1. Introduction
According to National Highway Traffic Safety Administration (NHTSA), drowsy driving causes more than 100,000 crashes a year [
1]. Drowsiness, in general, refers to a driver in a trance state while driving. The most common symptom of drowsiness includes excessive yawning and frequent eye-blinking due to difficulty of keeping one’s eyes open. Symptoms also include reduced steering wheel operation and frequent head-nodding. The European Transport Safety Council (ETSC) (Brussels, Belgium)indicates that increment of the above-mentioned symptoms means that the driver is in drowsiness [
2].
Automotive manufacturers are conducting diverse researches focusing on anti-drowsiness safety devices to prevent drowsy driving. Typical driver drowsiness detection methods includes learning driving patterns (operation of steering, speed acceleration/reduction, gear operation) or measuring brainwave (EEG), heartbeat, and body temperature to recognize and prevent the drowsy driving. Among many approaches, the non-contact sensor such as camera is often favored in detecting yawning, or tracking the head movement and eye-blink of the driver. Indeed, NHTSA and ETSC manuals suggest that detection and tracking of driver’s eye-blinking is the most reliable way in determining the consciousness level of the driver.
Given that camera sensors are now cheap and can be combined with the infra-red LEDs for the night driving environment, it appears that observing visual appearance of the face in determining the mental state of the driver becomes a main trend. In doing so, it is essential to have a good face model by which we can track the driver’s the face and facial features reliably against head pose variation, illumination change, and self-occlusion occurring sporadically during the natural driving situation.
One of the popular face models was initially proposed by Tim Cootes, the so called Point Distribution Model (PDM) [
3,
4]. There are two variations of it: one is Active Appearance Model (AAM) and the other Active Shape Model (ASM). AAM consists of appearance and shape parameters. Two versions have been developed depending on the way of dealing with these parameters: the initial model is the combined AAM [
5] and the other the independent AAM [
6].
AAM has been very successful in face recognition, face tracking, and facial expression recognition areas. Yet its performance varies depending on the training method and the amount of data. Moreover, it is slow since it requires a lot of computation during the fitting, and it suffers from illumination variation and occlusion. Although an improvement regarding to the illumination variation, occurring frequently in the mobile environment, has been reported by adopting a Difference of Gaussian (DoG) filter [
7], the speed and occlusion problems are yet to be solved.
ASM has been developed to align the shape of the face and it has a certain advantage in terms of speed simply because it has only one set of parameters (
i.e., the shape). However, the whole alignment process can be degraded by an error on any landmark drawn on the tracking face. To handle such problem, the Constrained Local Model (CLM) has been proposed [
8], where each shape landmark detects the local feature and then carries out tracking independently. Therefore, the performance critically depends on local feature detection and tracking, rather than any training method and data. In CLM, the shape generated at each landmark has the highest probability. Since each landmark is processed independently, it allows parallel processing. In the conventional AAM and ASM, the previous error often affects the present state. However, any error occurring in a local feature detector has minimal impact to the overall performance since each landmark behaves independently. Due to such reasons, ASM based on CLM shows robustness against occlusion.
In this study, we will use an updated version of ASM, called it Discriminative Bayesian—Active Shape Model (DB-ASM) [
9,
10] as a base model. Yet, even this model cannot deal with the extremes head pose cases well, for instance, when the driver looks at the side mirrors. Compared to the standard face model that contains average shape landmarks during the training stage, the extended version includes six more average shape landmarks to cover the extreme poses, such as look up, look down, rotated left, rotated right, look left, and look right, respectively, so called Pose Extended ASM (PE-ASM). Note that each head pose model has been independently trained. The POSIT (Pose from Orthography and Scaling with Iterations) algorithm is employed to estimate the present head pose of the given face [
11]. When the driver’s head pose crosses a certain threshold along a given direction, PE-ASM detects that and assigns the corresponding extreme average shape. Thus, the newly assigned model can track the head even when the head is in an extreme pose.
In monitoring driver’s drowsiness, many previous studies have actually adopted the geometrical approach rather than the statistical one, presumably because the latter is heavy or is not reliable at that time. For instance, Ji and Yang [
12] were able to build a real-time system using several visual cues, such as gaze, face pose, eyelid closure, approached by the geometrical perspective. Recently, Mbouna
et al. [
13] proposed a driver alertness monitoring system where a 3D graphical head model is combined with a POSIT algorithm in estimating driver’s head pose, and an eye index is designed in determining eye opening during driving.
Markov models are stochastic models used in analysis of time varying signals. Since HMM has been a powerful tool in modelling continuous signals, such as natural language processing, speech understanding, and computer vision [
14]. Modified versions of HMMs have also been proposed for computer vision, such as coupled or multi-dimensional models. It is shown that driver’s eye-movements can be modelled using an HMM [
15]. The driver’s behavior has also been modelled using HMM [
16]. In the present study, we have used a Markov chain framework whereby the driver’s eye-blinking and head nodding are separately modelled based upon their visual features, and then the system makes a decision by combining those behavioral states of whether the driver is drowsy or not, according to a certain criteria.
