

Action Detection for Wildlife Monitoring with Camera Traps Based on Segmentation with Filtering of Tracklets (SWIFT) and Mask-Guided Action Recognition (MAROON)
 , ,
, , 
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Datasets
3.2. Action Detection
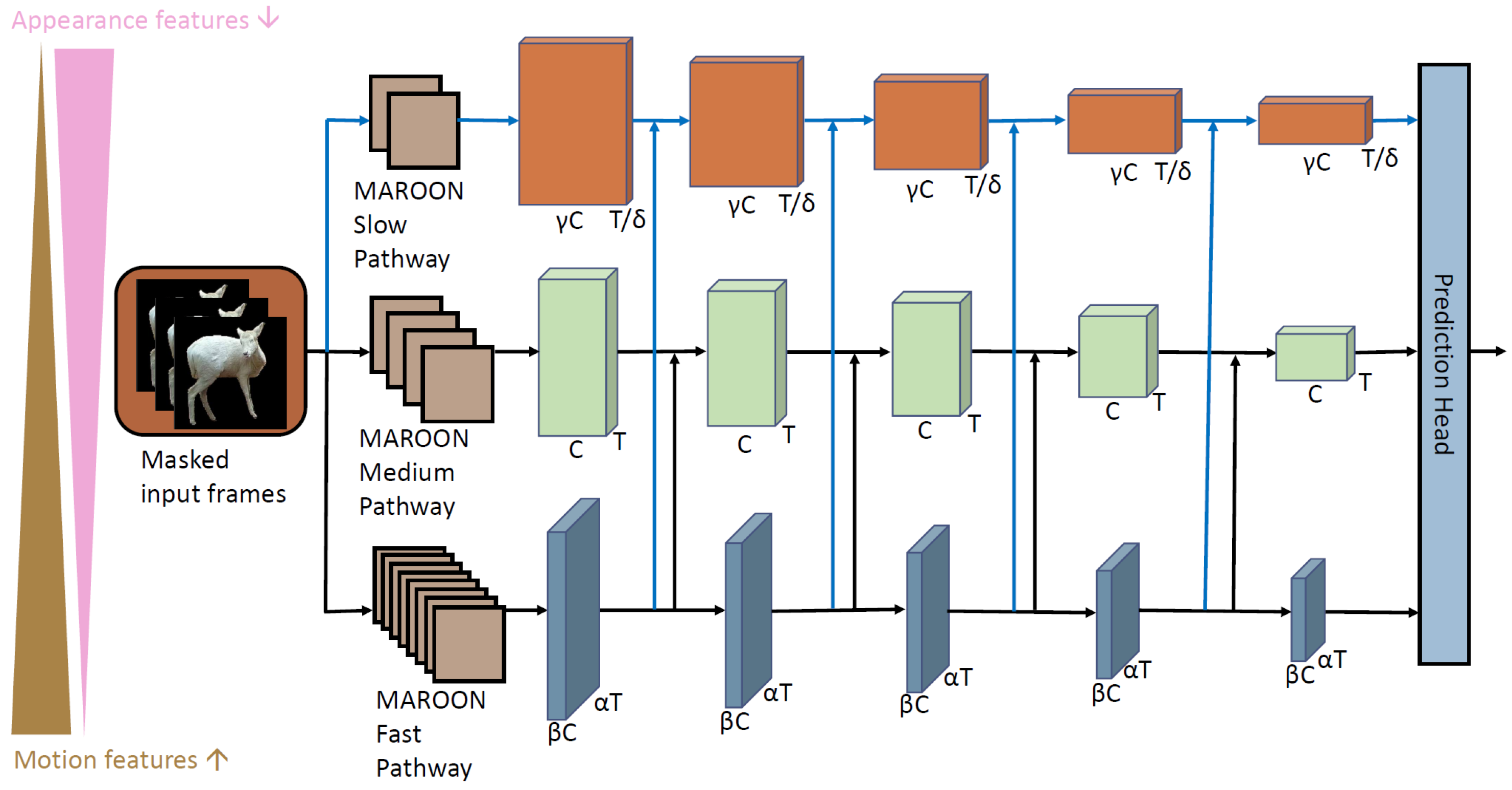
3.2.1. Action Recognition with MAROON
4. Results
4.1. Training and Testing Details
4.2. Evaluation Results
4.3. Ablation Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Description of Action Classes
- Foraging moving: The animal is moving or walking while the head is held towards the ground or towards a food source (bushes, young trees) with eyes opened. The mouth is near (and eventually touching) the ground or the food source, and the jaws are eventually moving.
