1. Introduction
Landslides are one of the many common natural disasters in the world [
1,
2]. A frequent occurrence of extreme weather increases the likelihood of landslides. Rapid economic and social development further aggravates the loss of landslide disasters [
3,
4]. Therefore, accurate landslide displacement prediction is becoming increasingly important in order to prevent and mitigate the damage caused by landslides [
5]. In the process of automated real-time monitoring of landslides, data acquisition and transmission are generally performed using different types of sensors and other electronic devices [
6]. Automated monitoring equipment is always in the open-air environment, and most of them inevitably suffer from tear, aging, power loss and other phenomena, all of which can lead to missing monitoring data. In addition, most landslide disasters are located in a relatively harsh geological environment, such as heavy rainfall, hail, dense fog, electromagnetic interference, etc., and the installation and deployment of geological hazard monitoring equipment in open fields will inevitably be affected by the abovementioned harsh environment. Randomness or prolonged interruptions in the operation of the monitoring device can cause the monitoring device to fail to properly send monitoring data to the server, which leads to the problem of missing monitoring time series in the server. Time series forecasting is a valid basis for making accurate discriminations. To enhance the accuracy of landslide prediction, it is necessary to construct a corresponding accurate data completion method.
For the problem of completing and predicting missing landslide data, most traditional time series models have focused on models such as regression analysis and exponential smoothing. The problem of incompleteness for missing time series data can be broadly classified as either deletion or padding. Data deletion is used as anomalous data to remove some objective abnormal monitoring data, which is primarily used for anomaly detection and feature analysis, while filling is utilized to find the long-term time series change pattern of monitoring data and to supplement the missing monitoring data. The main methods include missing value filling algorithm based on nearest neighbor method, cyclic neural network, random forest and matrix decomposition, but more data are required for machine learning training [
7,
8]. Statistical filling is more effective for data series with less dimensions that can establish a maximum model, provided that the relationship between missing eigenvalues and existing eigenvalues can be established through observation. The main methods of machine learning include missing value filling algorithm based on the nearest neighbor method, cyclic neural network, and matrix decomposition. Matrix decomposition can effectively explore the correlation between different time series for different dimensions of long time series problems. The matrix decomposition method is used to learn the overall characteristics of the time series matrix, which can be used to approximate the matrix with time characteristics in low-rank, and then complete the missing data [
9].
Large-scale time series data are always accompanied by the missing problem. Therefore, the tensor completion method has been introduced into this field to complement the traditional data completion method based on probability and statistics [
10,
11,
12]. The data completion scheme based on simple quantitative statistics has a relatively simple and efficient processing effect for small datasets and simple regression models, but it is not feasible for massive data in the era of data explosion. Modern research not only has many kinds of data variables and long time series, but also requires fast processing speed, high universality and portability. Multiple variables and long time series can better describe the complex causal relationship between each other [
13,
14]. Now, neural network technology is often used to deal with the above situations and delete the missing data in order to form a complex intelligent model, but it is not the best solution for missing data because deletion may strengthen or weaken the connection degree of a causal relationship. Based on this, scholars have explored the application of tensor decomposition technology to data completion in multivariate long time series, trying to improve the resolution speed and data missing problems.
Recent studies have found that low-rank matrices have certain advantages in the analysis of multivariate long time series data [
11,
12], including the sequence tensor completion method [
15]. The sequence tensor complement restores the potential tensor from the sampling structure of the time series, allocates the position of the missing items as needed, seamlessly integrates the future value of the time series into the framework of the missing data and improves the data completion accuracy [
15]. The low-rank matrix completion method performs singular spectrum analysis and singular value decomposition on the time series in order to complete the low-rank completion of the missing data of the time series, although its calculation is large [
16]. Therefore, by adding a time dimension to transform the status time series into a high-dimensional tensor, the cost of computing complexity is better solved. This is also in line with the law of human activities, both short and long term activities, so there are studies using tensors (sensors × 1 day × 24 h) which indicate the above activity mode [
17,
18]. The dependency between sensors is preserved, providing a new feasible scheme for capturing local and global time patterns [
16]. More scholars have combined the autoregressive moving average model with the tensor model to propose the low-rank matrix autoregressive tensor completion model and have achieved good results in the completion and prediction of financial time series data [
19].
The mean-based low-rank autoregressive tensor completion mainly includes completing low-rank matrix decomposition/tensor completion and constructing time series autoregressive models, as well as processing the missing data with the neighboring data mean instead of zero before the operation. The low-rank matrix completion model uses the underlying low-rank structure to recover incomplete matrices (assuming that the long-term landslide data sequence is incomplete) [
20]. Considering that the deformation displacement of landslide has a great correlation with the previous deformation, the autoregressive model is constructed to represent the deformation law of landslide displacement with time. The autoregressive regularizer is introduced in the low-rank matrix decomposition to characterize the temporal dynamics in landslide displacement deformation, and the learned autoregressive regularizer is implemented to predict the temporal factor matrix, thus realizing the landslide displacement monitoring data completion and predictive modeling [
12].
The purpose of this study is to establish a new method for completing and predicting landslide displacement data based on MLATC. In this paper, the causes of data loss of landslide displacement are analyzed. Taking the Shuizhuyuan landslide in the Three Gorges Reservoir area as an example, the data completion and prediction algorithm are designed by using MLATC. Then, the landslide displacement data are divided into training set and test set, and the random missing and non-random missing are selected for corresponding data completion and prediction. The designed model can achieve an accurate completion and prediction of landslide displacement. Finally, a comparative analysis with existing models verifies the effectiveness of the model.
