1. Introduction
In recent years, with the development of vehicle-to-everything (V2X) and sensor technologies, connected and automated vehicles (CAVs) received extensive attention regarding their ability to reduce the occurrence of traffic congestion and accidents [
1]. Using environmental sensing sensors, such as cameras, lidar, and radar, the CAVs are able to obtain the state of roads and vehicles around them. The continuous development of V2X (vehicle-to-everything) technology has accelerated the development of the automobile intelligent network. V2X, including vehicle-to-vehicle (V2V), vehicle-to-infrastructure (V2I), and vehicle-to-pedestrians (V2P), enables each CAV to share information about the vehicle position, speed, acceleration, orientation, destination, etc. with any traffic participating entity, which enhances the range of perception for these vehicles [
2]. Equipped with perception systems and vehicular communications, a CAV acquires a wider range of information, which is beneficial for cooperative driving to evade crashes and achieve better traffic performance [
3].
According to the intelligent degree of vehicles, vehicles are divided into six levels, from L0 to L5, by the Society of Automotive Engineers (SAE). By 2030, 82 million L4/L5 intelligent vehicles will be in operation in China, the United States, and Europe [
4]. Despite the dramatic advances in autonomous driving, the predictable transition from purely conventional vehicles to a purely intelligent and connected environment will require a sustained investment in infrastructure and technology development. In the coming years, the transportation environment will exist in a transition stage of mixed transportation where the human-driven vehicles (HDVs) and CAVs coexist.
In general, significant research regarding cooperative decision-making and control is under the assumption that all the vehicles on the road are CAVs [
5,
6]. Cooperative decision-making and control in mixed traffic is a challenge in the field of intelligent transportation systems (ITSs) [
7]. This is the reason why the CAVs need to interact with the HDVs, however the behavior of the HDVs is uncertain. To ensure a safe collaboration in mixed traffic environments, it is more practical to implement strategies for the CAVs that take the driver’s behavior into account than expecting drivers to interact with the CAVs with caution. To imitate the human driving behavior, Treiber et al. developed an intelligent driver model (IDM) [
8]. As a safe distance model, the IDM is able to describe the behavior of vehicles from free flow to congested flow with fewer parameters and reflects the dynamic changes of the vehicle position and speed in real time. Peng et al. [
9] modeled the HDVs using the IDM, which were guided by the CAVs to avoid collision and congestion and achieved a significant traffic efficiency. Li et al. [
10] extended the IDM using the Ornstein–Uhlenbeck process to describe the perceptual error dynamically. Wang et al. [
11] proposed a model that combined a first principles nominal model with a Gaussian process model to predict human behaviors and then implemented a mixed platoon. However, the HDVs normally follow traffic rules to drive, rather than following the CAVs. Based on this view, the CAVs will anticipate the trajectories of the HDVs and cooperate to upgrade their safety and crossing efficiency in this paper.
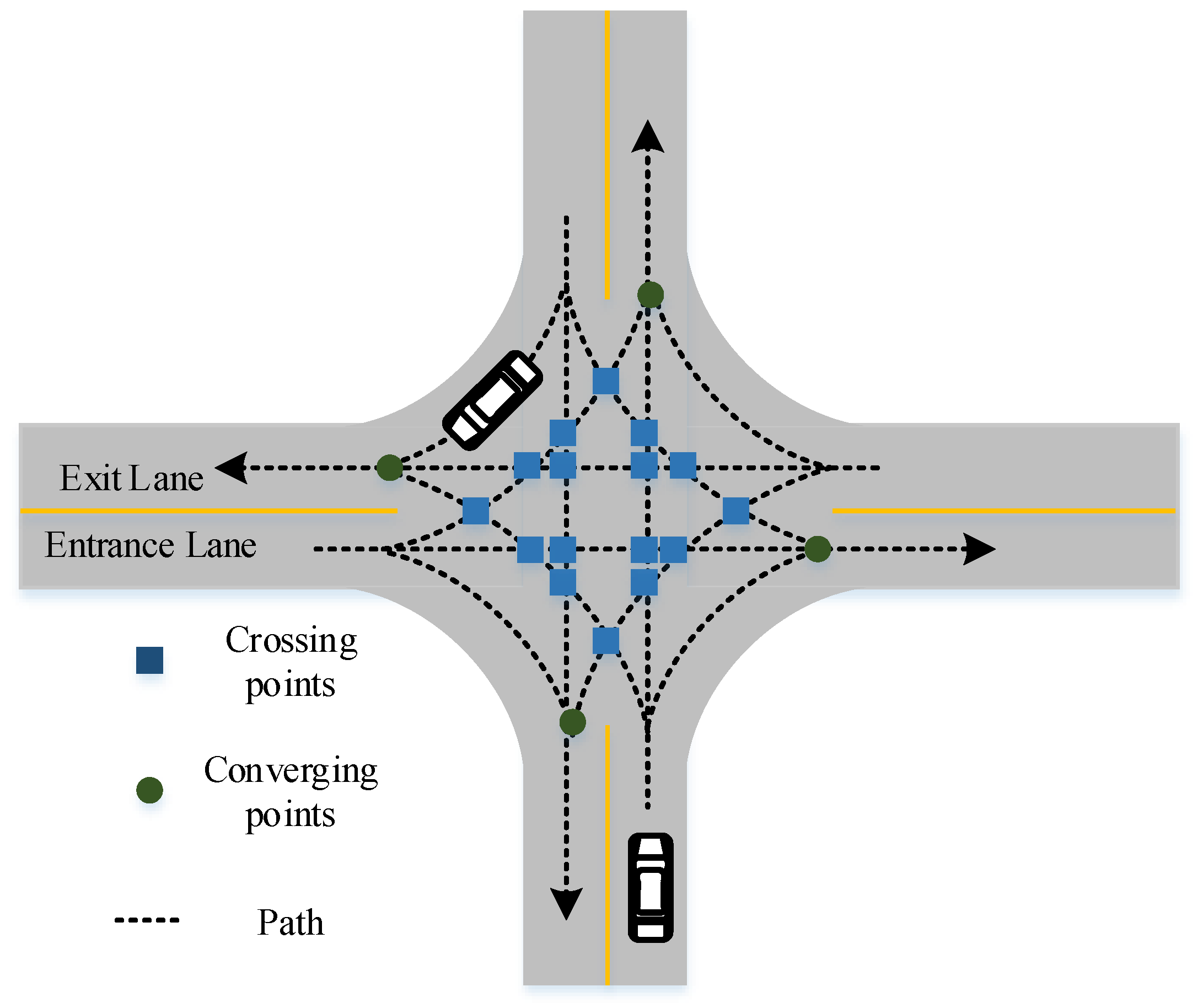
An unsignalized intersection scenario does not have traffic lights to govern it. The existence of conflict areas at the lane interchanges and the changes in the vehicle driving behaviors can easily cause disorder, resulting in traffic safety accidents, such as rear-end collisions and traffic jams, which is where a large number of accidents occur [
12]. In this paper, we assumed that all the vehicles, including the HDVs, will be given the right of way according to the traffic regulations. Based on this assumption, the CAVs learned to adapt to the HDVs and cooperate with them for safe and efficient crossing. Since multiple CAVs are required for cooperative driving, it is natural to adopt a multi-agent reinforcement learning framework to achieve the cooperative goal. The multi-agent proximal policy optimization (MAPPO) in a cooperative setting [
13], which had a surprising effectiveness, was used as the benchmark algorithm in this paper. The original algorithm directly took the information from the agent’s neighbors as its own observations. As the number of agents increased, learning became more difficult [
14]. Therefore, an attention representation was utilized to select the most relevant information from the vehicle’s neighbors. In the context of the cooperative multi-agent setting, the reward assignment problem concentrated on how to assign a global return to each agent that accurately reflected the agent’s contribution to the overall behavior. We noted that the distance between a vehicle and the intersection had different effects on the safe operation of the system, and thus proposed a weight reward assignment scheme.
