3.1. SC-YOLOv8 Network with Soft-Pooling and Attention Mechanism
Building upon the strengths inherited from the previous YOLO series networks, the YOLOv8 network significantly improves the overall detection performance through further optimization of the network structure. It has gained widespread application in various object detection tasks due to its efficient real-time processing and network architecture. The overall structure of the YOLOv8 network can be divided into three parts: the backbone network, the neck network, and the detection head.
The backbone network functions as the feature extraction component, aiming to perform preliminary feature extraction on the input image and generate three different scales of feature maps for subsequent use.
The neck network is located between the backbone network and the detection head, and its role is to combine the feature information of the three feature maps extracted by the backbone network to realize the retention of features and extract more detailed information, and the neck network will output three new feature maps.
The detection head employs the features extracted by the preceding networks to make predictions, producing the final output of the YOLOv8 network.
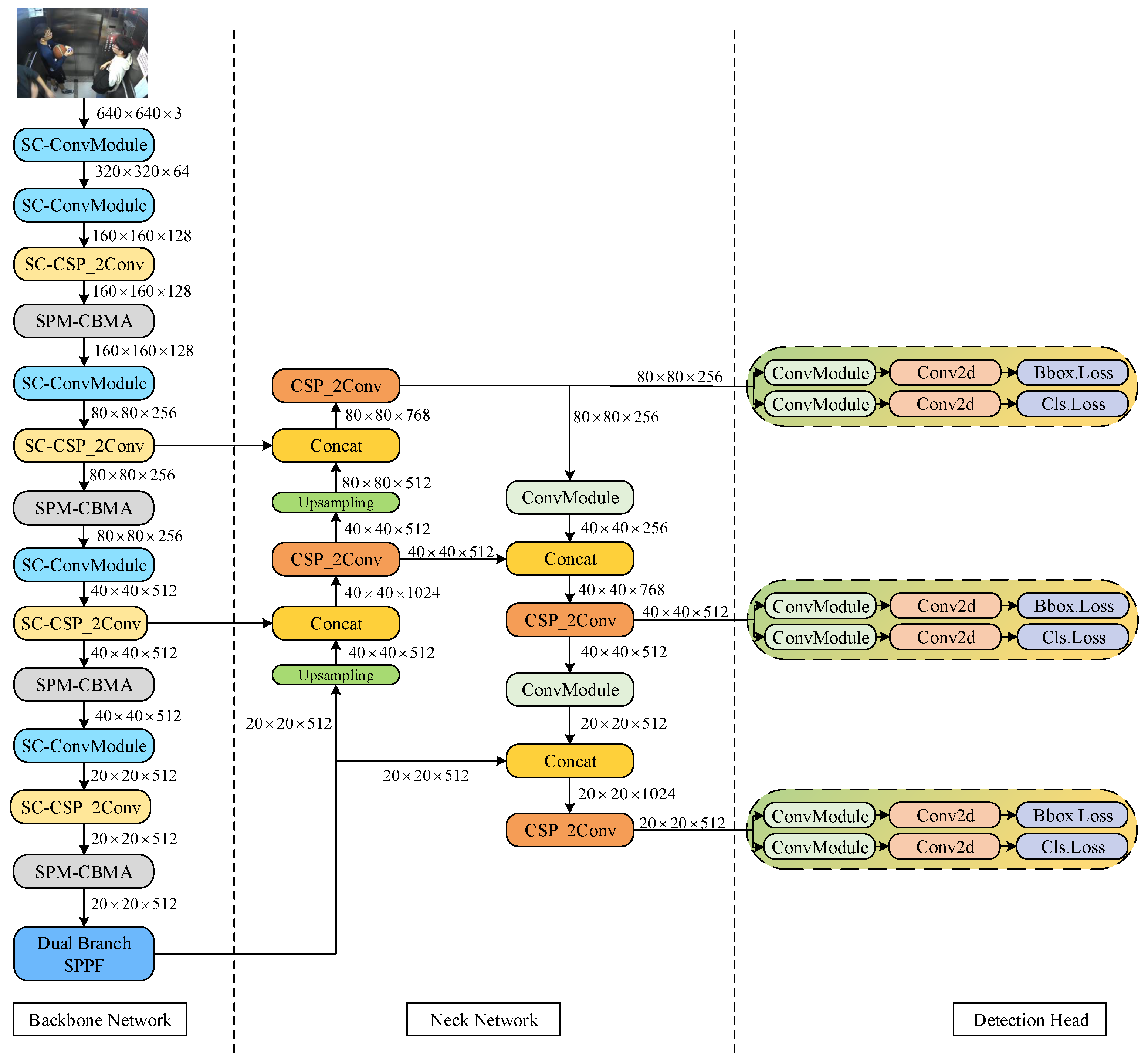
This paper aims to optimize the feature extraction process of the YOLOv8 backbone network, and consequently, the enhancements to the YOLOv8 network are primarily focused on the backbone network. The modified YOLOv8 network structure proposed in this paper is depicted in
Figure 1.
First, we propose an SC-ConvModule, which reduces spatial and channel redundancy between features during convolution operations by replacing the standard convolution of the ConvModule in the YOLOv8 backbone network with SCConv. Simultaneously, improvements are proposed for the SPP-Fast module in the YOLOv8 network. In the original SPP-Fast module, the use of max-pooling operations may lead to partial loss of local information. To solve this problem, we introduce soft-pooling branches to build a dual-branch SPP-Fast module to fully extract feature information. To further enhance the network performance, we embedded a newly designed SPM-CBAM module in the YOLOv8 backbone network. We improve the CBAM (convolutional block attention mechanism) module by combining a multi-scale depth-separable convolutional kernel and soft-pooling techniques to more effectively regulate channel attention and spatial attention. This innovation aims to enhance the model’s adaptability to different scales and features, thus improving the accuracy and robustness of target detection. In summary, this paper is dedicated to optimizing the feature extraction and attention mechanism of the YOLOv8 network through several module and technique improvements, aiming to achieve a higher level of performance.