3. Case Study
3.1. Experimental Dataset
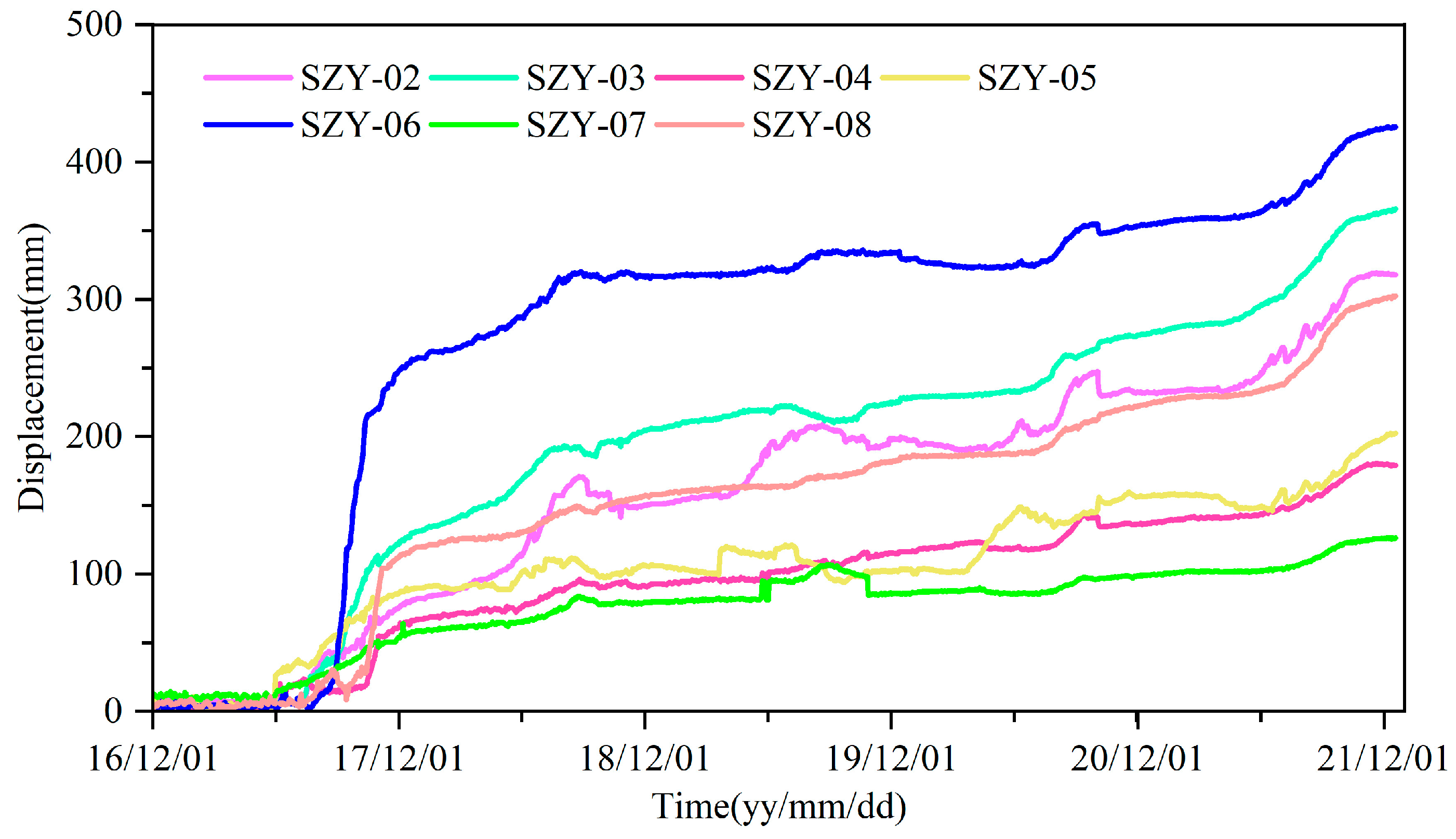
The displacement monitoring data of the Shuizhuyuan landslide in the Three Gorges Reservoir area is selected as the time series’ experimental dataset of this study. This time series is collected from seven GNSS monitoring sensors at the Shuizhuyuan landslide. The time interval is from 15 July 2017 to 1 December 2021, with a total of 1600 days. The data monitoring cycle is to obtain one monitoring data at the site every day, so the tensor size of the constructed dataset is 7
1600
1 (sensors
time points
day) tensor structure. The monitoring data are shown in
Figure 3.
3.2. Missing Data Processing for Time Series
In order to objectively describe the validity of the prediction model, two different data missing processing methods, random and non-random, are used to carry out certain data missing processes on the original time series dataset of landslides by combining the characteristics and main types of missing landslide monitoring data.
Random missing (RM): Random missing indicates that the landslide monitoring equipment has sporadic and random data loss in the operation process. The whole time series is divided according to the proportion of random missing data, with 5%, 10%, 20% and 40% set, respectively, representing different scales and levels of data loss of monitoring equipment.
Non-random missing (NM): Non-random missing means that the landslide monitoring equipment has regular equipment failure or regular network interruption during operation. The data missing is also simulated according to 5%, 10%, 20% and 40% and compared with random missing.
The original spatiotemporal landslide displacement dataset is artificially treated with missing data, and the effectiveness of different models in completing and predicting the missing data can be objectively evaluated by two different treatments, random as well as non-random. For landslide disasters with relatively complex genetic mechanisms, there must be certain trend characteristics and a correlation between different sensors on the landslide. Therefore, better data recovery and prediction for missing datasets after non-random missing processing is an important indicator of this model.
