1. Introduction
In recent years, the discourse surrounding climate change has intensified, with a growing consensus on the imperative need to transition the global economy towards achieving net-zero greenhouse gas emissions by mid-century. This ambitious goal, essential to averting dangerous anthropogenic interference with the climate system, requires rapid investment increase in near-zero emission technologies across all sectors [
1]. Among these technologies, Carbon Capture and Storage (CCS), also referred to as CCUS, where “U” stands for utilization, shows to be a pivotal solution to reducing carbon emissions, addressing climate change, and facilitating the transition to a carbon-neutral future [
2,
3]. Its significance lies in its potential to address emissions from various sources, including power-generating plants, hard-to-abate industries (such as cement and refineries), and hydrogen production. CCUS is the only technology capable of guiding industries to absolute net neutrality by capturing and treating emissions.
Once CO
2 is captured, it undergoes compression and transport to be permanently stored in geological formations, acting as a “sink” through injection. These geological formations must possess certain key characteristics [
4]. Essential conditions for a formation to be considered a suitable carbon storage site include the formation of a pore unit with sufficient capacity to store the intended CO
2 volume; pore interconnectivity allowing injection at the required rate; and the presence of an extensive cap rock or barrier at the top of the formation to retain the injected CO
2, prevent unwanted migration, and ensure long-term containment [
5]. Saline water-bearing formations [
6,
7,
8] are widely regarded as the most mature options for CO
2 storage, as demonstrated by numerous projects worldwide. Additionally, depleted oil and gas fields have recently emerged as potential storage sites, benefitting from operational experience gained through CO
2-EOR operations [
9,
10,
11].
Deploying CCUS technology on a large scale in saline aquifers or hydrocarbon fields necessitates accurate characterization of the storage site and reservoir, involving a complex process, from screening to deep geological and geophysical characterization [
12]. Numerical simulation and modeling using computational fluid dynamics (CFD), possibly coupled with reactive transport simulations, are employed to address complex subsurface geology, simulating the flow behavior of the injected and the in situ fluids. The goal of such models is to estimate the field sequestration capacity of the injected CO
2 under different trapping mechanisms, such as structural, dissolution, residual, and mineral storage, during all project phases [
13,
14].
Reservoir simulation is a crucial tool in the field of petroleum engineering that aids in modeling and predicting fluid flow behavior within subsurface reservoirs. The primary objective is to simulate the complex interactions among various components, such as rock, fluids, and wells. One of the fundamental principles underlying reservoir simulation is Darcy’s law, which describes the flow of fluids through porous media. The Darcy equation (Equation (
1)) relates fluid velocity to pressure gradient, permeability, and fluid viscosity [
15]. The simulator employs numerical methods to solve the mass, momentum, and energy differential equations governing fluid flow (
2) in the porous medium. The most widely used flow model in reservoir simulation is the black-oil one [
16]. In the black-oil formulation [
17], the model is considered to consist of three separate fluid phases or pseudocomponents (water, oil, and gas). Mixing among phases is allowed, and the amount of how much each phase is dissolved in the others and how it affects flow properties need to be kept tracked of.
where the subscript
a denotes the pseudocomponent oil (o), gas (g), or water (w). For each one, the variables are defined as follows:
is the phase flux, and
is the mobility of the phase. This is defined as
, where
and
are the viscosity and the relative permeability of each phase, respectively. In short, relative permeability is a measure of the effective permeability reduction of a phase in the presence of other phases and is a function of saturation.
is the pressure,
is the density, and
is the well outflux/influx of each phase, i.e., the volumetric flow rate at which each pseudocomponent is produced/injected from the system.
are accumulation terms dependent on phase saturation (
) and shrinkage phase factors (
). The flux terms
are known functions of shrinkage factor and phase fluxes. Finally, the terms
and
are the porosity and permeability, respectively.
The other popular simulation model is the compositional one [
18,
19]. The difference between the black-oil and compositional models lies in that the former traces the flow of each separate phase; hence, it only considers single-phase (gas, oil, and water) density and compressibility effects, as well as dissolution of gas in the oil phase. The fact that the volumetric and dissolution factors can be easily described by simple functions of the pressure is based on the assumption that the overall composition does not change significantly during reservoir depletion or waterflooding. On the other hand, compositional modeling, facilitated by means of an EoS model, is used when some “alien” composition is incorporated in the reservoir fluids. This is the typical case when handling EOR cases of CO
2, natural or acid gas injection, and injection of dry gas in gas condensate reservoirs.
Equations (
1) and (
2) are combined in a second-order partial differential equation (PDE) which can be analytically solved under simplifying assumptions (incompressible, single-phase system with constant porosity and permeability). However, when trying to model realistic subsurface formations, these assumptions do not hold. In this case, the discretization of the equation through linearization is a key step in numerical reservoir simulation. This process involves dividing the reservoir into a grid to represent the spatial distribution of rock properties and fluid flow and using a linearization scheme [
20]. Common methods for discretization include finite differences, finite volumes, and finite elements. Finite volumes [
21], in particular, are widely used in reservoir simulation due to their simplicity and efficiency. Gridding plays a vital role in the discretization process, involving defining the size and shape of the cells within the reservoir grid. Various types of grids, such as Cartesian, corner-point, and unstructured grids, are used based on the geological complexity of the reservoir. The choice of grid impacts the accuracy and computational efficiency of the simulation.
Petrophysical and fluid properties, such as porosity, permeability, fluid saturation, compressibility, and relative permeability, are crucial inputs for reservoir simulation [
22,
23]. Accurate characterization of these properties is essential for realistic simulation results. Furthermore, incorporating phase behavior models is essential to accurately representing the complex interactions among different phases of fluids and dissolved particles in multi-phase flow simulations. For instance, in CCS simulations, it is crucial to capture the dynamics of CO
2 dissolution, which significantly depends on the concentration of salts in the aquifer [
24].
