
Augmenting Environmental Interaction in Audio Feedback Systems †



Abstract
:1. Introduction
2. Related Work
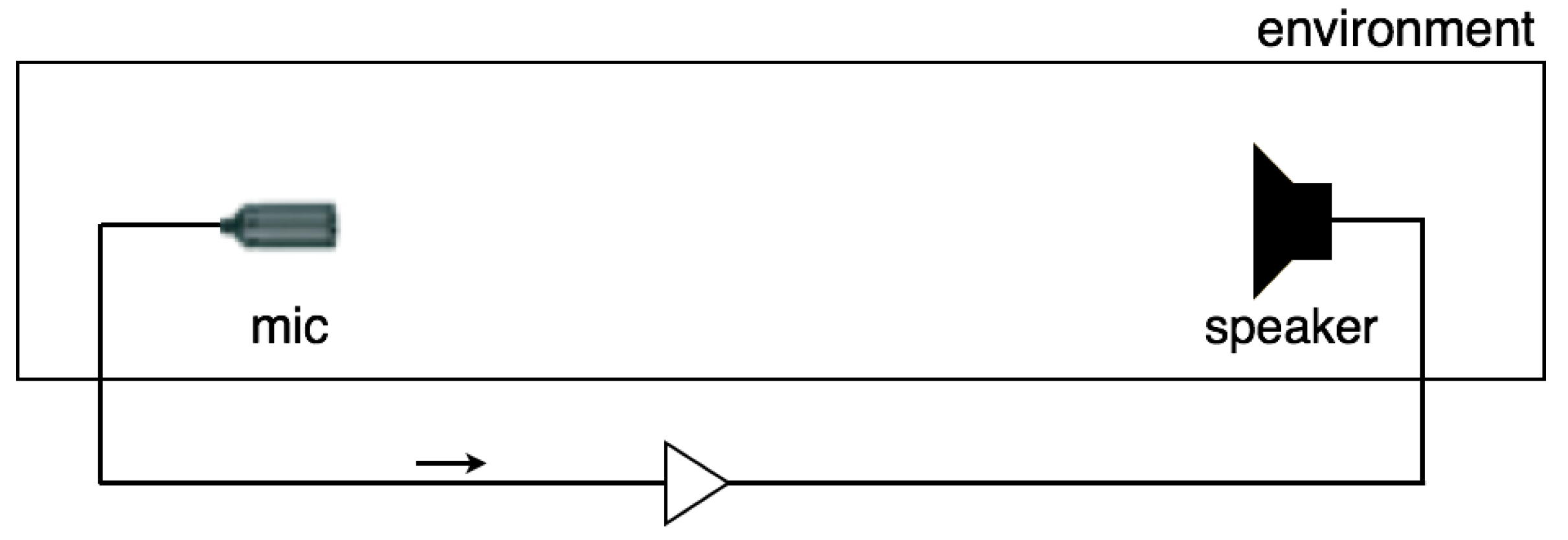
2.1. Audio Feedback in Computer Music
2.2. The Feature of Openness in Audio Feedback
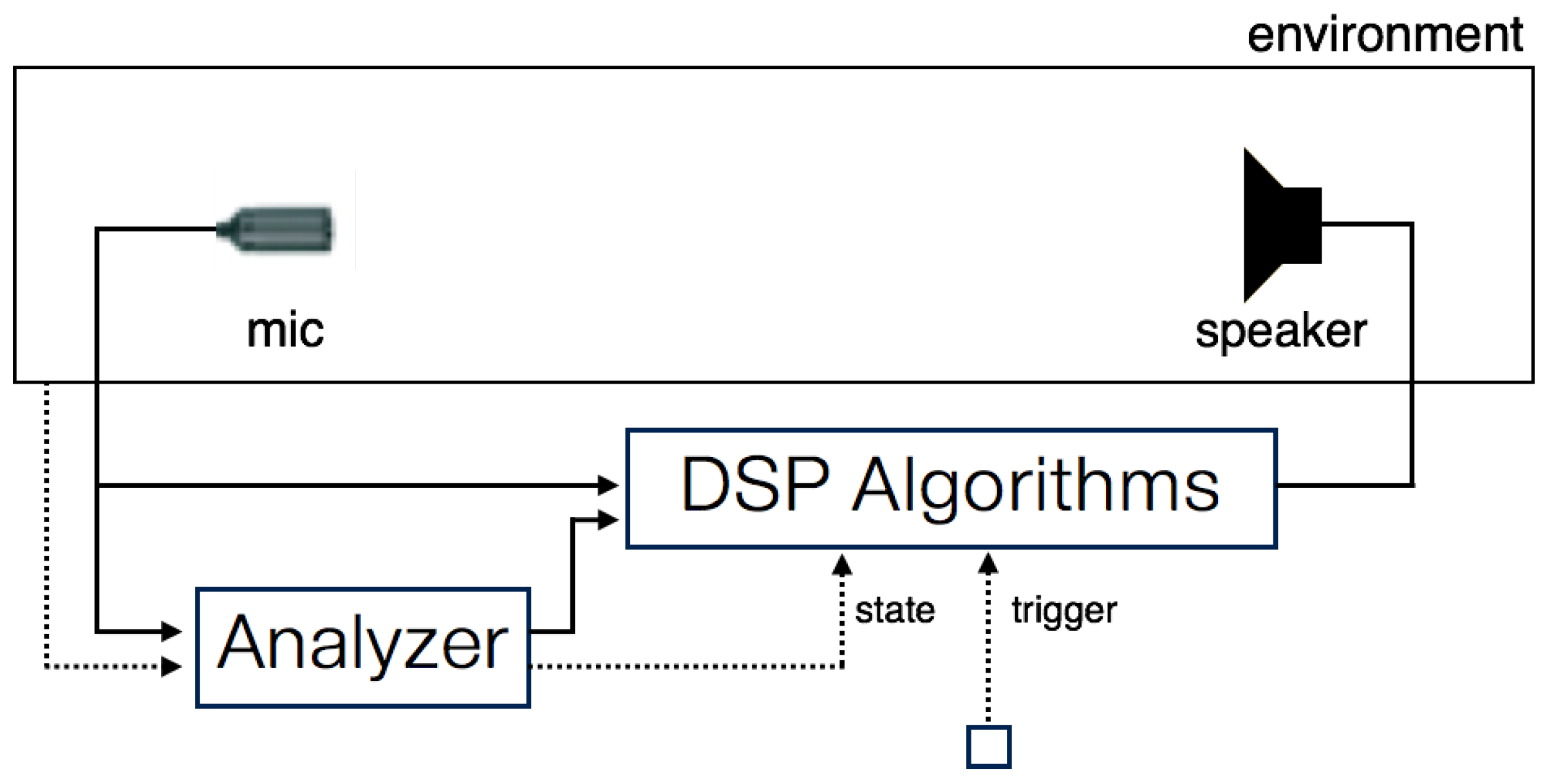
2.3. Context-Based Control of Audio Feedback
