
Illegal Domain Name Generation Algorithm Based on Character Similarity of Domain Name Structure

Abstract
:1. Introduction
2. Related Research
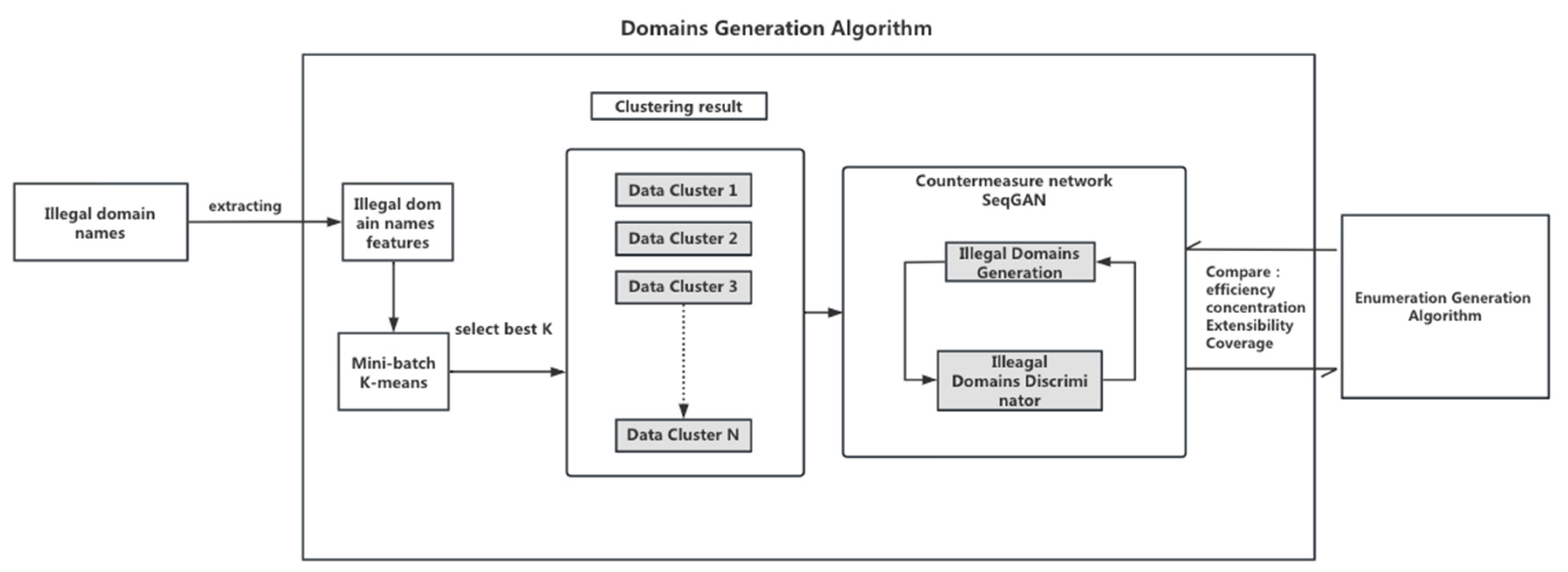
3. Algorithm Design and Process
3.1. Domain Name Coding and Decoding Method
- (1)
- Coding method
- (2)
- Decoding method
3.2. Illegal Domain Name Clustering
- Second-level Domain Name Characterization
- Top-level Domain Name Characterization
- (1)
- Randomly extract a fixed-size collection of illegal domain names from the data set to form a small batch and cluster the small batches through the K-means algorithm to construct initial K clusters;
- (2)