Building upon the foundation of accurate simulation models, the optimization of well placement becomes paramount to maximizing the sequestration potential of the aquifer in CCS endeavors [
25,
26]. The primary objective of CCS projects is to maximize CO
2 storage while adhering to constraints and technical policies [
27,
28]. In its most commonly employed form, the CCS plan requires that brine producers be closed off once significant CO
2 breakthrough occurs, whereas the injectors rate is reduced when the bottomhole pressure reaches the safety limit. Consequently, optimal well placement significantly influences the overall success of the sequestration project by delaying the breakthrough time. The objective function maximization in this context is defined as achieving the highest attainable CO
2 storage, considering the spatial distribution of the injection and brine withdrawal wells. This multi-dimensional function has an unknown functional form and its point values are expensive to compute since each one requires a fully implicit simulation to be run. Therefore, it needs to be treated as a black-box function.
Well placement decisions cannot rely solely on static properties, since geological variables are mostly non-linearly correlated to production performance. This is demonstrated in
Figure 1, where the objective function of oil production in the form of the expected net present value (NPV) is evaluated for the placement of a single oil producer in each cell. The complexity and non-linearity in CCS projects parallel those encountered in oil production, underscoring the importance of optimized well placement for maximizing storage efficiency while considering factors such as CO
2 dissolution dynamics and aquifer characteristics. In general, well placement optimization poses a formidable challenge due to the large number of the decision variables involved, the high non-linearity of the system response, the abundance of local optima, and the well placement constraints. Due to the discontinuities and the inherent non-smoothness of the objective, research has been mostly focused on derivative-free optimization methods such as Genetic Algorithms [
29] and Particle Swarm Optimization [
30] combined with various heuristics.
Guyaguler et al. (2002) [
31] developed and applied the Hybrid Genetic Algorithm (HGA) [
32] to determine the optimal location and number of vertical wells, while Badru et al. (2003) [
33] extended this work to also include horizontal wells. In essence, HGA comprises Genetic Algorithm (GA), the polytope algorithm for selecting the fittest individuals and a kriging proxy to expedite the optimization process. The results showed that after a few simulation runs, the method was able to optimize the production’s NPV compared with the base case. In another work, Emerick et al. (2009) [
34] designed a tool for well placement optimization using a GA with non-linear constraints. They applied the GENOCOP III algorithm [
35] which utilizes two separate populations where the evolution in one influences the evaluation of the other. The first population, named the “search population”, consists of individuals that satisfy the linear constraints, whereas the second, called the “reference population”, consists only of those that satisfy both linear and non-linear constraints. By using this procedure, the research team developed a tool that handled a total of eight decision variables per well (six in total that define the heel and toe coordinates of the well, one binary for producer or injector, and one defining active or inactive well). The results showed a significant increase in the NPV of the production plan in comparison with the base case proposed plans. Stopa et al. (2016) [
36] applied both GA and PSO to optimize well placement and well rates. Their approach was different in that they utilized an objective function that measures the ratio of the volume of mobile CO
2 phase (plume) over the volume of CO
2 injected after 10 years of injection and 80 years of monitoring. Their goal was to minimize this ratio, since by minimizing the plume, leakage risk is also reduced. In essence, they tried to find configurations that maximized the residual and solubility trapping of CO
2. In their work, PSO was able to find the optimal value of 12.5% in 500 simulation runs, while GA needed more than 850. Similarly, Goda and Sato (2013) [
37] utilized a similar objective function by using a global sampling method known as Latin Hypercube Sampling (LHS) [
38]. Notably, in their work, they enhanced the definition of immobile CO
2 by taking into account the irreducibility of relative permeability curves. Besides the mentioned landmark works, there have been dozens more published on this optimization problem. Islam et al. (2020) [
39] provided a detailed review of research conducted on the well placement optimization problem, focusing mostly on derivative-free and machine learning regression methods.
Bayesian Optimization (BO) [
40] is a global optimization method that efficiently constructs and updates surrogate models representing black-box objective functions, rendering it suitable for addressing the well placement optimization problem. In this work, our goal is to apply this method to optimize the carbon sequestration capabilities of a saline aquifer. BO represents a cutting-edge methodology that dynamically balances the exploration of the solution space with the exploitation of promising regions to efficiently discover well placement that can lead to the global optimum configuration. BO relies on constructing a probabilistic surrogate model, often a Gaussian Process (GP), to approximate the underlying objective function, which, in this context, measures total carbon storage. This surrogate model not only captures the observed data but also quantifies the uncertainty associated with predictions, allowing for the incorporation of prior knowledge and continuous refinement as new information becomes available through successive simulation runs. By iteratively selecting well locations based on the surrogate model’s predictions and subsequently updating the model with the actual reservoir response, BO intelligently adapts its search strategy. This adaptive nature makes it particularly well suited for navigating the high-dimensional and uncertain parameter space, providing a systematic and data-driven means of identifying optimal well configurations for enhanced carbon sequestration.
BO for well placement optimization was implemented in the work of Balabaeva et al. (2020) [
41]. In their work, the researchers attempted to optimize well locations by maximizing the cumulative drainage area of wells by using various derivative-free methods, with BO being one of them. In another work, Bordas et al. (2020) [
42] utilized a BO framework for field development planning while quantifying the effect of geological uncertainty. They generated a surrogate model that was able to identify well placement positions that maximized NPV while accounting for uncertainty. Kumar [
43,
44] also presented works on novel BO realizations, such as trust region BO [
45] and sparse-axis-aligned subspaces BO (SAASBO) [
46]. BO has additionally been investigated for optimizing various decision variables crucial in reservoir exploitation besides well placement. Lu et al. (2022) [
47] utilized BO to optimize the time cycle of gas/surfactant injection in Water Alternating Gas (WAG) schemes. Their study conducted at the Cranfield reservoir site resulted in a 16% increase in gas storage volume and a 56% reduction in water/surfactant usage compared with the baseline WAG schedule. In an MSc thesis, Javed [
48] employed a BO framework to optimize deviated well trajectories in a synthetic reservoir model located in the North Sea. The optimized trajectories led to a 28% enhancement in the objective function compared with the base case. Additionally, Wang and Chen (2017) [
49] investigated the Cardium tight formation, where they successfully optimized fracturing design parameters by using BO, achieving a notable 55% improvement in the objective function. These studies prove BO to be a suitable framework in reservoir engineering. However, to our knowledge, BO has not been studied for the well placement optimization problem in CCS specifically.
