
Short-Term Risk Estimation and Treatment Planning for Cardiovascular Disease Patients after First Diagnostic Catheterizations with Machine Learning Models




Abstract
:1. Introduction
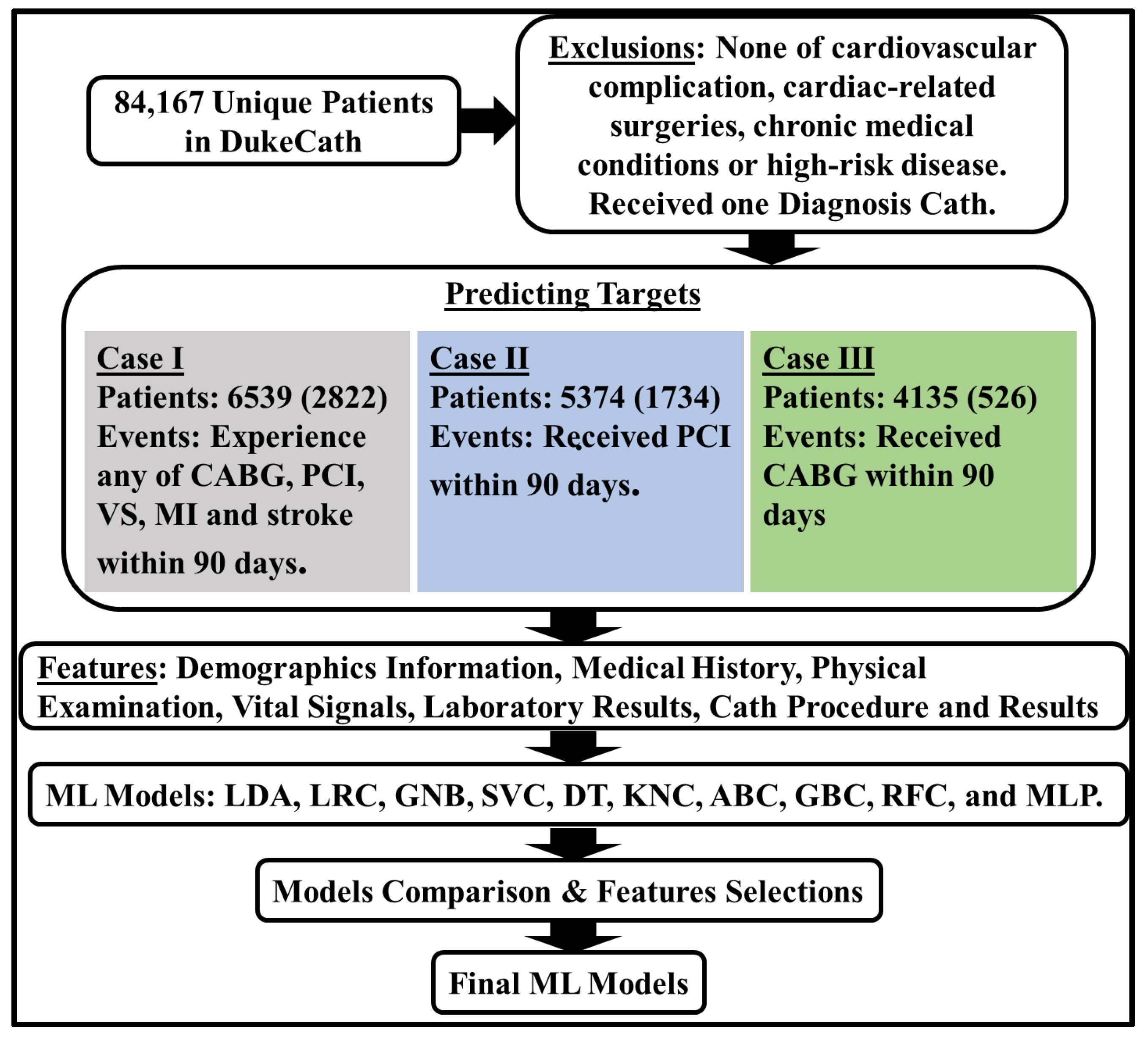
2. Materials and Methods
Machine Learning Models
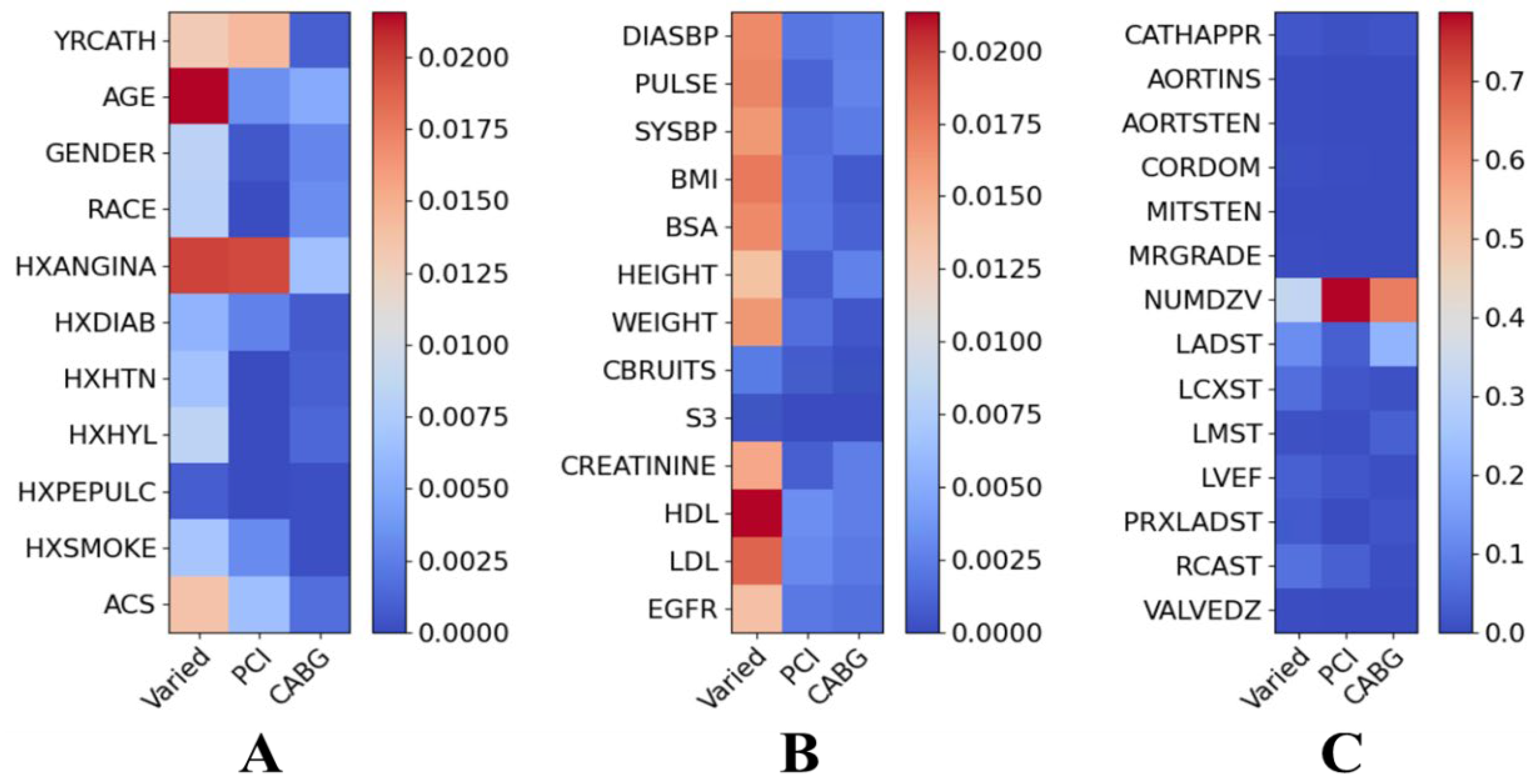
3. Results
3.1. Performance of ML Methods
3.2. Statistical Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Feature | No Risk (3717) | Risk (2822) | No PCI (3640) | PCI (1734) | No CABG (3609) | CABG (526) |
|---|---|---|---|---|---|---|
| Gender (male) | 1771 | 994 | 1759 | 626 | 1734 | 150 |
| Race | ||||||
| Missing | 98 | 64 | 97 | 42 | 96 | 11 |
| Caucasian | 2419 | 2128 | 2360 | 1267 | 2341 | 407 |
| African American | 1034 | 482 | 1019 | 325 | 1010 | 81 |
| Other | 166 | 148 | 164 | 100 | 162 | 27 |
| Age | ||||||
| 18–24 | 6 | 1 | 6 | 0 | 6 | 1 |
| 25–29 | 27 | 3 | 27 | 2 | 27 | 0 |
| 30–34 | 80 | 14 | 80 | 7 | 78 | 2 |
| 35–39 | 173 | 56 | 166 | 35 | 165 | 8 |
| 40–44 | 330 | 130 | 326 | 85 | 323 | 18 |
| 45–49 | 469 | 259 | 455 | 164 | 455 | 33 |
| 50–54 | 583 | 355 | 571 | 220 | 560 | 67 |
| 55–59 | 563 | 413 | 546 | 257 | 537 | 76 |
| 60–64 | 499 | 426 | 488 | 265 | 492 | 83 |
| 65–69 | 420 | 415 | 412 | 242 | 408 | 70 |
| 70–74 | 247 | 340 | 243 | 199 | 237 | 83 |
| 75–79 | 199 | 267 | 197 | 159 | 199 | 65 |
| ≥80 | 121 | 143 | 123 | 99 | 122 | 20 |
| History of peptic ulcer disease | 43 | 41 | 41 | 21 | 40 | 7 |
| History of diabetes | 740 | 698 | 719 | 400 | 704 | 144 |
| History of angina | 2552 | 2500 | 2488 | 1607 | 2460 | 459 |
| History of hypertension | 2015 | 1769 | 1966 | 1086 | 1947 | 326 |
| History of hyperlipidemia | 1534 | 1542 | 1491 | 925 | 1481 | 314 |
| History of smoking | 1504 | 1318 | 1463 | 818 | 1450 | 242 |
| Acute coronary syndrome status upon presentation (ACS) | ||||||
| No ACS | 2545 | 1292 | 2492 | 715 | 2478 | 280 |
| STEMI | 17 | 75 | 17 | 51 | 15 | 6 |
| Non-STEMI | 42 | 111 | 42 | 76 | 41 | 20 |
| MI Unspecified | 2 | 2 | 3 | 1 | 3 | 0 |
| Unstable Angina | 1111 | 1342 | 1086 | 891 | 1072 | 220 |
| Third heart sound (S3) | 29 | 12 | 28 | 3 | 29 | 4 |
| Carotid bruits | 47 | 105 | 47 | 42 | 47 | 32 |
| Height (cm) | 170.64 (10.8, 0) | 171.95 (10.34, 0) | 170.53 (10.76, 0) | 171.88 (10.39, 0) | 170.58 (10.79, 0) | 172.64 (10.45, 0) |
