

Practical Medical Image Generation with Provable Privacy Protection Based on Denoising Diffusion Probabilistic Models for High-Resolution Volumetric Images
 , , ,
, , ,
Abstract
:1. Introduction
2. Related Works
2.1. Deep Generative Models for High-Dimensional Data
2.2. Differential Privacy for Multidimensional Data
3. Methods
3.1. Score Matching and DDPMs
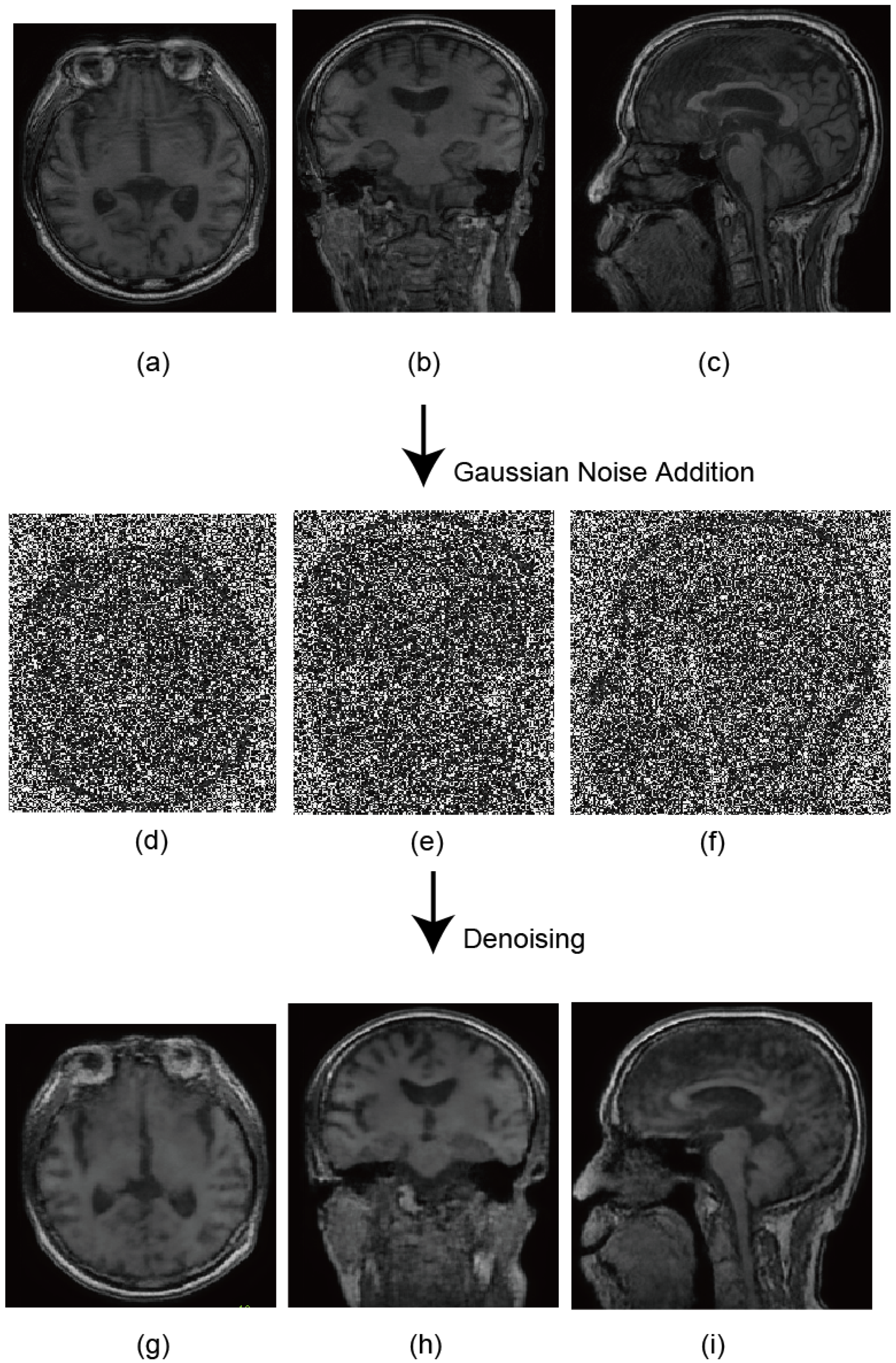
3.2. Scale Up to High-Resolution Volumetric Images by Model Unrolling
3.3. DP
3.4. Integration of DDPM and DP
4. Numerical Experiments
4.1. Preparation of Head MR Images
4.2. Training of DDPMs
5. Results
5.1. Unconditional Image Generation and Visual Evaluation
5.2. Conditional Image Generation and Equivalent Privacy Budget
6. Discussion
6.1. Novelty
6.2. Quality Evaluation by Medical Doctors
6.3. Limitation
6.4. Future Works
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CT | Computed Tomography |
| DDPM | Denoising Diffusion Probabilistic Models |
| GAN | Generative Adversarial Networks |
| LDP | Local Differential Privacy |
| MR | Magnetic Resonance |
| SGD | Stochastic Gradient Descent |
Appendix A. Network Architecture of the Proposed DDPM

Appendix B. All the Results of Evaluation by Three Medical Doctors

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case (Fake) | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Brain regions | ||||||
| Anterior commissure | 4 | 4 | 4 | 4 | 3 | 2 |
| Posterior commissure | 3 | 2 | 2 | 3 | 1 | 2 |
| Cerebral aqueduct | 2 | 1 | 2 | 2 | 1 | 1 |
| Tegmentum of midbrain | 3 | 3 | 3 | 3 | 3 | 3 |
| Cerebellar hemisphere sulcus | 1 | 2 | 2 | 2 | 2 | 3 |
| Cerebral peduncle | 4 | 4 | 4 | 4 | 3 | 3 |
| Corpus callosum | 4 | 4 | 4 | 4 | 4 | 4 |
| Third ventricle | 4 | 3 | 3 | 3 | 3 | 3 |
| Fourth ventricle | 4 | 5 | 4 | 5 | 4 | 5 |
| Lateral ventricle | 5 | 5 | 5 | 5 | 5 | 5 |
| Cortical white matter contrast | ||||||
| Hippocampus | 1 | 2 | 3 | 1 | 1 | 2 |
| Frontal lobe | 3 | 2 | 3 | 1 | 2 | 2 |
| Occipital lobe | 2 | 2 | 2 | 1 | 1 | 1 |
| Temporal lobe | 2 | 2 | 3 | 1 | 2 | 2 |
| Parietal lobe | 2 | 2 | 2 | 1 | 3 | 2 |
| Basal ganglia | 2 | 3 | 3 | 2 | 3 | 2 |
| Other regions | ||||||
| First cervical vertebra (C1) | 1 | 2 | 1 | 4 | 1 | 1 |
| Second cervical vertebra (C2) | 2 | 2 | 2 | 5 | 2 | 2 |
| Optic nerve | 1 | 5 | 3 | 4 | 2 | 2 |
| Extraocular muscles | 4 | 4 | 5 | 5 | 3 | 3 |
| Case (Fake) | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Brain regions | ||||||
| Anterior commissure | 3 | 2 | 2 | 1 | 2 | 2 |
| Posterior commissure | 2 | 1 | 2 | 2 | 1 | 1 |
| Cerebral aqueduct | 1 | 1 | 2 | 2 | 1 | 1 |
| Tegmentum of midbrain | 3 | 3 | 3 | 3 | 3 | 3 |