The rest of the paper is organized as follows: In
Section 2, we delve into a comprehensive explanation of the Bayesian Optimization method. Following that,
Section 3 offers a detailed description of the specific problem, elucidating how BO was strategically applied to address the challenges encountered, such as non-linear constraints and permutation invariance in the input space. In
Section 4, we present results stemming from various implementations of the BO method, comparing the performance of various acquisition functions and inspecting the exploration–exploitation trade-off.
Section 5 initiates an expansive discussion of the obtained results. Finally,
Section 6 draws insightful conclusions based on the findings and discussions presented throughout the study.
Figure 1.
NPV evaluation for oil production with a single well [
50].
Figure 1.
NPV evaluation for oil production with a single well [
50].
3. Problem Description
3.1. Reservoir System
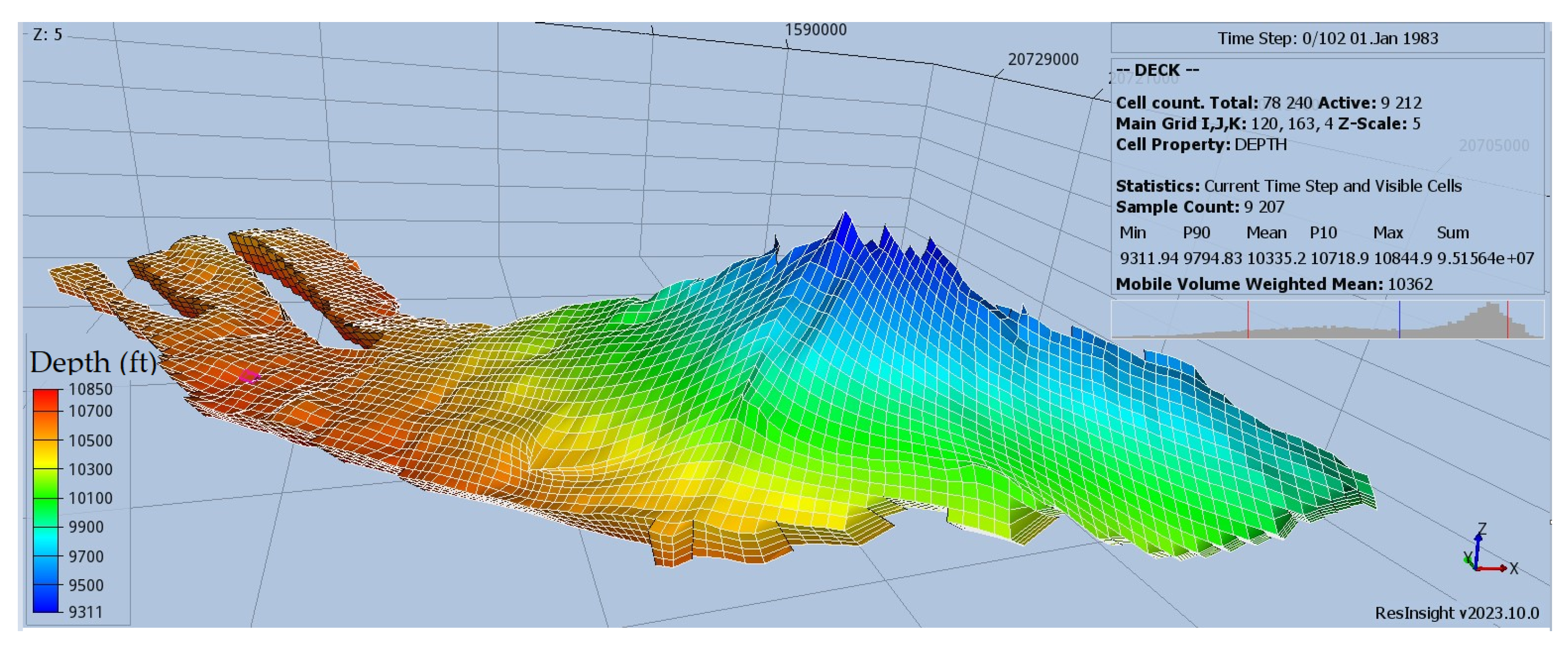
In this study, the sequestration potential of a deep and highly permeable synthetic aquifer (
Figure 2) is investigated. The aquifer exhibits an inclined profile, with a pronounced steepness near the crest resembling an anticline, expanding horizontally across a wide area, and comprises four sedimentary layers, each one with varying average permeability values. There is no apparent faulting or fracturing in the formation, and it is assumed to be sealed tightly by shales. The aquifer’s salinity is about 65,000 ppm. Furthermore, it maintains a temperature profile consistent with typical thermal gradient expectations at the reservoir depth. The characteristics of the aquifer can be seen in
Table 1. Due to its high permeability, the pressure distribution within the aquifer adheres to the pressure gradient, remaining isotropic on the x-y plane. The aquifer is considered to be slightly overpressurized, prompting the simultaneous production of brine during CCS operations to postpone reaching the pressure upper safety limit indicated by the technical and safety policies in place as 9000 psi. The significance of this approach is underscored by the zero-flow conditions at the aquifer’s sides, as dictated by no-flow boundary conditions in the simulation model [
64].
3.2. BO Framework
To formulate a BO framework, the objective function, its constraints, and the decision variables have to be defined. The target is to maximize the total amount of CO2 sequestered in the aquifer after continuous injection for 40 years and concurrent brine production with constant target rates. This is handled by introducing two types of groups, injectors and producers, with each group consisting of a number of identical wells.