Shuizhuyuan landslide is currently in the mean-slow deformation, and the first 1300 days are selected as the training set of the time series, and the last 300 days are selected as the test set. The and are used to test the accuracy and precision of the algorithm model in terms of prediction. Moreover, the MLATC model is compared with the high-accuracy low-rank tensor completion (HALRTC) and temporal regularized matrix factorization (TRMF) methods. The completion and prediction results with a smaller MAPE and RMSE are considered to be better.
3.3. Data Completion and Analysis
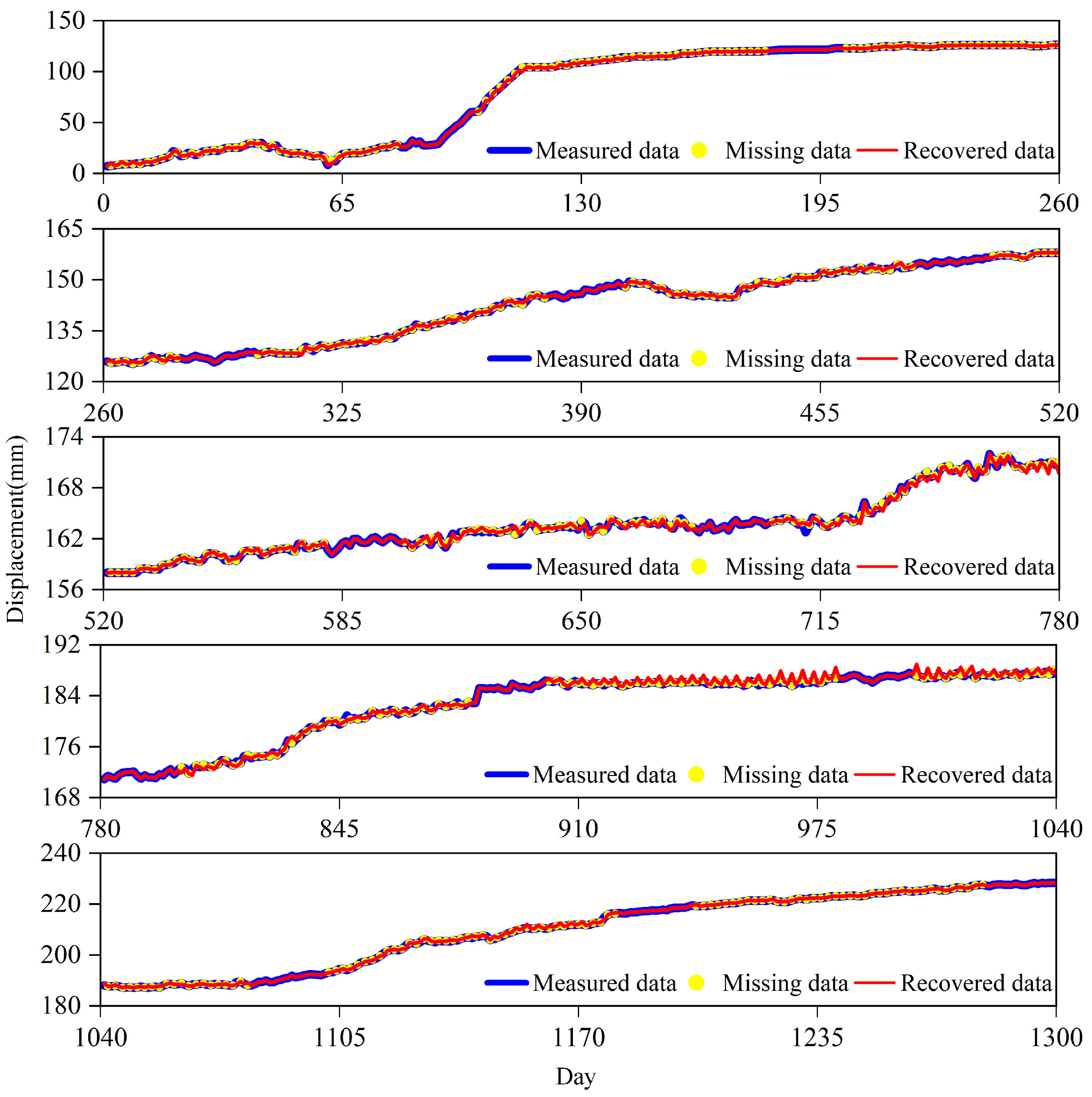
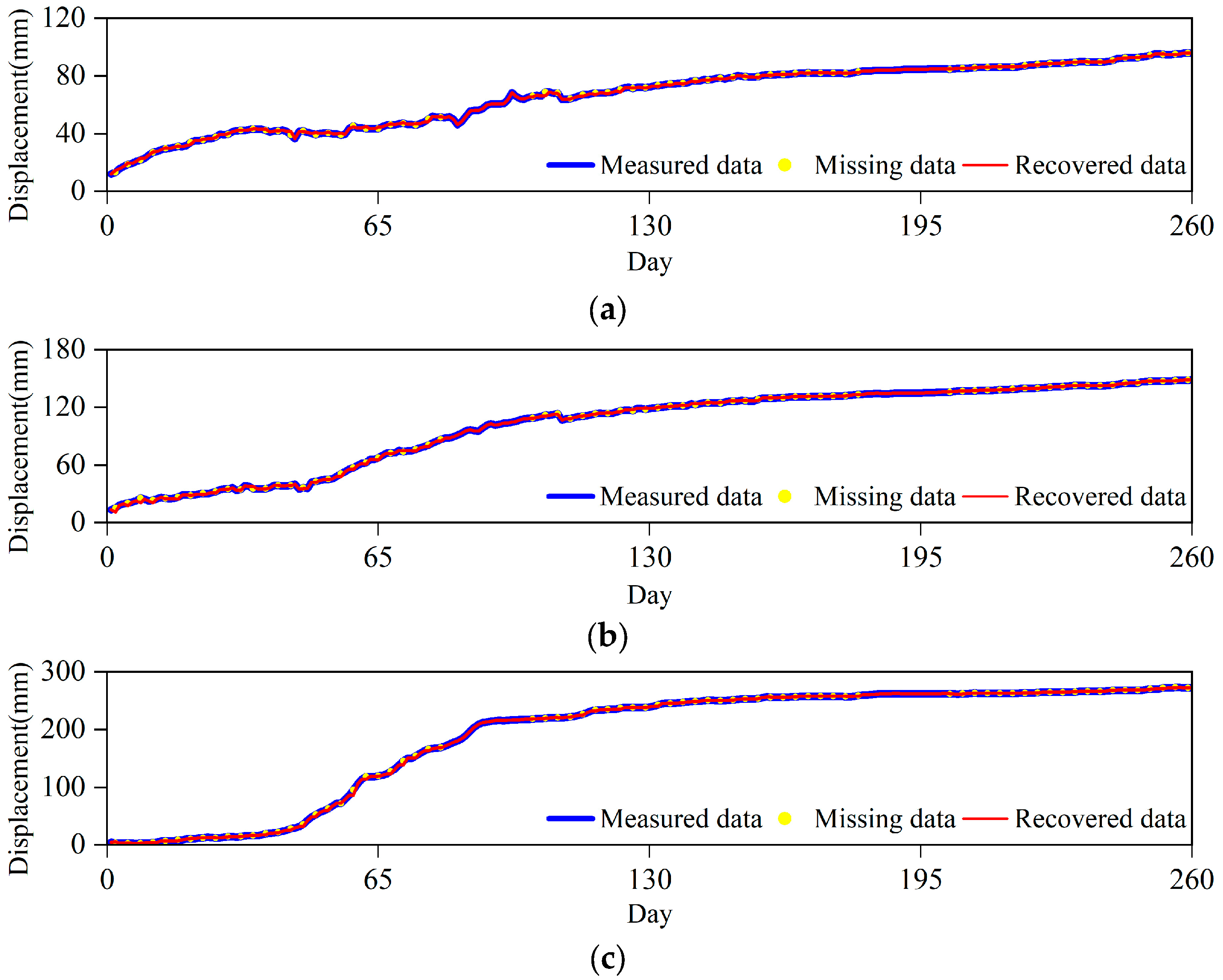
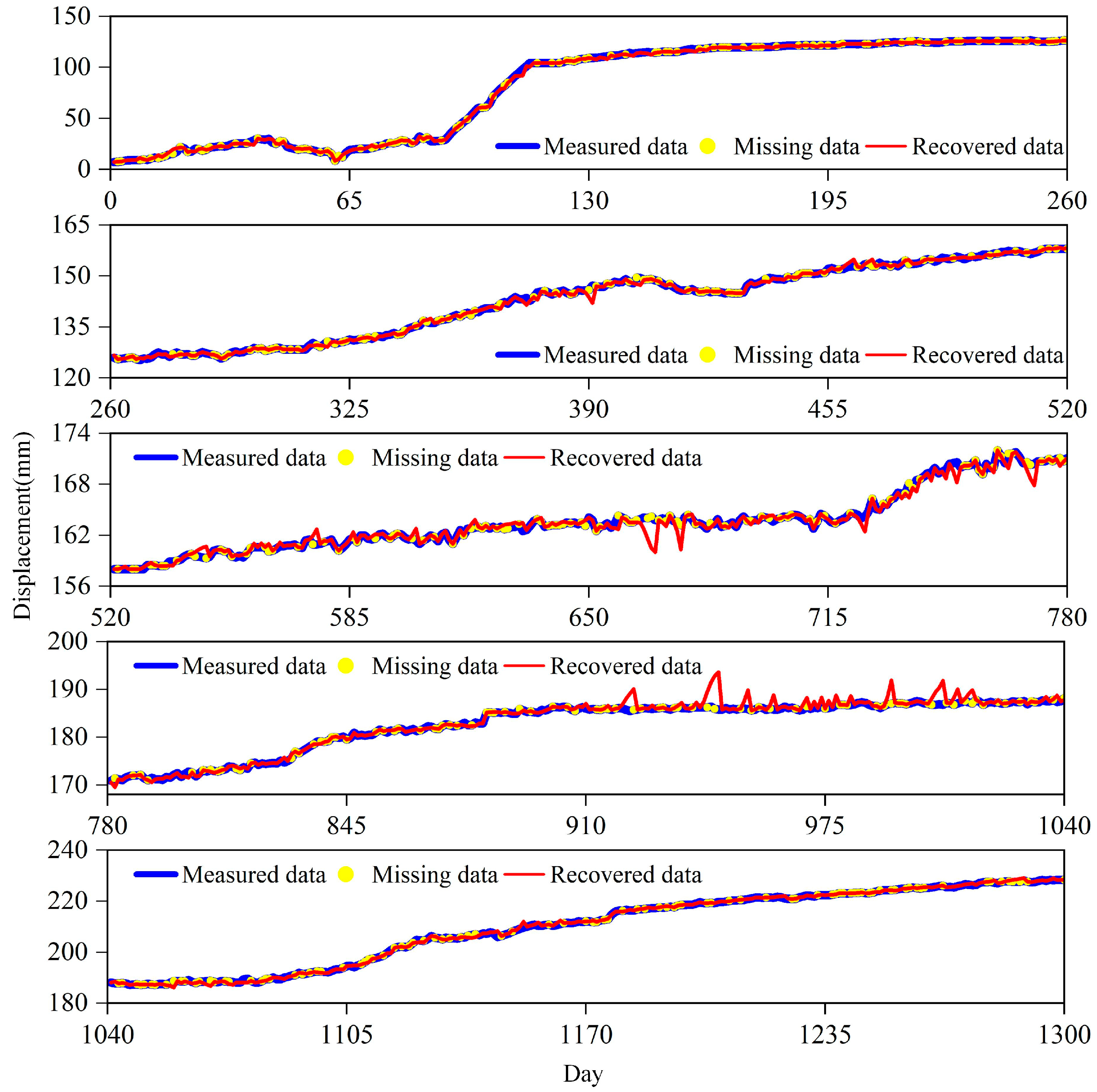
The experimental results of four sensors numbered SZY-02, SZY-03, SZY-06 and SZY-08 are used as examples to introduce the effect of landslide monitoring data completion. After NM40% processing of the dataset of Shuizhuyuan landslide, the data completion effect of the completed training set of SZY-08 is shown in
Figure 4. In
Figure 4, the blue curve represents the measured data, the yellow dots represent the missing data, the red curve represents the recovered data,
X-axis 0–260, 260–520, 520–780, 780–1040, 1040–1300 represents data recorded for each day and Y-axis is the displacement data. Considering the large amount of data for each sensor, only SZY-08 shows the complementary results for the entire time series, and the other sensors are the complementary results for the first 260 days.