| Weight (kg) | 86.29 (24.09, 0) | 86.54 (20.18,0) | 86.03 (24.12, 0) | 87.19 (20.42, 0) | 86.13 (24.11, 0) | 86.37 (19.92, 0) |
| Body surface area (m2) | 1.97 (0.27, 0) | 1.99 (0.24, 0) | 1.97 (0.27, 0) | 1.99 (0.24, 0) | 1.97 (0.27, 0) | 1.99 (0.24, 0) |
| Body mass index (kg/m2) | 29.63 (8.44, 0) | 29.3 (7.03, 0) | 29.58 (8.48, 0) | 29.58 (7.47, 0) | 29.6 (8.48, 0) | 28.95 (6.13, 0) |
| Diastolic blood pressure (mmHg) | 81.38 (13.59, 0) | 81.52 (13.93, 0) | 81.28 (13.63, 0) | 81.29 (13.6, 0) | 81.33 (13.63, 0) | 82.1 (13.23, 0) |
| Systolic blood pressure (mmHg) | 142.23 (23.29, 0) | 148.07 (24.62, 0) | 141.98 (23.22, 0) | 147.02 (24.01, 0) | 142.03 (23.21, 0) | 150.62 (24.96, 0) |
| Heart rate (bpm) | 74.31 (19.13, 0) | 69.87 (16.94, 0) | 74.41 (19.17, 0) | 68.83 (15.33, 0) | 74.39 (19.14, 0) | 71.52 (20.84, 0) |
| Serum creatinine (mg/dL) | 0.99 (0.46, 0) | 1.06 (0.53, 0) | 0.99 (0.46, 0) | 1.05 (0.5, 0) | 0.99 (0.46, 0) | 1.09 (0.53, 0) |
| High-density lipid (mg/dL) | 50.38 (18.46, 0) | 43.68 (14.02, 0) | 50.58 (18.52, 0) | 43.49 (13.27, 0) | 50.62 (18.56, 0) | 43.89 (14.68, 0) |
| Low-density lipid (mg/dL) | 110.44 (38.16, 0) | 114.79 (38.26, 0) | 110.22 (38.21, 0) | 113.55 (37.04, 0) | 110.12 (38.11, 0) | 117.14 (39.96, 0) |
| GFR Stage (mL/min per 1.73 m2) | ||||||
| <15 | 13 | 20 | 13 | 10 | 12 | 3 |
| 15–<30 | 48 | 36 | 45 | 17 | 47 | 7 |
| 30–<45 | 122 | 158 | 124 | 99 | 122 | 30 |
| 45–<60 | 342 | 366 | 340 | 224 | 334 | 72 |
| 60–<90 | 1680 | 1474 | 1649 | 900 | 1633 | 279 |
| ≥90 | 1512 | 768 | 1469 | 484 | 1461 | 135 |
| Valvular heart disease | 85 | 76 | 71 | 8 | 71 | 4 |
| Max stenosis of the right coronary artery | 14.9 (24.68, 23) | 62.39 (36.29, 609) | 14.27 (24.12, 22) | 61.3 (35.71, 495) | 14.43 (24.48, 21) | 72.88 (32.12, 13) |
| Max stenosis of the left main artery | 4.5 (11.81, 7) | 12.24 (22.67, 307) | 4.41 (11.8, 6) | 5.39 (12.94, 252) | 4.53 (11.96, 5) | 31.63 (31.83, 2) |
| Max stenosis of the left anterior descending artery | 20.07 (25.92, 8) | 72.46 (29.39, 450) | 19.42 (25.27, 5) | 71.66 (28.87, 371) | 19.65 (25.66, 5) | 84.78 (18.69, 4) |
| Max stenosis of the left circumflex artery | 13.74 (23.72, 21) | 57.48 (37.27, 712) | 13.1 (23.06, 20) | 54.19 (37.58, 589) | 13.32 (23.52, 19) | 71.75 (31.18, 8) |
| Max stenosis of the proximal left anterior descending artery | 6.96 (15.17, 8) | 28.5 (35.9, 451) | 6.72 (14.74, 5) | 23.58 (33.86, 371) | 6.88 (15.25, 5) | 45.53 (38.38, 4) |