Constraints are set to the maximum and minimum bottomhole pressure thresholds, as well as to the maximum afforded breakthrough rate of CO2 recycling. High non-linearity is introduced to the problem by the effect of the wells’ location on the objective function and of the dynamic schedule changes occurring when operational constraints are violated. If, for example, an injector is placed close to a producer, then it is likely that CO2 breakthrough will occur way sooner than otherwise. Subsequently, the producer will be closed off, and pressure will build up at a faster rate so that the constraint of maximum bottomhole pressure for the injector will be reached sooner, resulting in reduced sequestration. The depth at which each well is situated also plays a huge part in the breakthrough time. Since CO2 tends to migrate upwards, CO2 travels faster to a producer situated near the crest. In contrast, if the producer is situated closer to the reservoir bottom, CO2 breakthrough is delayed. The theoretical maximum amount of CO2 stored is easily calculated as the target rate of the injectors over the timespan of injection. However, this maximum may be unobtainable due to the constraints already mentioned.
The well placement optimization problem can be formulated as shown in Equation (
14).
where
corresponds to the CO
2 mass sequestered, which can be sampled by simulation runs, and
are the scheduling constraints, where
represents the decision variables, which, in this case, are the coordinates
of each vertical well. Most commercial and research reservoir simulators can embed scheduling constraints into their runs, thus ensuring that the simulation is operationally feasible. This way, the scheduling constraints are handled by the simulator and thus do not need to be explicitly handled by the optimizer. There are, however, additional constraints related to the feasibility of the input space, as discussed in the next subsection. For the optimization process, the python package Bayesian Optimization [
65] was utilized.
3.3. Decision Variables and Constraints
Constraints need to be imposed on the input space to define the feasible region of the objective function. For a CCS system with
N wells, the input space consists of
decision variables and the wells’ location may be written as in Equation (
15).
The first constraint to be imposed on the input space is that two wells cannot take up the same cells on the grid, since the simulator issues a simulation error instantly. As such, the optimizer is instructed to penalize such cases by giving a very negative value for the objective function when the simulator crashes.
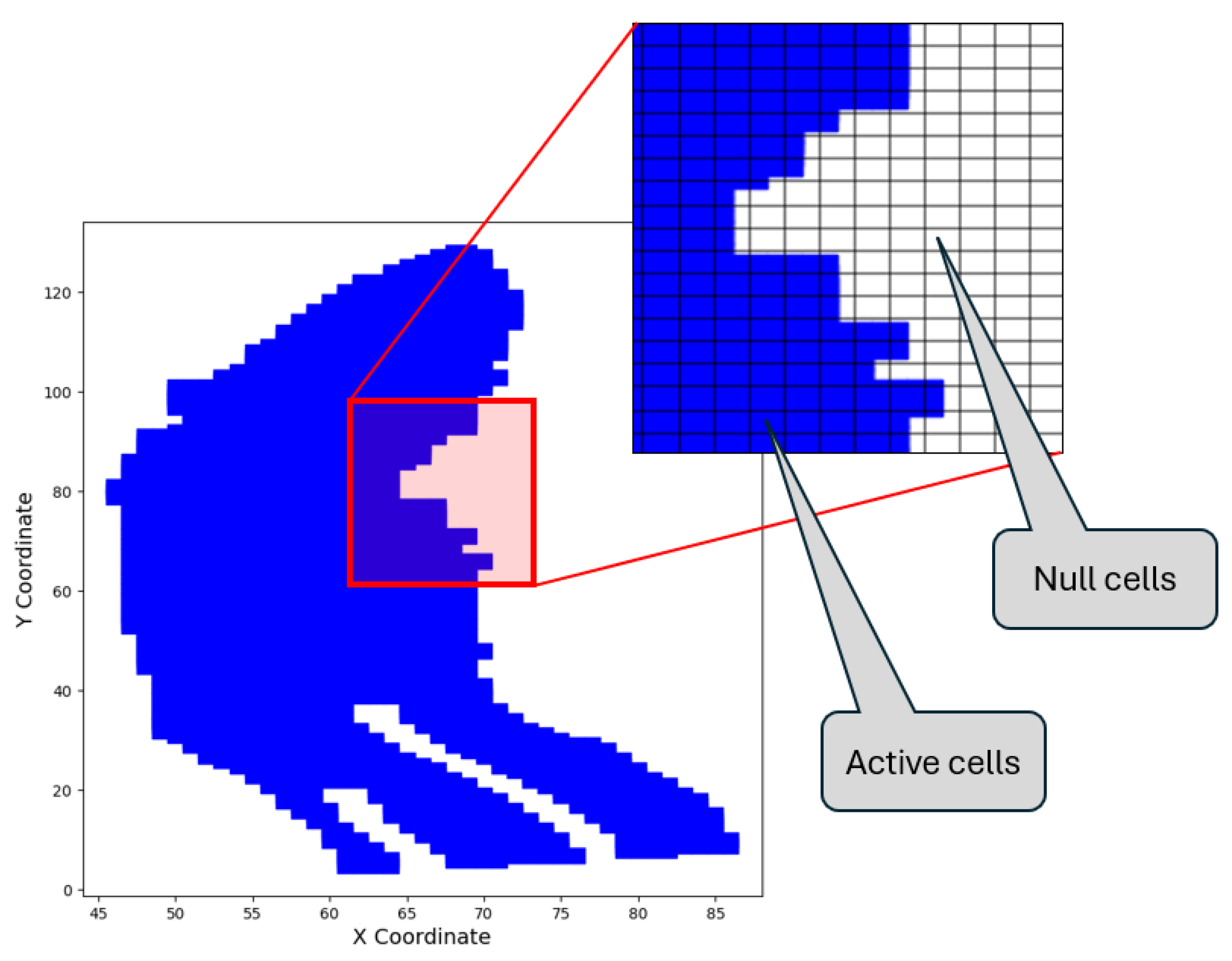
The second and much more troublesome-to-handle constraint is the one regarding the valid position of each well. Since the aquifer’s shape is not a square box, there are coordinate values within the grid-enclosing volume that correspond to null (non-existent) grid cells, as seen in
Figure 3. The recommended solution would be to add a severe penalty term by introducing a large negative objective function value for inputs in the infeasible area. For a reservoir with an active-to-total-cell ratio of
, this ratio corresponds to the probability of a well being placed within the feasible area. If the location of a single well were sought, the optimizer would be able to map the infeasible area quite quickly. However, when N wells have to be placed rather than just one, the probability of selecting all of them inside the feasible space is only
. Clearly, the timeframe for the determination of the feasible area increases exponentially with the number of wells selected.