Therefore, to address the above problems in this paper, a decentralized MAPPO based on the attention representations (Attn-MAPPO) is proposed to make joint decisions at the intersection based on the trajectory prediction of all the vehicles. The contributions of this paper are fourfold.
First, decision-making at the intersection where the CAVs and HDVs coexist was formulated as a decentralized MARL problem. Based on the traffic rules and the most valuable neighbor information extracted by an attention module, the Attn-MAPPO algorithm was developed to allow vehicles to cross the intersection safely and effectively.
Secondly, a weighted reward assignment scheme was proposed. According to the position of the vehicles, the contribution of each CAV could be measured to enhance the cooperation between the vehicles.
Thirdly, an effective reward function was designed. Due to the uncertain behavior of the HDVs, all the vehicle’s trajectories at every time step were predicted in a forward predictive time horizon, which reflected precisely how well the action was taken.
Fourthly, we conducted the comparative experiment about the traditional heuristic rule-based and our proposed approaches, and the results showed that our proposed approach was more adaptive and generalized in a complex traffic environment.
The remainder of the paper is organized as follows.
Section 2 briefly reviews several approaches to settle the decision-making problem at an intersection.
Section 3 states some of the problems, including the research scenario, the right of way the rules, and the vehicle intersection model. The problem formulation and the proposed MARL framework are described in
Section 4. The experiments, results, and discussions are presented in
Section 5. The paper is concluded, and the future works are discussed in
Section 6.
2. Literature Review
Due to the complex interactions, the decisions made by the CAVs at the unsignalized intersections are a critical issue. Several approaches have been recommended for a settlement, namely the rule-based, optimization-based, and data-driven algorithms.
Earlier research mainly used a rule-based approach, where the main idea was to determine the order of the vehicle passage based on the rules or experience. The most direct approach was to carry out the first-in-first-out rule reservation scheme based on the centralized controller [
15]. Another distributed approach based on fuzzy logic controllers was proposed. Milanes et al. [
16] used V2V communication to determine the position and speed of the other vehicles in the intersection and then utilized a fuzzy controller to adjust the speed according to the speed of the vehicles with right of way. The rule-based approach was simple to implement, but not optimal.
Optimization-based algorithms take the decision factor as the objective and formulate the optimization under the constraints. Bian et al. [
17] presented a distributed optimization to schedule the arriving times for the trajectory planning and achieved a satisfactory cooperative management with a 8.8–18.1% growth in the average passing times. However, the real-time optimization was limited to a high computational load and could not be achieved. In recent work, the combination of the above two approaches realized the approximations that dealt with the optimization via some heuristic rules, leading to a good trade-off between the performance and the computational complexity. For example, Xu et al. [
18] solved a nearly globally optimal coordinated decision using the Monte Carlo tree search algorithm based on the feasible passing order that was selected using two heuristic rules. Vaio at el. [
19] reformulated the vehicle coordination as the equivalent virtual platoon control problem based on the ascending order of the distance to the intersection. Due to the lack of learning and adaptability, these two methods were intractable to effectively tackle the task without accurate models.
As the field of artificial intelligence evolved, data-driven approaches have been a research hotspot for model-free problems due to their unparalleled data processing and generalization ability. Game theory [
20] and deep reinforcement learning (DRL) [
21] play a significant role in the decision-making at intersections. DRL addresses the cooperative decision-making tasks depending on the impressive learning capabilities based on the continuous interaction. Isele et al. [
22] used DRL to identify the strategy that outperforms the common approach based on the heuristic rules. Lin et al. [
23] discovered that when the scenario was modeled inaccurately, the policy trained by DRL performed better than the optimization approach of the interior point optimization (IPO). Shi et al. [
24] proposed a coordinated control method with a proximal policy optimization (PPO) to make the CAV adapt to the HDVs. Liu et al. [
25] employed a DRL to guide the expected speed and converge to the planned decision.
However, these studies involved only a single vehicle, disregarding the fact that concurrent interaction cooperative decision-making is a typical multi-agent system (MAS). Hence, it was logical to extend to a multi-agent reinforcement learning (MARL) framework. The decision at the intersection can be articulated as a fully cooperative MARL problem. MARL has already been used for research in the field of intelligent transportation, such as traffic signal control [
26] and highway decision-making [
27]. Decision-making at the intersection can be articulated as a fully cooperative MARL problem, for which very few works exist, even though it is still a new area of research [
21]. Based on the model accelerated proximal policy optimization (PPO), Guan et al. [
28] proposed a centralized coordination method to globally coordinate the CAVs approaching the intersection by considering their states altogether, which achieved an increased efficiency. Zhou et al. [
29] applied a centralized control for all CAVs that shared the same learned controller and then enabled the CAVs to form an appropriate behavior using the deep deterministic policy gradient (DDPG) algorithm. Antonio et al. [
30] used MARL to identify complex real-life traffic scenarios and collaboratively regulate the CAVs at the intersection, which reduced 59% of the travel time and 95% of the congestion time compared to the traffic light control method. However, some issues in the MARL settings were not considered in the aforementioned works. The first issue was how to learn the most relevant information from other agents in a partially observable environment. The second was the reward assignment problem. In this study, we attempt to address the abovementioned issues by adopting a multi-agent reinforcement learning-based approach.
4. Cooperative Decision-Making in a Multi-Vehicle Cooperative Task
4.1. Problem Formulation
In this paper, the unsignalized intersection environment, where the CAVs and HDVs coexist, was modeled as a model-free multi-agent system to solve the cooperative decision-making and control problems. The system was described as where represents a non-empty finite with CAVs and the edge set represents the connections among the CAVs. The CAVi makes decisions based on its observations of the local sensors, such as cameras and lidars, and its communication with its neighbors, denoted as , to enhance the range of perception. Considering that the decisions of N CAVs are interactive, the problem was considered a fully cooperative multi-agent task, which was modeled as a partially observed Markov decision process (POMDP). For the POMDP, each agent received a partial observation from the global state . Based on the observation, the agents took joint action, from the action set to interact with the environment and receive a reward from all the agents The goal was that the agents would attempt to learn an optimal joint policy to maximize the expected return in the interaction with the environment, where is the accumulated discount factor to quantify the importance of the future reward and T denotes the total steps of an episode. It can be defined by a tuple where P denotes a state transition function.
