1. Introduction
Federated learning (FL), a distributed machine learning paradigm proposed by Google [
1], enables data owners to train local models and collaboratively build a global model without exchanging sample data. FL only requires sending a representative to each location to record data, reducing privacy concerns and the issue of “qland” [
2,
3]. FL leverages cloud computing to access scalable storage and computing resources but faces challenges in meeting low latency, high reliability, and data security requirements in the Internet of Everything. As the number of participants and model complexity increases, FL communication overhead becomes a non-negligible issue, and the unreliable network connection between participants leads to high network delays during model transmission and aggregation tasks [
4,
5,
6].
In the context of the heterogeneous edge environment, the development of a hierarchical centralized FL architecture and aggregation mechanism is essential [
7]. A hierarchical architecture reduces the number of direct communication connections and the burden on computing centers. An aggregation mechanism balances the model’s accuracy and training efficiency to speed up model convergence and overall training [
8]. These optimizations address issues such as high model interaction overhead and poor convergence of heterogeneous data in the training process, promoting the deployment of FL algorithms to the edge and maximizing the benefits of collaborative training and privacy protection [
9]. However, research on FL algorithms in edge scenarios is still in its early stages, and further optimization of the system architecture and training strategies is needed.
The main contributions of this paper are as follows:
- (1)
A hierarchical federated learning algorithm with dynamic weighting is proposed to optimize the conventional FedAvg algorithm and address the heterogeneity of client data by adjusting the contribution of each local model to the global model using the Earth mover’s distance method during edge aggregation.
- (2)
A time-effective hierarchical federated learning aggregation algorithm is proposed to address the issue of varying completion times for local training tasks and model parameter uploads due to heterogeneous devices and data among participating clients, using a combination of synchronous and semi-asynchronous aggregation methods based on a dynamic packet-weighted aggregation strategy.
The remainder of this article is organized as follows:
Section 2 presents a review of related work in the field of federated learning.
Section 3 describes the hierarchical federated learning algorithm based on dynamic weighting (FedDyn).
Section 4 presents the hierarchical federated learning algorithm based on time-effective aggregation (FedEdge).
Section 5 analyzes the performance of the proposed method on the MNIST and the CIFAR-10 datasets. Finally,
Section 6 concludes this paper.
2. Related Works
As a decentralized machine learning approach, federated learning allows end devices to train on their own local datasets without uploading sensitive user data to a centralized server. However, in contrast to centralized learning, the implementation of federated learning presents a range of new challenges [
10].
The federated stochastic gradient descent (FedSGD) algorithm requires participant devices to upload local model parameters produced after each batch of stochastic gradient descent (SGD) to the central server. This process incurs a large communication overhead. The federated averaging (FedAvg) algorithm reduces communication costs by increasing the calculation costs, requiring participant devices to perform several rounds of SGD locally before sending updated model information to the central server. Konečný et al. [
1] combined sparsification and quantization methods to design a structured updating technique, and proposed that updated complete models should be compressed before being uploaded to reduce communication costs. Shi et al. [
11] proposed a federated learning algorithm based on flexible gradient sparsification, requiring participants to upload only some significant gradients in each round. Both methods improve communication costs at the expense of some sacrifices in model convergence and accuracy. The selection strategy of participating clients plays a crucial role in the training efficiency, model performance, and other standards of federated learning. Nishi et al. [
12] proposed a federated client selection (FedCS) algorithm that selects participants based on their cumulative frequency of participation. However, this method may not work well with complex network model structures and heterogeneous sample data, and could even result in reduced model training efficiency.
Heterogeneity in federated learning is one of the main research directions [
13,
14]. Statistical heterogeneity of data produced and collected by client devices in various network environments, as well as heterogeneity on client devices resulting from differences in their hardware configuration, power configuration, network configuration, and other aspects, are two subcategories of heterogeneity [
15]. Some current technologies offer better solutions and have achieved promising results when addressing client heterogeneity. Hanzely et al. [
16] presented a hybrid federated learning algorithm blending global and local models and proposed a new gradient descent algorithm named loopless local gradient descent (L2GD) applicable to this idea. Arivazhagan et al. [
17] proposed a two-layer deep neural network federated learning (FedPer) framework consisting of a basic layer and a personalization layer. Silva et al. [
18] proposed a personalized federated learning algorithm based on user subgroups and personality embedding to model user preferences. Wu et al. [
19] proposed the federated learning (PerFit) framework for providing personalized services in cloud-edge intelligent IoT (Internet of Things) services. However, these methods increase model complexity and associated costs, bringing great challenges for model deployment.
