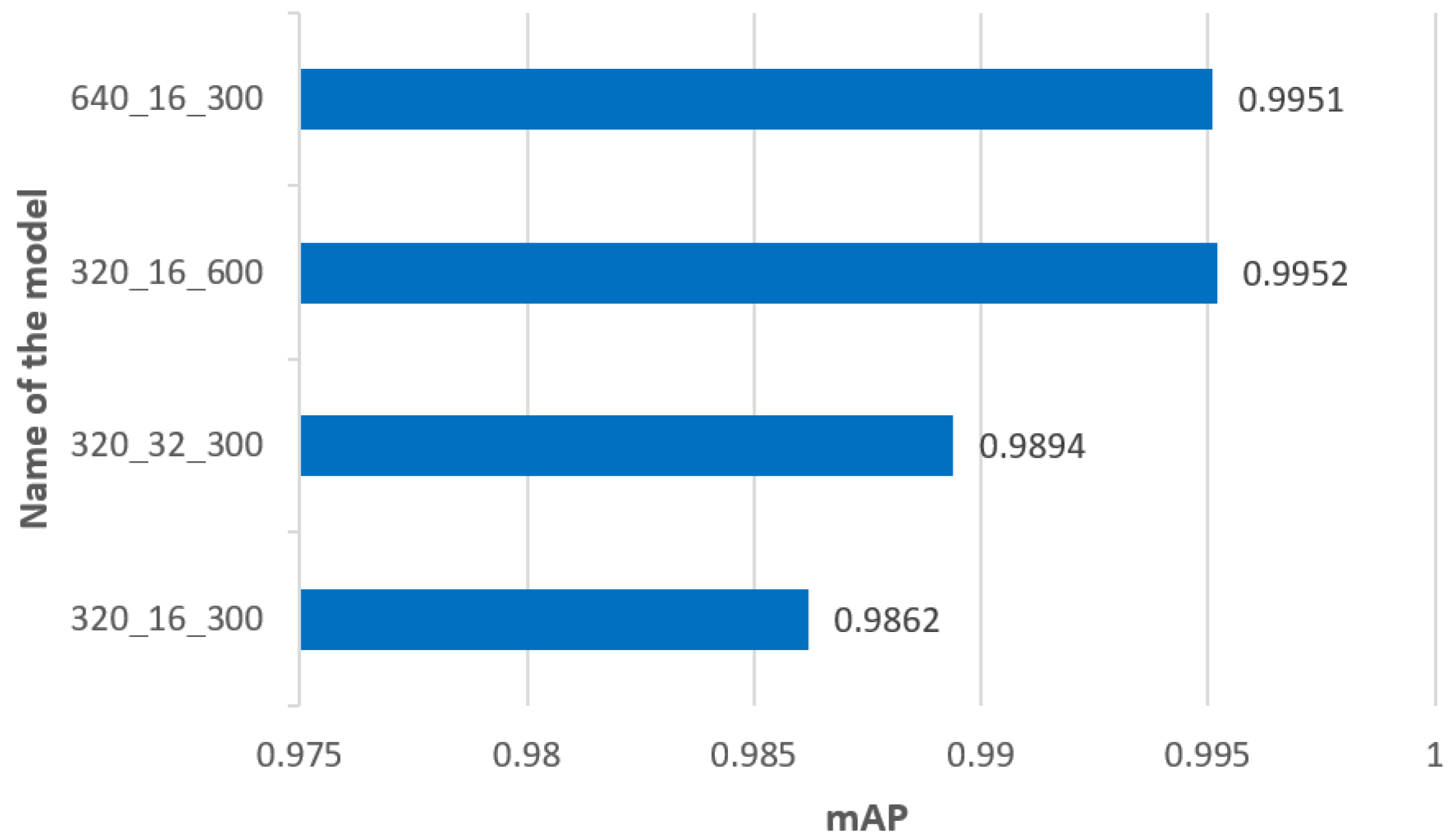
4.2. The Results of Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arunkumar, N.; Mohammed, M.A.; Abd Ghani, M.K.; Ibrahim, D.A.; Abdulhay, E.; Ramirez-Gonzalez, G.; de Albuquerque, V.H.C. K-means clustering and neural network for object detecting and identifying abnormality of brain tumor. Soft Comput. 2019, 23, 9083–9096. [Google Scholar] [CrossRef]
- Welikala, R.A.; Remagnino, P.; Lim, J.H.; Chan, C.S.; Rajendran, S.; Kallarakkal, T.G.; Barman, S.A. Automated detection and classification of oral lesions using deep learning for early detection of oral cancer. IEEE Access 2020, 8, 132677–132693. [Google Scholar] [CrossRef]
- Bozaba, E.; Solmaz, G.; Yazıcı, Ç.; Özsoy, G.; Tokat, F.; Iheme, L.O.; Çayır, S.; Ayaltı, S.; Kayhan, C.K.; İnce, Ü. Nuclei Detection on Breast Cancer Histopathology Images Using RetinaNet. In Proceedings of the 2021 29th Signal Processing and Communications Applications Conference (SIU), Istanbul, Turkey, 9–11 June 2021; pp. 1–4. [Google Scholar]
- Ajakwe, S.O.; Ihekoronye, V.U.; Akter, R.; Kim, D.S.; Lee, J.M. Adaptive drone identification and neutralization scheme for real-time military tactical operations. In Proceedings of the 2022 International Conference on Information Networking (ICOIN), Jeju-si, Republic of Korea, 12–15 January 2022; pp. 380–384. [Google Scholar]
- Hnewa, M.; Radha, H. Object detection under rainy conditions for autonomous vehicles: A review of state-of-the-art and emerging techniques. IEEE Signal Process. Mag. 2020, 38, 53–67. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef] [Green Version]
- Roy, A.M.; Bose, R.; Bhaduri, J. A fast accurate fine-grain object detection model based on YOLOv4 deep neural network. Neural Comput. Appl. 2022, 34, 3895–3921. [Google Scholar] [CrossRef]
- Tseng, G.; Sinkovics, K.; Watsham, T.; Rolnick, D.; Walters, T.C. Semi-Supervised Object Detection for Agriculture. In Proceedings of the 2nd AAAI Workshop on AI for Agriculture and Food Systems, Washington, DC, USA, 13–14 February 2023. [Google Scholar]
- Valdez, P. Apple defect detection using deep learning based object detection for better post harvest handling. arXiv 2020, arXiv:2005.06089. [Google Scholar]