- Continue randomly extracting a fixed-size set of illegal domain names from the data set to form a small batch;
- (3)
- For each illegal domain named in the small batch, calculate the Euclidean distance between and each cluster center, assign to the nearest cluster , and calculate the mean value of d and other illegal domain names in C to update the cluster C class center;
- (4)
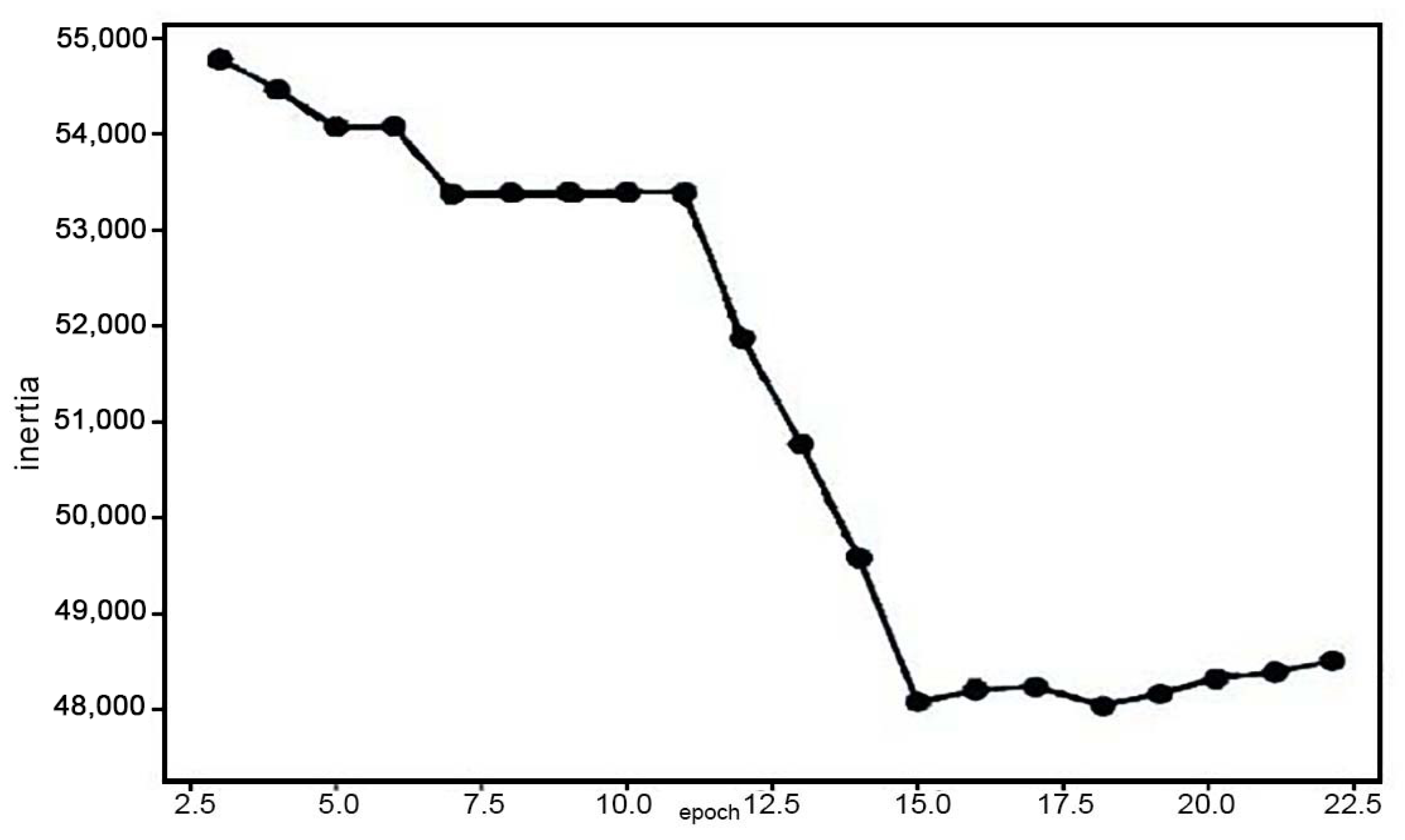
- Use the elbow method to select the optimal number of clusters K for this algorithm;
- (5)
- Steps (2) and (4) are iterated in a loop until the center point is stable or the number of iterations is reached, and the calculation operation is stopped.
