3.1. Data Collection and Preprocessing
We implemented a Python crawler to scrape online reviews on MOOC platforms. After that, we conducted the following preprocessing:
Step 1: Removing duplicate reviews. Removing duplicate reviews can help us improve the efficiency and quality of text mining.
Step 2: Text segmentation. As some reviews are long in length, they may contain multiple course keywords. We first used symbols (e.g., “.”, “?”, “!”, “…”) to segment longer reviews into short sentences, trying to make each sentence contain only one course keyword. Then we segmented the sentences into word lists to facilitate course attribute extraction and sentiment analysis.
Step 3: Removing stop words, including meaningless punctuation (e.g., !?#@). Removing stop words not only prevents subsequent steps from wasting time on non-informative words but also enhances the accuracy and efficiency of determining emotional and non-emotional content. As we intend to employ deep-learning-based text classification methods for the identification of emotional and non-emotional content, the presence of stop words can potentially compromise the performance of these models.
Step 4: Data labeling. Given that our sentiment analysis task relies on machine learning algorithms, labeled datasets are essential for training classifiers. Therefore, it is imperative to label the data, classifying them into four distinct categories: positive, negative, neutral, and non-emotional.
Step 5: Part-of-speech tagging. To extract alternative attribute words for courses, which are typically nouns, we must first determine the part-of-speech of each word in the course reviews.
Among them, for word segmentation and part-of-speech tagging, we utilized the jieba word segmentation tool, a highly renowned Chinese word segmentation utility in Python.
3.2. Course Attributes Extraction
Previous studies mainly used the LDA topic model or word embedding to extract and classify product attributes, where word embedding methods do not require manual interpretation of each topic [
49]. Therefore, we used the word embedding method to extract and classify course attributes. Our approach consisted of the following steps:
Step 1: Nouns were extracted from all the reviews for a course, that is, words that start with “n” in the POS tags. Course attributes are usually nouns, so we extract the nouns in course reviews as our alternative attribute words. The number of extracted nouns is usually large, and the main attributes of a course may be limited to a few, so we needed to find a way to cluster these nouns and then treat each cluster as an attribute. Clustering algorithms usually take input in vector form, so we needed to convert nouns into vector form.
Step 2: To convert the selected nouns into a vectorized format, we employed the FastText word embedding approach. Word embedding is a technique that maps words onto a vector space, allowing each word to be represented by a unique vector. Furthermore, words with similar meanings tend to have word vectors that are proximate in Euclidean space. This characteristic makes word embedding an ideal approach for converting words into vectors and subsequently clustering them. A representative word embedding method is FastText [
62], which considers the morphology of words, that is, the n-grams of word characters. For example, the 2-g of the word “where” includes “wh”, “he”, “er”, and “re”. FastText for words that do not occur during training can be represented by the sum of its character n-grams, which allows FastText to represent any word. The pre-trained Chinese FastText word vectors (
https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.zh.300.bin.gz (accessed on 1 February 2024)) are used to represent the nouns in our work.
Step 3: For noun clustering, we employed a combined approach incorporating Affinity Propagation (AP) clustering [
63] and manual intervention. AP is one of the most classical and widely used clustering methods that clusters the close words into the same cluster and the far words into different clusters by calculating the distance. A significant advantage of AP clustering is that it does not require the specification of the number of clusters upfront. After AP clustering, we manually proofread the clustering results to make the meaning of words in each cluster as close as possible and delete meaningless words.
Step 4: The words in each cluster after clustering are induced to summarize the course attributes. By summarizing the nouns in each cluster into attributes, we can know the main attributes of a course that learners pay attention to.
Step 5: The nouns’ frequency of different attributes was counted, as was the total word frequency of an attribute. This approach is based on the assumption that a higher frequency of an attribute word indicates greater learner attention and importance placed on that specific attribute.