3. System Design and Validation
- The amount of reverberation in the space determines a tempo-scale characteristic
- The system will change its output level depending on the volume level of ambient noise
- A prominent resonance determines a timbre characteristic
- The distribution of room modes determines a timbre characteristic, energy of higher frequency partials in particular
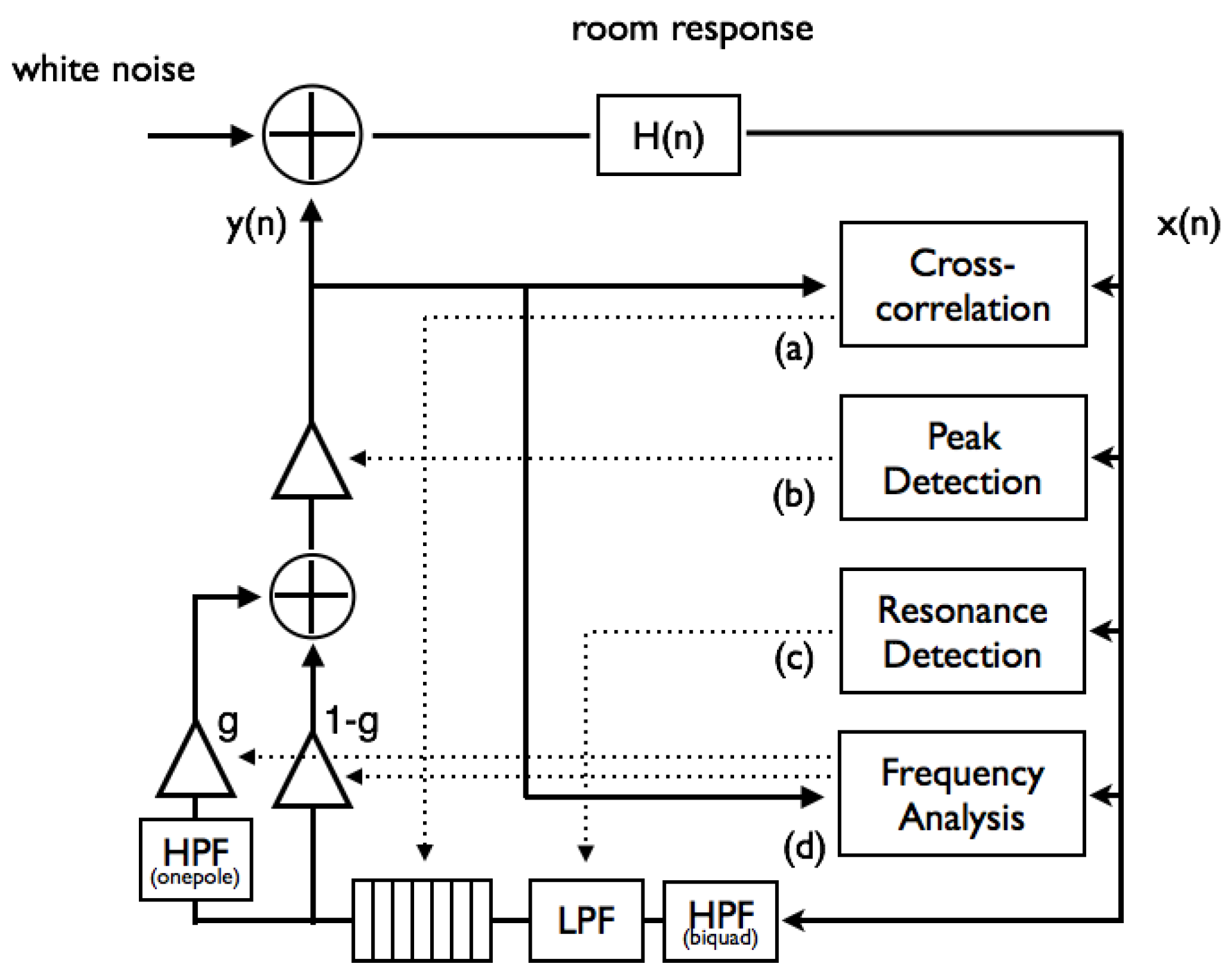
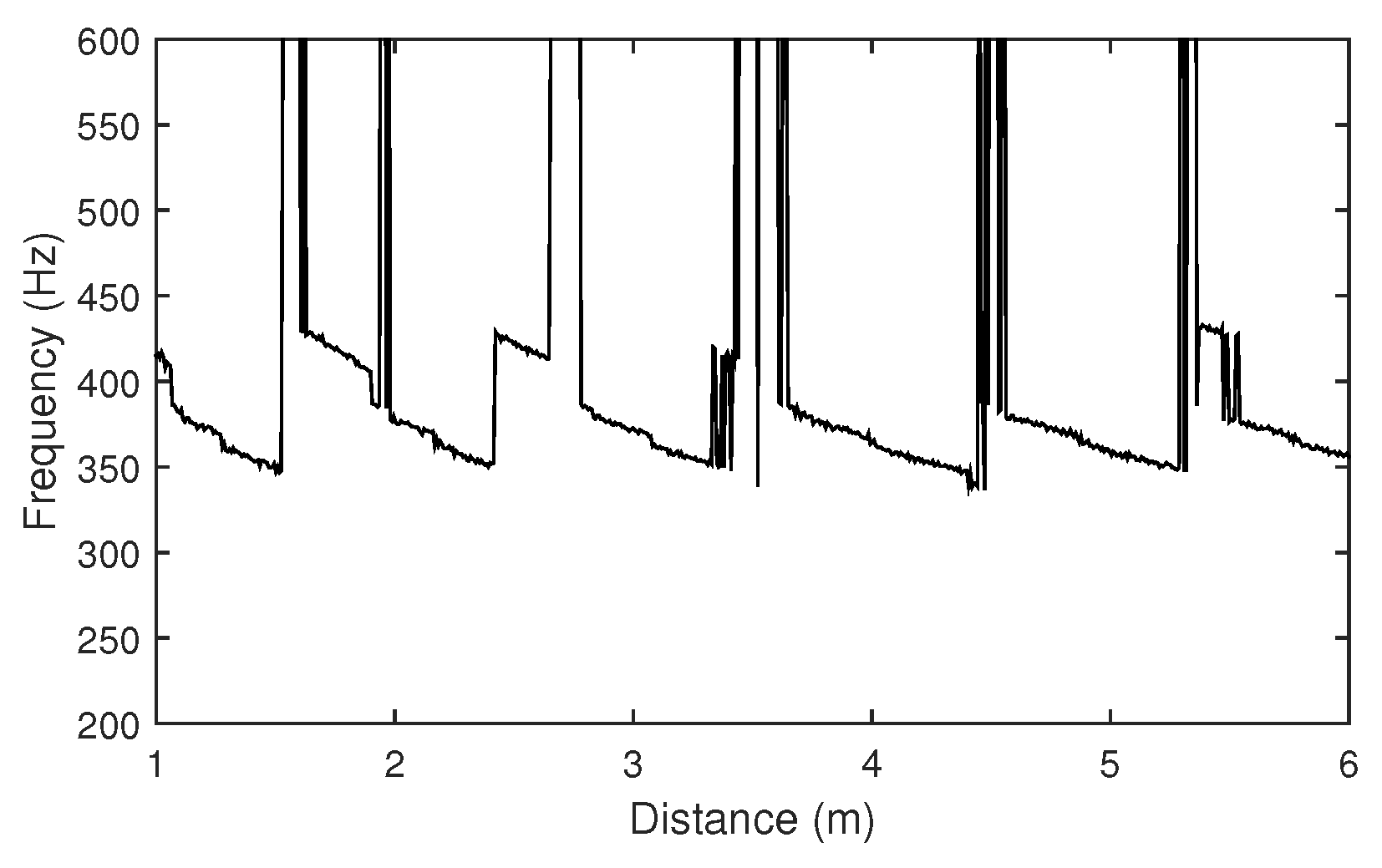
3.1. Reverberation Level with Tempo
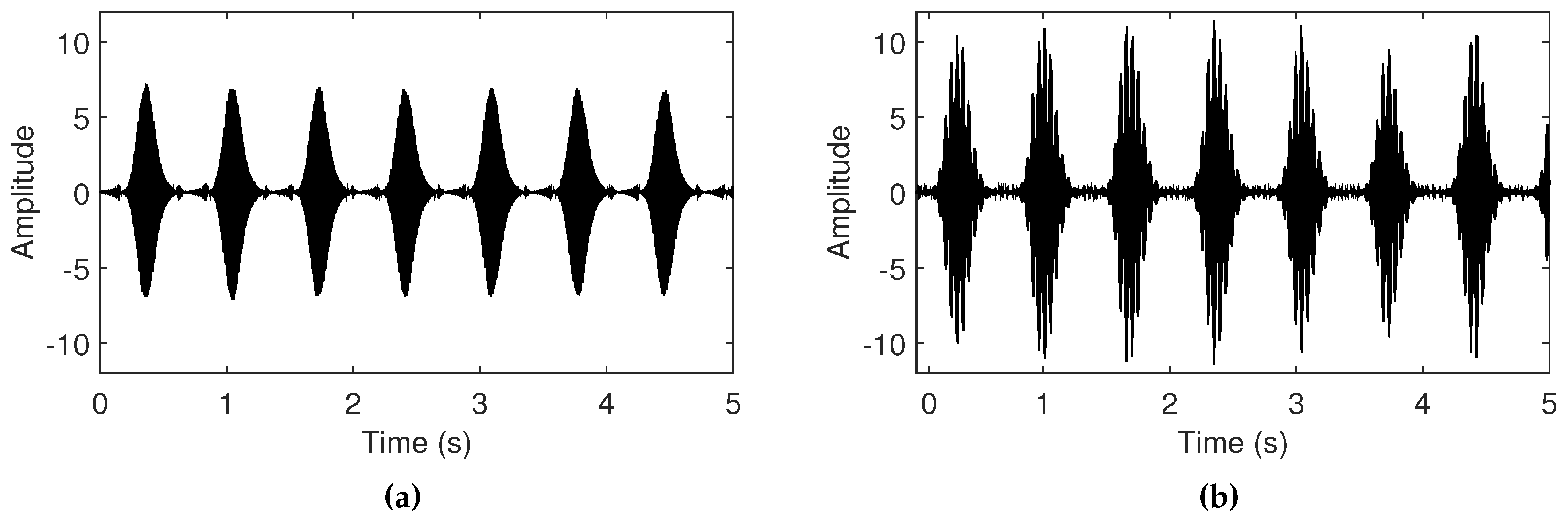
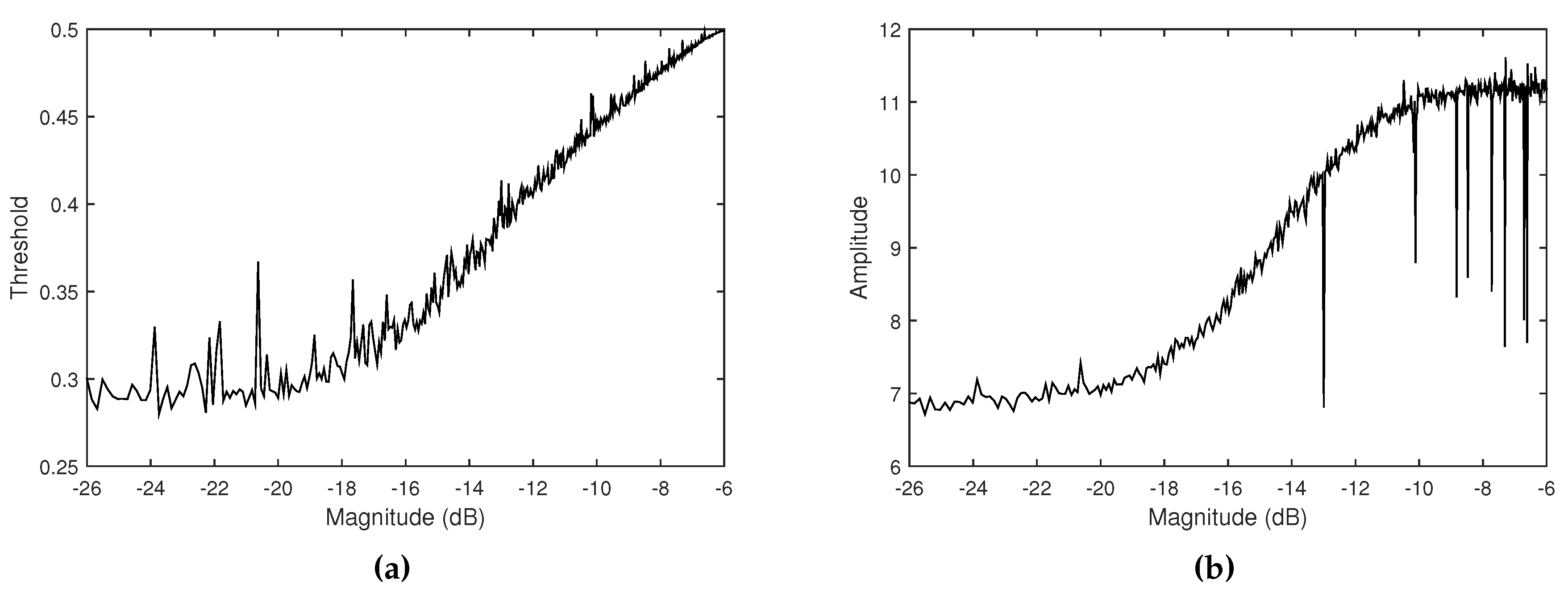
3.2. Ambient Noise Level with Amplitude Control
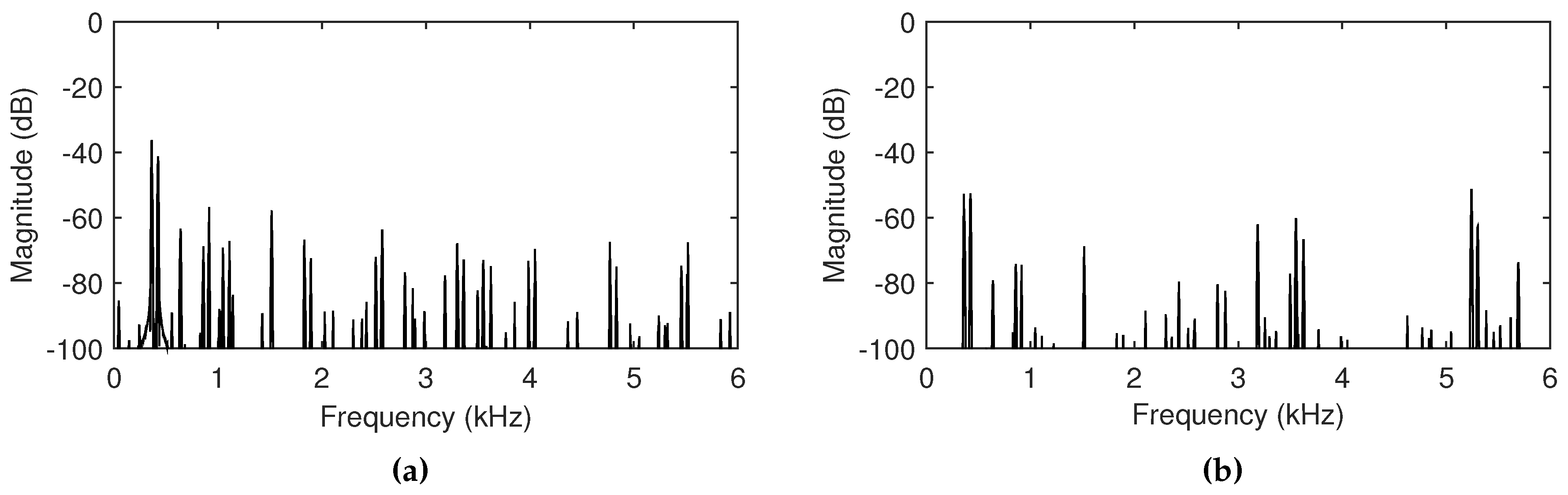