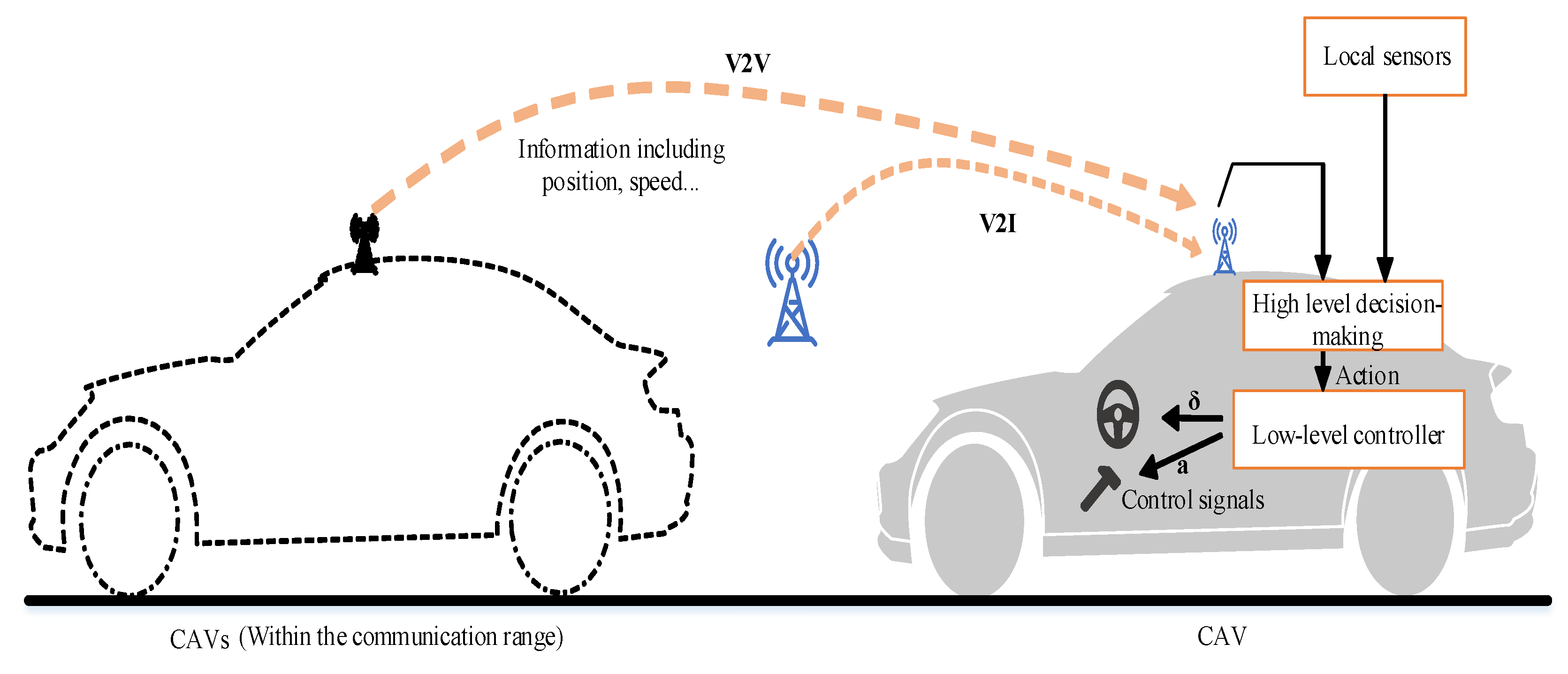
Action: In this paper, the control system of the vehicle was split into two levels, the high-level decision-making and the low-level controller, as depicted in
Figure 2. According to the local observation, the high-level decision-making selected an action in the action space
defined as
= {
hard acceleration, acceleration, idle, deceleration and hard deceleration}. Then, based on the decision taken, the lower level controller, i.e., a PID controller, generated the corresponding throttle signals to maneuver the CAV.
Observation: The observation of the vehicle included the information required to make decisions effectively. It was assumed that each vehicle could sense its state and exchange information with its neighbors, which is denoted as The neighbors of a vehicle were defined as the vehicles that were within meters and with the potential of a collision, i.e., a different priority on their respective routes. The observation was defined as a matrix of where denotes the upper bound of the number of its neighbors and W is the number of features ci representing the state of a vehicle. Specifically, the observation feature is defined as , where ispresent is a binary flag denoting whether a vehicle can be observable. represent the absolute longitudinal position, the lateral position, the longitudinal speed, and the lateral speed for the ego vehicle, while the relative to the ego vehicle for observed vehicles; h denotes the heading; and ps represents the priority of crossing the intersection. The entire state of the system is the Cartesian product of the individual observation, that is, .
Reward: The basic goals of a vehicle at the intersection include driving safely, crossing the intersection, and reaching its target lane under the right of way rules and in a timely manner. Several rewards are specified as follows.
- (a)
The occurrence of a collision is detected by the body circle model. It reduces the vehicle to a circle with the center of the vehicle as the center and the diagonal of the vehicle as the diameter. When two vehicles are tangent to each other, a collision is considered to have occurred. The collision reward
rc is defined to penalize the occurrence of a collision and reward the successful pass, expressed as follows.
- (b)
For safety, the vehicle is penalized when the minimum time headway
with other vehicles is less than desired time headway
. In this paper,
was set to 2 s. Our study scenario was a mixed traffic scenario where the HDVs and CAVs coexisted. The uncertain behavior of the HDVs prevented us from directly calculating the time to collision (TTC). Therefore, within a prediction horizon
Th, all the vehicles’ trajectories are predicted. The trajectories of the CAVs are predicted via the execution of the current action, while the HDVs are estimated from the IDM model. At each step of the prediction, the collision of vehicle
i is detected according to the body circle model. If a collision occurs at step
t, the time headway
is determined according to
, where
f represents the control frequency of the vehicle. When no collisions are detected,
rh is set to 1. Thus, the headway reward
rh is defined as follows.
- (c)
To pass though the intersection safely and effectively, the speed should be considered as appropriate and is punished too low. The speed reward is defined as follows.
where
are the current speed and the minimum and maximum speeds to be rewarded.
- (d)
For the vehicle to make decisions under the rules demonstrated in
Section 3.2 the rule reward
rr is set to 1 if the rule is obeyed, otherwise
.
Based on these definitions above, the total reward for the
at time step
t is defined as follows.
where
, and
are all weighting factors that account for each part of the reward.
4.2. Wighted Reward Assignment
In the fully cooperative MARL setting, each agent was provided with the same goal and assigned the same reward after executing the action at every step. The same reward can be represented by the average global reward as
However, the shared rewards scheme is intricate in order to infer each vehicle’s contributions to the system cooperation. Further, instead of embracing a global reward, a local reward assignment strategy could alleviate the issue of the credit assignment problem. Specifically, each host vehicle only focuses on its surrounding vehicles, which considerably impacts the smooth interaction between the vehicles. Thus, the reward for the ego vehicle
at the step
t is defined as follows.
where
is a set whose elements include the ego vehicle
and its neighbor vehicles and
represents the cardinality operator of the set. The local reward assignment has two advantages. First, the communication burden can be reduced by focusing only on the nearby vehicles, establishing a more real-time system. Second, the contribution of the vehicles to their cooperation can be indicated more accurately.
Nevertheless, the regional reward assignment strategy still doesn’t accurately differentiate between the contributions of each ego vehicle at different positions on the road. Collisions are more likely to occur inside the intersection than outside it, meaning that a vehicle closer to the intersection should be assigned more rewards, i.e., a weighted reward assignment according to the vehicle’s position. A weight factor
was defined to measure the contribution for crossing the intersection safely and efficiently, as shown in Equation (7).
where
denotes the distance from the vehicle
not entering the intersection to the entrance or from
not exiting the intersection to the exit, and
Ls is the length of the entrance or exit straight lane. When
enters the intersection,
. Thus, the reward for the ego vehicle
at the step
t is as follows.
When a vehicle and its neighbors are in the intersection, Equation (8) will degenerate to the local reward assignment strategy, i.e., Equation (6).