Figure 5 shows the complementary effect of the other sensors for the first 260 days.
As can be seen in
Figure 4 and
Figure 5, in the absence of raw landslide displacement data for many consecutive days, the data have been completely processed into missing data, which is challenging for tensor completion. Missing data for several consecutive days has lost the correlation and trend characteristic information between displacement data. The prediction results show that the MLATC model still achieves a very good complementary effect, which is essentially consistent with the original displacement data and achieves a good effective data recovery in some completely missing data days. This is very helpful to analyze the deformation law and deformation trend of the landslide, and also to provide data reference for understanding the relationship between different deformation areas of the landslide.
Table 1 shows the evaluation metrics for data completion in the non-random missing case. The results in
Table 1 show that the MLATC model has the best MAPE and RMSE for four different scenarios of NM5%, NM10%, NM20% and NM40%, indicating that the MLATC model has a greater improvement in data recovery performance compared to the HALRTC and TRMF models.
From
Table 1, it can be concluded that the MLATC model is better than the HALRTC and TRMF models in terms of completion effect, indicating that the tensor autoregressive kernel parametrization can effectively replace the rank function, which enables the low-rank tensor completion model to obtain a more accurate completion effect. In addition, the MLATC model introduces an autoregressive norm on the basis of the HALRTC model, which can make full use of the structural correlation and local trend feature information between the high-dimensional multivariate time series data, as well as more clearly correlate the multivariate time series