
Improving Named Entity Recognition for Social Media with Data Augmentation


Abstract
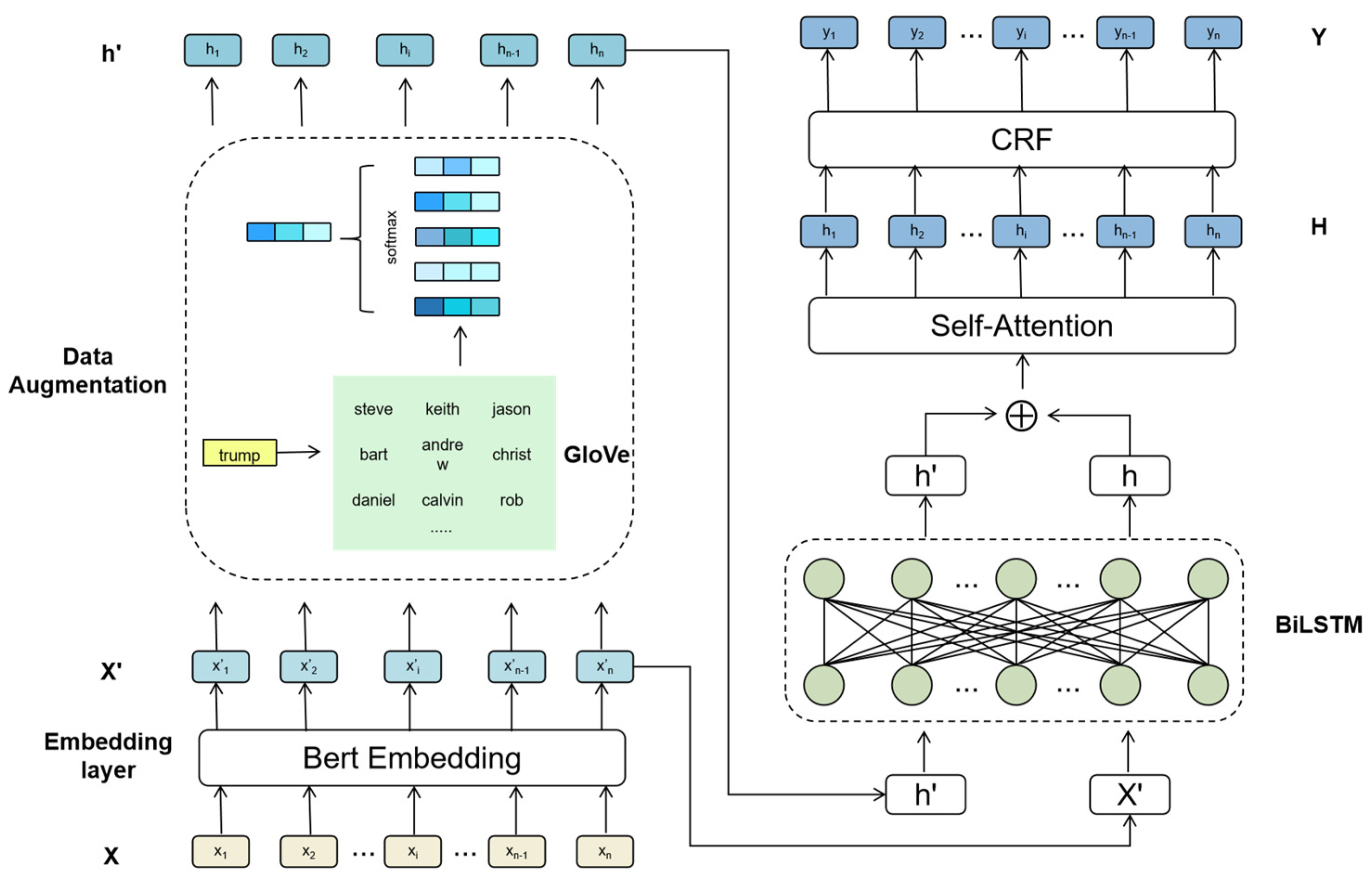
:1. Introduction
- We apply data augmentation techniques to social media NER, which effectively address the challenges of data sparsity and category imbalance. Experimental results demonstrate that the incorporation of data augmentation can significantly improve entity recognition performance and enhance the generalization and robustness of the model.
- In this paper, the attention mechanism is integrated into the Bi-LSTM model, which assigns weights to different words use the selection type. This enables the model to leverage contextual semantic associations and effectively address the challenges associated with acquiring local features.
- We conducted extensive experiments on three benchmark datasets for social media NER. The results demonstrate that our method outperforms other approaches and achieves outstanding performance on social media NER benchmark datasets.