3. Detecting a Drowsy Driver
3.1. Head Pose Estimation by the POSIT Algorithm
In this study, the POSIT algorithm is used in estimating the head pose of the driver [
11]. Head rotation is calculated by using the initialized standard 3D coordinate and current 2D shape coordinate. It calculates rotation and translation based on the correlation between points on the 2D coordinate space and corresponding points in the 3D coordinate space. Equation (10) is the formula for the POSIT algorithm.
Here, (X, Y, Z) represents the coordinate of 3D and (, ) that of 2D, which is obtained based on projection. The camera matrix has intrinsic parameters, which are the center point of image, (,), scale factor (), and focal length between pixels (,), respectively. The rotation matrix and translation matrix are extrinsic parameters that have and , respectively. The POSIT algorithm estimates the rotation matrix and translation matrix in 3D space.
To use the POSIT algorithm in estimating head pose, a 3D face model is built using FaceGen Modeler 3.0, where the size of 3D face model is average and the coordinate of this 3D space is identical with that of the facial feature. The coordinates of generated 3D facial features are used for input to POSIT.
3.2. Pose Extended-Active Shape Model
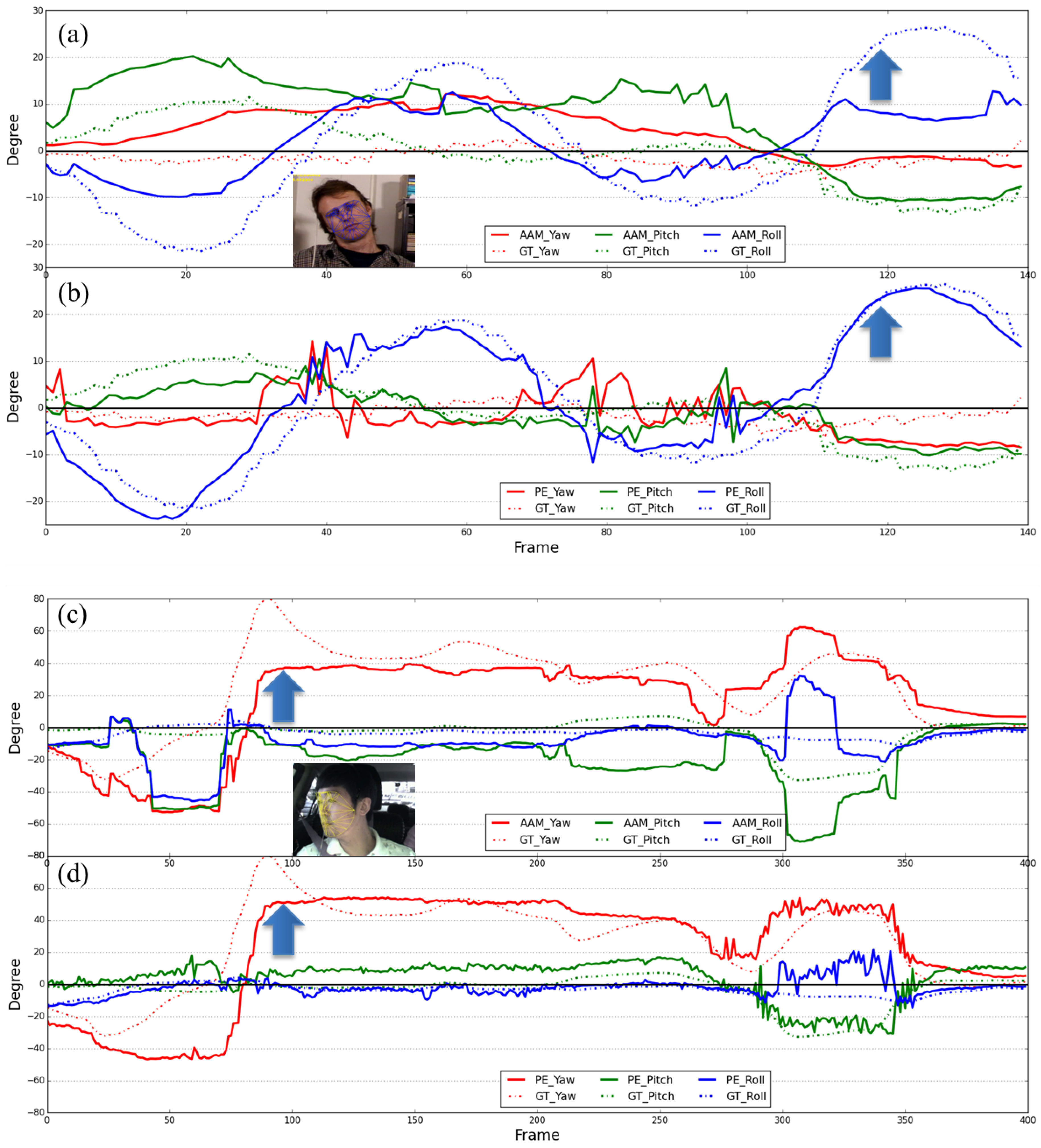
In general, it is known that the head pose of a driver changes continuously since one drives a car while watching the side mirrors and rear mirror in turn. In this study, the range of head movement occurred while driving is utilized to determine whether the driver is drowsy or not. In particular, the change of head pose is significant when the driver is looking at the side-mirror to the right rather than the side-mirror to the left. The change of the driver’s head pose and its frequency become an important factor in determining drowsiness of the given driver.