4.3. Cooperative Learning Algorithm for Multi-Agent Task
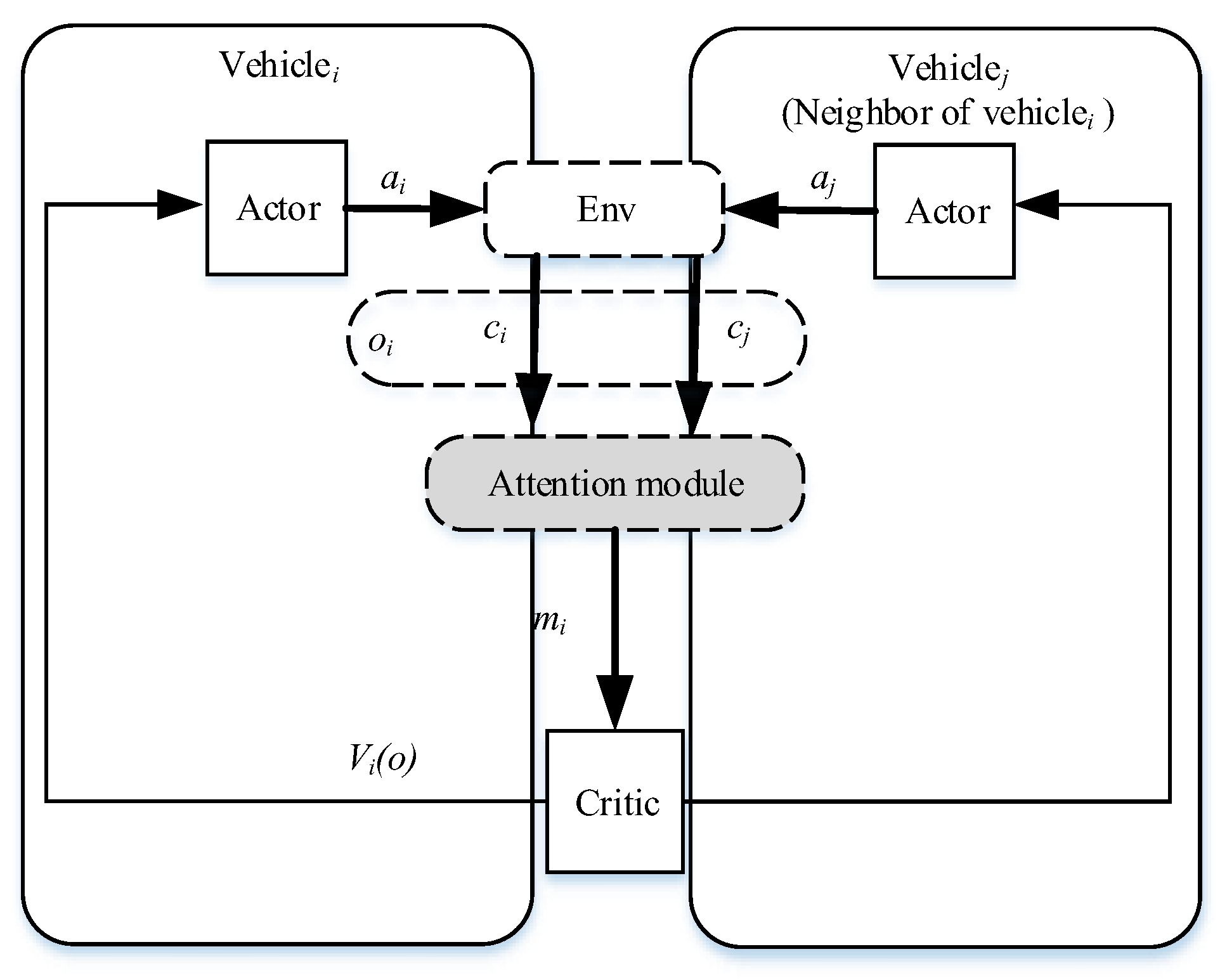
The MARL method was leveraged to deal with the unsignalized intersection management due to the fact that it could produce an optimal policy through a continuous interaction with the traffic environment. A cooperative PPO-based decision-making method (Attn-MAPPO) is proposed in this section, as shown in
Figure 3. The algorithm was based on a centralized training decentralized execution (CTDE) framework to reduce the environmental instability; that is, all the information of the agents was utilized during training and the agents only made decisions according to their own local observation after the training. Specifically, after choosing the actions from the policy to interact with the environment, all the vehicles executed them and reached a new state. Based on the new observation, an attention module was used to aggregate the information from the neighbors of a vehicle. Then, the output of the module was used to update the critic network. The critic network evaluated the taken actions and the agent network was updated.
In this paper, each vehicle could observe its neighbors and collect their state information to make decisions. Although the relevant vehicle was selected as the focus, the aggregated information was not the most valuable information. For example, the state information of the neighbors which were more likely to collide required more attention. The attention mechanism was introduced in this paper to selectively pay attention to the neighbors’ observations.
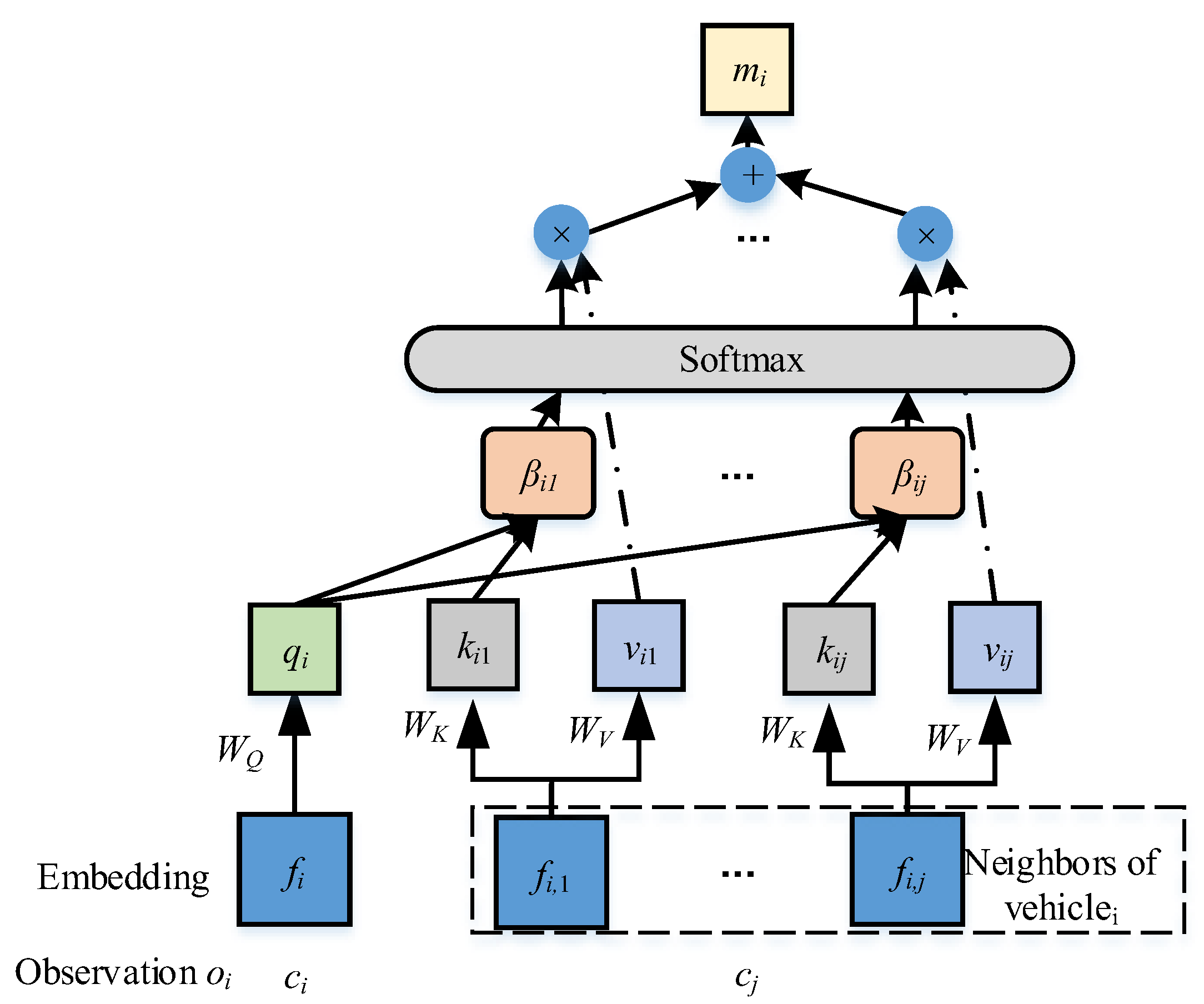
More specifically, the structure of the attention representation is defined as
Figure 4. The relevant message from other vehicles,
, is summed by assigning the attention weights to the embedding of each agent, which is mathematically expressed as the following.
where
is the embedding where a multi-layer perceptron (MLP)
is used as the embedding function and
is a matrix to linearly transform
into a “value”. The attention weight
between the vehicles
i and
j was calculated using a
softmax function, as shown in the following.
where
computes the correlation between the vehicles
i and
j, the matrix
linearly transforms
into a “query”, and
transforms
into a “key”.