| Cerebellar hemisphere sulcus | 2 | 3 | 2 | 3 | 3 | 3 |
| Cerebral peduncle | 3 | 3 | 3 | 3 | 2 | 3 |
| Corpus callosum | 4 | 4 | 4 | 5 | 4 | 4 |
| Third ventricle | 5 | 4 | 4 | 4 | 4 | 4 |
| Fourth ventricle | 5 | 4 | 4 | 4 | 4 | 4 |
| Lateral ventricle | 5 | 4 | 4 | 4 | 4 | 4 |
| Cortical white matter contrast | ||||||
| Hippocampus | 2 | 2 | 3 | 2 | 3 | 2 |
| Frontal lobe | 3 | 1 | 3 | 1 | 1 | 1 |
| Occipital lobe | 3 | 2 | 2 | 1 | 1 | 1 |
| Temporal lobe | 3 | 2 | 2 | 2 | 3 | 2 |
| Parietal lobe | 3 | 2 | 2 | 1 | 2 | 1 |
| Basal ganglia | 2 | 2 | 3 | 2 | 2 | 2 |
| Other regions | ||||||
| First cervical vertebra (C1) | 1 | 2 | 2 | 2 | 2 | 1 |
| Second cervical vertebra (C2) | 2 | 2 | 3 | 3 | 2 | 2 |
| Optic nerve | 1 | 4 | 2 | 4 | 2 | 2 |
| Extraocular muscles | 3 | 3 | 2 | 4 | 2 | 2 |
| Case (Fake) | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Brain regions | ||||||
| Anterior commissure | 4 | 4 | 4 | 2 | 3 | 2 |
| Posterior commissure | 2 | 3 | 2 | 3 | 2 | 2 |
| Cerebral aqueduct | 2 | 2 | 2 | 2 | 2 | 3 |
| Tegmentum of midbrain | 2 | 2 | 2 | 2 | 3 | 3 |
| Cerebellar hemisphere sulcus | 3 | 4 | 4 | 3 | 3 | 3 |
| Cerebral peduncle | 5 | 5 | 5 | 5 | 5 | 5 |
| Corpus callosum | 5 | 5 | 5 | 5 | 5 | 5 |
| Third ventricle | 5 | 4 | 5 | 5 | 5 | 4 |
| Fourth ventricle | 5 | 3 | 3 | 3 | 4 | 4 |
| Lateral ventricle | 5 | 5 | 5 | 5 | 5 | 5 |
| Cortical white matter contrast | ||||||
| Hippocampus | 3 | 3 | 3 | 4 | 3 | 3 |
| Frontal lobe | 2 | 3 | 3 | 3 | 3 | 3 |
| Occipital lobe | 3 | 3 | 3 | 3 | 4 | 3 |
| Temporal lobe | 3 | 4 | 4 | 4 | 4 | 3 |
| Parietal lobe | 3 | 3 | 3 | 3 | 4 | 3 |
| Basal ganglia | 2 | 3 | 3 | 4 | 4 | 4 |
| Other regions | ||||||
| First cervical vertebra (C1) | 3 | 2 | 5 | 5 | 5 | 5 |
| Second cervical vertebra (C2) | 3 | 2 | 3 | 3 | 4 | 4 |
| Optic nerve | 2 | 5 | 2 | 4 | 2 | 2 |
| Extraocular muscles | 4 | 3 | 2 | 4 | 3 | 3 |
References
- Dwork, C. Differential privacy. In Proceedings of the International Colloquium on Automata, Languages, and Programming ICALP 2006, Venice, Italy, 10–14 July 2006; pp. 1–12. [Google Scholar]
- Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; Naor, M. Our data, ourselves: Privacy via distributed noise generation. In Proceedings of the Advances in Cryptology-EUROCRYPT 2006: 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; pp. 486–503. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Croft, W.L.; Sack, J.R.; Shi, W. Differentially private facial obfuscation via generative adversarial networks. Future Gener. Comput. Syst. 2022, 129, 358–379. [Google Scholar] [CrossRef]