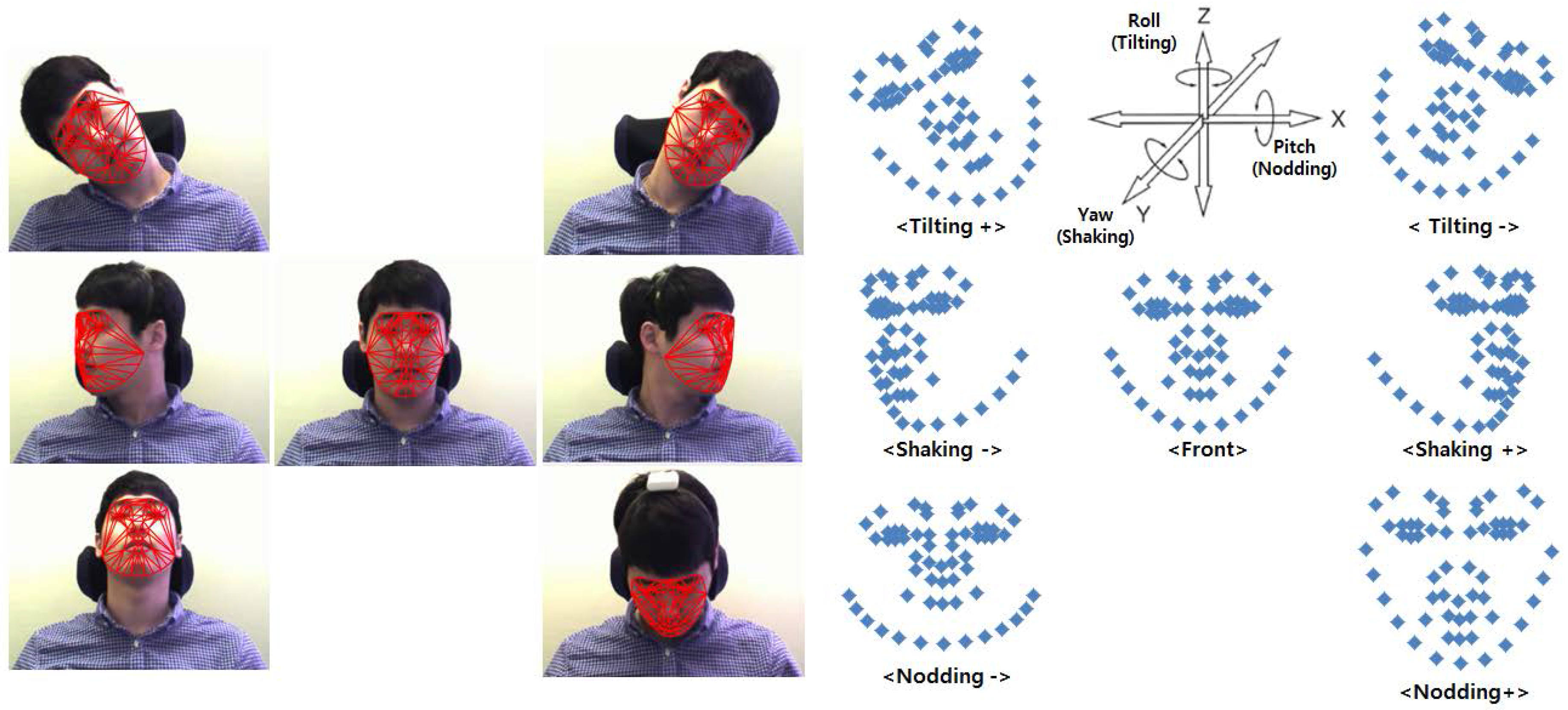
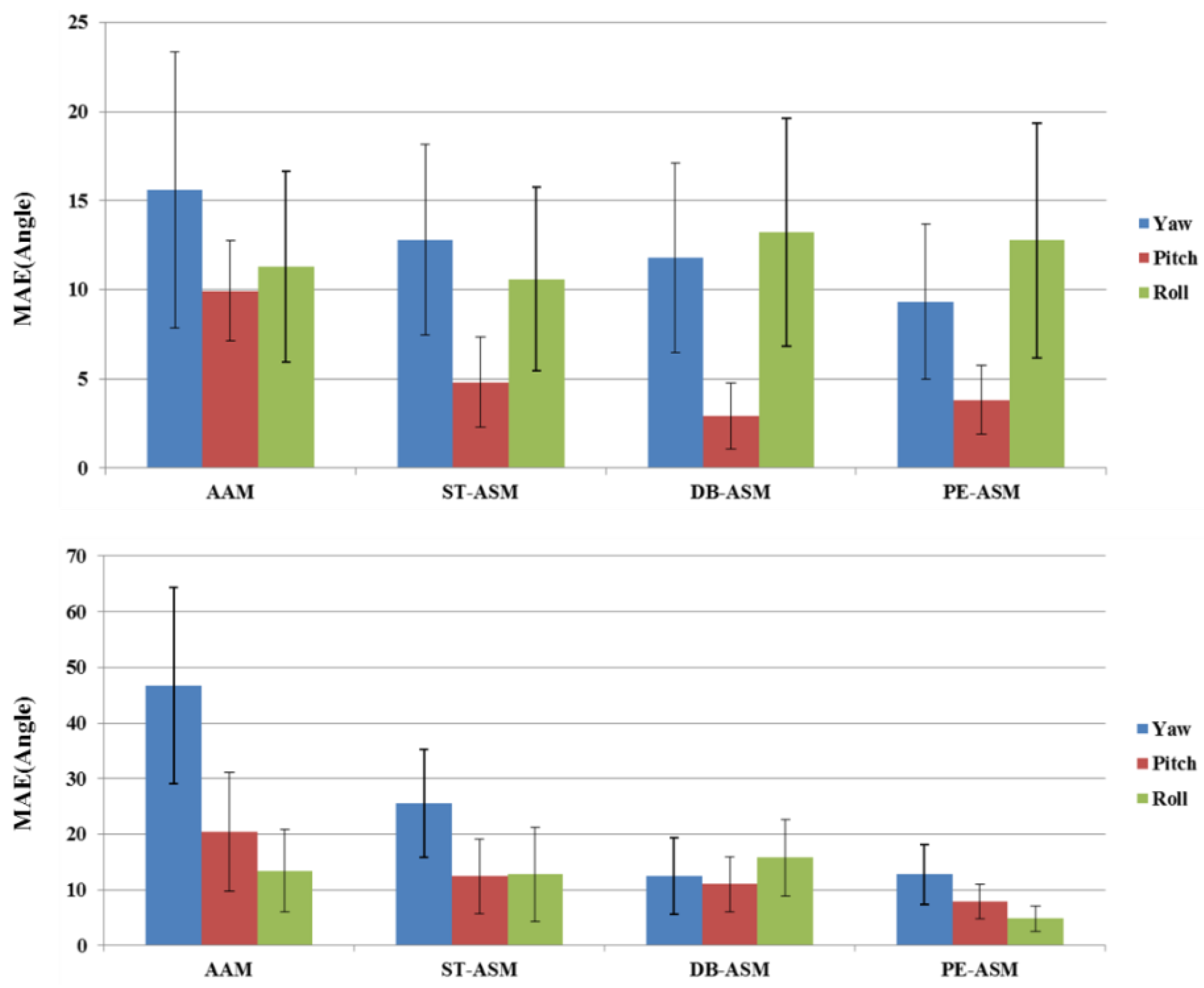
Among many, we can think of two statistical face models, favored in the computer vision community, for the present purpose. One of them is Active Shape Model (ASM) and the other is Active Appearance Model (AAM). Given that the head poses of the normal driver are very diverse and some of them are obviously extreme, the face model certainly needs to deal with such extreme pose cases. However, it is well known that these face models have been effective in estimating the head pose, which is less than about 30°, called the average face shape. Therefore, they cannot deal well in the cases where the head pose is higher than 30°, called the extreme head pose cases.
The reason is that some of extreme shape vectors are lost in carrying out the Principal Component Analysis (PCA) process. Moreover, since the locations of the average face shape significantly differ from those of the extreme shape, it is difficult to correct the fitting error. For instance, DB-ASM model typically uses the average shape model even when the head pose has increased more than a certain angle. In such case, the shape fitting becomes difficult and the fitting error is increased.
In this study, we have extended DB-ASM to include the extreme pose cases as illustrated in
Figure 2, called it Pose Extended ASM (PE-ASM), where six extreme head poses are embedded into the basic model. On the right of the same figure, the center is the average shape model, and the other six shape models correspond to the extreme head pose cases, respectively. In other words, we have trained seven different DB-ASMs including the frontal face model. We have used the threshold values, as indicated in
Table 1, in categorizing the head pose of the current face. In
Section 3.1, it is shown that the POSIT algorithm is used in estimating the head pose of the given face. According to the estimated head pose value, the corresponding shape model is assigned among the seven head pose categories. Therefore, our face model is a head pose-specific model. Once the shape model is assigned, the face fitting starts with it and iterates until the error converges to a certain threshold.
3.3. Detection of Eye-Blink
It is known that when humans get drowsy, the blood is moving to the end of hands and feet, and the eyes are blinked more often because tear production in the lachrymal glands is reduced. In addition, the blood supply to the brain is also reduced. As a result of these, the person goes into a trance state as the brain activity is naturally reduced.