Liu et al. [
20] proposed an edge-computing heuristic federated learning (HierFAVG) algorithm; they introduced the edge server as the aggregator close to the participant. The edge server performs edge aggregation immediately as some participating clients upload the updated local model parameters. Once the number of edge aggregations performed by the edge reaches a predetermined threshold, the edge server communicates with the central server to transfer the aggregation model parameters. Although the final model might not achieve the expected accuracy or even fail to converge when the data are non-independent and identically distributed (non-IID), this method significantly reduces the communication frequency between the client and the central server, thereby reducing the communication overhead. The advantages and disadvantages of the above algorithms are summarized in
Table 1. Although federated learning and edge computing have been extensively studied in their respective fields, attention is now turning to the possibility of combining the two and their future development direction.
4. Hierarchical Federated Learning Algorithm Based on Time-Effective Aggregation
This paper proposes a time-effective hierarchical federated learning aggregation algorithm to address the issue of varying completion times for local training tasks and model parameter uploads due to heterogeneous devices and data among participating clients. With synchronous aggregation, fast devices are idle while waiting for slower ones, but the proposed algorithm only aggregates local model parameters that have finished training and uploaded within an effective time. Slow clients can participate in subsequent model aggregations.
In the edge layer, the paper adopts a semi-asynchronous packet aggregation method, where the central server only receives local model parameters that arrive within the waiting time. Dynamic packet-weighted aggregation is necessary because the received parameters may be from different global model training rounds, rendering simple average-weighted aggregation inapplicable.
In the service layer, synchronous model parameter aggregation is used. The central server waits for all edge servers to complete their edge aggregation and upload the edge aggregation model parameters before conducting global aggregation and updating the global model parameters for the next round. This method can control the server’s waiting time and reduce the impact on the global training efficiency of slow or failing participants.
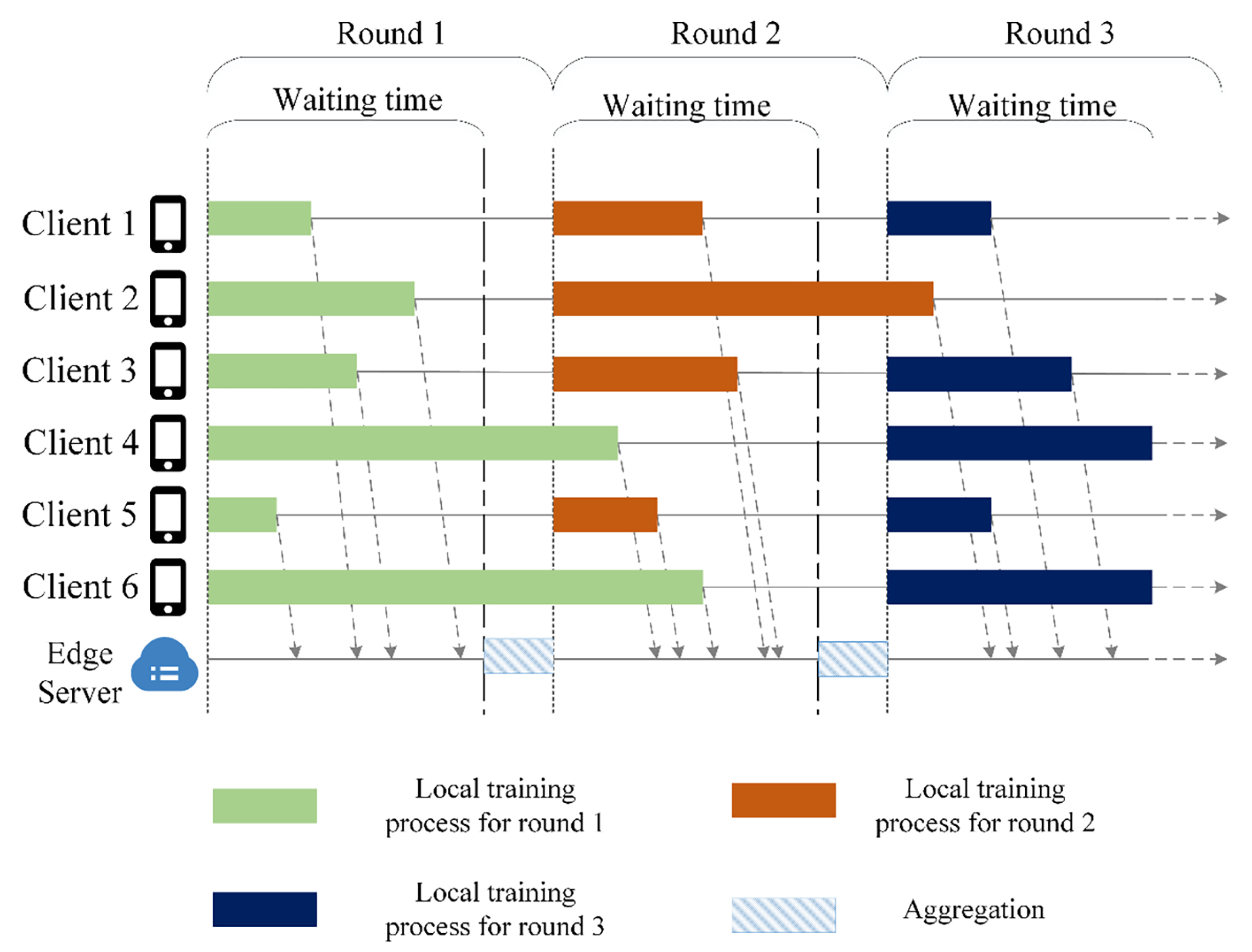
The aggregation strategy based on time effectiveness proposed in this paper is illustrated in
Figure 3.
