
RMFNet: Redetection Multimodal Fusion Network for RGBT Tracking


Abstract
:1. Introduction
- We propose an RGBT tracking network: the Redetection Multimodal Fusion Network (RMFNet), which contains two types of fusion, medium-term feature-level and late-term decision-level fusion, and can be divided into three branches, visible, thermal infrared, and fusion, and can fully utilize the complementarity and correlation of multimodal information to achieve robust RGBT tracking.
- We have designed an ECA attention-based multimodal feature fusion module that adaptively computes two modalities’ reliability and performs a weighted fusion of multimodal features to obtain a more favourable feature representation.
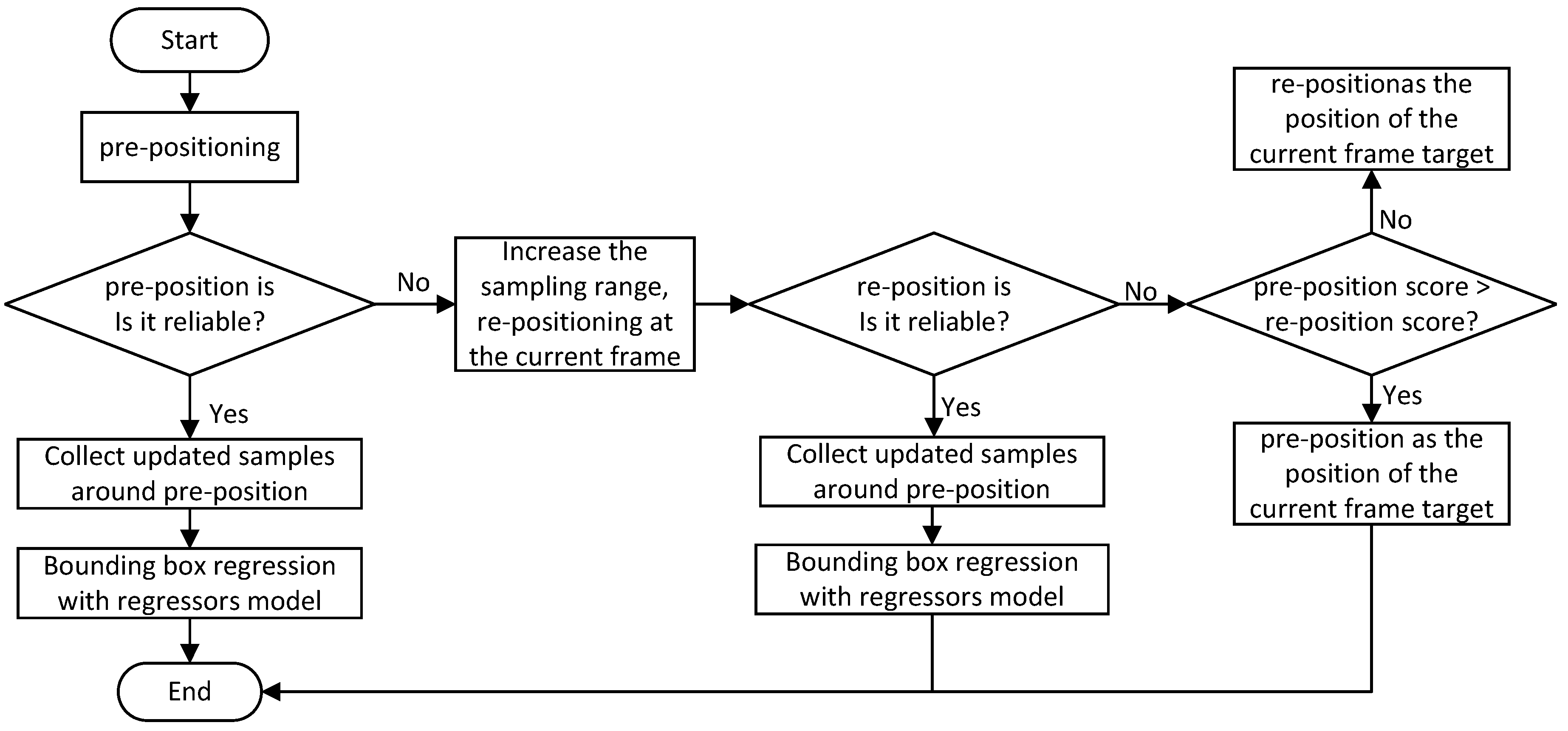
- We improve the re-detection algorithm of the base tracker by adding a re-detection step that performs a global target search at the current frame, which mitigates the accumulation of failures and can increase the robustness and precision of the tracking algorithm while decreasing the amount of computation and making the tracking algorithm more efficient.
2. Related Work
2.1. RGBT Tracking
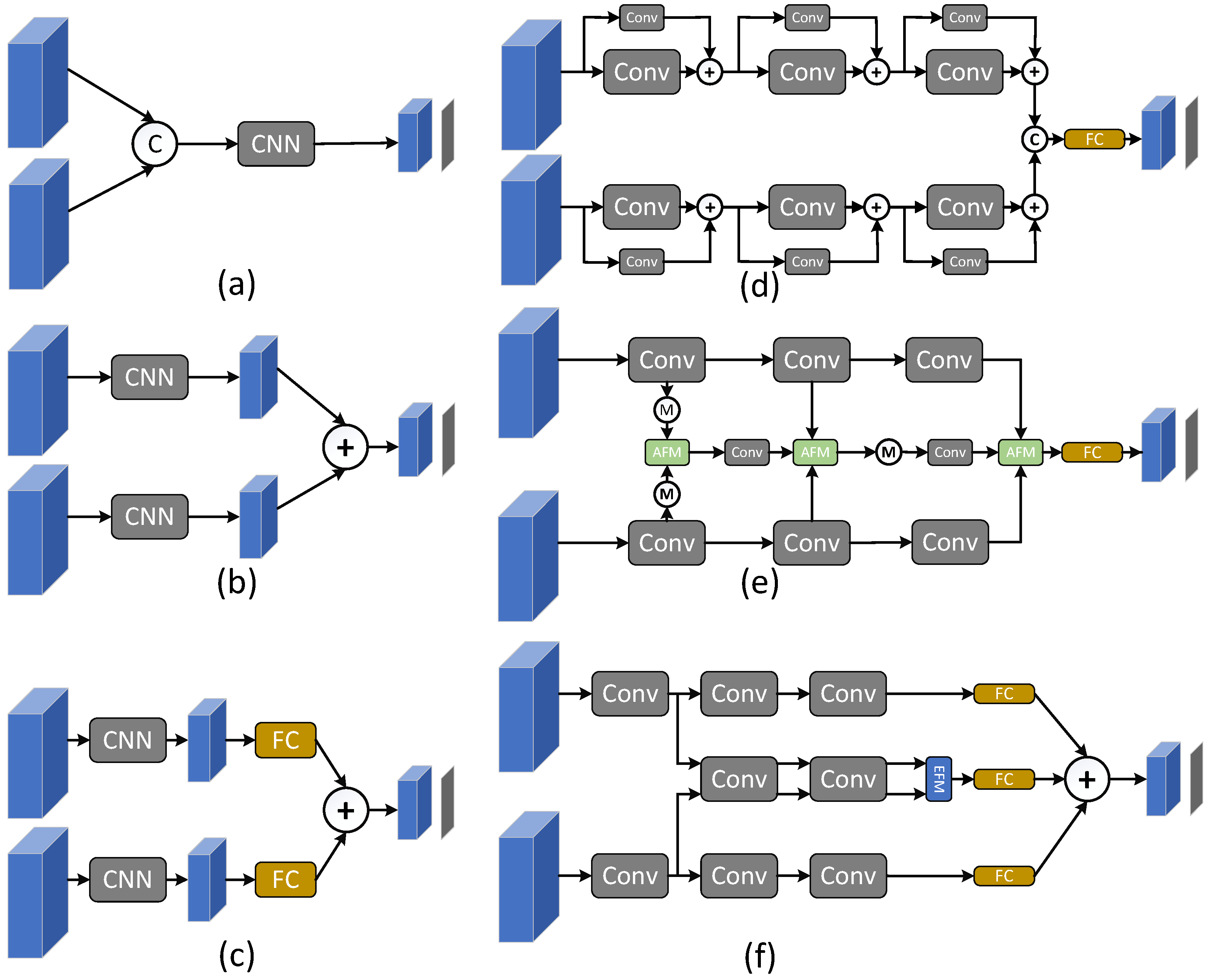
2.2. Multimodal Fusion Network
2.3. Attention Mechanism
3. Our Method
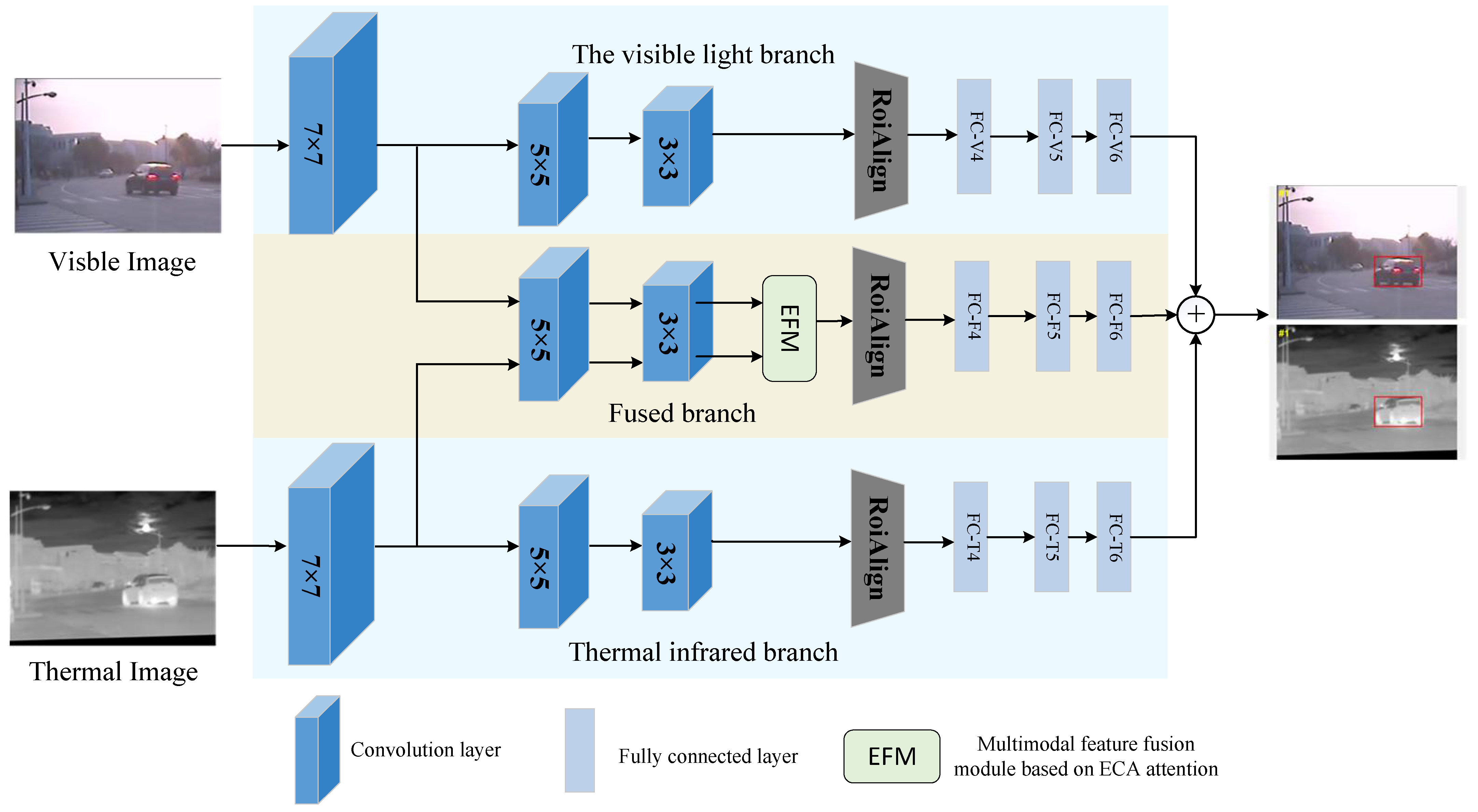
3.1. RMFNet Overall Architecture
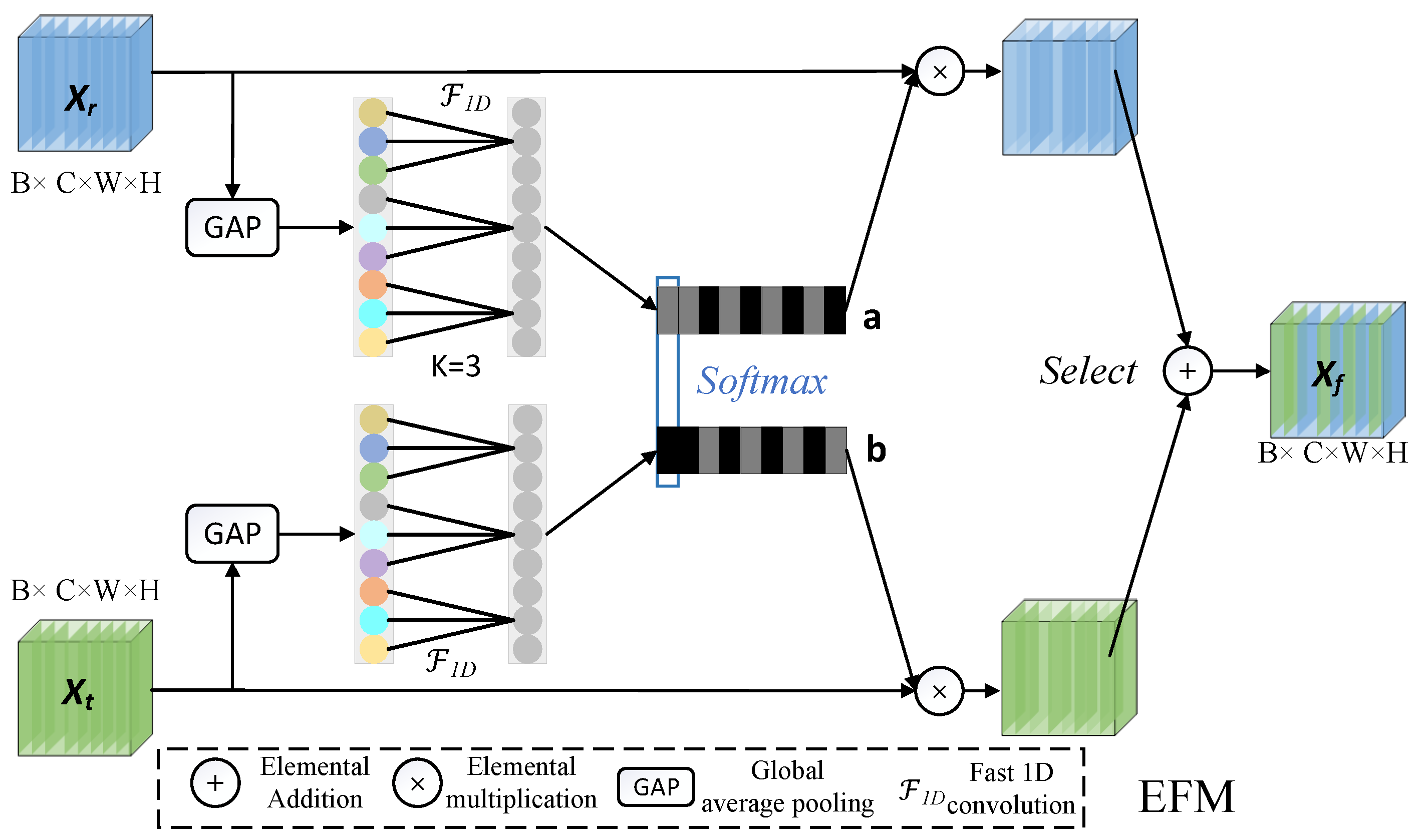
3.2. The Fusion Strategy
- (1)
- Medium-Term Feature-Level Fusion
- (2)
- Late Decision-Level Fusion
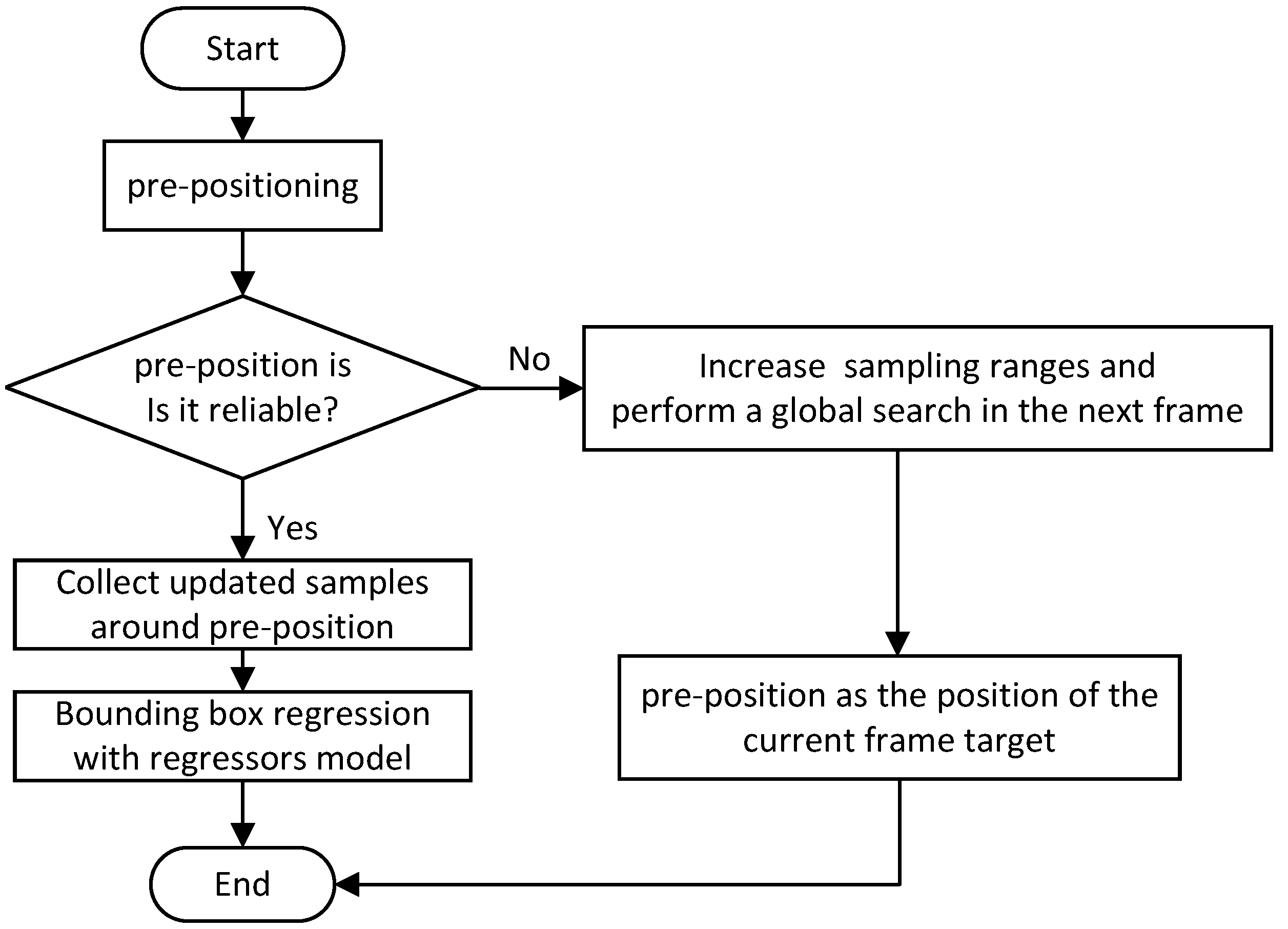
3.3. Improved Re-Detection Algorithm
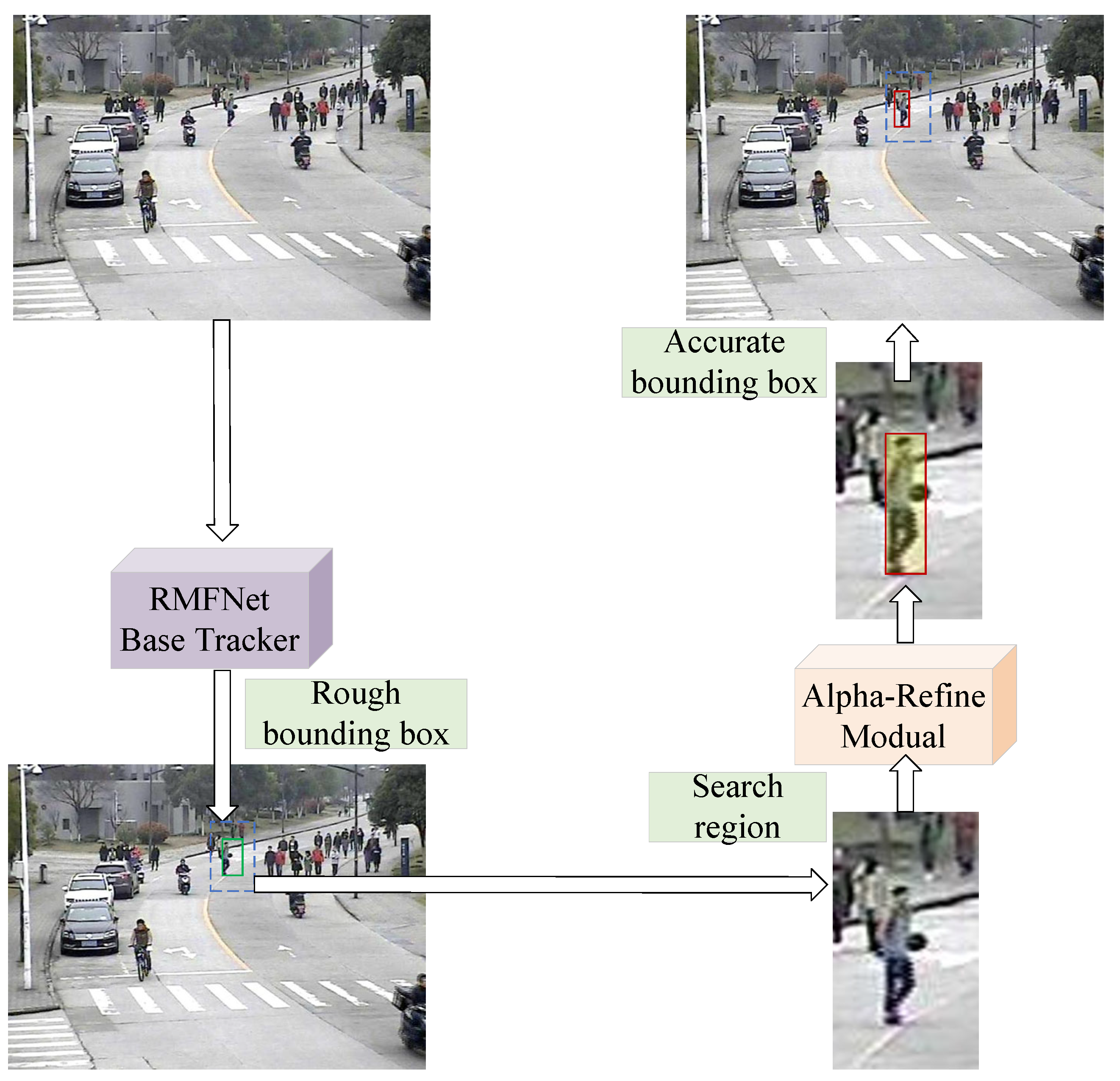
3.4. Alpha-Refine Module
