

A TEE-Based Federated Privacy Protection Method: Proposal and Implementation

Abstract
:1. Introduction
- (1)
- The proposed method has obvious advantages over the existing privacy inclusion methods. The proposed method has less accuracy loss than the method based on differential privacy and less performance loss than the method based on secure multi-party computation. Conventional privacy protection methods based on TEE do not consider the protection of the overall longitudinal federated model training process. The method proposed in this study considers the end-to-end privacy protection in the federated learning process, and it can cover horizontal federated learning and vertical federated learning.
- (2)
- The proposed method can effectively resist gradient leakage, model inversion, poisoning, and backdoor attacks with less performance loss under the premise of ensuring accuracy.
- (3)
- The method proposed in this study is based on Intel SGX technology, which could realize the migration of the general federated machine learning framework and end-to-end privacy protection for the complete federated learning training process.
- (4)
- The proposed method enhances the privacy protection ability for the general federated machine learning framework; therefore, the model developer does not need to perceive the privacy protection technology, which reduces the difficulty of use for developers.
- (5)
- The proposed method supports cloud-native architecture deployment and is suitable for deployment in the cloud environment.
2. Related Work
3. Method Introduction
3.1. Problem Modeling
3.2. Protection Objectives
- (1)
- Input protection: the inputs include training data, network parameters, and network structure.
- (2)
- Modeling process protection: model checkpoint and communication encryption.
- (3)
- Output protection: the outputs include model protection and model checkpoint protection.
- (4)
- Transmission security: adopting the method of dynamically creating certificates, combined with the remote authentication technology of SGX, ensures that participants and third parties cannot steal the transmitted messages.
3.3. Introduction of the Privacy Protection Model
| Algorithm 1. Confidential federated learning based on Intel SGX. |
3.3.1. Privacy Protection of Computing Process
3.3.2. Integrity Protection
3.3.3. Channel Protection
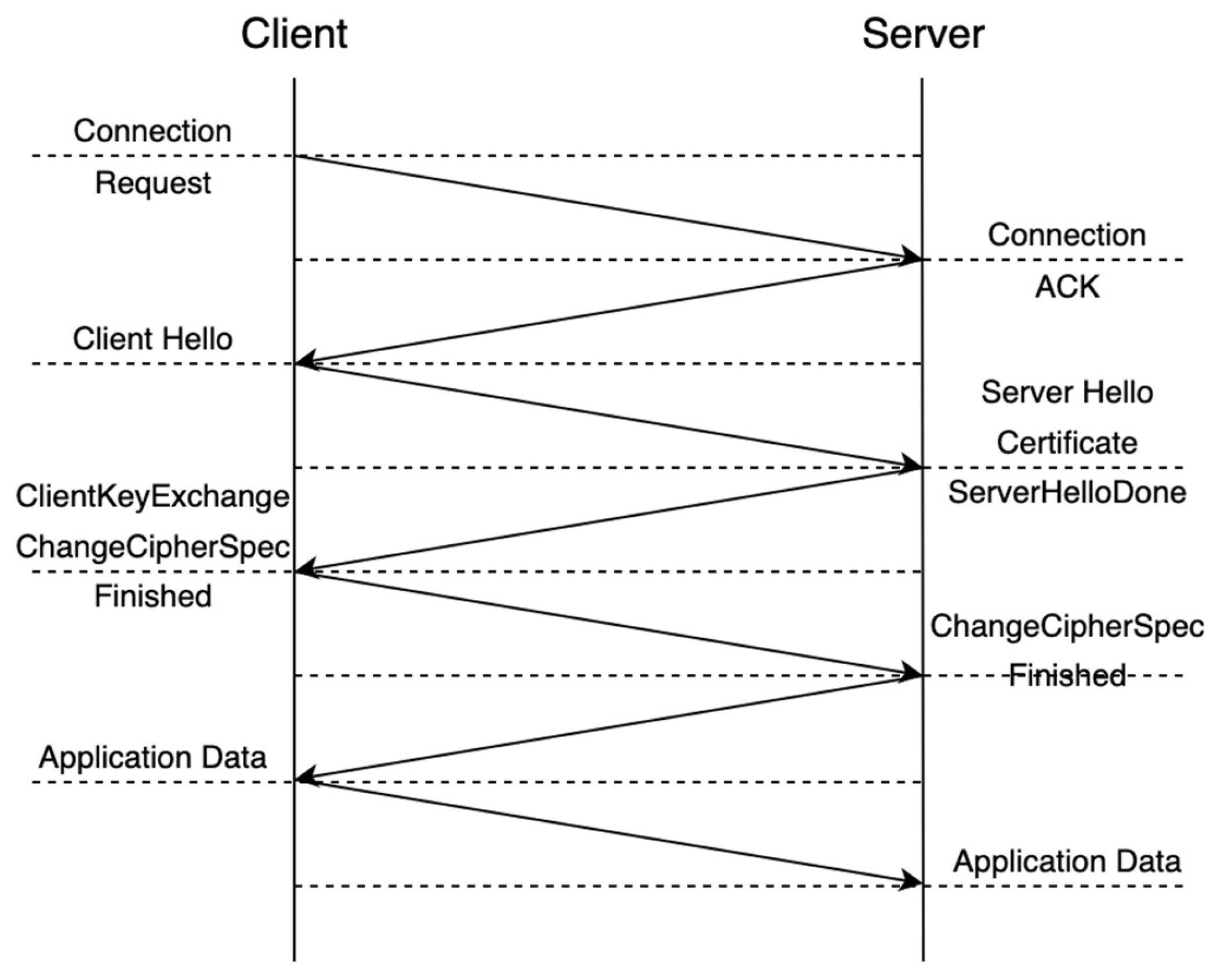
| Algorithm 2. TLS1.2 establishes a secure link process. |
| Algorithm 3. Process of RA-TLS1.2 establishing a secure link. |
|
3.3.4. External Memory Privacy Protection
3.4. System Design Security Assumptions
3.5. Introduction to the Training Process
3.6. Attack Defense
4. Experimental Testing and Evaluation
4.1. Test Content
4.2. Test Result
4.3. Privacy Protection Assessment
5. Conclusions
6. Limitations
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A survey on security and privacy of federated learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Fredrikson, M.; Lantz, E.; Jha, S.; Lin, S.; Page, D.; Ristenpart, T. Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing. In Proceedings of the USENIX Security Symposium, San Diego, CA, USA, 20–22 August 2014; pp. 17–32. [Google Scholar]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3–18. [Google Scholar]