- Foraging standing: The animal is standing while the head is held towards the ground or towards a food source (bushes, young trees) with eyes opened. The mouth is near (and eventually touching) the ground or the food source, and the jaws are eventually moving.
- Grooming: The animal is standing while scratching or licking itself. The animal’s mouth is touching a random body part while the head is moving slightly.
- Head lowering: The animal’s head is moved from the raised (parallel line with the body or higher) position to the lowered (head nearer towards the ground up to nearly parallel line with the body) position within a short time period.
- Head raising: The animal’s head is moved from the lowered (head nearer towards the ground up to nearly parallel line with the body) position to the raised (parallel line with the body or higher) position within a short time period.
- Resting: The animal’s body is on the ground. The torso is in a slightly lateral position. At the same time, the legs can be stretched off the body or bent underneath and besides the body. The head is placed down on the ground. The animal’s eyes can be either closed or opened.
- Running: A faster target-oriented forward movement than walking. The posture is relatively strained with the animal’s head raised and eyes opened. Two or more hooves do not touch the ground. It contains everything from trot to full speed.
- Sudden rush: The animal goes from standing to running without walking in between and within 1 s.
- Standing up: The animal changes its position from lying to standing.
- Vigilant lying: Lying with the head held high and occasional turning of the head and with ear twitching.
- Vigilant standing: Standing with a strained posture and with the head held parallel to body or higher. The animal is looking around and/or twitching the ears occasionally.
- Walking: A relatively slow, target-oriented forward movement while not feeding or chewing. The posture is relaxed with the animal’s head parallel to the body or higher and eyes opened. One hoof does not touch the ground.
References
- Berger-Tal, O.; Polak, T.; Oron, A.; Lubin, Y.; Kotler, B.P.; Saltz, D. Integrating animal behavior and conservation biology: A conceptual framework. Behav. Ecol. 2011, 22, 236–239. [Google Scholar] [CrossRef]
- Caravaggi, A.; Banks, P.B.; Burton, A.C.; Finlay, C.M.; Haswell, P.M.; Hayward, M.W.; Rowcliffe, M.J.; Wood, M.D. A review of camera trapping for conservation behaviour research. Remote Sens. Ecol. Conserv. 2017, 3, 109–122. [Google Scholar] [CrossRef]
- McCallum, J. Changing use of camera traps in mammalian field research: Habitats, taxa and study types. Mammal Rev. 2013, 43, 196–206. [Google Scholar] [CrossRef]
- Wearn, O.R.; Glover-Kapfer, P. Snap happy: Camera traps are an effective sampling tool when compared with alternative methods. R. Soc. Open Sci. 2019, 6, 181748. [Google Scholar] [CrossRef] [PubMed]
- Hongo, S.; Nakashima, Y.; Yajima, G.; Hongo, S. A practical guide for estimating animal density using camera traps: Focus on the REST model. bioRxiv 2021. [Google Scholar] [CrossRef]
- Villette, P.; Krebs, C.J.; Jung, T.S. Evaluating camera traps as an alternative to live trapping for estimating the density of snowshoe hares (Lepus americanus) and red squirrels (Tamiasciurus hudsonicus). Eur. J. Wildl. Res. 2017, 63, 1–9. [Google Scholar] [CrossRef]
- Henrich, M.; Burgueño, M.; Hoyer, J.; Haucke, T.; Steinhage, V.; Kühl, H.S.; Heurich, M. A semi-automated camera trap distance sampling approach for population density estimation. Remote Sens. Ecol. Conserv. 2023. [Google Scholar] [CrossRef]
- Tobler, M.; Carrillo-Percastegui, S.; Leite Pitman, R.; Mares, R.; Powell, G. Further notes on the analysis of mammal inventory data collected with camera traps. Anim. Conserv. 2008, 11, 187–189. [Google Scholar] [CrossRef]