To overcome this challenge, a mapping from this 2D input space to a 1D space is employed while maintaining a one-to-one relationship, using a transformation based on the cell distance from the origin. Subsequently, an ascending-order-sorting operation is applied to the Euclidean norms of each cell to arrange them. Algorithm 1 of the map can be seen below.
| Algorithm 1: Mapping function . |
![Applsci 14 03528 i001]() |
This mapping is one to one (1-1) because each point is uniquely associated with a real number . Note that this is not a homeomorphism, as it does not preserve topological properties such as closeness of points.
This mapping allows for dimensionality reduction from a
-dimensional input space to an
N-dimensional one. Furthermore, all values in the new input space represent the feasible region, so no more constraints on the input region need to be handled. The mapped values of each cell are shown in
Figure 4.
3.4. Permutation Invariance of Input Space
As mentioned earlier, the simulator splits wells into two groups, injectors and producers, managing them collectively under group control policies. Targets and constraints are set for each group, with an embedded optimizer in the simulator responsible for adjusting schedule parameters for individual wells within each group. Essentially, a group comprises wells of the same type, distinguished solely by their location on the grid. On the other hand, the wells’ locations serve as input variables in the BO framework, ordered in a vector. Therefore, the simulator handles the wells’ positions as two sets of unordered objects, partitioned on the respective group, while BO treats them as a vector. Consequently, for the simulator, the input space is invariant under permutations for well positions within a group, whereas for BO, it is not.
Let us consider a scenario following the mapping described in Algorithm 1. If variables m and n represent the positions of injectors and producers, respectively, the input space’s invariance implies that a sampled input exerts the same effect on the simulator, thus also on the objective function, across vectors, generated by all of the permutations of the inputs within the same group.
To illustrate this concept, let us consider a simple case with two wells of the same type placed on a
Cartesian grid (refer to
Figure 5). In this scenario, the top-left cell is denoted as [1,1]. Moving right from [1,1] brings us to [1,2], while moving downwards from [1,1] leads to [2,1]. This structure mirrors the conventions of matrix elements, facilitating a straightforward understanding of the grid’s layout. The coordinates for the left sample are
, and for the right sample,
, where
f is the mapping defined by Algorithm 1. Despite the differing configurations, the simulator produces identical outputs for both samples, since they belong to the same group, and the simulator handles them as a set, regardless of their order. Each sample has its counterpart, or “doppelganger”. As the number of wells increases, the number of potential configurations grows exponentially, since for
N wells, each unordered configuration can result from
different orderings. This example highlights the fundamental principle of group control and the resultant invariance in the input space, offering insights into the system’s behavior regardless of the specific arrangement of wells.
3.5. Modified Kernel Function
The observation of permutation invariance is crucial to better acknowledging the principal idea introduced in this work. Since the black-box function of the BO framework (i.e., the simulator) considers the inputs to be sets, it would be extremely beneficial for this to also be incorporated in the BO framework. By sampling an input vector, information is obtained not only regarding what its objective function value is but also regarding all input vectors that are derived from same-group permutations of its elements. For instance, in the N-dimensional input space, where , and n and m correspond to the dimensions of the groups, a single sample would give information about vectors. It is now obvious that incorporating this information in BO would greatly benefit its efficiency.
To incorporate this in BO, we need to recall that BO builds a surrogate objective function that is mostly influenced by samples and the covariance matrix which is derived from a kernel function. Modifying the kernel function is a clear pathway for improving the efficiency of BO. The kernel function calculates the covariance between points of the input space and acts as a measure of how similar the surrogate objective function’s values are based on the distance between inputs. The Matérn kernel utilized in this work is a stationary kernel, i.e., invariant to translations where the covariance of two input vectors is only dependent on their relative position . Inputs have high covariance when their distance approaches zero, whereas it decreases as they move further apart.
The modified input space generated by the mapping of Algorithm 1 is useful for generating inputs inside the feasible region, but the caveat is that it is not homogeneous. Points that are close in the modified input space might be very far apart when translated to the original input space. The lack of preservation of this closeness property in the modified input space can be expressed as follows:
where
are cells coordinates and
f is the mapping from Algorithm 1. In other words, the mapping function is not an increasing function of the well distance. It follows that if the kernel function utilizes the distances of the mapped input space directly, there will likely be a discrepancy between the calculated covariance and the actual covariance between inputs when this translates to the original input space.
To overcome this problem, the kernel function was modified so that covariance is calculated based on the inverse mapping of the input space, i.e., from the N-dimensional input space to the -dimensional one which now represents the actual distance between two cells , where . By utilizing this technique, the kernel function now considers the actual distance between two cells.
The last issue to be addressed is the permutation invariance. Since each input vector is invariant under permutations, to calculate the representative covariance between two inputs, the permutation ordering that minimizes the distance of the one input to the other needs to be applied. This is a key modification that transforms BO from considering inputs as vectors to now view them as sets. By permuting, it is now able to minimize the distance between sets rather than vectors.
To solve this, a matrix
is generated, with each value
representing the distance of the
ith well in
from the
jth well in
, as given by Equation (
16).