Assume that there are six participating clients taking part in the federated learning training process, and there are differences in the data distribution and computing capacity of each client. This round of local iterative training starts after receiving the global model parameters. Since the communication between the participants and the server is parallel and the downlink time of the model is short, it is assumed that all six participating clients start training simultaneously. The bar structure in
Figure 3 represents the total time for each client to complete local training. It is clear that the total time consumed by Client 4 and Client 6 is significantly higher than the other participating clients. When the server uses the synchronous update method, it must wait for the slowest client, Client 6, to upload successfully. This process is time-consuming for Client 5, which trains the fastest. Assuming that the waiting time for each round of training is fixed, the server only receives the model parameters that arrive during this time using the time-effective aggregation method proposed in this paper.
Taking the first round of global training (Round 1) as an example, Client 1, Client 2, Client 3, and Client 5 complete the local model upload within the specified time, so only these four participating clients’ local model parameters are aggregated. The second round (Round 2) of training starts once the server updates the global model. In Round 2, Client 4 and Client 6 do not need to use the new global model for training in this round since they did not complete the update in the previous round. When Round 2’s validity arrives, all clients except Client 2 upload local model parameters to the server. Client 1, Client 3, and Client 5 take part in the current round of training, while Client 4 and Client 6 take part in the previous round, which is relatively older. As can be seen, every global aggregation can separate the received local model parameters into two categories: new (local models participating in the current round of training) and old (local models participating in the previous round of training).
The following is an overview of the federated learning and training process based on the time-effective aggregation mechanism.
- (1)
Determine waiting time .
Before each round of global iteration starts, every edge server must determine the waiting time
for the current round.
indicates the waiting period that starts after the edge server distributes the global model to individual clients. During the waiting period, the participating clients’ local model parameters can be received by the edge server. Once the allotted waiting time has passed, the edge server ceases receiving and starts the edge aggregation. Since the global model is sent down in a very short time, the global model sending time is disregarded in this study. Namely, the waiting time
can be determined by the total time from the start of local training to the completion of uploading local model parameters for the last round of participating clients. The local training time
and the model upload time
are shown in Equations (
10) and (
12), respectively. For participating client
i, the time consumed from the start of local training to the end of the local model upload is given by:
Assuming the client device’s basic background conditions, such as geographical location, user population, and computing power, remain constant, there is no significant difference in the time required for the device to complete the training round using the same global parameter setting each time. Therefore, the time consumed in the current round can be estimated based on the total time spent in the previous round. The edge server m selects the median of the total time consumed by participating clients in the previous round as the waiting time for the current round. On the one hand, this ensures that each round has local model parameters that will participate in the global aggregation after passing this round of training. On the other hand, it prevents clients with fast training from waiting too long, which improves the overall training efficiency. This time-effective aggregation method enables fast-training clients to train more frequently within the same amount of time, while also incorporating the local models contributed by slow-training clients into global convergence.
- (2)
Local model receiving.