| Left ventricular ejection fraction (%) | 62.07 (10.59, 844) | 60.32 (10.69, 1416) | 62.11 (10.65, 848) | 61.24 (9.94, 1053) | 62.11 (10.63, 842) | 59.52 (11.3, 86) |
| Coronary dominance | ||||||
| Left | 341 | 167 | 342 | 98 | 338 | 27 |
| Right | 3087 | 2562 | 3011 | 1598 | 2983 | 464 |
| Balanced | 289 | 93 | 287 | 38 | 288 | 35 |
| Number of significantly diseased vessels | ||||||
| Missing | 91 | 94 | 91 | 71 | 89 | 7 |
| None | 3064 | 141 | 3028 | 26 | 2981 | 6 |
| One | 340 | 1421 | 325 | 1137 | 327 | 57 |
| Two | 129 | 646 | 109 | 409 | 115 | 129 |
| Three | 93 | 520 | 87 | 91 | 97 | 327 |
| Mitral regurgitation grade (left ventriculogram) | ||||||
| Missing | 858 | 1424 | 862 | 1057 | 856 | 88 |
| None | 2637 | 1215 | 2575 | 610 | 2547 | 382 |
| I | 143 | 116 | 131 | 46 | 134 | 45 |
| II | 59 | 37 | 54 | 20 | 54 | 11 |
| III | 12 | 12 | 12 | 1 | 12 | 0 |
| IV | 8 | 18 | 6 | 0 | 6 | 0 |
| Aortic valve insufficiency | ||||||
| Missing | 3528 | 2713 | 3460 | 1709 | 3427 | 508 |
| Absent | 123 | 53 | 123 | 16 | 124 | 15 |
| Mild | 24 | 18 | 20 | 2 | 20 | 1 |
| Moderate | 24 | 22 | 21 | 4 | 22 | 2 |
| Severe | 5 | 8 | 5 | 0 | 5 | 0 |
| Trace | 13 | 8 | 11 | 3 | 11 | 0 |
| Aortic valve stenosis | ||||||
| Missing | 3231 | 2584 | 3169 | 1626 | 3146 | 466 |
| Absent | 458 | 202 | 450 | 107 | 443 | 59 |
| Mild (>1.0 cm2) | 19 | 4 | 12 | 1 | 11 | 1 |
| Moderate (0.7–1.0 cm2) | 5 | 12 | 5 | 0 | 5 | 0 |
| Severe (<0.7 cm2) | 4 | 20 | 4 | 0 | 4 | 0 |
| Mitral valve stenosis | ||||||
| Missing | 3650 | 2791 | 3578 | 1726 | 3548 | 521 |
| Absent | 56 | 22 | 53 | 8 | 52 | 4 |
| Mild (>1.5 cm2) | 4 | 3 | 3 | 0 | 3 | 1 |
| Moderate (1.0–1.5 cm2) | 3 | 2 | 3 | 0 | 3 | 0 |
| Severe (<1.0 cm2) | 4 | 4 | 3 | 0 | 3 | 0 |
| Type of cardiac catheterization | ||||||
| Unknown | 8 | 35 | 8 | 26 | 7 | 1 |
| Right Heart Only | 5 | 1 | 5 | 0 | 5 | 0 |
| Left Heart Only | 2722 | 2558 | 2659 | 1644 | 2624 | 502 |
| Right and Left Heart | 982 | 228 | 968 | 64 | 973 | 23 |
| Year of cardiac cath | ||||||
| 1991–1994 | 2 | 6 | 2 | 1 | 2 | 5 |
| 1995–1998 | 698 | 860 | 665 | 492 | 656 | 170 |
| 1999–2002 | 947 | 816 | 909 | 501 | 897 | 153 |
| 2003–2006 | 892 | 594 | 888 | 415 | 882 | 94 |
| 2007–2010 | 676 | 336 | 672 | 195 | 669 | 72 |