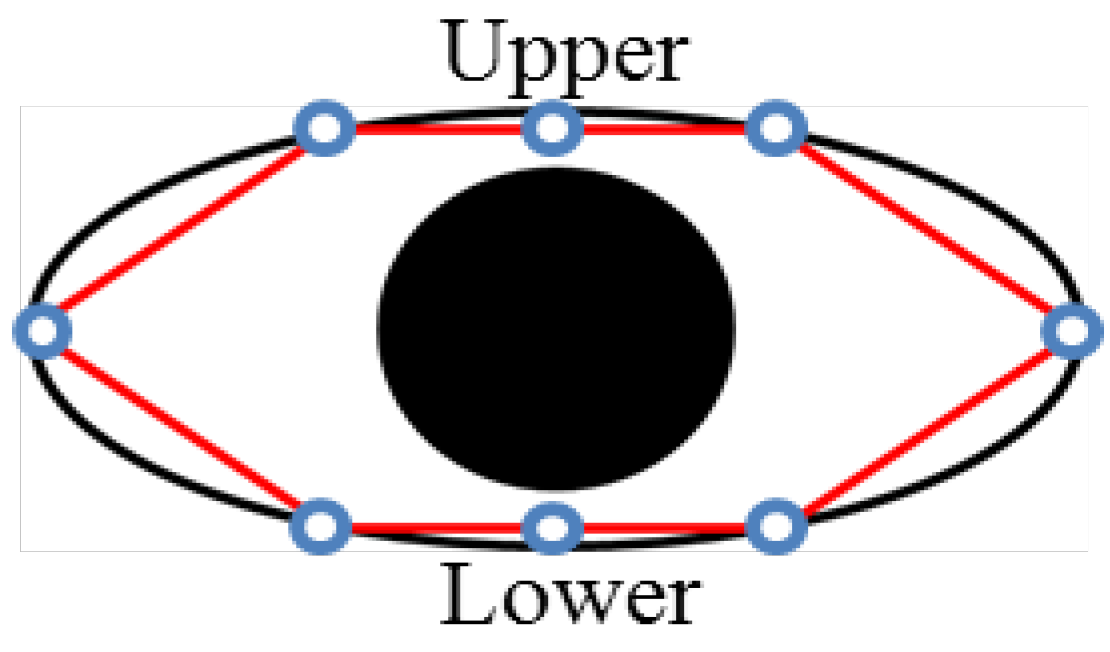
In the present study, eye-blink of the driver was counted based on the shape point around the eyes as shown in
Figure 3. When the eye of a driver blinks, the upper and lower points naturally come closer to each other.
The number of blinks can be determined with the following equation. When
d in Equation (11) is less than 80% to the maximum height of eyes, we consider it as a blink state. To make the ground truth of eye-blinking, three experts are employed: one for the judgment of blinking and two others for its verification.
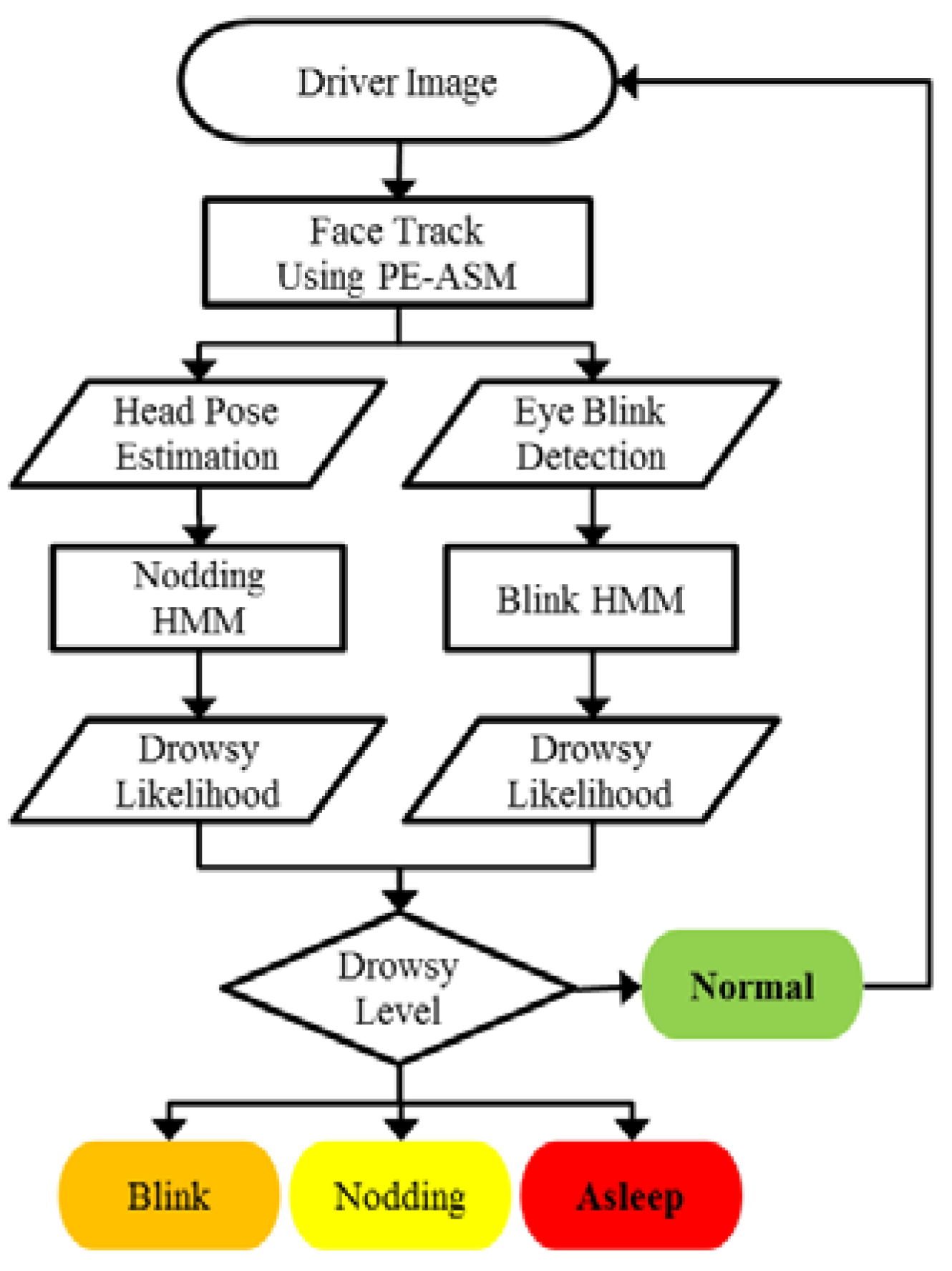
3.4. Hidden Markov Model for Drowsiness Detection