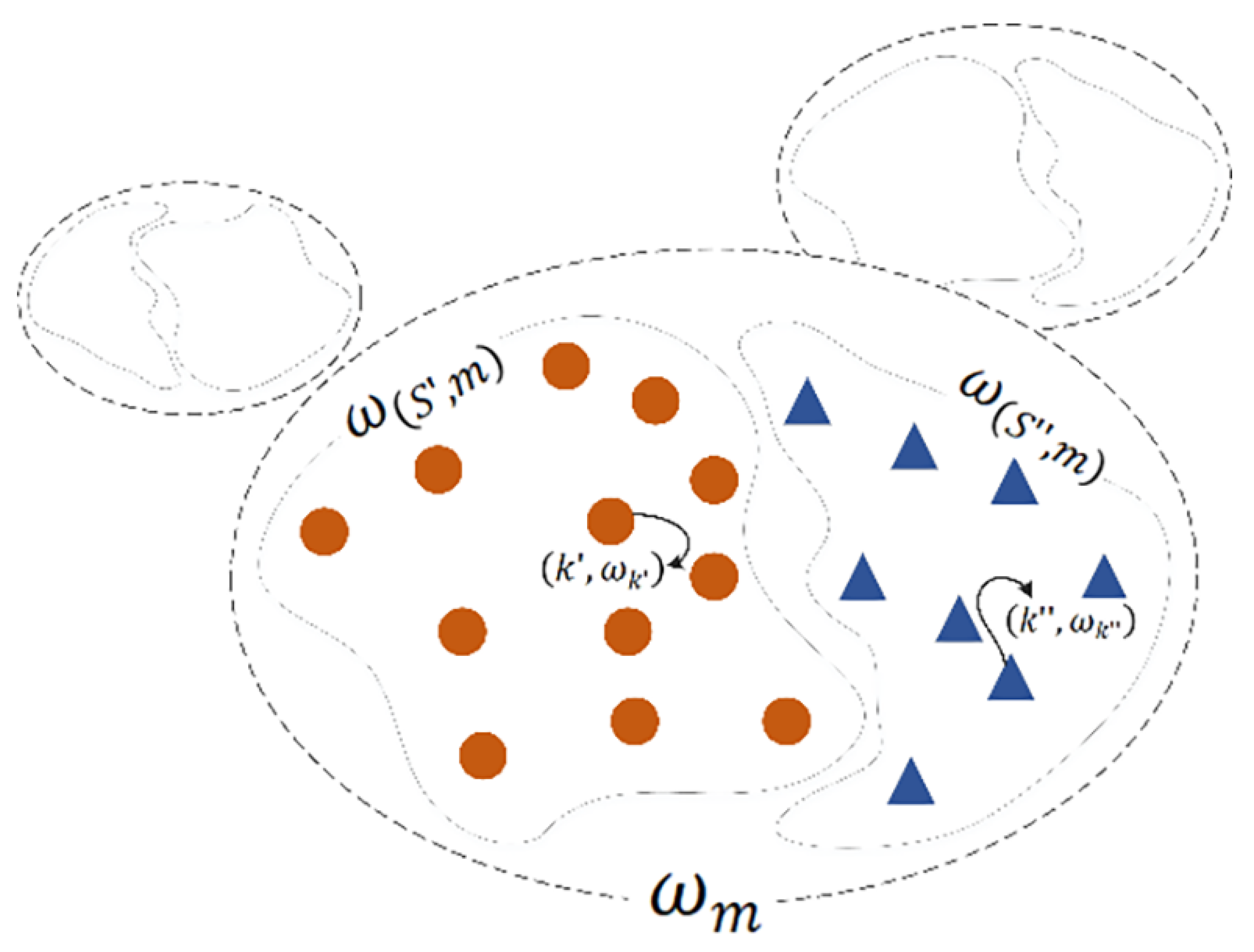
Assuming that the edge server m receives local model parameters from participating client devices during the waiting time , these clients can be classified into two groups according to the training round: the client devices participating in the current round of training and client devices participating in previous rounds, and satisfying . The local model parameters of participating client are denoted , which are obtained through training according to the latest global model parameters issued in this round, and their values must be retained during aggregation. Similarly, the relatively old local model parameters also possess value, and they could be more valuable in improving the accuracy of the global model than the models that are trained quickly. Therefore, they should not be ignored. However, if the old model is overemphasized, it may have a negative impact on the convergence of the global model.
To summarize, this algorithm needs to weigh the proportion of local model parameters of two subgroups in the global model. For each group of local model parameters, the edge group aggregation model is produced using the dynamic local model weighted aggregation algorithm in
Section 3.3.2. The details are as follows:
where
is the model parameter obtained by dynamic weighted aggregation of the client devices participating in the
t-th round of training on edge server
m, and
refers to the aggregation of obsolete local model parameters for the
t-th round of edge server
m. These local model parameters are obtained by the client devices through training on the obsolete global model, where
and
are defined as in Equation (
14).
- (3)
Group weighted edge aggregation.
After obtaining the two sets of grouping aggregation results,
and
, these sets must be weighted and combined. A relatively small weight needs to be given to the relatively stale model to reduce the effect of obsolescence on convergence. The edge aggregation model
for the
t-th round of the edge server
m is defined as follows:
where
is the dynamic weighting factor determined using the average obsolescence
of the local models of
.
is defined as:
- (4)
Global synchronization aggregation
The time difference for edge servers to complete edge aggregation is insignificant, as the edge waiting time is set at the edge. This enables the central server to use the synchronous aggregation method. Once all of the edge model parameters
have arrived at the central server, the global aggregation is performed using the average weighted algorithm to update the global model parameters. The calculation process for the global model parameters is as follows:
The overall training time of federated learning can be significantly shortened, and model training efficiency can be improved using this hierarchical grouping and time-effective aggregation method. At the same time, the dual-weighting method is used to ensure the accuracy of the global model.