- Xiao, Y.; Tian, Z.; Yu, J.; Zhang, Y.; Liu, S.; Du, S.; Lan, X. A review of object detection based on deep learning. Multimed. Tools Appl. 2020, 79, 23729–23791. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kim, H.; Kim, D.; Ryu, G.; Hong, H. A Study on Algorithm Selection and Comparison for Improving the Performance of an Artificial Intelligence Product Recognition Automatic Payment System. Int. J. Adv. Cult. Technol. 2022, 10, 230–235. [Google Scholar]
- Yahalomi, E.; Chernofsky, M.; Werman, M. Detection of distal radius fractures trained by a small set of X-ray images and Faster R-CNN. In Intelligent Computing: Proceedings of the 2019 Computing Conference; Springer International Publishing: Cham, Switzerland, 2019; Volume 1, pp. 971–981. [Google Scholar]
- Zhu, G.; Piao, Z.; Kim, S.C. Tooth detection and segmentation with mask R-CNN. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 070–072. [Google Scholar]
- Uzkent, B.; Yeh, C.; Ermon, S. Efficient object detection in large images using deep reinforcement learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 1824–1833. [Google Scholar]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Isa, I.S.; Rosli, M.S.A.; Yusof, U.K.; Maruzuki, M.I.F.; Sulaiman, S.N. Optimizing the Hyperparameter Tuning of YOLOv5 for Underwater Detection. IEEE Access 2022, 10, 52818–52831. [Google Scholar] [CrossRef]
- Mantau, A.J.; Widayat, I.W.; Adhitya, Y.; Prakosa, S.W.; Leu, J.S.; Köppen, M. A GA-Based Learning Strategy Applied to YOLOv5 for Human Object Detection in UAV Surveillance System. In Proceedings of the 2022 IEEE 17th International Conference on Control & Automation (ICCA), Naples, Italy, 27–30 June 2022; pp. 9–14. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar] [CrossRef]
- Tan, L.; Huangfu, T.; Wu, L.; Chen, W. Comparison of RetinaNet, SSD, and YOLO v3 for real-time pill identification. BMC Med. Inform. Decis. Mak. 2021, 21, 324. [Google Scholar] [CrossRef] [PubMed]
- Alkentar, S.M.; Alsahwa, B.; Assalem, A.; Karakolla, D. Practical comparation of the accuracy and speed of YOLO, SSD and Faster RCNN for drone detection. J. Eng. 2021, 27, 19–31. [Google Scholar] [CrossRef]
- Naftali, M.G.; Sulistyawan, J.S.; Julian, K. Comparison of Object Detection Algorithms for Street-level Objects. arXiv 2022, arXiv:2208.11315. [Google Scholar]
- Dlužnevskij, D.; Stefanovic, P.; Ramanauskaite, S. Investigation of YOLOv5 efficiency in iPhone supported systems. Balt. J. Mod. Comput. 2021, 9, 333–344. [Google Scholar] [CrossRef]