data, which also proves that the addition of the autoregressive norm can further improve the complementary performance and accuracy of the model in the low-rank tensor complementary structure. Since the tensor structure well maintains the structural information of the spatiotemporal data in the time dimension and exploits the correlation between the daily displacements of different sensors in the time series, the tensor completion results of the MLATC model are better than those of TRMF in the matrix form. The experimental results with different missing ratios simultaneously verify this inference and confirm that effective completion and rolling prediction of displacement monitoring data can be achieved by using global time series datasets. After analyzing the reasons, the TRMF model only analyzes and calculates the matrix structure and does not use the time domain smoothness of multivariate time series and the potential correlation information between the series in the time and space dimensions. MLATC and HALRTC both use the tensor structure to complete the time series prediction through the method of quantitative completion. In particular, the MLATC model introduces the autoregressive norm, which not only preserves the structural information of the original time series through the tensor structure, but also makes full use of the correlation and trend characteristic information between the time series.
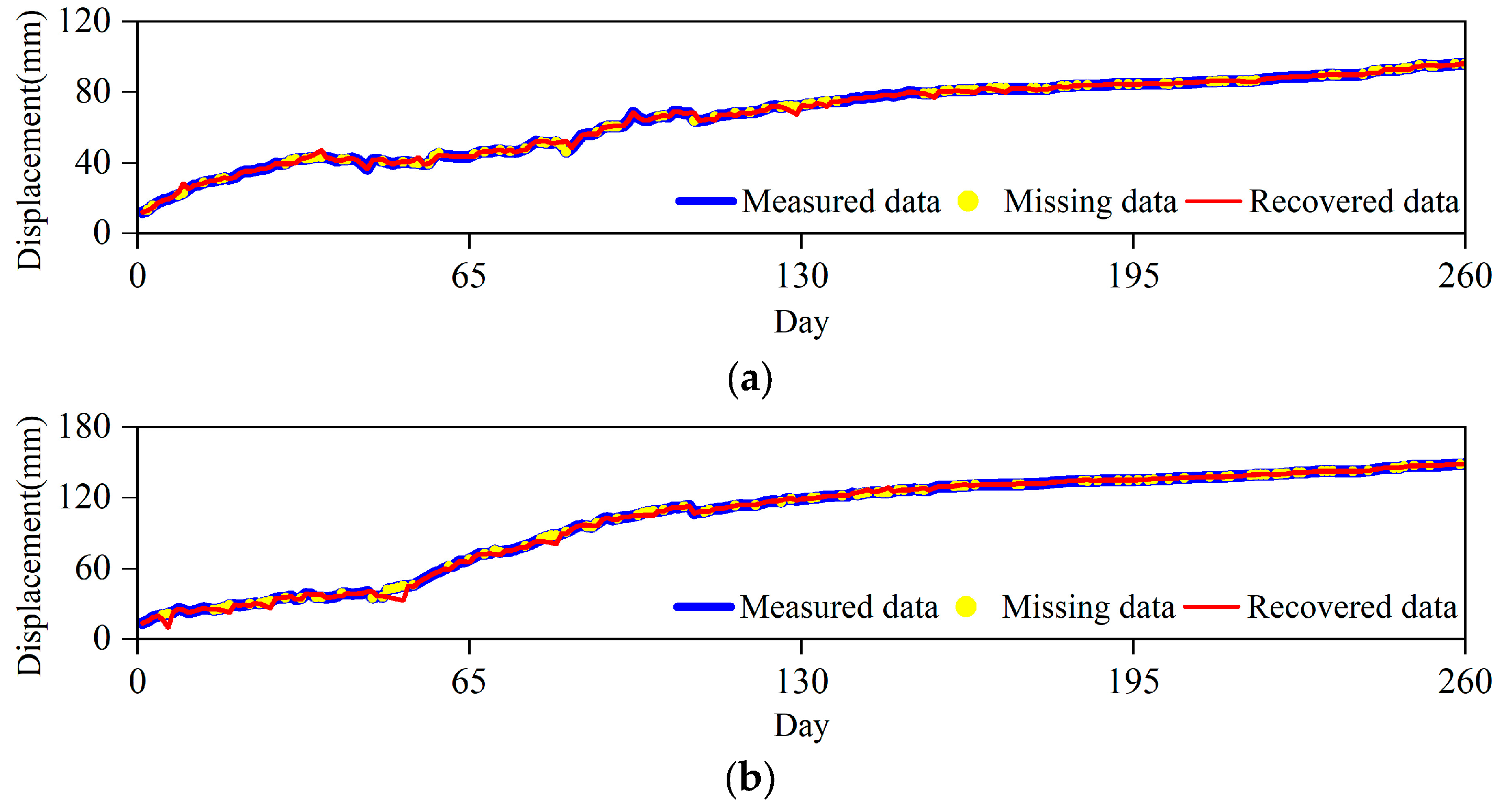
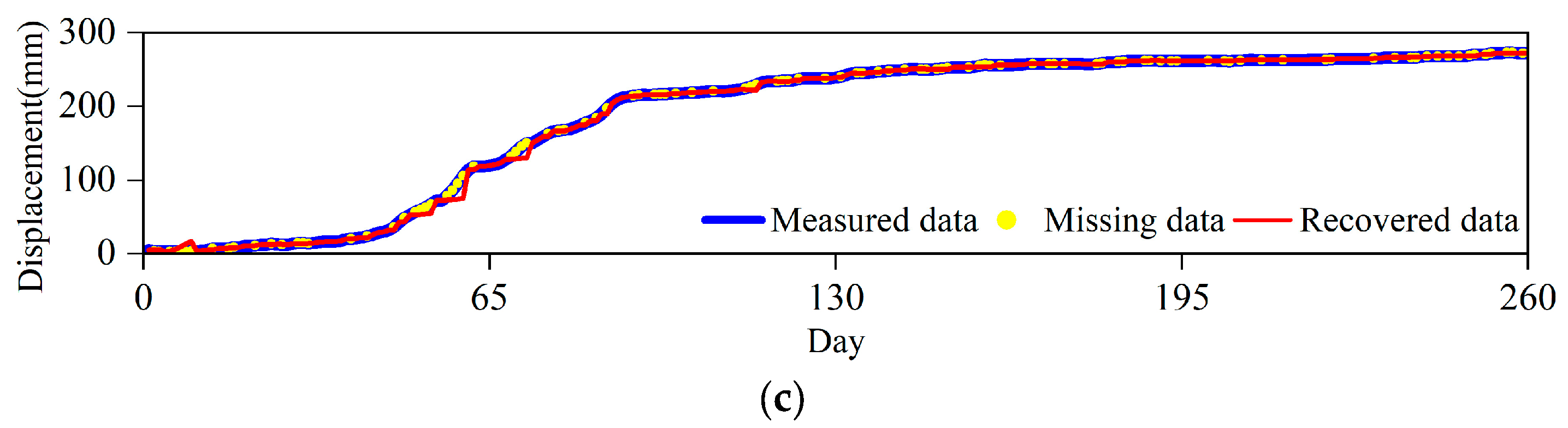
Similarly, the experimental results of the four sensors numbered SZY-08, SZY-02, SZY-03 and SZY-06 are shown in
Figure 6 and
Figure 7 after RM 40% processing of the dataset of the Shuizhuyuan landslide; the data completion performance are shown in
Table 2. The prediction model has a very good recovery effect on missing data and shows a better data fit in terms of time series trend prediction.