3.3. Determination of the Emotional and Non-Emotional Content Corresponding to the Course Attributes
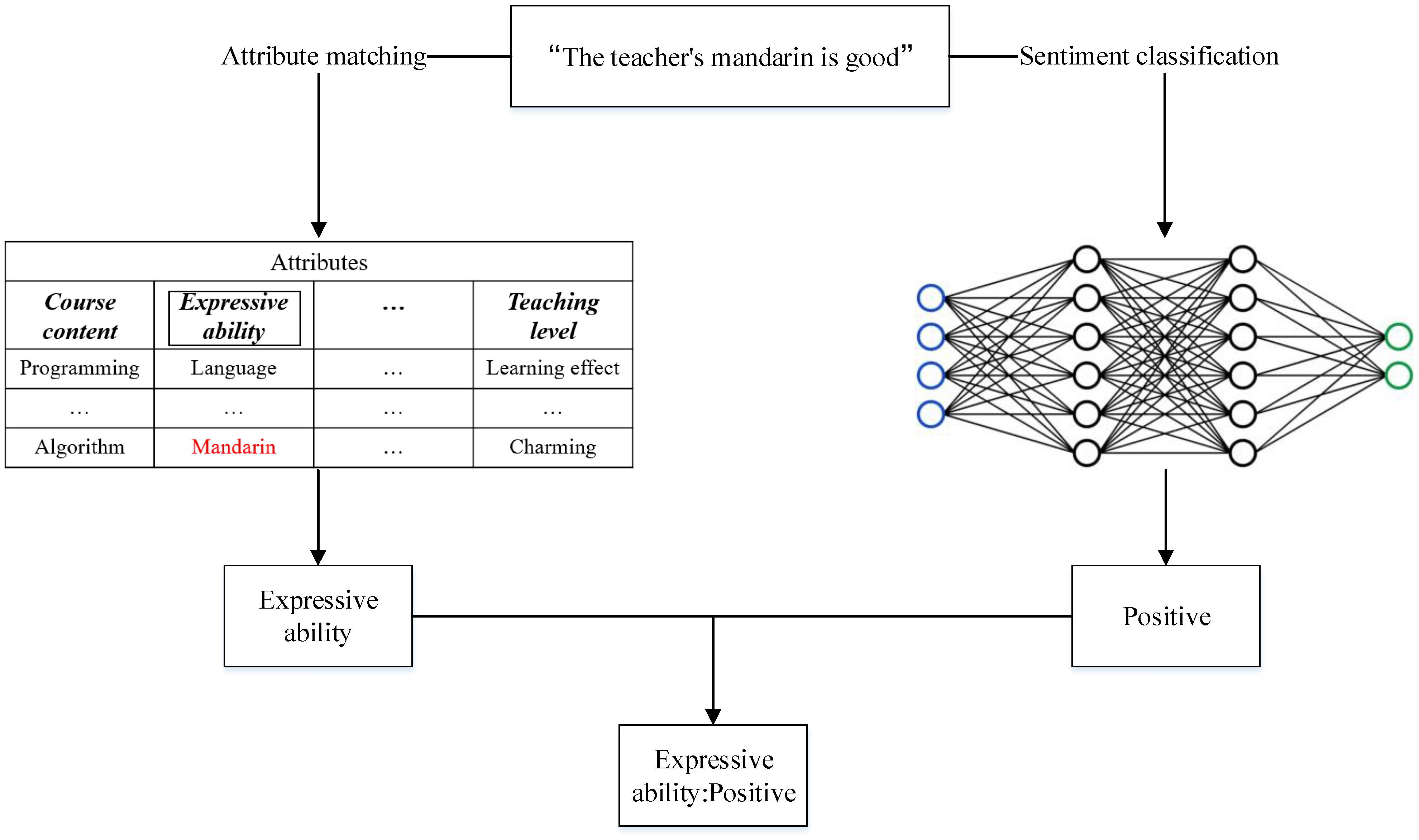
To identify the emotional and non-emotional content associated with the course attributes, we built a deep-learning-based text classification model. This model was trained to categorize review text into four distinct classes: positive, negative, neutral, and non-emotional. For ease of presentation, the classification of a review belonging to these four classes was collectively referred to as sentiment classification. We used a simple means to determine the course attribute and its corresponding sentiment class in a review: if a review contains a word belonging to an attribute whose sentiment tendency has been determined to be non-emotional, we consider the attribute to be non-emotional in this review. For example, in the sentence “The teacher’s mandarin is good”, obviously, this is a positive review, and if mandarin belongs to the attribute “expressive ability”, we can assume that the emotional tendency of expressive ability in this sentence is positive (see
Figure 2). We have highlighted the keywords that appear in the sentence in red in the
Figure 2 and highlighted the corresponding attribute in the box. First and foremost, we carefully selected a specific number of comments from the vast pool of online feedback to be manually annotated. Positive sentiment comments are labeled as 1, negative sentiment as −1, neutral sentiment as 0, and comments lacking emotional expression are designated as 2. Subsequently, a subset of these annotated comments was utilized to train a deep learning model, while the remaining comments served as a validation set to assess the model’s accuracy. After rigorous testing, the model exhibiting the highest predictive accuracy was chosen to analyze the emotional tendencies of the remaining unlabeled comments.