3.2. Spatial and Channel Reconstruction Convolution
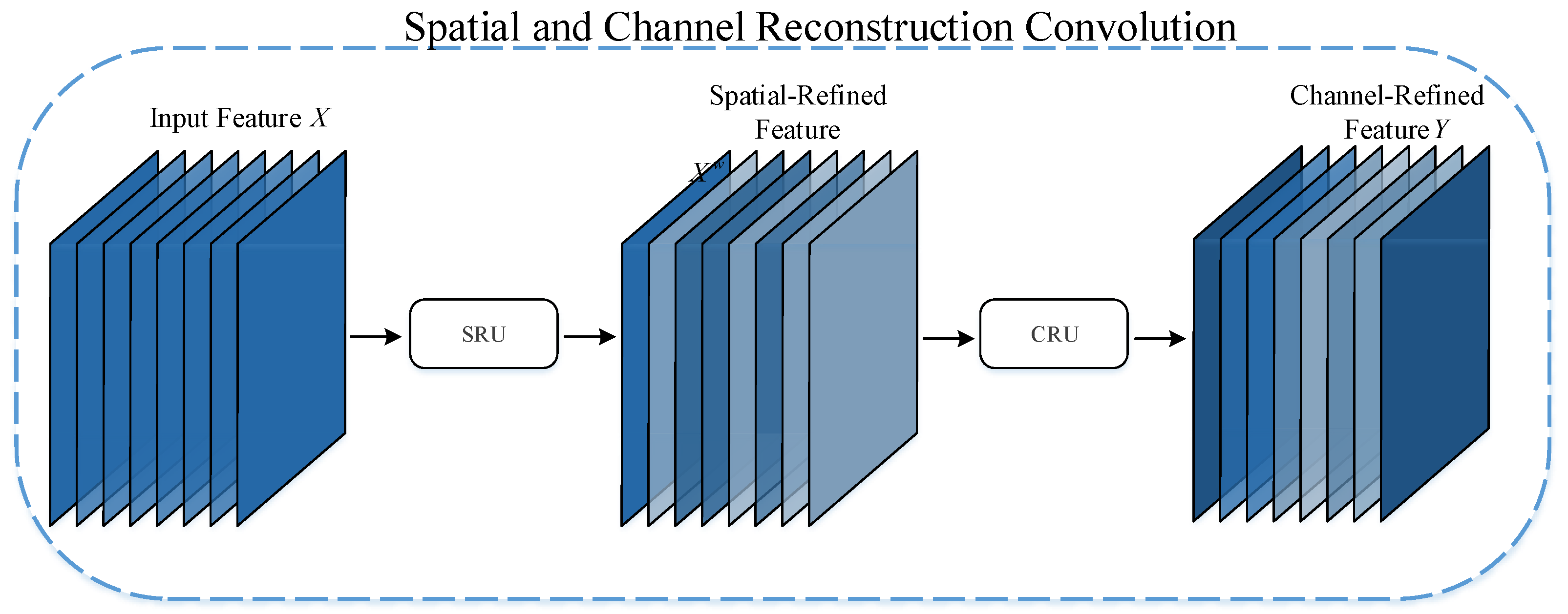
The background of elevator surveillance images is complex, and the standard convolutional kernel has limitations in processing elevator surveillance images because the standard convolutional kernel operates on the entire input image and fails to focus on specific regions and channels effectively. This convolutional operation suffers from redundancy of spatial and channel information in complex scenes, which, in turn, leads to degradation of model performance. Specifically, the standard convolutional kernel is unable to differentiate between important and minor regions in the image, and is also unable to effectively identify which channels are critical in the image. This results in the model consuming a large amount of computational resources to process unnecessary information when processing elevator surveillance images. Therefore, in this paper, we propose SC-ConvModule by replacing the standard convolution of the ConvModule of the YOLOv8 network using SCConv. As shown in
Figure 2, SCConv [
19] consists of a spatial reconstruction unit (SRU) and a channel reconstruction unit (CRU). The SRU separates features with rich information from those with less information, then reconstructs them to enhance representative features and reduce spatial redundancy in the input features. On the other hand, CRU employs a split–transform–fuse method to reduce channel redundancy. The combination of SRU and CRU in the SCConv module aims to enhance the adaptability and generalization performance of the YOLOv8 network, particularly in dealing with the challenging background and various interference factors present in elevator surveillance images.
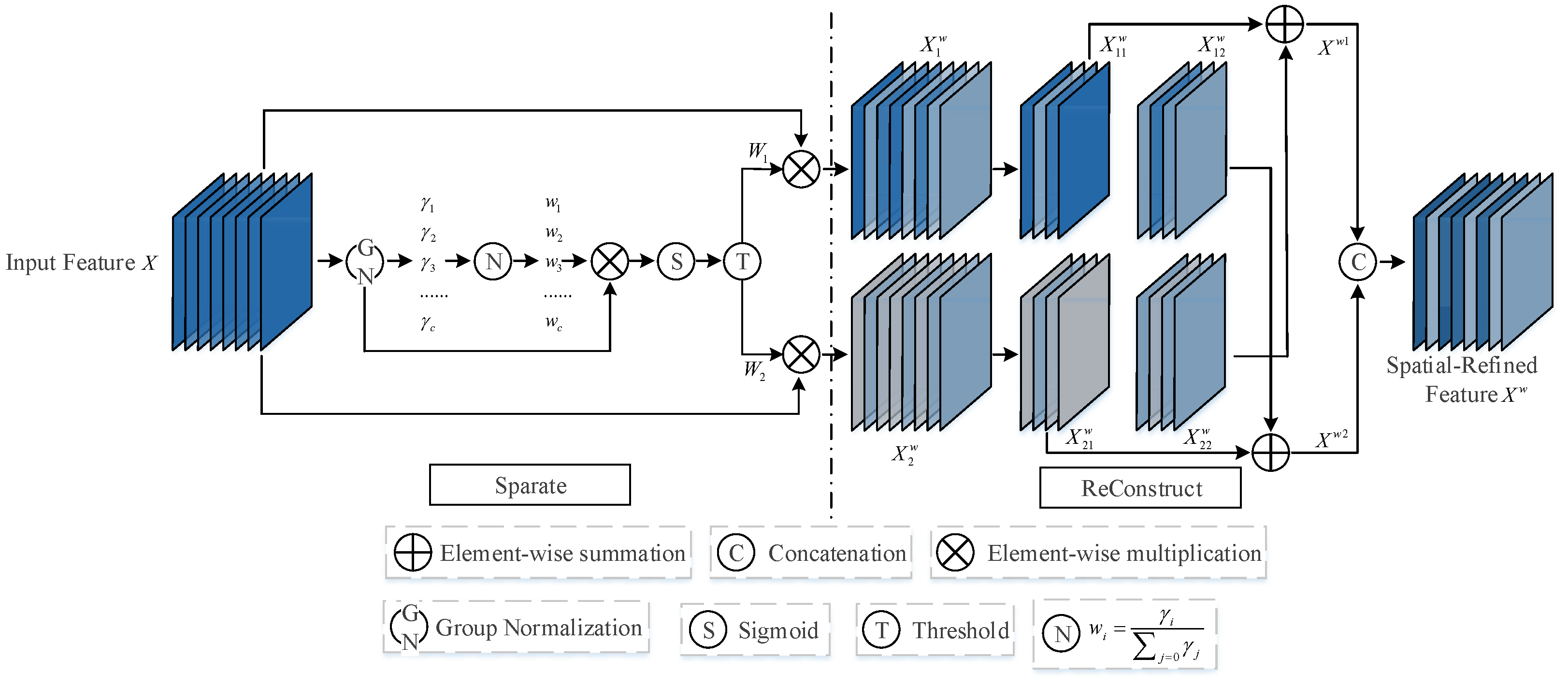
As shown in
Figure 3, the SRU reduces spatial redundancy in the input features through separation and reconstruction. The purpose of the separation operation is to separate those feature maps that are rich in spatial information from those with less spatial information. SRU begins by utilizing the scaling factor in the group normalization (GN) layer to assess the information content of different feature maps. The specific calculation of the GN layer is shown in Equation (
1).
where
X represents the input feature map, and
and
represent the mean and standard deviation of the feature map
X, respectively.
is a small positive constant added for the stability of the division.
and
are trainable affine transformations.