In the cooperative multi-agent setting, each agent shared an actor network (i.e., policy) and a critic network (i.e., policy evaluation), which were trained using the individual trajectory The actor network was trained to maximize the expected return. Each agent generated its action from the policy based on its local observations (i.e., at the time slot t. The most valuable information which an attention representation aggregated from the neighbors of an agent was access to the input of the critic network. An episodic setting was considered with each vehicle until a crash occurred or until it proceeded T seconds. Our objective was to obtain the optimal joint policy that maximized the accumulated reward.
The PPO algorithm based on the actor–critic framework was an improvement of the policy gradient (PG) algorithm. The objective function of the PG algorithm is expressed as the following.
where
is an estimation of the advantage function at the step
t and
are the parameters for identifying the policy and state value functions, respectively.
By modifying the objective, the PPO constructs a clipped surrogate objective function to confine the policy updates to a small scope of around 1. The objective and update functions are illustrated as the following.
where
l is the learning rate and
specifies the probability ratio of the old and new policies to select the action and
where
is the penalty factor to prevent the policy from changing extremely. When
the return for taking the action
is greater than the expected observation
. Therefore, the updated policy should increase the probability of the action, but the increase amplitude should be restrained to
. The opposite is true when
.
To decrease the variance, the advantage function
in Equation (13) is replaced by the generalized advantage estimation (GAE), which is expressed as the following.
where
is the TD error and
is a factor that balances the variance and bias of the estimation. When
which is unbiased with a high variance. The GAE achieves both a low bias and a low variance by linearly integrating the
n-step bootstrapping. The critic network
is updated using the loss function as follows.
The whole pseudo-code for the proposed method is presented in Algorithm 1.
| Algorithm 1: Attn-MAPPO |
1: Initialize the actor network and target the actor network using the parameters θ and
2: Initialize the critic network and target the critic network using the parameters and
3: Initialize the memory buffer Di and hyper-parameters lr, τ, ϵ.
4: for episode = 1, … , M do
5: for and not terminal do
6: for do
7: Observe and select an action using the ϵ-greedy strategy.
8: All agents execute the actions and receive their own reward .
9: Store trajectories in
10: end for
11: for do
12: Obtain the attention representation of each agent using Equation (9).
13: Update the critic network and the actor network using a randomly sampled mini batch from in Equations (15) and (19), respectively.
14: Update the target networks:
15: end for
16: end for
17: Initialize and reset the environment.
18: end for |
5. Results and Discussion
In this section, the proposed Attn-MAPPO algorithm was evaluated at the unsignalized intersection on an open source platform, called highway-env [
32]. A total of 30 episodes of the evaluation for each contrast were executed using 30 various seeds. Two metrics were used for the performance of the algorithm, namely the collision rate and the average speed. The collision rate was defined as the ratio of the number of episodes where the collision occurred to the total number of the test episodes. The average speed was defined as the average speed of all the vehicles in all the episodes. In the scenario, a straight lane had a distance of
Ls = 200 m, the right turn radius was
, and the left turn radius was 13 m. The vehicle’s policy frequency was set to 5 Hz, i.e., the CAVs took an action every 0.2 s. The speed range of receiving a reward was [
8,
10] m/s. For the actions, the normal acceleration and deceleration were to add or subtract 1.5 m/s from the current speed, as the desired speed and the hard were 3 m/s. The PID algorithm was used as the low-level controller to change the current speed to the expected speed. To avoid the excessive speed, the maximum speed of CAVs was set to 10 m/s. The HDVs’ desired speed was set to 10 m/s. The communication range