4. Implementation Details
4.1. Offline Training
4.2. Online Tracking
| Algorithm 1: Online Tracking |
Input: Pretrainded CNN filters { , }. Initial target state . Output: Estimated target state . 1: Randomly initialize ; 2: Train a bounding box regression model B R(·); 3: Draw positive and negative samples , ; 4: Update {} using and ; 5: Initialize short-term and long-term samples and 6: repeat 7: Draw target candidate samples . 8: Compute the optimal target state by (8). 9: if >0.5 then 10: Draw training samples and ; 11: , 12: = B R(); 13: if <0.5 then 14: Performing short-term updates {} with . 15: else if t mod 10 = 0 then 16: Performing long-term updates {} with . 17: until end |
5. Performance Evaluation
5.1. Datasets and Metrics
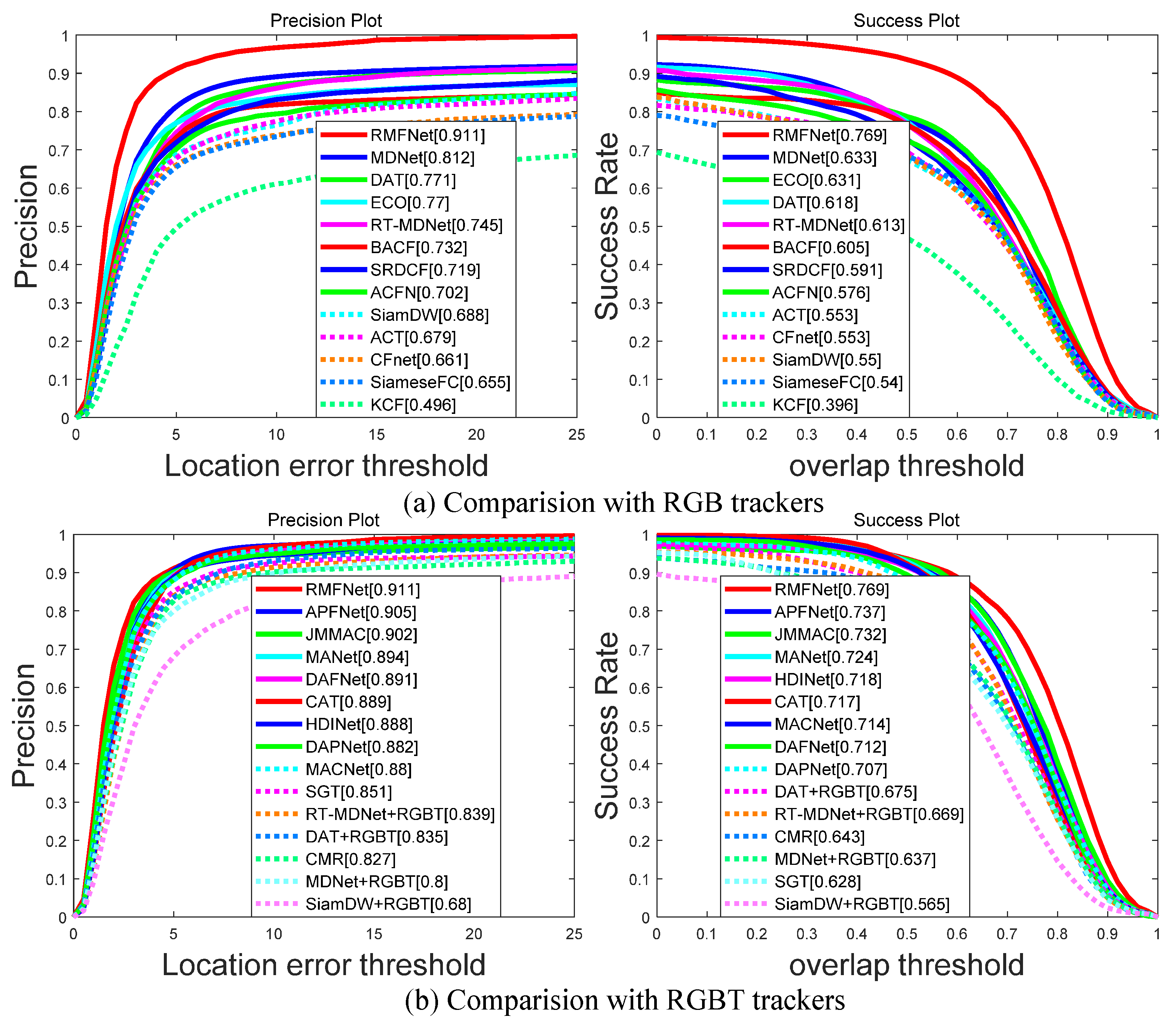
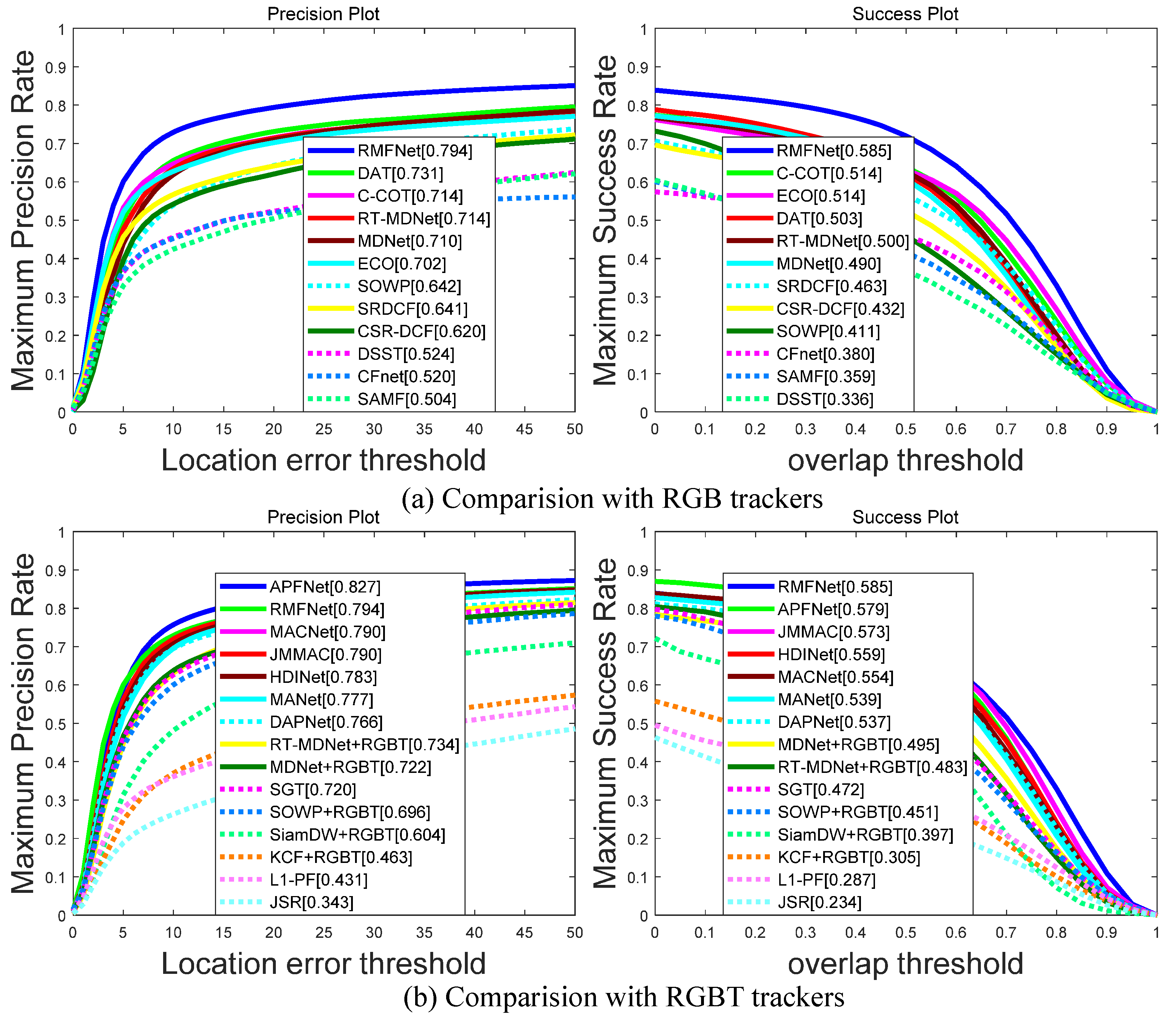
5.2. Evaluation on the GTOT Dataset
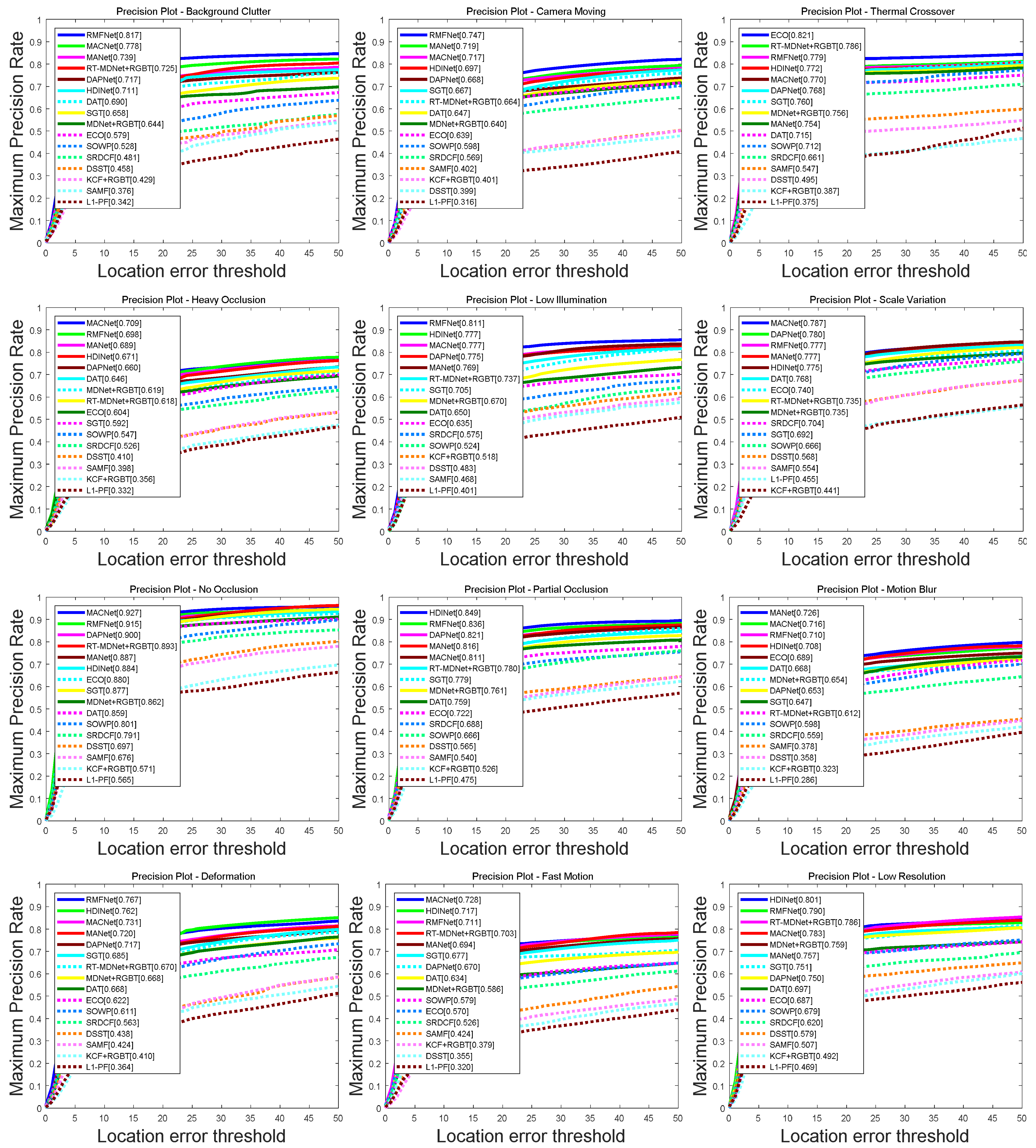
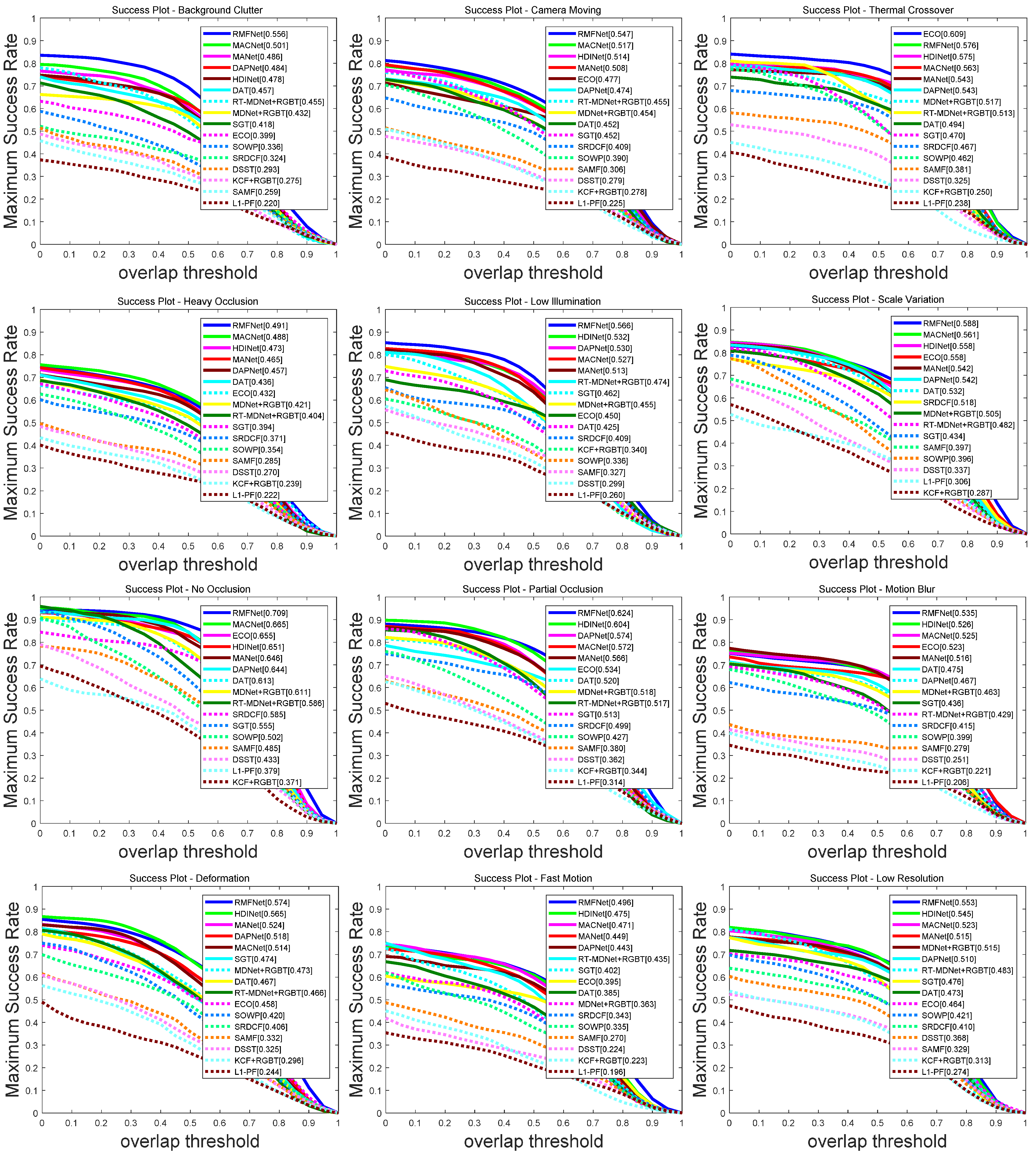
5.3. Evaluation on the RGBT234 Dataset
5.4. Ablation Experiments
5.4.1. Component Analysis
5.4.2. Multimodal Fusion Module Analysis
5.4.3. Efficiency Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, Y.; Li, C.; Luo, B.; Tang, J.; Wang, X. Dense feature aggregation and pruning for rgbt tracking. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 465–472. [Google Scholar]
- Xu, Q.; Mei, Y.; Liu, J.; Li, C. Multimodal cross-layer bilinear pooling for RGBT tracking. IEEE Trans. Multimed. 2021, 24, 567–580. [Google Scholar] [CrossRef]
- Li, Y.; Lai, H.; Wang, L.; Jia, Z. Multibranch Adaptive Fusion Network for RGBT Tracking. IEEE Sens. J. 2022, 22, 7084–7093. [Google Scholar] [CrossRef]