3.3. Acoustic Resonance with Timbre
3.4. Distribution of Room Modes with Timbre
4. Experiments in a Real Room
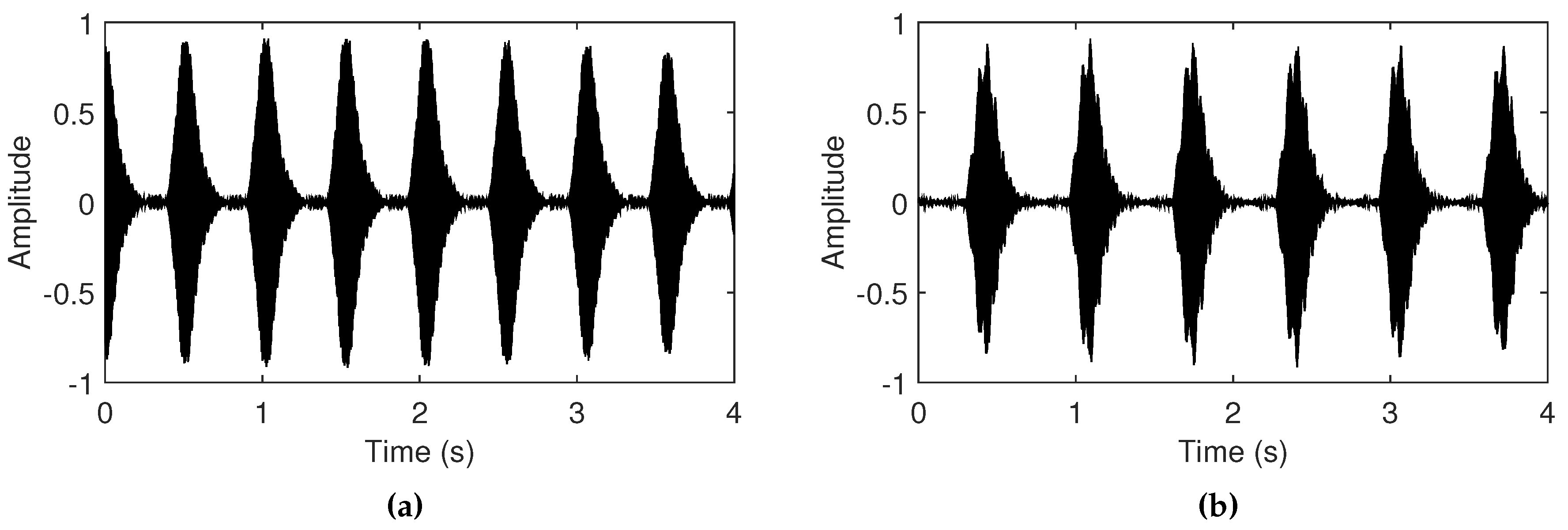
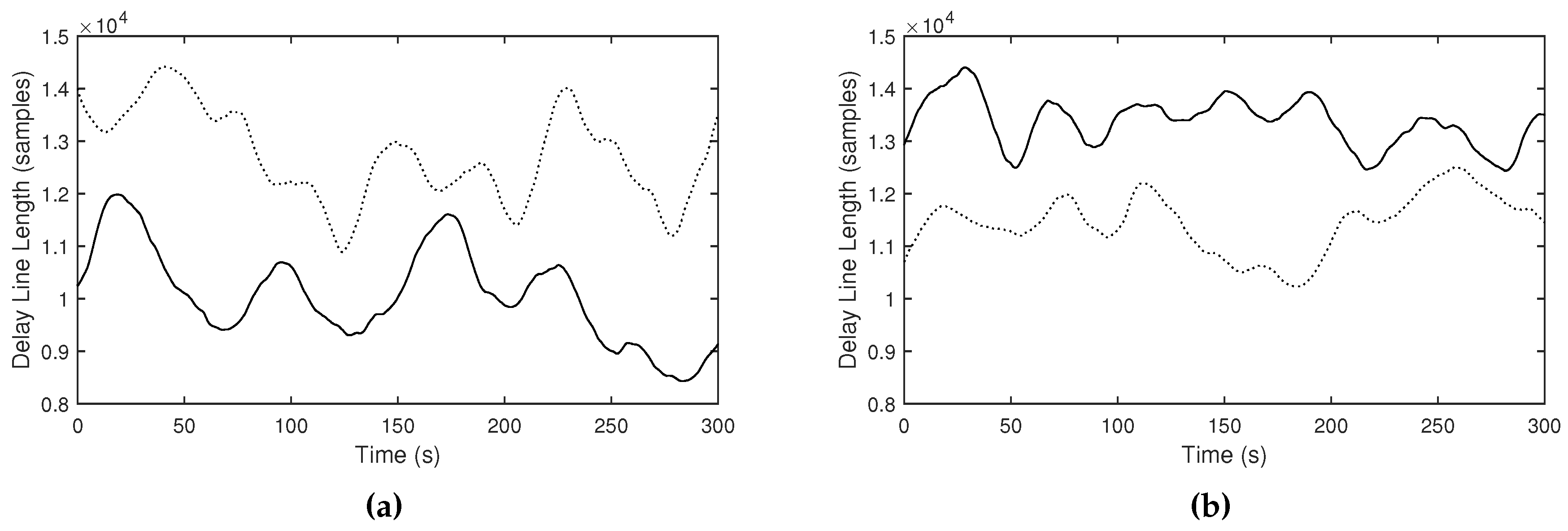
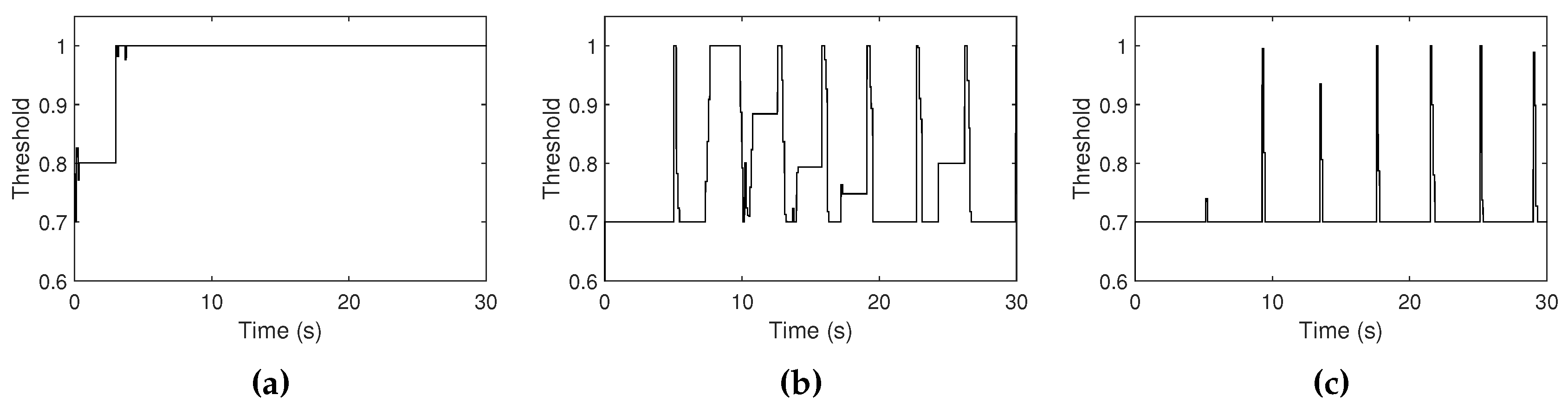
4.1. Observations in Different Room Reverberations
4.2. Observations in Different Ambient Noise Levels