- Pramanik, A.; Pal, S.K.; Maiti, J.; Mitra, P. Granulated RCNN and multi-class deep sort for multi-object detection and tracking. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 6, 171–181. [Google Scholar] [CrossRef]
- Han, G.; Huang, S.; Ma, J.; He, Y.; Chang, S.F. Meta faster r-cnn: Towards accurate few-shot object detection with attentive feature alignment. Proc. AAAI Conf. Artif. Intell. 2022, 36, 780–789. [Google Scholar] [CrossRef]
- Zhen, P.; Gao, Z.; Hou, T.; Cheng, Y.; Chen, H.B. Deeply tensor compressed transformers for end-to-end object detection. Proc. AAAI Conf. Artif. Intell. 2022, 36, 4716–4724. [Google Scholar] [CrossRef]
- Han, Y.; Wang, L.; Cheng, S.; Li, Y.; Du, A. Residual dense collaborative network for salient object detection. IET Image Process. 2023, 17, 492–504. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for autonomous landing spot detection in faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Resolution | Batch Size | Number of Iterations | Correctly Detected | Recognition Ratio |
|---|---|---|---|---|
| 320 | 16 | 100 | 22 | 0.1946 |
| 32 | 2 | 0.0177 | ||
| 64 | 0 | 0 | ||
| 128 | 0 | 0 | ||
| 16 | 300 | 69 | 0.6106 | |
| 32 | 75 | 0.6637 | ||
| 64 | 54 | 0.4778 | ||
| 16 | 600 | 69 | 0.6106 | |
| 32 | 64 | 0.5663 | ||
| 64 | 62 | 0.5486 | ||
| 640 | 16 | 300 | 69 | 0.6106 |
| 32 | 62 | 0.5486 | ||
| 64 | 62 | 0.5486 | ||
| 16 | 600 | 63 | 0.5575 | |
| 32 | 41 | 0.3628 | ||
| 64 | 60 | 0.5309 | ||
| 1280 | 16 | 300 | 59 | 0.5221 |
| 600 | 54 | 0.4778 |
| Image Resolution | Batch Size | Number of Iterations | Correctly Detected | Recognition Ratio |
|---|---|---|---|---|
| 320 | 16 | 100 | 6 | 0.0531 |
| 32 | 0 | 0 | ||
| 64 | 0 | 0 | ||
| 128 | 0 | 0 | ||
| 16 | 300 | 55 | 0.4867 | |
| 32 | 38 | 0.3362 | ||
| 64 | 40 | 0.3539 | ||
| 16 | 600 | 47 | 0.4159 | |
| 32 | 49 | 0.4336 | ||
| 64 | 50 | 0.4424 | ||
| 640 | 16 | 300 | 48 | 0.4247 |
| 32 | 51 | 0.4513 | ||
| 64 | 65 | 0.5752 | ||
| 16 | 600 | 52 | 0.4601 | |
| 32 | 45 | 0.3982 | ||
| 64 | 41 | 0.3628 | ||
| 1280 | 16 | 300 | 41 | 0.3628 |
| 600 | 46 | 0.4070 |
| Image Resolution | Batch Size | Number of Iterations | Correctly Detected | Recognition Ratio |
|---|---|---|---|---|
| 320 | 16 | 300 | 162 | 0.5242 |
| 320 | 32 | 300 | 137 | 0.4433 |
| 320 | 16 | 600 | 142 | 0.4595 |
| 640 | 16 | 300 | 155 | 0.5016 |