Lc was set to 120 m. The setting of the training process was presented as follows. The model was evaluated every 20 episodes during the training. ADAM was used as the optimizer and the learning rate was set to 8 × 10
−5. The soft update weighting factor
τ was set to 0.001. The trade-off coefficient of the GAE λ was set to 0.95 and the discounting factor was set to 0.99.
5.1. Performance Comparison between the Proposed Attn-MAPPO Algorithm and the Benchmark
In this subsection, we compared the proposed Attn-MAPPO approach with the MAPPO benchmarks [
13]. The architecture was the same for both, but the Attn-MAPPO used an attention mechanism to extract the most valuable information as the input for the network. To validate the performance of the proposed Attn-MAPPO algorithm, two traffic scenarios were set up with (1) two CAVs and three HDVs, and (2) four CAVs and five HDVs. The first setting was simple due to the sparse traffic density, while the second was complex. The comparison results of the episode reward in the training is illustrated in
Figure 5. The results showed that in the simple setting, namely with the two CAVs, three HDVs, both the algorithms performed comparably but moderately better than the benchmark. Yet, as the number of vehicles increased, the benchmark performance declined significantly and the Attn-MAPPO algorithm showed a stronger performance. In the 30 tests, one collision occurred using the proposed method and four collisions occurred using the benchmark in the complex setting.
Table 1 shows that for the proposed algorithm, the collision rate could be considerably diminished in the complex traffic setting. This implies that the added attention module was able to extract the critical information for decision-making, whereas the benchmark did not have this capability.
5.2. Performance of the Proposed Reward Scheme Designs
In this paper, the setting of the reward mechanism had two main aspects. The first was the design of the reward function and the second was the design of the reward assignment scheme.
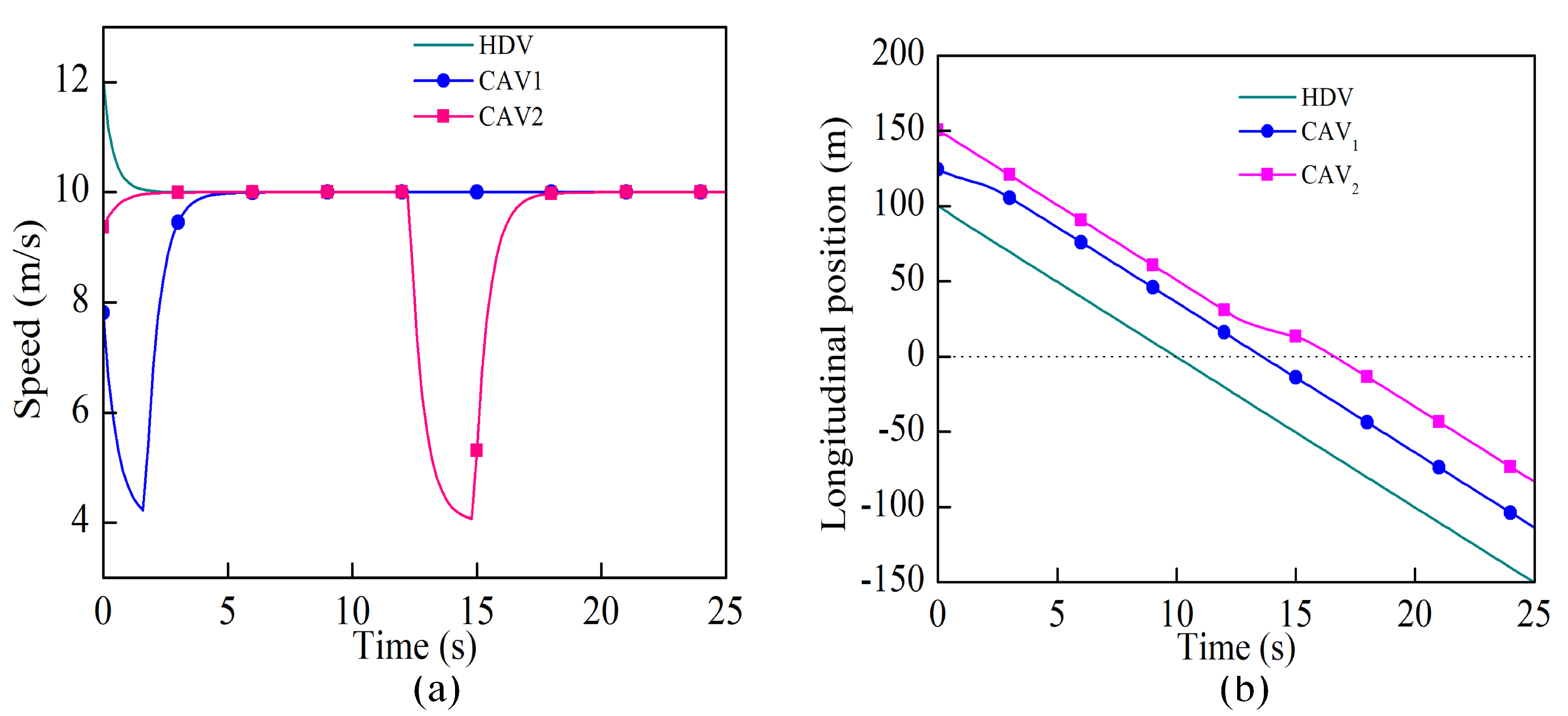
There were four components in the reward function, including the collision evaluation, headway evaluation, speed evaluation, and rule evaluation. In order to validate the effectiveness of the reward function for decision-making, we set up an intersection crossing scenario. There were three vehicles in this scenario, where one HDV shown in blue was going straight and two CAVs shown in green were turning left, denoted as CAV
1 and CAV
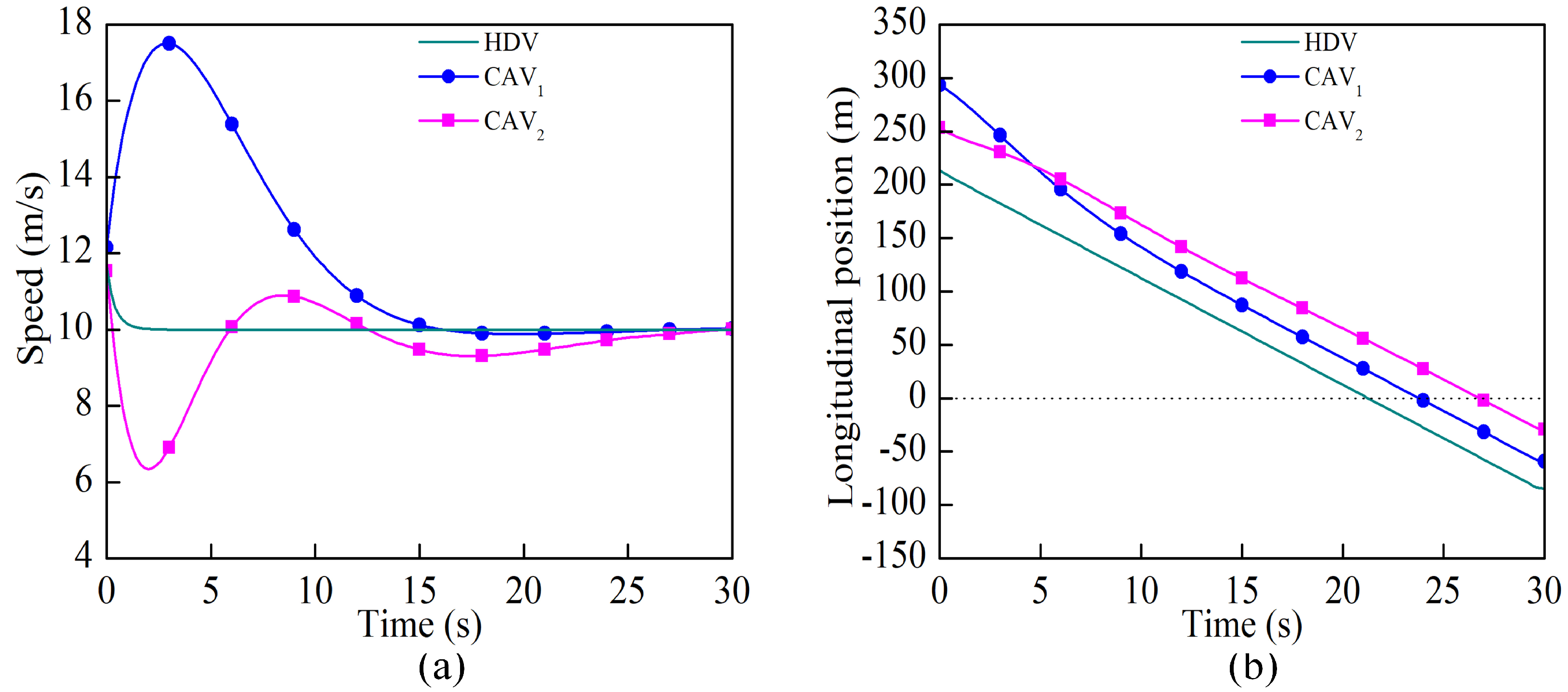
2, respectively. In order to present the spatial relationship of the vehicles more intuitively, the positions of the vehicles were represented by the distance from the stop line along their path, rather than their world coordinates. The positions were negative when the vehicles crossed the stop line. The position and speed curves of all the vehicles during the whole process are shown in
Figure 6.
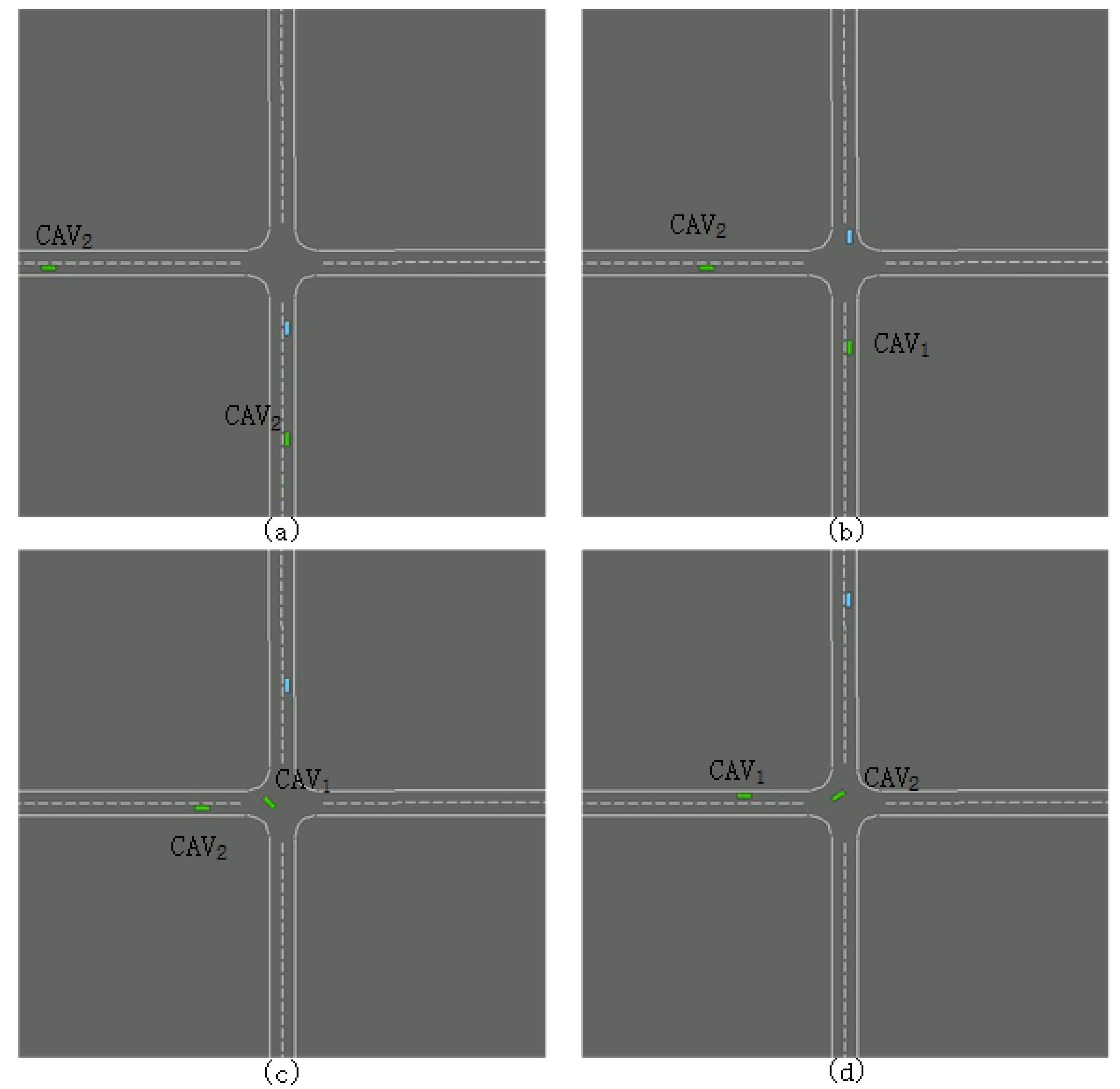
Figure 7 shows a sequence of the time slices for demonstrating the inter-vehicle interaction. Apparently, all the vehicles crossed through the conflict zone safely. As shown in
Figure 6a, when there was no interaction between vehicles, they could accelerate to the maximum speed of 10m/s to obtain a higher reward. In accordance with the traffic rules introduced in
Section 3.2, the vehicle going straight goes first, and the one on the right has the right of way. Thereby, the passage sequence of the three vehicles was HDV, CAV
1, and CAV
2, which was exactly what is shown in
Figure 7. There were two interactions during the crossing. CAV
1 and the HDV first interacted in the same lane, where CAV
1 slowed down and pulled away from the HDV ahead of it. The second interaction took place between the two CAVs. Since CAV
2 should have crossed later than CAV
1, CAV
2 decelerated to make way at 12.4 s. All the above analyses demonstrated that the designed reward function was qualified for the effective decision-making for the CAVs.