3.3. Illegal Domain Name Generating
- : Generator;
- : Discriminator;
- : Vocabulary;
- : Word generated in the step;
- : Sequence formed by the words generated in the previous step.
- : Probability value of generating the word as when the previous words have been generated.
- : Existing sequence .
- N: Number of completed complete sequences.
- : Discriminator.
- : Generator.
- T: Length of the complete sequence.
- : Complete sequence at the completion.
- : Possible complete sequences obtained by Monte Carlo search.
- : Sequence of words generated in the previous steps.
3.3.1. Generator Design
- (1)
- First, a batch of initial character numbers is selected from the set of numbers corresponding to letters and numbers by pseudo-random seeds, and the batch size is , which is input to the embedding layer;
- (2)
- The GRU layer obtains a tensor according to the input embedding feature, which contains information to predict the next batch of character numbers, and outputs it to the fully connected layer;
- (3)
- The fully connected layer and LogSoftMax convert the above tensor into output, take the index and convert it into the probability distribution of the next batch of character numbers, where is the size of the domain name character table;
- (4)
- Each line of the above output is the probability distribution of the next character number, and the character number with the highest probability in each line is selected as the next character number to obtain the next batch of character numbers. This batch of character numbers is used as the new input of the generator;
- (5)
- Repeat steps (2)~(5) until the current character number is the last character number of the specified domain name length, arrange the character numbers generated in each step in the order of generation to form a domain name vector, and obtain a batch of generated domain name vectors.
3.3.2. Discriminator Design
- (1)
- First input a batch of domain name vectors to the embedding layer, and obtain a embedding tensor, where is the batch size, and is the maximum length of the domain name;
- (2)
- The above-embedded tensor extracts the 2-g and 3-g features of the domain name through the convolution and pooling combination layer and outputs feature tensor, where is the number of extracted features;
- (3)
- Then slow down the gradient problem of the deep neural network through the highway network, and output a batch of domain name feature vectors;
- (4)