| 2011–2013 | 502 | 210 | 504 | 130 | 503 | 32 |
| DSPCI | 1871.03 (1439.18, 3606) | 63.57 (418.21, 722) | 1945.08 (1461.92, 3550) | 0.49 (3.63, 0) | ||
| DSVALVE | 1957.11 (1632.88, 3671) | 450.57 (1149.06, 2638) | ||||
| DSMI | 1907.78 (1545.51, 3643) | 1523.77 (1524.79, 2547) | ||||
| DSCABG | 2110.27 (1701.61, 3624) | 397.05 (1072.4, 1874) | 1924.44 (1649.45, 3550) | 5.18 (8.67, 0) | ||
| DSSTROKE | 2158.53 (1577.75, 3587) | 1642.44 (1800.13, 2508) | ||||
References
- Virani, S.S.; Alonso, A.; Aparicio, H.J.; Benjamin, E.J.; Bittencourt, M.S.; Callaway, C.W.; Carson, A.P.; Chamberlain, A.M.; Cheng, S.; Delling, F.N.; et al. Heart Disease and Stroke Statistics—2021 Update. Circulation 2021, 143, e254–e743. [Google Scholar] [CrossRef] [PubMed]
- Centers for Disease Control and Prevention, National Center for Health Statistics. About Multiple Cause of Death, 1999–2019; CDC WONDER Online Database Website; Centers for Disease Control and Prevention: Atlanta, GA, USA, 2019. [Google Scholar]
- Kern, M.J.; Sorajja, P.; Lim, M.J. Cardiac Catheterization Handbook; Elsevier Health Sciences: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Manda, Y.R.; Baradhi, K.M. Cardiac Catheterization, Risks and Complications. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2019. [Google Scholar]
- Fatima, M.; Pasha, M. Survey of Machine Learning Algorithms for Disease Diagnostic. J. Intell. Learn. Syst. Appl. 2017, 9, 73781. [Google Scholar] [CrossRef]
- Damen, J.A.A.G.; Hooft, L.; Schuit, E.; Debray, T.P.A.; Collins, G.S.; Tzoulaki, I.; Lassale, C.M.; Siontis, G.C.M.; Chiocchia, V.; Roberts, C.; et al. Prediction models for cardiovascular disease risk in the general population: Systematic review. BMJ 2016, 353, i2416. [Google Scholar] [CrossRef]
- Beunza, J.J.; Puertas, E.; García-Ovejero, E.; Villalba, G.; Condes, E.; Koleva, G.; Hurtado, C.; Landecho, M.F. Comparison of machine learning algorithms for clinical event prediction (risk of coronary heart disease). J. Biomed. Inform. 2019, 97, 103257. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.; Lu, A.; Wang, J.; Ma, X.; Zhao, L.; Wu, W.; Du, Z.; Fei, H.; Lin, Q.; Yu, Z.; et al. Using machine learning to predict one-year cardiovascular events in patients with severe dilated cardiomyopathy. Eur. J. Radiol. 2019, 117, 178–183. [Google Scholar] [CrossRef]