Since the goal is to find the permutation that minimizes the distance between wells in the two samples, the problem can be expressed as finding the permutation of rows (or columns) that minimizes the trace of matrix
, shown in
Table 2, which has complexity
. Since permutation invariance only affects injectors and producers separately, the problem can be reduced to the two counterparts, i.e., finding the right ordering of the injectors which has complexity
and finding the right ordering of the producers with complexity
. This is a very well-known problem in the literature called the assignment problem. Algorithm A1 (
Appendix A), known as the Hungarian method [
66], or Munkres algorithm [
67], is commonly utilized to reduce its complexity to the order of
, or in our case,
, saving valuable computational time. Algorithm 2, describing the full Kernel modification, is shown below.
| Algorithm 2: Covariance calculation. |
![Applsci 14 03528 i002]() |
The modified kernel function is represented by a functional form, , where denotes the permutation matrix. This functional form introduces significant non-linearity, due to the involvement of inverse mapping and permutation matrix . This non-linearity poses challenges in directly establishing a proof of satisfaction of Mercer’s conditions, which typically rely on simpler, more linear forms of kernel functions. However, despite the inherent complexity introduced by the functional form, extensive sampling efforts across a large number of input samples consistently yield a positive semidefinite covariance matrix. This empirical observation is crucial, as it provides compelling evidence supporting the validity of the modified kernel function. To elaborate, the positive semi-definite covariance matrix implies that the resulting kernel function preserves important properties required for Mercer’s conditions, such as symmetry and non-negativity. The positive semi-definite nature of the covariance matrix indicates that any linear combination of kernel evaluations over the sampled inputs remains non-negative, thus aligning with the requirements of Mercer’s theorem. Furthermore, although direct analytical proof may be challenging due to the non-linearity of the modified kernel, the empirical validation through covariance matrix analysis corroborates the functional form’s adherence to Mercer’s conditions. This empirical evidence, coupled with the observed positive semi-definite covariance matrix, lends strong support to the validity of the modified kernel function despite its inherent non-linearity.
Importantly, due to the permutation invariance inherent in the function, it can be construed as a kernel function operating between sets rather than individual vectors. Algorithm 3 delineates the primary workflow of the Bayesian Optimization (BO) framework employed in this study.
| Algorithm 3: Bayesian Optimization framework. |
![Applsci 14 03528 i003]() |
5. Discussion
To facilitate a broad discussion on the modifications and the results presented so far, a brief synopsis of what has transpired thus far needs to be presented. The objective of this work is to apply a BO framework to optimize well placement in a CCS project. Rather than applying BO in a “out of the shelf” straightforward fashion, several key modifications and analyses outlined throughout
Section 3 were employed, aiming at enhancing optimization efficiency and effectiveness. Firstly, by utilizing a formation with complex geometry rather than a simple “sugar box”, the issue of infeasible areas within the input space emerged and had to be addressed by implementing a transformation technique. This step allowed us to circumvent infeasible regions that took up the majority of the original input space.
This modification was not tax-free, as it introduced a severe issue to the kernel. The non-homeomorphic nature of the map implied that kernel closeness of points in the new modified input space did not translate to the same closeness on the original, thus violating the need for the kernel function to calculate the covariance properly. To address this, modifications were further introduced to the Matérn kernel, utilizing inverse mapping to capture real distances between well positions. By recalculating covariances based on actual distances, this adapted kernel accurately represented the spatial relationships crucial for optimal well placement.
A significant advancement in the proposed methodology was the integration of our knowledge of permutation invariance into the kernel function. From a mathematical point of view, this innovation enabled the kernel to operate on sets rather than conventional vectors, effectively considering the minimum distances between well positions under permutations. The resulting kernel showed to be instrumental in improving optimization outcomes, as demonstrated through rigorous experimentation in
Section 4.2, where BO was run with and without the proposed modifications, with the results being significantly better in the modified case.
Clearly, the modified kernel exhibited superior performance, highlighting its pivotal role in driving significant improvements in well placement optimization outcomes. It is our strong belief that a solid foundation has been laid for future research endeavors aimed at optimizing the well placement problem with enhanced precision and efficiency. The proposed method is generalizable to other applications of well placement optimization, not necessarily restricted to a BO framework as long as wells operate under group control, making the input space invariant under permutations. These modifications can also find applications in other learning algorithms characterized by permutation invariant inputs.
In addition to the comparisons presented thus far, it is important to address the optimal placement identified by the algorithms and consider what insights engineers’ intuition could offer. Generally, in a closed system, producers and injectors should be positioned as far apart as possible. For this aquifer, an alternative configuration could involve injecting CO
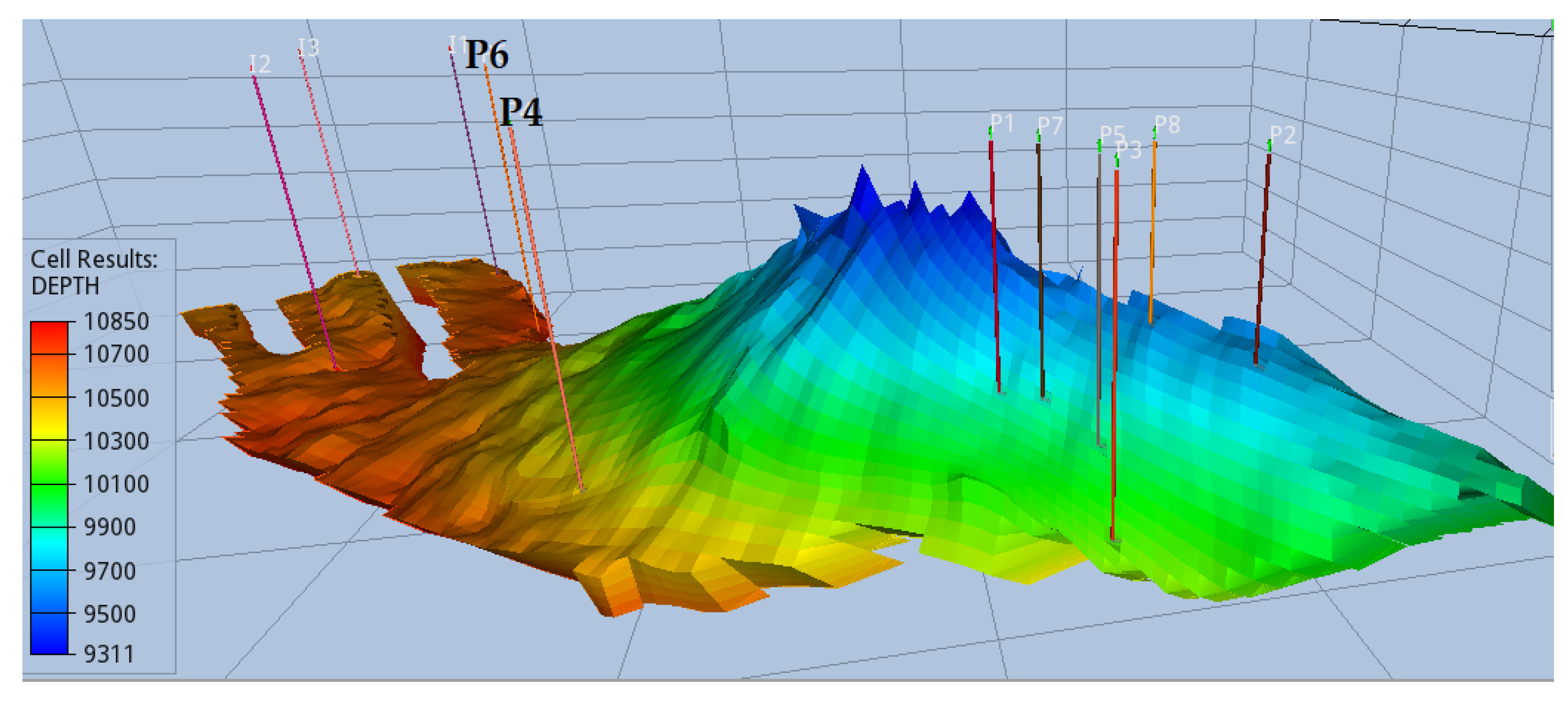
2 at the crest and placing the producers around the periphery, which would potentially enforce the resulting plume to remain relatively stationary and not descend as rapidly. As depicted in
Figure 11, the solution derived by the BO algorithm reflects a blend of both engineering perspectives and considerations.