The trainable parameter
in the GN layer is used to measure the spatial pixel variance for each batch and channel. The more spatially rich the information, reflecting larger spatial pixel changes, the larger
becomes. The normalized correlation weight
of
is used to represent the importance of different feature maps, calculated in Equation (
2).
where
C is the number of channels in the input feature map.
Afterwards, the re-weighted feature map values by
are mapped through the sigmoid function to the range
and filtered by a threshold. We set weights higher than the threshold to 1 to obtain informative weights
. Additionally, weights higher than the threshold are set to 0 to obtain non-informative weights
. The specific calculation of
is as shown in Equation (
3).
Finally, the input feature map
X is multiplied by both
and
, respectively, resulting in the separation of the input feature map
X into an information-rich feature map
and a redundant feature map
with almost no information. The computation of feature maps
and
is as shown in Equation (
4).
where, ⊗ represents element-wise multiplication.
The reconstruction operation involves using a cross-reconstruction method to obtain features maps
and
by combining an information-rich feature map
with an information-poor feature map
. Then, the feature maps
and
are concatenated to obtain the spatially refined feature map
. The specific calculations for the reconstruction operation are as shown in Equation (
5).
where,
represents the split operation along the channel. ⊕ represents element-wise summation. ∪ represents concatenation.
and
are the feature maps obtained by splitting
along the channels, while
and
are the feature maps obtained by splitting
along the channels.
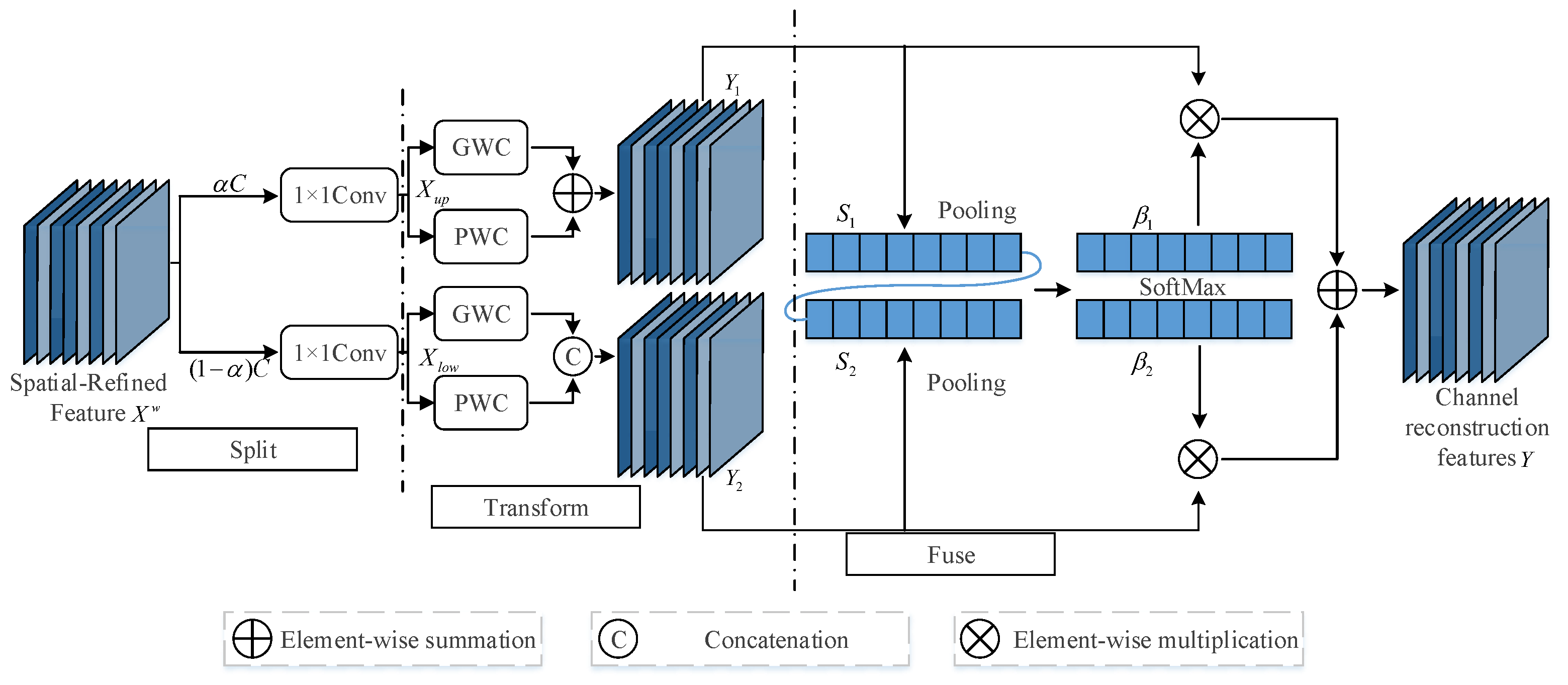
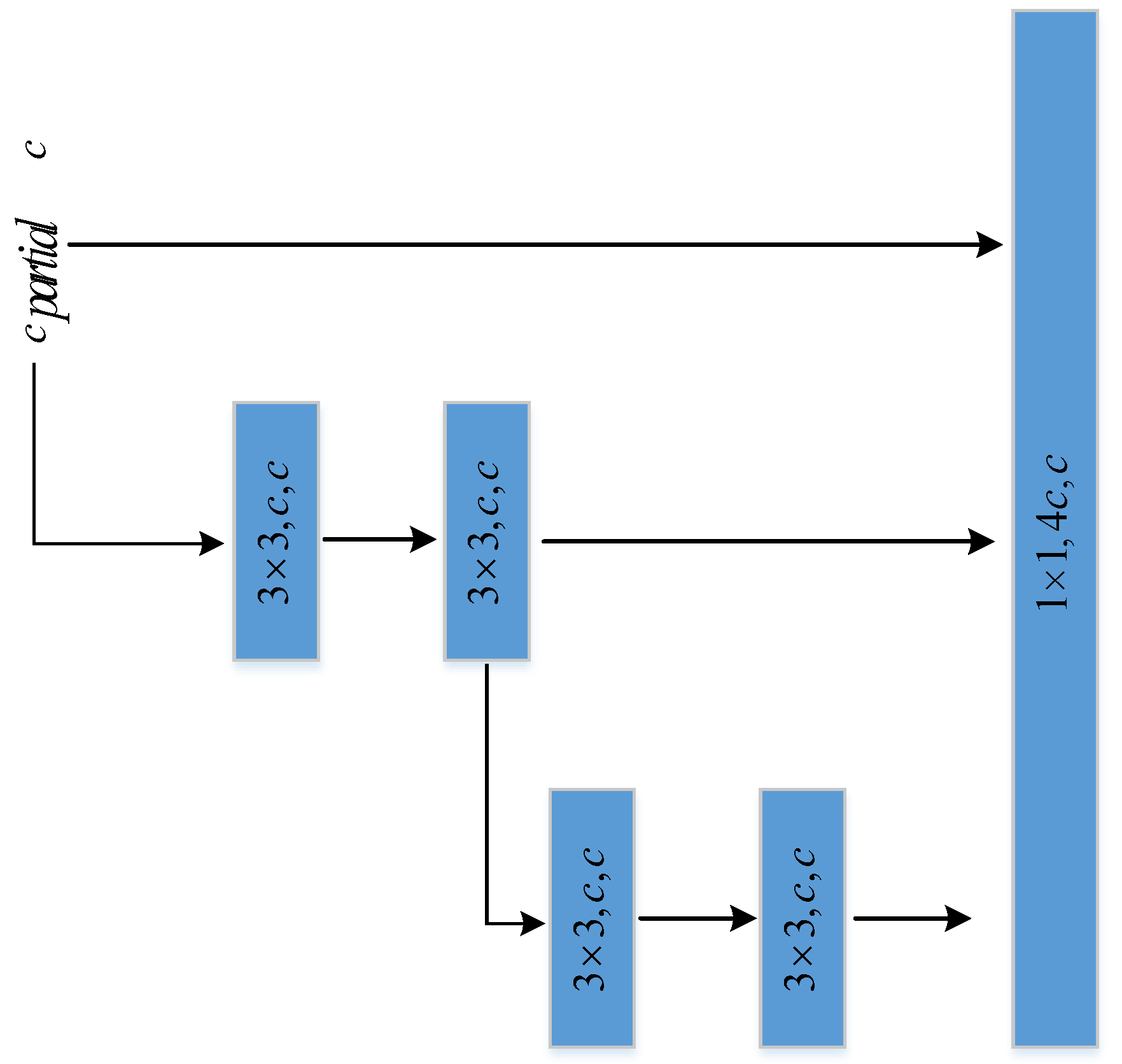
As shown in
Figure 4, the CRU is implemented through three operations: split, transform, and fuse. For the feature map
processed by SRU, the channels of
are first divided into two parts, namely, the
channel and the
channel, where
. Then, a
convolution is applied to compress the channels of the feature map. At this point, the feature map
is divided into the feature map
and the feature map
.