The pivotal aspect lies in developing a deep-learning-based sentiment classification model that can effectively categorize and analyze the sentiment expressed in reviews. The reason why we choose deep learning for sentiment classification is that in recent years, deep learning has gradually become the mainstream model for sentiment classification, and with the help of pre-trained language models such as BERT [
64], the accuracy of sentiment classification has also been greatly improved. Deep learning is a machine learning technique rooted in artificial neural networks, requiring the integration of various deep learning modules to construct a complete model. Our deep-learning-based sentiment classification model is structured into three distinct modules: the embedding layer, the intermediate layer, and the output layer.
3.3.1. Embedding Layer
As previously mentioned in
Section 3.2, word embeddings serve as a mechanism to transform words into a vectorized format. The embedding layer specifically handles the vectorization of words within the deep learning model. We utilized the BERT model directly for word embedding due to its exceptional performance in downstream tasks, particularly sentiment classification. In this paper, we directly used Chinese BERT (
https://huggingface.co/bert-base-chinese (accessed on 2 February 2024)) pre-trained by Hugging Face to help us with word embedding. Hugging Face (
https://huggingface.co/ (accessed on 1 February 2024)) is an artificial intelligence community, providing people with a large number of artificial intelligence code and application programming interface (API), so that people can implement artificial intelligence with low cost. The inputs and outputs in BERT-based embedding can be seen in
Figure 3.
The inputs in BERT embedding are words (for English) or characters (for Chinese) of a sentence, which are [CLS], , , …, , [SEP], where , , …, are words or characters of a sentence of length n (the number of English words or Chinese characters), “[CLS]” is a symbol specifically used for text classification, and “[SEP]” represents a sentence separator or terminator. When we input sentences, Hugging Face automatically adds these two symbols to the original sentences without us having to manually do so. The outputs are , , …, , and , which are the vector representation of all inputs.
3.3.2. Intermediate Layer
Compared with the embedding layer and output layer, which are relatively fixed, the intermediate layer changes more. In order to avoid using only one intermediate layer and resulting in poor performance of the trained classifier, we compared six intermediate layers: base BERT, feed-forward neural network (FFNN), CNN, LSTM, LSTM combined with attention mechanism (LSTM + attention), and LSTM combined with CNN (LSTM + CNN).
- (1)
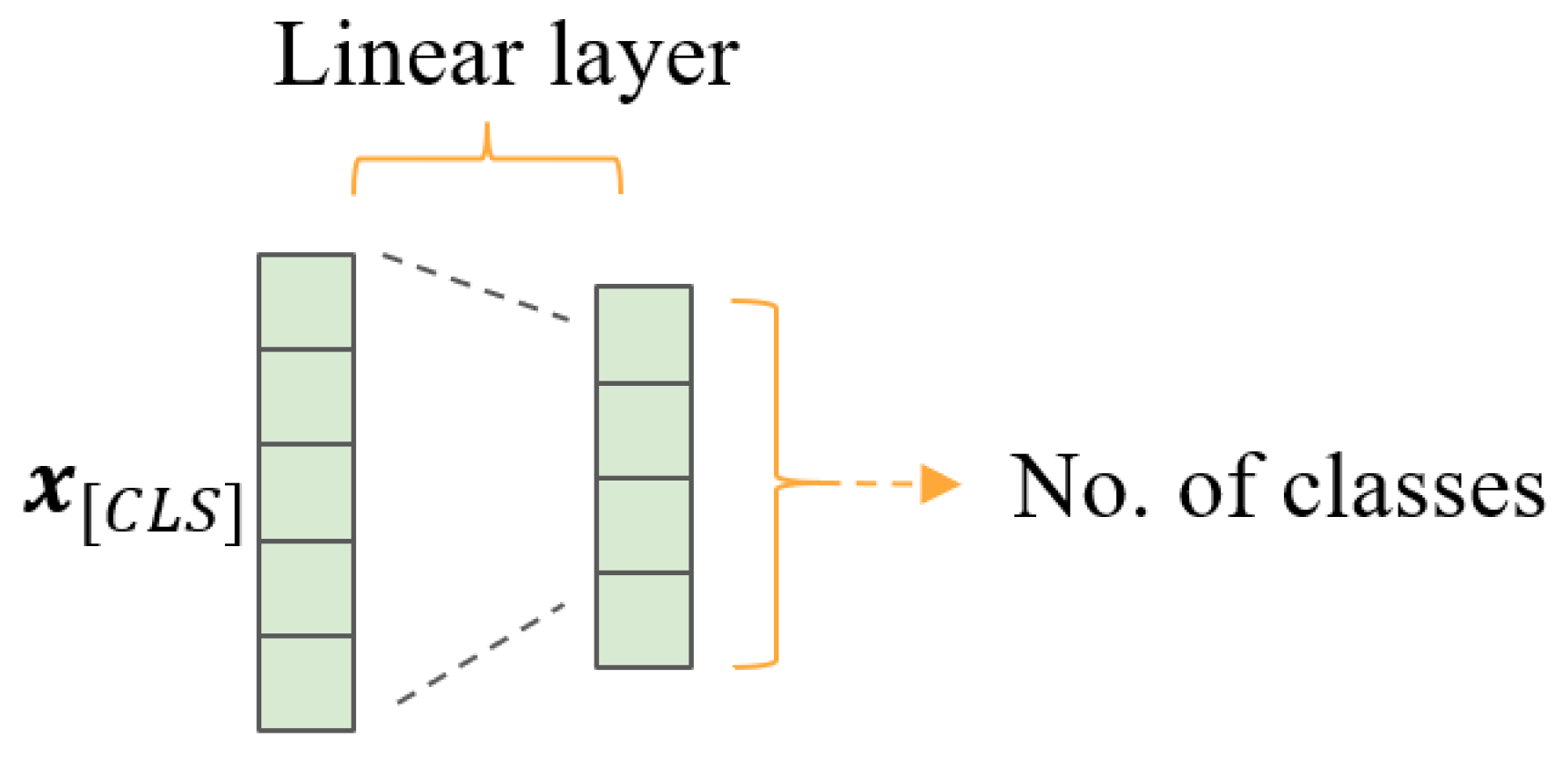
Base BERT