- Finally, the domain name feature vector fully connected layer is used to obtain the probability output of this batch of domain name vectors. When the probability value exceeds 0.5, it is a real domain name vector. Otherwise, it is determined as a generated domain name vector to realize the identification of the authenticity of this batch of domain name vectors.
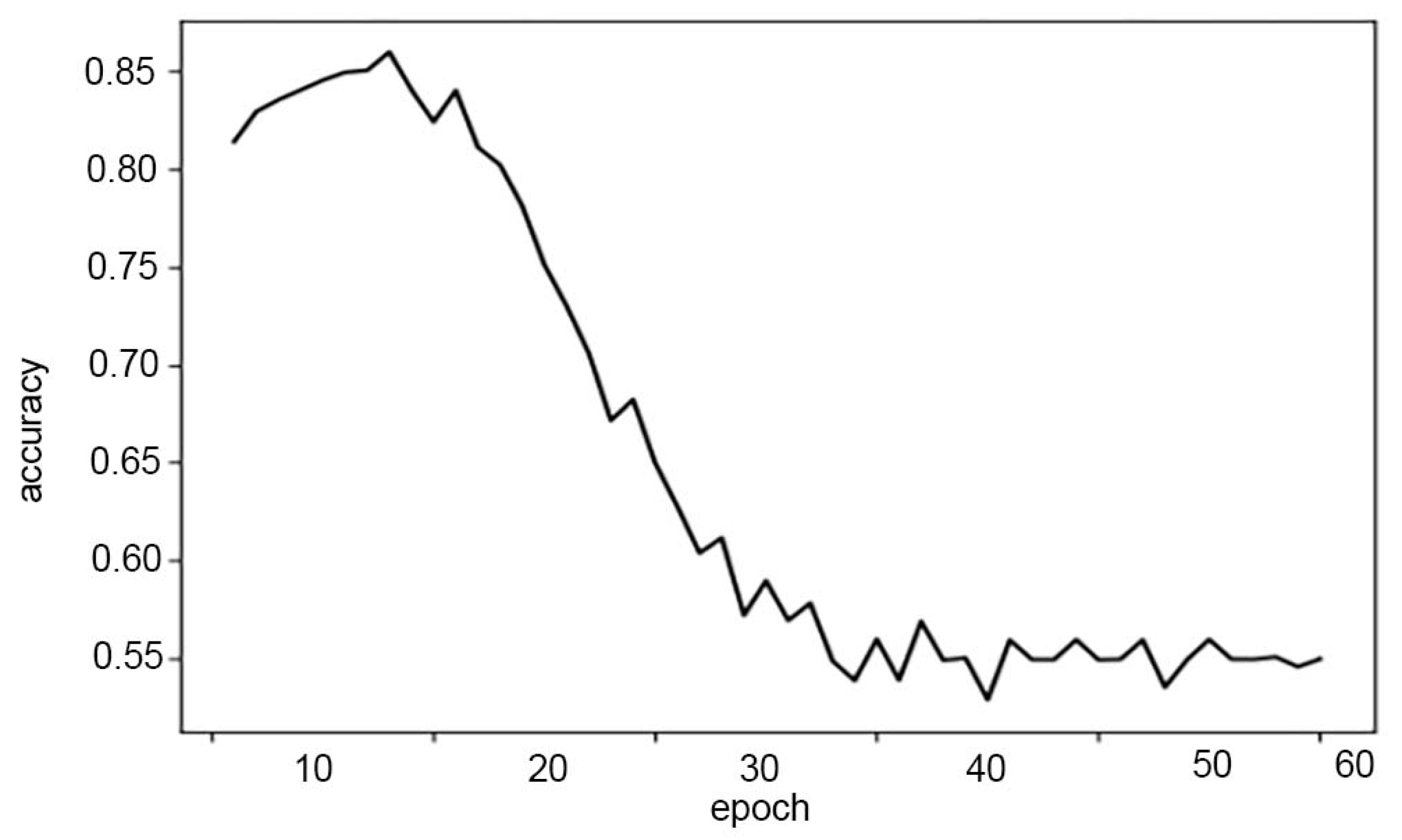
3.3.3. SeqGAN Training
- (1)
- Initialize the generator and discriminator parameters;
- (2)
- Minimize the maximum likelihood loss pre-training generator by Adam optimizer. Use the generator to generate some fake domain name vectors mixed with real domain name vectors and input them into the discriminator, and minimize the cross entropy through the AdaGrad optimizer to pre-train the discriminator;
- (3)
- Use the generator to generate some fake domain name vectors and mix them with the actual domain name vectors and input them into the discriminator to obtain reward signals for these domain name vectors;
- (4)
- Use Monte Carlo search to pass the reward signal output by the discriminator back to the intermediate state step to calculate the loss of these domain name vectors generated by the generator and update the network parameters of the generator through the Adam optimizer;
- (5)
- Use the generator to generate fake domain name vectors, mix them with real domain name vectors, and input them into the discriminator. Using cross entropy as the loss function, calculate the loss of the discriminator to identify these domain name vectors, and update the network parameters of the discriminator through the AdaGrad optimizer;
- (6)
- Repeat steps (3)~(5) until the maximum number of iterations is reached or the sequence confrontation network tends to be stable.
3.4. Illegal Domain Name Enumeration
- (1)
- If and , then and are similar.
- (2)
- If , length [] = length [] and , each character of is the same, and does not exceed 3, then and are similar.
- (3)
- If =, length [] = length [], and the number of characters in the corresponding positions is not more than 2, then and are similar.
- (4)
- If =, the lengths of the second-level domains differ by one, and they are the same after one editing operation, then and are similar.
3.5. Results Comparison Method
- TP represents the number of positive samples predicted as positive samples.
- FN represents the number of positive samples predicted as negative samples.
- FP represents the number of negative samples predicted as positive samples.
- TN represents the number of negative samples predicted as negative samples.