2. Related Work
2.1. Named Entity Recognition
2.2. Data Augmentation
3. Method
3.1. BERT
3.2. Data Augmentation
3.3. Bi-LSTM
3.4. Tagging
4. Experimental and Analysis
4.1. Set
4.2. Baseline
- Bi-LSTM-CRF [14] uses a bi-directional LSTM (Bi-LSTM) to model the language and obtain both left-to-right and right-to-left sentence encodings. This enables the model to capture the context of a word from both directions. Then, a Conditional Random Field (CRF) layer is added to capture the dependencies between the tags and make predictions based on the entire sentence.
- BERT [12]. BERT is a language model that is specifically designed for pre-training deep bidirectional representations from unlabeled text. It does so by conditioning on both left and right contexts in all layers, making it highly effective in capturing contextual information in natural language processing tasks.
- XLNET [22] is an autoregressive model that implements bidirectional contextual information by per-training language models. It predicts the possible words at a certain position by randomly arranging the input sequence and then trains a contextualized word vector with context.
- AESINER [24] improves entity recognition by leveraging syntactic information or semantically relevant texts.
- InferNER [25] is a method designed for Named Entity Recognition (NER) in short texts. It utilizes word-, character-, and sentence-level information without relying on external sources. Additionally, it can incorporate visual information and includes an attention component that computes attention weight probabilities over textual and text-relevant visual contexts separately.
- HGN [26]. HGN obtains more local features and location information through multi-window loops and combines global information and multiple local features to predict entity labels.
4.3. Results and Analyses
4.4. Ablation Study
- DANER. DANER is the proposed method.
- DANER without attention. The attention mechanism is removed, and the entities are labeled by CRF after direct vector fusion.
- DANER without weight word. In data augmentation, pre-trained vectors are not weighted, and data augmentation and semantic transformation are performed directly on the embedded vectors.
- DANER without data augmentation. The model with data augmentation removed is degraded to BERT + Bi-LSTM + CRF neural network model.
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Humphreys, L. Populating Legal Ontologies Using Information Extraction Based on Semantic Role Labeling and Text Similarity. Ph.D. Thesis, University of Luxembourg, Luxembourg, 2016. [Google Scholar]
- Babych, B.; Hartley, A. Improving machine translation quality with automatic named entity recognition. In Proceedings of the 7th International EAMT Workshop on MT and Other Language Technology Tools, Improving MT through Other Language Technology Tools, Resource and Tools for Building MT at EACL 2003, Budapest, Hungary, 13 April 2003; pp. 1–8. [Google Scholar]
- Pang, L.; Lan, Y.; Guo, J.; Xu, J.; Su, L.; Cheng, X. Has-qa: Hierarchical answer spans model for open-domain question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 6875–6882. [Google Scholar]
- Ritter, A.; Clark, S.; Etzioni, O. Named entity recognition in tweets: An experimental study. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 1524–1534. [Google Scholar]
- Peng, N.; Dredze, M. Named entity recognition for chinese social media with jointly trained embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 548–554. [Google Scholar]
- Aguilar, G.; Maharjan, S.; López-Monroy, A.P.; Solorio, T. A multi-task approach for named entity recognition in social media data. arXiv 2019, arXiv:1906.04135. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Advances in Neural Information Processing Systems; National Science Foundation: Alexandria, VA, USA, 2015; Volume 28. [Google Scholar]
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Coulombe, C. Text data augmentation made simple by leveraging nlp cloud apis. arXiv 2018, arXiv:1812.04718. [Google Scholar]
- Wang, W.Y.; Yang, D. That’s so annoying!!!: A lexical and frame-semantic embedding based data augmentation approach to automatic categorization of annoying behaviors using# petpeeve tweets. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2557–2563. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. Tinybert: Distilling bert for natural language understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Zhou, G.; Su, J. Named entity recognition using an HMM-based chunk tagger. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 473–480. [Google Scholar]