Figure 4 vividly illustrates the above aggregation ideas.
The proposed hierarchical federated learning algorithm, based on an efficient aggregation mechanism, is presented in Algorithm 2. It is noteworthy that, in contrast to the direct aggregation method used by the central server in Algorithm 1, the edge server process in Algorithm 2 first performs semi-asynchronous edge aggregation of the local model. This hierarchical aggregation method can effectively reduce the number of model parameters that the central server process needs to receive. To improve training efficiency, the edge server process has a waiting time set, enabling edge aggregation to be performed without waiting for all participating client devices to complete local training. This reduces idle waiting time on both the edge and central servers, allowing as many training rounds as possible to be conducted concurrently, and speeding up the global model’s convergence. To ensure the model’s training effect, the local model parameters arriving at the edge server in each round are grouped, and the two groups of model parameters are weighted to balance the local model’s contribution to the global model.
| Algorithm 2 The hierarchical federated learning algorithm based on efficient aggregation mechanism (FedEdge) |
| Require: Initialize global model parameters , global epochs T, local epochs E, learning rates , waiting time , |
| Ensure: Global model ; |
- 1:
Central server: - 2:
for
do - 3:
for each edge server do - 4:
Send global model parameters to edge server m in parallel; - 5:
Receive aggregation model from edge server m; - 6:
end for - 7:
Global aggregation: ; - 8:
end for - 9:
Edge server: - 10:
for each edge server do - 11:
Select participating client ; - 12:
for each local client i do - 13:
Send global model to client i; - 14:
Set the version number ; - 15:
end for - 16:
Edge aggregation: receive the local model parameters from the participating client i within the waiting time ; - 17:
if then - 18:
Aggregation participating in the t-th round of training; - 19:
else - 20:
Aggregation participating in the previous round of training; - 21:
end if - 22:
Weighted aggregation of and ; - 23:
end for
|
5. Simulation and Analysis
The parameters of the FedEdge algorithm used in this simulation are reported in
Table 2. We varied the distribution of data across clients to include IID, non-IID(2), and non-IID(5) distributions. We set the total number of clients,
N, to 100, with a subset of 5 clients participating in each round of training. We also employed
M edge servers. We conducted separate experiments using the MNIST and CIFAR-10 datasets, respectively, with a total of 20 and 200 global training iterations,
T. At each training iteration, each participating client performed
E local training iterations with a batch size of 64 and a learning rate of
set to 0.01. For non-IID datasets, we use a completely random method to partition the dataset.
Figure 5 and
Figure 6 show the experimental comparison results of the dynamic and average weighted aggregation methods using the MNIST and CIFAR-10 datasets, respectively. The x-axis represents the global training round, and the y-axis represents the global model’s classification accuracy after each global aggregation.
Figure 5 compares the effects of two algorithms on the MNIST dataset after 20 rounds of training. The model’s accuracy is highest when the q is IID, and it fluctuates more when the client’s data distribution differs greatly. For non-IID data with two classifications, the model accuracy obtained with the dynamic weighting algorithm is higher than that obtained with the FedAvg algorithm. For non-IID data with five classifications, the accuracy of the model trained with the dynamic weighting algorithm is similar to that trained with the FedAvg algorithm, but with less fluctuation. In summary, the proposed federated learning algorithm based on dynamic weighted aggregation can achieve excellent results for both IID and non-IID cases in the MNIST dataset.