| Label of The Construction Detail | Recognition Ratio of Each Class | |||
|---|---|---|---|---|
| 320_16_300 | 320_32_300 | 320_16_600 | 640_16_300 | |
| 6 × 6 | 1 | 0.5 | 1 | 1 |
| 2 × 6 | 0.75 | 0.88 | 0.75 | 1 |
| 2 × 3 | 0.33 | 0.33 | 0.5 | 0.5 |
| 1 × 4 | 0.69 | 0.62 | 0.69 | 0.54 |
| 2 × 2 | 0.8 | 0.2 | 0.4 | 0.6 |
| 8 × 16 | 1 | 1 | 1 | 1 |
| 4 × 6 | 1 | 1 | 1 | 0 |
| 1 × 2 | 0.39 | 0.28 | 0.39 | 0.33 |
| 1 × 2_3D | 0.58 | 0.58 | 0.5 | 0.42 |
| 2 × 3_3D | 0.7 | 0.6 | 0.7 | 0.6 |
| 2 × 6_3D | 0.3 | 0.5 | 0.6 | 0.6 |
| 2 × 2_3D | 0.57 | 0.57 | 0.43 | 0.29 |
| 1 × 4_3D | 0.46 | 0.54 | 0.38 | 0.54 |
| 1 × 4_trapeze | 0.82 | 0.73 | 0.82 | 0.73 |
| grid | 0.92 | 0.68 | 0.56 | 0.92 |
| 1 × 1_square | 0.5 | 0.5 | 0.33 | 0.83 |
| 2 × 4 | 0.44 | 0.31 | 0.38 | 0.56 |
| 2 × 16 | 1 | 0 | 0.5 | 0 |
| 1 × 1_3D_square | 0.5 | 0.25 | 0.25 | 0.5 |
| 1 × 12 | 0 | 1 | 1 | 0 |
| 2 × 10 | 0.5 | 0 | 0.5 | 0 |
| 4 × 12 | 0 | 0 | 0 | 0 |
| 3 × 3 | 0.6 | 0.4 | 0.2 | 0 |
| 4 × 4 | 0.5 | 0.5 | 0.5 | 0.5 |
| 2 × 4_3D | 0.38 | 0.38 | 0.38 | 0.5 |
| 1 × 3 | 0.31 | 0.08 | 0.31 | 0.46 |
| 1 × 1_round_flat | 0.6 | 0.6 | 0.6 | 0.6 |
| 1 × 1_cilindre | 0.33 | 0.3 | 0.37 | 0.37 |
| 1 × 6_3D | 0 | 0 | 0 | 0 |
| 1 × 6 | 0.5 | 0 | 1 | 0 |
| 1 × 1_trapeze | 0.44 | 0.33 | 0.22 | 0.22 |
| 1 × 1_round | 1 | 1 | 1 | 1 |
| 1 × 3_3D | 0.22 | 0.22 | 0.11 | 0.11 |
| 1 × 2_rectangle_flat | 0.5 | 0.39 | 0.39 | 0.44 |
| 1 × 2_trapeze | 0.27 | 0.18 | 0.18 | 0.18 |
| 1 × 2_rectangle_knob | 0.58 | 0.5 | 0.33 | 0.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kvietkauskas, T.; Stefanovič, P. Influence of Training Parameters on Real-Time Similar Object Detection Using YOLOv5s. Appl. Sci. 2023, 13, 3761. https://doi.org/10.3390/app13063761
Kvietkauskas T, Stefanovič P. Influence of Training Parameters on Real-Time Similar Object Detection Using YOLOv5s. Applied Sciences. 2023; 13(6):3761. https://doi.org/10.3390/app13063761
Chicago/Turabian StyleKvietkauskas, Tautvydas, and Pavel Stefanovič. 2023. "Influence of Training Parameters on Real-Time Similar Object Detection Using YOLOv5s" Applied Sciences 13, no. 6: 3761. https://doi.org/10.3390/app13063761
APA StyleKvietkauskas, T., & Stefanovič, P. (2023). Influence of Training Parameters on Real-Time Similar Object Detection Using YOLOv5s. Applied Sciences, 13(6), 3761. https://doi.org/10.3390/app13063761