- Linkie, M.; Dinata, Y.; Nugroho, A.; Haidir, I.A. Estimating occupancy of a data deficient mammalian species living in tropical rainforests: Sun bears in the Kerinci Seblat region, Sumatra. Biol. Conserv. 2007, 137, 20–27. [Google Scholar] [CrossRef]
- Frey, S.; Fisher, J.T.; Burton, A.C.; Volpe, J.P. Investigating animal activity patterns and temporal niche partitioning using camera-trap data: Challenges and opportunities. Remote Sens. Ecol. Conserv. 2017, 3, 123–132. [Google Scholar] [CrossRef]
- Caravaggi, A.; Zaccaroni, M.; Riga, F.; Schai-Braun, S.C.; Dick, J.T.; Montgomery, W.I.; Reid, N. An invasive-native mammalian species replacement process captured by camera trap survey random encounter models. Remote Sens. Ecol. Conserv. 2016, 2, 45–58. [Google Scholar] [CrossRef]
- Green, S.E.; Rees, J.P.; Stephens, P.A.; Hill, R.A.; Giordano, A.J. Innovations in camera trapping technology and approaches: The integration of citizen science and artificial intelligence. Animals 2020, 10, 132. [Google Scholar] [CrossRef] [PubMed]
- Mitterwallner, V.; Peters, A.; Edelhoff, H.; Mathes, G.; Nguyen, H.; Peters, W.; Heurich, M.; Steinbauer, M.J. Automated visitor and wildlife monitoring with camera traps and machine learning. Remote Sens. Ecol. Conserv. 2023. [Google Scholar] [CrossRef]
- Vélez, J.; McShea, W.; Shamon, H.; Castiblanco-Camacho, P.J.; Tabak, M.A.; Chalmers, C.; Fergus, P.; Fieberg, J. An evaluation of platforms for processing camera-trap data using artificial intelligence. Methods Ecol. Evol. 2023, 14, 459–477. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Schindler, F.; Steinhage, V. Identification of animals and recognition of their actions in wildlife videos using deep learning techniques. Ecol. Inform. 2021, 61, 101215. [Google Scholar] [CrossRef]
- Sakib, F.; Burghardt, T. Visual recognition of great ape behaviours in the wild. arXiv 2020, arXiv:2011.10759. [Google Scholar]
- Ng, X.L.; Ong, K.E.; Zheng, Q.; Ni, Y.; Yeo, S.Y.; Liu, J. Animal kingdom: A large and diverse dataset for animal behavior understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19023–19034. [Google Scholar]
- Brookes, O.; Mirmehdi, M.; Kühl, H.; Burghardt, T. Triple-stream Deep Metric Learning of Great Ape Behavioural Actions. arXiv 2023, arXiv:2301.02642. [Google Scholar]
- Schindler, F.; Steinhage, V. Instance segmentation and tracking of animals in wildlife videos: SWIFT-segmentation with filtering of tracklets. Ecol. Inform. 2022, 71, 101794. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6824–6835. [Google Scholar]
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A comprehensive survey of vision-based human action recognition methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [PubMed]
- Bhoi, A. Spatio-temporal action recognition: A survey. arXiv 2019, arXiv:1901.09403. [Google Scholar]
- Liu, X.; Bai, S.; Bai, X. An empirical study of end-to-end temporal action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20010–20019. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6546–6555. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Zhou, B.; Andonian, A.; Oliva, A.; Torralba, A. Temporal relational reasoning in videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 803–818. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks for action recognition in videos. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2740–2755. [Google Scholar] [CrossRef] [PubMed]
- Feichtenhofer, C. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 203–213. [Google Scholar]
- Christoph, R.; Pinz, F.A. Spatiotemporal residual networks for video action recognition. Adv. Neural Inf. Process. Syst. 2016, 2, 3468–3476. [Google Scholar]
- Sheth, I. Three-stream network for enriched Action Recognition. arXiv 2021, arXiv:2104.13051. [Google Scholar]