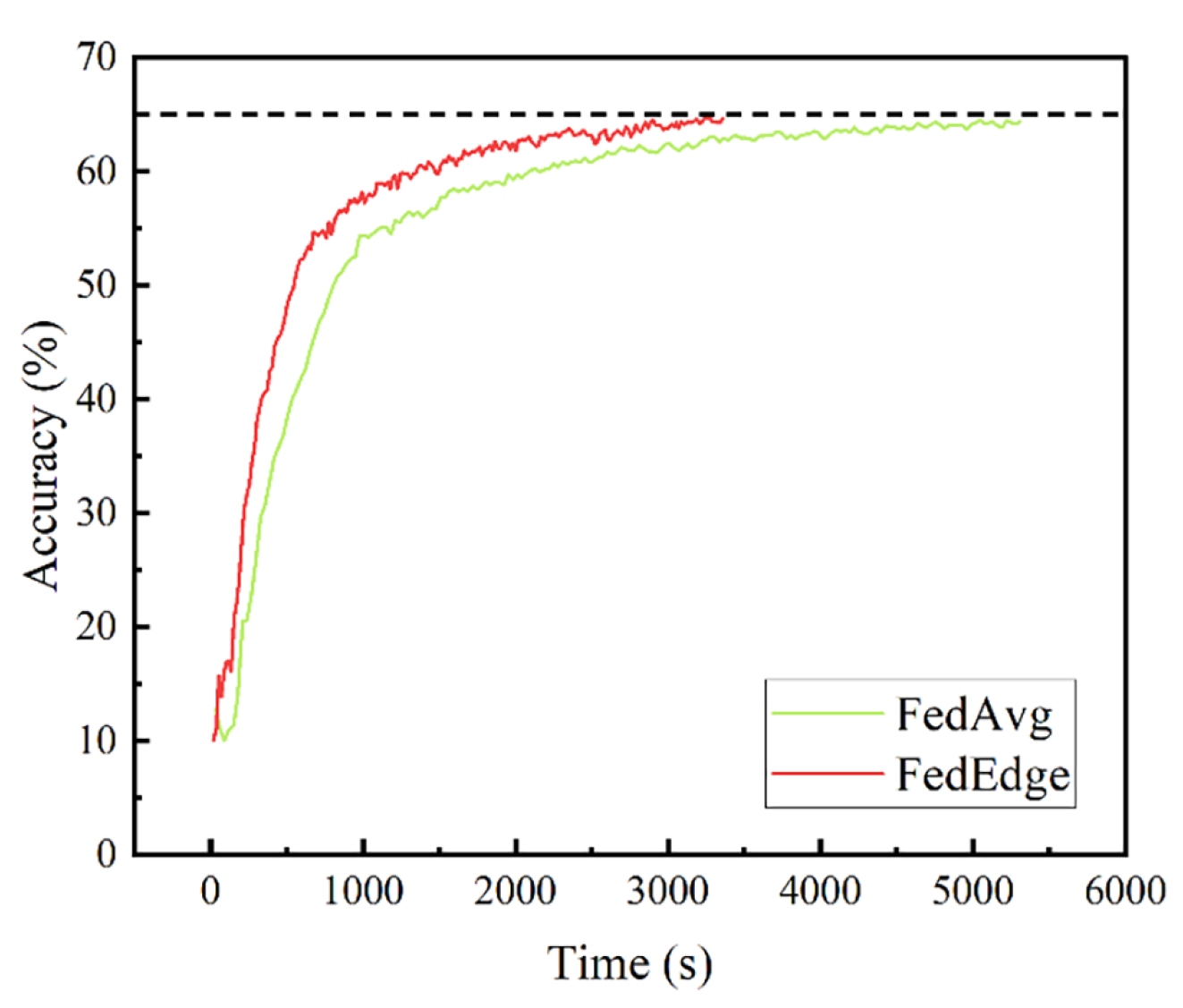
Figure 6 compares two federated learning algorithm model effects after 200 training rounds on the CIFAR-10 dataset. The complexity of CIFAR-10 leads to longer convergence times and more model fluctuation between rounds than MNIST. Under IID conditions, the best classification accuracy is 65%. The training model effect is unsatisfactory under non-IID conditions. Nevertheless, dynamic weighted aggregation of local model parameters outperforms direct average weighted aggregation overall, irrespective of whether the non-IID case has two or five classifications.
The efficient hierarchical federated learning algorithm is evaluated on the MNIST dataset using confusion matrices for IID and non-IID(5) data distributions. The CNN model performs well on both distributions, with a slightly higher classification deviation observed in the non-IID case.
Figure 7 and
Figure 8 show the classification results.