- Croft, L.; Sack, J.R.; Shi, W. Obfuscation of images via differential privacy: From facial images to general images. Peer Netw. Appl. 2021, 14, 1705–1733. [Google Scholar] [CrossRef]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-Based Generative Modeling through Stochastic Differential Equations. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Shibata, H.; Hanaoka, S.; Nomura, Y.; Nakao, T.; Takenaga, T.; Hayashi, N.; Abe, O. On the Simulation of Ultra-Sparse-View and Ultra-Low-Dose Computed Tomography with Maximum a Posteriori Reconstruction Using a Progressive Flow-Based Deep Generative Model. Tomography 2022, 8, 2129–2152. [Google Scholar] [CrossRef] [PubMed]
- Dinh, L.; Krueger, D.; Bengio, Y. Nice: Non-linear independent components estimation. arXiv 2014, arXiv:1410.8516. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using real nvp. arXiv 2016, arXiv:1605.08803. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1x1 convolutions. Adv. Neural Inf. Process. Syst. 2018, 31, 10236–10245. [Google Scholar]
- Khader, F.; Müller-Franzes, G.; Tayebi Arasteh, S.; Han, T.; Haarburger, C.; Schulze-Hagen, M.; Schad, P.; Engelhardt, S.; Baeßler, B.; Foersch, S. Denoising diffusion probabilistic models for 3D medical image generation. Sci. Rep. 2023, 13, 7303. [Google Scholar] [CrossRef] [PubMed]
- Bieder, F.; Wolleb, J.; Durrer, A.; Sandkuehler, R.; Cattin, P.C. Memory-Efficient 3D Denoising Diffusion Models for Medical Image Processing. In Proceedings of the Medical Imaging with Deep Learning, Nashville, TN, USA, 10–12 July 2023. [Google Scholar]
- Dorjsembe, Z.; Odonchimed, S.; Xiao, F. Three-dimensional medical image synthesis with denoising diffusion probabilistic models. In Proceedings of the Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022. [Google Scholar]
- Sun, L.; Chen, J.; Xu, Y.; Gong, M.; Yu, K.; Batmanghelich, K. Hierarchical amortized GAN for 3D high resolution medical image synthesis. IEEE J. Biomed. Health Inform. 2022, 26, 3966–3975. [Google Scholar] [CrossRef] [PubMed]
- Fan, L. Image pixelization with differential privacy. In Proceedings of the IFIP Annual Conference on Data and Applications Security and Privacy, Bergamo, Italy, 16–18 July 2018; pp. 148–162. [Google Scholar]
- Li, T.; Clifton, C. Differentially private imaging via latent space manipulation. arXiv 2021, arXiv:2103.05472. [Google Scholar]