- Xiao, Y.; Yang, M.; Li, C.; Liu, L.; Tang, J. Attribute-based progressive fusion network for rgbt tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 2831–2838. [Google Scholar]
- Lu, A.; Li, C.; Yan, Y.; Tang, J.; Luo, B. RGBT tracking via multi-adapter network with hierarchical divergence loss. IEEE Trans. Image Process. 2021, 30, 5613–5625. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Yan, B.; Zhang, X.; Wang, D.; Lu, H.; Yang, X. Alpha-refine: Boosting tracking performance by precise bounding box estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–27 June 2021; pp. 5289–5298. [Google Scholar]
- Li, C.; Cheng, H.; Hu, S.; Liu, X.; Tang, J.; Lin, L. Learning collaborative sparse representation for grayscale-thermal tracking. IEEE Trans. Image Process. 2016, 25, 5743–5756. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Liang, X.; Lu, Y.; Zhao, N.; Tang, J. RGB-T object tracking: Benchmark and baseline. Pattern Recognit. 2019, 96, 106977. [Google Scholar] [CrossRef]
- Li, C.; Wu, X.; Zhao, N.; Cao, X.; Tang, J. Fusing two-stream convolutional neural networks for RGB-T object tracking. Neurocomputing 2018, 281, 78–85. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Li, C.; Lu, A.; Zheng, A.; Tu, Z.; Tang, J. Multi-Adapter RGBT Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 2262–2270. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Yang, X. Learning adaptive attribute-driven representation for real-time RGB-T tracking. Int. J. Comput. Vis. 2021, 129, 2714–2729. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Peng, S.; Liu, J.; Gong, K.; Xiao, G. SiamFT: An RGB-infrared fusion tracking method via fully convolutional siamese networks. IEEE Access 2019, 7, 122122–122133. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Zhang, X.; Ye, P.; Peng, S.; Liu, J.; Xiao, G. DSiamMFT: An RGB-T fusion tracking method via dynamic Siamese networks using multi-layer feature fusion. Signal Process. Image Commun. 2020, 84, 115756. [Google Scholar] [CrossRef]
- Peng, J.; Zhao, H.; Hu, Z.; Zhuang, Y.; Wang, B. Siamese Infrared and Visible Light Fusion Network for RGB-T Tracking. arXiv 2021, arXiv:2103.07302. [Google Scholar]
- Yang, R.; Zhu, Y.; Wang, X.; Li, C.; Tang, J. Learning Target-Oriented Dual Attention for Robust RGB-T Tracking. In Proceedings of the 2019 IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 3975–3979. [Google Scholar]
- Gao, Y.; Li, C.; Zhu, Y.; Tang, J.; He, T.; Wang, F. Deep Adaptive Fusion Network for High Performance RGBT Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 Octomber–2 November 2019; pp. 91–99. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8 September 2018; pp. 267–283. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 3–8 January 2021; pp. 3560–3569. [Google Scholar]
- Tu, Z.; Lin, C.; Zhao, W.; Li, C.; Tang, J. M 5 l: Multi-modal multi-margin metric learning for rgbt tracking. IEEE Trans. Image Process. 2021, 31, 85–98. [Google Scholar] [CrossRef] [PubMed]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Wang, D.; Li, P.; Wang, S.; Lu, H. Real-time’actor-critic’tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 318–334. [Google Scholar]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Choi, J.; Jin Chang, H.; Yun, S.; Fischer, T.; Demiris, Y.; Young Choi, J. Attentional correlation filter network for adaptive visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4807–4816. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end representation learning for correlation filter based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Jung, I.; Son, J.; Baek, M.; Han, B. Real-time mdnet. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 83–98. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4591–4600. [Google Scholar]
- Kiani Galoogahi, H.; Fagg, A.; Lucey, S. Learning background-aware correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1135–1143. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Pu, S.; Song, Y.; Ma, C.; Zhang, H.; Yang, M. Deep Attentive Tracking via Reciprocative Learning. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 1935–1945. [Google Scholar]
- Li, C.; Zhao, N.; Lu, Y.; Zhu, C.; Tang, J. Weighted sparse representation regularized graph learning for RGB-T object tracking. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA USA, 23–27 October 2017; pp. 1856–1864. [Google Scholar]
- Li, C.; Zhu, C.; Huang, Y.; Tang, J.; Wang, L. Cross-modal ranking with soft consistency and noisy labels for robust RGB-T tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 808–823. [Google Scholar]
- Zhang, P.; Zhao, J.; Bo, C.; Wang, D.; Lu, H.; Yang, X. Jointly modeling motion and appearance cues for robust RGB-T tracking. IEEE Trans. Image Process. 2021, 30, 3335–3347. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Zhang, L.; Zhuo, L.; Zhang, J. Object tracking in RGB-T videos using modal-aware attention network and competitive learning. Sensors 2020, 20, 393. [Google Scholar] [CrossRef] [PubMed]