- Angraal, S.; Mortazavi, B.J.; Gupta, A.; Khera, R.; Ahmad, T.; Desai, N.R.; Jacoby, D.L.; Masoudi, F.A.; Spertus, J.A.; Krumholz, H.M. Machine Learning Prediction of Mortality and Hospitalization in Heart Failure With Preserved Ejection Fraction. JACC Hear. Fail. 2020, 8, 12–21. [Google Scholar] [CrossRef]
- Mandair, D.; Tiwari, P.; Simon, S.; Colborn, K.L.; Rosenberg, M.A. Prediction of incident myocardial infarction using machine learning applied to harmonized electronic health record data. BMC Med. Inform. Decis. Mak. 2020, 20, 252. [Google Scholar] [CrossRef]
- Suter, T.M.; Ewer, M.S. Cancer drugs and the heart: Importance and management. Eur. Heart J. 2013, 34, 1102–1111. [Google Scholar] [CrossRef]
- Ambale-Venkatesh, B.; Yang, X.; Wu, C.O.; Liu, K.; Gregory Hundley, W.; McClelland, R.; Gomes, A.S.; Folsom, A.R.; Shea, S.; Guallar, E.; et al. Cardiovascular Event Prediction by Machine Learning: The Multi-Ethnic Study of Atherosclerosis. Circ. Res. 2017, 121, 1092–1101. [Google Scholar] [CrossRef]
- Bhatti, N.K.; Karimi Galougahi, K.; Paz, Y.; Nazif, T.; Moses, J.W.; Leon, M.B.; Stone, G.W.; Kirtane, A.J.; Karmpaliotis, D.; Bokhari, S.; et al. Diagnosis and Management of Cardiovascular Disease in Advanced and End-Stage Renal Disease. J. Am. Heart Assoc. 2016, 5, e003648. [Google Scholar] [CrossRef]
- Cho, H.; Lee, J.G.; Kang, S.J.; Kim, W.J.; Choi, S.Y.; Ko, J.; Min, H.S.; Choi, G.H.; Kang, D.Y.; Lee, P.H.; et al. Angiography-based machine learning for predicting fractional flow reserve in intermediate coronary artery lesions. J. Am. Heart Assoc. 2019, 8, e011685. [Google Scholar] [CrossRef] [PubMed]
- Hae, H.; Kang, S.J.; Kim, W.J.; Choi, S.Y.; Lee, J.G.; Bae, Y.; Cho, H.; Yang, D.H.; Kang, J.W.; Lim, T.H.; et al. Machine learning assessment of myocardial ischemia using angiography: Development and retrospective validation. PLoS Med. 2018, 15, e1002693. [Google Scholar] [CrossRef] [PubMed]
- Mathur, P.; Srivastava, S.; Xu, X.; Mehta, J.L. Artificial Intelligence, Machine Learning, and Cardiovascular Disease. Clin. Med. Insights Cardiol. 2020, 14, 1179546820927404. [Google Scholar] [CrossRef] [PubMed]
- Analysis Dataset of Cardiac Catheterization Procedures from the Duke Information System for Cardiovascular Care (DISCC) (“ACATHD”) (DukeCath); VIVLI: Cambridge, MA, USA, 2014. [CrossRef]