For
, group convolution and pointwise convolution are employed, and the outputs are summed to obtain the feature map
. The specific calculations are as in Equation (
6).
where
represents the group convolution, and
represents the pointwise convolution.
Group convolution can significantly reduce the number of model parameters and the amount of computation [
20], but it will cut off the flow of information between channel groups. The cutting off of channel groups causes the network to lose some context information when learning features. To compensate for this loss of information, pointwise convolution is introduced to promote the flow of information between feature channels [
21]. Pointwise convolution performs convolution operations on feature channels at each location, which is conducive to the global information transmission between features.
For the feature map
, a
pointwise convolution is applied to generate a feature map with shallow hidden details. Subsequently, the generated feature map is concatenated with the feature map
to obtain the feature map
. The specific calculations are as Equation (
7).
Next, global average-pooling is used to process
and
to collect global spatial information
with channel statistics. The calculation method is as Equation (
8).
where
H represents the length of the feature maps
and
, and
W represents the width of the feature maps
and
.
Then,
is stacked with
, and a channel-wise soft attention operation is applied to generate the feature importance vectors
and
. Finally, feature
and
features are combined to obtain the channel refinement feature
Y, guided by the feature importance vectors
and
. The calculation method is as Equation (
9).
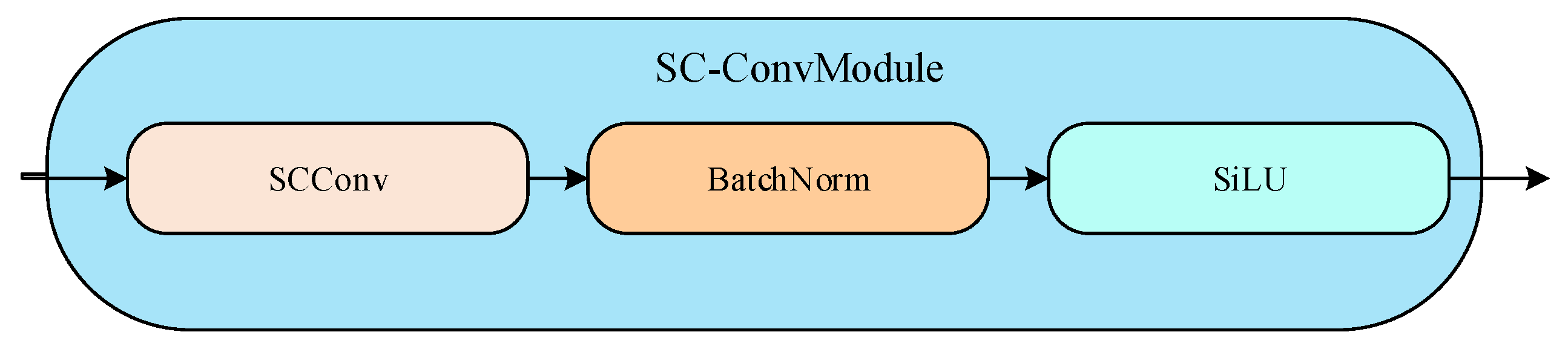
3.3. SC-ConvModule
The SC-ConvModule consists of a sequential combination of SCConv, the batch normalization layer, and the sigmoid linear unit (SiLU) activation function, as depicted in
Figure 5.
SCConv reduces the storage space and computational cost of the YOLOv8 network by reducing the spatial and channel redundancy between features in the convolutional neural network, while improving the accuracy and generalization of the YOLOv8 network for object detection tasks.