- Mei, J.; Zhou, D.; Cao, J.; Nie, R.; Guo, Y. Hdinet: Hierarchical dual-sensor interaction network for rgbt tracking. IEEE Sens. J. 2021, 21, 16915–16926. [Google Scholar] [CrossRef]
- Kim, H.U.; Lee, D.Y.; Sim, J.Y.; Kim, C.S. Sowp: Spatially ordered and weighted patch descriptor for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3011–3019. [Google Scholar]
- Lukezic, A.; Vojir, T.; Cehovin Zajc, L.; Matas, J.; Kristan, M. Discriminative correlation filter with channel and spatial reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6309–6318. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Li, Y.; Zhu, J. A scale adaptive kernel correlation filter tracker with feature integration. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 254–265. [Google Scholar]
- Danelljan, M.; Robinson, A.; Shahbaz Khan, F.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part V 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 472–488. [Google Scholar]
- Liu, H.; Sun, F. Fusion tracking in color and infrared images using joint sparse representation. Sci. China Inf. Sci. 2012, 55, 590–599. [Google Scholar] [CrossRef]
- Wu, Y.; Blasch, E.; Chen, G.; Bai, L.; Ling, H. Multiple source data fusion via sparse representation for robust visual tracking. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–8. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | OCC | LSV | FM | LI | TC | SO | DEF | ALL |
|---|---|---|---|---|---|---|---|---|