- Melis, L.; Song, C.; Cristofaro, E.D.; Shmatikov, V. Exploiting unintended feature leakage in collaborative learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online, 26–28 August 2020. PMLR. [Google Scholar]
- Cabrero-Holgueras, J.; Pastrana, S. SoK: Privacy-Preserving Computation Techniques for Deep Learning. Proc. Priv. Enhancing Technol. 2021, 4, 139–162. [Google Scholar] [CrossRef]
- Mireshghallah, F.; Vepakomma, P.; Singh, A.; Raskar, R.; Esmaeilzadeh, H. Privacy in deep learning: A survey. arXiv 2020, arXiv:2004.12254. [Google Scholar]
- Costan, V.; Devadas, S. Intel sgx explained. IACR Cryptol. ePrint Arch. 2016, 86, 1–118. [Google Scholar]
- Kaplan, D.; Powell, J.; Woller, T. AMD Memory Encryption. White Paper. 2016. Available online: https://www.amd.com/content/dam/amd/en/documents/epyc-business-docs/white-papers/memory-encryption-white-paper.pdf (accessed on 1 January 2024).
- Winter, J. Trusted computing building blocks for embedded linux-based arm trustzone platforms. In Proceedings of the 3rd ACM Workshop on Scalable Trusted Computing, Fairfax, VA, USA, 16 June 2008; pp. 21–30. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016. [Google Scholar]
- Damgård, I.; Pastro, V.; Smart, N.; Zakarias, S. Multiparty Computation from Somewhat Homomorphic Encryption; Safavi-Naini, R., Canetti, R., Eds.; CRYPTO 2012 LNCS; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7417, pp. 643–662. [Google Scholar]
- Keller, M.; Orsini, E.; Scholl, P. MASCOT: Faster malicious arithmetic secure computation with oblivious transfer. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 830–842. [Google Scholar]
- Ball, M.; Malkin, T.; Rosulek, M. Garbling Gadgets for Boolean and Arithmetic Circuits. In ACM CCS 16; Weippl, E.R., Katzenbeisser, S., Kruegel, C., Myers, A.C., Halevi, S., Eds.; ACM Press: New York, NY, USA, 2016; pp. 565–577. [Google Scholar]
- Keller, M.; Pastro, V.; Rotaru, D. Overdrive: Making SPDZ great again. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Tel Aviv, Israel, 29 April–3 May 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Mo, F.; Haddadi, H.; Katevas, K.; Marin, E.; Perino, D.; Kourtellis, N. PPFL: Privacy-preserving federated learning with trusted execution environments. In Proceedings of the 19th Annual International Conference on Mobile Systems, Applications, and Services, Virtual Event, 24 June–2 July 2021; pp. 94–108. [Google Scholar]
- Zhao, L.; Jiang, J.; Feng, B.; Wang, Q.; Shen, C.; Li, Q. Sear: Secure and efficient aggregation for byzantine-robust federated learning. IEEE Trans. Dependable Secur. Comput. 2021, 19, 3329–3342. [Google Scholar] [CrossRef]
- Freivalds, R. Probabilistic Machines Can Use Less Running Time. IFIP Congr. 1977, 839, 842. [Google Scholar]
- Knauth, T.; Steiner, M.; Chakrabarti, S.; Lei, L.; Xing, C.; Vij, M. Integrating remote attestation with transport layer security. arXiv 2018, arXiv:1801.05863. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack Name | Attack Pattern | Attack Process | White/Black Box | Attack Target |
|---|---|---|---|---|
| Model inversion attack | For a model with a simple structure, dynamic analysis is used or the similarity between samples is calculated. | Training | White box | Breaks user or training dataset privacy. |