SC-ConvModule further improves the stability and convergence speed of the network through the batch normalization layer. Batch normalization improves the stability of model training by performing a normalization operation on the inputs of each batch, i.e., each input is subtracted from the mean of the inputs of that batch and divided by the standard deviation, which keeps the distribution of inputs of each layer of the network small, helps prevent excessive growth or reduction in the gradient, and improves the stability of model training. In addition, batch normalization also reduces the sensitivity to the initialization parameters, making it easier for the neural network to converge to a suitable solution.
SC-ConvModule introduces nonlinear factors through the SiLU activation function layer to enhance the expressive power of the network.The unboundedness and smoothing of the SiLU function prevents the problem of vanishing gradients in neural networks, allowing the network to be more flexible in adapting to different features. In addition, the non-monotonicity of the SiLU function enables it to handle more complex feature mappings, thus helping the network to learn more complex feature representations [
22].
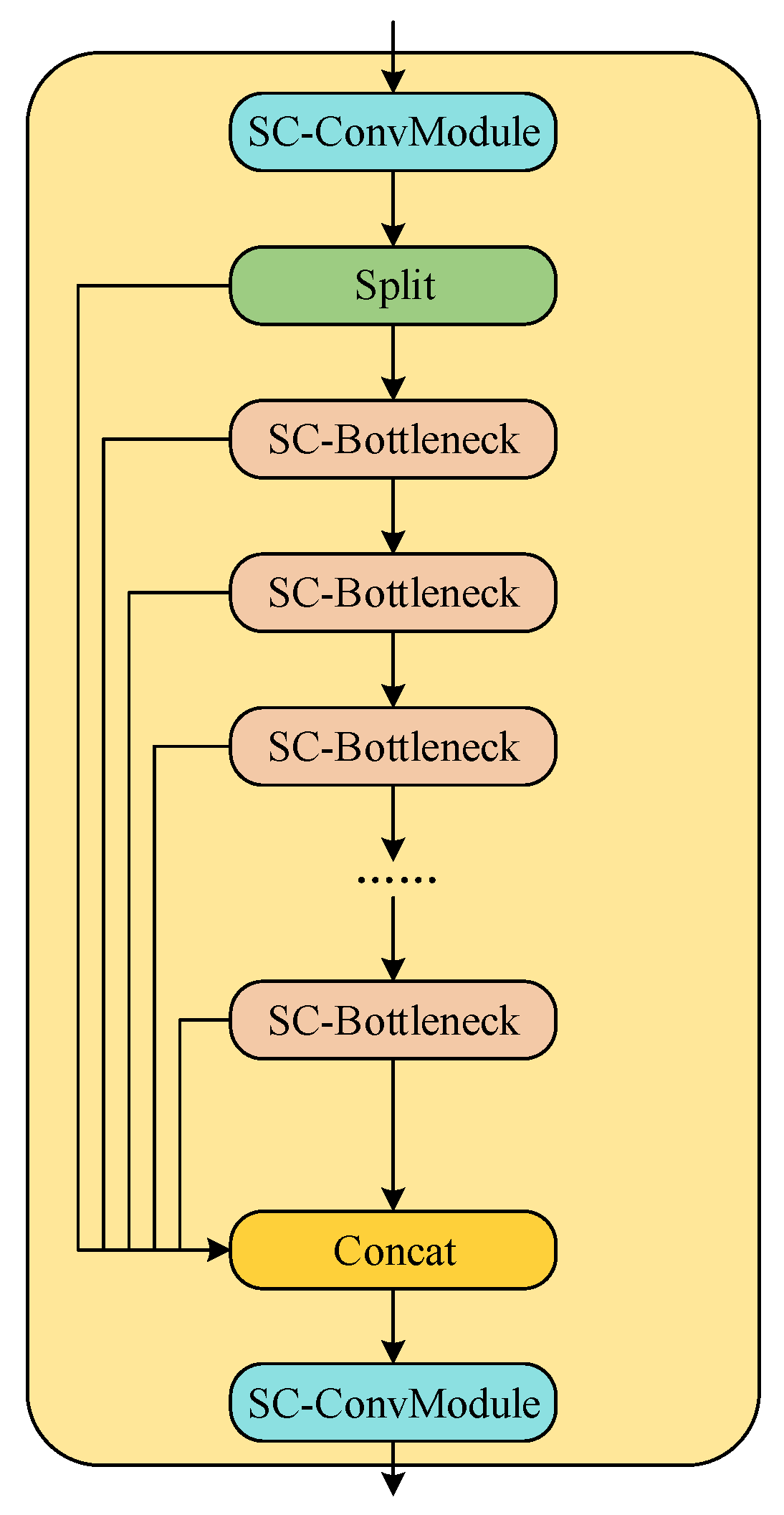
The CSP_2Conv module is the result of an improvement to the C3 module of the YOLOv5 network, and the key to this improvement is the introduction of extended efficient layer aggregation networks (ELANs) to effectively avoid the problem of deterioration in the network’s convergence during model scaling. As illustrated in
Figure 6, the ELAN structure is a layer-aggregation architecture with an effective gradient propagation path [
23]. It optimizes the gradient length of the entire network by utilizing a stack structure within the computation block. When the features are input into the CSP_2Conv module, they first undergo a convolution operation for channel integration, and the integrated feature map has a richer representation. The CSP_2Conv module incorporates parallel bottleneck layer structures, which diverge different dimensional feature map information and then merge them at the end of the module. Consequently, the CSP_2Conv module can obtain richer gradient information, and the backpropagation gradients can be more effectively transmitted to shallower feature maps. This enhances the feature extraction capability of the convolutional neural network while reducing the time consumption of memory access. As the ConvModule is also present within the CSP_2Conv module, it is replaced with the SC-ConvModule. The modified CSP_2Conv module is referred to as the SC-CSP_2Conv module, and its specific structure is illustrated in
Figure 7.