4. Experimental Result
4.1. Illegal Domain Name Clustering Result
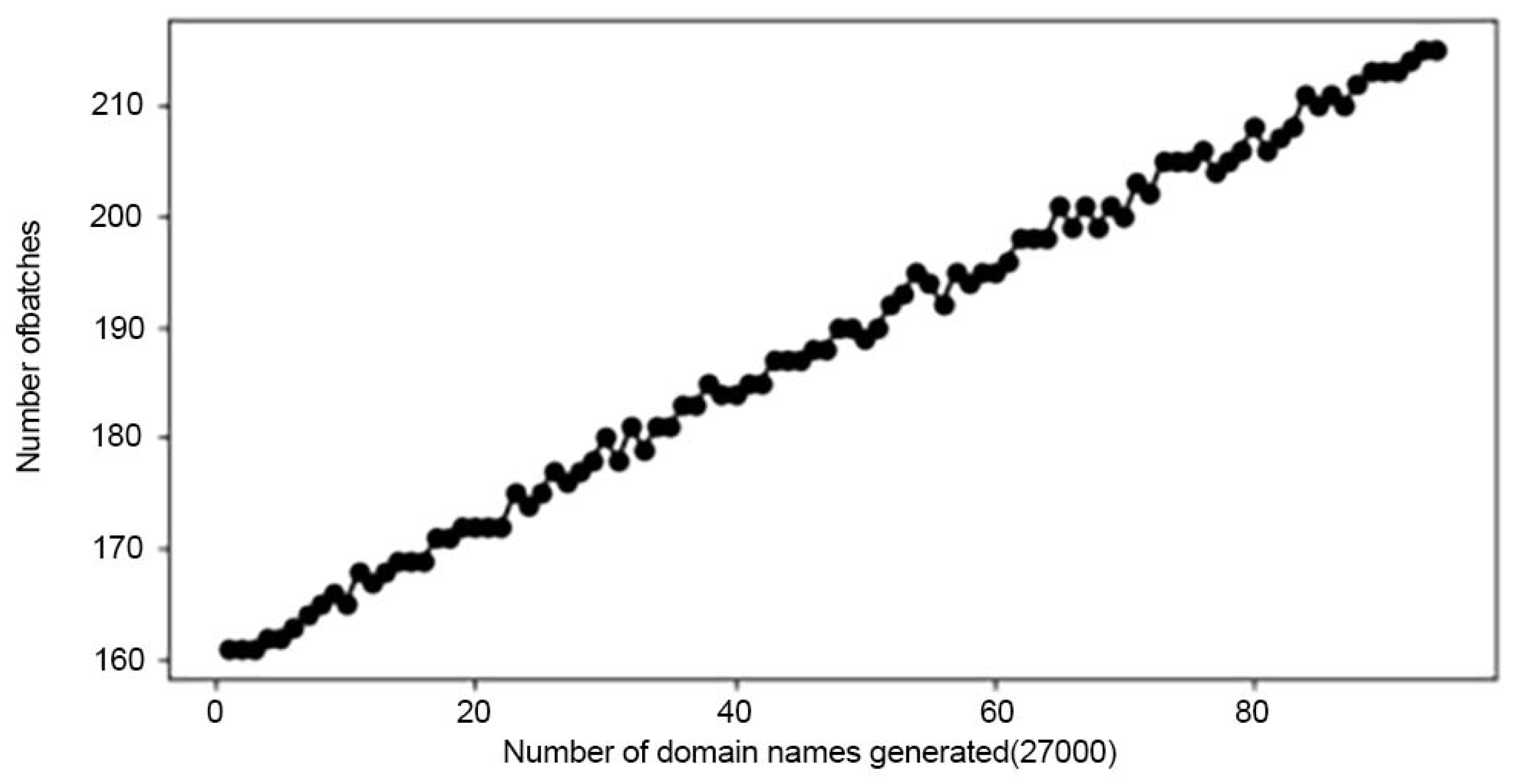
4.2. Illegal Domain Name Generating Result
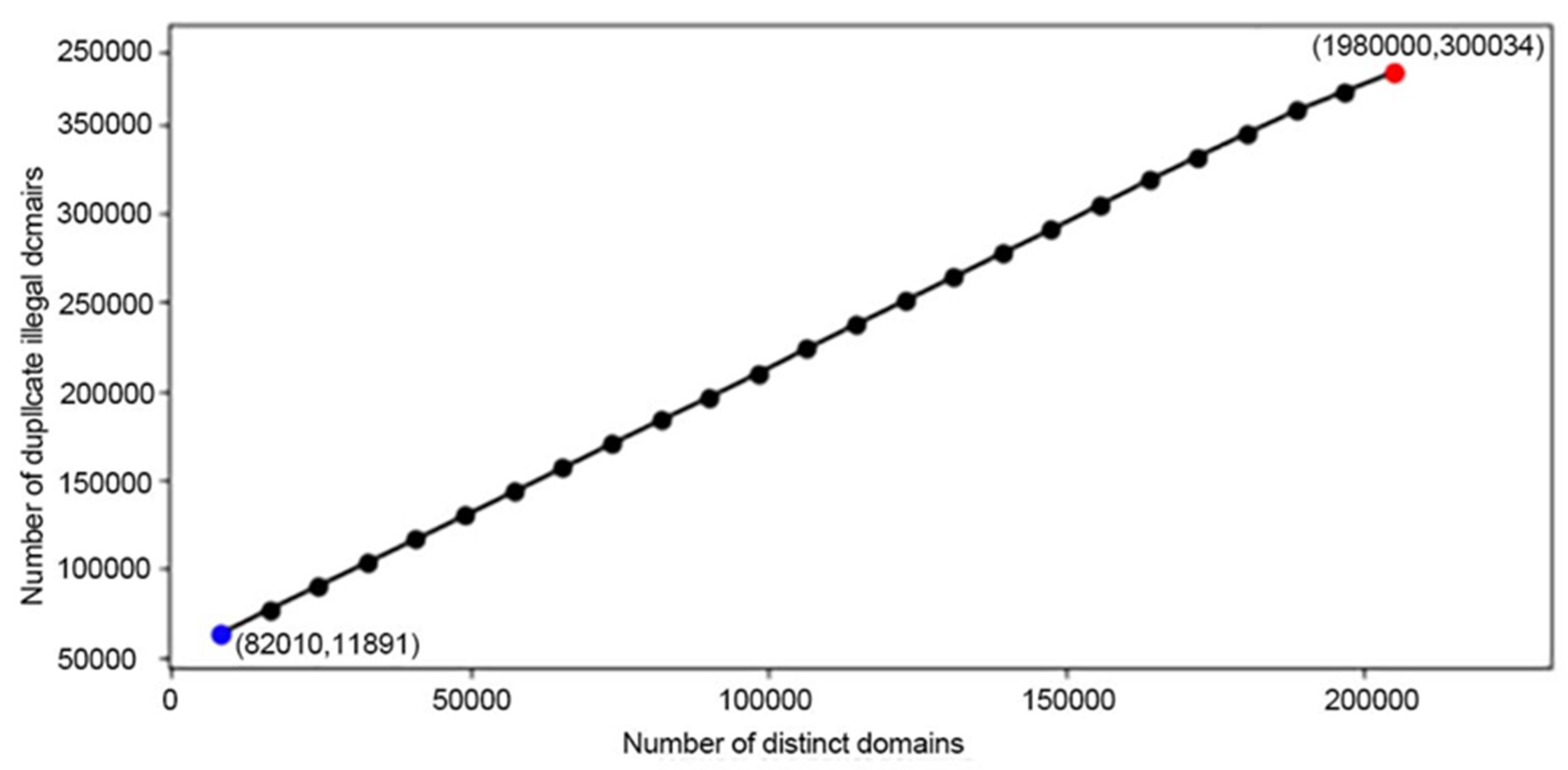
4.3. Generate Algorithm Results Comparison
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- ITU. Measuring Digital Development: Facts and Figures 2021. Available online: https://www.itu.int/itu-d/reports/statistics/facts-figures-2021/ (accessed on 1 December 2021).