One of the simplest uses of the BERT architecture is baseBERT, which uses BERT for word embeddings and then feeds the vector representation of “[CLS]” into a linear layer classifier (see
Figure 4).
- (2)
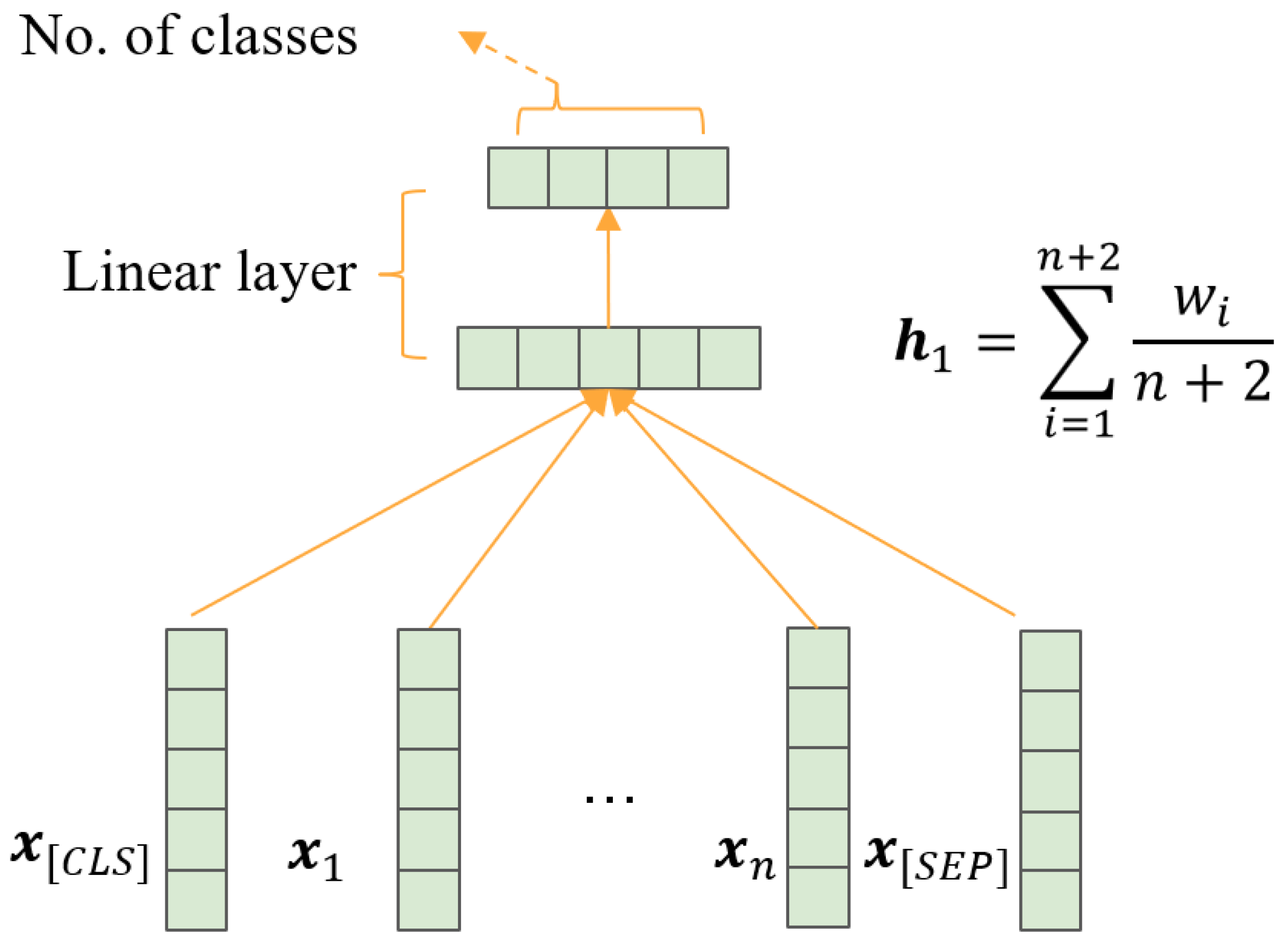
FFNN
FFNNs are the most primitive deep learning modes. A representative model is the deep average network (DAN) [
65], as shown in
Figure 5. Its main structure includes the embedded, average, linear, and output layers. In our work, we adopted the following structure depicted in
Figure 5. The embedding size within our DAN was set to 100.
- (3)
CNN
CNNs (convolutional neural networks) extract features from the input text by applying convolutional filters, enabling the capture of local n-gram patterns. Max-pooling layers then select the most important features, and fully connected layers classify the text. In our work, we used the structure based on the work of Kim [
66]. We employed 100 kernels of three different sizes (2, 3, and 4) for feature extraction, followed by max-pooling for pooling (see
Figure 6).
- (4)
LSTM
LSTM networks are a type of RNN designed to handle sequential data. In sentiment classification, LSTMs process text one token at a time, capturing contextual information through their memory cells. The final hidden state is then fed into a classification layer to predict the label. We used Bidirectional LSTM (BiLSTM) in our work (see
Figure 7). The hidden layer size of the LSTM is 100 and the output size of the first linear layer is 128.