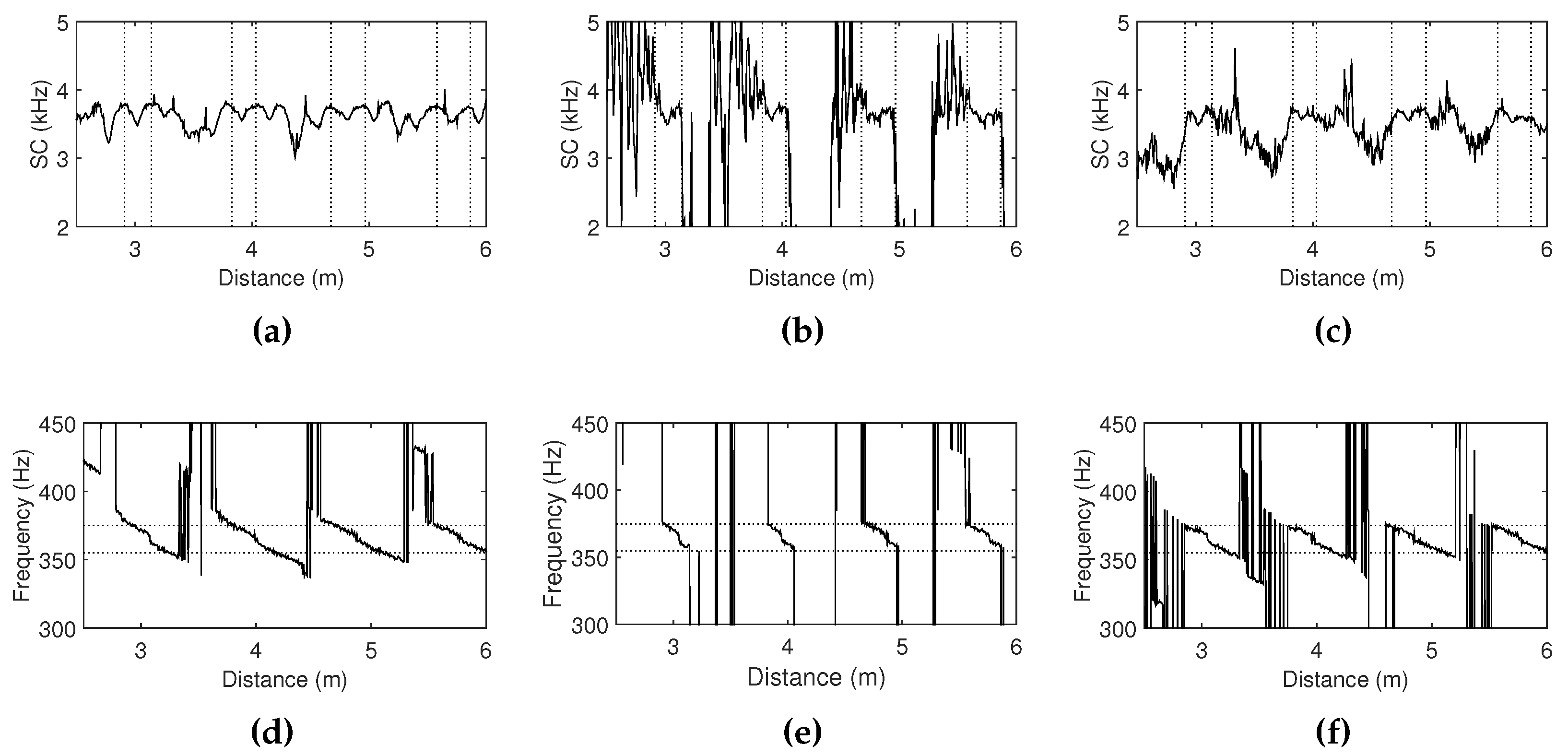
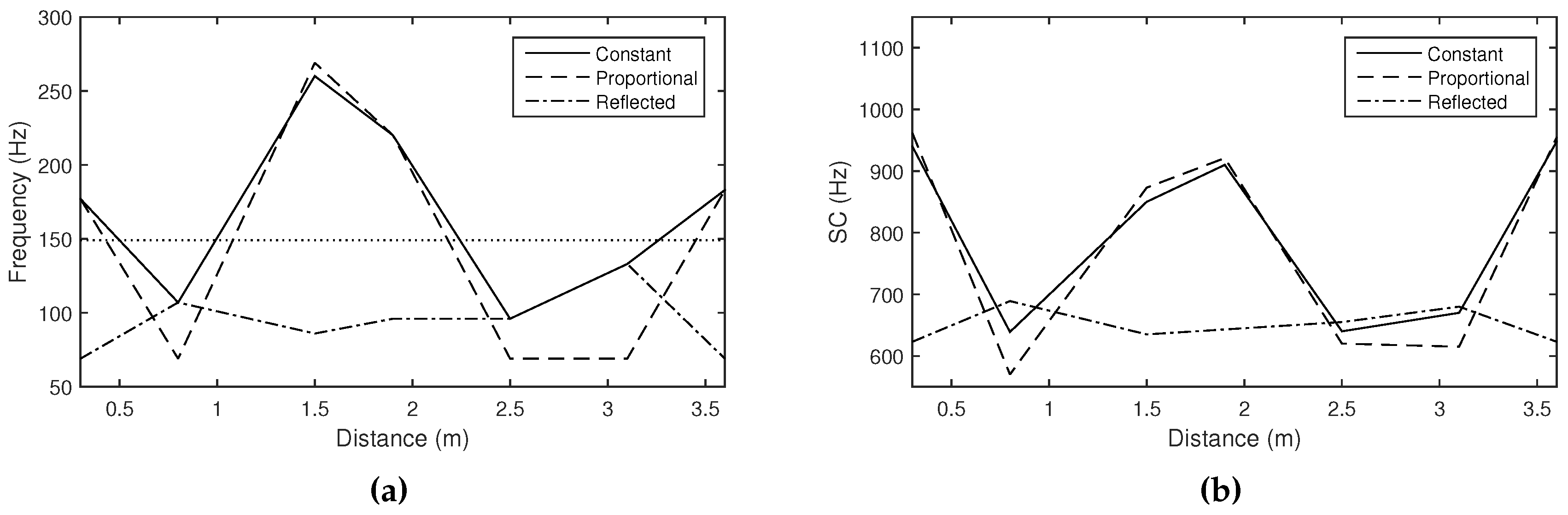
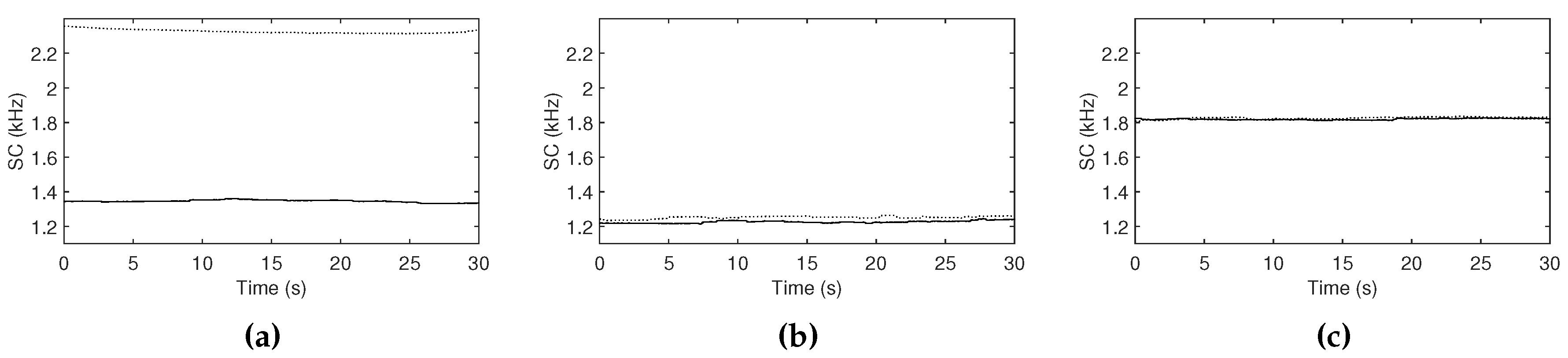
4.3. Observations with Different Acoustic Resonances
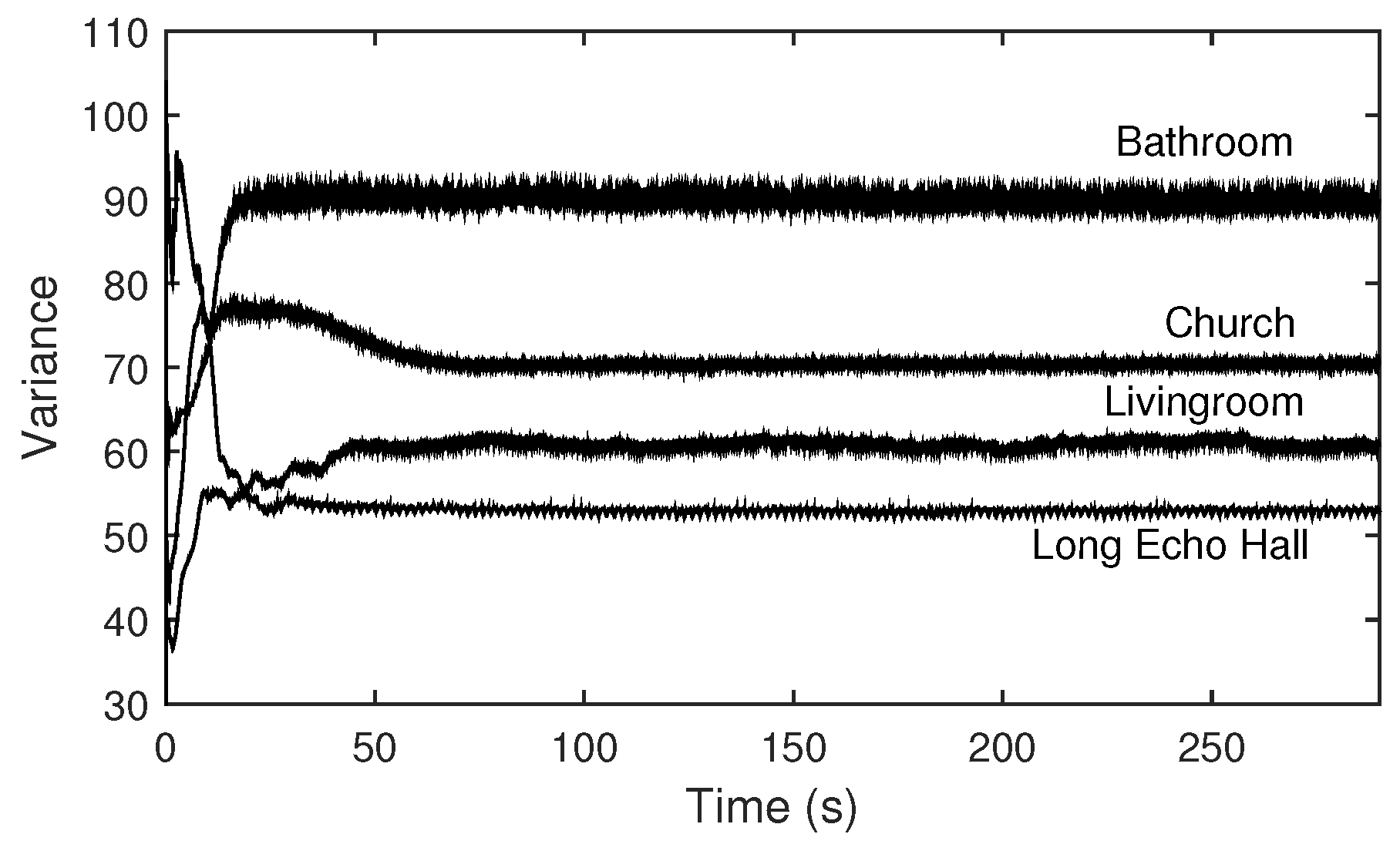
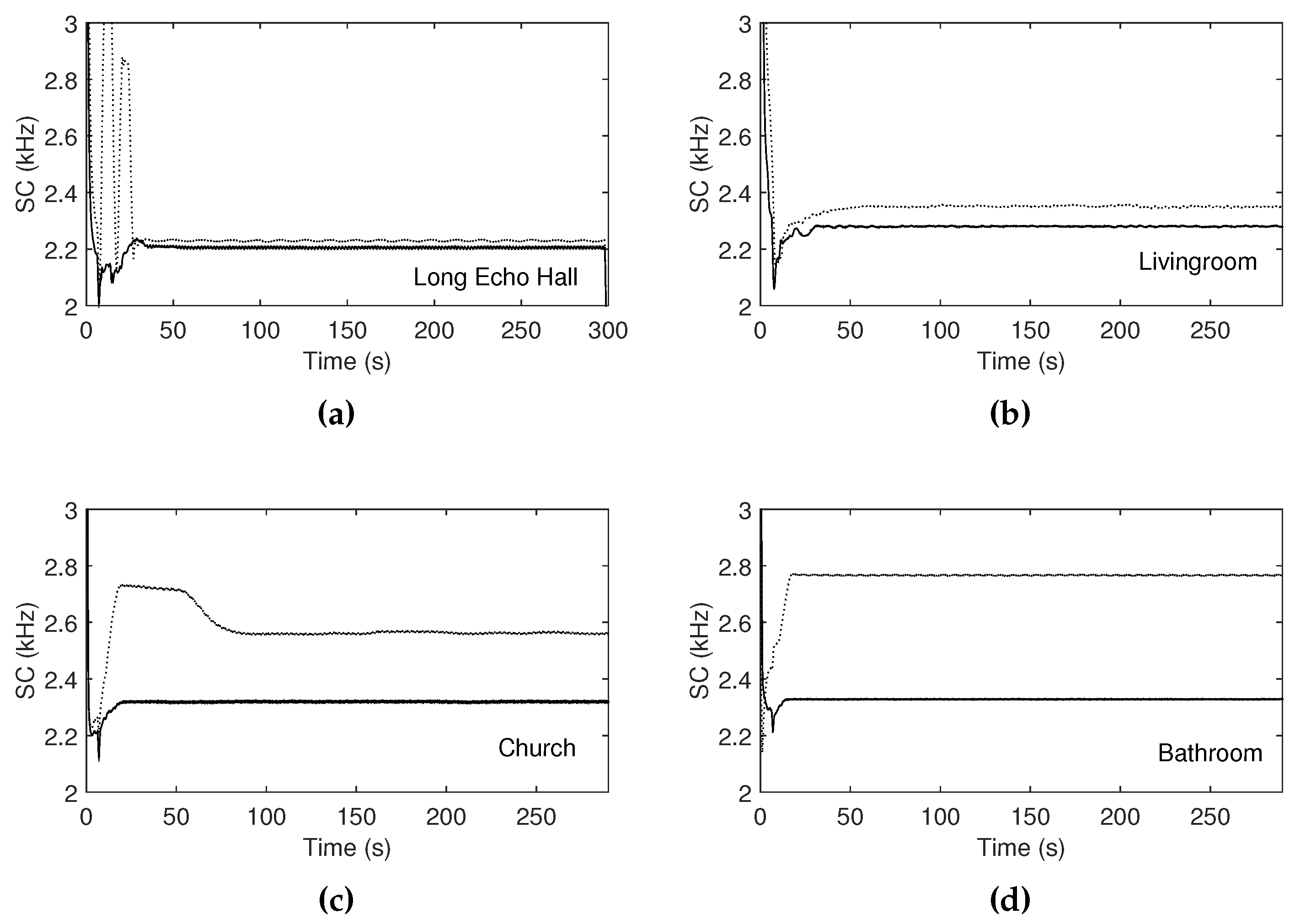
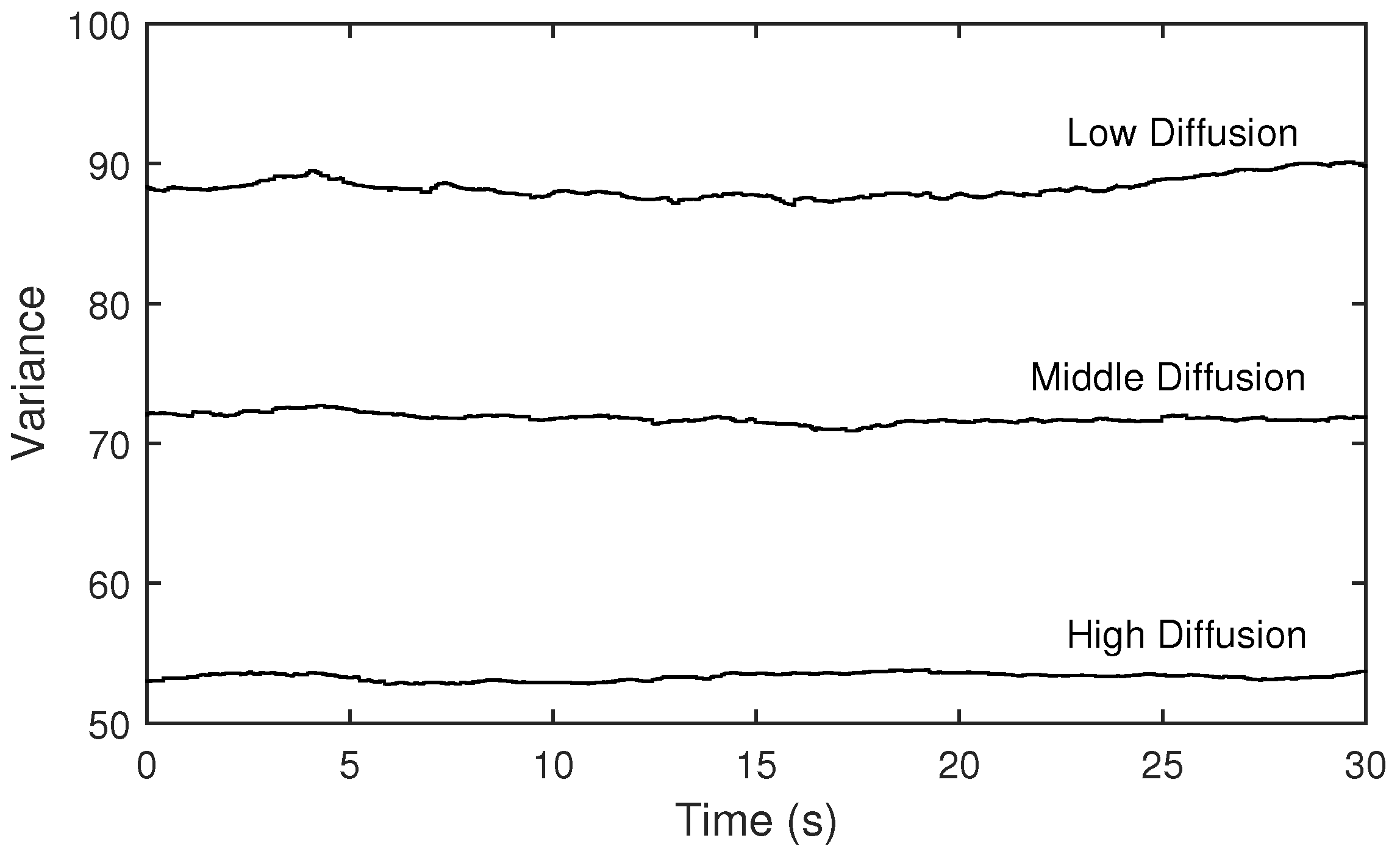
4.4. Observations with Different Distributions of Room Modes
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Reich, S. Pendulum Music; Universal Editor: London, UK, 1968. [Google Scholar]
- Sanfilippo, D.; Valle, A.; Elettronica, M. Feedback Systems: An Analytical Framework. Comput. Music J. 2013, 37, 12–27. [Google Scholar] [CrossRef]
- Di Scipio, A. “Sound is the interface”: From Interactive to Ecosystemic Signal Processing. Organ. Sound 2003, 8, 269–277. [Google Scholar] [CrossRef]
- Kollias, P.A. Ephemeron : Control over Self-Organised Music. In Proceedings of the 5th International Conference of Sound and Music Computing, Berlin, Germany, 31 July–3 August 2008; pp. 138–146.