- Invernizzi, L.; Comparetti, P.M.; Benvenuti, S.; Kruegel, C.; Cova, M.; Vigna, G. Evilseed: A guided approach to finding malicious web pages. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 428–442. [Google Scholar]
- Wang, Q.; He, L.; Han, W. Realization of Harmful Website Discovery and Discrimination System Based on Crawlers. Inf. Netw. Secur. 2012, 12, 140–142. [Google Scholar]
- Sato, K.; Ishibashi, K.; Toyono, T.; Miyake, N. Extending black domain name list by using co-occurrence relation between dns queries. IEICE Trans. Commun. 2012, 95, 794–802. [Google Scholar] [CrossRef] [Green Version]
- Guerid, H.; Mittig, K.; Serhrouchni, A. Privacy-Preserving Domain-Flux Botnet Detection in a Largescale Network. In Proceedings of the 2013 Fifth International Conference on Communication Systems and Networks, Bangalore, India, 7–10 January 2013; pp. 1–9. [Google Scholar]
- Khalil, I.; Yu, T.; Guan, B. Discovering Malicious Domains through Passive DNS Data Graph Analysis. In Proceedings of the 11th ACM on Asia Conference on Computer and Communications Security, Xi’an, China, 30 May–3 June 2016; pp. 663–674. [Google Scholar]
- Yuan, C.; Qian, L.; Zhang, H.; Zhang, T. Generation of malicious domain name training data based on generation of anti-network. Comput. Appl. Res. 2019, 36, 1540–1543, 1568. [Google Scholar]
- Cheng, Y.; Jiang, H.; Zhang, Z.; Du, Y.; Cai, T. Birds of a Feather Flock Together: Generating Pornographic and Gambling Domain Names Based on Character Composition Similarity. Wirel. Commun. Mob. Comput. 2022, 2022. [Google Scholar] [CrossRef]
- Cheng, Y.; Chai, T.; Zhang, Z.; Lu, K.; Du, Y. Detecting Malicious Domain Names with Abnormal WHOIS Records Using Feature-Based Rules. Comput. J. 2022, 65, 2262–2275. [Google Scholar] [CrossRef]
- Marchal, S.; François, J.; Engel, T. Proactive Discovery of Phishing Related Domain Names. In Proceedings of the 15th International Symposium on Research in Attacks, Intrusions, and Defenses, Amsterdam, The Netherlands, 12–14 September 2012; pp. 190–209. [Google Scholar]
- Bi, X. Research on APT Discovery Technology Based on Malicious Domain Name Detection. 2022. Available online: https://kns.cnki.net/kcms2/article/abstract?v=3uoqIhG8C475KOm_zrgu4lQARvep2SAke-wuWrktdE-tSIT2YIbQ2H_SqDW--2FOj4oZMiXvJfZXHUWHC6djVGBJTZTUJdNh&uniplatform=NZKPT (accessed on 1 December 2021).
- Zhang, W.; Gong, J.; Liu, Q.; Liu, S.-D.; Hu, X.-Y. Lightweight domain name detection algorithm based on morpheme features. J. Softw. 2016, 27, 2348–2364. [Google Scholar]
- Peng, K.; Leung, V.C.M.; Huang, Q. Clustering approach based on mini batch Kmeans for intrusion detection system over big data. IEEE Access 2018, 6, 11897–11906. [Google Scholar] [CrossRef]
- Béjar Alonso, J. K-Means vs Mini Batch K-Means: A Comparison. 2013. Available online: https://upcommons.upc.edu/handle/2117/23414 (accessed on 1 December 2021).