HMM can be classified into the following types upon the modeling of output probabilities: (1) HMM with discrete probabilities distribution predicts the observed output probabilities with the discrete characteristic of the state; (2) HMM with continuous probabilities distribution uses the probability density function allowing the use of a particular vector of error in the absence of a quantization process for a given output signal; and (3) HMM with semi-continuous distribution poses, combining the advantages of the two aforementioned models—the probability values in HMM with discrete probabilities and the probability density function in the HMM with the continuous probabilities distribution.
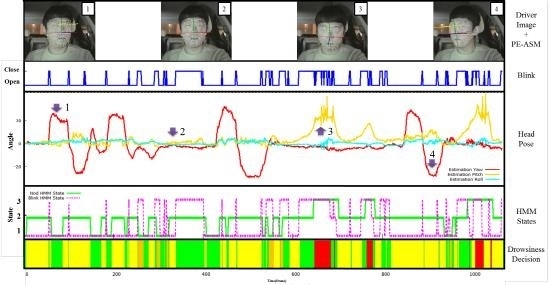
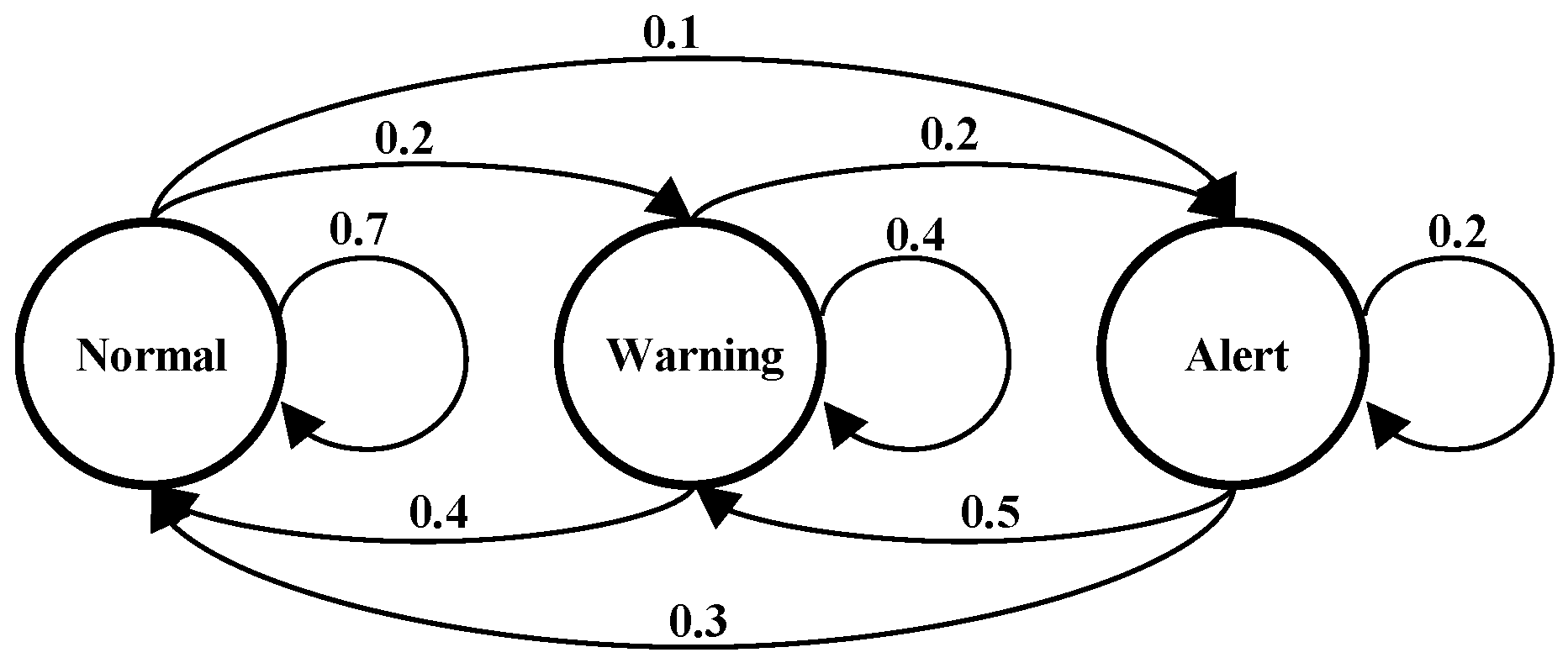