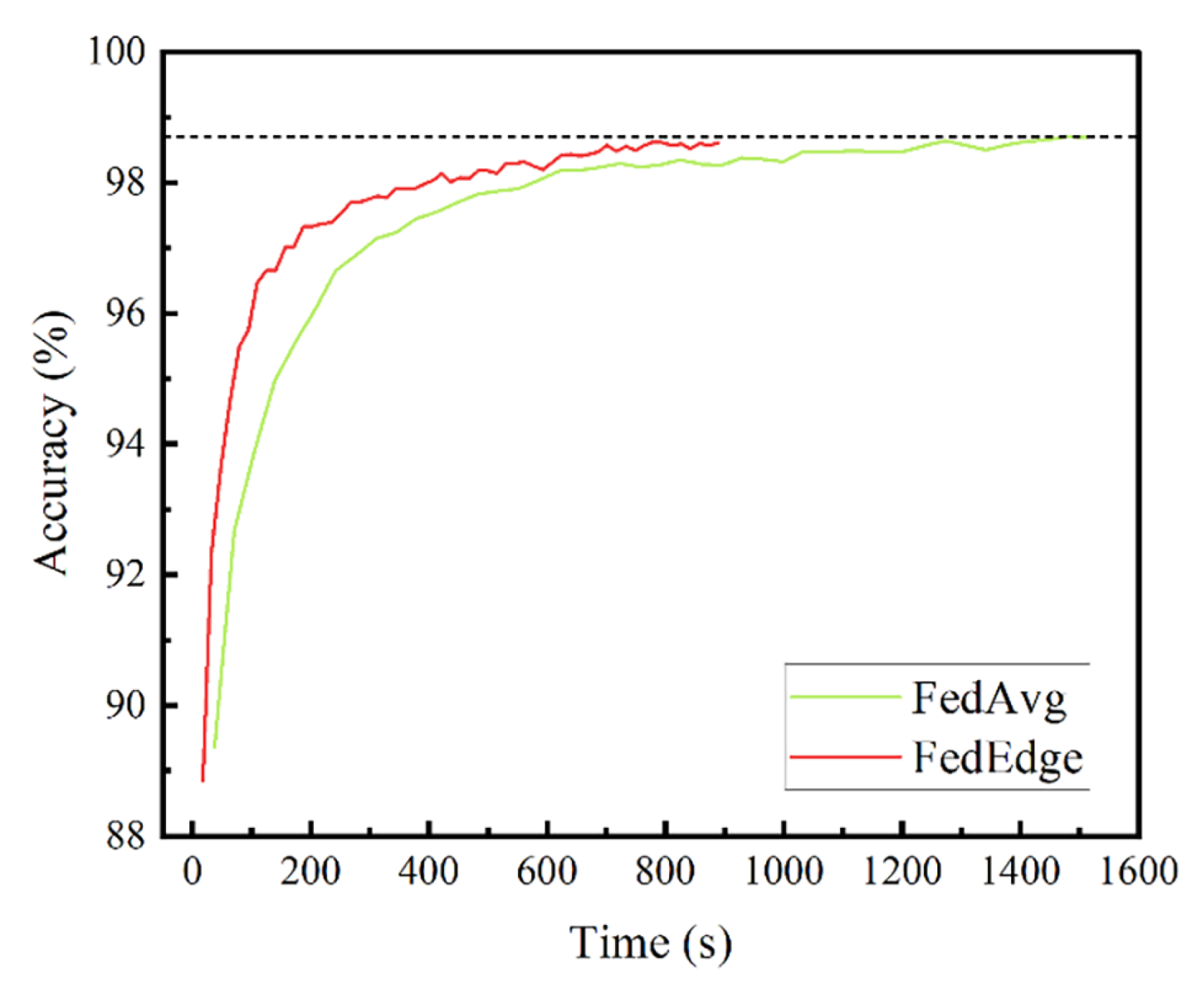
Figure 9 and
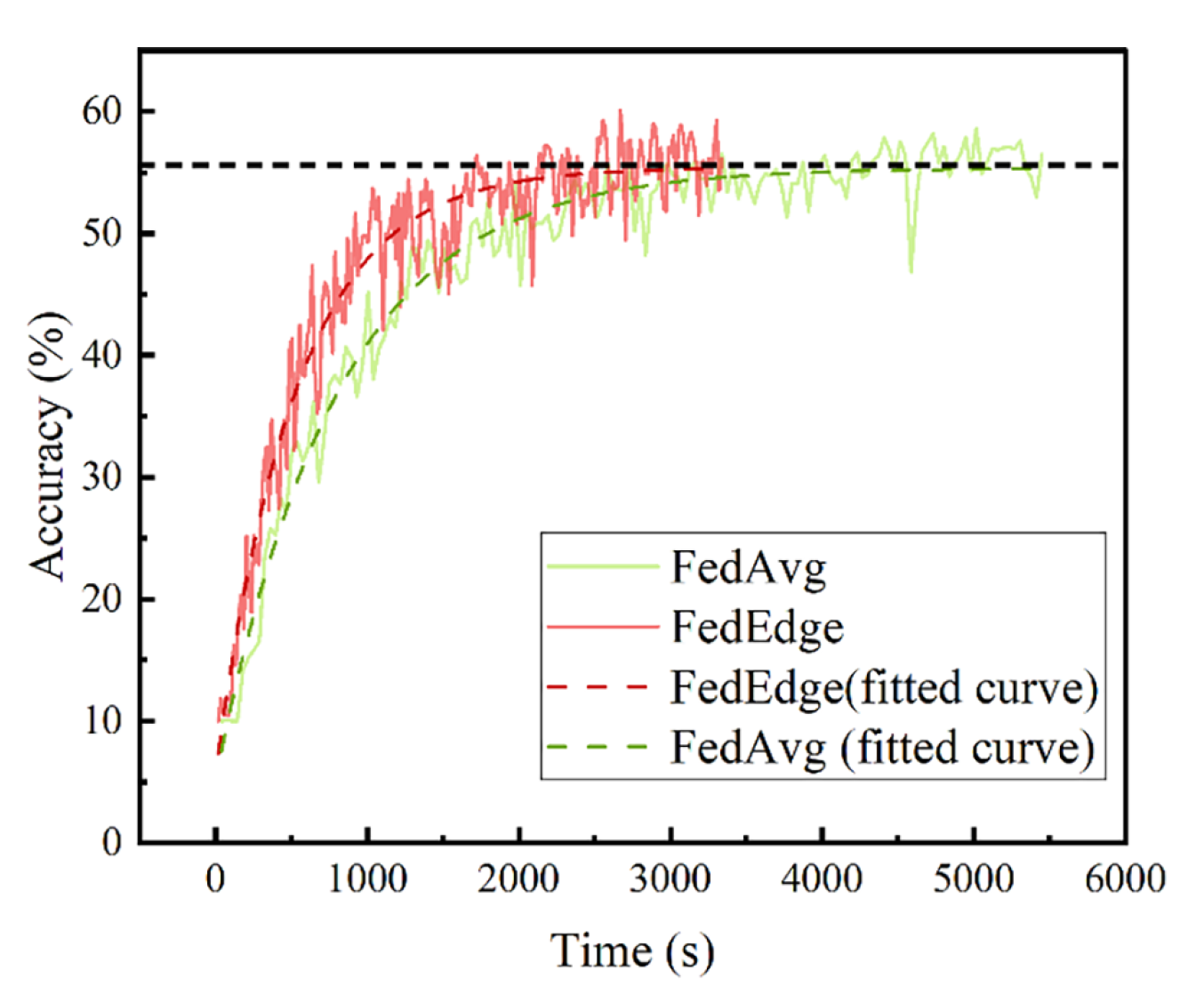
Figure 10 compare the classification accuracy of the FedAvg and FedEdge algorithms on the MNIST dataset after 60 rounds of global training, under IID and non-IID conditions. The FedEdge algorithm achieves the same accuracy in less time than the FedAvg algorithm, as it performs edge aggregation in each iteration without waiting for all clients to finish training. The proposed algorithm reduces training time by 37.3% and achieves good accuracy when classifying handwritten datasets, improving training efficiency by about 30–40%. In the non-IID case, the accuracy of the model fluctuates greatly due to the different distributions of training data used in each round of aggregation. Overall, the results demonstrate the effectiveness and efficiency of the hierarchical federated learning algorithm based on efficient aggregation.
The efficient hierarchical federated learning algorithm was evaluated on the CIFAR-10 dataset under IID and non-IID settings. The confusion matrices of the model’s classification results are shown in
Figure 11 and
Figure 12. The model performed well in the IID case, achieving a high number of correct classifications for each class. However, in the non-IID case, the model’s performance was less than ideal, likely due to the deviation of the client’s training data samples leading to insufficient training for individual classes. This negatively affected the model’s recognition performance on the classified samples.
Next, the classification performance of the efficient hierarchical federated learning algorithm on the CIFAR-10 dataset is analyzed. As shown in
Figure 13 and
Figure 14, the model’s classification results are represented using confusion matrices in both IID and non-IID settings. In the IID case, the model achieved high accuracy, but in the non-IID case, the classification results were less than ideal due to deviations in client training data samples. The FedAvg and FedEdge algorithms are compared after 