- (5)
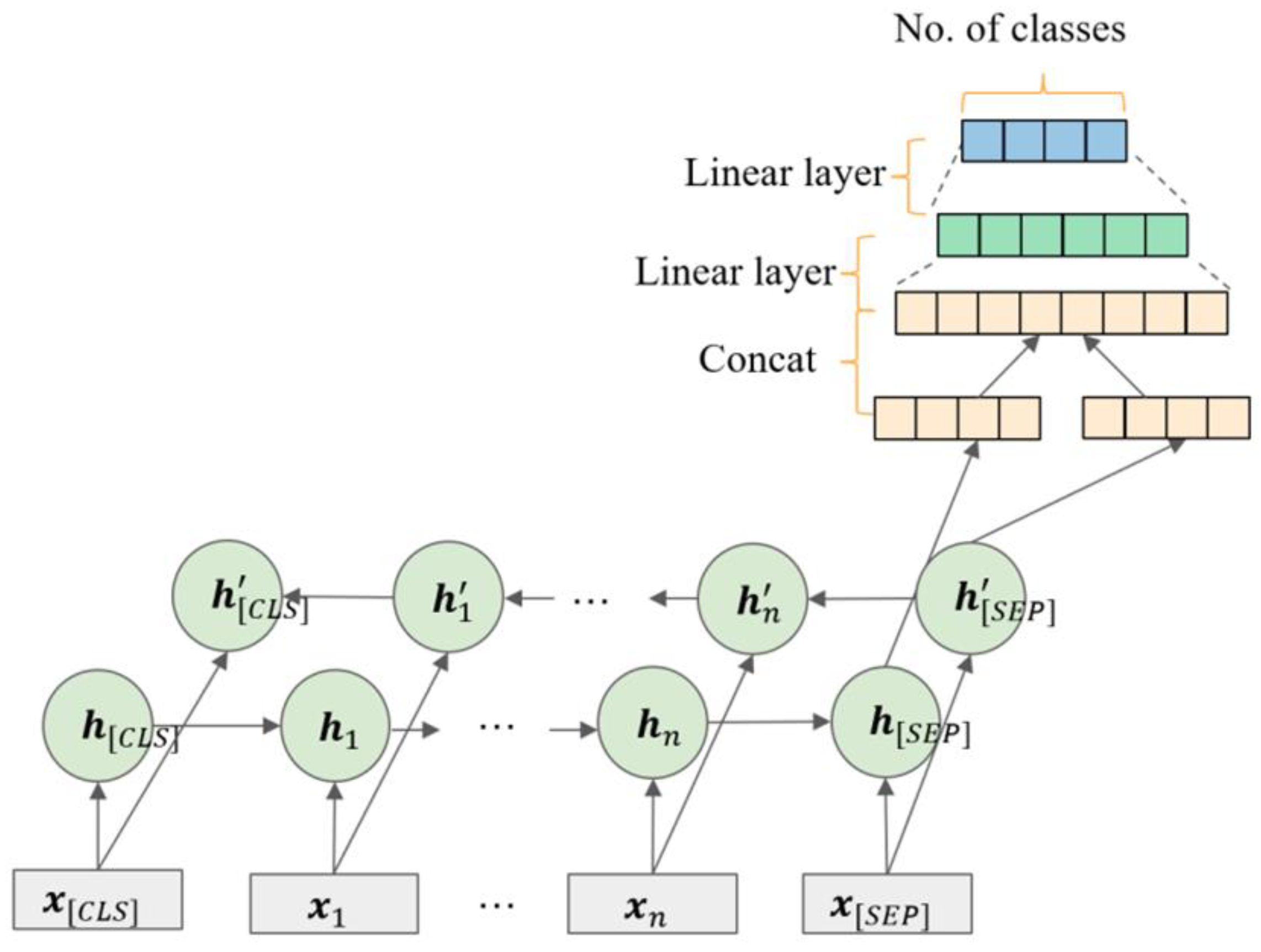
LSTM+attention
The ordinary LSTM-based text classification method only uses the output of the last time step as the input of the classifier, while the LSTM+attention-based method aims to weight the output of all time steps to obtain the input of the classifier (see
Figure 8), which can consider more semantic information.
We used the calculation of Yang et al. [
67] to achieve
as follows:
Then we can obtain the weighted sentence representation
as follows:
where
,
,
are parameters,
is the weight of the output
, and
is the sentence representation after the weighted sum.
- (6)
LSTM+CNN
The LSTM+CNN structure is able to combine the advantages of LSTM and CNN, where LSTM is able to capture long-term dependencies and CNN is able to extract local features. We added residual structure to help convergence. The model we used can be seen in
Figure 9.
3.3.3. Output Layer
The output layer is unified as softmax layer for most deep-learning-based sentiment classification. The softmax layer can be calculated as follows:
By utilizing our proposed sentiment classification method, we can extract the attributes mentioned in each review along with their corresponding sentiment. Subsequently, we calculate the overall count of reviews that involve distinct attributes and various emotional responses, as depicted in
Figure 10.