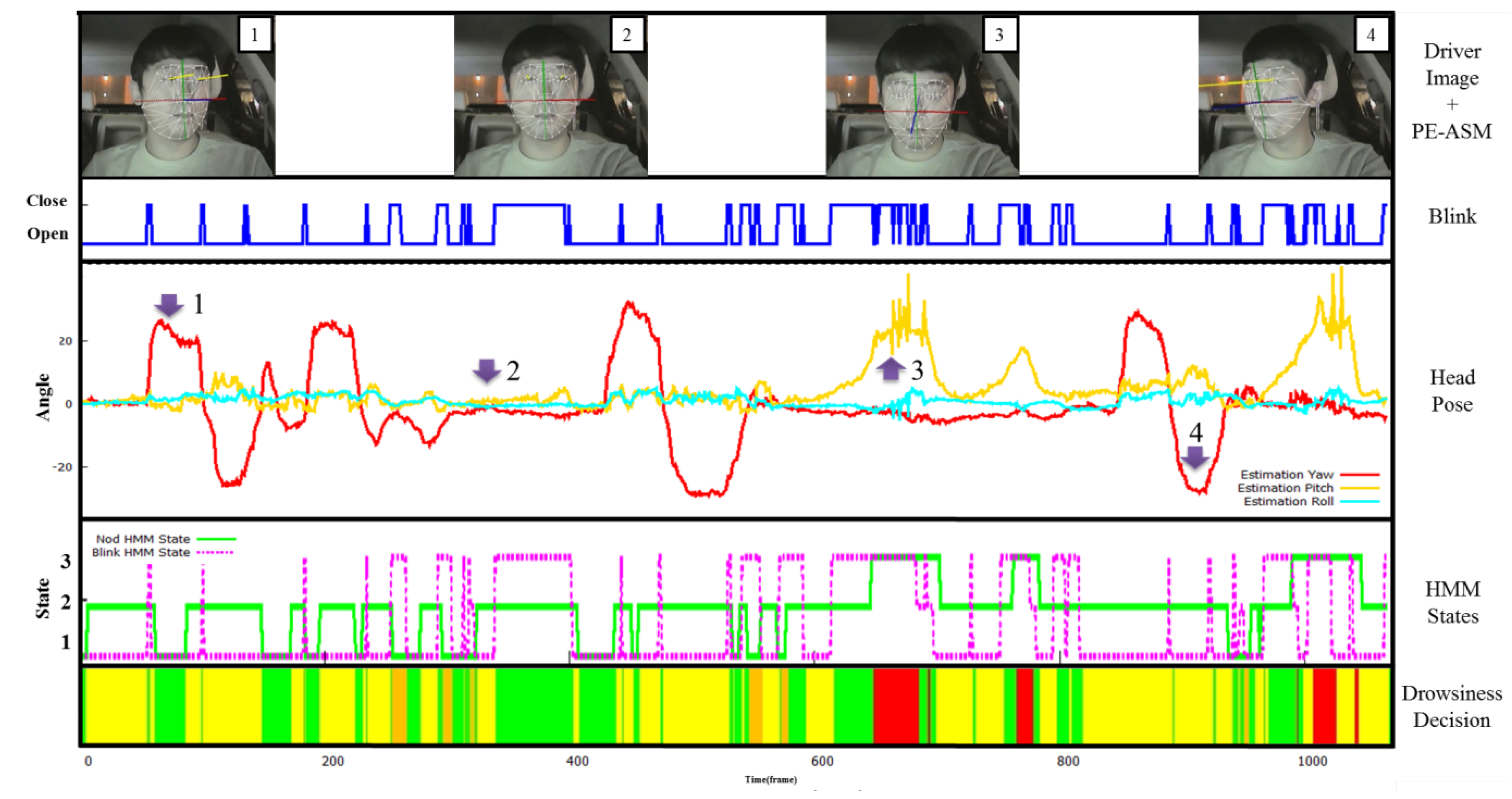
Figure 4 presents our HMM structure that consists of three different mental states of the driver. The head pose estimation and eye-blinking detection were used to create the HMM observation symbols and predict the probabilities of the parameter with the Baum-Welch algorithm, calculating the symbol state for each state. Here, it is considered that the transition probability and initial value of symbol probability at each state are equivalent when calculating the transition probability at each state. The predicted probability distribution, as well as the Viterbi algorithm, were used as a test sequence to obtain the sequence at the best state, selecting the best matching state.