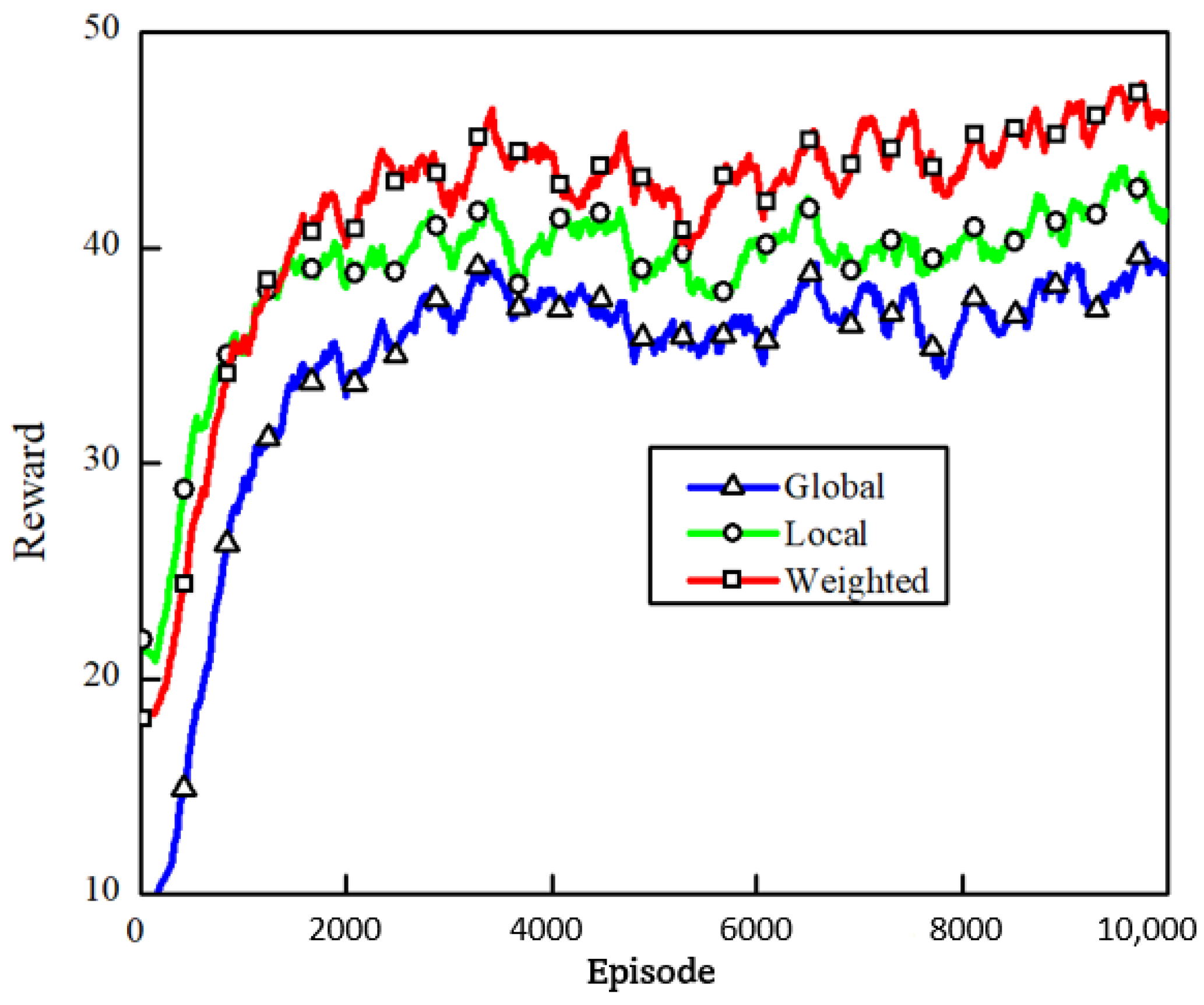
To validate the performance of the proposed reward assignment scheme, the global reward, local reward, and the proposed weighted reward scheme were used for the training in the simple setting, i.e., the two CAVs and three HDVs. As many people are aware, collisions are more likely to occur in the areas within the intersections than in the straight lanes. When the system was penalized, the vehicle nearest the intersection should have been assigned more penalties to help it execute the correct decision. The same went for receiving a reward. The results are shown in
Figure 8. As excepted, the results confirmed that the proposed weighted assignment outperformed the other two assignment schemes.
Table 2 shows a clear improvement in the collision rates and the average speed metrics. This was because the global reward was not an accurate representation of the contribution of a CAV. Although the local reward improved on this, the reward could not be assigned based on an agent’s location. The weight reward assignment scheme assigned more rewards to the vehicles closer to the intersection, which facilitated the cooperation between the agents.