| Inference attack | Trains a factor or target attribute binary classifier. | Training | Black box | Determines whether a training set exists for a particular sample or statistical feature. |
| Backdoor attack | A backdoor model is trained by poisoning samples and so on and implanting them into the global model. | Training | Black box | Affects the performance of the model and makes wrong judgments on specific samples. The attack is more extensive. |
| No. | Model | Batch Size | Epoch | Loading Time | Running Time (avg) | Mem (G), Threads (per Process) | ||
|---|---|---|---|---|---|---|---|---|
| Enclave (s) | Native (s) | Enclave | Native | |||||
| 1 | Linear | 1 | 2 | 11 m 10 s | 24 s | 2 s | 32, 512 | 5, − |
| 2 | w&d | 256 | 2 | 12 m 51 s | 13 m 53 s | 4 m 24 s | 32, 512 | 5, − |
| No. | Model | Batch Size | Epoch | Loading Time | Running Time (avg) | Mem (G), Threads | PF | ||
|---|---|---|---|---|---|---|---|---|---|
| Enclave (s) | Native (s) | Enclave | Native | ||||||
| 1 | w&d | 256 | 2 | 11 m 5 s | 11 m 16 s | 4 m 24 s | 32, 512 | 5, 360+ | N |
| 2 | w&d | 256 | 2 | 11 m 5 s | 10 m 50 s | 4 m 24 s | 32, 512 | 5, 360+ | Y |
| 3 | w&d | 256 | 2 | 21 m 14 s | 11 m 32 s | 4 m 24 s | 64, 512 | 5, 360+ | N |
| 4 | w&d | 256 | 2 | 21 m 14 s | 11 m 20 s | 4 m 24 s | 64, 512 | 5, 360+ | Y |
| 5 | w&d | 1024 | 2 | 11 m 6 s | 4 m 35 s | 2 m 7 s | 32, 512 | 5, 360+ | Y |
| 6 | w&d | 1024 | 2 | 11 m 7 s | 4 m 26 s | 2 m 7 s | 32, 512 | 5, 360+ | N |
| 7 | w&d | 1024 | 10 | 11 m 4 s | 17 m 12 s | 7 m 5 s | 32, 512 | 5, 360+ | Y |
| 8 | w&d | 1024 | 10 | 11 m 3 s | 16 m 55 s | 7 m 5 s | 32, 512 | 5, 360+ | N |
| 9 | w&d | 1024 | 500 | 21 m 4 s | 2 h 23 m 49 s | 1 h 1 m 54 s | 64, 1024 | 5, 360+ | Y |
| Attack Method | Test Method and Results | Expected Outcome |
|---|---|---|
| Hardware penetration attack | Printing the content of the Enclave address through GDB, an illegal memory access error occurs | Enclave memory illegal access, as expected |
| Man-in-the-middle attack | Capturing packets to steal cipher text, unable to obtain the private key of the certificate, and thus unable to decrypt | Unable to decrypt, as expected |
| External data access | By reading the model parameter information from the model checkpoint file, the cipher text is obtained and cannot be viewed | The cipher text cannot be viewed, as expected |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Duan, B.; Li, J.; Ma, Z.; Cao, X. A TEE-Based Federated Privacy Protection Method: Proposal and Implementation. Appl. Sci. 2024, 14, 3533. https://doi.org/10.3390/app14083533
Zhang L, Duan B, Li J, Ma Z, Cao X. A TEE-Based Federated Privacy Protection Method: Proposal and Implementation. Applied Sciences. 2024; 14(8):3533. https://doi.org/10.3390/app14083533
Chicago/Turabian StyleZhang, Libo, Bing Duan, Jinlong Li, Zhan’gang Ma, and Xixin Cao. 2024. "A TEE-Based Federated Privacy Protection Method: Proposal and Implementation" Applied Sciences 14, no. 8: 3533. https://doi.org/10.3390/app14083533
APA StyleZhang, L., Duan, B., Li, J., Ma, Z., & Cao, X. (2024). A TEE-Based Federated Privacy Protection Method: Proposal and Implementation. Applied Sciences, 14(8), 3533. https://doi.org/10.3390/app14083533