- Habib, R.H.; Dimitrova, K.R.; Badour, S.A.; Yammine, M.B.; El-Hage-Sleiman, A.-K.M.; Hoffman, D.M.; Geller, C.M.; Schwann, T.A.; Tranbaugh, R.F. CABG Versus PCI Greater Benefit in Long-Term Outcomes With Multiple Arterial Bypass Grafting. J. Am. Coll. Cardiol. 2015, 66, 1417–1427. [Google Scholar] [CrossRef]
- Taggart, D.P. PCI or CABG in coronary artery disease? Lancet 2009, 373, 1150–1152. [Google Scholar] [CrossRef]
- Hsieh, M.-H.; Lin, S.-Y.; Lin, C.-L.; Hsieh, M.-J.; Hsu, W.-H.; Ju, S.-W.; Lin, C.-C.; Hsu, C.Y.; Kao, C.-H. A fitting machine learning prediction model for short-term mortality following percutaneous catheterization intervention: A nationwide population-based study. Ann. Transl. Med. 2019, 7, 732. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation Between Training and Testing Sets: A Pedagogical Explanation. Dep. Tech. Rep. 2018, 1209, 1–6. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- Strain, W.D.; Paldánius, P.M. Diabetes, cardiovascular disease and the microcirculation. Cardiovasc. Diabetol. 2018, 17, 57. [Google Scholar] [CrossRef]
- Leon, B.M. Diabetes and cardiovascular disease: Epidemiology, biological mechanisms, treatment recommendations and future research. World J. Diabetes 2015, 6, 1246. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Lin, C.H.; Davidson, R.; Dong, C.; Liao, Y. Diagnostic value of 64-slice CT angiography in coronary artery disease: A systematic review. Eur. J. Radiol. 2008, 67, 78–84. [Google Scholar] [CrossRef] [PubMed]
- Mowatt, G.; Cook, J.A.; Hillis, G.S.; Walker, S.; Fraser, C.; Jia, X.; Waugh, N. 64-Slice computed tomography angiography in the diagnosis and assessment of coronary artery disease: Systematic review and meta-analysis. Heart 2008, 94, 1386–1393. [Google Scholar] [CrossRef]
- Cavender, M.A.; Alexander, K.P.; Broderick, S.; Shaw, L.K.; McCants, C.B.; Kempf, J.; Ohman, E.M. Long-term morbidity and mortality among medically managed patients with angina and multivessel coronary artery disease. Am. Heart J. 2009, 158, 933–940. [Google Scholar] [CrossRef] [PubMed]
- Thomas, K.L.; Honeycutt, E.; Shaw, L.K.; Peterson, E.D. Racial differences in long-term survival among patients with coronary artery disease. Am. Heart J. 2010, 160, 744–751. [Google Scholar] [CrossRef] [PubMed]