- Liang, D.; Fan, G.; Lin, G.; Chen, W.; Pan, X.; Zhu, H. Three-stream convolutional neural network with multi-task and ensemble learning for 3d action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Jiang, B.; Wang, M.; Gan, W.; Wu, W.; Yan, J. Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2000–2009. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. Tsm: Temporal shift module for efficient video understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Li, Y.; Ji, B.; Shi, X.; Zhang, J.; Kang, B.; Wang, L. Tea: Temporal excitation and aggregation for action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 909–918. [Google Scholar]
- Kwon, H.; Kim, M.; Kwak, S.; Cho, M. Motionsqueeze: Neural motion feature learning for video understanding. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16. Springer: Cham, Switzerland, 2020; pp. 345–362. [Google Scholar]
- Ryoo, M.S.; Piergiovanni, A.; Arnab, A.; Dehghani, M.; Angelova, A. Tokenlearner: What can 8 learned tokens do for images and videos? arXiv 2021, arXiv:2106.11297. [Google Scholar]
- Chen, M.; Wei, F.; Li, C.; Cai, D. Frame-wise action representations for long videos via sequence contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13801–13810. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Yan, S.; Xiong, X.; Arnab, A.; Lu, Z.; Zhang, M.; Sun, C.; Schmid, C. Multiview transformers for video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3333–3343. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Sushmit, A.S.; Ghosh, P.; Istiak, M.A.; Rashid, N.; Akash, A.H.; Hasan, T. SegCodeNet: Color-Coded Segmentation Masks for Activity Detection from Wearable Cameras. arXiv 2020, arXiv:2008.08452. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zaghbani, S.; Bouhlel, M.S. Mask rcnn for human motion and actions recognition. In Proceedings of the 12th International Conference on Soft Computing and Pattern Recognition (SoCPaR 2020); Springer: Cham, Switzerland, 2021; pp. 1–9. [Google Scholar]
- Hacker, L.; Bartels, F.; Martin, P.E. Fine-Grained Action Detection with RGB and Pose Information using Two Stream Convolutional Networks. arXiv 2023, arXiv:2302.02755. [Google Scholar]
- Tang, J.; Xia, J.; Mu, X.; Pang, B.; Lu, C. Asynchronous interaction aggregation for action detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XV 16. Springer: Cham, Switzerland, 2020; pp. 71–87. [Google Scholar]
- Biswas, S.; Gall, J. Discovering Multi-Label Actor-Action Association in a Weakly Supervised Setting. In Proceedings of the Asian Conference on Computer Vision, Online, 30 November–4 December 2020. [Google Scholar]
- Chen, L.; Tong, Z.; Song, Y.; Wu, G.; Wang, L. Efficient Video Action Detection with Token Dropout and Context Refinement. arXiv 2023, arXiv:2304.08451. [Google Scholar]
- Yuan, L.; Zhou, Y.; Chang, S.; Huang, Z.; Chen, Y.; Nie, X.; Wang, T.; Feng, J.; Yan, S. Toward accurate person-level action recognition in videos of crowed scenes. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 4694–4698. [Google Scholar]
- Dutta, A.; Zisserman, A. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia, MM ’19, Nice, France, 21–25 October 2019. [Google Scholar] [CrossRef]
- Sofiiuk, K.; Petrov, I.A.; Konushin, A. Reviving iterative training with mask guidance for interactive segmentation. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3141–3145. [Google Scholar]
- Zhang, Y.; Kang, B.; Hooi, B.; Yan, S.; Feng, J. Deep long-tailed learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023. [Google Scholar] [CrossRef] [PubMed]
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. Ava: A video dataset of spatio-temporally localized atomic visual actions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6047–6056. [Google Scholar]
- Liu, Q.; Xu, Z.; Bertasius, G.; Niethammer, M. Simpleclick: Interactive image segmentation with simple vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 22290–22300. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Chatfield, C.; Lemon, R.E. Analysing sequences of behavioural events. J. Theor. Biol. 1970, 29, 427–445. [Google Scholar] [CrossRef] [PubMed]