- Ratinov, L.; Roth, D. Design challenges and misconceptions in named entity recognition. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL-2009), Boulder, Colorado, 4–5 June 2009; pp. 147–155. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Ma, X.; Hovy, E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual string embeddings for sequence labeling. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1638–1649. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in Neural Information Processing Systems; National Science Foundation: Alexandria, VA, USA, 2019; Volume 32. [Google Scholar]
- Ethayarajh, K. How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. arXiv 2019, arXiv:1909.00512. [Google Scholar]
- Nie, Y.; Tian, Y.; Song, Y.; Ao, X.; Wan, X. Improving named entity recognition with attentive ensemble of syntactic information. arXiv 2020, arXiv:2010.15466. [Google Scholar]
- Shahzad, M.; Amin, A.; Esteves, D.; Ngomo, A.-C.N. InferNER: An attentive model leveraging the sentence-level information for Named Entity Recognition in Microblogs. In Proceedings of the The International FLAIRS Conference Proceedings, North Miami Beach, FL, USA, 17–19 May 2021; Volume 34. [Google Scholar]
- Hu, J.; Shen, Y.; Liu, Y.; Wan, X.; Chang, T.-H. Hero-Gang Neural Model For Named Entity Recognition. arXiv 2022, arXiv:2205.07177. [Google Scholar]
- Liu, S.; Lee, K.; Lee, I. Document-level multi-topic sentiment classification of email data with bilstm and data augmentation. Knowl.-Based Syst. 2020, 197, 105918. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Zettlemoyer, L.; Yih, W.-T. Dissecting contextual word embeddings: Architecture and representation. arXiv 2018, arXiv:1808.08949. [Google Scholar]
- Strauss, B.; Toma, B.; Ritter, A.; De Marneffe, M.-C.; Xu, W. Results of the wnut16 named entity recognition shared task. In Proceedings of the 2nd Workshop on Noisy User-Generated Text (WNUT), Osaka, Japan, 11 December 2016; pp. 138–144. [Google Scholar]
- Derczynski, L.; Nichols, E.; Van Erp, M.; Limsopatham, N. Results of the WNUT2017 shared task on novel and emerging entity recognition. In Proceedings of the 3rd Workshop on Noisy User-Generated Text, Copenhagen, Denmark, 7 September 2017; pp. 140–147. [Google Scholar]
- Pradhan, S.; Moschitti, A.; Xue, N.; Ng, H.T.; Björkelund, A.; Uryupina, O.; Zhang, Y.; Zhong, Z. Towards robust linguistic analysis using ontonotes. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning, Sofia, Bulgaria, 8–9 August 2013; pp. 143–152. [Google Scholar]


{kind=link}
| Dataset | NE Types | Train | Dev | Test | |
|---|---|---|---|---|---|
| WN16 | 10 | Se. | 2.4 K | 1.0 K | 3.9 K |
| NE. | 1.5 K | 0.7 K | 3.5 K | ||
| WN17 | 6 | Se. | 3.4 K | 1.0 K | 1.3 K |
| NE. | 2.0 K | 0.8 K | 1.1 K | ||
| ON5e | 18 | Se. | 59.9 K | 8.5 K | 8.3 K |
| NE. | 81.8 K | 11.1 K | 11.3 K |
| Methods | WN16 | WN17 | ON5e | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| Bi-LSTM-CRF | - | - | - | - | - | - | 86.04 | 86.53 | 86.28 |
| BERT | - | 49.02 | 54.36 | - | 46.73 | 49.52 | - | - | 89.6 |
| XLNET | 55.94 | 57.46 | 56.69 | 58.68 | 49.18 | 53.51 | 89.72 | 91.05 | 90.38 |
| AESINER | - | - | 55.14 | - | - | 50.68 | - | - | 90.32 |
| IfterNER | - | - | - | - | - | 50.52 | - | - | - |
| HGN | 59.74 | 59.26 | 59.50 | 62.49 | 53.10 | 57.41 | 90.29 | 91.56 | 90.92 |
| Ours | 58.37 | 65.23 | 61.61 | 58.11 | 68.89 | 63.04 | 90.42 | 91.65 | 91.03 |
| Attention | Weight Word | DA | F1 |
|---|---|---|---|
| √ | √ | √ | 61.61 |
| × | √ | √ | 60.73 |
| √ | × | √ | 58.36 |
| × | × | √ | 56.83 |
| √ | × | × | 55.62 |
| × | × | × | 54.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Cui, X. Improving Named Entity Recognition for Social Media with Data Augmentation. Appl. Sci. 2023, 13, 5360. https://doi.org/10.3390/app13095360
Liu W, Cui X. Improving Named Entity Recognition for Social Media with Data Augmentation. Applied Sciences. 2023; 13(9):5360. https://doi.org/10.3390/app13095360
Chicago/Turabian StyleLiu, Wenzhong, and Xiaohui Cui. 2023. "Improving Named Entity Recognition for Social Media with Data Augmentation" Applied Sciences 13, no. 9: 5360. https://doi.org/10.3390/app13095360
APA StyleLiu, W., & Cui, X. (2023). Improving Named Entity Recognition for Social Media with Data Augmentation. Applied Sciences, 13(9), 5360. https://doi.org/10.3390/app13095360