Injectors are strategically positioned as far away as possible from the majority of the producers, situated in the region resembling a fork at the base of the aquifer. Conversely, most producers are sited on the opposing side of the crest that resembles a “hill”. CO
2 naturally migrates upwards, facilitated by a clear pathway to the crest. It is reasonable to assume that producer P6 is strategically placed along the anticipated path of the plume for pressure maintenance, given the substantial injection rate from day 1. Producer P4 is strategically located to ensure a uniformly distributed plume. Considering the gravitational pressure differential that causes CO
2 to migrate towards the crest, the advancement of the resulting plume’s front would be uneven. However, P4 counteracts this by moderating the pressure in its vicinity, resulting in even plume migration by the end of the CCS period, as illustrated in
Figure 12.
Finally, the remaining six producers are positioned behind the crest, in accordance with the second intuition, that is, the deceleration of the CO
2 plume once it reaches the crest, primarily due to density differences between CO
2 and the brine. At this juncture, breakthrough to the producers becomes inevitable, marking the conclusion of the injection period. It is noteworthy that the simulation ran successfully for approximately 40 years, during which the injection rate naturally decelerated due to pressure buildup. However, as depicted in
Figure 13, the plume had not yet reached the producers by this point.
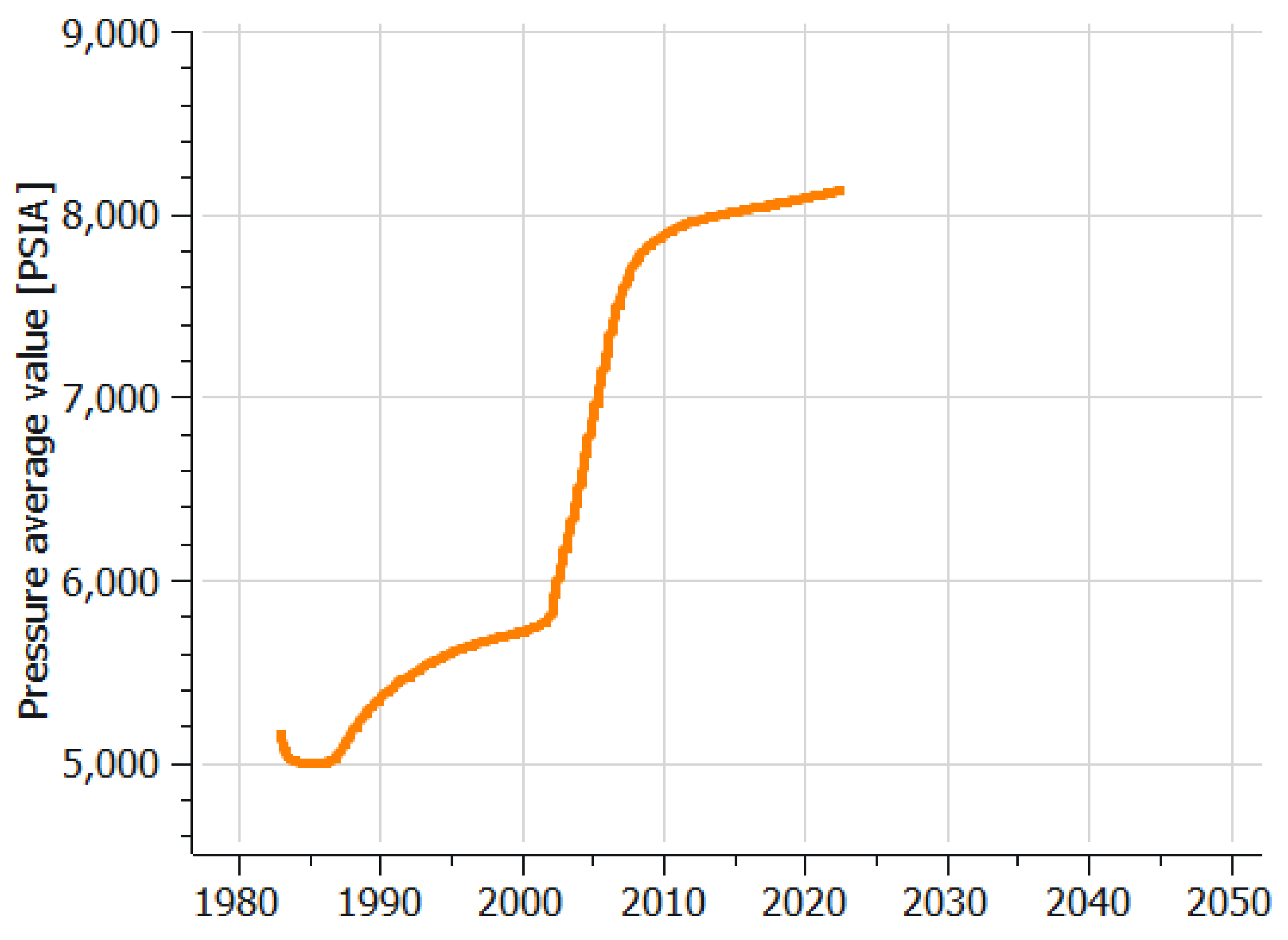
Field pressure, depicted in
Figure 14, is shown to emphasize that even after 40 years of continuous development, the aquifer has not yet reached the safety limit pressure. Pressure gradient varies due to the constraints imposed on production/injection and breakthrough rates.