- Liu, B.; Ding, M.; Xue, H.; Zhu, T.; Ye, D.; Song, L.; Zhou, W. DP-Image: Differential Privacy for Image Data in Feature Space. arXiv 2021, arXiv:2103.07073. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Song, Y.; Ermon, S. Generative modeling by estimating gradients of the data distribution. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Jabri, A.; Fleet, D.J.; Chen, T. Scalable Adaptive Computation for Iterative Generation. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 14569–14589. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; pp. 1–19. [Google Scholar]
- Fujita, S.; Mori, S.; Onda, K.; Hanaoka, S.; Nomura, Y.; Nakao, T.; Yoshikawa, T.; Takao, H.; Hayashi, N.; Abe, O. Characterization of Brain Volume Changes in Aging Individuals With Normal Cognition Using Serial Magnetic Resonance Imaging. JAMA Netw. Open 2023, 6, e2318153. [Google Scholar] [CrossRef] [PubMed]
- Leandrou, S.; Petroudi, S.; Kyriacou, P.A.; Reyes-Aldasoro, C.C.; Pattichis, C.S. Quantitative MRI brain studies in mild cognitive impairment and Alzheimer’s disease: A methodological review. IEEE Rev. Biomed. Eng. 2018, 11, 97–111. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Pawar, K.; Ekanayake, M.; Pain, C.; Zhong, S.; Egan, G.F. Deep learning for image enhancement and correction in magnetic resonance imaging—State-of-the-art and challenges. J. Digit. Imaging 2023, 36, 204–230. [Google Scholar] [CrossRef] [PubMed]
- Denoising Diffusion Probabilistic Model, in PyTorch. Available online: https://github.com/lucidrains/denoising-diffusion-pytorch/releases/tag/1.8.5 (accessed on 12 March 2024).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]



| Stages | Criteria |
|---|---|
| 1 | The structure is invisible. |
| 2 | The structure is slightly identifiable. |
| 3 | The structure is visible but not sufficient. |
| 4 | The structure is visible as in real cases |
| with the resolution of . | |
| 5 | The structure is well visible as in real cases |
| with the resolution of . |
| Doctor | A | B | C | Ave. () |
|---|---|---|---|---|
| Brain regions | ||||
| Anterior commissure | 5.0 | 5.0 | 5.0 | 5.0 |
| Posterior commissure | 5.0 | 5.0 | 5.0 | 5.0 |
| Cerebral aqueduct | 5.0 | 5.0 | 5.0 | 5.0 |
| Tegmentum of midbrain | 5.0 | 5.0 | 5.0 | 5.0 |
| Cerebellar hemisphere | 5.0 | 5.0 | 4.7 | 4.9 |
| sulcus | ||||
| Cerebral peduncle | 5.0 | 5.0 | 5.0 | 5.0 |
| Corpus callosum | 5.0 | 5.0 | 5.0 | 5.0 |
| Third ventricle | 5.0 | 5.0 | 5.0 | 5.0 |
| Fourth ventricle | 5.0 | 5.0 | 5.0 | 5.0 |
| Lateral ventricle | 5.0 | 5.0 | 5.0 | 5.0 |
| Cortical white matter contrast | ||||
| Hippocampus | 5.0 | 5.0 | 4.8 | 4.9 |
| Frontal lobe | 5.0 | 5.0 | 4.8 | 4.9 |
| Occipital lobe | 5.0 | 5.0 | 4.8 | 4.9 |
| Temporal lobe | 5.0 | 5.0 | 5.0 | 5.0 |
| Parietal lobe | 5.0 | 5.0 | 5.0 | 5.0 |
| Basal ganglia | 4.8 | 4.8 | 4.8 | 4.8 |
| Other regions | ||||
| First cervical vertebra | 5.0 | 5.0 | 5.0 | 5.0 |