3.5. Generation of the Priority of Attributes Improvement
After the previous steps, we obtained six evaluation criteria for each course attribute: the number of positive reviews (
), the number of neutral reviews (
), the number of negative reviews (
), the number of non-emotional reviews (
), the attribute frequency (
), and the improvement cost (
) (see
Table 1).
In
Table 2,
,…,
represent evaluation criteria,
,…,
represent course attributes, and
represents the value of the
th evaluation criterion of the
th attribute.
Given the varying number of attribute words across different attributes, it is unfair to simply tally the total number of reviews expressing various sentiments for all the attribute words within a single attribute, especially for those with fewer attribute words. We normalize the values of , , , and using the number of reviews involving the attribute with positive, negative, neutral and no sentiment divided by the total number of reviews involving the attribute. For , we take the average of the number of reviews involving each word in an attribute.
So, we use the following formulas to calculate
,
,
,
, and
:
can by calculated by Formula (5). In Formulas (6)–(10), represents the index of word, represents the set of attribute words for attribute , represents the cardinality of set , represents the number of reviews involving th word, represents the number of reviews involving any words in and , , , and represent the number of positive, neutral, negative, and non-emotional reviews involving th word, respectively.
Our task is to decide the priority of course attribute improvement. represents the degree of learners’ satisfaction. Obviously, the higher the degree of satisfaction, the lower the priority for improvement. Therefore, it is a cost criterion. The neutral reviews indicate that learners are not very satisfied with the mentioned attributes; that is, they still have a certain degree of dissatisfaction, and thus, is the benefit criterion. Similarly, is a benefit criterion. Although reviews without emotional content do not express satisfaction or dissatisfaction, if certain attributes are mentioned by learners in reviews, it means that learners may pay more attention to these attributes. Thus, the is benefit criterion. represents the total attention and is therefore a benefit criterion. The higher the improvement cost, the more difficult the improvement. Obviously, is the cost criterion.
Next, we employed the multi-attribute decision-making (MADM) approach to assess the attributes. Specifically, we utilized the Technique for Order Preference by Similarity to Ideal Solution (TOPSIS) method [
69] to determine the priority scores for attribute improvement. TOPSIS determines a score for each alternative by calculating the distance between the true alternative and two ideal alternatives: the positive ideal alternative (a dummy alternative constructed with the best value of each attribute of all alternatives) and the negative ideal alternative (a dummy alternative constructed with the worst value of each attribute of all alternatives). The calculation process for TOPSIS has been detailed in our previous work [
70].
The TOPSIS method requires the weights of various indicators to be determined beforehand. Therefore, we adopted the entropy weight method (EWM) to determine the weights of each indicator. Since the entropy weight method is an objective weight calculation method that determines the weight of an indicator based on the amount of information, it can reduce the deviation caused by subjective factors when determining the weight of indicators and make the results more practical. It has been widely used [
71]. The calculation steps are as follows:
Step 1: Data standardization.
To eliminate the influence of varying scales and magnitudes, the original data must be normalized. The normalization formula is as follows:
where
is the original value of the
th evaluation criterion of the
th alternative,
is the normalized value, and
and
are the minimum and maximum values of the
th evaluation criterion, respectively.
Step 2: Calculate the entropy value of each criterion.
Compute the entropy value for each criterion. The entropy value reflects the degree of dispersion in the criterion data. The formula is as follows:
where
is the entropy value of the
th evaluation criterion,
is the number of alternatives,
is the proportion of the
th evaluation criterion value for the
th alternative to the sum of that criterion, which can be calculated by
, and
is the natural logarithm.
Step 3: Calculate the dispersion coefficient of each criterion.
The dispersion coefficient is the reciprocal of the entropy value and reflects the ability of a criterion to distinguish between evaluation objects. The formula is as follows:
Step 4: Calculate the weight of each criterion.
Determine the weight for each criterion based on its dispersion coefficient. The weights are proportional to the dispersion coefficients. The formula is as follows:
where
is the weight of the
th evaluation criterion, and
is the number of criteria.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