| ECO | 77.5/62.2 | 85.6/70.5 | 77.9/64.5 | 75.2/61.7 | 81.9/65.3 | 90.7/69.1 | 75.2/59.8 | 77.0/63.1 |
| RT-MDNet | 73.3/57.6 | 79.1/63.7 | 78.1/64.1 | 77.2/63.8 | 73.7/59.0 | 85.6/63.4 | 73.1/61.0 | 74.5/61.3 |
| SiamDW+RGBT | 67.5/53.6 | 68.9/56.6 | 71.1/57.6 | 70.0/58.8 | 63.5/51.7 | 76.4/58.5 | 69.1/58.2 | 68.0/56.5 |
| SRDCF | 72.7/58.0 | 80.4/68.1 | 68.3/61.1 | 71.7/59.4 | 70.5/58.0 | 80.5/57.5 | 66.6/53.7 | 71.9/59.1 |
| RT-MDNet+RGBT | 79.6/61.8 | 80.9/63.6 | 79.4/61.2 | 85.0/68.9 | 86.4/65.8 | 93.5/67.6 | 90.8/73.4 | 83.9/66.9 |
| MDNet+RGBT | 82.9/64.1 | 77.0/57.3 | 80.5/59.8 | 79.5/64.3 | 79.5/60.9 | 87.0/62.2 | 81.6/73.3 | 80.0/63.7 |
| SGT | 81.0/56.7 | 84.2/54.7 | 79.9/55.9 | 88.4/65.1 | 84.8/61.5 | 91.7/61.8 | 91.9/73.3 | 85.1/62.8 |
| CMR | 82.5/62.6 | 85.3/66.7 | 83.5/65.0 | 88.7/67.8 | 81.1/62.2 | 86.5/61.0 | 84.7/65.2 | 82.7/64.3 |
| MANet | 88.2/69.6 | 86.9/70.6 | 87.9/69.4 | 91.4/73.6 | 88.9/70.2 | 93.2/70.0 | 92.3/75.2 | 89.4/72.4 |
| DAPNet | 87.3/67.4 | 84.7/54.8 | 82.3/61.9 | 90.0/72.2 | 89.3/69.0 | 93.7/69.2 | 91.9/77.1 | 88.2/70.7 |
| MACNet | 87.6/68.7 | 84.6/67.3 | 82.3/65.9 | 89.4/73.1 | 89.2/69.7 | 95.0/69.5 | 92.6/76.5 | 88.0/71.4 |
| APFNet | 90.3/71.3 | 87.7/71.2 | 86.5/68.4 | 91.4/74.8 | 90.4/71.6 | 94.3/71.3 | 94.6/78.0 | 90.5/73.7 |
| RMFNet | 89.2/73.6 | 88.1/75.1 | 85.9/73.4 | 92.5/77.1 | 92.0/76.3 | 93.6/74.9 | 94.1/78.4 | 91.1/76.9 |
| Method | RGBT234 | GTOT | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | LF | FB | EFM | RD | AR | PR | SR | PR | SR | |
| I | ✓ | × | × | × | × | × | 75.5 | 51.9 | 83.6 | 68.2 |
| II | ✓ | ✓ | × | × | × | × | 76.2 | 52.9 | 86.5 | 70.0 |