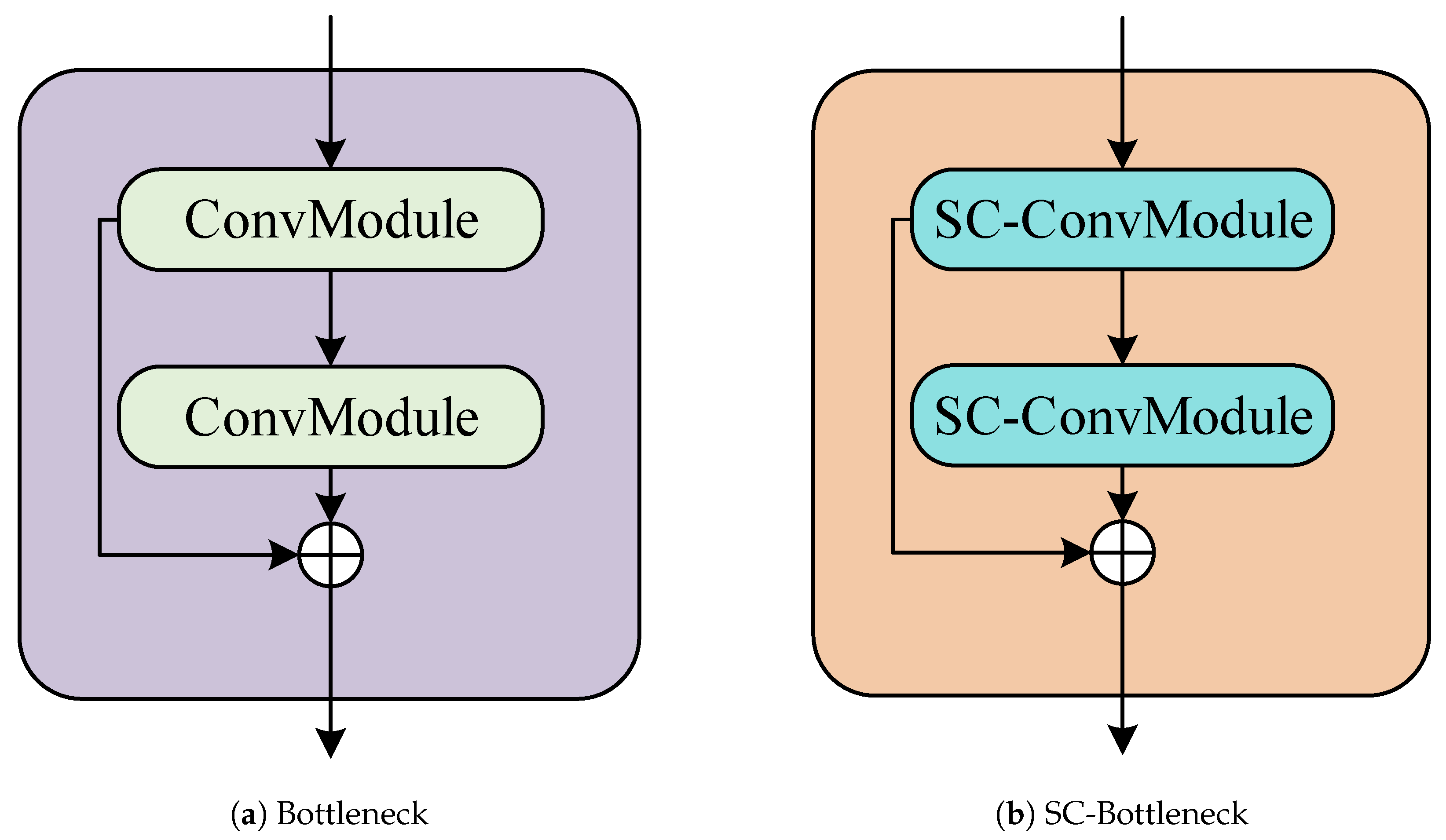
In YOLOv8, the bottleneck within the CSP_2Conv module consists of two ConvModules and is augmented with a skip connection, as illustrated in
Figure 8a. The primary function of the bottleneck is to propagate low-level feature information [
24], enabling effective learning and convergence during the training process, even in the case of a deep network model. It leverages the residual concept, conducting two convolutional operations on the original input to extract features, followed by element-wise addition with the original input. The advantage of the residual concept lies in its ability to preserve the essential features of the original input and mitigate the vanishing gradient problem. The bottleneck employs multiple small convolutional kernels to replace a large convolutional kernel, deepening the network and simultaneously reducing the number of parameters compared to the original structure. This not only enhances the depth of the network but also decreases the overall parameter count. This paper replaces the ConvModule in the bottleneck with the SC-ConvModule. The transformed bottleneck is referred to as the SC-Bottleneck, as illustrated in
Figure 8b.
3.4. Dual-Branch SPP-Fast Module
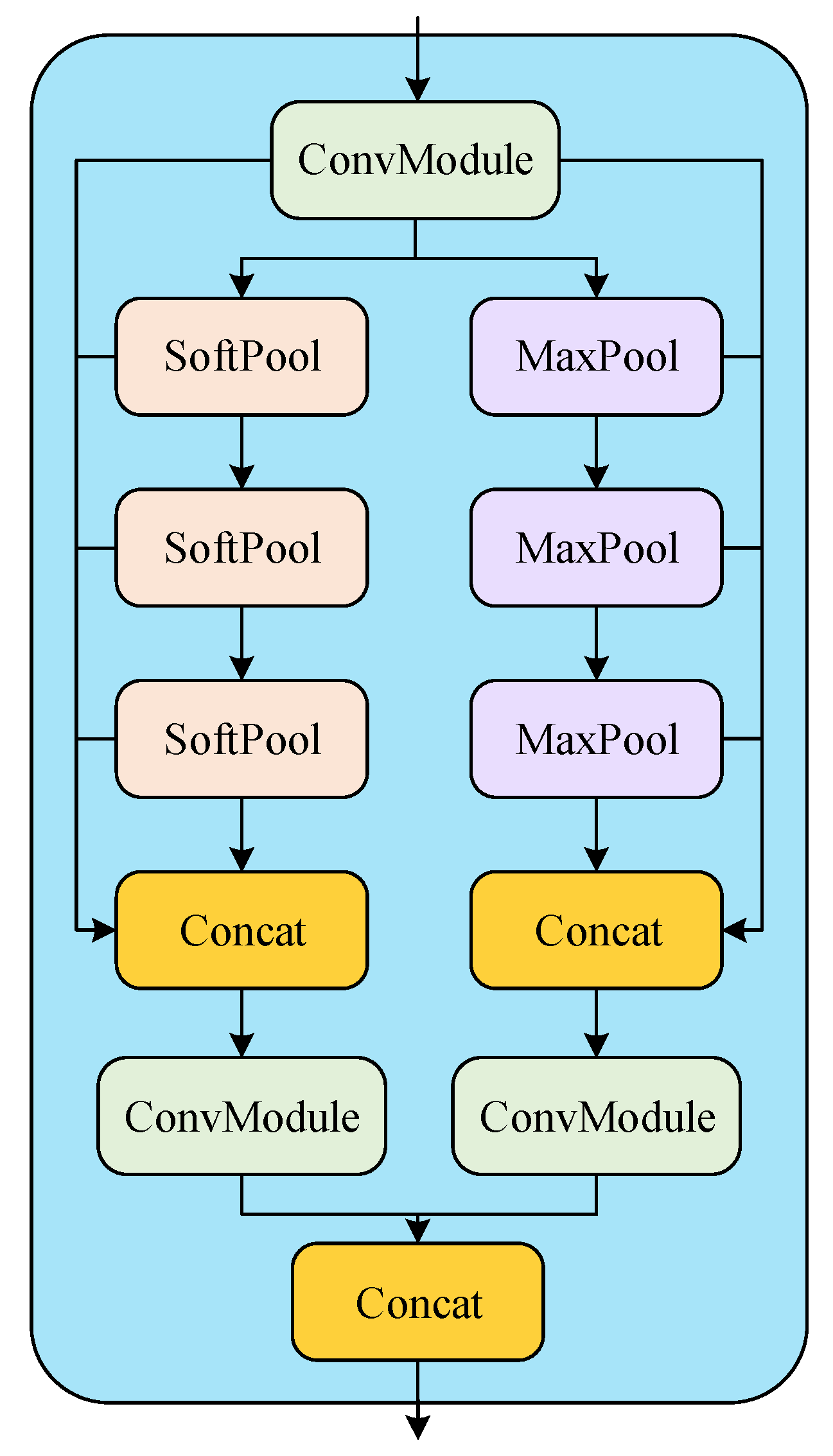
The SPP-Fast module is an important feature extraction module in the YOLOv8 backbone network, and is called the SPP-Fast module because of its computational speed advantage over the spatial pyramid pooling (SPP) module. The SPP-Fast module is optimized from the SPP module and uses a serial approach to the max-pooling operation and splices the outputs from each location when the last max-pooling is complete. The SPP-Fast module extracts features using only the max-pooling operation, which can lead to the loss of some local information. In the elevator scene, noise adversely affects the local information in the image, while uneven illumination leads to changes in the global features. To address this problem this paper proposes a dual-branch SPP-Fast module by introducing soft-pooling branches in the SPP-Fast module. This modification aims to enhance feature extraction by merging the soft-pooling operations, thus mitigating the potential loss of local information.