3.4. Data Prediction and Analysis
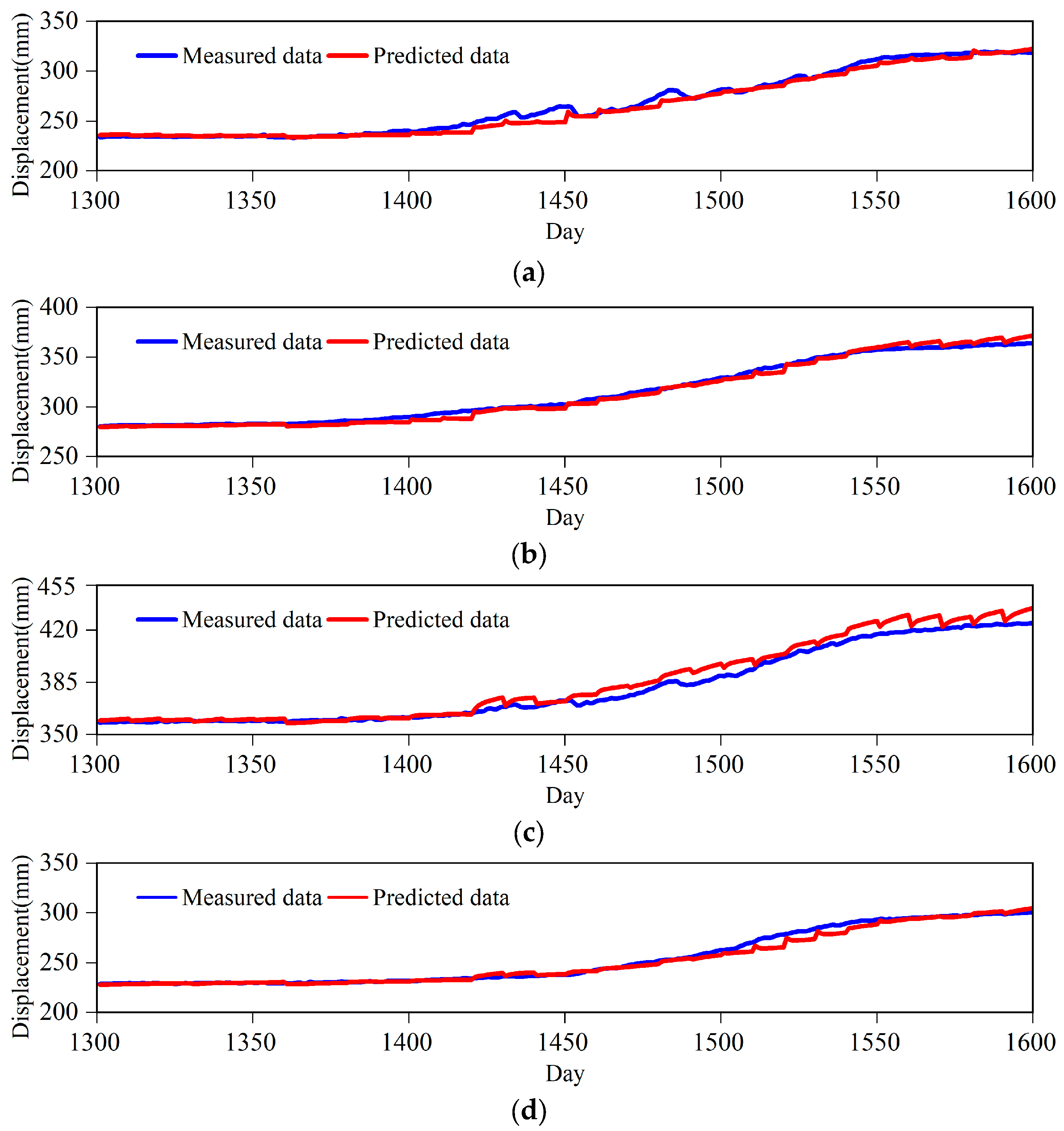
In the case of random missing, the time series of the Shuizhuyuan landslide is predicted for 300 days after data missing processing is performed with a missing ratio of 40%. The time series of four sensors numbered SZY-02, SZY-03, SZY-06 and SZY-08 are analyzed separately, and the prediction results are shown in
Figure 8. The analysis shows that the prediction results are ultimately consistent with the original displacement data in the case of the 40% missing data ratio. The MLATC model realizes well the deformation trend feature fitting of displacement, and effectively predicts the displacement data.
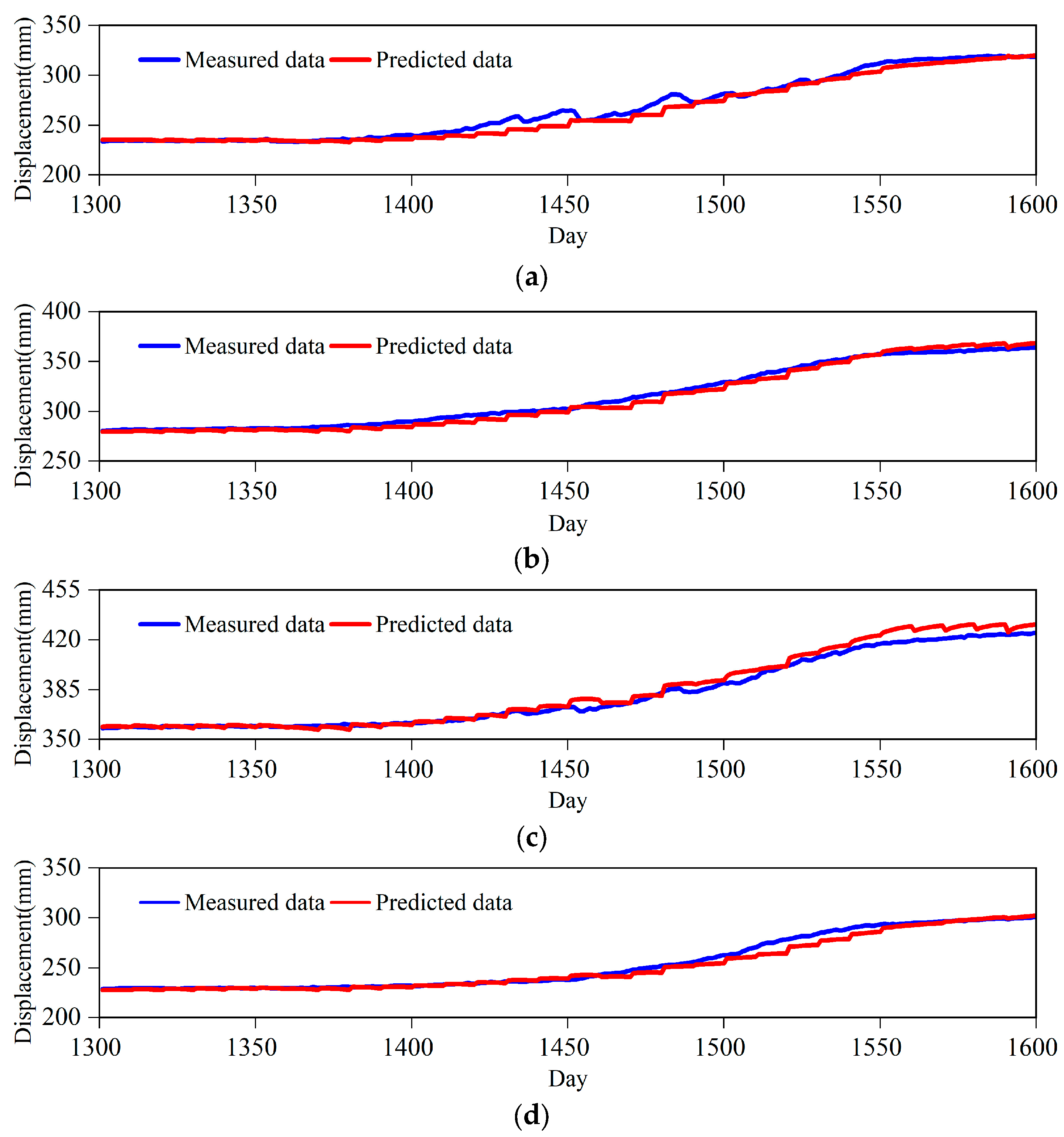
Similarly, after processing the dataset of the Shuizhuyuan landslide with 40% non-random missing, the data completion effect is shown in
Figure 9. The prediction results of MLATC model are also ultimately close to the original displacement data. Although there are some fluctuations in the prediction data, the overall effective fitting of displacement is still achieved.
The prediction effect of MLATC model under random and non-random missing is shown in
Table 3 and
Table 4.
By analyzing the prediction results of each model, it can be proven that the prediction accuracy of the time series model is effectively improved after converting the original time series into a tensor structure in this method. The prediction accuracy of both HALRTC model and MLATC model has improved significantly over the prediction accuracy of TRMF. This indicates that although the TRMF model captures the global consistency of the time series, the model mainly acts on the latent layer matrix data, which may cause the local trend feature information between different sensors to be ignored, thus affecting the prediction accuracy. Due to the intervention of the autoregressive norm, the prediction of HALRTC and MLATC models is significantly better than that of TRMF model, and the MAPE and RMSE accuracy of the models are higher. This demonstrates that the spatiotemporal monitoring data between displacement sensors in different areas of the landslide are utilized under the framework of tensor complementary structure, and the deformation law characteristics of short-term correlation and long-term deformation consistency in the inherent deformation process of the landslide are fully considered.
4. Discussion
Affected by the complex environment in the field, there will be missing data in the process of landslide monitoring, which will affect the accurate analysis of landslide displacement. In landslide disaster monitoring, landslide displacement deformation is relatively complex, and the displacement changes of each deformation area on the landslide are not the same. From the analysis of landslide local deformation characteristics, there is a certain correlation between the daily displacement deformation of different monitoring points. In