- Turer, A.T.; Mahaffey, K.W.; Honeycutt, E.; Tuttle, R.H.; Shaw, L.K.; Sketch, M.H.; Smith, P.K.; Califf, R.M.; Alexander, J.H. Influence of body mass index on the efficacy of revascularization in patients with coronary artery disease. J. Thorac. Cardiovasc. Surg. 2009, 137, 1468–1474. [Google Scholar] [CrossRef]
- Manikandan, S. Heart attack prediction system. In Proceedings of the 2017 International Conference on Energy, Communication, Data Analytics and Soft Computing, ICECDS, Chennai, India, 1–2 August 2017. [Google Scholar]
- Layeghian Javan, S.; Sepehri, M.M. A predictive framework in healthcare: Case study on cardiac arrest prediction. Artif. Intell. Med. 2021, 117, 102099. [Google Scholar] [CrossRef]
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can Machine-learning improve cardiovascular risk prediction using routine clinical data? PLoS ONE 2017, 12, e0174944. [Google Scholar] [CrossRef]
- Alaa, A.M.; Bolton, T.; Di Angelantonio, E.; Rudd, J.H.F.; van der Schaar, M. Cardiovascular disease risk prediction using automated machine learning: A prospective study of 423,604 UK Biobank participants. PLoS ONE 2019, 14, e0213653. [Google Scholar] [CrossRef]


| Model | Accuracy (%) | Sensitivity (%) | Specificity (%) | AUROC (%) |
|---|---|---|---|---|
| LDA | 88.13 | 92.20 | 85.05 | 93.67 |
| KNC 1 | 83.03 | 77.53 | 87.20 | 89.53 |
| DTC | 83.58 | 82.00 | 84.78 | 83.39 |
| GNB | 75.90 | 95.68 | 60.89 | 89.15 |
| SVC | 87.31 | 91.35 | 84.24 | 93.87 |
| LR | 88.47 | 89.58 | 87.63 | 93.57 |
| RFC | 89.69 | 93.83 | 86.55 | 95.76 |
| GBC | 89.05 | 91.85 | 86.93 | 95.58 |
| ABC | 88.53 | 89.09 | 88.11 | 94.41 |
| MLP 2 | 87.61 | 87.53 | 87.68 | 94.26 |
| Model | Accuracy (%) | Sensitivity (%) | Specificity (%) | AUROC (%) |
|---|---|---|---|---|
| No-CR | 67.89 | 59.32 | 74.39 | 73.97 |
| CR | 88.90 | 91.92 | 86.61 | 95.37 |
| Model | Accuracy (%) | Sensitivity (%) | Specificity (%) | AUROC (%) |
|---|---|---|---|---|
| LDA | 89.36 | 94.00 | 87.14 | 96.19 |
| KNC 1 | 85.34 | 73.24 | 91.10 | 91.15 |
| DTC | 87.12 | 81.78 | 89.67 | 85.72 |
| GNB | 36.32 | 97.81 | 7.03 | 53.86 |
| SVC | 89.21 | 88.00 | 89.78 | 95.69 |
| LR | 89.62 | 87.20 | 90.77 | 95.76 |
| RFC | 91.40 | 95.62 | 89.40 | 97.46 |
| GBC | 92.07 | 95.50 | 90.44 | 98.02 |
| ABC | 90.36 | 89.39 | 90.82 | 96.91 |
| MLP 2 | 89.58 | 86.62 | 90.99 | 96.10 |
| Model | Accuracy (%) | Sensitivity (%) | Specificity (%) | AUROC (%) |
|---|---|---|---|---|