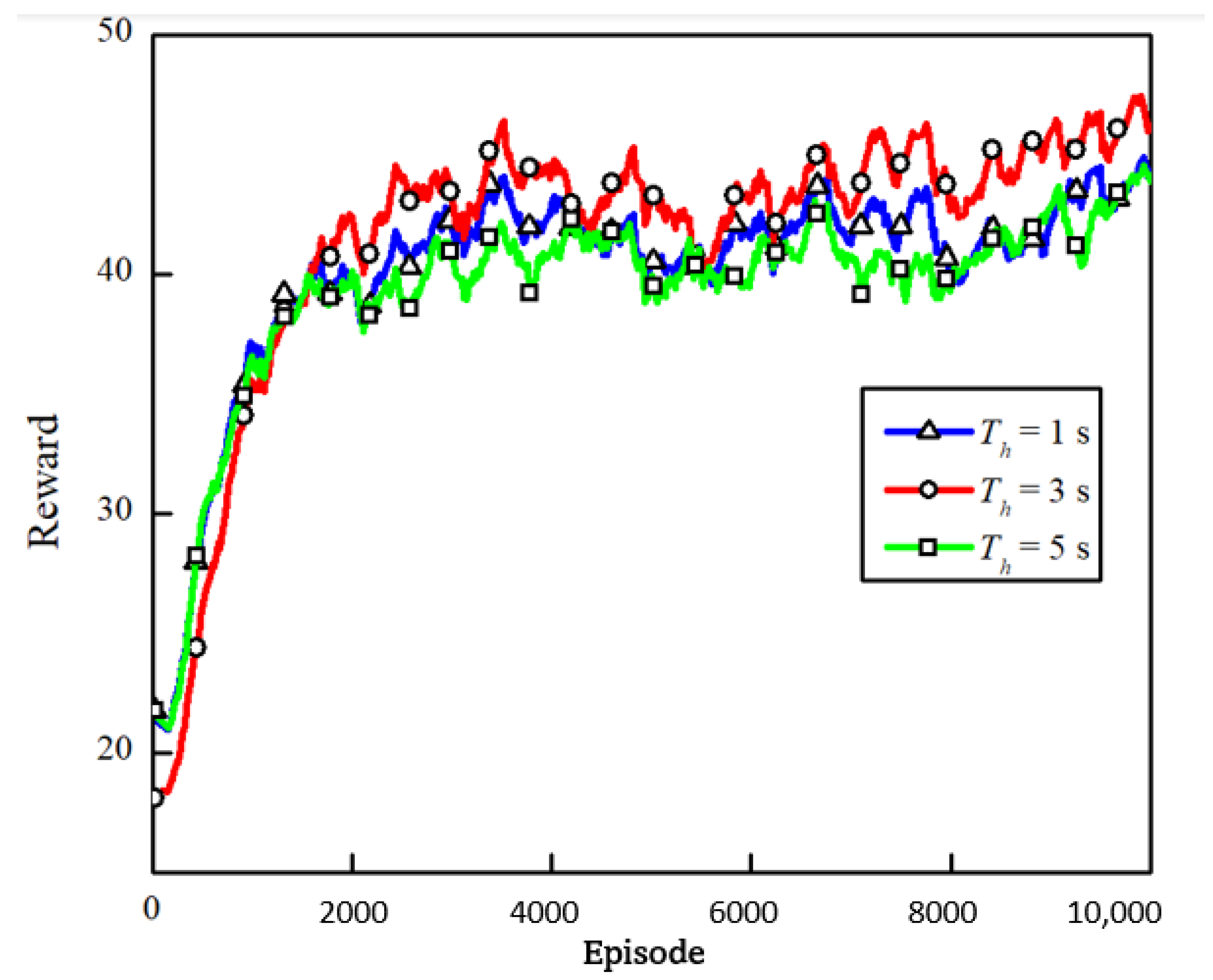
5.3. Performance Comparison of the Different Forward Predictive Horizons
Our research scenario was a mixed traffic scenario where the HDVs and CAVs coexisted. In this paper, the CAVs made decisions based on the predicted trajectories of all the vehicles over time. To validate the impact of the different time horizon for predicting the trajectories of all the vehicles, three settings were used for the training. The results are shown in
Figure 9 and the performance metrics are presented in
Table 3. The results indicated that a larger prediction time horizon did not imply a better performance. Although a larger predictive time horizon could reduce the collision rate, it would significantly reduce the metrics of the average speed. The performance depended on the design of the headway evaluation in the reward function and the desired headway time, as introduced in
Section 4.1. The desired headway time
was set to 2 s during the training. When
, even though the current headway time was less than
, the vehicle agent still received a positive reward because no collision was detected within the predictive horizon. This could easily result in the vehicle anticipating a collision when the brakes would not be able to prevent a collision. Compared to
, the prediction horizon of
was conservative for the decision-making of the vehicle. As long as the collision was not detected within 3 s, the vehicle received a reward of one with a 3 s prediction horizon. In the case of
, the vehicle would be rewarded with the value of
, even though the collision was predicted at 5 s. This indicated that a suitable prediction time horizon could achieve a better performance.
achieved a good trade-off between the collision rate and the prediction efficiency.
5.4. Performance Comparison of the Proposed and Heuristic Rule-Based Algorithm
In this subsection, we verified the adaptability of our proposed algorithm by comparing it with the heuristic rule-based algorithm using the same scenario in
Section 5.2. The traditional ruled-based or model-based decision control approaches were capable of generating stable decision results, accurate control curves, and were easy to implement. For example, the vehicles coordination of negotiating the access in an intersection was reformulated as a virtual platoon control problem in [
9]. According to the passage sequence, the HDV acted as the leader and the two CAVs kept the desired following distance.
Figure 10 shows the results using a virtual platoon. The HDV traveled at the desired speed of 10 m/s. CAV
1 adjusted its speed to keep the desired distance from the HDV and CAV
2 followed CAV
1.
Although the vehicles could cooperatively and efficiently cross the intersections under the ideal traffic conditions using the heuristic rule-based model, some of the idealized condition assumptions were difficult to satisfy in many cases. Generally speaking, the traffic scenarios involving the HDVs were more complex and uncertain for the uncontrolled human driving. For example, some drivers were conservative and traveled at a low speed for fear of getting scratched in intersections. The speed and position curves of all the vehicles when the HDV traveled at a low speed using a heuristic rule-based algorithm are shown as
Figure 11. In order to form a virtual platoon, the speed of both CAVs converged to that of the leading HDV. Practically, the CAV
2 was not in the same lane as the HDV, so it did not need to keep up with the speed of the HDV, which could greatly enhance the road efficiency. The results demonstrated that the heuristic rule-based approaches, while easy to implement, were not adaptive to some special cases.
A learning-based approach enabled more efficient decision-making. The results are presented in
Figure 12 using the proposed algorithm when the HDV traveled at a low speed. Based on the trajectory prediction of the other vehicles, CAV
2 predicted that the slow speed of the HDV would not cause a collision. CAV
2 made the decision to breaks traffic rules and pass first, since the reward for following the traffic rules was smaller than the penalty for crossing the intersection at a low speed. Thus, if no collision was predicted, the HDV only affected the decision of CAV
1 behind it in the same lane but not CAV
2’s in other lane. As shown in
Figure 12b, after the HDV crossed the stop line, that is, when its position was less than 0, the CAV began to accelerate. This accounted for the fact that the proposed approach could deal with some special cases, which were more adaptive and generalized.
6. Conclusions
In this paper, we modeled the decision-making at the intersection of the CAVs and HDVs in coexistence as a model-free and fully cooperative multi-agent system. Based on this, we presented the design of the observation, action, and reward functions to formulate the cooperative decision-making as a MARL problem. Then, a decentralized MAPPO based on the attention representations algorithm (Attn-MAPPO) was developed to make joint decisions to avoid collisions and cross the intersection effectively. Finally, the policy was trained and evaluated via an open source simulation platform. The results showed the advantages of our proposed algorithm and the designed reward scheme. In addition, the comparison of the results using the three prediction time horizons also suggested that a suitable horizon could achieve a better performance. We compared the performance of the Attn-MAPPO to an equivalent virtual platoon control, a heuristic rule-based method, which indicated that the proposed approach could deal with some special cases more adaptively and generically.
However, there were still some unsolved problems in this paper. The driving behavior of the HDVs was modeled using the IDM model. In practice, more accurate models may be needed. Moreover, the scalability of the algorithm needs to be improved, i.e., increasing the number of CAVs. At the same time, in this paper, only the full cooperation between the vehicles was considered. In fact, there was also a competition between the vehicles at the intersection. In future works, we will pay more attention to these issues and continue to expand from this study.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}