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 2852–2858. [Google Scholar]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A.M. Character-Aware Neural Language Models. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2741–2749. [Google Scholar]
- Bojanowski, P.; Joulin, A.; Mikolov, T. Alternative Structures for Character-Level RNNs. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015; pp. 1–9. [Google Scholar]
- Wang, K.-F.; Gou, C.; Duan, Y.-J.; Lin, Y.-L.; Zheng, X.-H.; Wang, F.-Y. Generative Adversarial Networks: The State of the Art and Beyond. Acta Autom. Sin. 2017, 43, 321–332. [Google Scholar]
- Liang, J.; Wei, J.; Jiang, Z. Generative Adversarial Networks GAN Overview. J. Front. Comput. Sci. Technol. 2020, 14, 1–17. [Google Scholar]
- Yu, Y.; Chen, D. Botnet Detection Based on Convolutional Neural Network. Comput. Appl. Softw. 2022, 39, 336–341, 349. [Google Scholar]
- Zhang, Z.; Cheng, Y.; Wu, X. Illegal Domain Name Mining Method Based on Domain Name Structure Similarity: China. CN108712403A, 26 October 2018. [Google Scholar]
- Zhu, L.; Ma, B.; Zhao, X. Clustering validity analysis based on silhouette coefficient. J. Comput. Appl. 2010, 30, 139–141. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Improvement Direction | Existing Approaches | Proposed Approaches |
|---|---|---|---|
| 1 | Mining for different types of illegal domain names | The existing illegal domain name mining method is only for the specific illegal type of domain name mining. | The illegal domain names with similar names are gathered in the same cluster by clustering. Then different clusters are trained so that illegal domain names with different characteristics can be better mined. |
| 2 | The coverage of illegal domain names mined is not broad enough | The obtained illegal domain name is limited to a certain area of the domain name space. Therefore, global information about illegal domain names cannot be obtained. Therefore, the obtained illegal domain name cannot be reused and further mined. | The potential illegal domain names scattered in many corners of domain name space can be mined effectively by using the adversarial generation network method to obtain more comprehensive illegal domain names. |
| 3 | Algorithm efficiency | In the existing illegal domain name enumeration algorithm, although the number of generations is large, the effective concentration is low, and the generation time is too long. | The clustering algorithm is used to form different types of illegal domain name clusters so as to reduce the generation of invalid domain names in the generation process. At the same time, the adversarial generation network is used to reduce the gradient disappearance or gradient explosion caused by feature extraction and thus reduce the training time. |
| Performance | Illegal Domain Name Generation Algorithm | Illegal Domain Name Enumeration Algorithm | Comparison Results |
|---|---|---|---|
| Efficiency (hour) | 10 | 96 | −86 |
| Concentration (%) | 15.15 | 10 | +4.16 |
| Extensibility (individual) | >7.5 | 7.5 | Larger |
| Coverage (ten thousand) | >30 | 30 | More extensive |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, Y.; Cheng, Y.; Zhang, Z.; Chai, T.; Li, C. Illegal Domain Name Generation Algorithm Based on Character Similarity of Domain Name Structure. Appl. Sci. 2023, 13, 4061. https://doi.org/10.3390/app13064061
Liang Y, Cheng Y, Zhang Z, Chai T, Li C. Illegal Domain Name Generation Algorithm Based on Character Similarity of Domain Name Structure. Applied Sciences. 2023; 13(6):4061. https://doi.org/10.3390/app13064061
Chicago/Turabian StyleLiang, Yuchen, Yanan Cheng, Zhaoxin Zhang, Tingting Chai, and Chao Li. 2023. "Illegal Domain Name Generation Algorithm Based on Character Similarity of Domain Name Structure" Applied Sciences 13, no. 6: 4061. https://doi.org/10.3390/app13064061
APA StyleLiang, Y., Cheng, Y., Zhang, Z., Chai, T., & Li, C. (2023). Illegal Domain Name Generation Algorithm Based on Character Similarity of Domain Name Structure. Applied Sciences, 13(6), 4061. https://doi.org/10.3390/app13064061