| No CR | 72.57 | 47.87 | 84.34 | 76.66 |
| CR | 91.63 | 95.62 | 89.73 | 97.93 |
| Model | Accuracy (%) | Sensitivity (%) | Specificity (%) | AUROC (%) |
|---|---|---|---|---|
| LDA | 93.96 | 84.03 | 95.4 | 97.52 |
| KNC 1 | 92.36 | 63.88 | 96.51 | 89.57 |
| DTC | 92.07 | 69.58 | 95.35 | 82.46 |
| GNB | 62.86 | 88.97 | 59.06 | 83.82 |
| SVC | 94.58 | 73.00 | 97.73 | 96.33 |
| LR | 94.73 | 75.67 | 97.51 | 96.86 |
| RFC | 95.31 | 87.83 | 96.40 | 98.21 |
| GBC | 95.45 | 86.31 | 96.79 | 98.33 |
| ABC | 94.83 | 82.51 | 96.62 | 97.68 |
| MLP 2 | 94.58 | 72.24 | 97.84 | 97.05 |
| Model | Accuracy (%) | Sensitivity (%) | Specificity (%) | AUROC (%) |
|---|---|---|---|---|
| No CR | 86.65 | 20.15 | 96.34 | 76.12 |
| CR | 94.49 | 85.17 | 95.84 | 97.73 |
| Model 1 | Accuracy (%) | Sensitivity (%) | Specificity (%) | AUROC (%) |
|---|---|---|---|---|
| Risk-RFC | 88.17 | 89.72 | 86.98 | 91.68 |
| PCI-GBC | 89.21 | 90.20 | 88.74 | 94.16 |
| CABG-GBC | 93.86 | 77.57 | 96.23 | 96.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, G.; Gamage, P.T.; Balasubramanian, V.; Li, J.K.-J.; Subasi, E.; Subasi, M.M.; Kaya, M. Short-Term Risk Estimation and Treatment Planning for Cardiovascular Disease Patients after First Diagnostic Catheterizations with Machine Learning Models. Appl. Sci. 2023, 13, 5191. https://doi.org/10.3390/app13085191
Ye G, Gamage PT, Balasubramanian V, Li JK-J, Subasi E, Subasi MM, Kaya M. Short-Term Risk Estimation and Treatment Planning for Cardiovascular Disease Patients after First Diagnostic Catheterizations with Machine Learning Models. Applied Sciences. 2023; 13(8):5191. https://doi.org/10.3390/app13085191
Chicago/Turabian StyleYe, Guochang, Peshala Thibbotuwawa Gamage, Vignesh Balasubramanian, John K.-J. Li, Ersoy Subasi, Munevver Mine Subasi, and Mehmet Kaya. 2023. "Short-Term Risk Estimation and Treatment Planning for Cardiovascular Disease Patients after First Diagnostic Catheterizations with Machine Learning Models" Applied Sciences 13, no. 8: 5191. https://doi.org/10.3390/app13085191
APA StyleYe, G., Gamage, P. T., Balasubramanian, V., Li, J. K. -J., Subasi, E., Subasi, M. M., & Kaya, M. (2023). Short-Term Risk Estimation and Treatment Planning for Cardiovascular Disease Patients after First Diagnostic Catheterizations with Machine Learning Models. Applied Sciences, 13(8), 5191. https://doi.org/10.3390/app13085191