addition, landslide displacement is a continuous cumulative process, and the landslide displacement occurring in the preceding period will have a certain influence on the landslide displacement occurring subsequently. Therefore, in order to better realize landslide data completion and prediction, a novel model based on MLATC method is proposed, and the RM and NM cases are designed, respectively, so as to verify the validity and reliability of the designed model. In addition, from the construction of the model, the initial time series matrix is converted into a third-order tensor structure. Under the assumption that the time series data satisfy approximate low-rankness, the time series completion and prediction problem is transformed into low-rank tensor completion and prediction. The tensor-based completion method fully considers the time series of landslide displacement data, which not only preserves the correlation between different displacements, but also better fits the landslide displacement deformation characteristics, making the displacement completion more accurate.
To verify the effectiveness of the algorithm, a comparative analysis with the existing RTMF and HALRTC models was performed. The MAPE and RMSE of the MLATC model are 0.9066, 0.9196 and 0.7676, 0.9880 for the NM5% and RM5% data completion, respectively. Similarly, the MAPE and RMSE for NM5% and RM5% data prediction are 1.1079, 3.6676 and 1.1084, 3.6774, respectively. The analysis results show that under the conditions of 5%, 10%, 20% and 40% missing data, the data completion and prediction effects of the MLATC model are better than those of other models, which also confirms the significant data completion and prediction effects of the MLATC model. In this study, the completion and prediction model were constructed by considering the intrinsic correlation between landslide displacement data and using the low-rankness of the completion tensor. Data completion is an iterative calculation of the landslide displacement time series based on the entire original data. In order to verify the effectiveness of the data completion model, random and non-random data missing cases are designed, and time series prediction is based on the predicted experimental data as the missing value, which also belongs to a special case of missing data. By default, this part of the experimental data is not involved in iterative calculations. Therefore, the data prediction for time series is the same as the method used for data completion. The model is implemented in a rolling prediction method with cyclic and iterative computation, which leads to a loss in the amount of data in the prediction case. The MAPE and RMSE values of NM and RM also show that the prediction effect of the MLATC model is lower than that of data completion, but both can achieve satisfactory results, which are more in line with the actual needs of landslide monitoring.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}