- Kim, S.; Nam, J.; Wakefield, G. Toward Certain Sonic Properties of an Audio Feedback System by Evolutionary Control of Second-Order Structures. In Proceedings of the 4th International Conference (and 12th European event) on Evolutionary and Biologically Inspired Music, Sound, Art and Design (Part of Evostar 2015), Copenhagen, Denmark, 8–10 April 2015.
- Berdahl, E.; Harris, D. Frequency Shifting for Acoustic Howling Suppression. In Proceedings of the 13th International Conference on Digital Audio Effects, Graz, Austria, 6–10 September 2010.
- Gabrielli, L.; Giobbi, M.; Squartini, S.; Valimaki, V. A Nonlinear Second-Order Digital Oscillator for Virtual Acoustic Feedback. In Processing of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 7485–7489.
- Karjalainen, M.; Välimäki, V.; Tolonen, T. Plucked-String Models: From the Karplus-Strong Algorithm to Digital Waveguides and Beyond. Comput. Music J. 1998, 17–32. [Google Scholar] [CrossRef]
- Kim, S.; Kim, M.; Yeo, W.S. Digital Waveguide Synthesis of the Geomungo with a Time-varying Loss Filter. J. Audio Eng. Soc. 2013, 61, 50–61. [Google Scholar]
- Smith, J.O. Physical Modeling using Digital Waveguides. Comput. Music J. 1992, 16, 74–91. [Google Scholar] [CrossRef]
- Sullivan, C.R. Extending the Karplus-Strong Algorithm to Synthesize Electric Guitar Timbres with Distortion and Feedback. Comput. Music J. 1990, 14, 26–37. [Google Scholar] [CrossRef]
- Gustafsson, F. System and Method for Simulation of Acoustic Feedback. US Patent 7,572,972, 2009. [Google Scholar]
- Waters, S. Performance Ecosystems: Ecological Approaches to Musical Interaction. EMS: Electroacoustic Music Studies Network, 2007; pp. 1–20. [Google Scholar]
- Overholt, D.; Berdahl, E.; Hamilton, R. Advancements in Actuated Musical Instruments. Organ. Sound 2011, 16, 154–165. [Google Scholar] [CrossRef]
- Kollias, P.A. The Self-Organising Work of Music. Organ. Sound 2011, 16, 192–199. [Google Scholar] [CrossRef]
- Scamarcio, M. Space as an Evolution Strategy. Sketch of a Generative Ecosystemic Structure of Sound. In Proceedings of the Sound and Music Computing Conference, Berlin, Germany, 31 July–3 August 2008; pp. 95–99.
- Di Scipio, A. Listening to Yourself through the Otherself: On Background Noise Study and Other Works. Organ. Sound 2011, 16, 97–108. [Google Scholar] [CrossRef]
- Aufermann, K. Feedback and Music: You Provide the Noise, the Order Comes by Itself. Kybernetes 2005, 34, 490–496. [Google Scholar] [CrossRef]
- Impulse Responses Made by Fokke van Saane. Available online: http://fokkie.home.xs4all.nl/IR.htm (accessed on 23 April 2016).
- Free Reverb Impulse Responses. Available online: http://www.voxengo.com/impulses (accessed on 23 April 2016).
- Lerch, A. An Introduction to Audio Content Analysis: Applications in Signal Processing and Music Informatics; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Fritz, C.; Blackwell, A.F.; Cross, I.; Woodhouse, J.; Moore, B.C. Exploring Violin Sound Quality: Investigating English Timbre Descriptors and Correlating Resynthesized Acoustical Modifications with Perceptual Properties. J. Acoust. Soc. Am. 2012, 131, 783–794. [Google Scholar] [PubMed]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Information | Approximation Methods | Control Targets | Control Methods |
|---|---|---|---|
| Reverberation | Cross-correlation of input/output | Tempo | Delay line length |
| Ambient noise volume | Peak amplitude | Output level | Gain threshold |
| Acoustic resonance | Freq. of maximum energy | Timbre | LPF cutoff freq. |
| Distribution of room modes | Variance of magnitudes | Timbre | HPF gain |
| from the transfer function |
| Room Types | RT60 (s) | Xcorr | ||
|---|---|---|---|---|
| Livingroom | 0.28 | 0.0407 | 23496 | 46991 |
| Bathroom | 0.58 | 0.1365 | 30674 | 42633 |
| Church | 0.97 | 0.4205 | 46311 | 30691 |
| Long Echo Hall | 3.07 | 0.4904 | 59604 | 25302 |
| Room Types | Spectral Flatness | Var(||) | Var(||) | g |
|---|---|---|---|---|
| Long Echo Hall | 0.85 | 29.71 | 52.90 | 0.56 |
| Livingroom | 0.83 | 31.52 | 61.08 | 0.74 |
| Church | 0.73 | 52.68 | 70.37 | 0.95 |
| Bathroom | 0.64 | 79.15 | 90.00 | 1.0 |
| RT30 (s) | ||
|---|---|---|
| 0.65 | 12720 | 11450 |
| 1.33 | 11690 | 11940 |
| 8.50 | 10070 | 13360 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.; Wakefield, G.; Nam, J. Augmenting Environmental Interaction in Audio Feedback Systems. Appl. Sci. 2016, 6, 125. https://doi.org/10.3390/app6050125
Kim S, Wakefield G, Nam J. Augmenting Environmental Interaction in Audio Feedback Systems. Applied Sciences. 2016; 6(5):125. https://doi.org/10.3390/app6050125
Chicago/Turabian StyleKim, Seunghun, Graham Wakefield, and Juhan Nam. 2016. "Augmenting Environmental Interaction in Audio Feedback Systems" Applied Sciences 6, no. 5: 125. https://doi.org/10.3390/app6050125
APA StyleKim, S., Wakefield, G., & Nam, J. (2016). Augmenting Environmental Interaction in Audio Feedback Systems. Applied Sciences, 6(5), 125. https://doi.org/10.3390/app6050125