| Second cervical vertebra | 5.0 | 5.0 | 5.0 | 5.0 |
| Optic nerve | 5.0 | 5.0 | 4.8 | 4.9 |
| Extraocular muscles | 5.0 | 5.0 | 5.0 | 5.0 |
| Doctor | A | B | C | Ave. () |
|---|---|---|---|---|
| Brain regions | ||||
| Anterior commissure | 3.5 | 2.0 | 3.2 | 2.9 |
| Posterior commissure | 1.8 | 1.5 | 2.3 | 1.9 |
| Cerebral aqueduct | 1.5 | 1.3 | 2.2 | 1.7 |
| Tegmentum of midbrain | 3.0 | 3.0 | 2.3 | 2.8 |
| Cerebellar hemisphere | 2.0 | 2.7 | 3.3 | 2.7 |
| sulcus | ||||
| Cerebral peduncle | 3.2 | 2.8 | 5.0 | 3.7 |
| Corpus callosum | 4.0 | 4.2 | 5.0 | 4.4 |
| Third ventricle | 3.2 | 4.2 | 4.7 | 4.0 |
| Fourth ventricle | 4.5 | 4.2 | 4.7 | 4.5 |
| Lateral ventricle | 5.0 | 4.2 | 3.7 | 4.3 |
| Corticomedullary contrast | ||||
| Hippocampus | 1.7 | 2.3 | 3.2 | 2.4 |
| Frontal lobe | 2.3 | 1.7 | 2.8 | 2.3 |
| Occipital lobe | 1.5 | 1.7 | 3.2 | 2.1 |
| Temporal lobe | 2.0 | 2.3 | 3.7 | 2.7 |
| Parietal lobe | 2.0 | 1.8 | 3.2 | 2.3 |
| Basal ganglia | 2.5 | 2.2 | 3.3 | 2.7 |
| Other regions | ||||
| First cervical vertebra | 1.7 | 1.7 | 4.2 | 2.5 |
| Second cervical vertebra | 2.5 | 2.3 | 3.2 | 2.7 |
| Optic nerve | 2.8 | 2.5 | 2.8 | 2.7 |
| Extraocular muscles | 4.0 | 2.7 | 3.2 | 3.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shibata, H.; Hanaoka, S.; Nakao, T.; Kikuchi, T.; Nakamura, Y.; Nomura, Y.; Yoshikawa, T.; Abe, O. Practical Medical Image Generation with Provable Privacy Protection Based on Denoising Diffusion Probabilistic Models for High-Resolution Volumetric Images. Appl. Sci. 2024, 14, 3489. https://doi.org/10.3390/app14083489
Shibata H, Hanaoka S, Nakao T, Kikuchi T, Nakamura Y, Nomura Y, Yoshikawa T, Abe O. Practical Medical Image Generation with Provable Privacy Protection Based on Denoising Diffusion Probabilistic Models for High-Resolution Volumetric Images. Applied Sciences. 2024; 14(8):3489. https://doi.org/10.3390/app14083489
Chicago/Turabian StyleShibata, Hisaichi, Shouhei Hanaoka, Takahiro Nakao, Tomohiro Kikuchi, Yuta Nakamura, Yukihiro Nomura, Takeharu Yoshikawa, and Osamu Abe. 2024. "Practical Medical Image Generation with Provable Privacy Protection Based on Denoising Diffusion Probabilistic Models for High-Resolution Volumetric Images" Applied Sciences 14, no. 8: 3489. https://doi.org/10.3390/app14083489
APA StyleShibata, H., Hanaoka, S., Nakao, T., Kikuchi, T., Nakamura, Y., Nomura, Y., Yoshikawa, T., & Abe, O. (2024). Practical Medical Image Generation with Provable Privacy Protection Based on Denoising Diffusion Probabilistic Models for High-Resolution Volumetric Images. Applied Sciences, 14(8), 3489. https://doi.org/10.3390/app14083489