In the dual-branch SPP-Fast module, the soft-pooling operation selectively preserves pixels based on the pixel weights in the feature map [
25]. Soft-pooling achieves this by obtaining normalized results through the SoftMax function, and then retaining pixels according to the weights of the features. This ensures that more crucial features contribute more significantly, addressing the issue of information loss often associated with max-pooling. Soft-pooling enables the thorough utilization of any activation factor within the pooling kernel, while incurring only a lesser additional computational cost. It not only enhances the network model’s ability to discriminate between similar feature information but also preserves feature information across the entire receptive field during soft-pooling operations. This helps minimize feature information loss during the pooling process, thereby improving the detection accuracy of the algorithm. During backpropagation, soft-pooling accumulates activations in an exponentially weighted manner, facilitating continuous updates to gradient values. The calculation method for soft-pooling is outlined in Equations (
10) and (
11).
where
represents the weight of the candidate region,
a represents the weight of the activation mapping, and
represents the feature map obtained by multiplying and adding weight
with activation mapping
. The significance of weights lies in the fact that a larger value indicates a more crucial pixel, increasing the likelihood of its retention. The advantage of soft-pooling lies in its ability to effectively preserve image information even when the number of features is reduced.
As shown in
Figure 9, the dual-branch SPP-Fast module proposed in this paper can be divided into two parts: one part comprises the max-pooling branch, while the other part consists of the soft-pooling branch. The specific calculation process is detailed in Equations (
12)–(
14).
Here, and represent the outputs of the max-pooling branch and the soft-pooling branch, respectively. represents the output after max-pooling, and represents the output after soft-pooling. represents the standard convolution operation.
3.5. Soft-Pooling and Multi-Scale Convolution CBAM
The visual attention mechanism has significant advantages in the elevator passenger detection task, which can dynamically weight the features of the input image, and, therefore, can help to localize and identify the objects in the image in the object detection task. The CBAM attention mechanism is a typical hybrid attention mechanism that sequentially applies channel attention mechanism (CAM) and spatial attention mechanism (SAM) modules. Compared to using channel attention or spatial attention independently, CBAM can achieve better results [
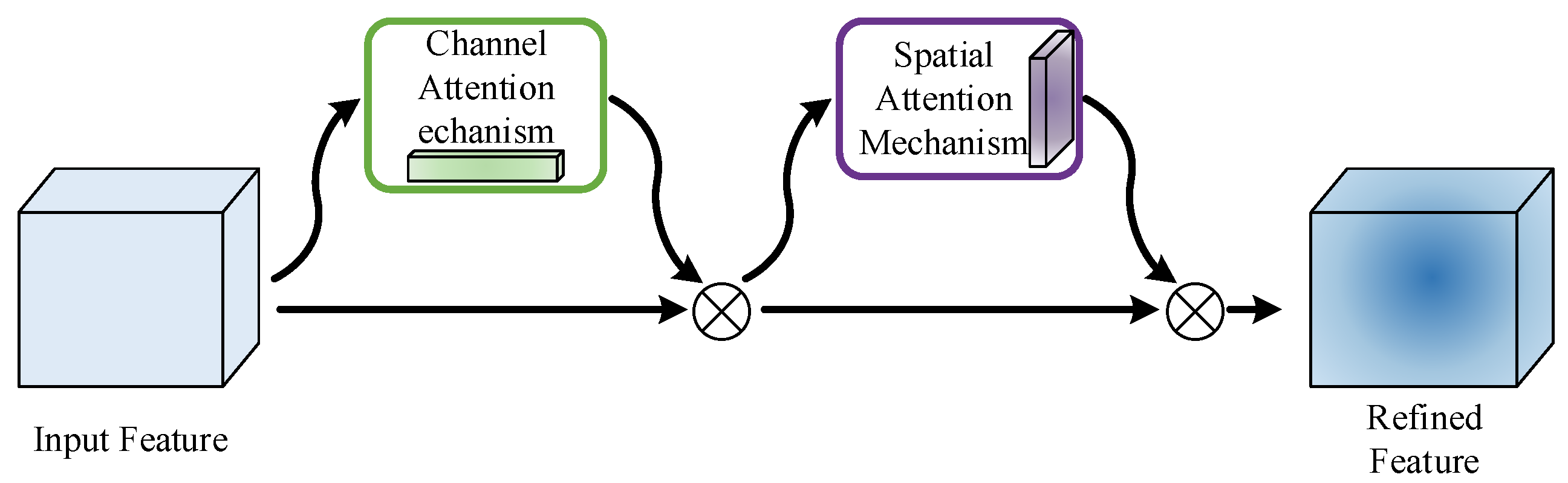
26]. As illustrated in
Figure 10, the CBAM attention mechanism takes a given intermediate feature map
as input. First, the CAM module aggregates the spatial information of the feature map through operations like average-pooling and max-pooling. Subsequently, the spatial information is processed through a shared multilayer perceptron (Share MLP) to generate a one-dimensional channel attention map
.
is then element-wise multiplied with the input feature map
F, and the channel attention values are broadcast along the spatial dimension to obtain refined features
with channel attention. The SAM module processes
to generate a spatial attention map
. The final output feature
is obtained by element-wise multiplication of
and
. The convolutional module receives the spatial attention map for channel mixing. Finally, the refined features are obtained as output by element-wise multiplication of the channel mixing result with channel priors, as detailed in Equations (
15) and (
16).