- Bels, V.L.; Pallandre, J.P.; Pelle, E.; Kirchhoff, F. Studies of the Behavioral Sequences: The Neuroethological Morphology Concept Crossing Ethology and Functional Morphology. Animals 2022, 12, 1336. [Google Scholar] [CrossRef]
- Gygax, L.; Zeeland, Y.R.; Rufener, C. Fully flexible analysis of behavioural sequences based on parametric survival models with frailties—A tutorial. Ethology 2022, 128, 183–196. [Google Scholar] [CrossRef]
- Keatley, D. Pathways in Crime: An Introduction to Behaviour Sequence Analysis; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | No. of Videos | Frames per Second (FPS) | Resolution | Avg. No. of Animals per Video | Different Action Classes |
|---|---|---|---|---|---|
| Rolandseck Daylight | 33 | 30 | 5.88 | 11 | |
| Bavarian Forest Daylight | 54 | 15 | 1.13 | 7 | |
| Bavarian Forest Nighttime | 31 | 8 | 2.15 | 7 |
| Dataset | Model | Top-1 | Top-5 |
|---|---|---|---|
| Rolandseck Daylight | MAROON | 69.16 | 96.31 |
| SlowFast | 42.05 | 89.66 | |
| MViT | 43.13 | 85.18 | |
| Bavarian Forest Daylight | MAROON | 46.39 | 97.24 |
| SlowFast | 35.40 | 95.88 | |
| MViT | 35.05 | 94.17 | |
| Bavarian Forest Nighttime | MAROON | 43.05 | 96.33 |
| SlowFast | 35.49 | 95.68 | |
| MViT | 31.91 | 93.26 |
| Dataset | Model | Top-1 (without Mask) | Top-5 (without Mask) | Top-1 (with Mask) | Top-5 (with Mask) |
|---|---|---|---|---|---|
| Rolandseck Daylight | MAROON | 54.65 | 90.96 | 69.19 | 96.31 |
| SlowFast | 42.05 | 89.66 | 57.67 | 92.48 | |
| MViT | 43.13 | 85.18 | 49.41 | 89.57 | |
| Bavarian Forest Daylight | MAROON | 36.44 | 94.85 | 46.39 | 97.24 |
| SlowFast | 35.40 | 95.88 | 45.35 | 96.57 | |
| MViT | 35.05 | 94.17 | 42.63 | 95.54 | |
| Bavarian Forest Nighttime | MAROON | 35.04 | 91.42 | 43.05 | 96.33 |
| SlowFast | 35.49 | 95.68 | 42.93 | 93.86 | |
| MViT | 31.91 | 93.26 | 40.62 | 92.03 |
| Dataset | Type of Lateral Connection | Top-1 | Top-5 |
|---|---|---|---|
| Rolandseck Daylight | fast to slow | 69.16 | 96.31 |
| no connection | 65.50 | 95.70 | |
| medium (before merging) to slow | 66.74 | 94.32 | |
| medium (after merging) to slow | 68.26 | 96.00 | |
| Bavarian Forest Daylight | fast to slow | 46.39 | 97.24 |
| no connection | 45.71 | 97.94 | |
| medium (before merging) to slow | 51.89 | 96.21 | |
| medium (after merging) to slow | 46.38 | 96.92 | |
| Bavarian Forest Nighttime | fast to slow | 43.05 | 96.33 |
| no connection | 42.35 | 96.93 | |
| medium (before merging) to slow | 39.18 | 95.10 | |
| medium (after merging) to slow | 41.70 | 95.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schindler, F.; Steinhage, V.; van Beeck Calkoen, S.T.S.; Heurich, M. Action Detection for Wildlife Monitoring with Camera Traps Based on Segmentation with Filtering of Tracklets (SWIFT) and Mask-Guided Action Recognition (MAROON). Appl. Sci. 2024, 14, 514. https://doi.org/10.3390/app14020514
Schindler F, Steinhage V, van Beeck Calkoen STS, Heurich M. Action Detection for Wildlife Monitoring with Camera Traps Based on Segmentation with Filtering of Tracklets (SWIFT) and Mask-Guided Action Recognition (MAROON). Applied Sciences. 2024; 14(2):514. https://doi.org/10.3390/app14020514
Chicago/Turabian StyleSchindler, Frank, Volker Steinhage, Suzanne T. S. van Beeck Calkoen, and Marco Heurich. 2024. "Action Detection for Wildlife Monitoring with Camera Traps Based on Segmentation with Filtering of Tracklets (SWIFT) and Mask-Guided Action Recognition (MAROON)" Applied Sciences 14, no. 2: 514. https://doi.org/10.3390/app14020514
APA StyleSchindler, F., Steinhage, V., van Beeck Calkoen, S. T. S., & Heurich, M. (2024). Action Detection for Wildlife Monitoring with Camera Traps Based on Segmentation with Filtering of Tracklets (SWIFT) and Mask-Guided Action Recognition (MAROON). Applied Sciences, 14(2), 514. https://doi.org/10.3390/app14020514