200 rounds of global training on the test set. The proposed algorithm achieves higher accuracy in a shorter amount of time compared to FedAvg, due to reduced waiting time for edge aggregation. The hierarchical federated learning based on an efficient aggregation mechanism proposed in this study can be applied to a variety of datasets and models and can achieve the desired effect. Compared with conventional federated learning, the proposed algorithm reduces direct communication and improves training efficiency by about 30%.
Table 3 shows the time difference between the FedAvg algorithm and the FedEdge algorithm achieving the same accuracy on different datasets.
The number of participating clients in each round of training can impact the accuracy of a model in addition to the distribution of local data. This study evaluated the impact of the number of participating clients on the accuracy of a model trained using the efficient hierarchical federated learning algorithm on non-IID(2) MNIST and CIFAR-10 datasets. The results shown in
Figure 15 and
Figure 16 indicate that a larger number of participating clients led to better training effects with smaller fluctuations in the non-IID setting. For MNIST, the model accuracy increased from 82.05% to 89.29% when the number of participating clients increased from 10 to 30 after 20 rounds of training. Similarly, the model accuracy increased from 39.54% to 44.39% when the number of participating clients increased from 10 to 30 after 60 rounds of training on CIFAR-10. This is due to the fact that a larger number of clients provides a more balanced global model, as the data categories are more comprehensive. Conversely, a smaller number of clients can result in a significant deviation between classification learning with fewer occurrences and classification learning with more occurrences. The study shows that the proposed algorithm can improve training efficiency and achieve the desired effect on a variety of datasets and models.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}