| III | ✓ | ✓ | ✓ | × | × | × | 77.2 | 53.5 | 87.4 | 70.3 |
| IV | ✓ | ✓ | ✓ | ✓ | × | × | 77.4 | 54.0 | 87.7 | 71.1 |
| V | ✓ | ✓ | ✓ | ✓ | ✓ | × | 78.2 | 54.4 | 87.7 | 71.5 |
| VI | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 79.4 | 58.5 | 91.1 | 76.9 |
| Method | RGBT234 | GTOT | ||
|---|---|---|---|---|
| PR | SR | PR | SR | |
| Baseline | 75.5 | 51.9 | 83.6 | 68.2 |
| Baseline + EFM-AFF | 71.8 | 46.0 | 82.5 | 64.7 |
| Baseline + EFM | 77.9 | 52.9 | 86.9 | 69.2 |
| MDNet + RGBT | MANet | DAFNet | CBPNet | RMFNet-noAR | RMFNet | ||
|---|---|---|---|---|---|---|---|
| GTOT | Speed PR/SR | 3 fps 80.0/63.7 | 1.1 fps 89.4/72.4 | 2 fps 88.2/70.7 | 3.7 fps 88.5/71.6 | 14.2 fps 87.7/71.5 | 10.9 fps 91.1/76.9 |
| RGBT234 | Speed PR/SR | 3 fps 72.2/49.5 | 1.5 fps 77.7/53.9 | 2 fps 76.6/53.7 | 3.3 fps 79.4/54.1 | 13.8 fps 78.2/54.4 | 10.1 fps 79.4/58.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Lai, H.; Gao, G. RMFNet: Redetection Multimodal Fusion Network for RGBT Tracking. Appl. Sci. 2023, 13, 5793. https://doi.org/10.3390/app13095793
Zhao Y, Lai H, Gao G. RMFNet: Redetection Multimodal Fusion Network for RGBT Tracking. Applied Sciences. 2023; 13(9):5793. https://doi.org/10.3390/app13095793
Chicago/Turabian StyleZhao, Yanjie, Huicheng Lai, and Guxue Gao. 2023. "RMFNet: Redetection Multimodal Fusion Network for RGBT Tracking" Applied Sciences 13, no. 9: 5793. https://doi.org/10.3390/app13095793
APA StyleZhao, Y., Lai, H., & Gao, G. (2023). RMFNet: Redetection Multimodal Fusion Network for RGBT Tracking. Applied Sciences, 13(9), 5793. https://doi.org/10.3390/app13095793