Overall, BO optimization successfully captured, without any explicit guidance and in a very limited number of simulation runs, the need for producers and injectors to be spaced as further apart as possible, while positioning the producers below the crest to slow down CO
2 plume breakthrough. These are the two primary insights crucial for injection optimization, which an experienced engineer would typically independently deduce. Configurations deviating from these principles are deemed sub-optimal, leading to earlier CO
2 breakthrough in producers. Consequently, producers are prematurely closed off, pressure builds up faster, and injection rates decline sooner, resulting in reduced total CO
2 injection and less effective plume sweep efficiency. This trend is illustrated in
Figure 15, where the optimal case’s injection rate (blue line) is compared to a sub-optimal one (red line). Despite the optimal case having a notably higher target injection rate, it maintains this rate for over a decade longer and exhibits a more gradual decline compared with the sub-optimal scenario. In the latter, injectors are not efficiently spaced with respect to the producers; therefore, the pressure reaches the safety limit of 9000 psi in less than a decade of development. The number of producers and injectors, as well as the aquifer system, are identical in both cases.
Given the engineering-oriented approach of the optimizer’s solution, there is a high degree of confidence that the proposed solution is indeed optimal. However, it is essential to acknowledge the complexity introduced by the multi-dimensional nature of the input space. While the solution obtained represents a significant achievement, it is plausible that there exist alternative configurations capable of matching or even surpassing this optimal value. Furthermore, an interesting consideration arises from the spatial proximity of the six producers. Given their close positioning, there is potential for aggregation into one or two total producers during the project’s design phase. Consolidating these producers could streamline operational logistics and potentially optimize resource utilization, contributing to further efficiency gains. After performing multiple simulations, aggregating the six wells into one or two and considering the rates of the optimized case, it was seen that the total volume of sequestered CO2 slightly dropped by 3–7%, which could of course be negated by the reduced costs of drilling so many wells. However, a complete evaluation of this trade-off is beyond the scope of this work.
6. Conclusions
In this study, the well placement optimization problem was handled as a Bayesian Optimization one. To our knowledge, this was the first attempt of applying BO in a well placement CCS setting. The analysis focused on several key modifications and comparisons to enhance the efficiency and effectiveness of the optimization process. Firstly, the issue of the input space’s infeasible area was addressed by introducing a mapping to a modified input space. This adjustment allowed the algorithm not to be concerned with exploring the infeasible regions by itself, a process which would require hundreds of thousands of iterations. Furthermore, a novel kernel modification was proposed, aiming at achieving invariance under permutations of the input vectors. This adaptation not only enhanced the robustness of the optimization process but also ensured that the model’s performance remained consistent across different permutations, a crucial consideration in real-world well optimization.
Subsequently, comprehensive analyses were conducted by using various acquisition functions, including expected improvement (EI), upper confidence bound (UCB), and probability of improvement (POI). Through comparative graphs, the performance differences among these functions was illustrated, providing valuable insights into their respective strengths and limitations in the context of CCS well placement optimization. One of the primary contributions of this study was the comparative evaluation of the developed modified kernel against its unmodified counterpart and a random function. The obtained findings unequivocally demonstrated the substantial impact of the modified kernel on optimization efficacy.
After extensive testing, we successfully optimized the sequestration of CO2 in a saline aquifer. The resulting scenario reflects both intuitive engineering principles and computational efficiency. Our efforts culminated in a comprehensive case study outlining the optimal sequestration of 115 million tons of CO2 over a four-decade period. This achievement represents 80% of the theoretically maximum value of 142 million tons, signifying exceptional efficiency within a closed system. Typically, breakthrough and pressure buildup pose significant challenges in such processes, often limiting their duration and effectiveness.
In conclusion, this study significantly enriches the ongoing discourse surrounding Bayesian Optimization and its practical implementation in complex domains like CCS. Through the introduction of bespoke modifications and comprehensive comparative analyses, a solid foundation for future progress in optimization methodologies has been established, tailored specifically to the nuanced challenges of real-world scenarios. Our efforts pave the way for further refinement and expansion of these techniques, bringing us ever closer to harnessing the complete capabilities of Bayesian Optimization in addressing the intricate well placement problem. Moving forward, the exploration of advanced exotic Bayesian Optimization procedures and frameworks becomes a priority, thereby pushing the boundaries of optimization capabilities in CCS and related fields. This includes extending our methodology to accommodate various types of wells, such as horizontal, inclined, and multi-segment wells, which pose unique challenges due to their non-traditional geometries and flow characteristics. Additionally, the importance of addressing geological uncertainty and the complexities of diverse formations is recognized; thus, future research endeavors will focus on incorporating these factors into the optimization framework. Furthermore, to enhance the industry relevance and real-life applicability of this research, the integration of a net present value (NPV) objective function into the optimization model is intended to be incorporated. This addition will enable the direct optimization of well placement decisions based on economic considerations, aligning our approach more closely with the priorities and objectives of stakeholders in the CCS industry. By integrating NPV considerations, we can ensure that our optimization solutions not only meet technical requirements but also deliver optimal economic outcomes, thereby facilitating more informed decision making in real-world CCS projects.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}