For the present study, the GHMM (General Hidden Markov Model) public library, which is a standard HMM package, is used [
18]. The driver’s head position and eye-blinking output are used to predict the state most suitable to the driver’s state: one is an eye-blinking HMM and the other a nodding HMM, as shown in
Figure 5. For training of the two HMMs, the videos are divided into many segments and each segment consists of 15 frames. The total is about 23,000 frames, and 70% of them are used for training and 30% of them for testing. The recognition rate during the training phase was 98% and during the testing phase was 92%. As training is carried out, the nodding and eye-blink states are enumerated to determine drowsy level of the given driver as shown in
Figure 4. The mental state of the driver is categorized into: normal, warning, and alert. The state transition among the three states is determined by weights, as indicated in
Figure 4.
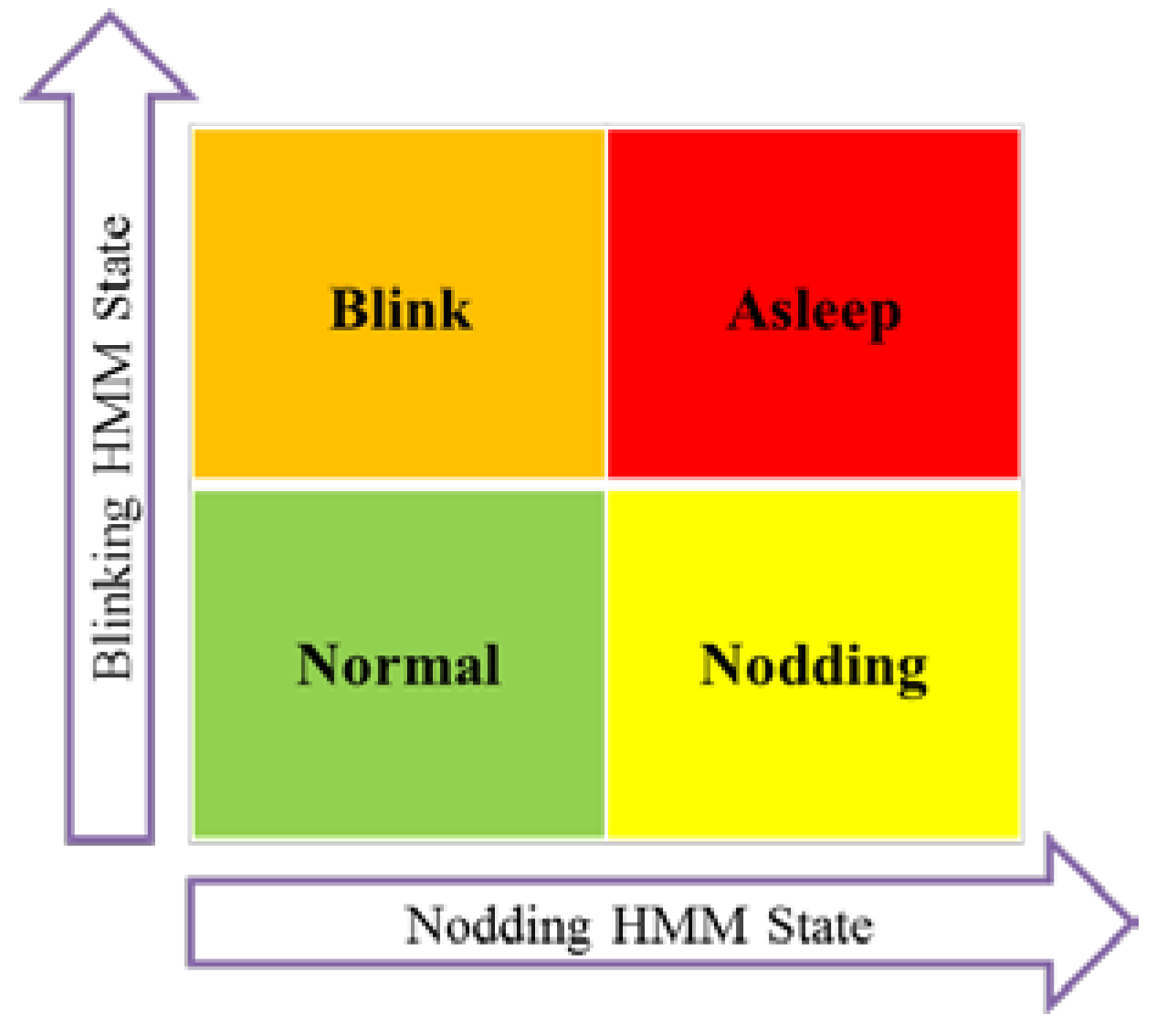
Figure 6 presents the criteria in determining the driver’s final mental state upon the variation of state. It is noticeable that when the eye-blinking and head nodding occur together, the system consider the driver’s state as asleep.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}