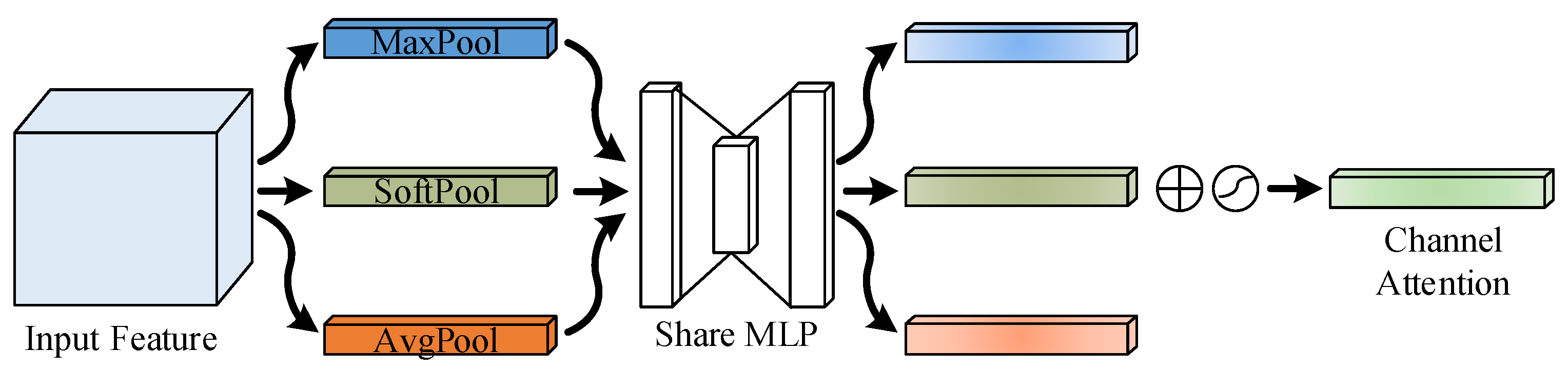
In the CAM module, the processing of the feature map involves the use of average-pooling and max-pooling operations to aggregate spatial information. However, the max-pooling operation overlooks the influence of other elements in the pooling region on the result and, thus, may result in the loss of useful information. On the other hand, the average-pooling operation, while capable of preserving more information of the feature map, can result in the loss of discriminative information due to mutual cancellation of positive and negative activation values. To retain more useful information from the feature map, as shown in
Figure 11, this paper introduces soft-pooling operations into the CAM module. This addition aims to preserve more useful information. Assuming the input feature map to the CAM module proposed in this paper is denoted as
, the expression for the channel attention feature vector
of dimension
generated by the CAM module is as Equation (
17).
where
represents the max-pooling operation,
represents the soft-pooling operation,
stands for the average-pooling operation,
stands for the sigmoid activation function, and
stands for the Share MLP operation.
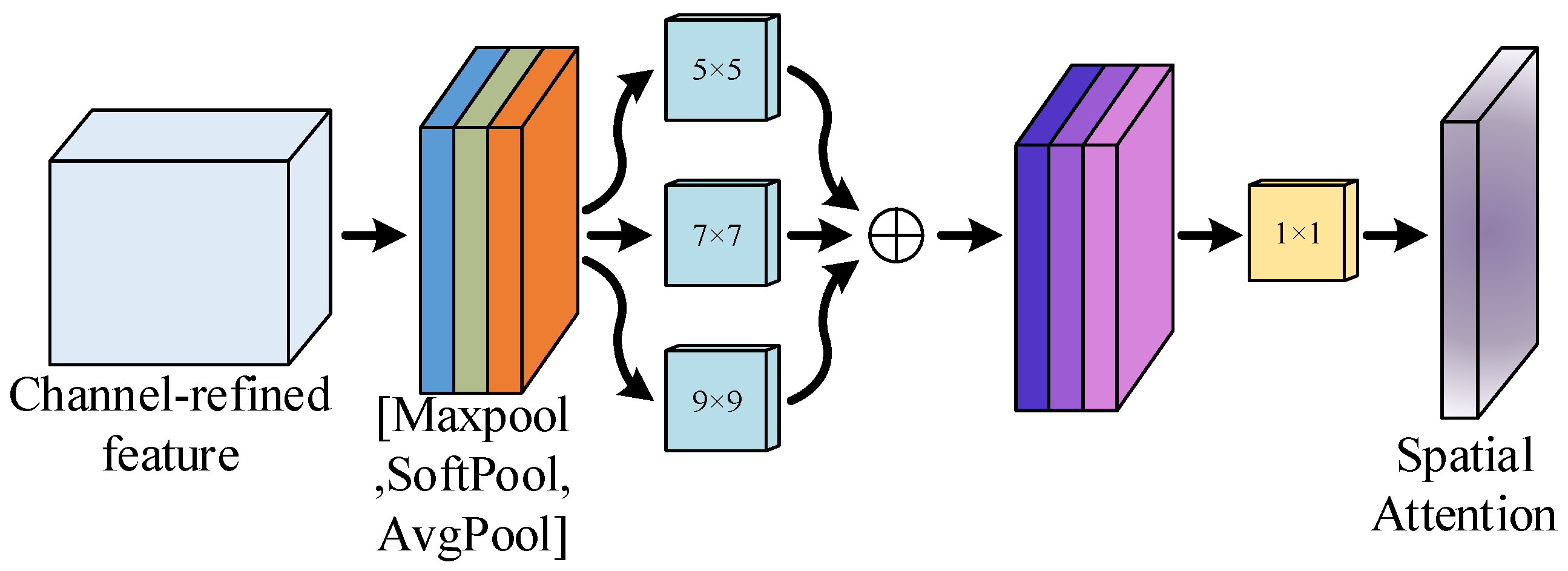
As depicted in
Figure 12, in the SAM module, this paper also incorporates soft-pooling operations. Considering that the SAM module employs a
convolutional kernel for feature map processing, which may lead to a uniform spatial attention weight distribution among channels, this paper addresses this by using multi-scale depth-wise separable convolutions instead of the
convolutional kernel in the SAM module. The calculation of spatial attention can be described as Equation (
18).
where
represents depthwise separable convolution, and
represents
standard convolution.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}